 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling
Feb 03, 2023
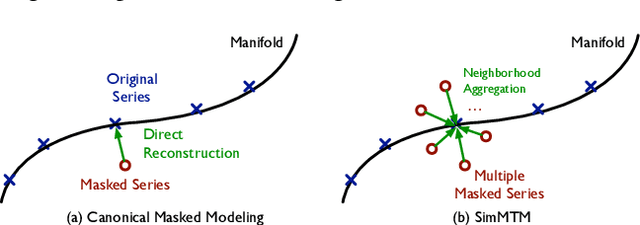
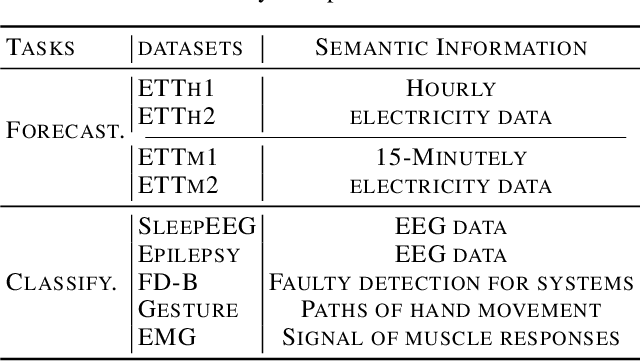
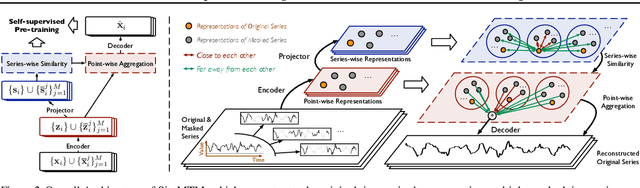
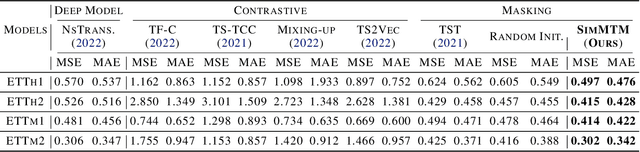
Time series analysis is widely used in extensive areas. Recently, to reduce labeling expenses and benefit various tasks, self-supervised pre-training has attracted immense interest. One mainstream paradigm is masked modeling, which successfully pre-trains deep models by learning to reconstruct the masked content based on the unmasked part. However, since the semantic information of time series is mainly contained in temporal variations, the standard way of randomly masking a portion of time points will ruin vital temporal variations of time series seriously, making the reconstruction task too difficult to guide representation learning. We thus present SimMTM, a Simple pre-training framework for Masked Time-series Modeling. By relating masked modeling to manifold learning, SimMTM proposes to recover masked time points by the weighted aggregation of multiple neighbors outside the manifold, which eases the reconstruction task by assembling ruined but complementary temporal variations from multiple masked series. SimMTM further learns to uncover the local structure of the manifold helpful for masked modeling. Experimentally, SimMTM achieves state-of-the-art fine-tuning performance in two canonical time series analysis tasks: forecasting and classification, covering both in- and cross-domain settings.
Spectral Aware Softmax for Visible-Infrared Person Re-Identification
Feb 03, 2023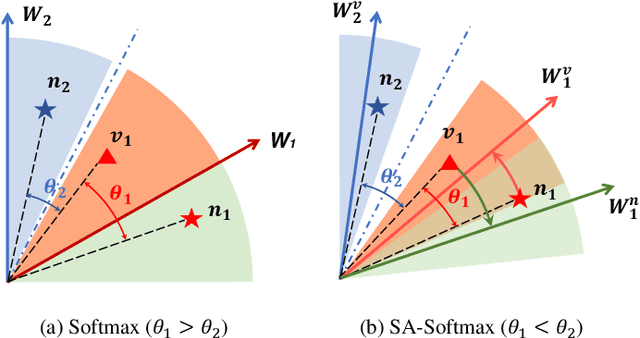
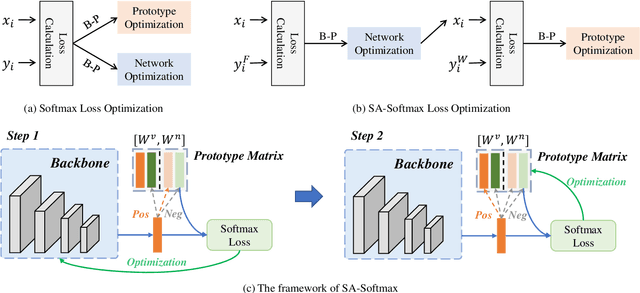
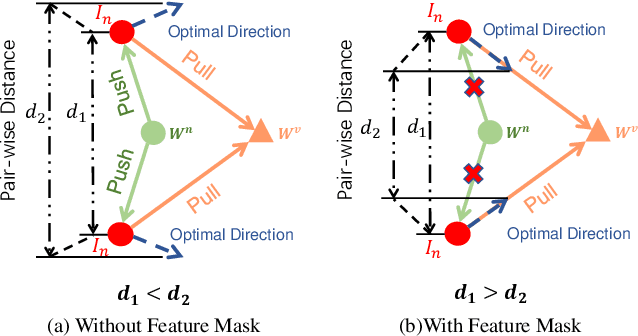
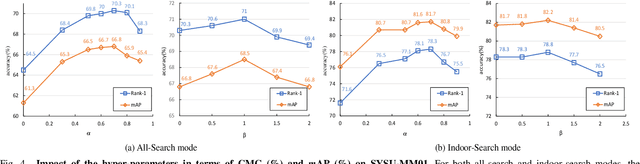
Visible-infrared person re-identification (VI-ReID) aims to match specific pedestrian images from different modalities. Although suffering an extra modality discrepancy, existing methods still follow the softmax loss training paradigm, which is widely used in single-modality classification tasks. The softmax loss lacks an explicit penalty for the apparent modality gap, which adversely limits the performance upper bound of the VI-ReID task. In this paper, we propose the spectral-aware softmax (SA-Softmax) loss, which can fully explore the embedding space with the modality information and has clear interpretability. Specifically, SA-Softmax loss utilizes an asynchronous optimization strategy based on the modality prototype instead of the synchronous optimization based on the identity prototype in the original softmax loss. To encourage a high overlapping between two modalities, SA-Softmax optimizes each sample by the prototype from another spectrum. Based on the observation and analysis of SA-Softmax, we modify the SA-Softmax with the Feature Mask and Absolute-Similarity Term to alleviate the ambiguous optimization during model training. Extensive experimental evaluations conducted on RegDB and SYSU-MM01 demonstrate the superior performance of the SA-Softmax over the state-of-the-art methods in such a cross-modality condition.
Iterative Document-level Information Extraction via Imitation Learning
Oct 12, 2022

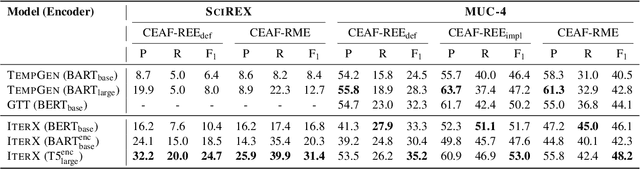
We present a novel iterative extraction (IterX) model for extracting complex relations, or templates, i.e., N-tuples representing a mapping from named slots to spans of text contained within a document. Documents may support zero or more instances of a template of any particular type, leading to the tasks of identifying the templates in a document, and extracting each template's slot values. Our imitation learning approach relieves the need to use predefined template orders to train an extractor and leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.
Guiding Online Reinforcement Learning with Action-Free Offline Pretraining
Jan 30, 2023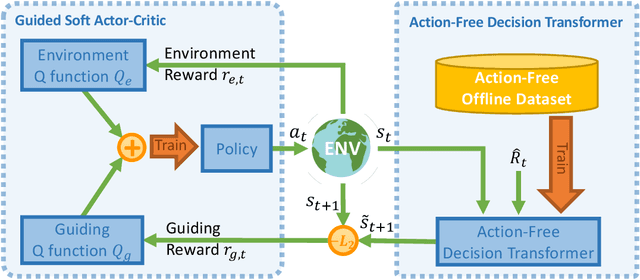

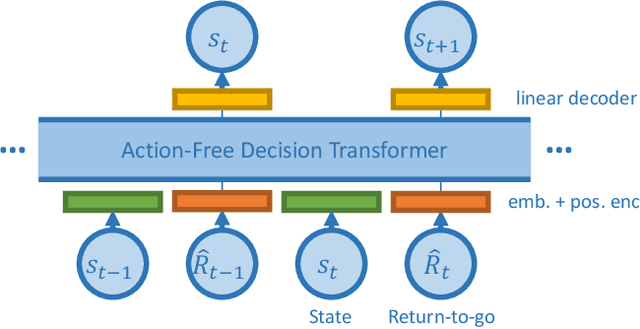
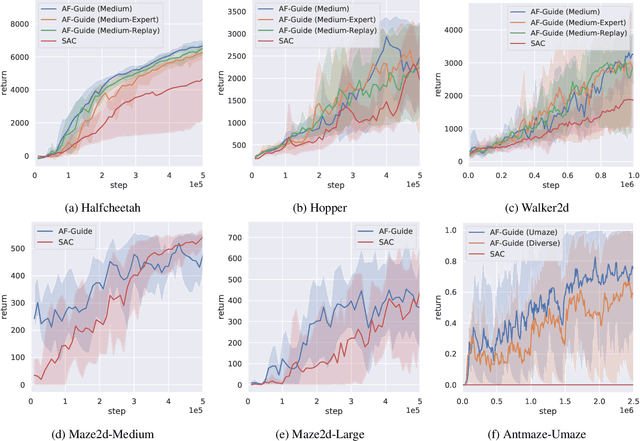
Offline RL methods have been shown to reduce the need for environment interaction by training agents using offline collected episodes. However, these methods typically require action information to be logged during data collection, which can be difficult or even impossible in some practical cases. In this paper, we investigate the potential of using action-free offline datasets to improve online reinforcement learning, name this problem Reinforcement Learning with Action-Free Offline Pretraining (AFP-RL). We introduce Action-Free Guide (AF-Guide), a method that guides online training by extracting knowledge from action-free offline datasets. AF-Guide consists of an Action-Free Decision Transformer (AFDT) implementing a variant of Upside-Down Reinforcement Learning. It learns to plan the next states from the offline dataset, and a Guided Soft Actor-Critic (Guided SAC) that learns online with guidance from AFDT. Experimental results show that AF-Guide can improve sample efficiency and performance in online training thanks to the knowledge from the action-free offline dataset.
Incomplete Multi-view Clustering via Prototype-based Imputation
Jan 30, 2023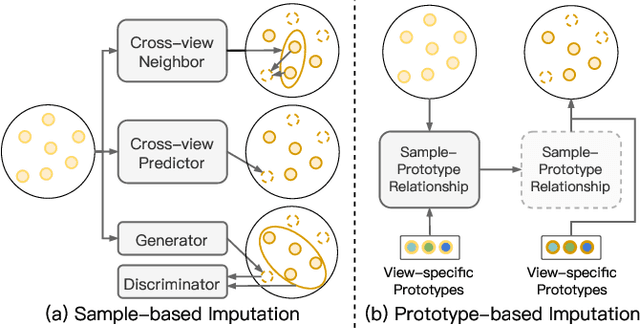
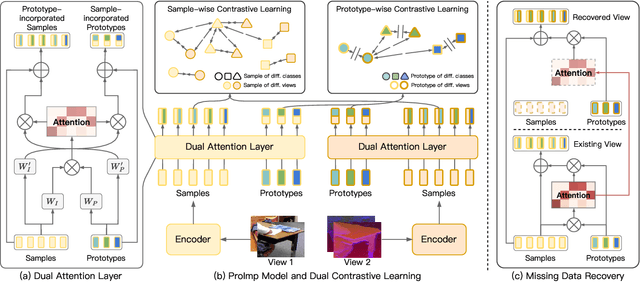
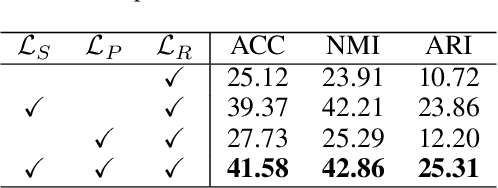
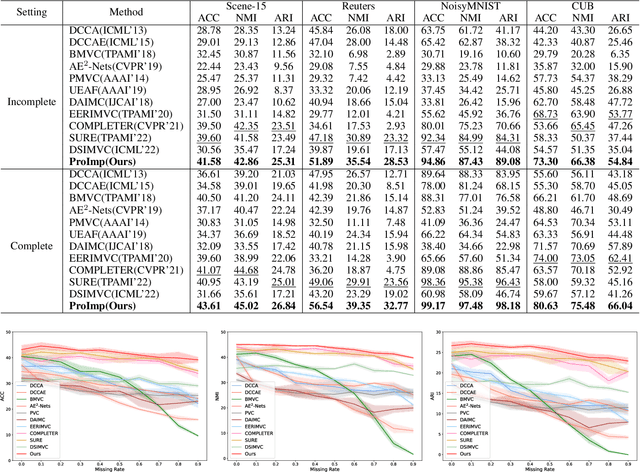
In this paper, we study how to achieve two characteristics highly-expected by incomplete multi-view clustering (IMvC). Namely, i) instance commonality refers to that within-cluster instances should share a common pattern, and ii) view versatility refers to that cross-view samples should own view-specific patterns. To this end, we design a novel dual-stream model which employs a dual attention layer and a dual contrastive learning loss to learn view-specific prototypes and model the sample-prototype relationship. When the view is missed, our model performs data recovery using the prototypes in the missing view and the sample-prototype relationship inherited from the observed view. Thanks to our dual-stream model, both cluster- and view-specific information could be captured, and thus the instance commonality and view versatility could be preserved to facilitate IMvC. Extensive experiments demonstrate the superiority of our method on six challenging benchmarks compared with 11 approaches. The code will be released.
CSDN: Combing Shallow and Deep Networks for Accurate Real-time Segmentation of High-definition Intravascular Ultrasound Images
Jan 30, 2023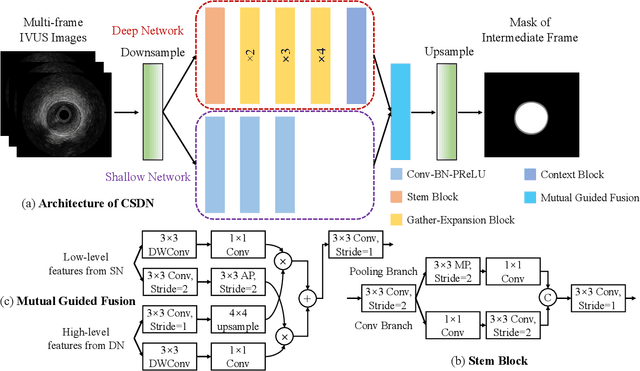
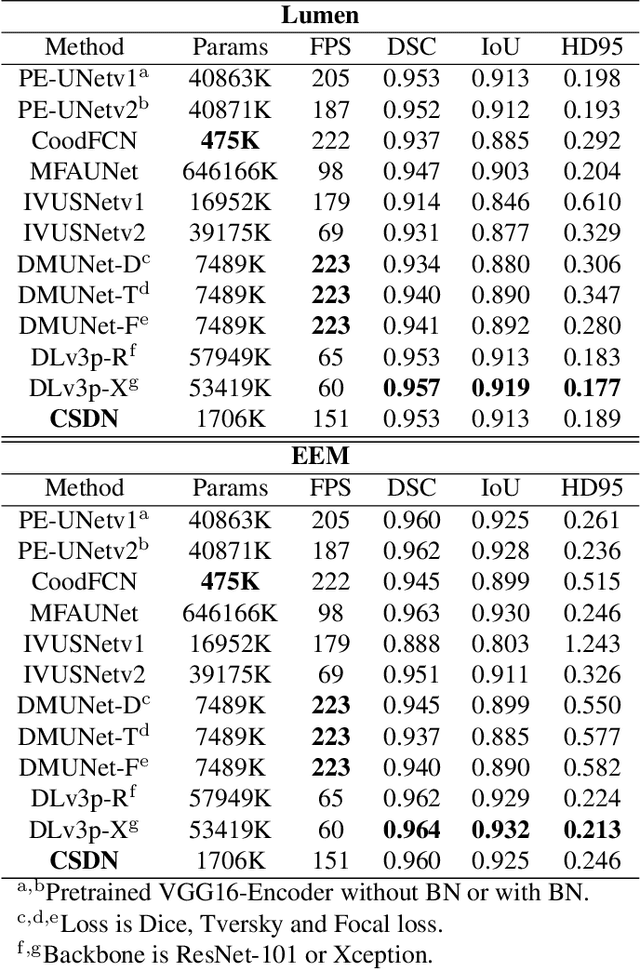

Intravascular ultrasound (IVUS) is the preferred modality for capturing real-time and high resolution cross-sectional images of the coronary arteries, and evaluating the stenosis. Accurate and real-time segmentation of IVUS images involves the delineation of lumen and external elastic membrane borders. In this paper, we propose a two-stream framework for efficient segmentation of 60 MHz high resolution IVUS images. It combines shallow and deep networks, namely, CSDN. The shallow network with thick channels focuses to extract low-level details. The deep network with thin channels takes charge of learning high-level semantics. Treating the above information separately enables learning a model to achieve high accuracy and high efficiency for accurate real-time segmentation. To further improve the segmentation performance, mutual guided fusion module is used to enhance and fuse both different types of feature representation. The experimental results show that our CSDN accomplishes a good trade-off between analysis speed and segmentation accuracy.
Equivariant Differentially Private Deep Learning
Jan 30, 2023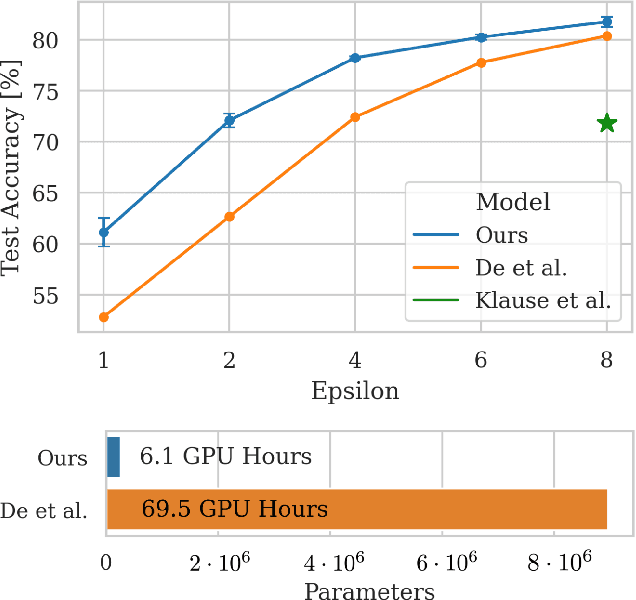
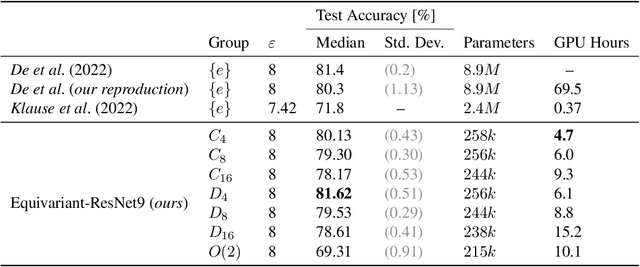
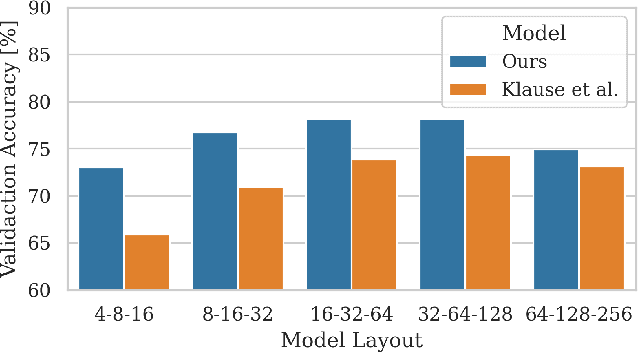

The formal privacy guarantee provided by Differential Privacy (DP) bounds the leakage of sensitive information from deep learning models. In practice, however, this comes at a severe computation and accuracy cost. The recently established state of the art (SOTA) results in image classification under DP are due to the use of heavy data augmentation and large batch sizes, leading to a drastically increased computation overhead. In this work, we propose to use more efficient models with improved feature quality by introducing steerable equivariant convolutional networks for DP training. We demonstrate that our models are able to outperform the current SOTA performance on CIFAR-10 by up to $9\%$ across different $\varepsilon$-values while reducing the number of model parameters by a factor of $35$ and decreasing the computation time by more than $90 \%$. Our results are a large step towards efficient model architectures that make optimal use of their parameters and bridge the privacy-utility gap between private and non-private deep learning for computer vision.
Gossiped and Quantized Online Multi-Kernel Learning
Jan 24, 2023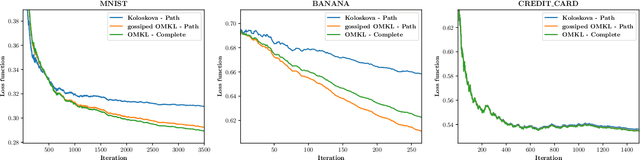
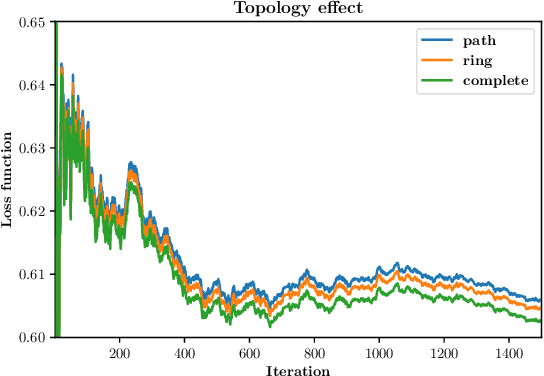
In instances of online kernel learning where little prior information is available and centralized learning is unfeasible, past research has shown that distributed and online multi-kernel learning provides sub-linear regret as long as every pair of nodes in the network can communicate (i.e., the communications network is a complete graph). In addition, to manage the communication load, which is often a performance bottleneck, communications between nodes can be quantized. This letter expands on these results to non-fully connected graphs, which is often the case in wireless sensor networks. To address this challenge, we propose a gossip algorithm and provide a proof that it achieves sub-linear regret. Experiments with real datasets confirm our findings.
Learning Choice Functions with Gaussian Processes
Feb 01, 2023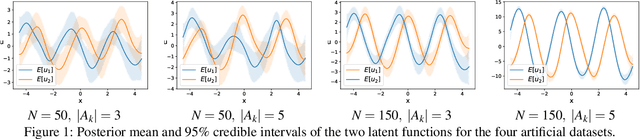

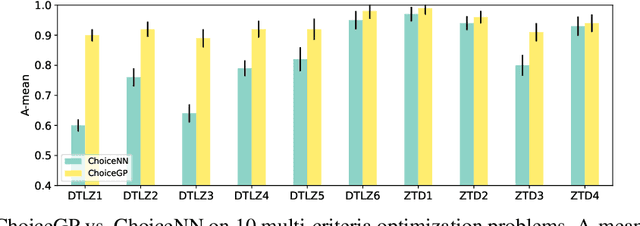
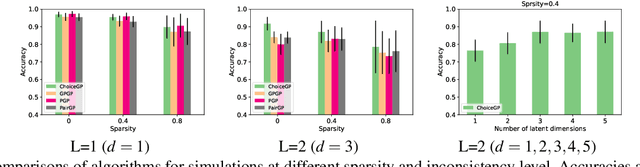
In consumer theory, ranking available objects by means of preference relations yields the most common description of individual choices. However, preference-based models assume that individuals: (1) give their preferences only between pairs of objects; (2) are always able to pick the best preferred object. In many situations, they may be instead choosing out of a set with more than two elements and, because of lack of information and/or incomparability (objects with contradictory characteristics), they may not able to select a single most preferred object. To address these situations, we need a choice-model which allows an individual to express a set-valued choice. Choice functions provide such a mathematical framework. We propose a Gaussian Process model to learn choice functions from choice-data. The proposed model assumes a multiple utility representation of a choice function based on the concept of Pareto rationalization, and derives a strategy to learn both the number and the values of these latent multiple utilities. Simulation experiments demonstrate that the proposed model outperforms the state-of-the-art methods.
Variational Autoencoder Learns Better Feature Representations for EEG-based Obesity Classification
Feb 01, 2023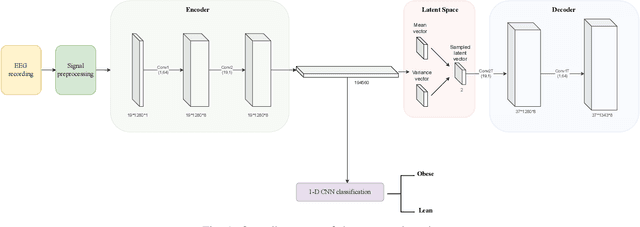
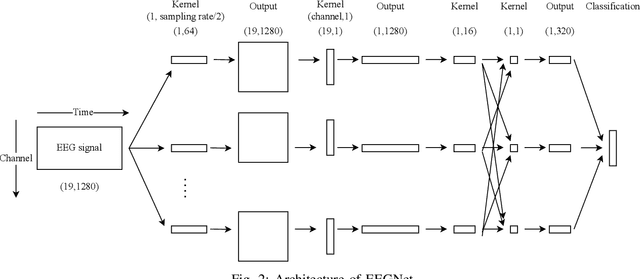
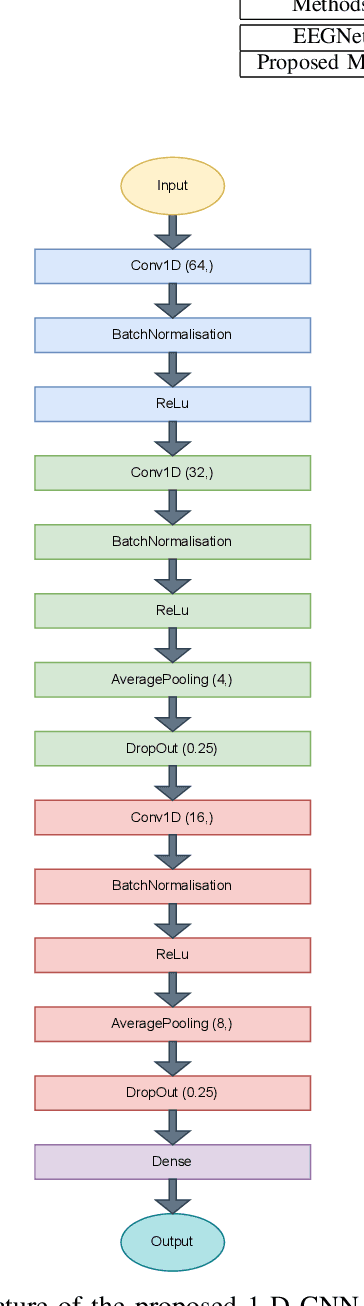
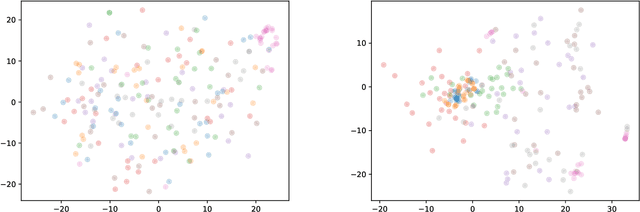
Obesity is a common issue in modern societies today that can lead to various diseases and significantly reduced quality of life. Currently, research has been conducted to investigate resting state EEG (electroencephalogram) signals with an aim to identify possible neurological characteristics associated with obesity. In this study, we propose a deep learning-based framework to extract the resting state EEG features for obese and lean subject classification. Specifically, a novel variational autoencoder framework is employed to extract subject-invariant features from the raw EEG signals, which are then classified by a 1-D convolutional neural network. Comparing with conventional machine learning and deep learning methods, we demonstrate the superiority of using VAE for feature extraction, as reflected by the significantly improved classification accuracies, better visualizations and reduced impurity measures in the feature representations. Future work can be directed to gaining an in-depth understanding regarding the spatial patterns that have been learned by the proposed model from a neurological view, as well as improving the interpretability of the proposed model by allowing it to uncover any temporal-related information.