 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Operator Learning Framework for Digital Twin and Complex Engineering Systems
Jan 18, 2023
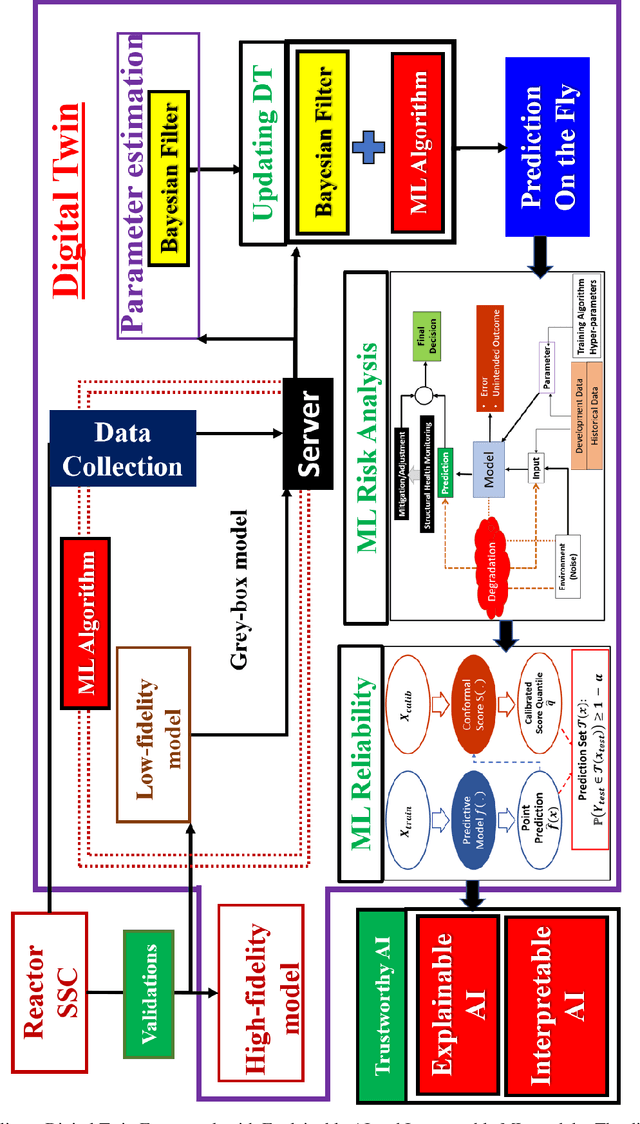
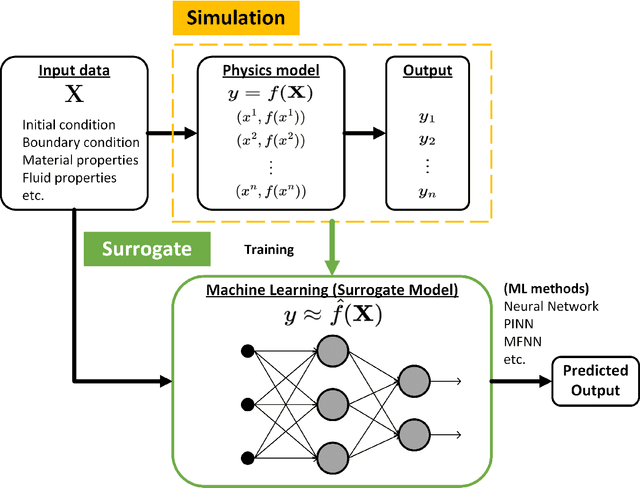
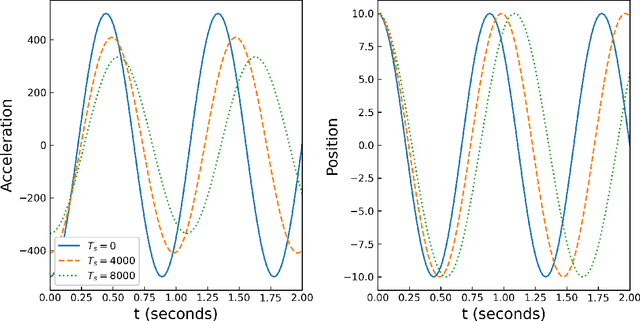
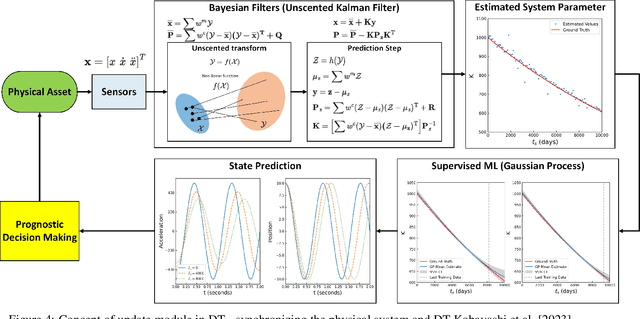
With modern computational advancements and statistical analysis methods, machine learning algorithms have become a vital part of engineering modeling. Neural Operator Networks (ONets) is an emerging machine learning algorithm as a "faster surrogate" for approximating solutions to partial differential equations (PDEs) due to their ability to approximate mathematical operators versus the direct approximation of Neural Networks (NN). ONets use the Universal Approximation Theorem to map finite-dimensional inputs to infinite-dimensional space using the branch-trunk architecture, which encodes domain and feature information separately before using a dot product to combine the information. ONets are expected to occupy a vital niche for surrogate modeling in physical systems and Digital Twin (DT) development. Three test cases are evaluated using ONets for operator approximation, including a 1-dimensional ordinary differential equations (ODE), general diffusion system, and convection-diffusion (Burger) system. Solutions for ODE and diffusion systems yield accurate and reliable results (R2>0.95), while solutions for Burger systems need further refinement in the ONet algorithm.
Training Full Spike Neural Networks via Auxiliary Accumulation Pathway
Jan 27, 2023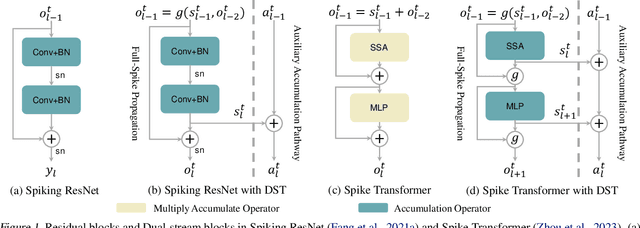

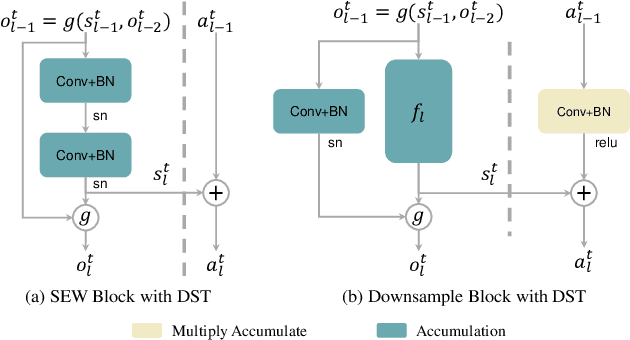
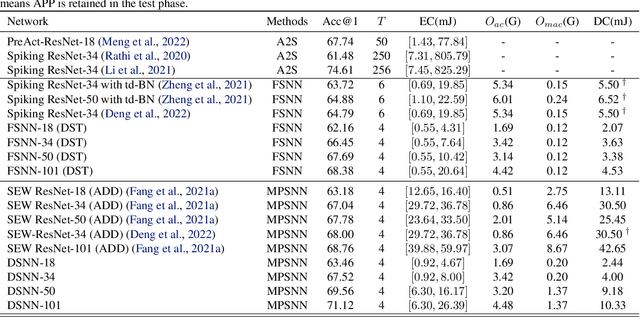
Due to the binary spike signals making converting the traditional high-power multiply-accumulation (MAC) into a low-power accumulation (AC) available, the brain-inspired Spiking Neural Networks (SNNs) are gaining more and more attention. However, the binary spike propagation of the Full-Spike Neural Networks (FSNN) with limited time steps is prone to significant information loss. To improve performance, several state-of-the-art SNN models trained from scratch inevitably bring many non-spike operations. The non-spike operations cause additional computational consumption and may not be deployed on some neuromorphic hardware where only spike operation is allowed. To train a large-scale FSNN with high performance, this paper proposes a novel Dual-Stream Training (DST) method which adds a detachable Auxiliary Accumulation Pathway (AAP) to the full spiking residual networks. The accumulation in AAP could compensate for the information loss during the forward and backward of full spike propagation, and facilitate the training of the FSNN. In the test phase, the AAP could be removed and only the FSNN remained. This not only keeps the lower energy consumption but also makes our model easy to deploy. Moreover, for some cases where the non-spike operations are available, the APP could also be retained in test inference and improve feature discrimination by introducing a little non-spike consumption. Extensive experiments on ImageNet, DVS Gesture, and CIFAR10-DVS datasets demonstrate the effectiveness of DST.
On Leave-One-Out Conditional Mutual Information For Generalization
Jul 01, 2022

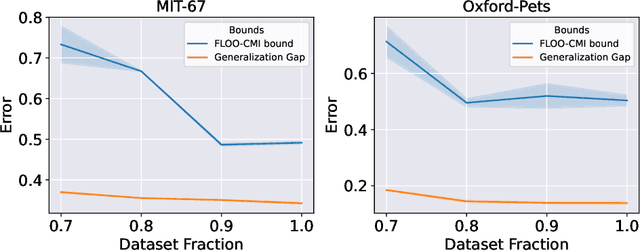
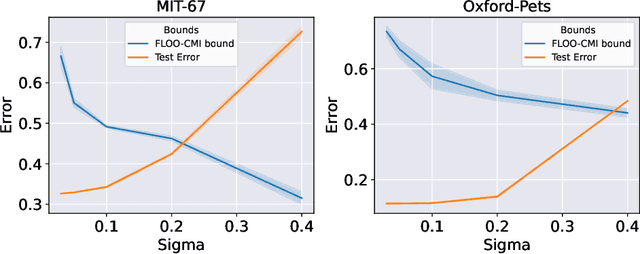
We derive information theoretic generalization bounds for supervised learning algorithms based on a new measure of leave-one-out conditional mutual information (loo-CMI). Contrary to other CMI bounds, which are black-box bounds that do not exploit the structure of the problem and may be hard to evaluate in practice, our loo-CMI bounds can be computed easily and can be interpreted in connection to other notions such as classical leave-one-out cross-validation, stability of the optimization algorithm, and the geometry of the loss-landscape. It applies both to the output of training algorithms as well as their predictions. We empirically validate the quality of the bound by evaluating its predicted generalization gap in scenarios for deep learning. In particular, our bounds are non-vacuous on large-scale image-classification tasks.
Learning in POMDPs is Sample-Efficient with Hindsight Observability
Feb 03, 2023
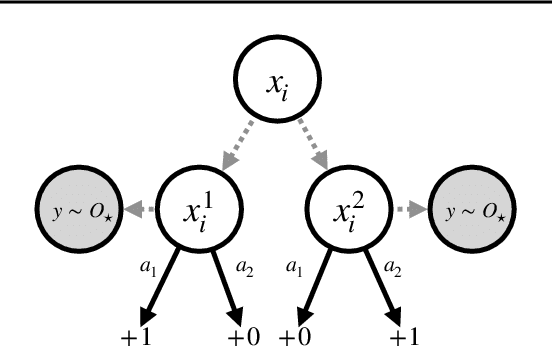
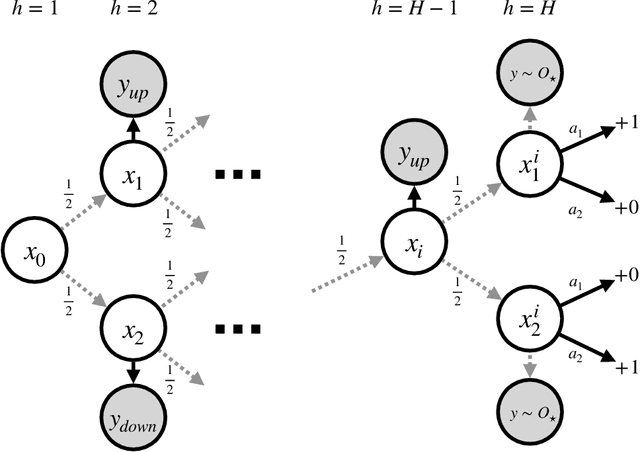
POMDPs capture a broad class of decision making problems, but hardness results suggest that learning is intractable even in simple settings due to the inherent partial observability. However, in many realistic problems, more information is either revealed or can be computed during some point of the learning process. Motivated by diverse applications ranging from robotics to data center scheduling, we formulate a Hindsight Observable Markov Decision Process (HOMDP) as a POMDP where the latent states are revealed to the learner in hindsight and only during training. We introduce new algorithms for the tabular and function approximation settings that are provably sample-efficient with hindsight observability, even in POMDPs that would otherwise be statistically intractable. We give a lower bound showing that the tabular algorithm is optimal in its dependence on latent state and observation cardinalities.
Teleoperated Robot Grasping in Virtual Reality Spaces
Jan 30, 2023

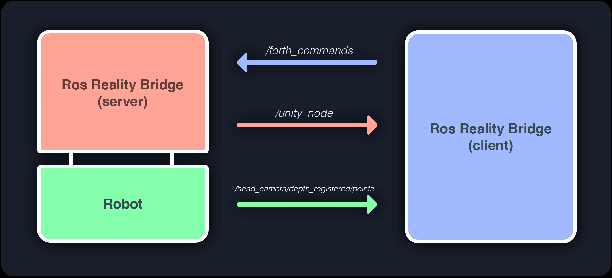
Despite recent advancement in virtual reality technology, teleoperating a high DoF robot to complete dexterous tasks in cluttered scenes remains difficult. In this work, we propose a system that allows the user to teleoperate a Fetch robot to perform grasping in an easy and intuitive way, through exploiting the rich environment information provided by the virtual reality space. Our system has the benefit of easy transferability to different robots and different tasks, and can be used without any expert knowledge. We tested the system on a real fetch robot, and a video demonstrating the effectiveness of our system can be seen at https://youtu.be/1-xW2Bx_Cms.
Multilayer hypergraph clustering using the aggregate similarity matrix
Jan 27, 2023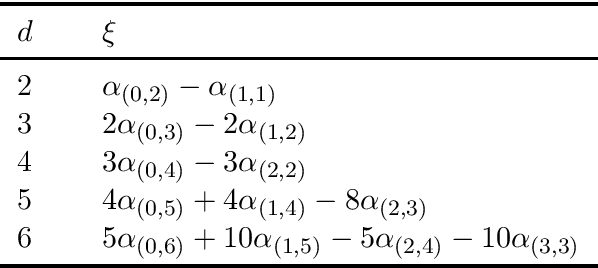
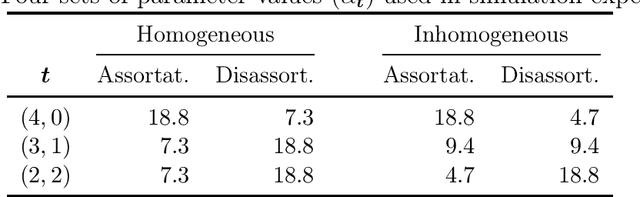
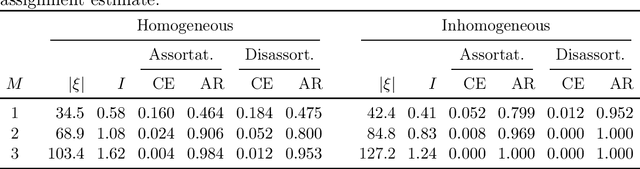
We consider the community recovery problem on a multilayer variant of the hypergraph stochastic block model (HSBM). Each layer is associated with an independent realization of a d-uniform HSBM on N vertices. Given the aggregated number of hyperedges incident to each pair of vertices, represented using a similarity matrix, the goal is to obtain a partition of the N vertices into disjoint communities. In this work, we investigate a semidefinite programming (SDP) approach and obtain information-theoretic conditions on the model parameters that guarantee exact recovery both in the assortative and the disassortative cases.
A Novel Framework for Handling Sparse Data in Traffic Forecast
Jan 12, 2023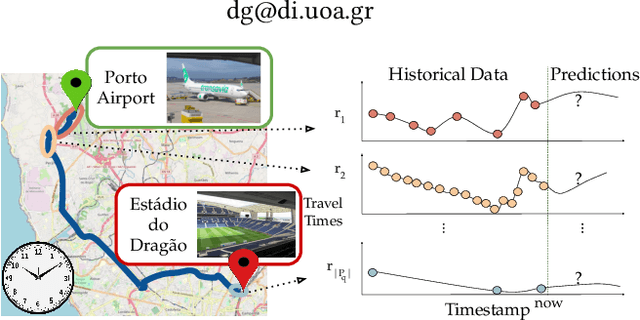
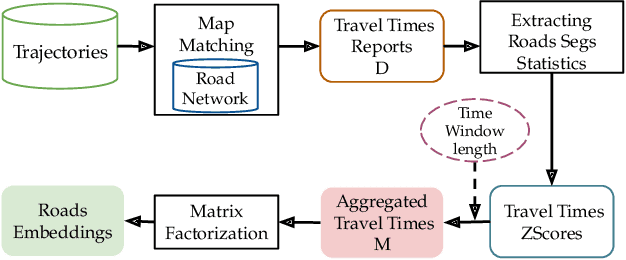
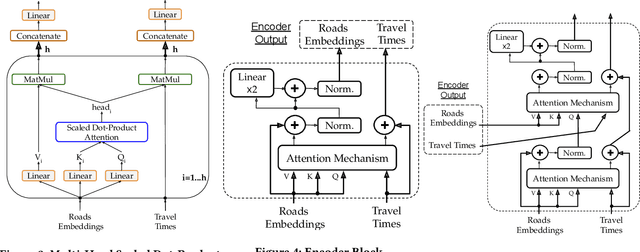
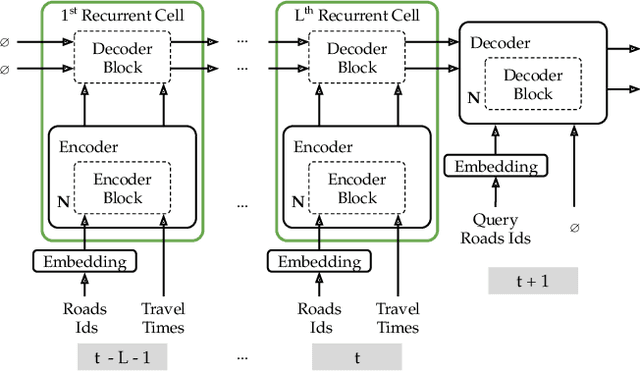
The ever increasing amount of GPS-equipped vehicles provides in real-time valuable traffic information for the roads traversed by the moving vehicles. In this way, a set of sparse and time evolving traffic reports is generated for each road. These time series are a valuable asset in order to forecast the future traffic condition. In this paper we present a deep learning framework that encodes the sparse recent traffic information and forecasts the future traffic condition. Our framework consists of a recurrent part and a decoder. The recurrent part employs an attention mechanism that encodes the traffic reports that are available at a particular time window. The decoder is responsible to forecast the future traffic condition.
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training
Feb 12, 2023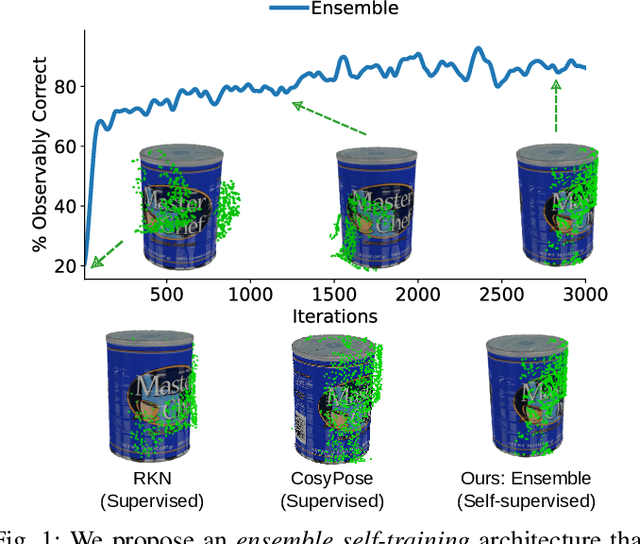
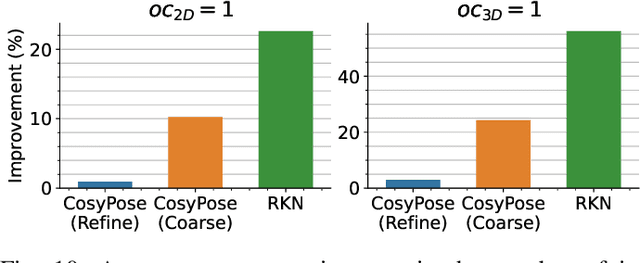
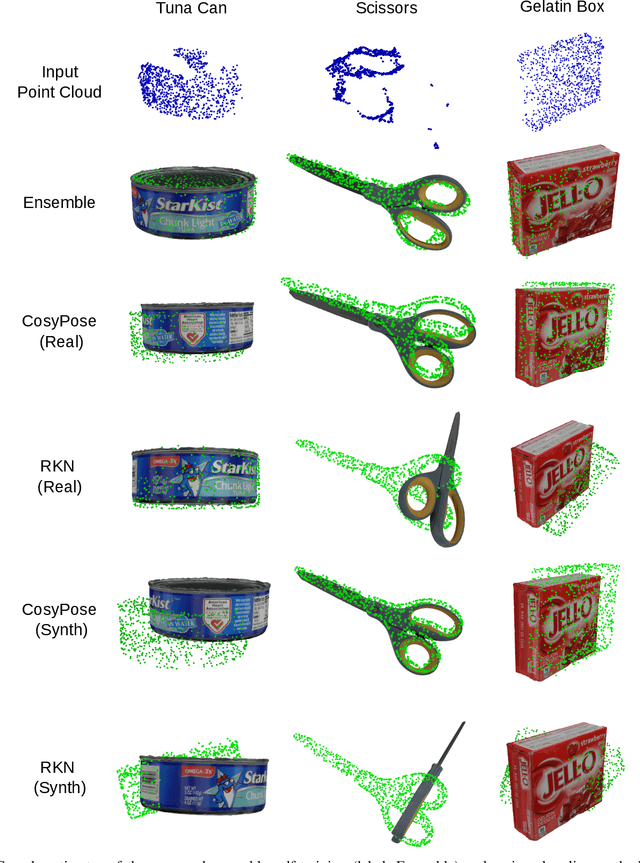

Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self-supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training outperforms fully supervised baselines while not requiring 3D annotations on real data.
Enhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation
Jan 31, 2023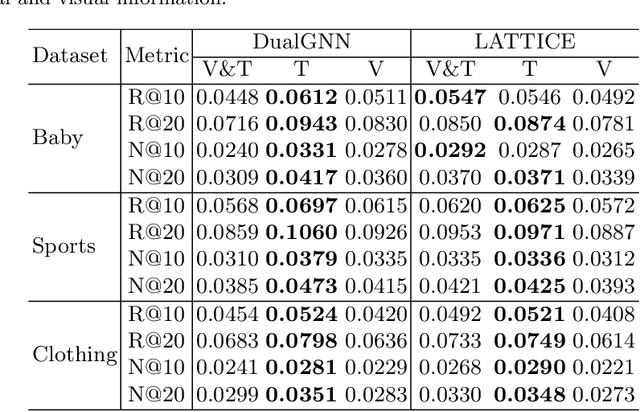
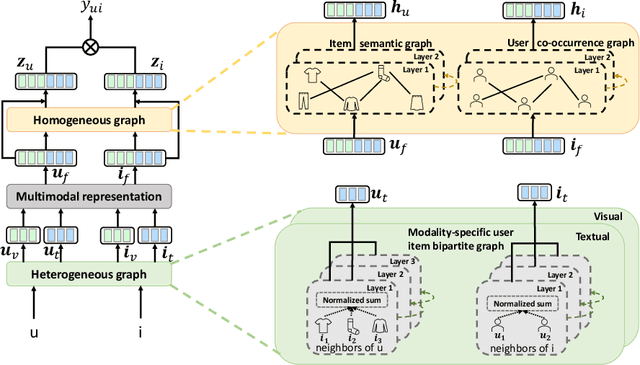
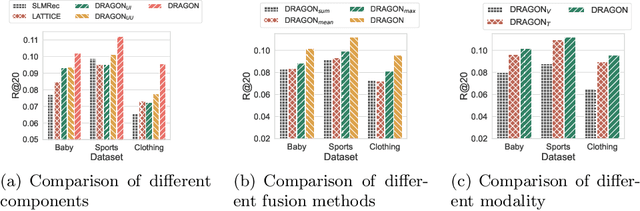
User interaction data in recommender systems is a form of dyadic relation that reflects the preferences of users with items. Learning the representations of these two discrete sets of objects, users and items, is critical for recommendation. Recent multimodal recommendation models leveraging multimodal features (e.g., images and text descriptions) have been demonstrated to be effective in improving recommendation accuracy. However, state-of-the-art models enhance the dyadic relations between users and items by considering either user-user or item-item relations, leaving the high-order relations of the other side (i.e., users or items) unexplored. Furthermore, we experimentally reveal that the current multimodality fusion methods in the state-of-the-art models may degrade their recommendation performance. That is, without tainting the model architectures, these models can achieve even better recommendation accuracy with uni-modal information. On top of the finding, we propose a model that enhances the dyadic relations by learning Dual RepresentAtions of both users and items via constructing homogeneous Graphs for multimOdal recommeNdation. We name our model as DRAGON. Specifically, DRAGON constructs the user-user graph based on the commonly interacted items and the item-item graph from item multimodal features. It then utilizes graph learning on both the user-item heterogeneous graph and the homogeneous graphs (user-user and item-item) to obtain the dual representations of users and items. To capture information from each modality, DRAGON employs a simple yet effective fusion method, attentive concatenation, to derive the representations of users and items. Extensive experiments on three public datasets and seven baselines show that DRAGON can outperform the strongest baseline by 22.03% on average. Various ablation studies are conducted on DRAGON to validate its effectiveness.
Dynamic Local Feature Aggregation for Learning on Point Clouds
Jan 07, 2023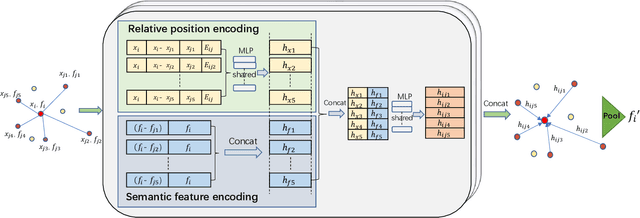
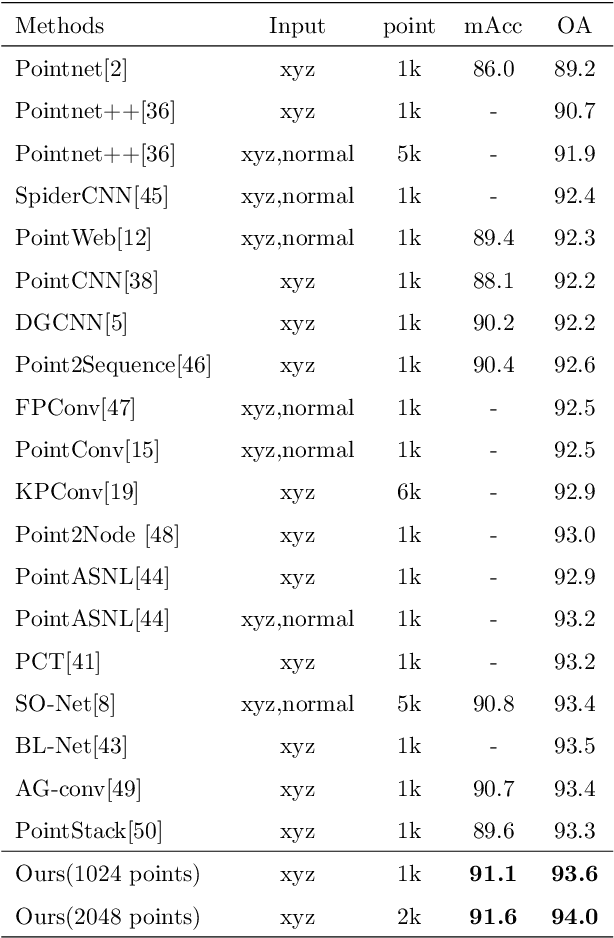
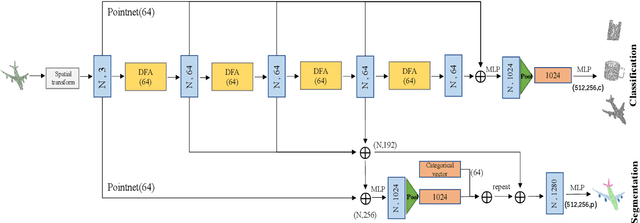

Existing point cloud learning methods aggregate features from neighbouring points relying on constructing graph in the spatial domain, which results in feature update for each point based on spatially-fixed neighbours throughout layers. In this paper, we propose a dynamic feature aggregation (DFA) method that can transfer information by constructing local graphs in the feature domain without spatial constraints. By finding k-nearest neighbors in the feature domain, we perform relative position encoding and semantic feature encoding to explore latent position and feature similarity information, respectively, so that rich local features can be learned. At the same time, we also learn low-dimensional global features from the original point cloud for enhancing feature representation. Between DFA layers, we dynamically update the constructed local graph structure, so that we can learn richer information, which greatly improves adaptability and efficiency. We demonstrate the superiority of our method by conducting extensive experiments on point cloud classification and segmentation tasks. Implementation code is available: https://github.com/jiamang/DFA.