 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Is Distance Matrix Enough for Geometric Deep Learning?
Feb 11, 2023
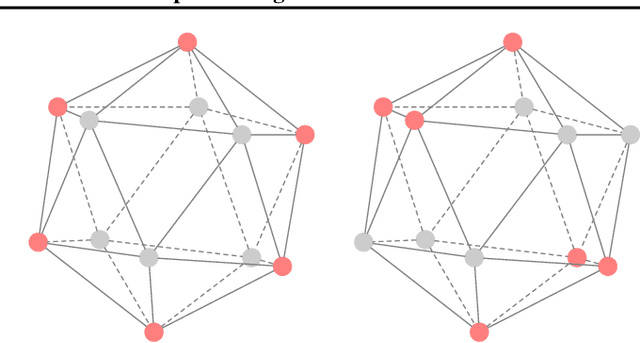
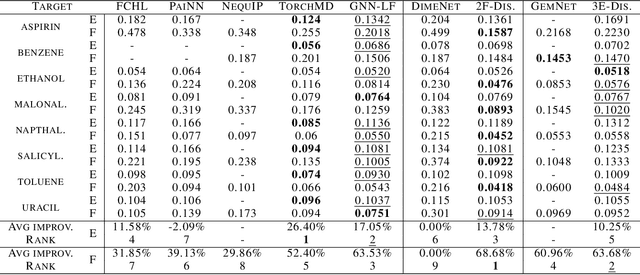
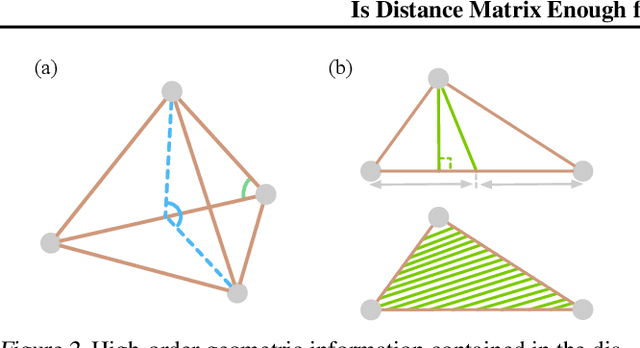
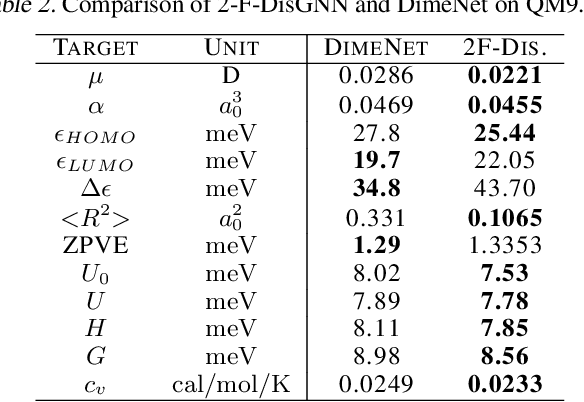
Graph Neural Networks (GNNs) are often used for tasks involving the geometry of a given graph, such as molecular dynamics simulation. While the distance matrix of a graph contains the complete geometric structure information, whether GNNs can learn this geometry solely from the distance matrix has yet to be studied. In this work, we first demonstrate that Message Passing Neural Networks (MPNNs) are insufficient for learning the geometry of a graph from its distance matrix by constructing families of geometric graphs which cannot be distinguished by MPNNs. We then propose $k$-DisGNNs, which can effectively exploit the rich geometry contained in the distance matrix. We demonstrate the high expressive power of our models and prove that some existing well-designed geometric models can be unified by $k$-DisGNNs as special cases. Most importantly, we establish a connection between geometric deep learning and traditional graph representation learning, showing that those highly expressive GNN models originally designed for graph structure learning can also be applied to geometric deep learning problems with impressive performance, and that existing complex, equivariant models are not the only solution. Experimental results verify our theory.
Sequential Underspecified Instrument Selection for Cause-Effect Estimation
Feb 11, 2023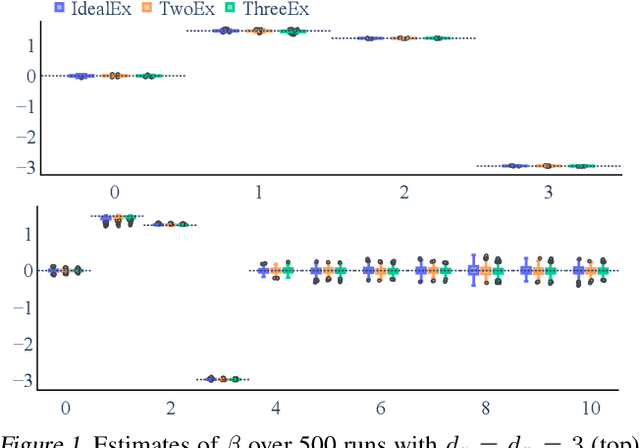
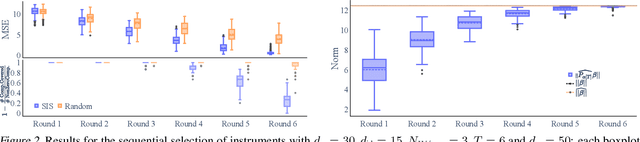
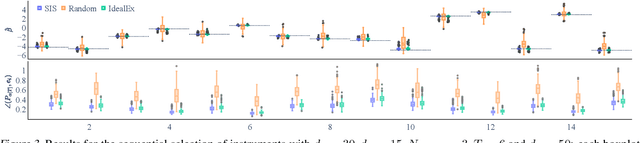
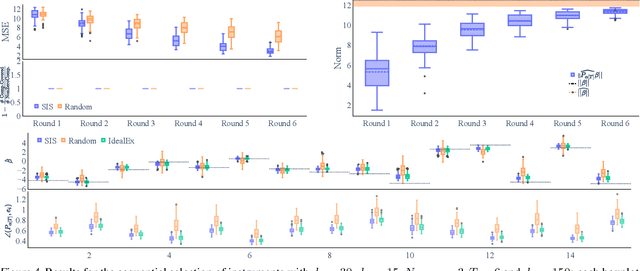
Instrumental variable (IV) methods are used to estimate causal effects in settings with unobserved confounding, where we cannot directly experiment on the treatment variable. Instruments are variables which only affect the outcome indirectly via the treatment variable(s). Most IV applications focus on low-dimensional treatments and crucially require at least as many instruments as treatments. This assumption is restrictive: in the natural sciences we often seek to infer causal effects of high-dimensional treatments (e.g., the effect of gene expressions or microbiota on health and disease), but can only run few experiments with a limited number of instruments (e.g., drugs or antibiotics). In such underspecified problems, the full treatment effect is not identifiable in a single experiment even in the linear case. We show that one can still reliably recover the projection of the treatment effect onto the instrumented subspace and develop techniques to consistently combine such partial estimates from different sets of instruments. We then leverage our combined estimators in an algorithm that iteratively proposes the most informative instruments at each round of experimentation to maximize the overall information about the full causal effect.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023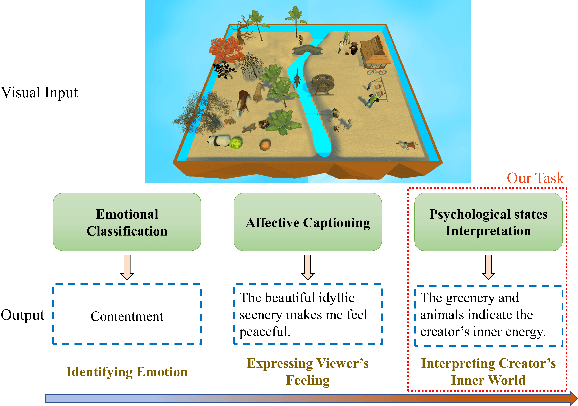

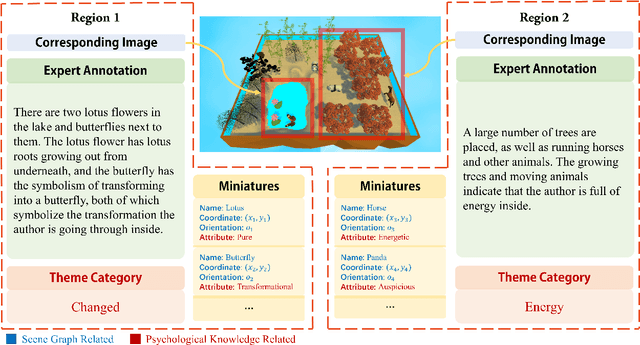
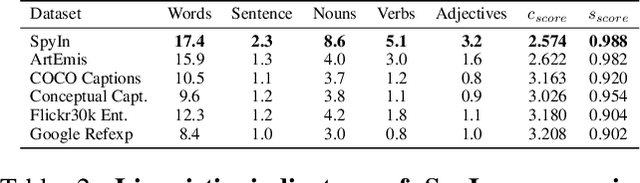
In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
Effective and Interpretable Information Aggregation with Capacity Networks
Jul 25, 2022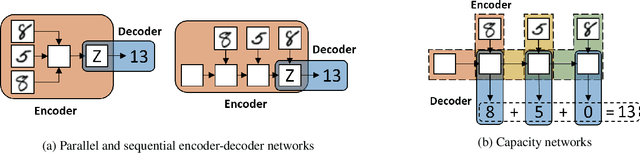
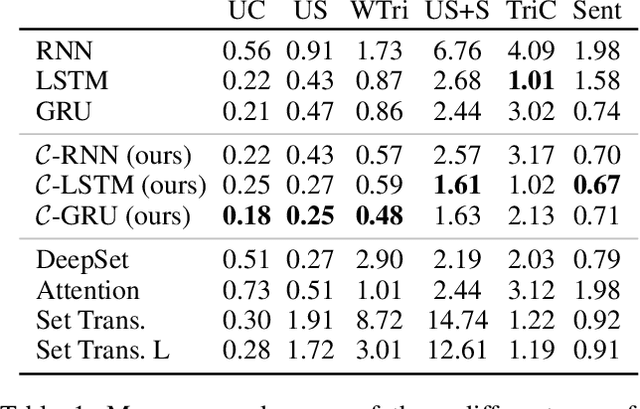
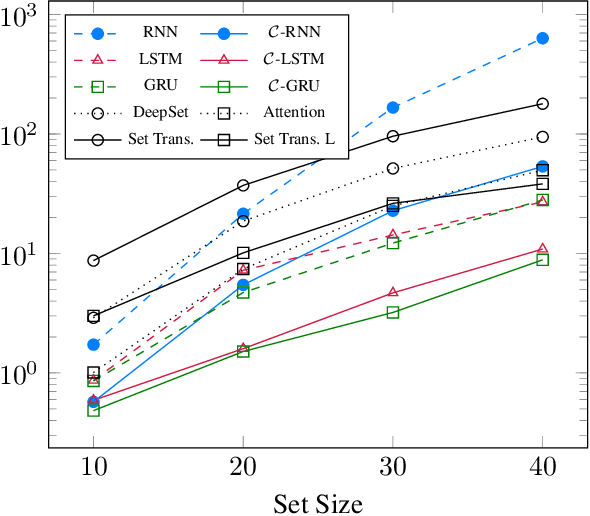
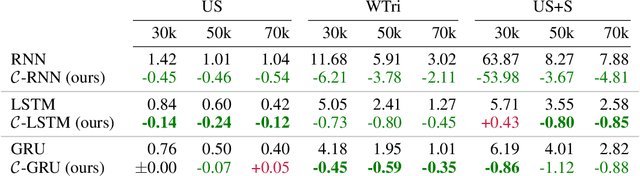
How to aggregate information from multiple instances is a key question multiple instance learning. Prior neural models implement different variants of the well-known encoder-decoder strategy according to which all input features are encoded a single, high-dimensional embedding which is then decoded to generate an output. In this work, inspired by Choquet capacities, we propose Capacity networks. Unlike encoder-decoders, Capacity networks generate multiple interpretable intermediate results which can be aggregated in a semantically meaningful space to obtain the final output. Our experiments show that implementing this simple inductive bias leads to improvements over different encoder-decoder architectures in a wide range of experiments. Moreover, the interpretable intermediate results make Capacity networks interpretable by design, which allows a semantically meaningful inspection, evaluation, and regularization of the network internals.
Augmenting Zero-Shot Dense Retrievers with Plug-in Mixture-of-Memories
Feb 07, 2023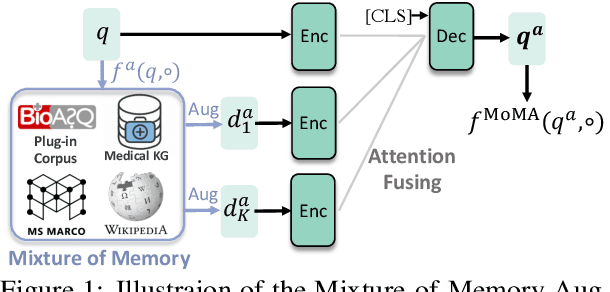
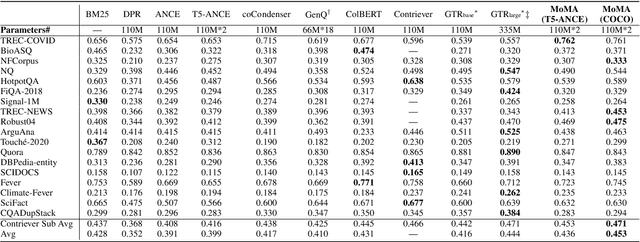
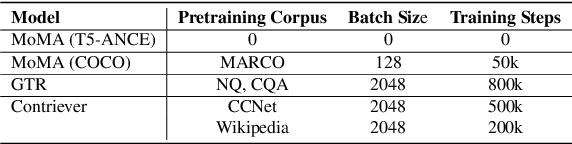
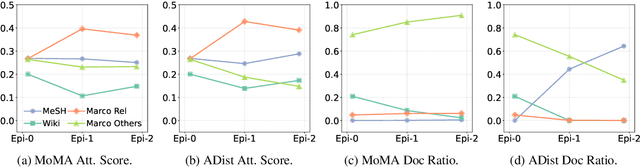
In this paper we improve the zero-shot generalization ability of language models via Mixture-Of-Memory Augmentation (MoMA), a mechanism that retrieves augmentation documents from multiple information corpora ("external memories"), with the option to "plug in" new memory at inference time. We develop a joint learning mechanism that trains the augmentation component with latent labels derived from the end retrieval task, paired with hard negatives from the memory mixture. We instantiate the model in a zero-shot dense retrieval setting by augmenting a strong T5-based retriever with MoMA. Our model, MoMA, obtains strong zero-shot retrieval accuracy on the eighteen tasks included in the standard BEIR benchmark. It outperforms systems that seek generalization from increased model parameters and computation steps. Our analysis further illustrates the necessity of augmenting with mixture-of-memory for robust generalization, the benefits of augmentation learning, and how MoMA utilizes the plug-in memory at inference time without changing its parameters. We plan to open source our code.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 07, 2023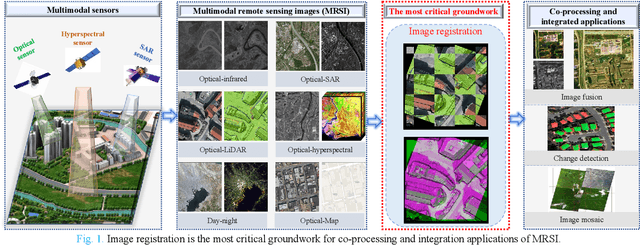
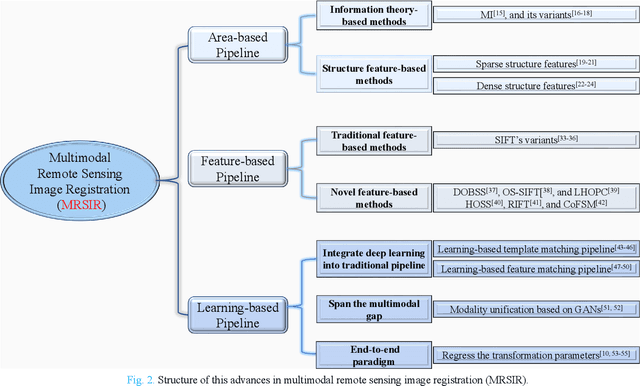
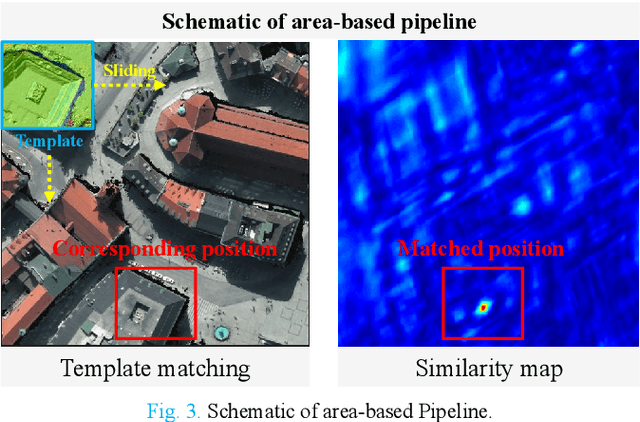

Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.
Fine-grained Affordance Annotation for Egocentric Hand-Object Interaction Videos
Feb 07, 2023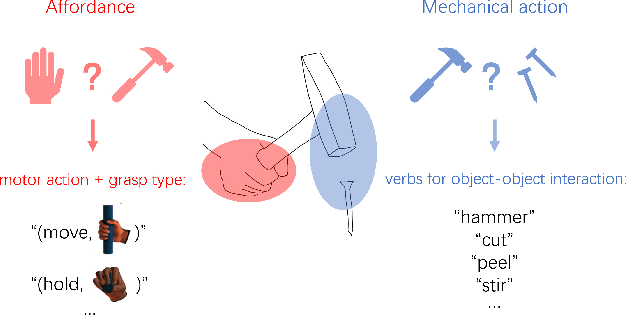


Object affordance is an important concept in hand-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, the definition of affordance in existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition, hand-object interaction hotspots prediction, and cross-domain evaluation of affordance. The results show that models trained with our annotation can distinguish affordance from other concepts, predict fine-grained interaction possibilities on objects, and generalize through different domains.
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023
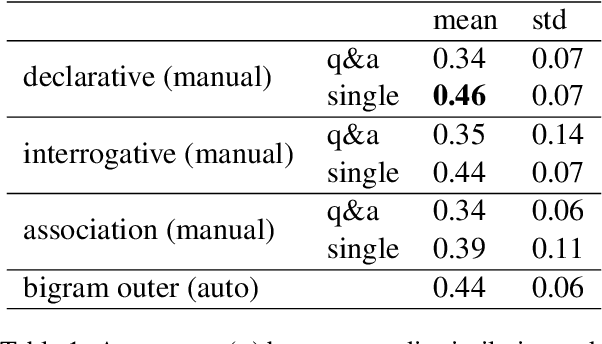

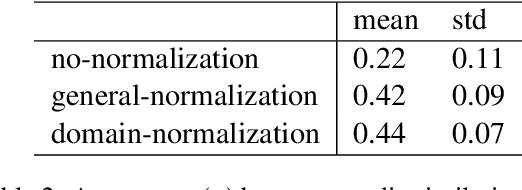
Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
Sparse GEMINI for Joint Discriminative Clustering and Feature Selection
Feb 07, 2023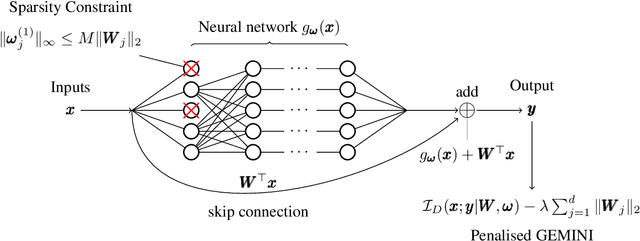
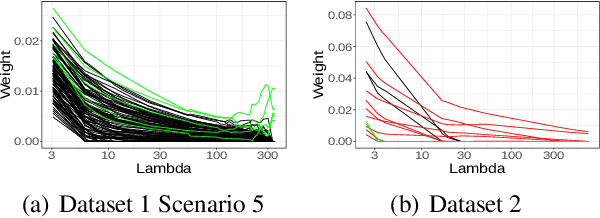
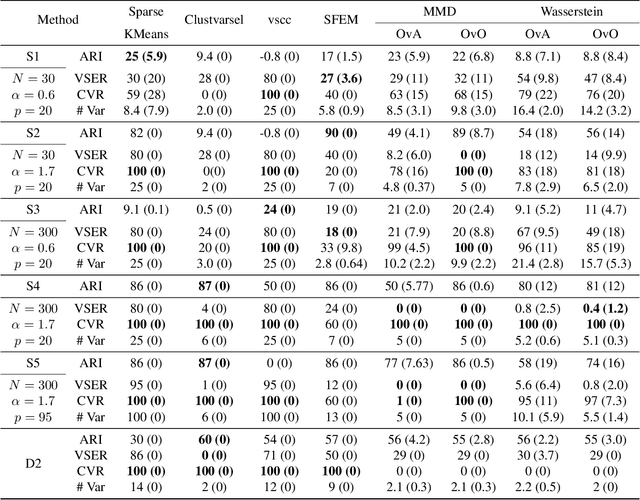
Feature selection in clustering is a hard task which involves simultaneously the discovery of relevant clusters as well as relevant variables with respect to these clusters. While feature selection algorithms are often model-based through optimised model selection or strong assumptions on $p(\pmb{x})$, we introduce a discriminative clustering model trying to maximise a geometry-aware generalisation of the mutual information called GEMINI with a simple $\ell_1$ penalty: the Sparse GEMINI. This algorithm avoids the burden of combinatorial feature subset exploration and is easily scalable to high-dimensional data and large amounts of samples while only designing a clustering model $p_\theta(y|\pmb{x})$. We demonstrate the performances of Sparse GEMINI on synthetic datasets as well as large-scale datasets. Our results show that Sparse GEMINI is a competitive algorithm and has the ability to select relevant subsets of variables with respect to the clustering without using relevance criteria or prior hypotheses.
Predicting CSI Sequences With Attention-Based Neural Networks
Feb 01, 2023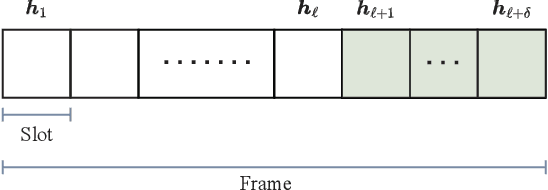
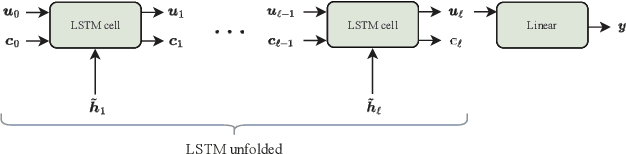
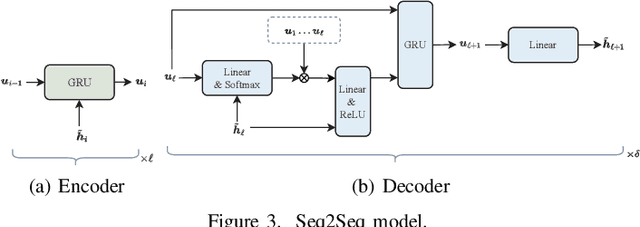
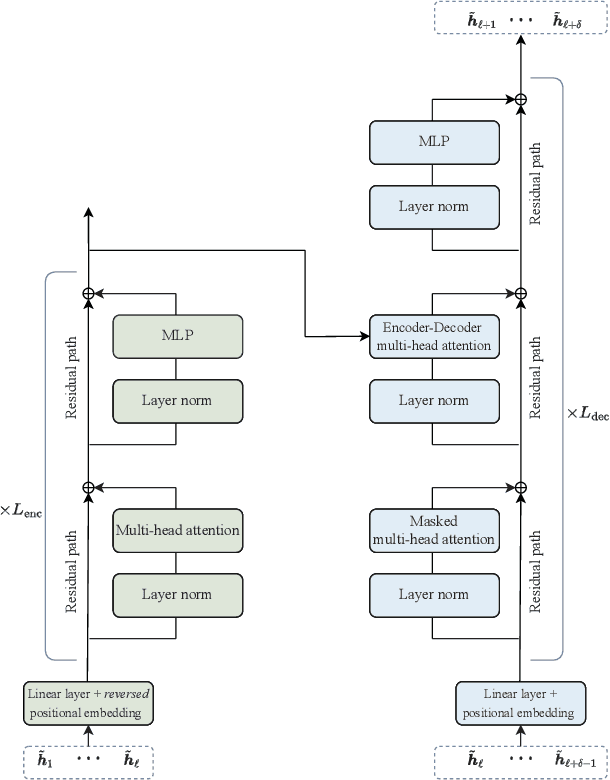
In this work, we consider the problem of multi-step channel prediction in wireless communication systems. In existing works, autoregressive (AR) models are either replaced or combined with feed-forward neural networks(NNs) or, alternatively, with recurrent neural networks (RNNs). This paper explores the possibility of using sequence-to-sequence (Seq2Seq) and transformer neural network (TNN) models for channel state information (CSI) prediction. Simulation results show that both, Seq2Seq and TNNs, represent an appealing alternative to RNNs and feed-forward NNs in the context of CSI prediction. Additionally, the TNN with a few adaptations can extrapolate better than other models to CSI sequences that are either shorter or longer than the ones the model saw during training.