 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An AI-Driven Approach to Wind Turbine Bearing Fault Diagnosis from Acoustic Signals
Mar 14, 2024

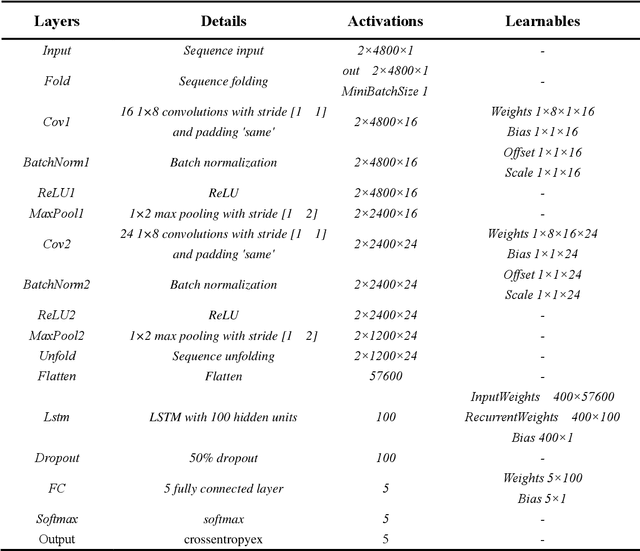
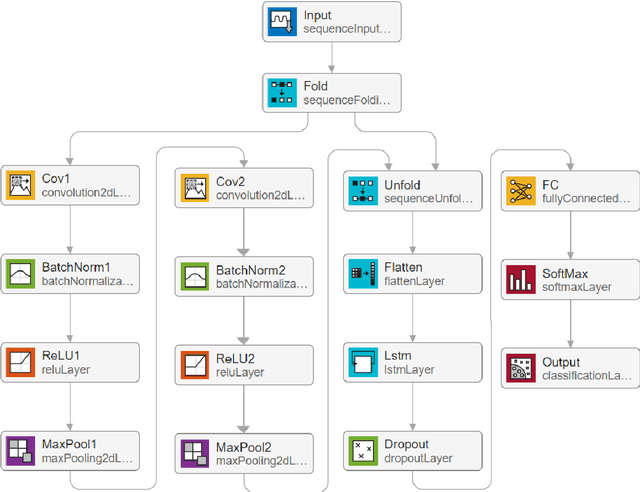
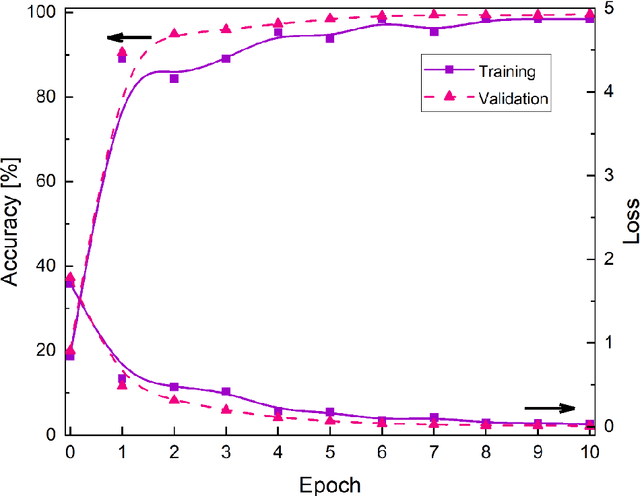
This study aimed to develop a deep learning model for the classification of bearing faults in wind turbine generators from acoustic signals. A convolutional LSTM model was successfully constructed and trained by using audio data from five predefined fault types for both training and validation. To create the dataset, raw audio signal data was collected and processed in frames to capture time and frequency domain information. The model exhibited outstanding accuracy on training samples and demonstrated excellent generalization ability during validation, indicating its proficiency of generalization capability. On the test samples, the model achieved remarkable classification performance, with an overall accuracy exceeding 99.5%, and a false positive rate of less than 1% for normal status. The findings of this study provide essential support for the diagnosis and maintenance of bearing faults in wind turbine generators, with the potential to enhance the reliability and efficiency of wind power generation.
The negation of permutation mass function
Mar 13, 2024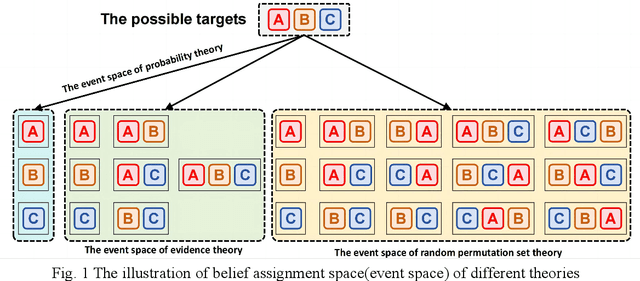
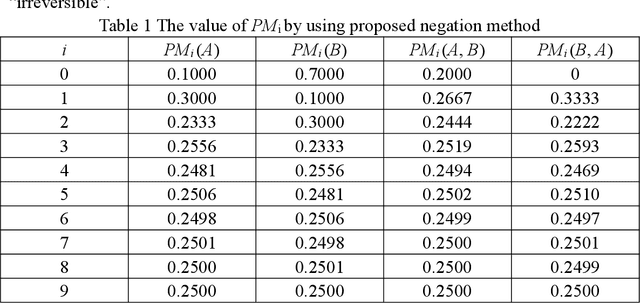
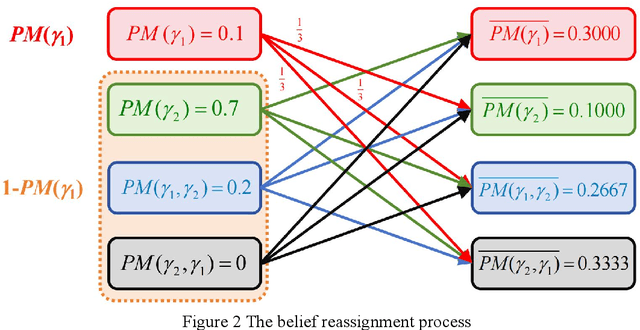
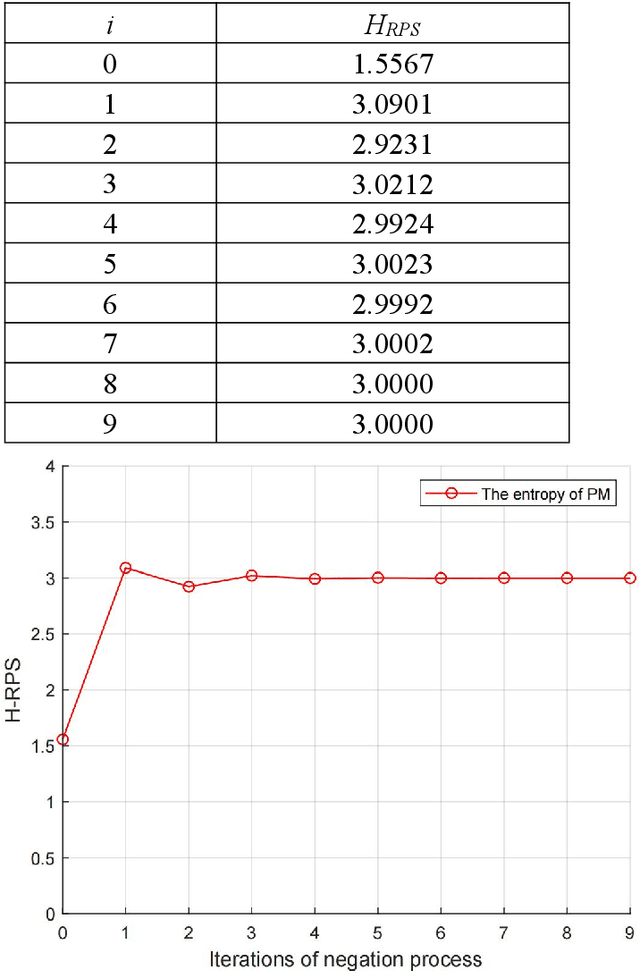
Negation is an important perspective of knowledge representation. Existing negation methods are mainly applied in probability theory, evidence theory and complex evidence theory. As a generalization of evidence theory, random permutation sets theory may represent information more precisely. However, how to apply the concept of negation to random permutation sets theory has not been studied. In this paper, the negation of permutation mass function is proposed. Moreover, in the negation process, the convergence of proposed negation method is verified. The trends of uncertainty and dissimilarity after each negation operation are investigated. Numerical examples are used to demonstrate the rationality of the proposed method.
Plasmon Resonance Model: Investigation of Analysis of Fake News Diffusion Model with Third Mover Intervention Using Soliton Solution in Non-Complete Information Game under Repeated Dilemma Condition
Mar 03, 2024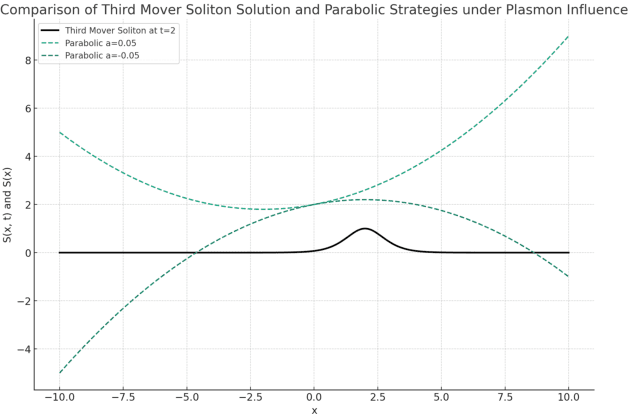
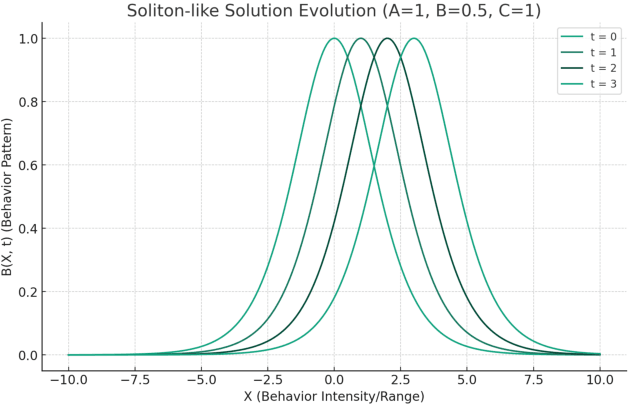
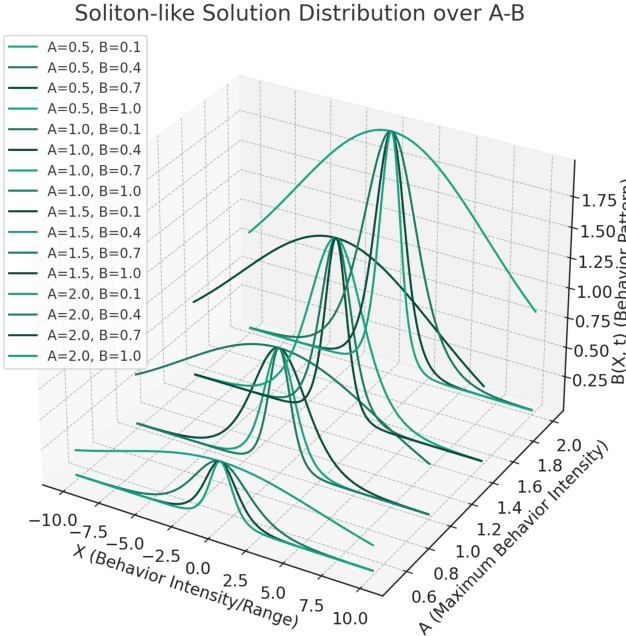
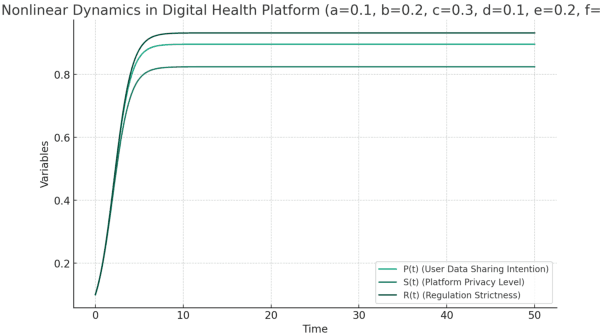
In this research note, we propose a new approach to model the fake news diffusion process within the framework of incomplete information games. In particular, we use nonlinear partial differential equations to represent the phenomenon of plasmon resonance, in which the diffusion of fake news is rapidly amplified within a particular social group or communication network, and analyze its dynamics through a soliton solution approach. In addition, we consider how first mover, second mover, and third mover strategies interact within this nonlinear system and contribute to the amplification or suppression of fake news diffusion. The model aims to understand the mechanisms of fake news proliferation and provide insights into how to prevent or combat it. By combining concepts from the social sciences and the physical sciences, this study attempts to develop a new theoretical framework for the contemporary problem of fake news.
ViTCN: Vision Transformer Contrastive Network For Reasoning
Mar 15, 2024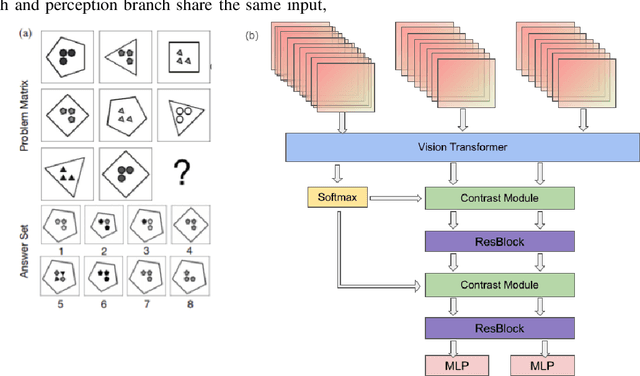

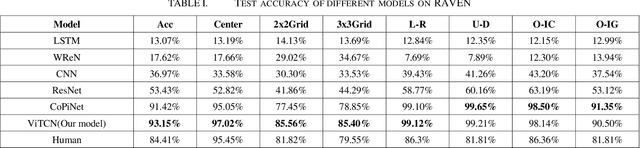
Machine learning models have achieved significant milestones in various domains, for example, computer vision models have an exceptional result in object recognition, and in natural language processing, where Large Language Models (LLM) like GPT can start a conversation with human-like proficiency. However, abstract reasoning remains a challenge for these models, Can AI really thinking like a human? still be a question yet to be answered. Raven Progressive Matrices (RPM) is a metric designed to assess human reasoning capabilities. It presents a series of eight images as a problem set, where the participant should try to discover the underlying rules among these images and select the most appropriate image from eight possible options that best completes the sequence. This task always be used to test human reasoning abilities and IQ. Zhang et al proposed a dataset called RAVEN which can be used to test Machine Learning model abstract reasoning ability. In this paper, we purposed Vision Transformer Contrastive Network which build on previous work with the Contrastive Perceptual Inference network (CoPiNet), which set a new benchmark for permutationinvariant models Raven Progressive Matrices by incorporating contrast effects from psychology, cognition, and education, and extends this foundation by leveraging the cutting-edge Vision Transformer architecture. This integration aims to further refine the machine ability to process and reason about spatial-temporal information from pixel-level inputs and global wise features on RAVEN dataset.
EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
Mar 15, 2024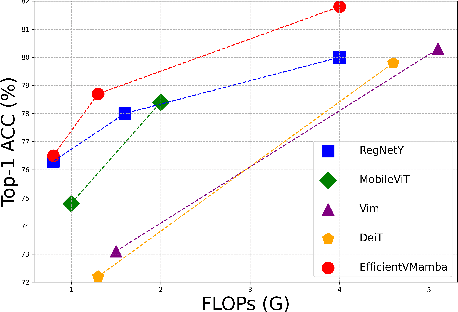
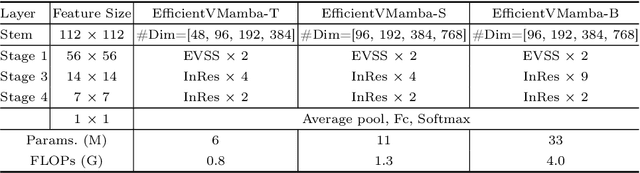
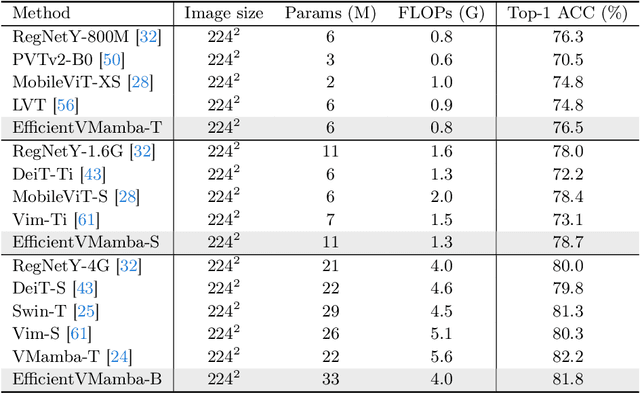
Prior efforts in light-weight model development mainly centered on CNN and Transformer-based designs yet faced persistent challenges. CNNs adept at local feature extraction compromise resolution while Transformers offer global reach but escalate computational demands $\mathcal{O}(N^2)$. This ongoing trade-off between accuracy and efficiency remains a significant hurdle. Recently, state space models (SSMs), such as Mamba, have shown outstanding performance and competitiveness in various tasks such as language modeling and computer vision, while reducing the time complexity of global information extraction to $\mathcal{O}(N)$. Inspired by this, this work proposes to explore the potential of visual state space models in light-weight model design and introduce a novel efficient model variant dubbed EfficientVMamba. Concretely, our EfficientVMamba integrates a atrous-based selective scan approach by efficient skip sampling, constituting building blocks designed to harness both global and local representational features. Additionally, we investigate the integration between SSM blocks and convolutions, and introduce an efficient visual state space block combined with an additional convolution branch, which further elevate the model performance. Experimental results show that, EfficientVMamba scales down the computational complexity while yields competitive results across a variety of vision tasks. For example, our EfficientVMamba-S with $1.3$G FLOPs improves Vim-Ti with $1.5$G FLOPs by a large margin of $5.6\%$ accuracy on ImageNet. Code is available at: \url{https://github.com/TerryPei/EfficientVMamba}.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024
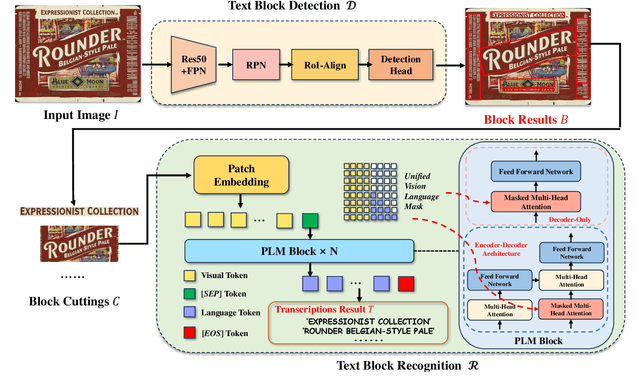
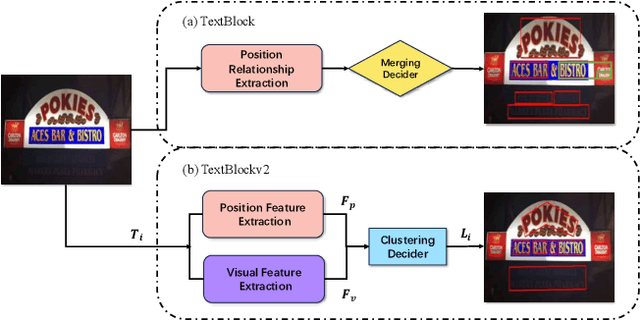
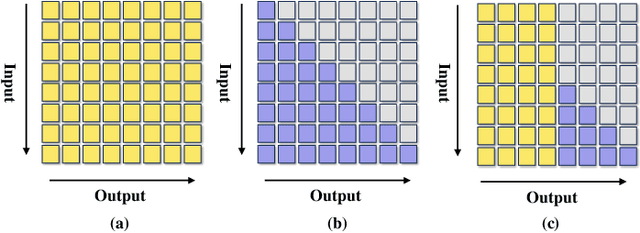
Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).
Do Visual-Language Maps Capture Latent Semantics?
Mar 15, 2024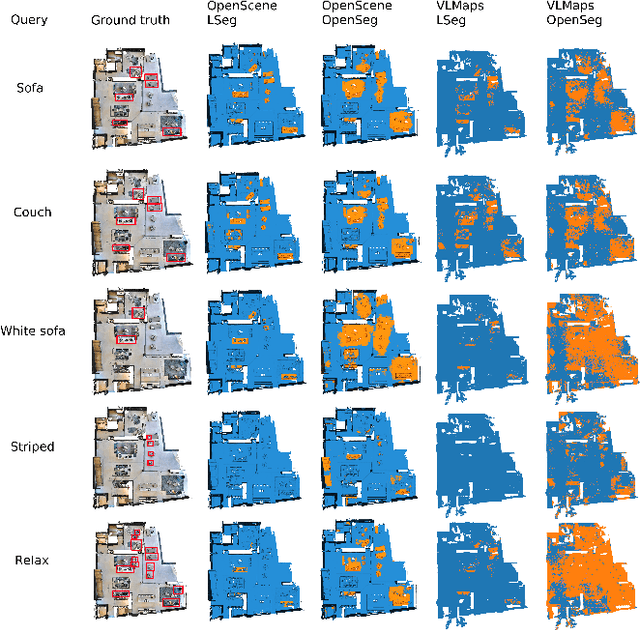
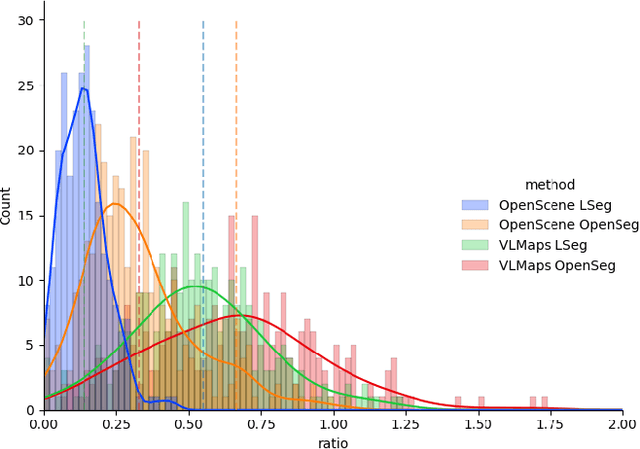
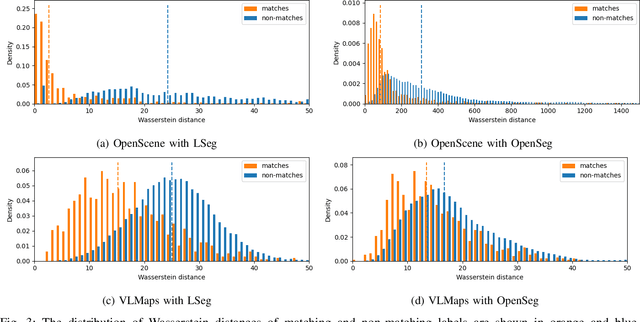
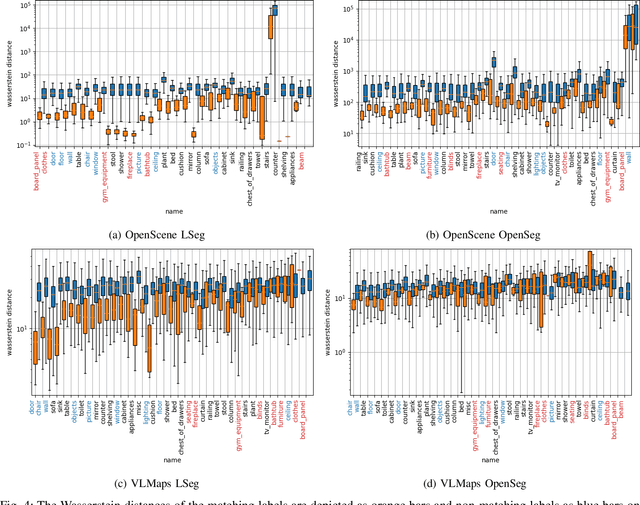
Visual-language models (VLMs) have recently been introduced in robotic mapping by using the latent representations, i.e., embeddings, of the VLMs to represent the natural language semantics in the map. The main benefit is moving beyond a small set of human-created labels toward open-vocabulary scene understanding. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is lacking. We investigate two critical properties of map quality: queryability and consistency. The evaluation of queryability addresses the ability to retrieve information from the embeddings. We investigate two aspects of consistency: intra-map consistency and inter-map consistency. Intra-map consistency captures the ability of the embeddings to represent abstract semantic classes, and inter-map consistency captures the generalization properties of the representation. In this paper, we propose a way to analyze the quality of maps created using VLMs, which forms an open-source benchmark to be used when proposing new open-vocabulary map representations. We demonstrate the benchmark by evaluating the maps created by two state-of-the-art methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set. We find that OpenScene outperforms VLMaps with both encoders, and LSeg outperforms OpenSeg with both methods.
Investigating grammatical abstraction in language models using few-shot learning of novel noun gender
Mar 15, 2024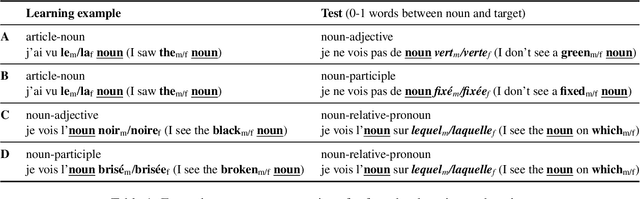
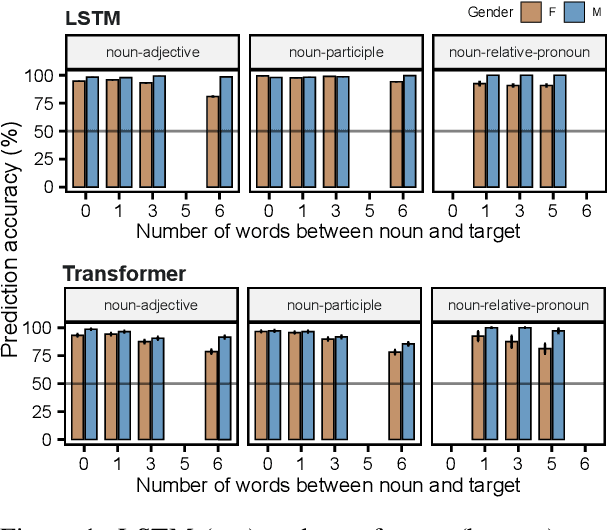
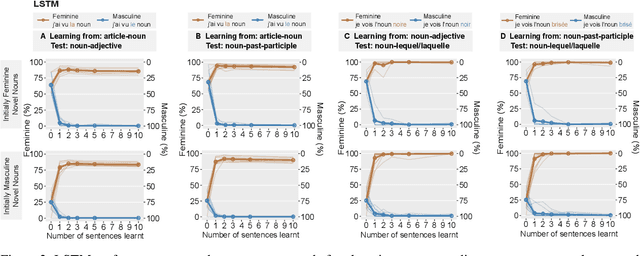
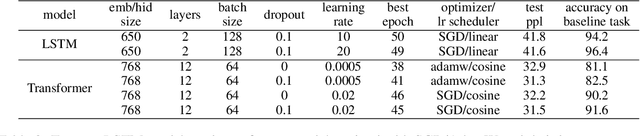
Humans can learn a new word and infer its grammatical properties from very few examples. They have an abstract notion of linguistic properties like grammatical gender and agreement rules that can be applied to novel syntactic contexts and words. Drawing inspiration from psycholinguistics, we conduct a noun learning experiment to assess whether an LSTM and a decoder-only transformer can achieve human-like abstraction of grammatical gender in French. Language models were tasked with learning the gender of a novel noun embedding from a few examples in one grammatical agreement context and predicting agreement in another, unseen context. We find that both language models effectively generalise novel noun gender from one to two learning examples and apply the learnt gender across agreement contexts, albeit with a bias for the masculine gender category. Importantly, the few-shot updates were only applied to the embedding layers, demonstrating that models encode sufficient gender information within the word embedding space. While the generalisation behaviour of models suggests that they represent grammatical gender as an abstract category, like humans, further work is needed to explore the details of how exactly this is implemented. For a comparative perspective with human behaviour, we conducted an analogous one-shot novel noun gender learning experiment, which revealed that native French speakers, like language models, also exhibited a masculine gender bias and are not excellent one-shot learners either.
German also Hallucinates! Inconsistency Detection in News Summaries with the Absinth Dataset
Mar 14, 2024
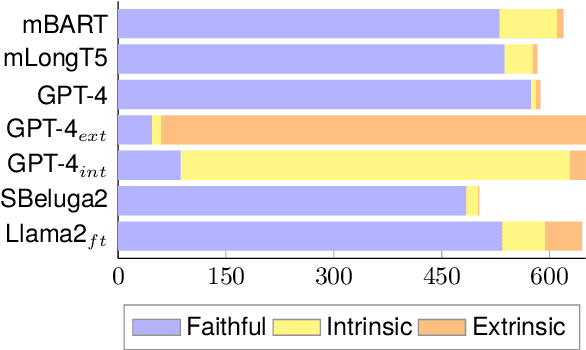
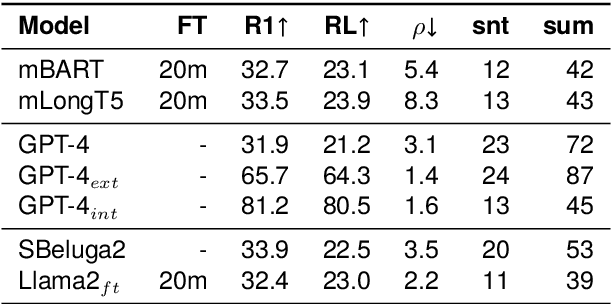
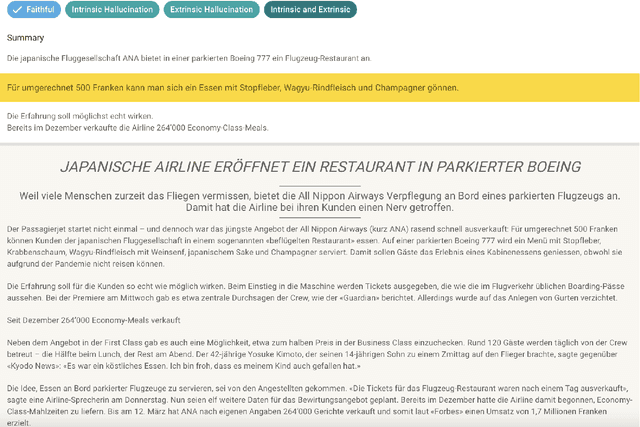
The advent of Large Language Models (LLMs) has led to remarkable progress on a wide range of natural language processing tasks. Despite the advances, these large-sized models still suffer from hallucinating information in their output, which poses a major issue in automatic text summarization, as we must guarantee that the generated summary is consistent with the content of the source document. Previous research addresses the challenging task of detecting hallucinations in the output (i.e. inconsistency detection) in order to evaluate the faithfulness of the generated summaries. However, these works primarily focus on English and recent multilingual approaches lack German data. This work presents absinth, a manually annotated dataset for hallucination detection in German news summarization and explores the capabilities of novel open-source LLMs on this task in both fine-tuning and in-context learning settings. We open-source and release the absinth dataset to foster further research on hallucination detection in German.
Compute-first optical detection for noise-resilient visual perception
Mar 14, 2024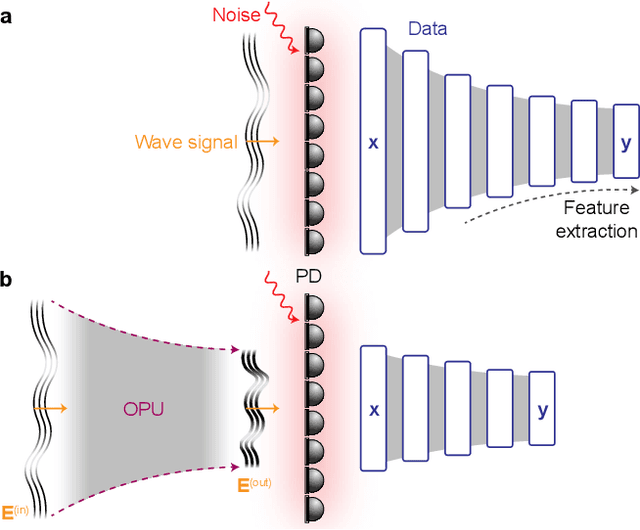
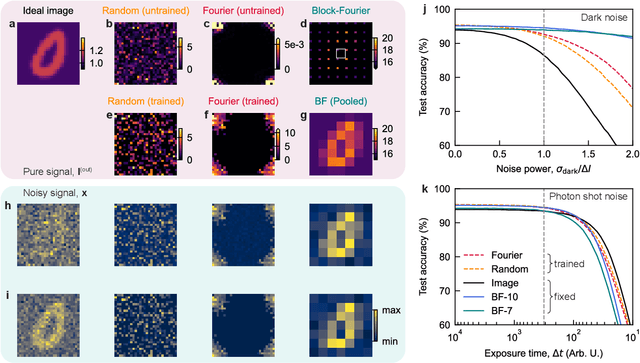
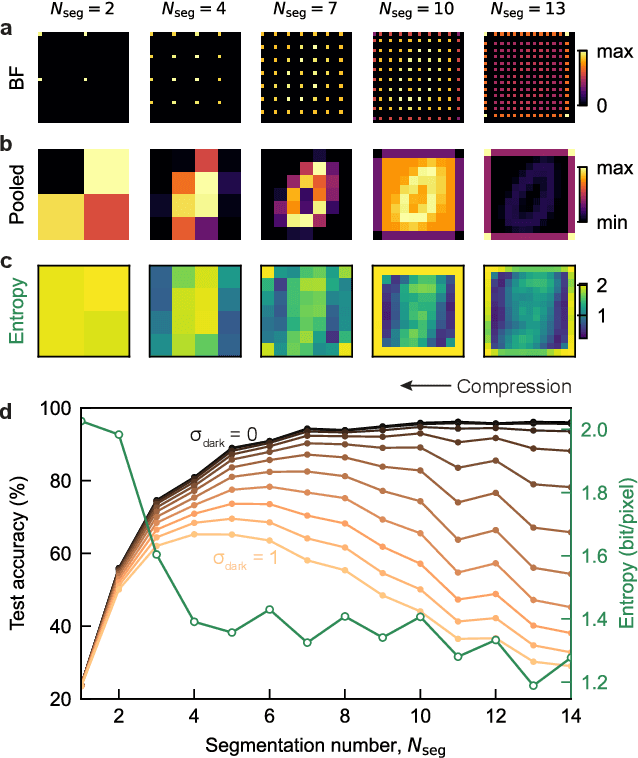
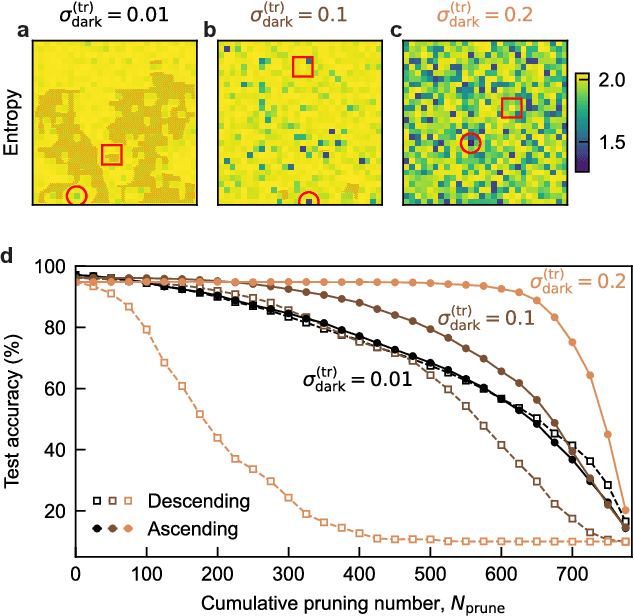
In the context of visual perception, the optical signal from a scene is transferred into the electronic domain by detectors in the form of image data, which are then processed for the extraction of visual information. In noisy and weak-signal environments such as thermal imaging for night vision applications, however, the performance of neural computing tasks faces a significant bottleneck due to the inherent degradation of data quality upon noisy detection. Here, we propose a concept of optical signal processing before detection to address this issue. We demonstrate that spatially redistributing optical signals through a properly designed linear transformer can enhance the detection noise resilience of visual perception tasks, as benchmarked with the MNIST classification. Our idea is supported by a quantitative analysis detailing the relationship between signal concentration and noise robustness, as well as its practical implementation in an incoherent imaging system. This compute-first detection scheme can pave the way for advancing infrared machine vision technologies widely used for industrial and defense applications.