 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Faster Convergence with Lexicase Selection in Tree-based Automated Machine Learning
Feb 01, 2023
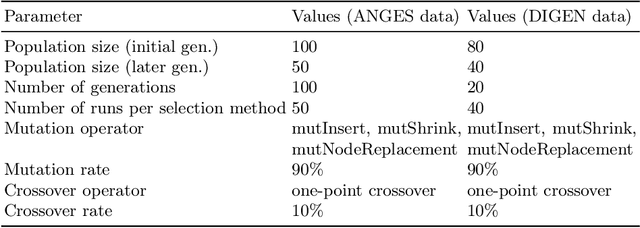
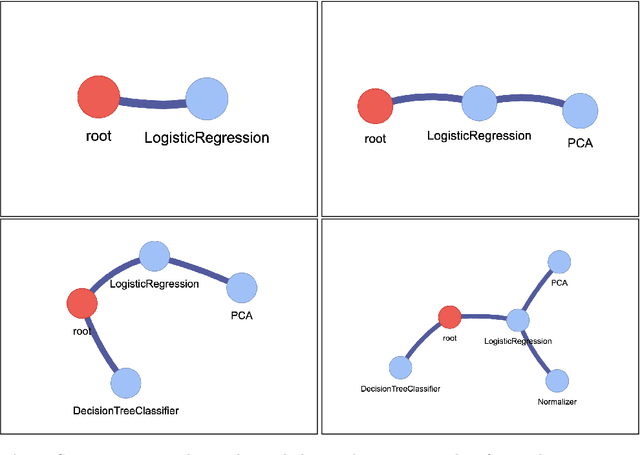
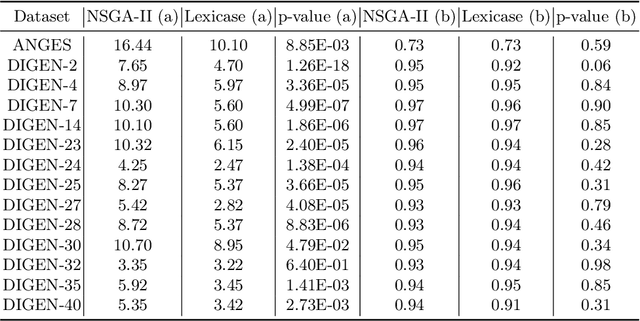
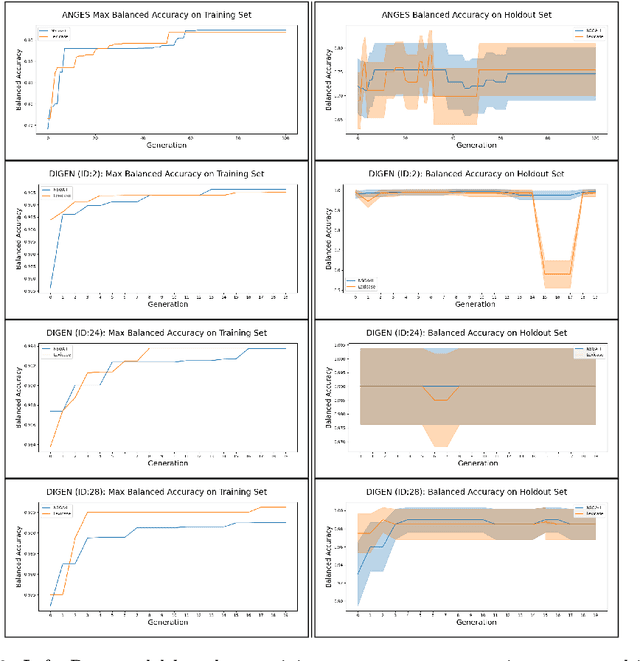
In many evolutionary computation systems, parent selection methods can affect, among other things, convergence to a solution. In this paper, we present a study comparing the role of two commonly used parent selection methods in evolving machine learning pipelines in an automated machine learning system called Tree-based Pipeline Optimization Tool (TPOT). Specifically, we demonstrate, using experiments on multiple datasets, that lexicase selection leads to significantly faster convergence as compared to NSGA-II in TPOT. We also compare the exploration of parts of the search space by these selection methods using a trie data structure that contains information about the pipelines explored in a particular run.
Machine Learning for Visualization Recommendation Systems: Open Challenges and Future Directions
Feb 01, 2023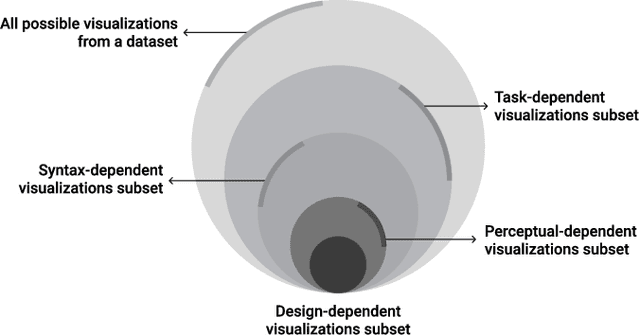

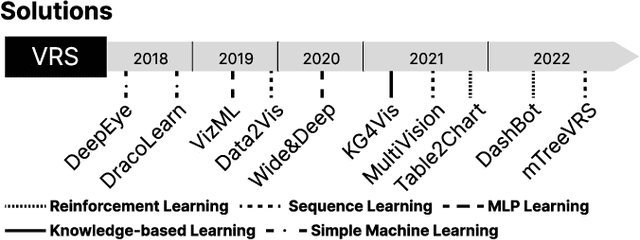
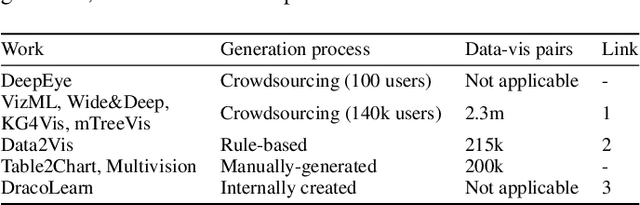
Visualization Recommendation Systems (VRS) are a novel and challenging field of study, whose aim is to automatically generate insightful visualizations from data, to support non-expert users in the process of information discovery. Despite its enormous application potential in the era of big data, progress in this area of research is being held back by several obstacles among which are the absence of standardized datasets to train recommendation algorithms, and the difficulty in defining quantitative criteria to assess the effectiveness of the generated plots. In this paper, we aim not only to summarize the state-of-the-art of VRS, but also to outline promising future research directions.
Efficient Classification of SARS-CoV-2 Spike Sequences Using Federated Learning
Feb 17, 2023
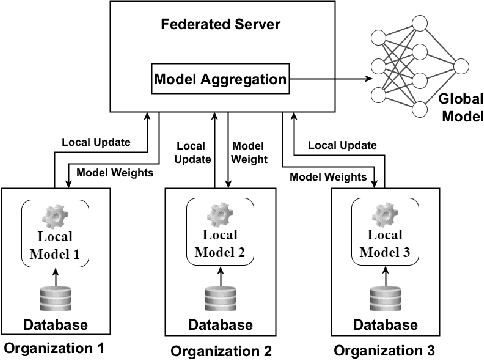
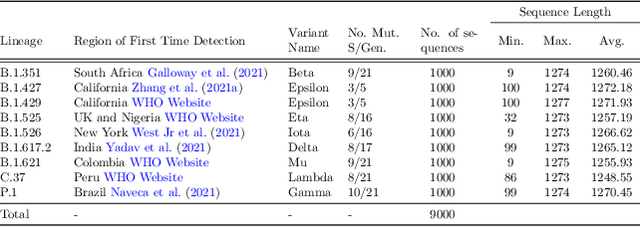
This paper presents a federated learning (FL) approach to train an AI model for SARS-Cov-2 coronavirus variant identification. We analyze the SARS-CoV-2 spike sequences in a distributed way, without data sharing, to detect different variants of the rapidly mutating coronavirus. A vast amount of sequencing data of SARS-CoV-2 is available due to various genomic monitoring initiatives by several nations. However, privacy concerns involving patient health information and national public health conditions could hinder openly sharing this data. In this work, we propose a lightweight FL paradigm to cooperatively analyze the spike protein sequences of SARS-CoV-2 privately, using the locally stored data to train a prediction model from remote nodes. Our method maintains the confidentiality of local data (that could be stored in different locations) yet allows us to reliably detect and identify different known and unknown variants of the novel coronavirus SARS-CoV-2. We compare the performance of our approach on spike sequence data with the recently proposed state-of-the-art methods for classification from spike sequences. Using the proposed approach, we achieve an overall accuracy of $93\%$ on the coronavirus variant identification task. To the best of our knowledge, this is the first work in the federated learning paradigm for biological sequence analysis. Since the proposed model is distributed in nature, it could scale on ``Big Data'' easily. We plan to use this proof-of-concept to implement a privacy-preserving pandemic response strategy.
Cross-Domain Label Propagation for Domain Adaptation with Discriminative Graph Self-Learning
Feb 17, 2023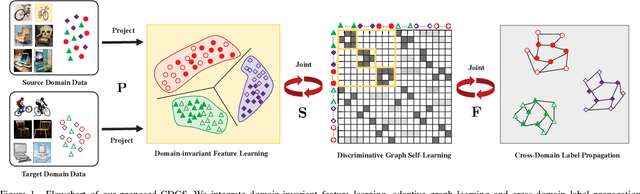

Domain adaptation manages to transfer the knowledge of well-labeled source data to unlabeled target data. Many recent efforts focus on improving the prediction accuracy of target pseudo-labels to reduce conditional distribution shift. In this paper, we propose a novel domain adaptation method, which infers target pseudo-labels through cross-domain label propagation, such that the underlying manifold structure of two domain data can be explored. Unlike existing cross-domain label propagation methods that separate domain-invariant feature learning, affinity matrix constructing and target labels inferring into three independent stages, we propose to integrate them into a unified optimization framework. In such way, these three parts can boost each other from an iterative optimization perspective and thus more effective knowledge transfer can be achieved. Furthermore, to construct a high-quality affinity matrix, we propose a discriminative graph self-learning strategy, which can not only adaptively capture the inherent similarity of the data from two domains but also effectively exploit the discriminative information contained in well-labeled source data and pseudo-labeled target data. An efficient iterative optimization algorithm is designed to solve the objective function of our proposal. Notably, the proposed method can be extended to semi-supervised domain adaptation in a simple but effective way and the corresponding optimization problem can be solved with the identical algorithm. Extensive experiments on six standard datasets verify the significant superiority of our proposal in both unsupervised and semi-supervised domain adaptation settings.
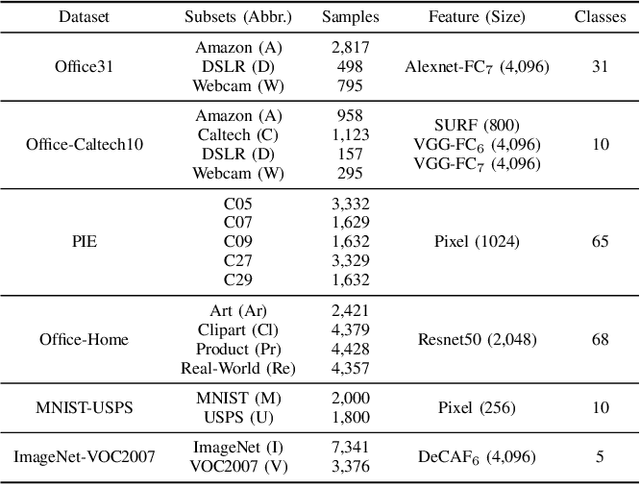
Multimodal Federated Learning via Contrastive Representation Ensemble
Feb 17, 2023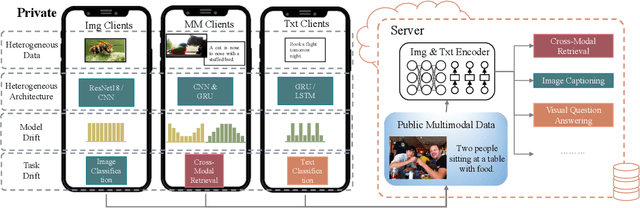
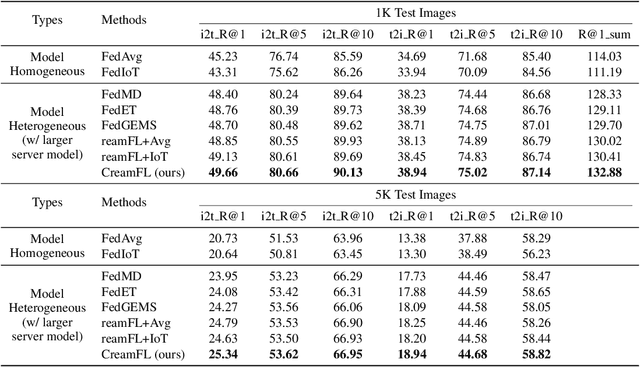
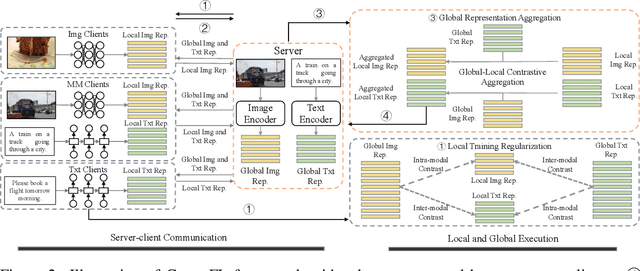
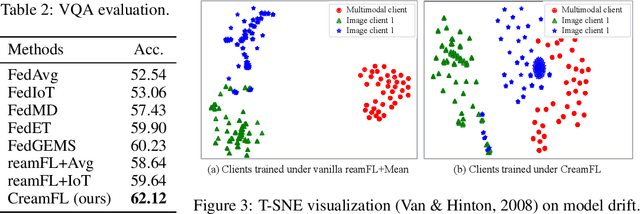
With the increasing amount of multimedia data on modern mobile systems and IoT infrastructures, harnessing these rich multimodal data without breaching user privacy becomes a critical issue. Federated learning (FL) serves as a privacy-conscious alternative to centralized machine learning. However, existing FL methods extended to multimodal data all rely on model aggregation on single modality level, which restrains the server and clients to have identical model architecture for each modality. This limits the global model in terms of both model complexity and data capacity, not to mention task diversity. In this work, we propose Contrastive Representation Ensemble and Aggregation for Multimodal FL (CreamFL), a multimodal federated learning framework that enables training larger server models from clients with heterogeneous model architectures and data modalities, while only communicating knowledge on public dataset. To achieve better multimodal representation fusion, we design a global-local cross-modal ensemble strategy to aggregate client representations. To mitigate local model drift caused by two unprecedented heterogeneous factors stemming from multimodal discrepancy (modality gap and task gap), we further propose two inter-modal and intra-modal contrasts to regularize local training, which complements information of the absent modality for uni-modal clients and regularizes local clients to head towards global consensus. Thorough evaluations and ablation studies on image-text retrieval and visual question answering tasks showcase the superiority of CreamFL over state-of-the-art FL methods and its practical value.
Dynamic Training of Liquid State Machines
Feb 06, 2023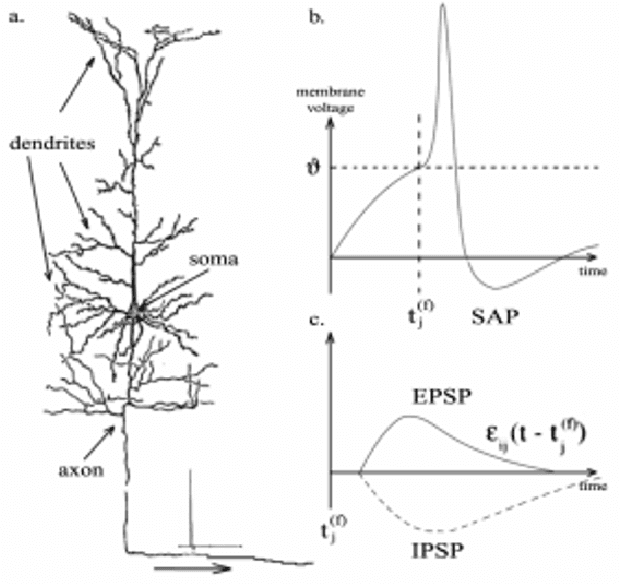
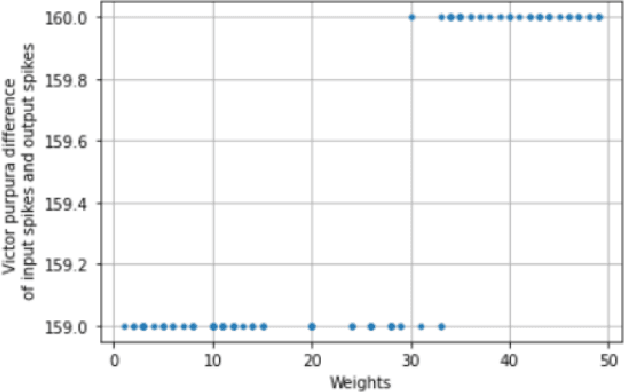
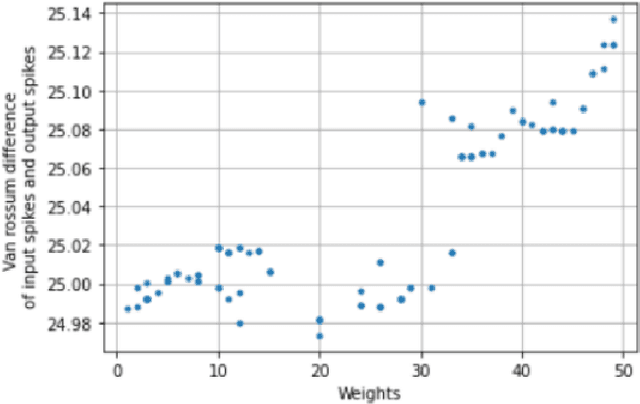
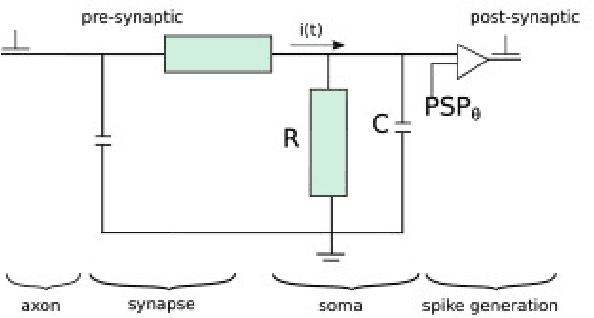
Spiking Neural Networks (SNNs) emerged as a promising solution in the field of Artificial Neural Networks (ANNs), attracting the attention of researchers due to their ability to mimic the human brain and process complex information with remarkable speed and accuracy. This research aimed to optimise the training process of Liquid State Machines (LSMs), a recurrent architecture of SNNs, by identifying the most effective weight range to be assigned in SNN to achieve the least difference between desired and actual output. The experimental results showed that by using spike metrics and a range of weights, the desired output and the actual output of spiking neurons could be effectively optimised, leading to improved performance of SNNs. The results were tested and confirmed using three different weight initialisation approaches, with the best results obtained using the Barabasi-Albert random graph method.
Bottlenecks CLUB: Unifying Information-Theoretic Trade-offs Among Complexity, Leakage, and Utility
Jul 11, 2022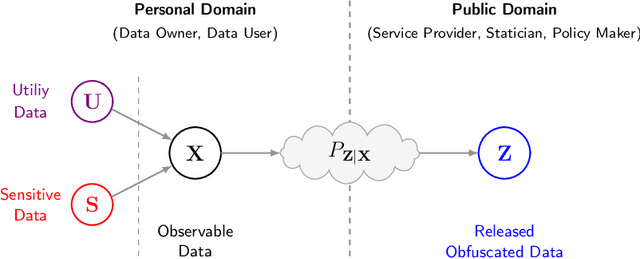
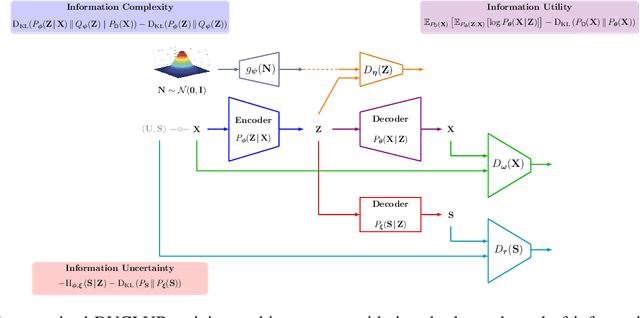
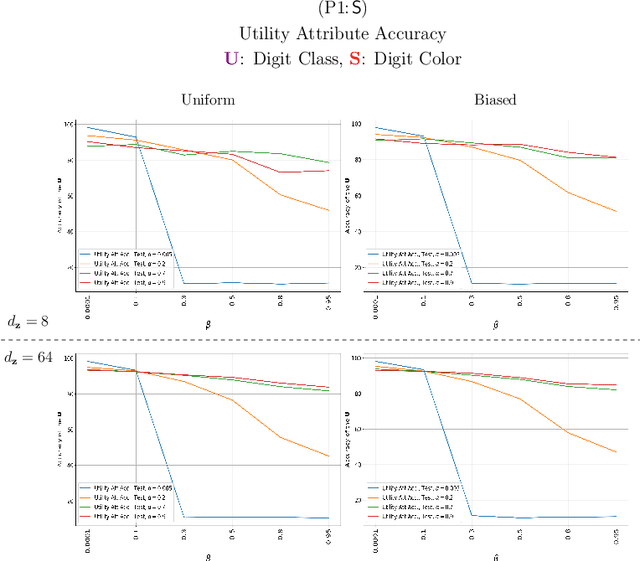
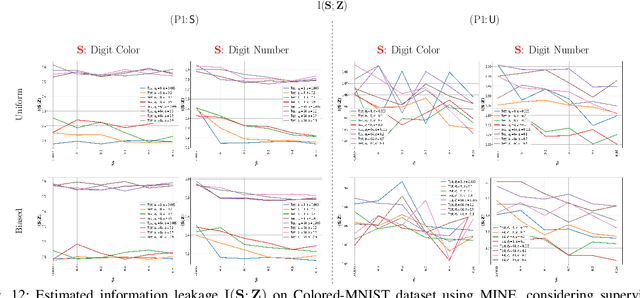
Bottleneck problems are an important class of optimization problems that have recently gained increasing attention in the domain of machine learning and information theory. They are widely used in generative models, fair machine learning algorithms, design of privacy-assuring mechanisms, and appear as information-theoretic performance bounds in various multi-user communication problems. In this work, we propose a general family of optimization problems, termed as complexity-leakage-utility bottleneck (CLUB) model, which (i) provides a unified theoretical framework that generalizes most of the state-of-the-art literature for the information-theoretic privacy models, (ii) establishes a new interpretation of the popular generative and discriminative models, (iii) constructs new insights to the generative compression models, and (iv) can be used in the fair generative models. We first formulate the CLUB model as a complexity-constrained privacy-utility optimization problem. We then connect it with the closely related bottleneck problems, namely information bottleneck (IB), privacy funnel (PF), deterministic IB (DIB), conditional entropy bottleneck (CEB), and conditional PF (CPF). We show that the CLUB model generalizes all these problems as well as most other information-theoretic privacy models. Then, we construct the deep variational CLUB (DVCLUB) models by employing neural networks to parameterize variational approximations of the associated information quantities. Building upon these information quantities, we present unified objectives of the supervised and unsupervised DVCLUB models. Leveraging the DVCLUB model in an unsupervised setup, we then connect it with state-of-the-art generative models, such as variational auto-encoders (VAEs), generative adversarial networks (GANs), as well as the Wasserstein GAN (WGAN), Wasserstein auto-encoder (WAE), and adversarial auto-encoder (AAE) models through the optimal transport (OT) problem. We then show that the DVCLUB model can also be used in fair representation learning problems, where the goal is to mitigate the undesired bias during the training phase of a machine learning model. We conduct extensive quantitative experiments on colored-MNIST and CelebA datasets, with a public implementation available, to evaluate and analyze the CLUB model.
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
Feb 12, 2023
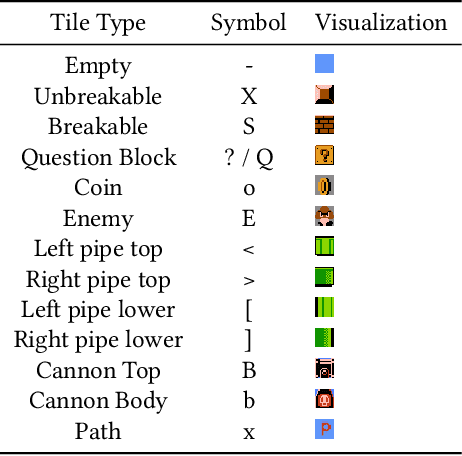
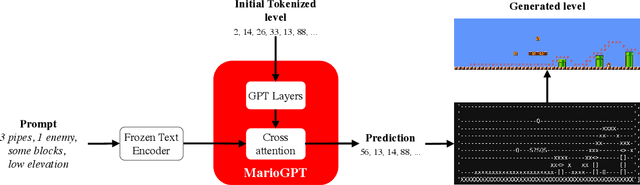

Procedural Content Generation (PCG) algorithms provide a technique to generate complex and diverse environments in an automated way. However, while generating content with PCG methods is often straightforward, generating meaningful content that reflects specific intentions and constraints remains challenging. Furthermore, many PCG algorithms lack the ability to generate content in an open-ended manner. Recently, Large Language Models (LLMs) have shown to be incredibly effective in many diverse domains. These trained LLMs can be fine-tuned, re-using information and accelerating training for new tasks. In this work, we introduce MarioGPT, a fine-tuned GPT2 model trained to generate tile-based game levels, in our case Super Mario Bros levels. We show that MarioGPT can not only generate diverse levels, but can be text-prompted for controllable level generation, addressing one of the key challenges of current PCG techniques. As far as we know, MarioGPT is the first text-to-level model. We also combine MarioGPT with novelty search, enabling it to generate diverse levels with varying play-style dynamics (i.e. player paths). This combination allows for the open-ended generation of an increasingly diverse range of content.
Diagnosing and Rectifying Vision Models using Language
Feb 08, 2023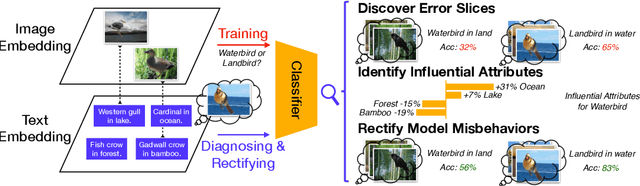

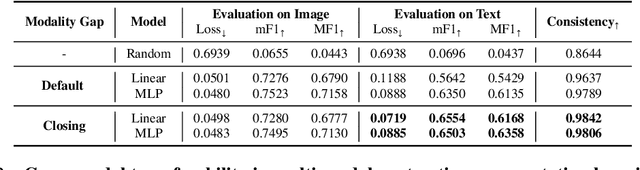
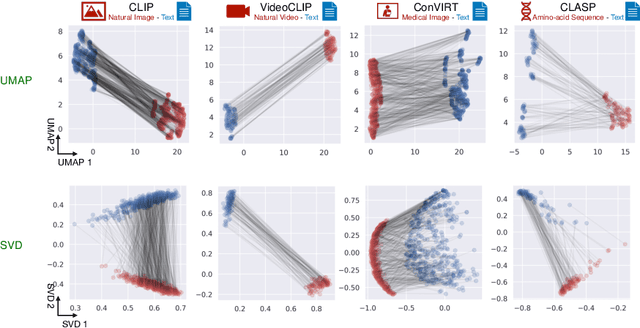
Recent multi-modal contrastive learning models have demonstrated the ability to learn an embedding space suitable for building strong vision classifiers, by leveraging the rich information in large-scale image-caption datasets. Our work highlights a distinct advantage of this multi-modal embedding space: the ability to diagnose vision classifiers through natural language. The traditional process of diagnosing model behaviors in deployment settings involves labor-intensive data acquisition and annotation. Our proposed method can discover high-error data slices, identify influential attributes and further rectify undesirable model behaviors, without requiring any visual data. Through a combination of theoretical explanation and empirical verification, we present conditions under which classifiers trained on embeddings from one modality can be equivalently applied to embeddings from another modality. On a range of image datasets with known error slices, we demonstrate that our method can effectively identify the error slices and influential attributes, and can further use language to rectify failure modes of the classifier.
Hyperspectral Image Compression Using Implicit Neural Representation
Feb 08, 2023
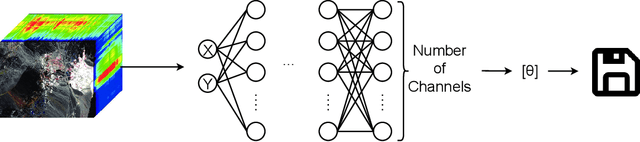

Hyperspectral images, which record the electromagnetic spectrum for a pixel in the image of a scene, often store hundreds of channels per pixel and contain an order of magnitude more information than a typical similarly-sized color image. Consequently, concomitant with the decreasing cost of capturing these images, there is a need to develop efficient techniques for storing, transmitting, and analyzing hyperspectral images. This paper develops a method for hyperspectral image compression using implicit neural representations where a multilayer perceptron network $\Phi_\theta$ with sinusoidal activation functions ``learns'' to map pixel locations to pixel intensities for a given hyperspectral image $I$. $\Phi_\theta$ thus acts as a compressed encoding of this image. The original image is reconstructed by evaluating $\Phi_\theta$ at each pixel location. We have evaluated our method on four benchmarks -- Indian Pines, Cuprite, Pavia University, and Jasper Ridge -- and we show the proposed method achieves better compression than JPEG, JPEG2000, PCA-DCT, and HVEC at low bitrates.