 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pixel Relationships-based Regularizer for Retinal Vessel Image Segmentation
Dec 28, 2022
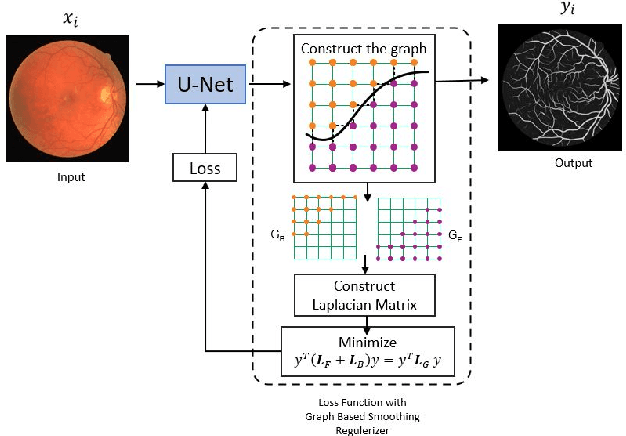
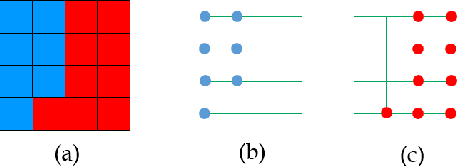
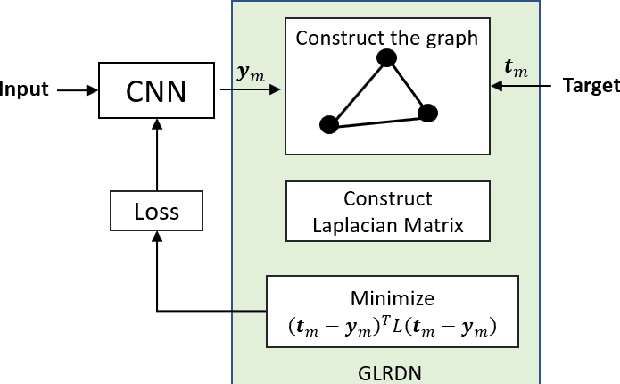
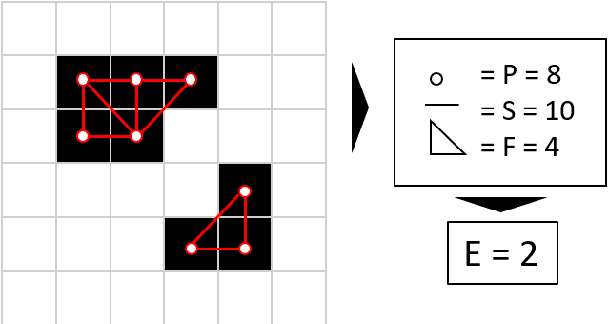
The task of image segmentation is to classify each pixel in the image based on the appropriate label. Various deep learning approaches have been proposed for image segmentation that offers high accuracy and deep architecture. However, the deep learning technique uses a pixel-wise loss function for the training process. Using pixel-wise loss neglected the pixel neighbor relationships in the network learning process. The neighboring relationship of the pixels is essential information in the image. Utilizing neighboring pixel information provides an advantage over using only pixel-to-pixel information. This study presents regularizers to give the pixel neighbor relationship information to the learning process. The regularizers are constructed by the graph theory approach and topology approach: By graph theory approach, graph Laplacian is used to utilize the smoothness of segmented images based on output images and ground-truth images. By topology approach, Euler characteristic is used to identify and minimize the number of isolated objects on segmented images. Experiments show that our scheme successfully captures pixel neighbor relations and improves the performance of the convolutional neural network better than the baseline without a regularization term.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023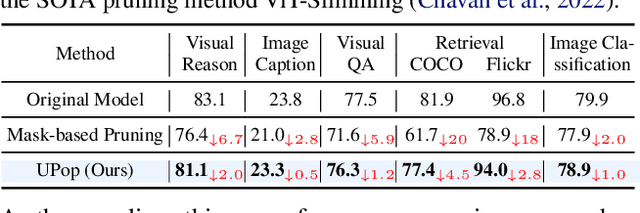
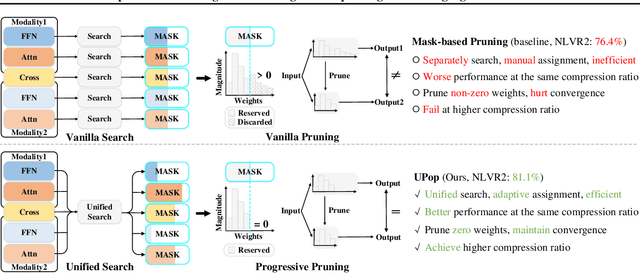

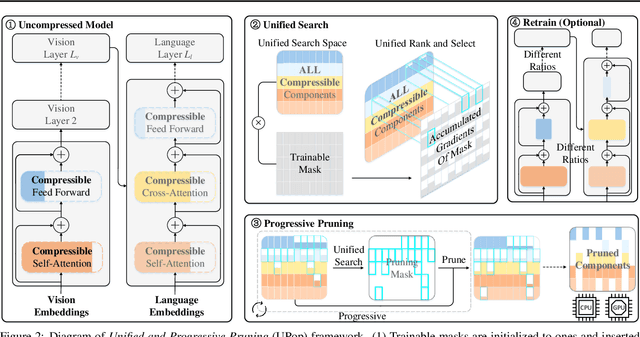
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
CSDR-BERT: a pre-trained scientific dataset match model for Chinese Scientific Dataset Retrieval
Jan 31, 2023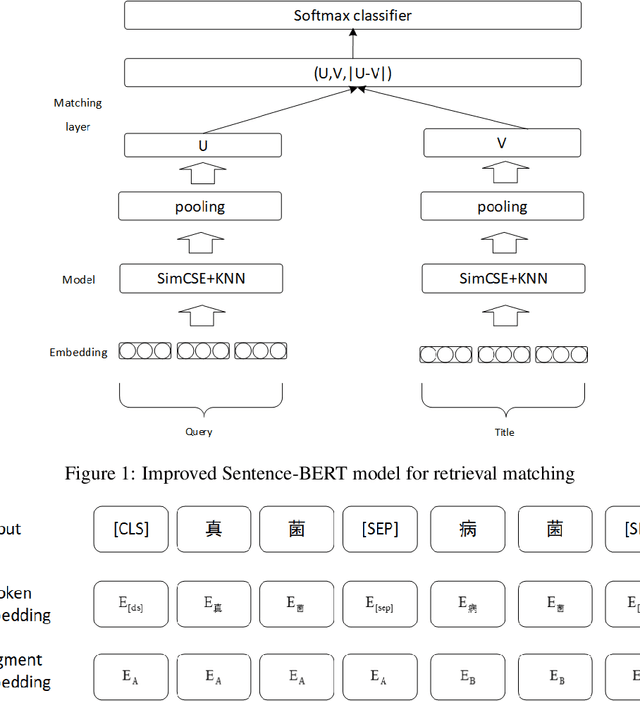

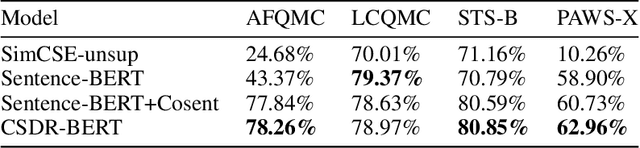
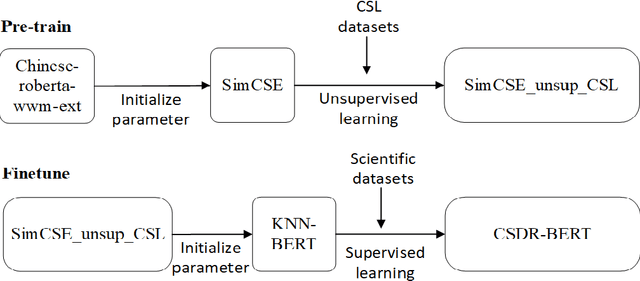
As the number of open and shared scientific datasets on the Internet increases under the open science movement, efficiently retrieving these datasets is a crucial task in information retrieval (IR) research. In recent years, the development of large models, particularly the pre-training and fine-tuning paradigm, which involves pre-training on large models and fine-tuning on downstream tasks, has provided new solutions for IR match tasks. In this study, we use the original BERT token in the embedding layer, improve the Sentence-BERT model structure in the model layer by introducing the SimCSE and K-Nearest Neighbors method, and use the cosent loss function in the optimization phase to optimize the target output. Our experimental results show that our model outperforms other competing models on both public and self-built datasets through comparative experiments and ablation implementations. This study explores and validates the feasibility and efficiency of pre-training techniques for semantic retrieval of Chinese scientific datasets.
Federated Temporal Difference Learning with Linear Function Approximation under Environmental Heterogeneity
Feb 04, 2023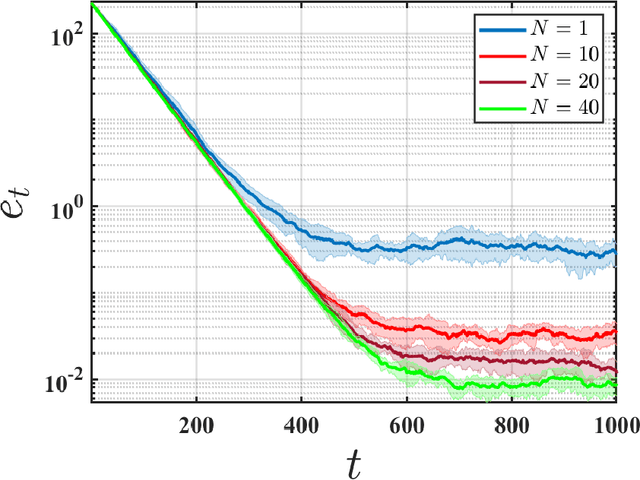
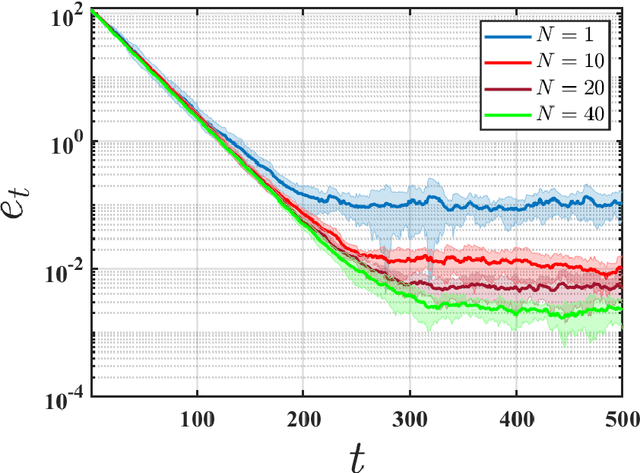
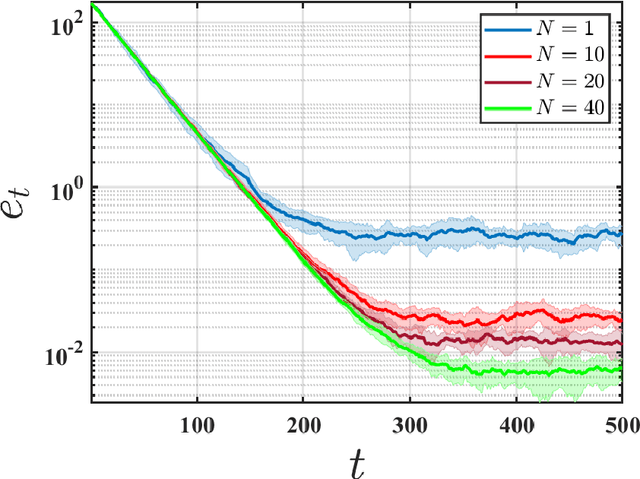
We initiate the study of federated reinforcement learning under environmental heterogeneity by considering a policy evaluation problem. Our setup involves $N$ agents interacting with environments that share the same state and action space but differ in their reward functions and state transition kernels. Assuming agents can communicate via a central server, we ask: Does exchanging information expedite the process of evaluating a common policy? To answer this question, we provide the first comprehensive finite-time analysis of a federated temporal difference (TD) learning algorithm with linear function approximation, while accounting for Markovian sampling, heterogeneity in the agents' environments, and multiple local updates to save communication. Our analysis crucially relies on several novel ingredients: (i) deriving perturbation bounds on TD fixed points as a function of the heterogeneity in the agents' underlying Markov decision processes (MDPs); (ii) introducing a virtual MDP to closely approximate the dynamics of the federated TD algorithm; and (iii) using the virtual MDP to make explicit connections to federated optimization. Putting these pieces together, we rigorously prove that in a low-heterogeneity regime, exchanging model estimates leads to linear convergence speedups in the number of agents.
MessageNet: Message Classification using Natural Language Processing and Meta-data
Jan 04, 2023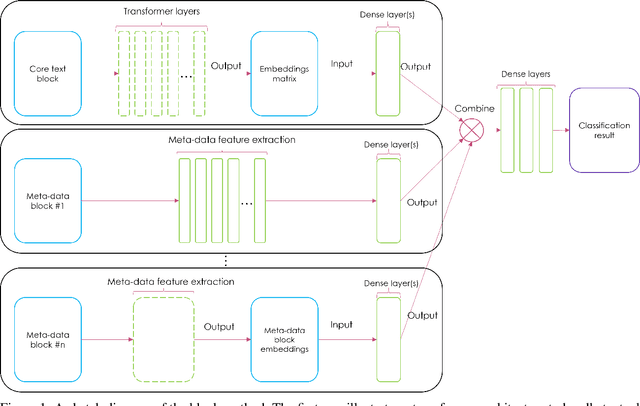
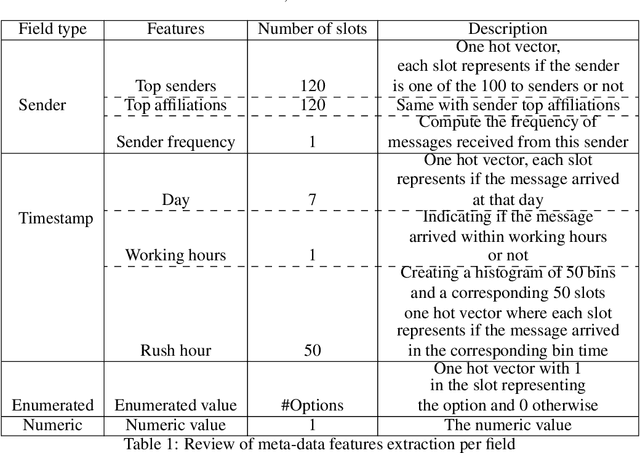
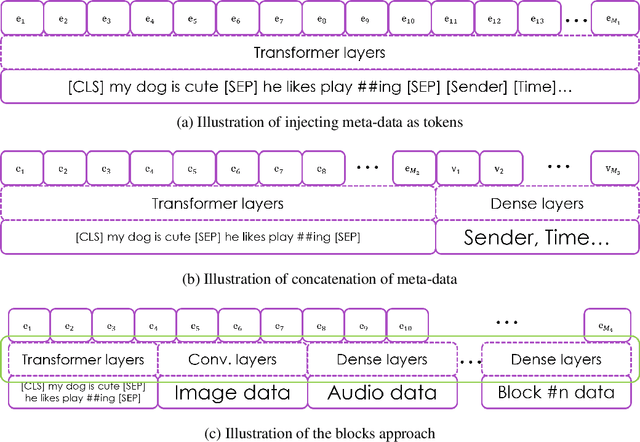
In this paper we propose a new Deep Learning (DL) approach for message classification. Our method is based on the state-of-the-art Natural Language Processing (NLP) building blocks, combined with a novel technique for infusing the meta-data input that is typically available in messages such as the sender information, timestamps, attached image, audio, affiliations, and more. As we demonstrate throughout the paper, going beyond the mere text by leveraging all available channels in the message, could yield an improved representation and higher classification accuracy. To achieve message representation, each type of input is processed in a dedicated block in the neural network architecture that is suitable for the data type. Such an implementation enables training all blocks together simultaneously, and forming cross channels features in the network. We show in the Experiments Section that in some cases, message's meta-data holds an additional information that cannot be extracted just from the text, and when using this information we achieve better performance. Furthermore, we demonstrate that our multi-modality block approach outperforms other approaches for injecting the meta data to the the text classifier.
Towards Human-Agent Communication via the Information Bottleneck Principle
Jun 30, 2022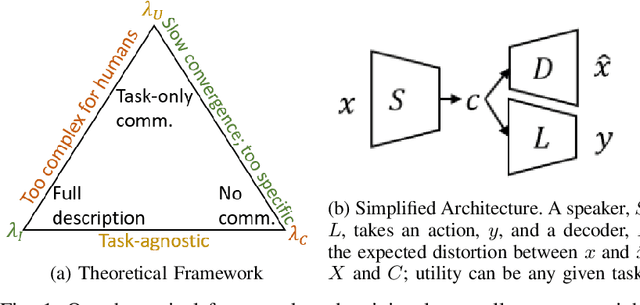
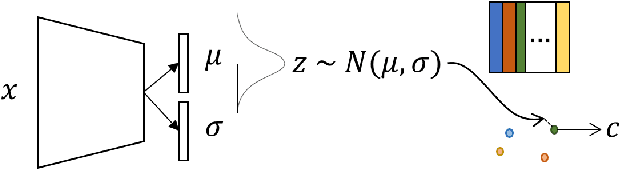
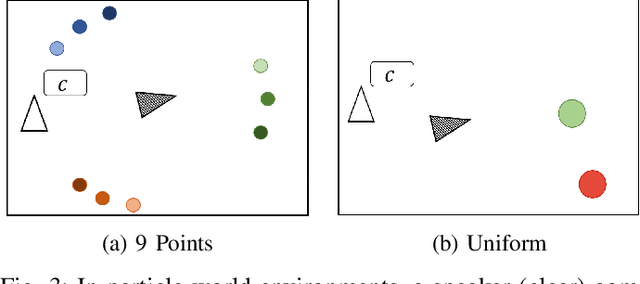

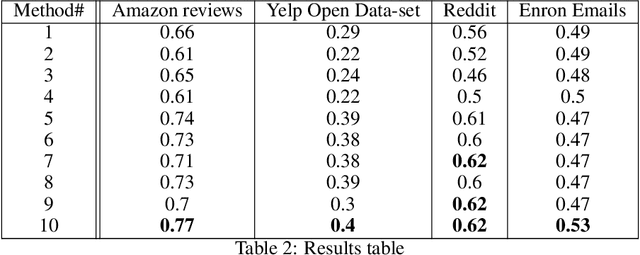
Emergent communication research often focuses on optimizing task-specific utility as a driver for communication. However, human languages appear to evolve under pressure to efficiently compress meanings into communication signals by optimizing the Information Bottleneck tradeoff between informativeness and complexity. In this work, we study how trading off these three factors -- utility, informativeness, and complexity -- shapes emergent communication, including compared to human communication. To this end, we propose Vector-Quantized Variational Information Bottleneck (VQ-VIB), a method for training neural agents to compress inputs into discrete signals embedded in a continuous space. We train agents via VQ-VIB and compare their performance to previously proposed neural architectures in grounded environments and in a Lewis reference game. Across all neural architectures and settings, taking into account communicative informativeness benefits communication convergence rates, and penalizing communicative complexity leads to human-like lexicon sizes while maintaining high utility. Additionally, we find that VQ-VIB outperforms other discrete communication methods. This work demonstrates how fundamental principles that are believed to characterize human language evolution may inform emergent communication in artificial agents.
Generating Templated Caption for Video Grounding
Jan 15, 2023
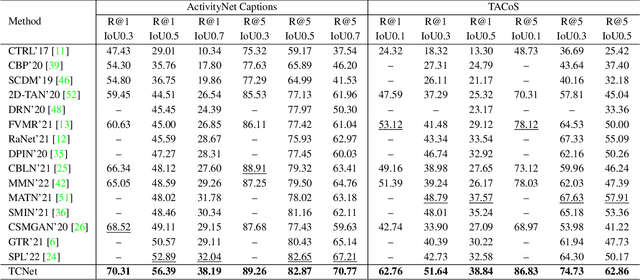
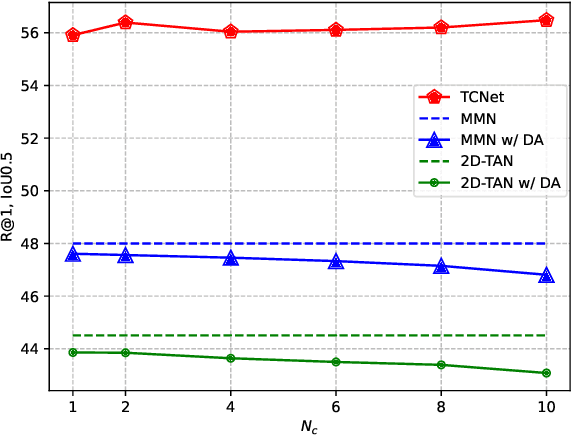
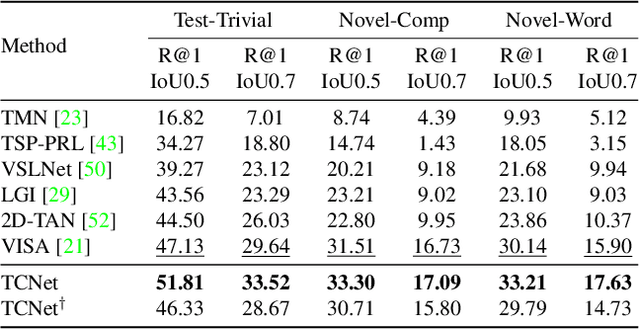
Video grounding aims to locate a moment of interest matching the given query sentence from an untrimmed video. Previous works ignore the \emph{sparsity dilemma} in video annotations, which fails to provide the context information between potential events and query sentences in the dataset. In this paper, we contend that providing easily available captions which describe general actions \ie, templated captions defined in our paper, will significantly boost the performance. To this end, we propose a Templated Caption Network (TCNet) for video grounding. Specifically, we first introduce dense video captioning to generate dense captions, and then obtain templated captions by Non-Templated Caption Suppression (NTCS). To utilize templated captions better, we propose Caption Guided Attention (CGA) project the semantic relations between templated captions and query sentences into temporal space and fuse them into visual representations. Considering the gap between templated captions and ground truth, we propose Asymmetric Dual Matching Supervised Contrastive Learning (ADMSCL) for constructing more negative pairs to maximize cross-modal mutual information. Without bells and whistles, extensive experiments on three public datasets (\ie, ActivityNet Captions, TACoS and ActivityNet-CG) demonstrate that our method significantly outperforms state-of-the-art methods.
An adversarial feature learning strategy for debiasing neural networks
Feb 02, 2023
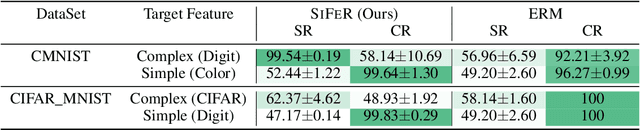
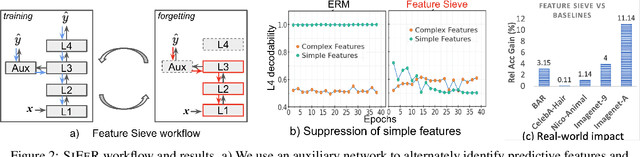
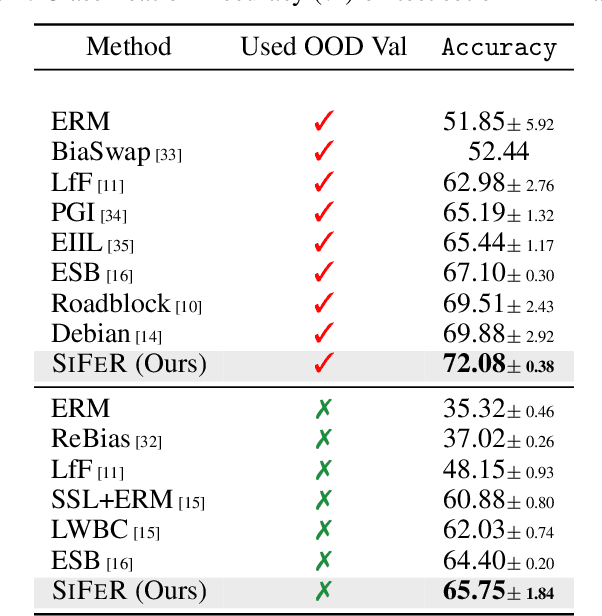
Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This causes biased, incorrect model predictions in many real-world applications, exacerbated by incomplete training data containing spurious feature-label correlations. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we outperform many baselines that incorporate knowledge about known spurious or biased attributes, despite our method not using any such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction & representation learning for deep networks.
Semantic Coherence Markers for the Early Diagnosis of the Alzheimer Disease
Feb 02, 2023
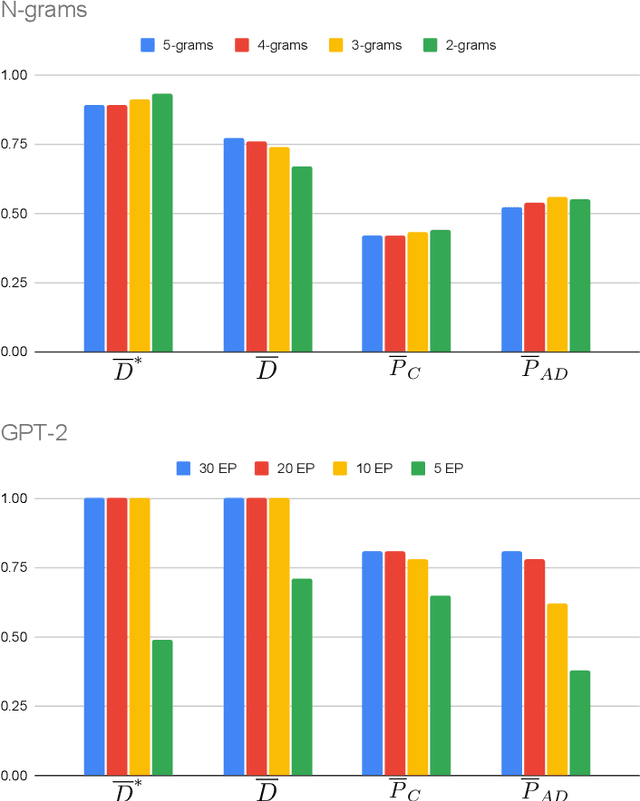
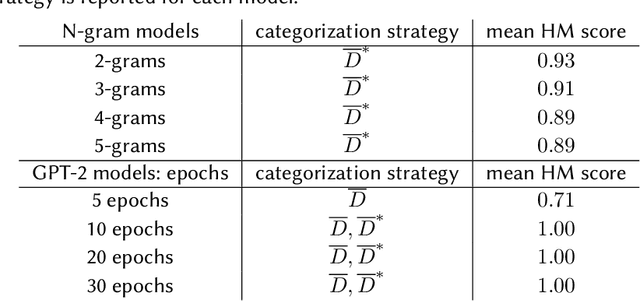
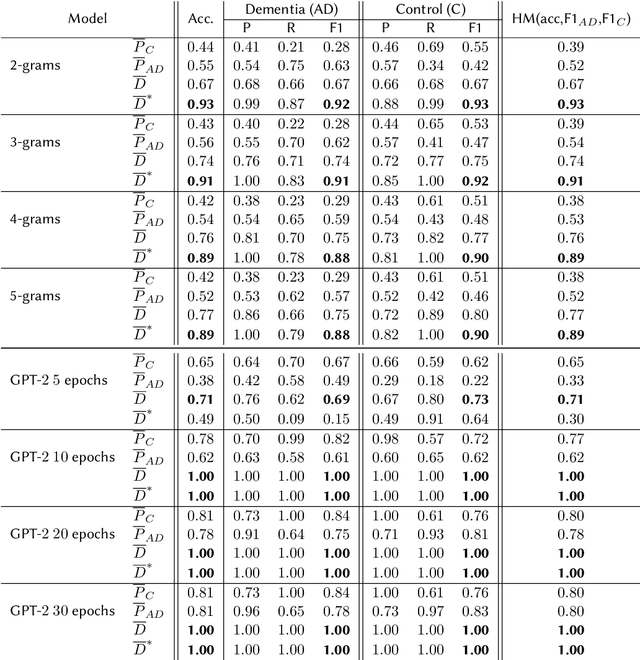
In this work we explore how language models can be employed to analyze language and discriminate between mentally impaired and healthy subjects through the perplexity metric. Perplexity was originally conceived as an information-theoretic measure to assess how much a given language model is suited to predict a text sequence or, equivalently, how much a word sequence fits into a specific language model. We carried out an extensive experimentation with the publicly available data, and employed language models as diverse as N-grams, from 2-grams to 5-grams, and GPT-2, a transformer-based language model. We investigated whether perplexity scores may be used to discriminate between the transcripts of healthy subjects and subjects suffering from Alzheimer Disease (AD). Our best performing models achieved full accuracy and F-score (1.00 in both precision/specificity and recall/sensitivity) in categorizing subjects from both the AD class and control subjects. These results suggest that perplexity can be a valuable analytical metrics with potential application to supporting early diagnosis of symptoms of mental disorders.
CREPES: Cooperative RElative Pose EStimation towards Real-World Multi-Robot Systems
Feb 02, 2023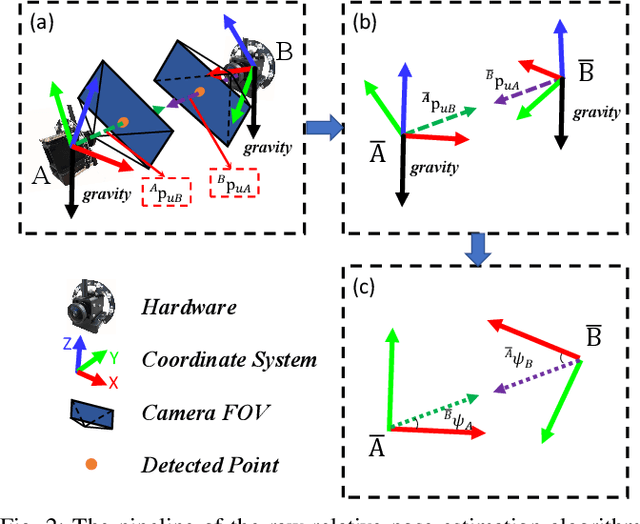
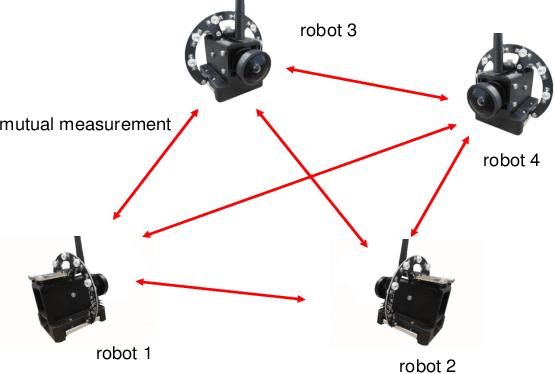
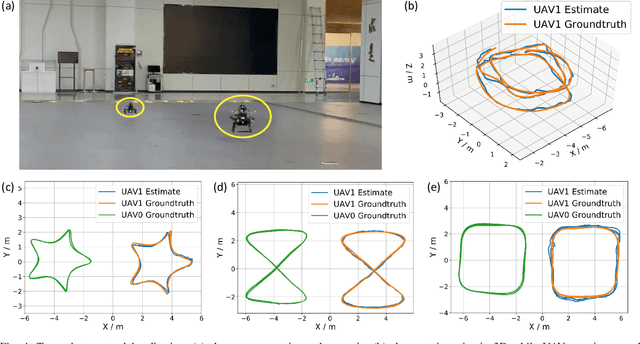
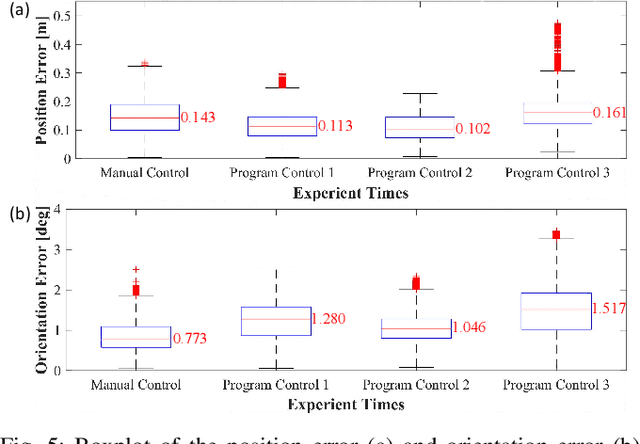
Mutual localization plays a crucial role in multi-robot systems. In this work, we propose a novel system to estimate the 3D relative pose targeting real-world applications. We design and implement a compact hardware module using active infrared (IR) LEDs, an IR fish-eye camera, an ultra-wideband (UWB) module and an inertial measurement unit (IMU). By leveraging IR light communication, the system solves data association between visual detection and UWB ranging. Ranging measurements from the UWB and directional information from the camera offer relative 3D position estimation. Combining the mutual relative position with neighbors and the gravity constraints provided by IMUs, we can estimate the 3D relative pose from every single frame of sensor fusion. In addition, we design an estimator based on the error-state Kalman filter (ESKF) to enhance system accuracy and robustness. When multiple neighbors are available, a Pose Graph Optimization (PGO) algorithm is applied to further improve system accuracy. We conduct experiments in various environments, and the results show that our system outperforms state-of-the-art accuracy and robustness, especially in challenging environments.