 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-grained Affordance Annotation for Egocentric Hand-Object Interaction Videos
Feb 07, 2023
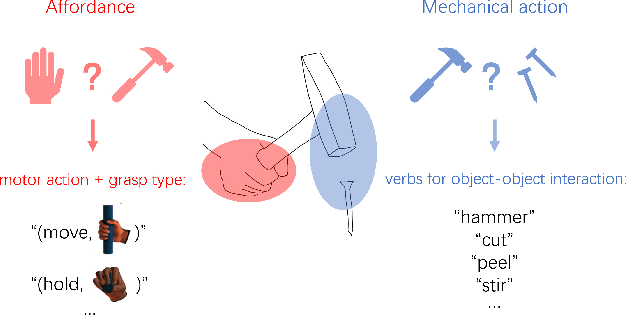


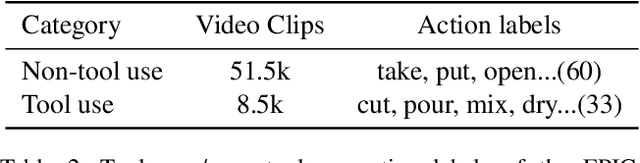
Object affordance is an important concept in hand-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, the definition of affordance in existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition, hand-object interaction hotspots prediction, and cross-domain evaluation of affordance. The results show that models trained with our annotation can distinguish affordance from other concepts, predict fine-grained interaction possibilities on objects, and generalize through different domains.
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023
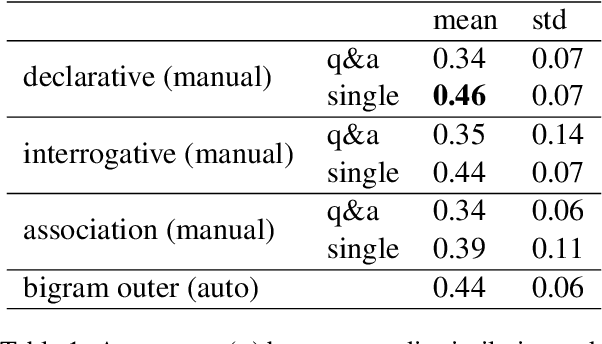

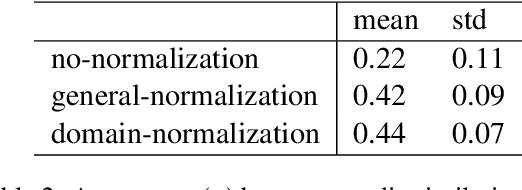
Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
Sparse GEMINI for Joint Discriminative Clustering and Feature Selection
Feb 07, 2023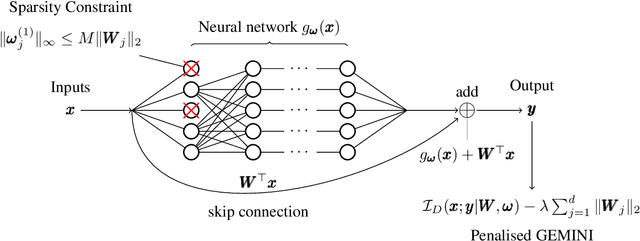
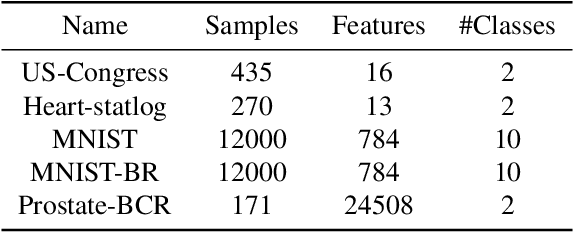
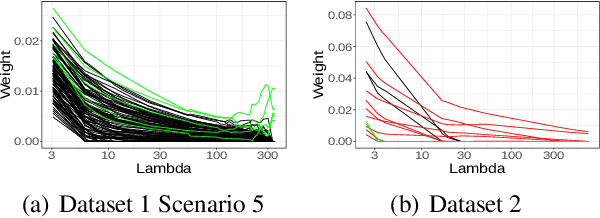
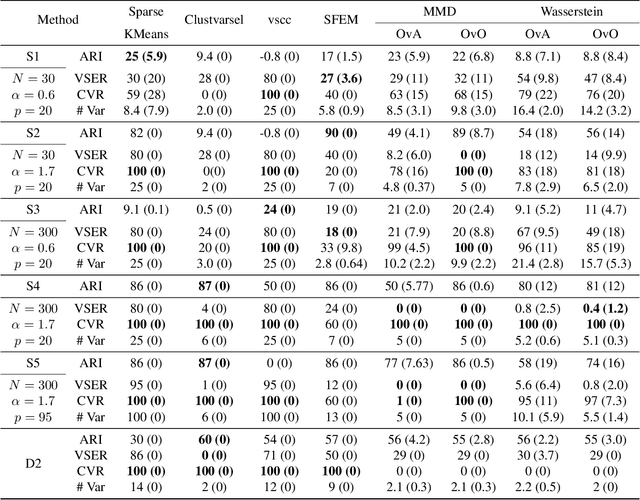
Feature selection in clustering is a hard task which involves simultaneously the discovery of relevant clusters as well as relevant variables with respect to these clusters. While feature selection algorithms are often model-based through optimised model selection or strong assumptions on $p(\pmb{x})$, we introduce a discriminative clustering model trying to maximise a geometry-aware generalisation of the mutual information called GEMINI with a simple $\ell_1$ penalty: the Sparse GEMINI. This algorithm avoids the burden of combinatorial feature subset exploration and is easily scalable to high-dimensional data and large amounts of samples while only designing a clustering model $p_\theta(y|\pmb{x})$. We demonstrate the performances of Sparse GEMINI on synthetic datasets as well as large-scale datasets. Our results show that Sparse GEMINI is a competitive algorithm and has the ability to select relevant subsets of variables with respect to the clustering without using relevance criteria or prior hypotheses.
Few-Shot Table-to-Text Generation with Prompt Planning and Knowledge Memorization
Feb 09, 2023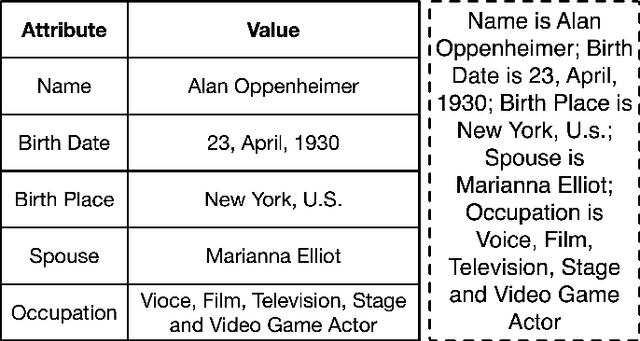
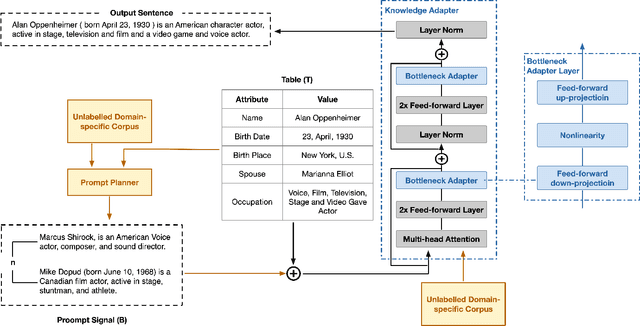
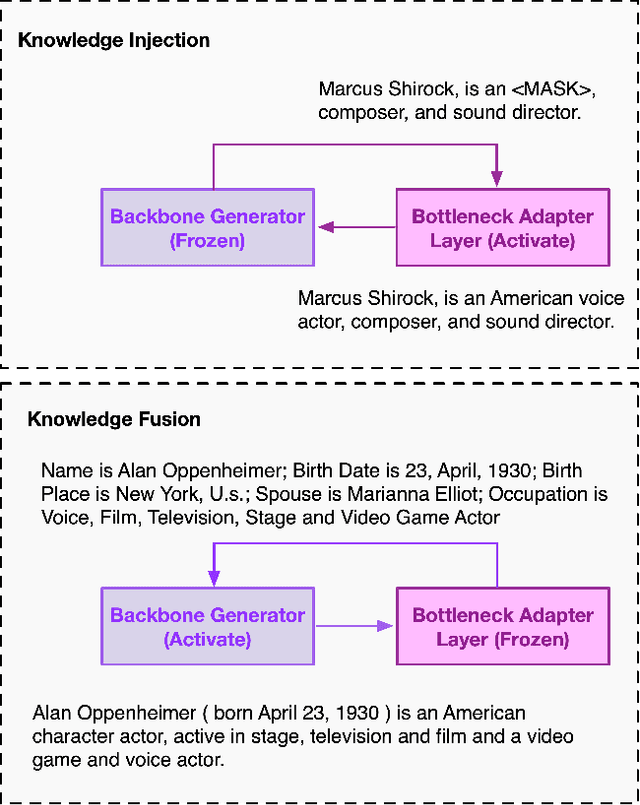

Pre-trained language models (PLM) have achieved remarkable advancement in table-to-text generation tasks. However, the lack of labeled domain-specific knowledge and the topology gap between tabular data and text make it difficult for PLMs to yield faithful text. Low-resource generation likewise faces unique challenges in this domain. Inspired by how humans descript tabular data with prior knowledge, we suggest a new framework: PromptMize, which targets table-to-text generation under few-shot settings. The design of our framework consists of two aspects: a prompt planner and a knowledge adapter. The prompt planner aims to generate a prompt signal that provides instance guidance for PLMs to bridge the topology gap between tabular data and text. Moreover, the knowledge adapter memorizes domain-specific knowledge from the unlabelled corpus to supply essential information during generation. Extensive experiments and analyses are investigated on three open domain few-shot NLG datasets: human, song, and book. Compared with previous state-of-the-art approaches, our model achieves remarkable performance in generating quality as judged by human and automatic evaluations.
Differentially Private Deep Q-Learning for Pattern Privacy Preservation in MEC Offloading
Feb 09, 2023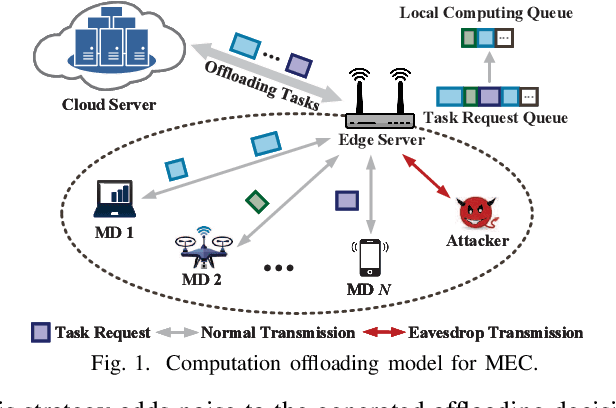
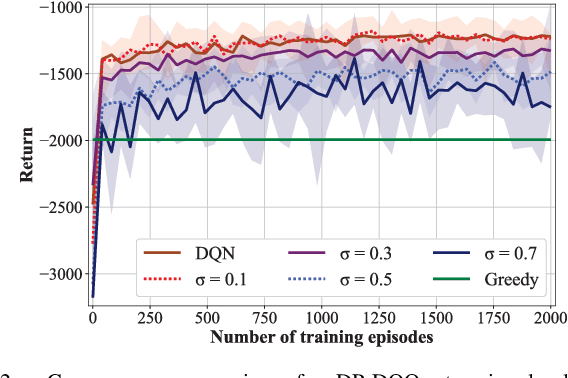
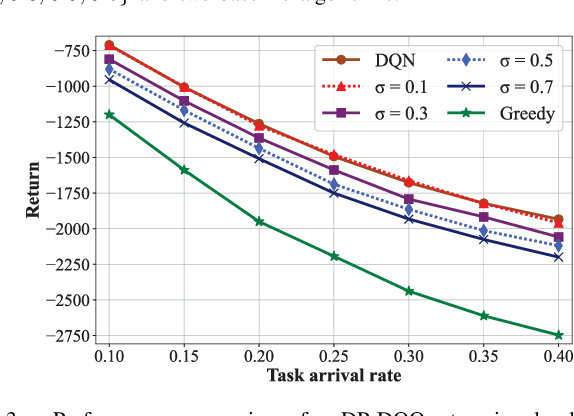
Mobile edge computing (MEC) is a promising paradigm to meet the quality of service (QoS) requirements of latency-sensitive IoT applications. However, attackers may eavesdrop on the offloading decisions to infer the edge server's (ES's) queue information and users' usage patterns, thereby incurring the pattern privacy (PP) issue. Therefore, we propose an offloading strategy which jointly minimizes the latency, ES's energy consumption, and task dropping rate, while preserving PP. Firstly, we formulate the dynamic computation offloading procedure as a Markov decision process (MDP). Next, we develop a Differential Privacy Deep Q-learning based Offloading (DP-DQO) algorithm to solve this problem while addressing the PP issue by injecting noise into the generated offloading decisions. This is achieved by modifying the deep Q-network (DQN) with a Function-output Gaussian process mechanism. We provide a theoretical privacy guarantee and a utility guarantee (learning error bound) for the DP-DQO algorithm and finally, conduct simulations to evaluate the performance of our proposed algorithm by comparing it with greedy and DQN-based algorithms.
FDD Massive MIMO Without CSI Feedback
Feb 09, 2023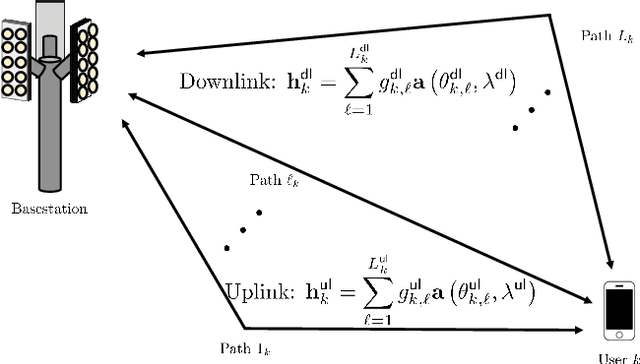
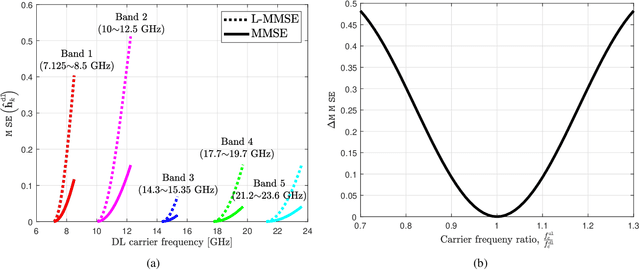
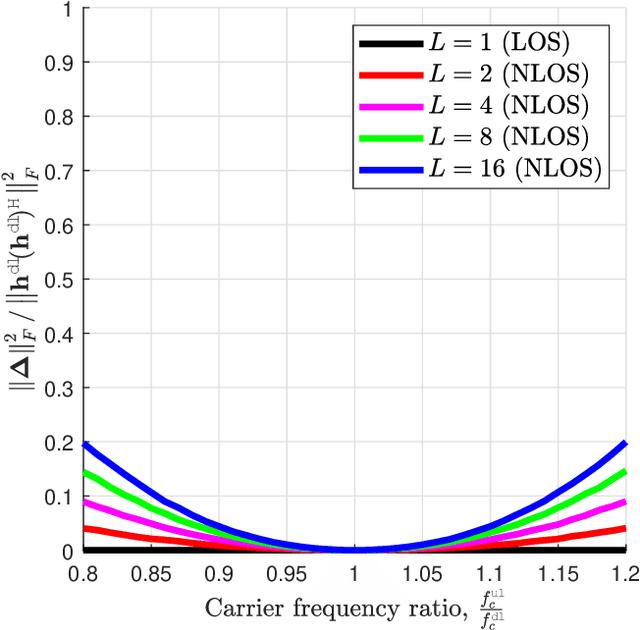
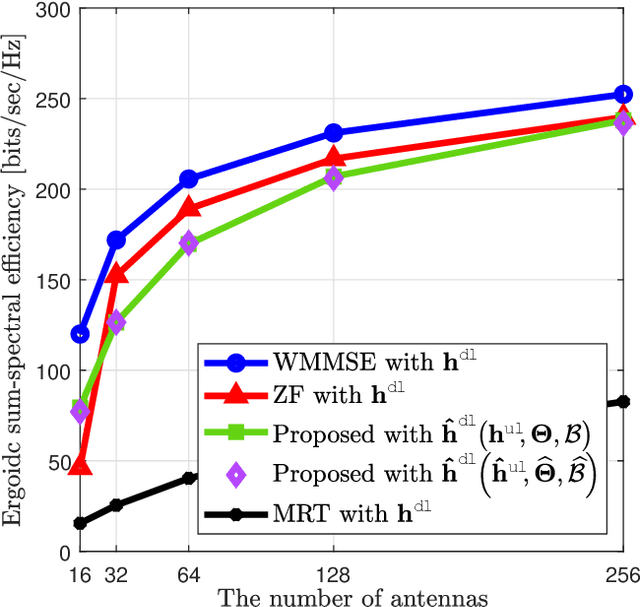
Transmitter channel state information (CSIT) is indispensable for the spectral efficiency gains offered by massive multiple-input multiple-output (MIMO) systems. In a frequency-division-duplexing (FDD) massive MIMO system, CSIT is typically acquired through downlink channel estimation and user feedback, but as the number of antennas increases, the overhead for CSI training and feedback per user grows, leading to a decrease in spectral efficiency. In this paper, we show that, using uplink pilots in FDD, the downlink sum spectral efficiency gain with perfect downlink CSIT is achievable when the number of antennas at a base station is infinite under some mild channel conditions. The key idea showing our result is the mean squared error-optimal downlink channel reconstruction method using uplink pilots, which exploits the geometry reciprocity of uplink and downlink channels. We also present a robust downlink precoding method harnessing the reconstructed channel with the error covariance matrix. Our system-level simulations show that our proposed precoding method can attain comparable sum spectral efficiency to zero-forcing precoding with perfect downlink CSIT, without CSI training and feedback.
Improving Generalization of Adapter-Based Cross-lingual Transfer with Scheduled Unfreezing
Jan 13, 2023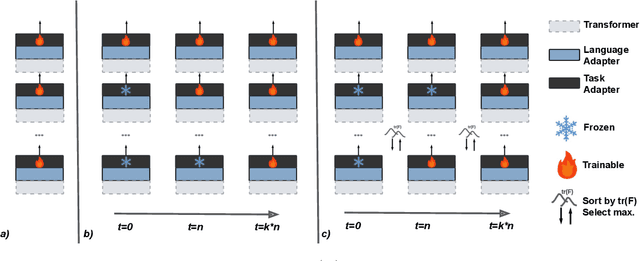
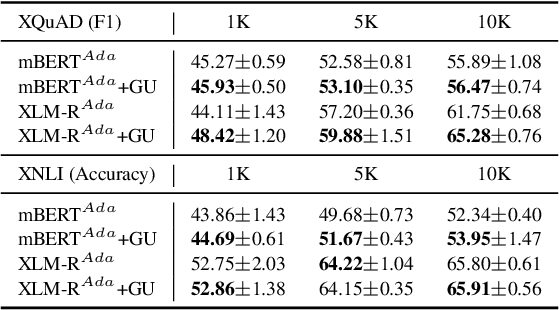
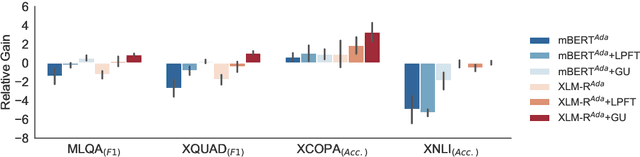
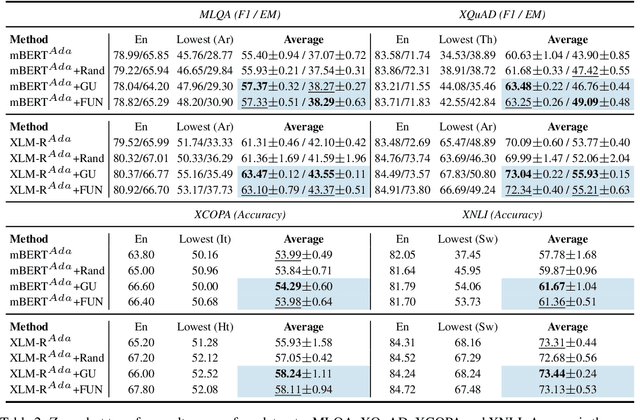
Standard fine-tuning of language models typically performs well on in-distribution data, but suffers with generalization to distribution shifts. In this work, we aim to improve generalization of adapter-based cross-lingual task transfer where such cross-language distribution shifts are imminent. We investigate scheduled unfreezing algorithms -- originally proposed to mitigate catastrophic forgetting in transfer learning -- for fine-tuning task adapters in cross-lingual transfer. Our experiments show that scheduled unfreezing methods close the gap to full fine-tuning and achieve state-of-the-art transfer performance, suggesting that these methods can go beyond just mitigating catastrophic forgetting. Next, aiming to delve deeper into those empirical findings, we investigate the learning dynamics of scheduled unfreezing using Fisher Information. Our in-depth experiments reveal that scheduled unfreezing induces different learning dynamics compared to standard fine-tuning, and provide evidence that the dynamics of Fisher Information during training correlate with cross-lingual generalization performance. We additionally propose a general scheduled unfreezing algorithm that achieves an average of 2 points improvement over four datasets compared to standard fine-tuning and provides strong empirical evidence for a theory-based justification of the heuristic unfreezing schedule (i.e., the heuristic schedule is implicitly maximizing Fisher Information). Our code will be publicly available.
Does Search Engine Optimization come along with high-quality content? A comparison between optimized and non-optimized health-related web pages
Jan 24, 2023

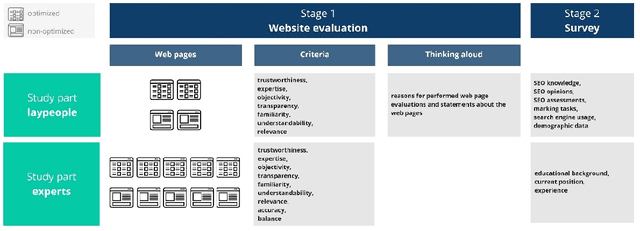
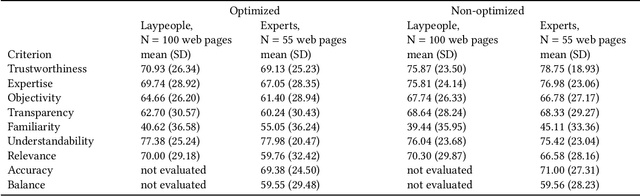
Searching for medical information is both a common and important activity since it influences decisions people make about their healthcare. Using search engine optimization (SEO), content producers seek to increase the visibility of their content. SEO is more likely to be practiced by commercially motivated content producers such as pharmaceutical companies than by non-commercial providers such as governmental bodies. In this study, we ask whether content quality correlates with the presence or absence of SEO measures on a web page. We conducted a user study in which N = 61 participants comprising laypeople as well as experts in health information assessment evaluated health-related web pages classified as either optimized or non-optimized. The subjects rated the expertise of non-optimized web pages as higher than the expertise of optimized pages, justifying their appraisal by the more competent and reputable appearance of non-optimized pages. In addition, comments about the website operators of the non-optimized pages were exclusively positive, while optimized pages tended to receive positive as well as negative assessments. We found no differences between the ratings of laypeople and experts. Since non-optimized, but high-quality content may be outranked by optimized content of lower quality, trusted sources should be prioritized in rankings.
InfoAT: Improving Adversarial Training Using the Information Bottleneck Principle
Jun 23, 2022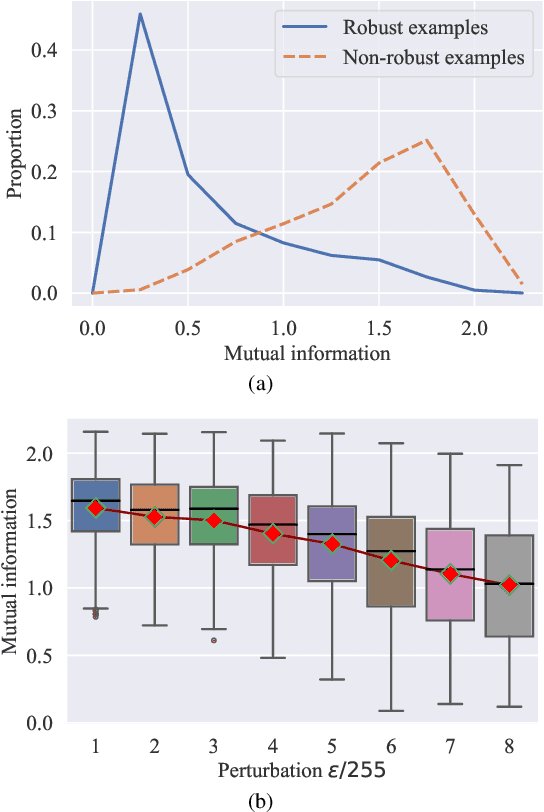
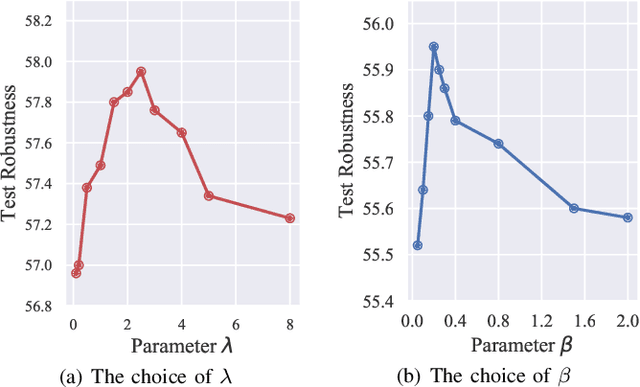
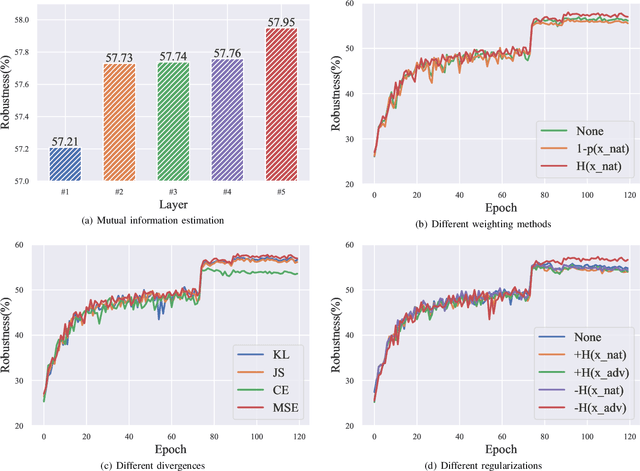
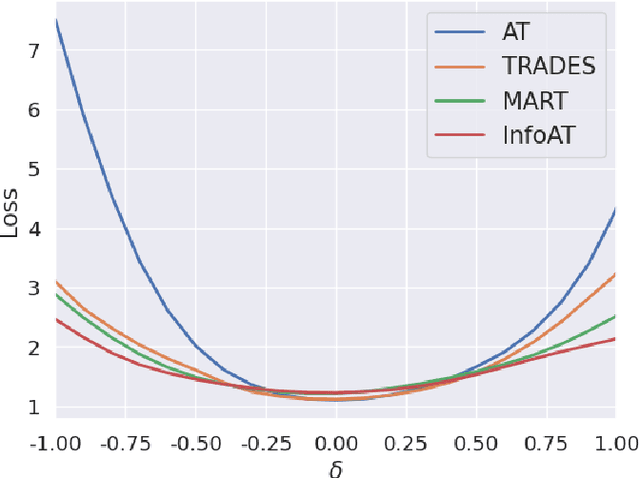
Adversarial training (AT) has shown excellent high performance in defending against adversarial examples. Recent studies demonstrate that examples are not equally important to the final robustness of models during AT, that is, the so-called hard examples that can be attacked easily exhibit more influence than robust examples on the final robustness. Therefore, guaranteeing the robustness of hard examples is crucial for improving the final robustness of the model. However, defining effective heuristics to search for hard examples is still difficult. In this article, inspired by the information bottleneck (IB) principle, we uncover that an example with high mutual information of the input and its associated latent representation is more likely to be attacked. Based on this observation, we propose a novel and effective adversarial training method (InfoAT). InfoAT is encouraged to find examples with high mutual information and exploit them efficiently to improve the final robustness of models. Experimental results show that InfoAT achieves the best robustness among different datasets and models in comparison with several state-of-the-art methods.
Deep Learning for Event-based Vision: A Comprehensive Survey and Benchmarks
Feb 17, 2023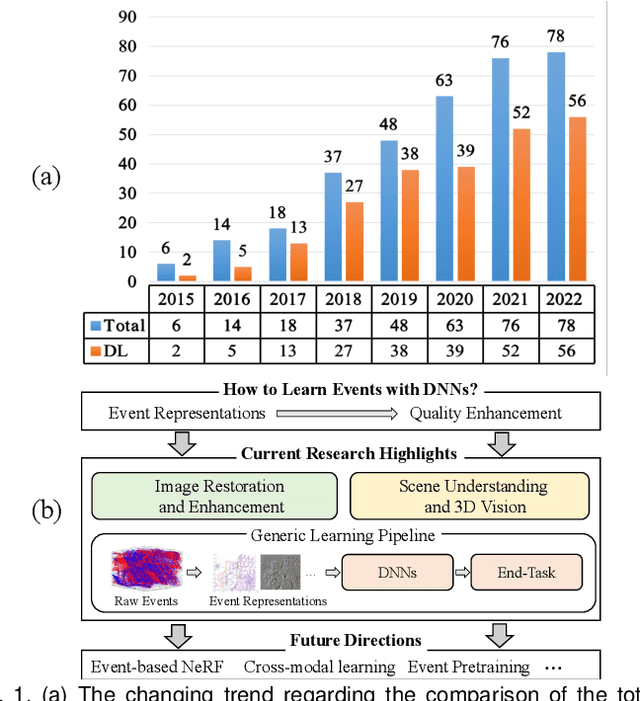
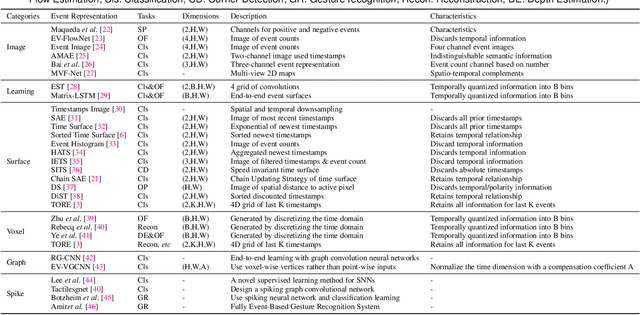

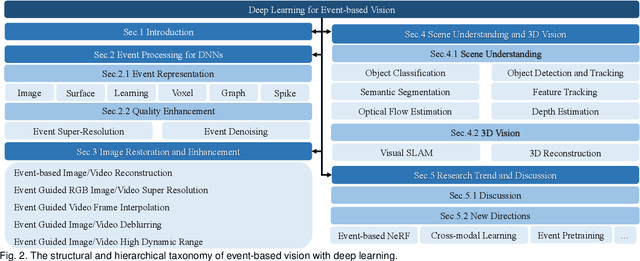
Event cameras are bio-inspired sensors that capture the per-pixel intensity changes asynchronously and produce event streams encoding the time, pixel position, and polarity (sign) of the intensity changes. Event cameras possess a myriad of advantages over canonical frame-based cameras, such as high temporal resolution, high dynamic range, low latency, etc. Being capable of capturing information in challenging visual conditions, event cameras have the potential to overcome the limitations of frame-based cameras in the computer vision and robotics community. In very recent years, deep learning (DL) has been brought to this emerging field and inspired active research endeavors in mining its potential. However, the technical advances still remain unknown, thus making it urgent and necessary to conduct a systematic overview. To this end, we conduct the first yet comprehensive and in-depth survey, with a focus on the latest developments of DL techniques for event-based vision. We first scrutinize the typical event representations with quality enhancement methods as they play a pivotal role as inputs to the DL models. We then provide a comprehensive taxonomy for existing DL-based methods by structurally grouping them into two major categories: 1) image reconstruction and restoration; 2) event-based scene understanding 3D vision. Importantly, we conduct benchmark experiments for the existing methods in some representative research directions (eg, object recognition and optical flow estimation) to identify some critical insights and problems. Finally, we make important discussions regarding the challenges and provide new perspectives for motivating future research studies.