 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Analysis of Classification Approaches for Hit Song Prediction using Engineered Metadata Features with Lyrics and Audio Features
Jan 31, 2023


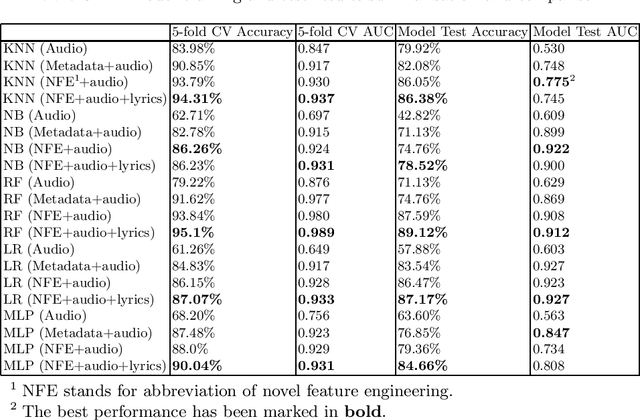
Hit song prediction, one of the emerging fields in music information retrieval (MIR), remains a considerable challenge. Being able to understand what makes a given song a hit is clearly beneficial to the whole music industry. Previous approaches to hit song prediction have focused on using audio features of a record. This study aims to improve the prediction result of the top 10 hits among Billboard Hot 100 songs using more alternative metadata, including song audio features provided by Spotify, song lyrics, and novel metadata-based features (title topic, popularity continuity and genre class). Five machine learning approaches are applied, including: k-nearest neighbours, Naive Bayes, Random Forest, Logistic Regression and Multilayer Perceptron. Our results show that Random Forest (RF) and Logistic Regression (LR) with all features (including novel features, song audio features and lyrics features) outperforms other models, achieving 89.1% and 87.2% accuracy, and 0.91 and 0.93 AUC, respectively. Our findings also demonstrate the utility of our novel music metadata features, which contributed most to the models' discriminative performance.
OrthoReg: Improving Graph-regularized MLPs via Orthogonality Regularization
Jan 31, 2023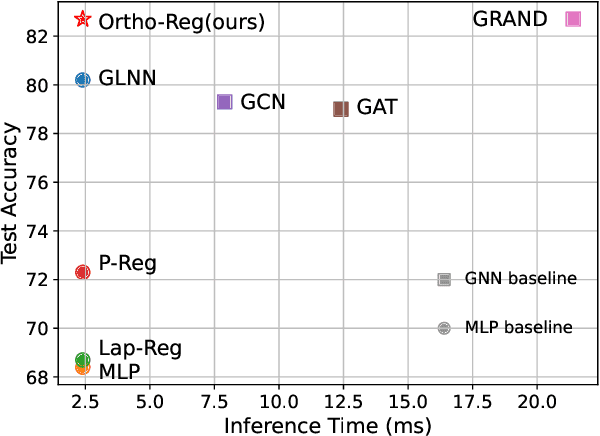
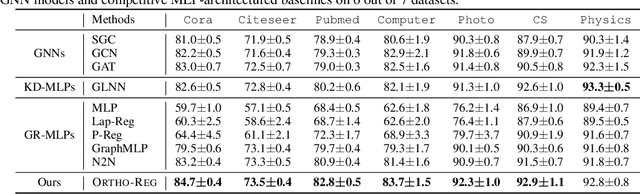
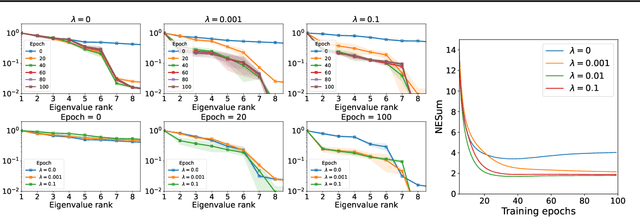
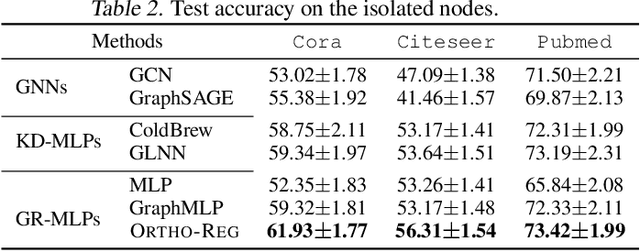
Graph Neural Networks (GNNs) are currently dominating in modeling graph-structure data, while their high reliance on graph structure for inference significantly impedes them from widespread applications. By contrast, Graph-regularized MLPs (GR-MLPs) implicitly inject the graph structure information into model weights, while their performance can hardly match that of GNNs in most tasks. This motivates us to study the causes of the limited performance of GR-MLPs. In this paper, we first demonstrate that node embeddings learned from conventional GR-MLPs suffer from dimensional collapse, a phenomenon in which the largest a few eigenvalues dominate the embedding space, through empirical observations and theoretical analysis. As a result, the expressive power of the learned node representations is constrained. We further propose OrthoReg, a novel GR-MLP model to mitigate the dimensional collapse issue. Through a soft regularization loss on the correlation matrix of node embeddings, OrthoReg explicitly encourages orthogonal node representations and thus can naturally avoid dimensionally collapsed representations. Experiments on traditional transductive semi-supervised classification tasks and inductive node classification for cold-start scenarios demonstrate its effectiveness and superiority.
Towards Deep Learning-aided Wireless Channel Estimation and Channel State Information Feedback for 6G
Sep 05, 2022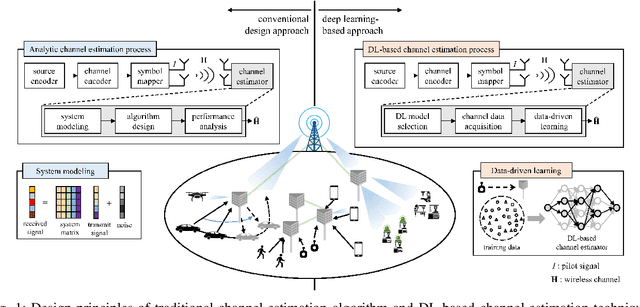
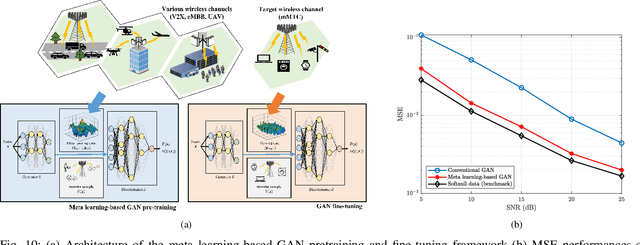
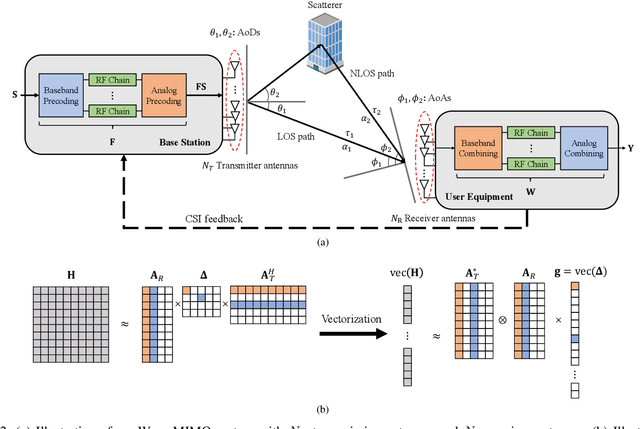
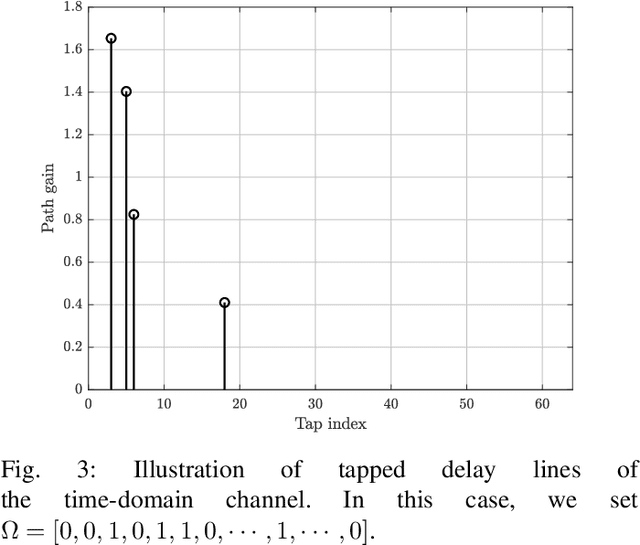
Deep learning (DL), a branch of artificial intelligence (AI) techniques, has shown great promise in various disciplines such as image classification and segmentation, speech recognition, language translation, among others. This remarkable success of DL has stimulated increasing interest in applying this paradigm to wireless channel estimation in recent years. Since DL principles are inductive in nature and distinct from the conventional rule-based algorithms, when one tries to use DL technique to the channel estimation, one might easily get stuck and confused by so many knobs to control and small details to be aware of. The primary purpose of this paper is to discuss key issues and possible solutions in DL-based wireless channel estimation and channel state information (CSI) feedback including the DL model selection, training data acquisition, and neural network design for 6G. Specifically, we present several case studies together with the numerical experiments to demonstrate the effectiveness of the DL-based wireless channel estimation framework.
Context-sensitive neocortical neurons transform the effectiveness and efficiency of neural information processing
Jul 15, 2022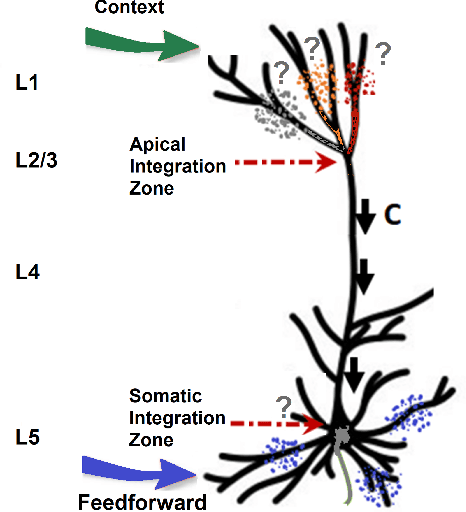
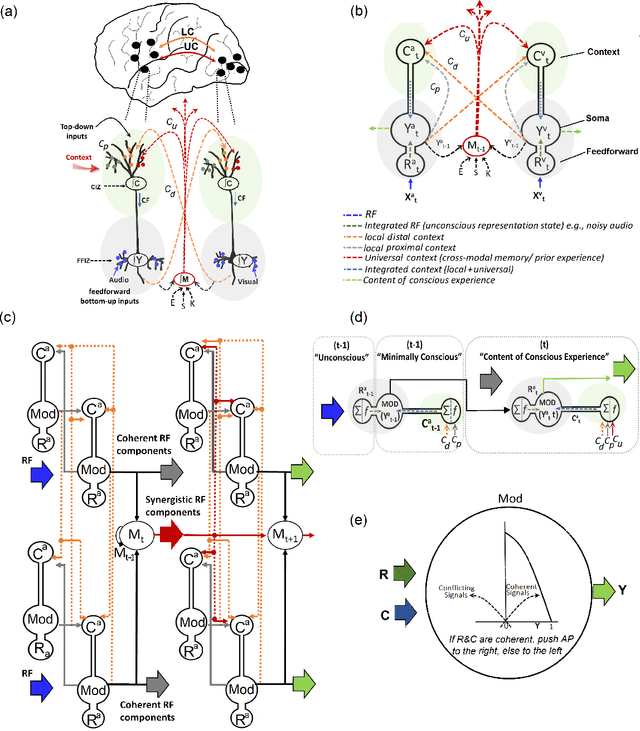
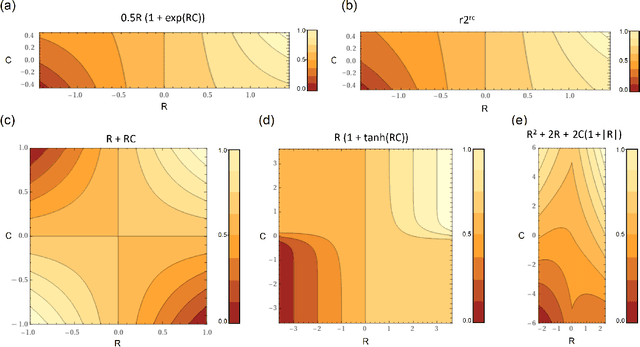
There is ample neurobiological evidence that context-sensitive neocortical neurons use their apical inputs as context to amplify the transmission of coherent feedforward (FF) inputs. However, it has not been demonstrated until now how this known mechanism can provide useful neural computation. Here we show for the first time that the processing and learning capabilities of this form of neural information processing are well-matched to the abilities of mammalian neocortex. Specifically, we show that a network composed of such local processors restricts the transmission of conflicting information to higher levels and greatly reduces the amount of activity required to process large amounts of heterogeneous real-world data e.g., when processing audiovisual speech, these local processors use seen lip movements to selectively amplify FF transmission of the auditory information that those movements generate and vice versa. As this mechanism is shown to be far more effective and efficient than the best available forms of deep neural nets, it offers a step-change in understanding the brain's mysterious energy-saving mechanism and inspires advances in designing enhanced forms of biologically plausible machine learning algorithms.
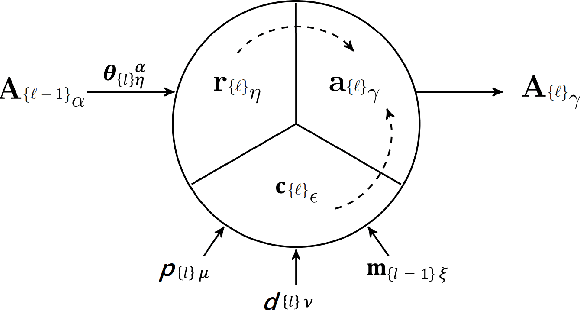
Explainable Data-Driven Optimization: From Context to Decision and Back Again
Jan 24, 2023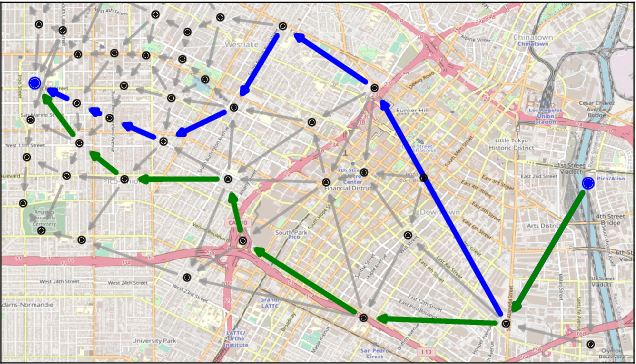
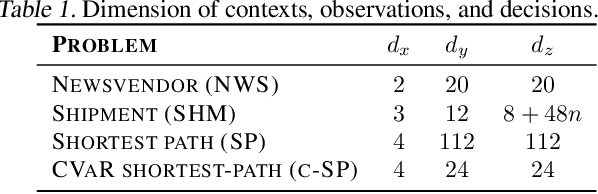
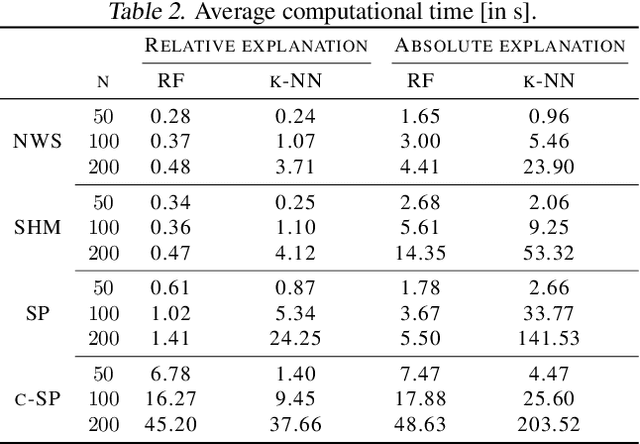
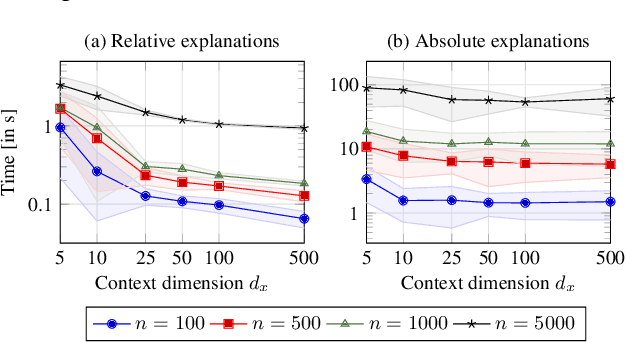
Data-driven optimization uses contextual information and machine learning algorithms to find solutions to decision problems with uncertain parameters. While a vast body of work is dedicated to interpreting machine learning models in the classification setting, explaining decision pipelines involving learning algorithms remains unaddressed. This lack of interpretability can block the adoption of data-driven solutions as practitioners may not understand or trust the recommended decisions. We bridge this gap by introducing a counterfactual explanation methodology tailored to explain solutions to data-driven problems. We introduce two classes of explanations and develop methods to find nearest explanations of random forest and nearest-neighbor predictors. We demonstrate our approach by explaining key problems in operations management such as inventory management and routing.
Task2KB: A Public Task-Oriented Knowledge Base
Jan 24, 2023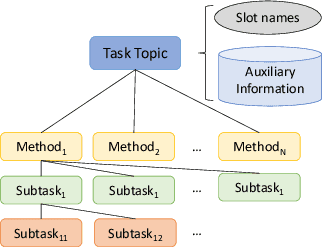
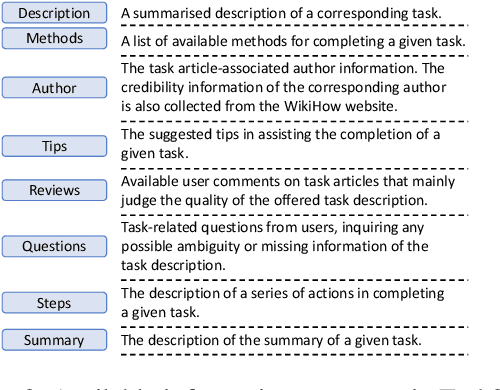
Search engines and conversational assistants are commonly used to help users complete their every day tasks such as booking travel, cooking, etc. While there are some existing datasets that can be used for this purpose, their coverage is limited to very few domains. In this paper, we propose a novel knowledge base, 'Task2KB', which is constructed using data crawled from WikiHow, an online knowledge resource offering instructional articles on a wide range of tasks. Task2KB encapsulates various types of task-related information and attributes, such as requirements, detailed step description, and available methods to complete tasks. Due to its higher coverage compared to existing related knowledge graphs, Task2KB can be highly useful in the development of general purpose task completion assistants
The Dependence of Parallel Imaging with Linear Predictability on the Undersampling Direction
Jan 18, 2023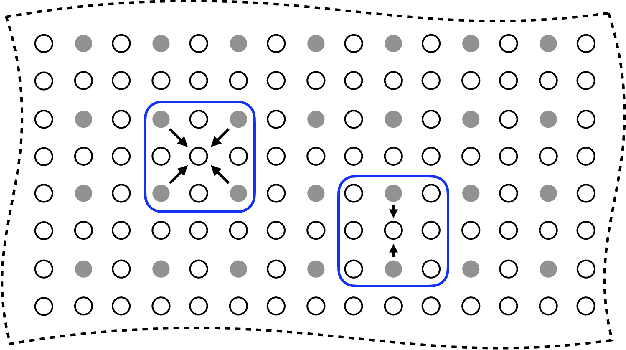
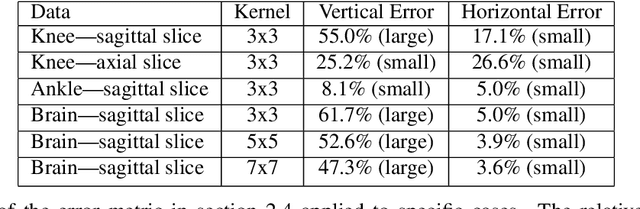
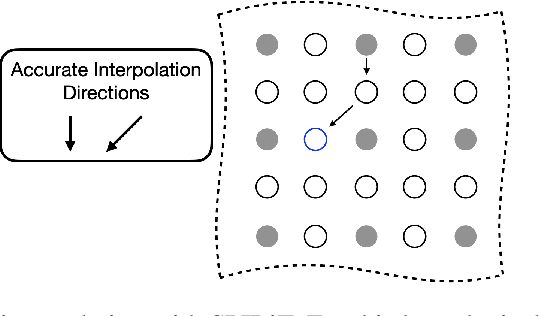
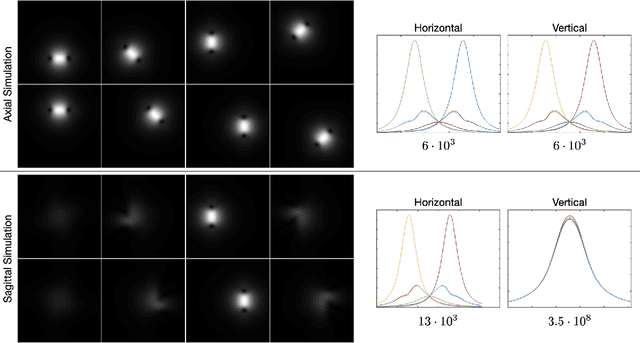
Parallel imaging with linear predictability takes advantage of information present in multiple receive coils to accurately reconstruct the image with fewer samples. Commonly used algorithms based on linear predictability include GRAPPA and SPIRiT. We present a sufficient condition for reconstruction based on the direction of undersampling and the arrangement of the sensing coils. This condition is justified theoretically and examples are shown using real data. We also propose a metric based on the fully-sampled auto-calibration region which can show which direction(s) of undersampling will allow for a good quality image reconstruction.
CoBigICP: Robust and Precise Point Set Registration using Correntropy Metrics and Bidirectional Correspondence
Jan 21, 2023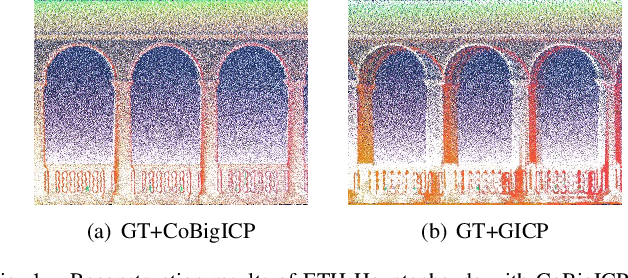
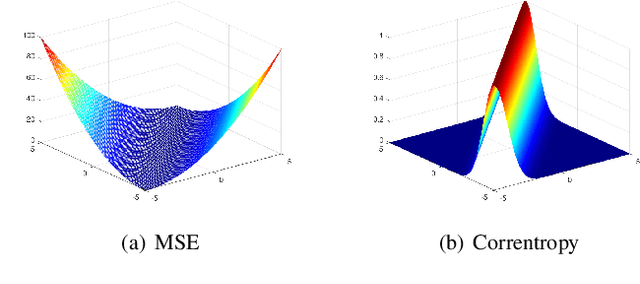
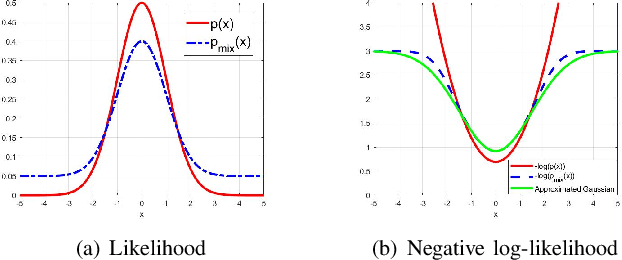
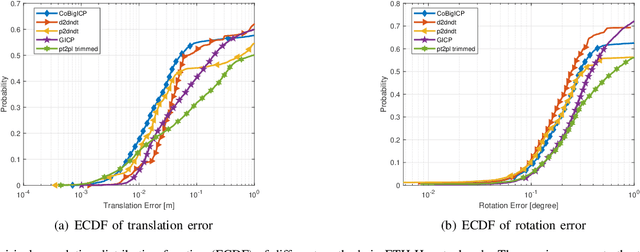
In this paper, we propose a novel probabilistic variant of iterative closest point (ICP) dubbed as CoBigICP. The method leverages both local geometrical information and global noise characteristics. Locally, the 3D structure of both target and source clouds are incorporated into the objective function through bidirectional correspondence. Globally, error metric of correntropy is introduced as noise model to resist outliers. Importantly, the close resemblance between normal-distributions transform (NDT) and correntropy is revealed. To ease the minimization step, an on-manifold parameterization of the special Euclidean group is proposed. Extensive experiments validate that CoBigICP outperforms several well-known and state-of-the-art methods.
Decentralized Multi-agent Filtering
Jan 21, 2023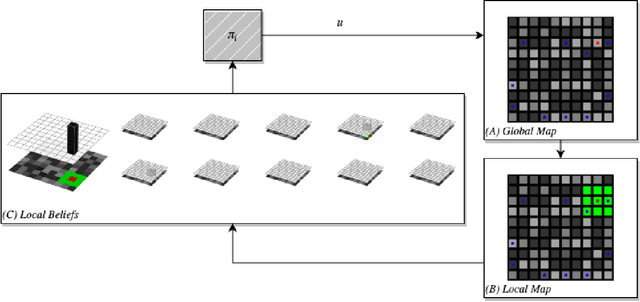
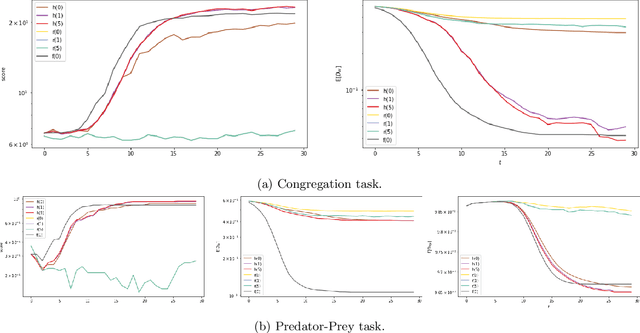
This paper addresses the considerations that comes along with adopting decentralized communication for multi-agent localization applications in discrete state spaces. In this framework, we extend the original formulation of the Bayes filter, a foundational probabilistic tool for discrete state estimation, by appending a step of greedy belief sharing as a method to propagate information and improve local estimates' posteriors. We apply our work in a model-based multi-agent grid-world setting, where each agent maintains a belief distribution for every agents' state. Our results affirm the utility of our proposed extensions for decentralized collaborative tasks. The code base for this work is available in the following repo
SwinCross: Cross-modal Swin Transformer for Head-and-Neck Tumor Segmentation in PET/CT Images
Feb 08, 2023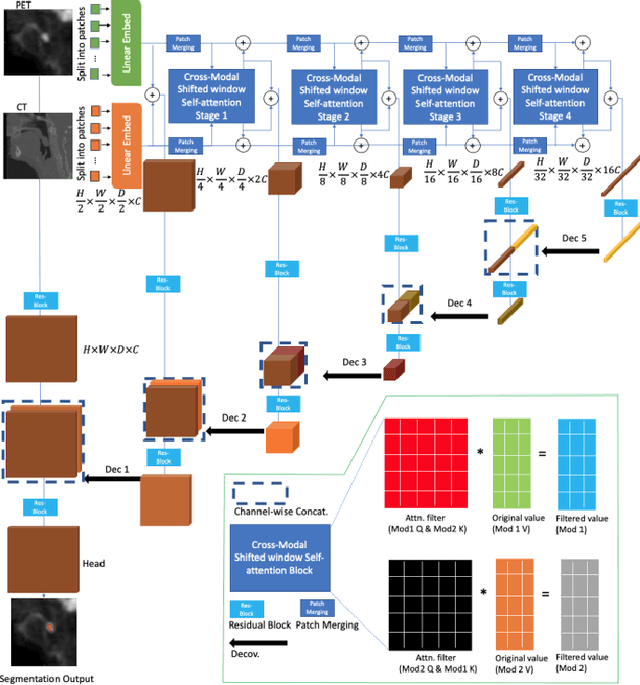
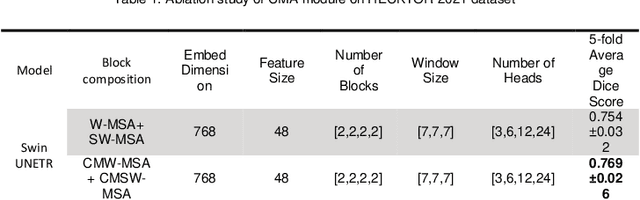
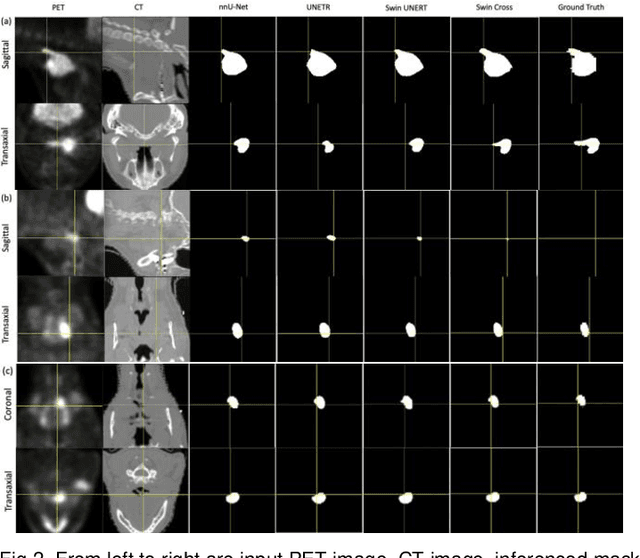
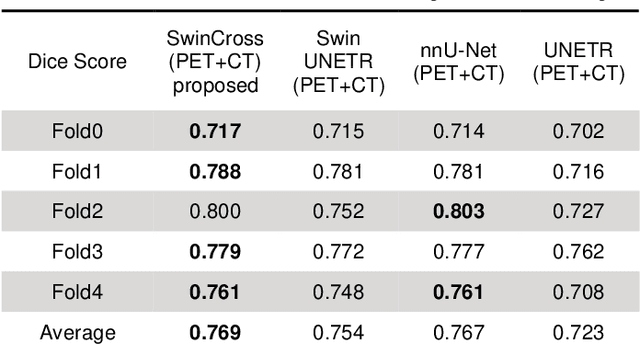
Radiotherapy (RT) combined with cetuximab is the standard treatment for patients with inoperable head and neck cancers. Segmentation of head and neck (H&N) tumors is a prerequisite for radiotherapy planning but a time-consuming process. In recent years, deep convolutional neural networks have become the de facto standard for automated image segmentation. However, due to the expensive computational cost associated with enlarging the field of view in DCNNs, their ability to model long-range dependency is still limited, and this can result in sub-optimal segmentation performance for objects with background context spanning over long distances. On the other hand, Transformer models have demonstrated excellent capabilities in capturing such long-range information in several semantic segmentation tasks performed on medical images. Inspired by the recent success of Vision Transformers and advances in multi-modal image analysis, we propose a novel segmentation model, debuted, Cross-Modal Swin Transformer (SwinCross), with cross-modal attention (CMA) module to incorporate cross-modal feature extraction at multiple resolutions.To validate the effectiveness of the proposed method, we performed experiments on the HECKTOR 2021 challenge dataset and compared it with the nnU-Net (the backbone of the top-5 methods in HECKTOR 2021) and other state-of-the-art transformer-based methods such as UNETR, and Swin UNETR. The proposed method is experimentally shown to outperform these comparing methods thanks to the ability of the CMA module to capture better inter-modality complimentary feature representations between PET and CT, for the task of head-and-neck tumor segmentation.