 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforcement Learning Aided Sequential Optimization for Unsignalized Intersection Management of Robot Traffic
Feb 10, 2023
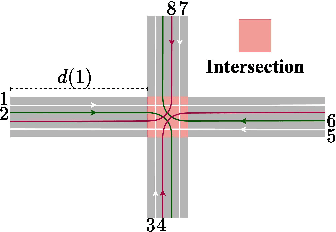

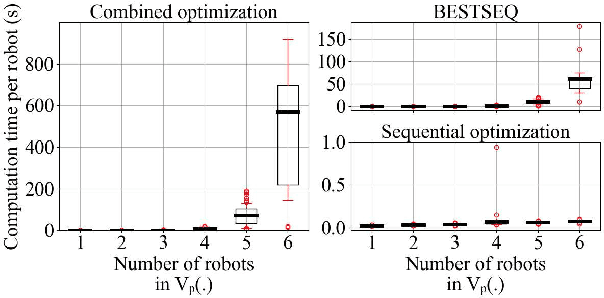
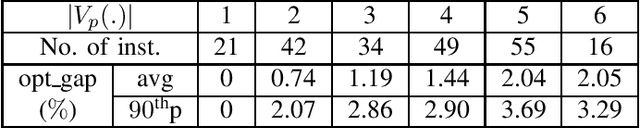
We consider the problem of optimal unsignalized intersection management for continual streams of randomly arriving robots. This problem involves solving many instances of a mixed integer program, for which the computation time using a naive optimization algorithm scales exponentially with the number of robots and lanes. Hence, such an approach is not suitable for real-time implementation. In this paper, we propose a solution framework that combines learning and sequential optimization. In particular, we propose an algorithm for learning a policy that given the traffic state information, determines the crossing order of the robots. Then, we optimize the trajectories of the robots sequentially according to that crossing order. The proposed algorithm learns a shared policy that can be deployed in a distributed manner. We validate the performance of this approach using extensive simulations. Our approach, on average, significantly outperforms the heuristics from the literature and gives near-optimal solutions. We also show through simulations that the computation time for our approach scales linearly with the number of robots.
Fast Learnings of Coupled Nonnegative Tensor Decomposition Using Optimal Gradient and Low-rank Approximation
Feb 10, 2023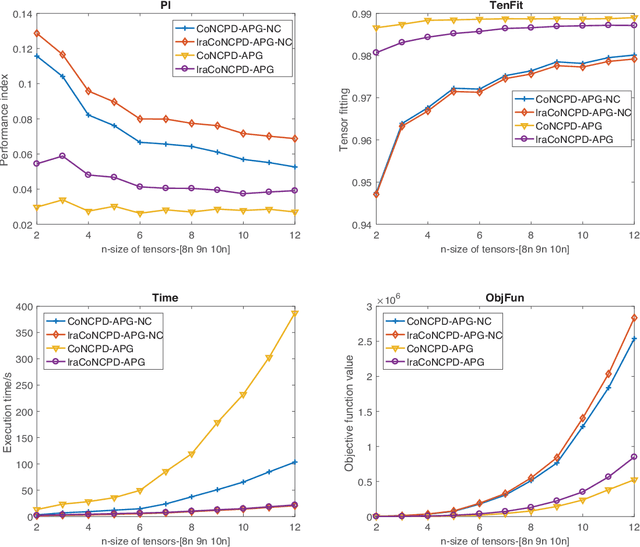
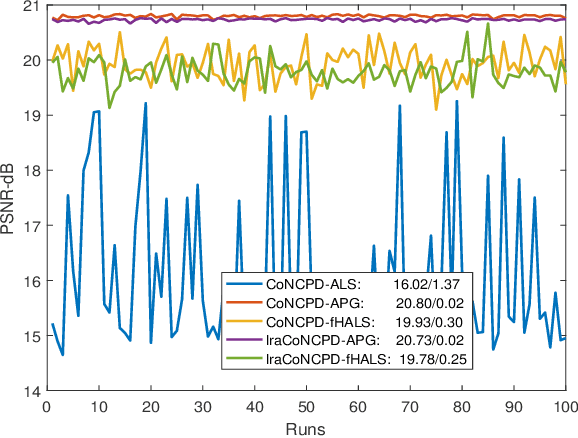
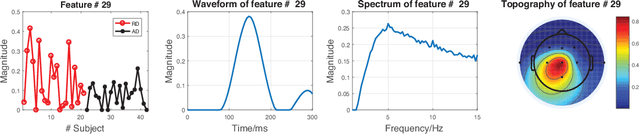
Nonnegative tensor decomposition has been widely applied in signal processing and neuroscience, etc. When it comes to group analysis of multi-block tensors, traditional tensor decomposition is insufficient to utilize the shared/similar information among tensors. In this study, we propose a coupled nonnegative CANDECOMP/PARAFAC decomposition algorithm optimized by the alternating proximal gradient method (CoNCPDAPG), which is capable of a simultaneous decomposition of tensors from different samples that are partially linked and a simultaneous extraction of common components, individual components and core tensors. Due to the low optimization efficiency brought by the nonnegative constraint and the high-dimensional nature of the data, we further propose the lraCoNCPD-APG algorithm by combining low-rank approximation and the proposed CoNCPD-APG method. When processing multi-block large-scale tensors, the proposed lraCoNCPD-APG algorithm can greatly reduce the computational load without compromising the decomposition quality. Experiment results of coupled nonnegative tensor decomposition problems designed for synthetic data, real-world face images and event-related potential data demonstrate the practicability and superiority of the proposed algorithms.
Example-Based Sampling with Diffusion Models
Feb 10, 2023
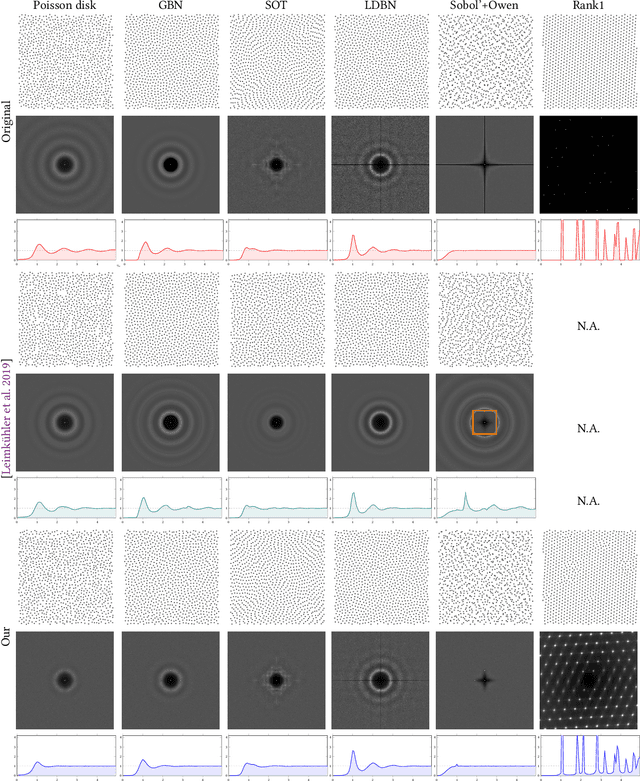
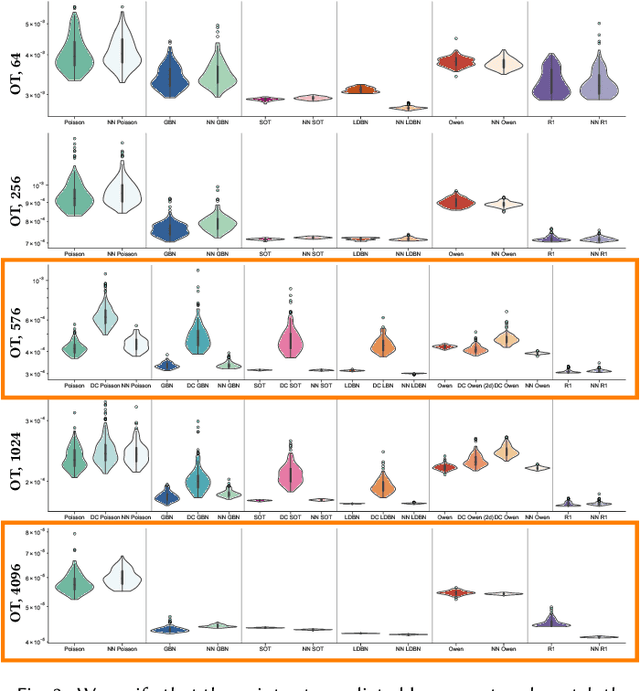
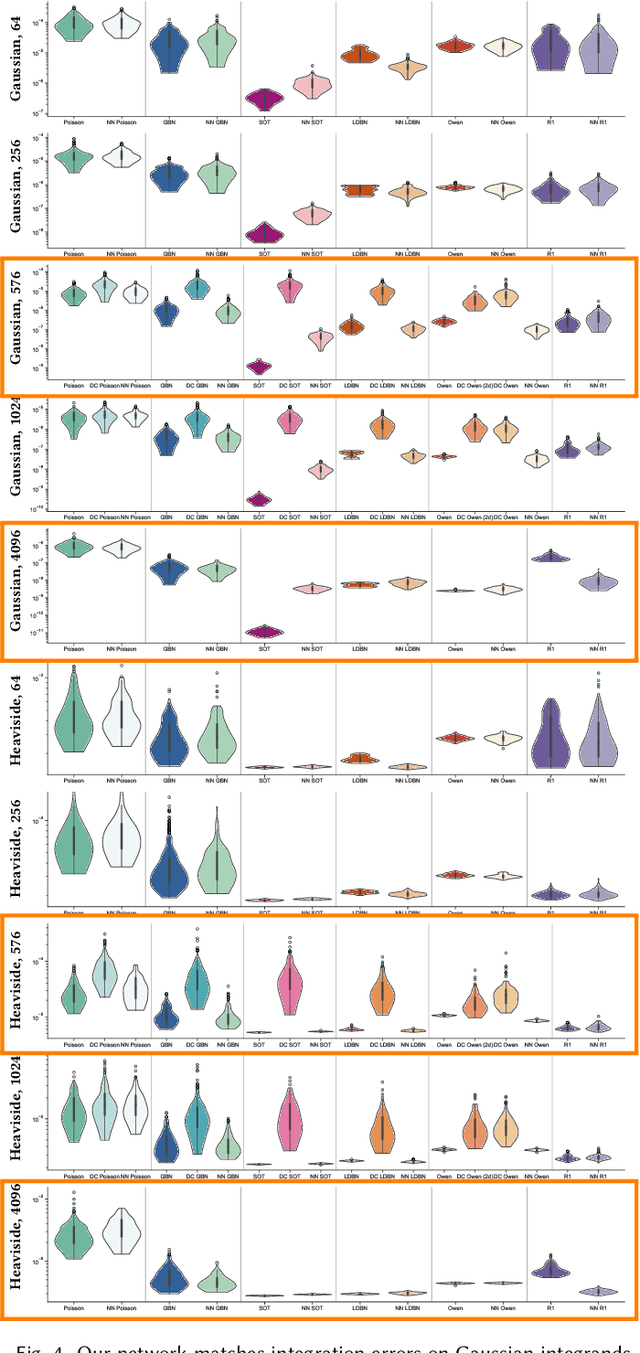
Much effort has been put into developing samplers with specific properties, such as producing blue noise, low-discrepancy, lattice or Poisson disk samples. These samplers can be slow if they rely on optimization processes, may rely on a wide range of numerical methods, are not always differentiable. The success of recent diffusion models for image generation suggests that these models could be appropriate for learning how to generate point sets from examples. However, their convolutional nature makes these methods impractical for dealing with scattered data such as point sets. We propose a generic way to produce 2-d point sets imitating existing samplers from observed point sets using a diffusion model. We address the problem of convolutional layers by leveraging neighborhood information from an optimal transport matching to a uniform grid, that allows us to benefit from fast convolutions on grids, and to support the example-based learning of non-uniform sampling patterns. We demonstrate how the differentiability of our approach can be used to optimize point sets to enforce properties.
Reinforcement Learning from Multiple Sensors via Joint Representations
Feb 10, 2023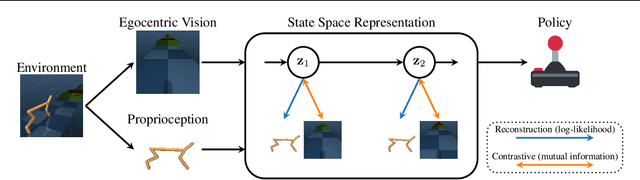


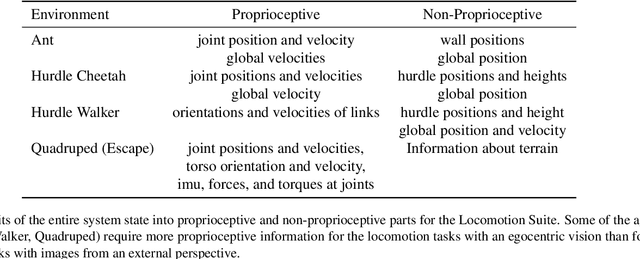
In many scenarios, observations from more than one sensor modality are available for reinforcement learning (RL). For example, many agents can perceive their internal state via proprioceptive sensors but must infer the environment's state from high-dimensional observations such as images. For image-based RL, a variety of self-supervised representation learning approaches exist to improve performance and sample complexity. These approaches learn the image representation in isolation. However, including proprioception can help representation learning algorithms to focus on relevant aspects and guide them toward finding better representations. Hence, in this work, we propose using Recurrent State Space Models to fuse all available sensory information into a single consistent representation. We combine reconstruction-based and contrastive approaches for training, which allows using the most appropriate method for each sensor modality. For example, we can use reconstruction for proprioception and a contrastive loss for images. We demonstrate the benefits of utilizing proprioception in learning representations for RL on a large set of experiments. Furthermore, we show that our joint representations significantly improve performance compared to a post hoc combination of image representations and proprioception.
Improving Small Molecule Generation using Mutual Information Machine
Aug 18, 2022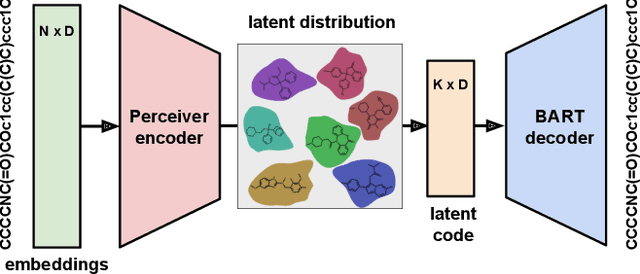

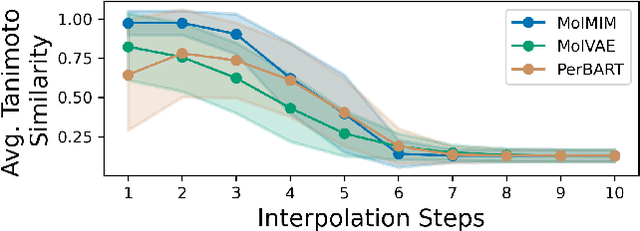
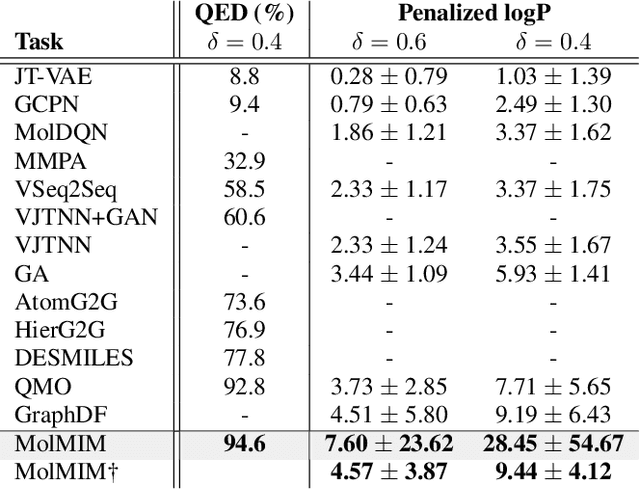
We address the task of controlled generation of small molecules, which entails finding novel molecules with desired properties under certain constraints (e.g., similarity to a reference molecule). Here we introduce MolMIM, a probabilistic auto-encoder for small molecule drug discovery that learns an informative and clustered latent space. MolMIM is trained with Mutual Information Machine (MIM) learning, and provides a fixed length representation of variable length SMILES strings. Since encoder-decoder models can learn representations with ``holes'' of invalid samples, here we propose a novel extension to the training procedure which promotes a dense latent space, and allows the model to sample valid molecules from random perturbations of latent codes. We provide a thorough comparison of MolMIM to several variable-size and fixed-size encoder-decoder models, demonstrating MolMIM's superior generation as measured in terms of validity, uniqueness, and novelty. We then utilize CMA-ES, a naive black-box and gradient free search algorithm, over MolMIM's latent space for the task of property guided molecule optimization. We achieve state-of-the-art results in several constrained single property optimization tasks as well as in the challenging task of multi-objective optimization, improving over previous success rate SOTA by more than 5\% . We attribute the strong results to MolMIM's latent representation which clusters similar molecules in the latent space, whereas CMA-ES is often used as a baseline optimization method. We also demonstrate MolMIM to be favourable in a compute limited regime, making it an attractive model for such cases.
KLIF: An optimized spiking neuron unit for tuning surrogate gradient slope and membrane potential
Feb 18, 2023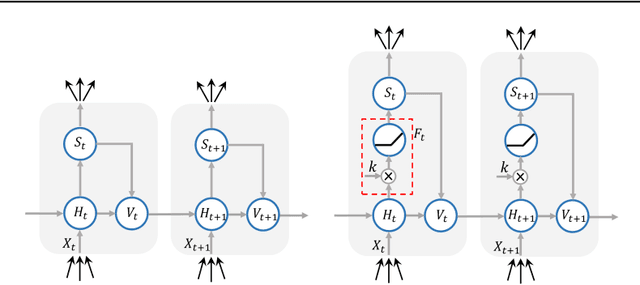
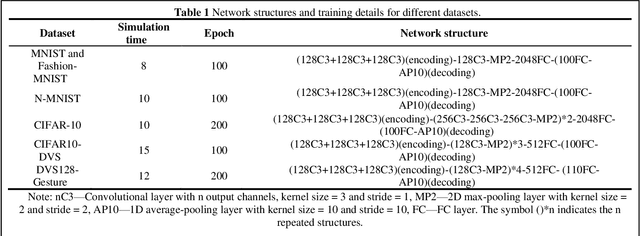
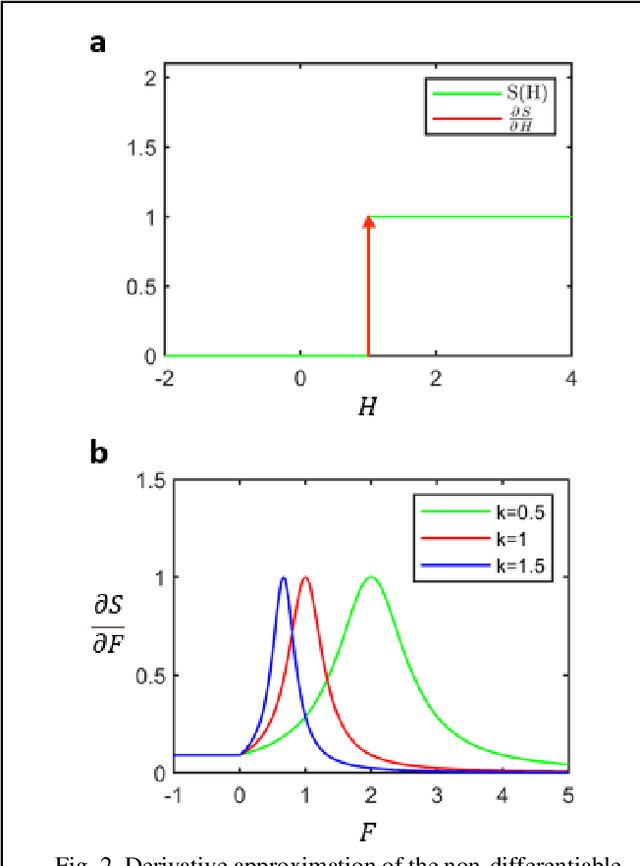
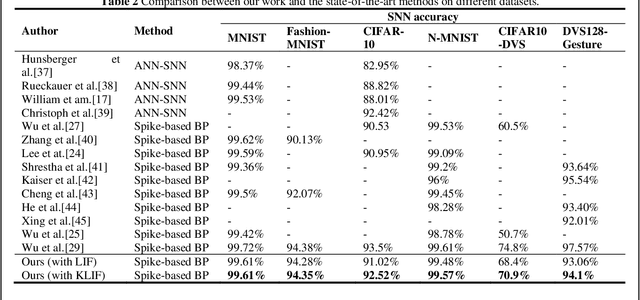
Spiking neural networks (SNNs) have attracted much attention due to their ability to process temporal information, low power consumption, and higher biological plausibility. However, it is still challenging to develop efficient and high-performing learning algorithms for SNNs. Methods like artificial neural network (ANN)-to-SNN conversion can transform ANNs to SNNs with slight performance loss, but it needs a long simulation to approximate the rate coding. Directly training SNN by spike-based backpropagation (BP) such as surrogate gradient approximation is more flexible. Yet now, the performance of SNNs is not competitive compared with ANNs. In this paper, we propose a novel k-based leaky Integrate-and-Fire (KLIF) neuron model to improve the learning ability of SNNs. Compared with the popular leaky integrate-and-fire (LIF) model, KLIF adds a learnable scaling factor to dynamically update the slope and width of the surrogate gradient curve during training and incorporates a ReLU activation function that selectively delivers membrane potential to spike firing and resetting. The proposed spiking unit is evaluated on both static MNIST, Fashion-MNIST, CIFAR-10 datasets, as well as neuromorphic N-MNIST, CIFAR10-DVS, and DVS128-Gesture datasets. Experiments indicate that KLIF performs much better than LIF without introducing additional computational cost and achieves state-of-the-art performance on these datasets with few time steps. Also, KLIF is believed to be more biological plausible than LIF. The good performance of KLIF can make it completely replace the role of LIF in SNN for various tasks.
SPADE: Self-supervised Pretraining for Acoustic DisEntanglement
Feb 03, 2023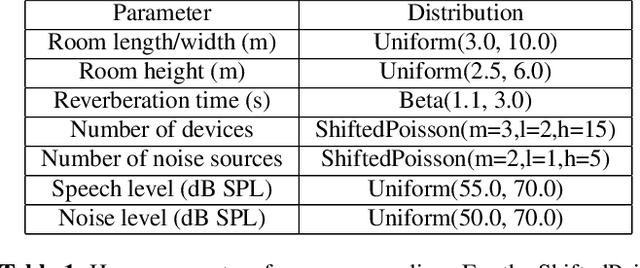
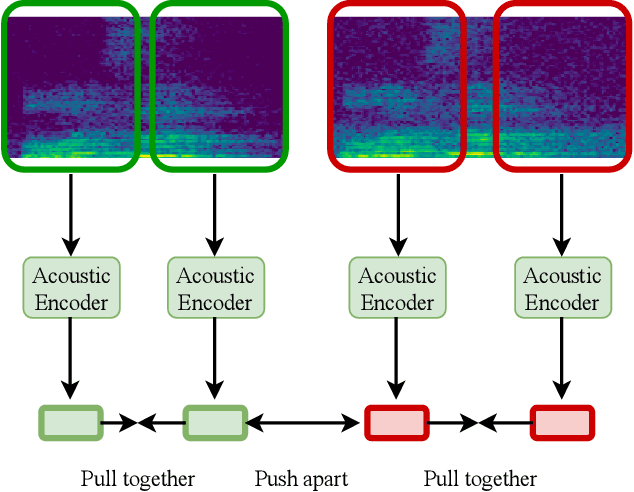
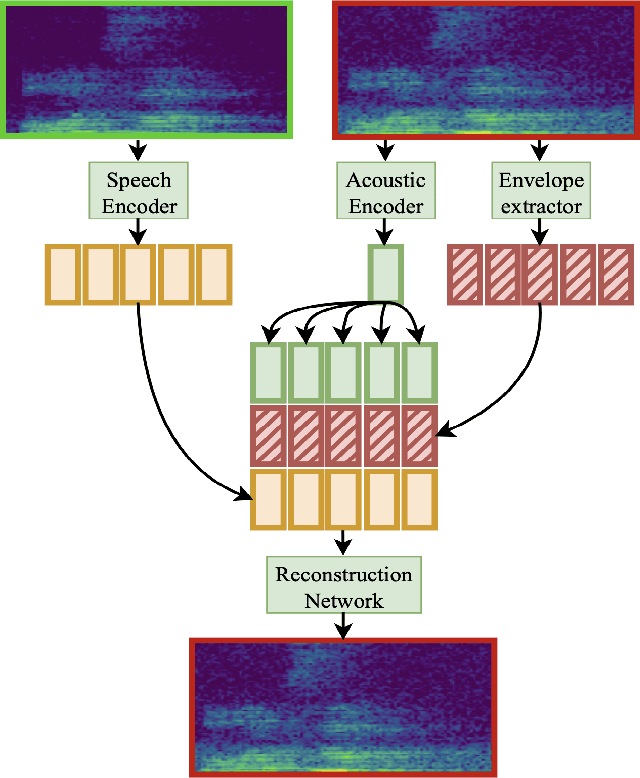
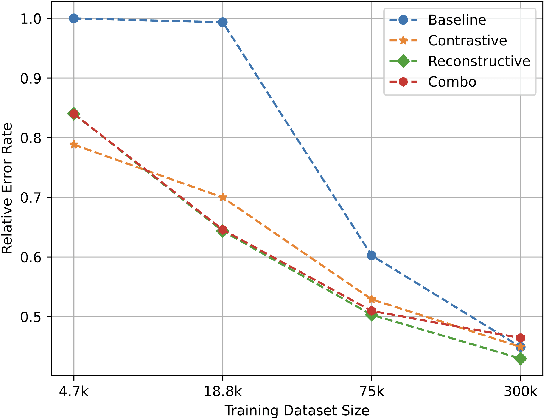
Self-supervised representation learning approaches have grown in popularity due to the ability to train models on large amounts of unlabeled data and have demonstrated success in diverse fields such as natural language processing, computer vision, and speech. Previous self-supervised work in the speech domain has disentangled multiple attributes of speech such as linguistic content, speaker identity, and rhythm. In this work, we introduce a self-supervised approach to disentangle room acoustics from speech and use the acoustic representation on the downstream task of device arbitration. Our results demonstrate that our proposed approach significantly improves performance over a baseline when labeled training data is scarce, indicating that our pretraining scheme learns to encode room acoustic information while remaining invariant to other attributes of the speech signal.
A Method For Eliminating Contour Errors In Self-Encoder Reconstructed Images
Jan 25, 2023
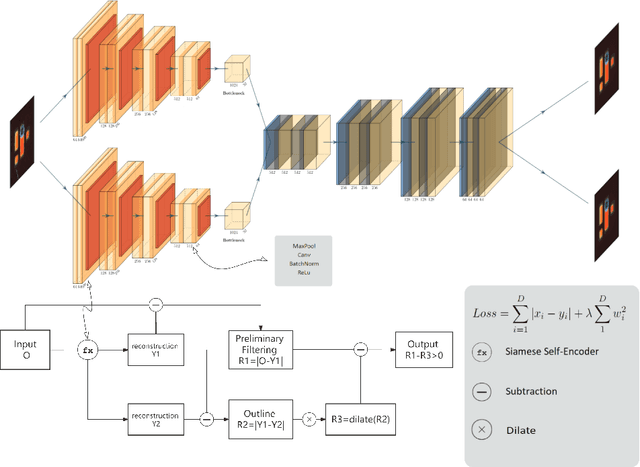
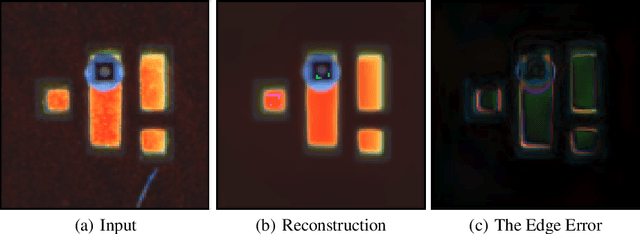
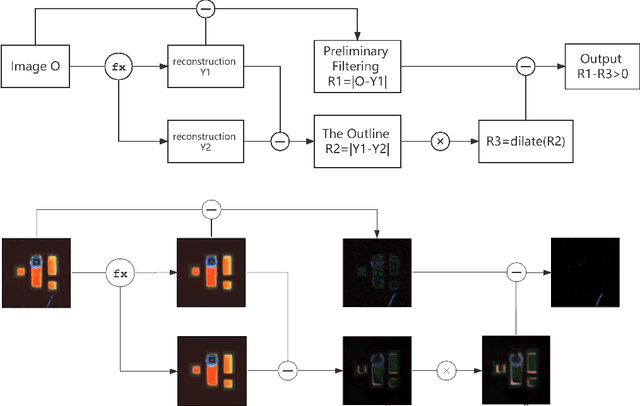
In this paper, we propose a self-supervised twin network approach based on this a priori. The method of generating the approximate10 edge information of an image and then differentially eliminating the edge errors11 in the reconstructed image with a dilate algorithm. This is used to improve the12 accuracy of the reconstructed image and to separate foreign matter and noise from13 the original image, so that it can be visualized in a more practical scene
Reconstructing Rayleigh-Benard flows out of temperature-only measurements using Physics-Informed Neural Networks
Jan 18, 2023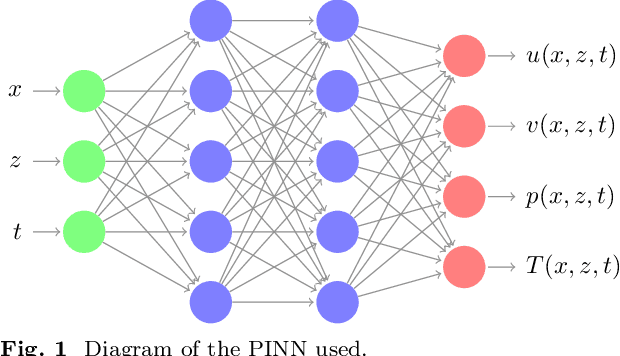
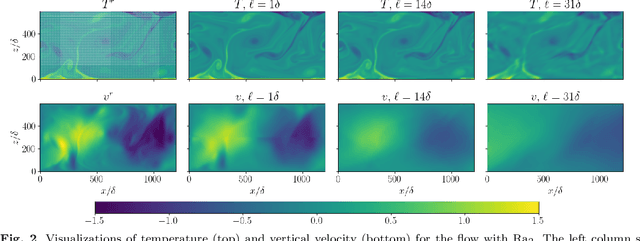
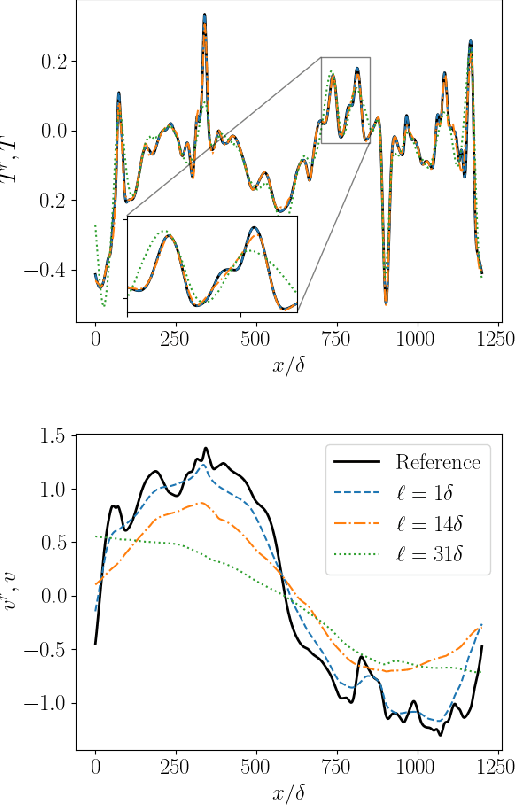
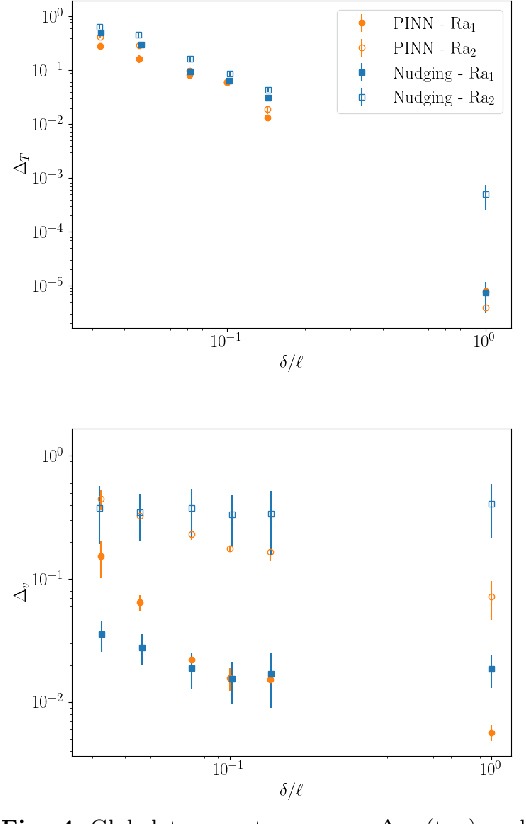
We investigate the capabilities of Physics-Informed Neural Networks (PINNs) to reconstruct turbulent Rayleigh-Benard flows using only temperature information. We perform a quantitative analysis of the quality of the reconstructions at various amounts of low-passed-filtered information and turbulent intensities. We compare our results with those obtained via nudging, a classical equation-informed data assimilation technique. At low Rayleigh numbers, PINNs are able to reconstruct with high precision, comparable to the one achieved with nudging. At high Rayleigh numbers, PINNs outperform nudging and are able to achieve satisfactory reconstruction of the velocity fields only when data for temperature is provided with high spatial and temporal density. When data becomes sparse, the PINNs performance worsens, not only in a point-to-point error sense but also, and contrary to nudging, in a statistical sense, as can be seen in the probability density functions and energy spectra.
A Picture May Be Worth a Thousand Lives: An Interpretable Artificial Intelligence Strategy for Predictions of Suicide Risk from Social Media Images
Feb 19, 2023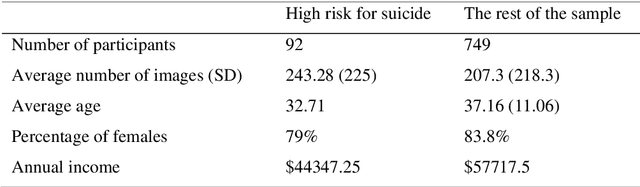
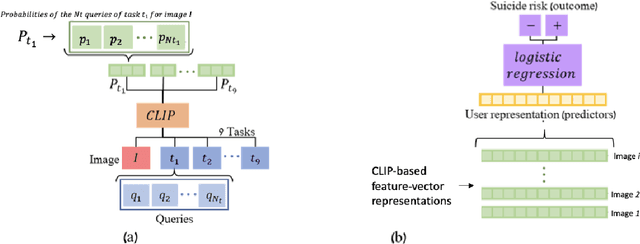
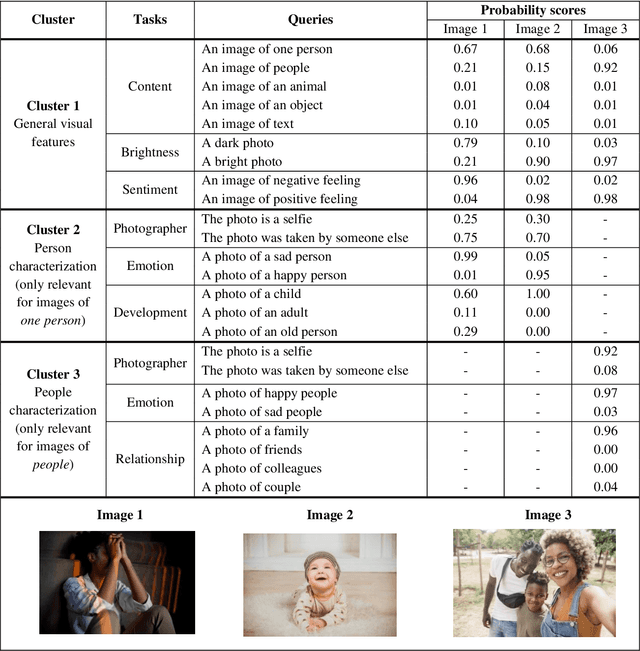

The promising research on Artificial Intelligence usages in suicide prevention has principal gaps, including black box methodologies, inadequate outcome measures, and scarce research on non-verbal inputs, such as social media images (despite their popularity today, in our digital era). This study addresses these gaps and combines theory-driven and bottom-up strategies to construct a hybrid and interpretable prediction model of valid suicide risk from images. The lead hypothesis was that images contain valuable information about emotions and interpersonal relationships, two central concepts in suicide-related treatments and theories. The dataset included 177,220 images by 841 Facebook users who completed a gold-standard suicide scale. The images were represented with CLIP, a state-of-the-art algorithm, which was utilized, unconventionally, to extract predefined features that served as inputs to a simple logistic-regression prediction model (in contrast to complex neural networks). The features addressed basic and theory-driven visual elements using everyday language (e.g., bright photo, photo of sad people). The results of the hybrid model (that integrated theory-driven and bottom-up methods) indicated high prediction performance that surpassed common bottom-up algorithms, thus providing a first proof that images (alone) can be leveraged to predict validated suicide risk. Corresponding with the lead hypothesis, at-risk users had images with increased negative emotions and decreased belonginess. The results are discussed in the context of non-verbal warning signs of suicide. Notably, the study illustrates the advantages of hybrid models in such complicated tasks and provides simple and flexible prediction strategies that could be utilized to develop real-life monitoring tools of suicide.