 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022
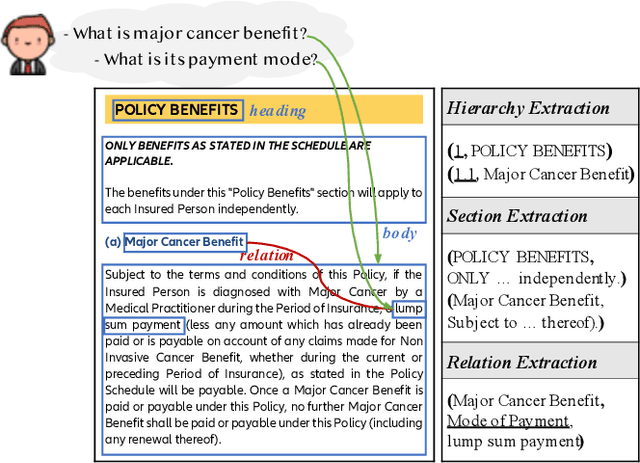
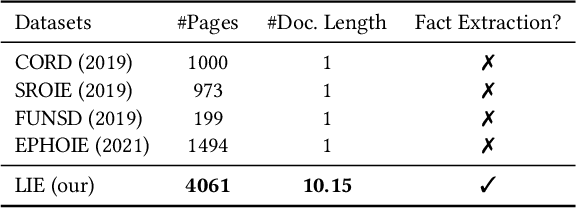

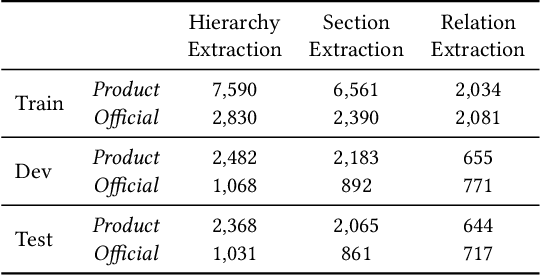
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
Perceptive Locomotion with Controllable Pace and Natural Gait Transitions Over Uneven Terrains
Jan 30, 2023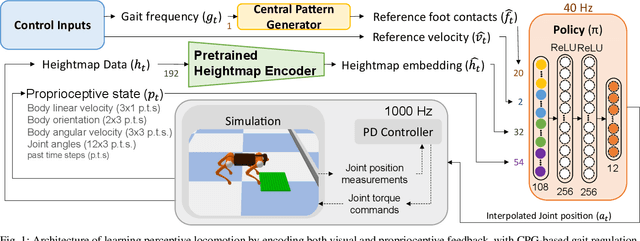
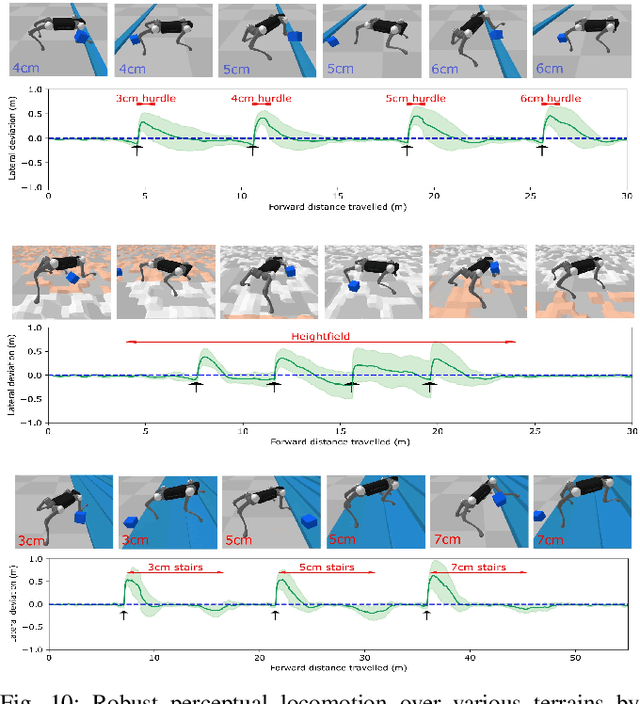
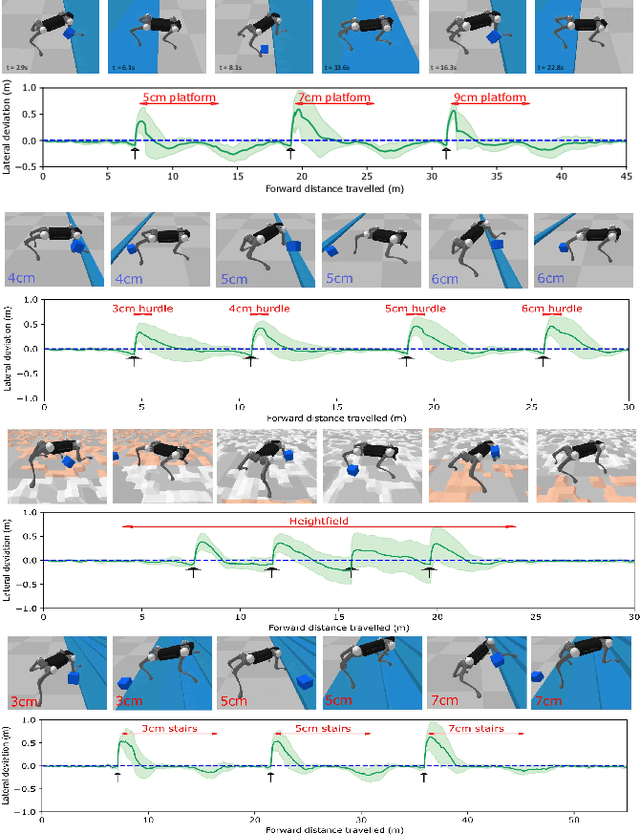
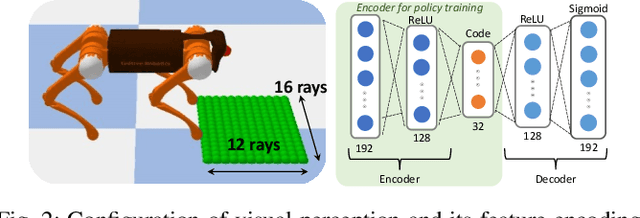
This work developed a learning framework for perceptive legged locomotion that combines visual feedback, proprioceptive information, and active gait regulation of foot-ground contacts. The perception requires only one forward-facing camera to obtain the heightmap, and the active regulation of gait paces and traveling velocity are realized through our formulation of CPG-based high-level imitation of foot-ground contacts. Through this framework, an end-user has the ability to command task-level inputs to control different walking speeds and gait frequencies according to the traversal of different terrains, which enables more reliable negotiation with encountered obstacles. The results demonstrated that the learned perceptive locomotion policy followed task-level control inputs with intended behaviors, and was robust in presence of unseen terrains and external force perturbations. A video demonstration can be found at https://youtu.be/OTzlWzDfAe8, and the codebase at https://github.com/jennyzzt/perceptual-locomotion.
Protein Representation Learning via Knowledge Enhanced Primary Structure Modeling
Jan 30, 2023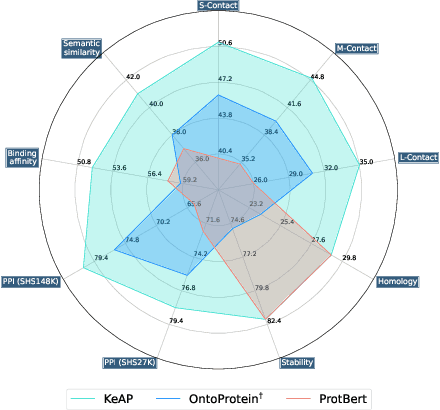
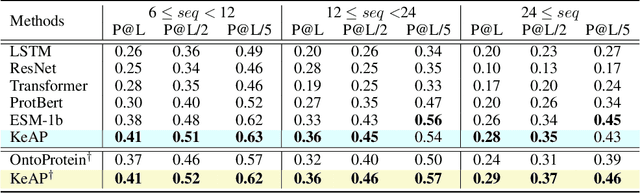
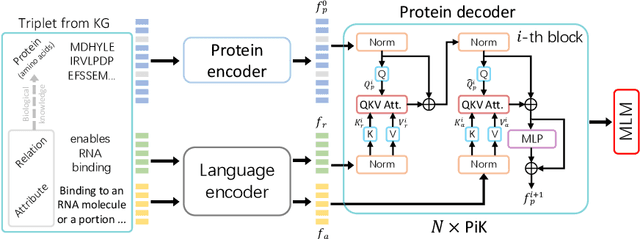

Protein representation learning has primarily benefited from the remarkable development of language models (LMs). Accordingly, pre-trained protein models also suffer from a problem in LMs: a lack of factual knowledge. The recent solution models the relationships between protein and associated knowledge terms as the knowledge encoding objective. However, it fails to explore the relationships at a more granular level, i.e., the token level. To mitigate this, we propose Knowledge-exploited Auto-encoder for Protein (KeAP), which performs token-level knowledge graph exploration for protein representation learning. In practice, non-masked amino acids iteratively query the associated knowledge tokens to extract and integrate helpful information for restoring masked amino acids via attention. We show that KeAP can consistently outperform the previous counterpart on 9 representative downstream applications, sometimes surpassing it by large margins. These results suggest that KeAP provides an alternative yet effective way to perform knowledge enhanced protein representation learning.
Federated Temporal Difference Learning with Linear Function Approximation under Environmental Heterogeneity
Feb 04, 2023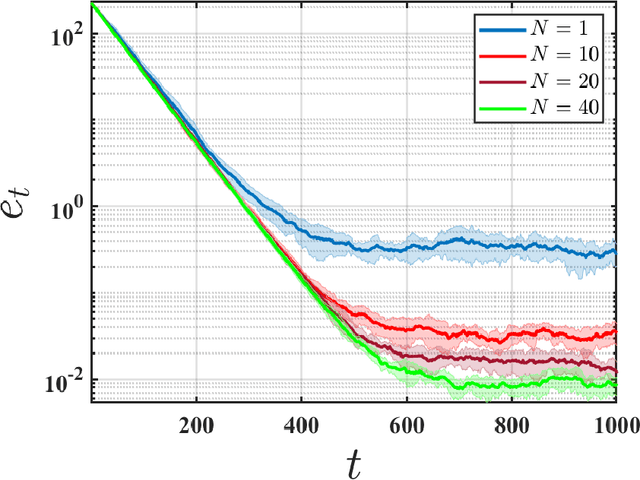
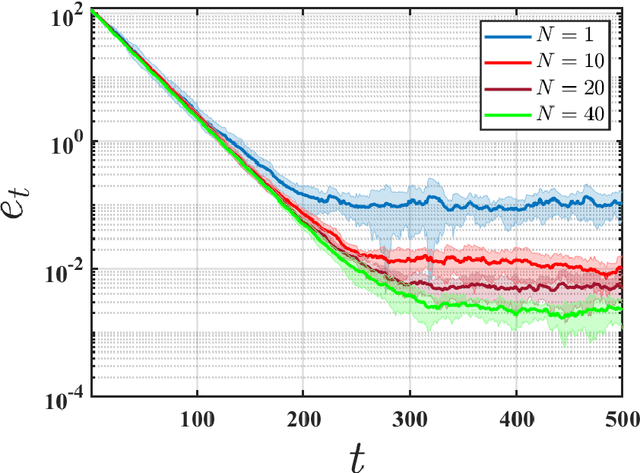
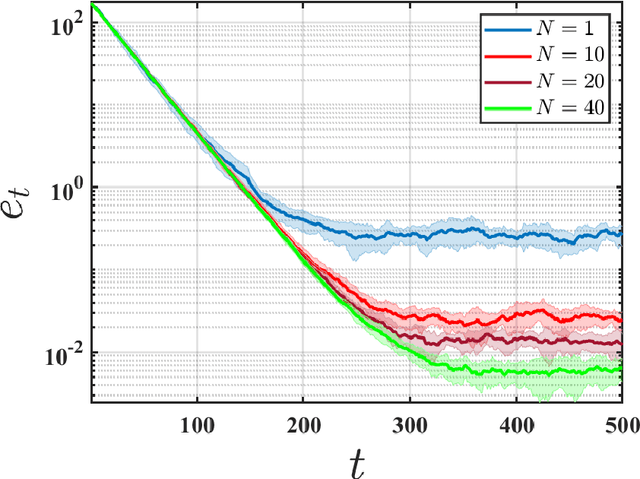
We initiate the study of federated reinforcement learning under environmental heterogeneity by considering a policy evaluation problem. Our setup involves $N$ agents interacting with environments that share the same state and action space but differ in their reward functions and state transition kernels. Assuming agents can communicate via a central server, we ask: Does exchanging information expedite the process of evaluating a common policy? To answer this question, we provide the first comprehensive finite-time analysis of a federated temporal difference (TD) learning algorithm with linear function approximation, while accounting for Markovian sampling, heterogeneity in the agents' environments, and multiple local updates to save communication. Our analysis crucially relies on several novel ingredients: (i) deriving perturbation bounds on TD fixed points as a function of the heterogeneity in the agents' underlying Markov decision processes (MDPs); (ii) introducing a virtual MDP to closely approximate the dynamics of the federated TD algorithm; and (iii) using the virtual MDP to make explicit connections to federated optimization. Putting these pieces together, we rigorously prove that in a low-heterogeneity regime, exchanging model estimates leads to linear convergence speedups in the number of agents.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023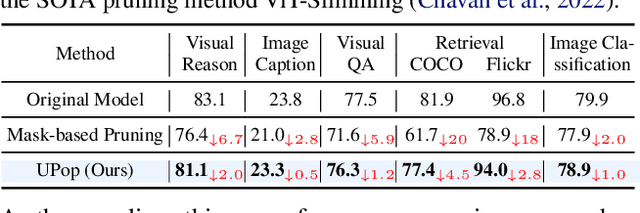
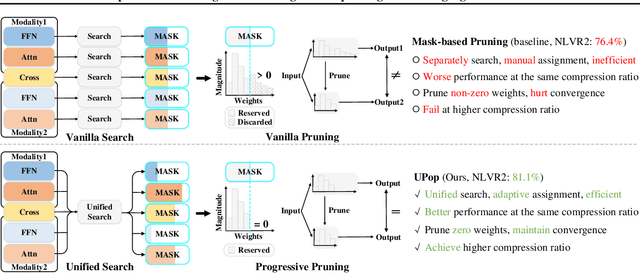

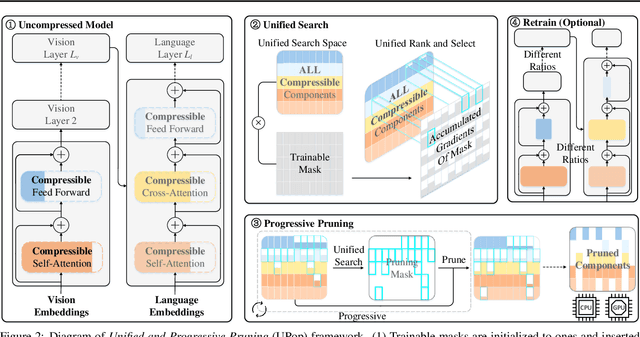
Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
CSDR-BERT: a pre-trained scientific dataset match model for Chinese Scientific Dataset Retrieval
Jan 31, 2023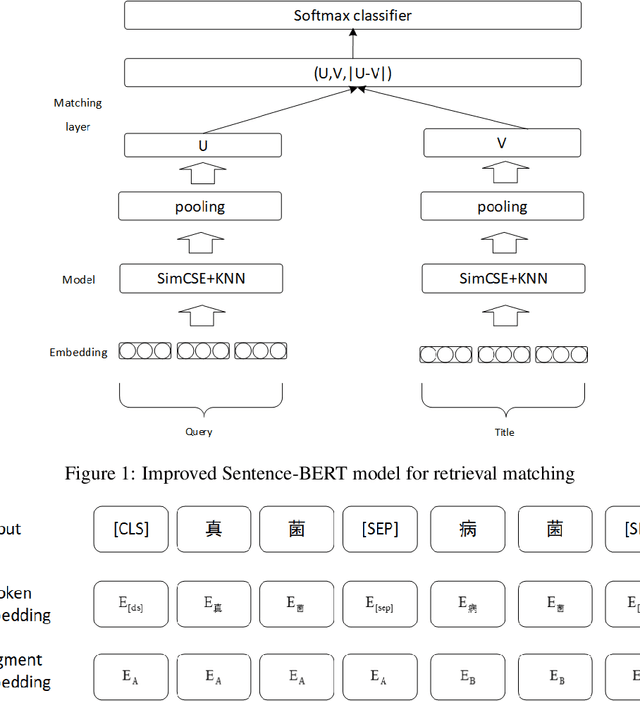

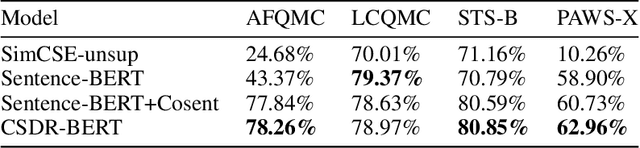
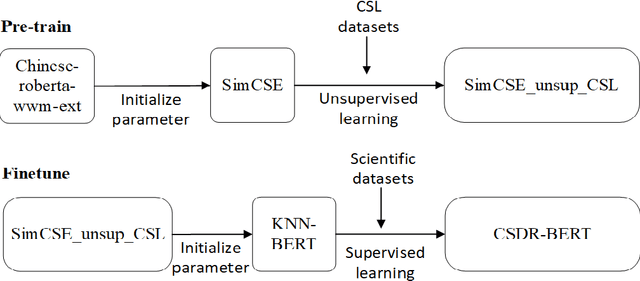
As the number of open and shared scientific datasets on the Internet increases under the open science movement, efficiently retrieving these datasets is a crucial task in information retrieval (IR) research. In recent years, the development of large models, particularly the pre-training and fine-tuning paradigm, which involves pre-training on large models and fine-tuning on downstream tasks, has provided new solutions for IR match tasks. In this study, we use the original BERT token in the embedding layer, improve the Sentence-BERT model structure in the model layer by introducing the SimCSE and K-Nearest Neighbors method, and use the cosent loss function in the optimization phase to optimize the target output. Our experimental results show that our model outperforms other competing models on both public and self-built datasets through comparative experiments and ablation implementations. This study explores and validates the feasibility and efficiency of pre-training techniques for semantic retrieval of Chinese scientific datasets.
An adversarial feature learning strategy for debiasing neural networks
Feb 02, 2023
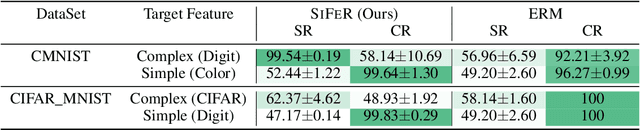
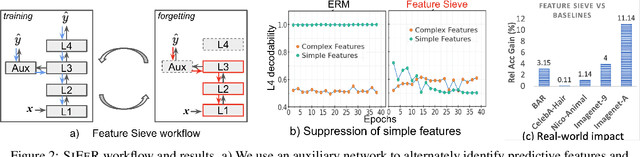
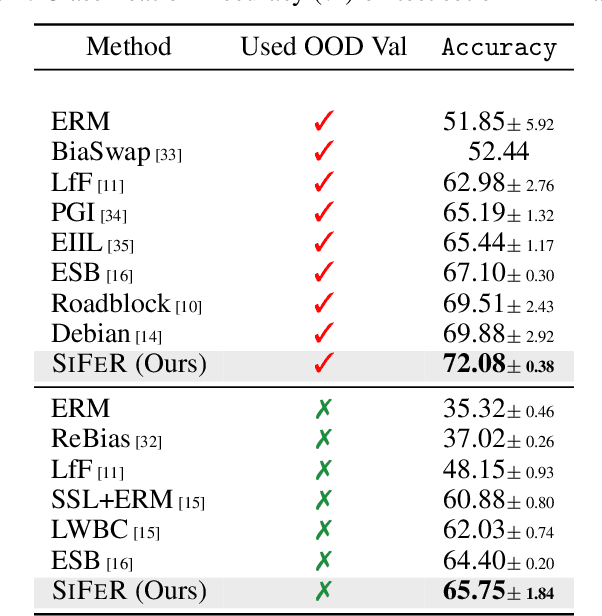
Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This causes biased, incorrect model predictions in many real-world applications, exacerbated by incomplete training data containing spurious feature-label correlations. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we outperform many baselines that incorporate knowledge about known spurious or biased attributes, despite our method not using any such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction & representation learning for deep networks.
AOP-Net: All-in-One Perception Network for Joint LiDAR-based 3D Object Detection and Panoptic Segmentation
Feb 02, 2023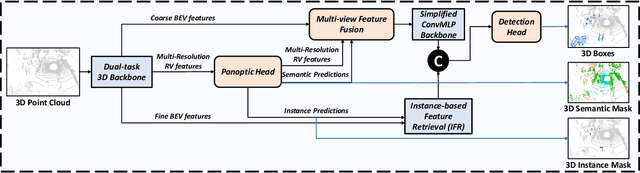
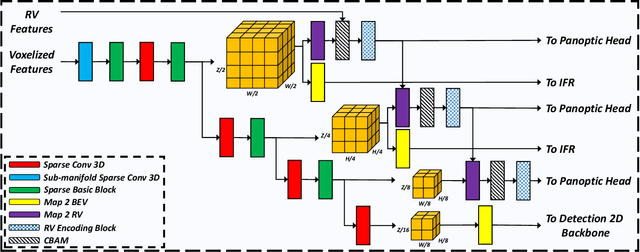
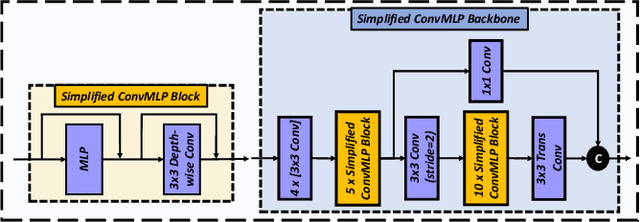
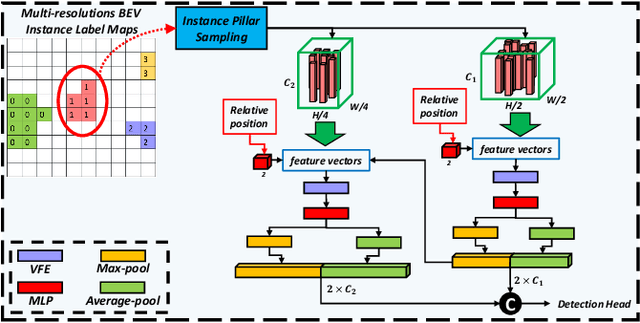
LiDAR-based 3D object detection and panoptic segmentation are two crucial tasks in the perception systems of autonomous vehicles and robots. In this paper, we propose All-in-One Perception Network (AOP-Net), a LiDAR-based multi-task framework that combines 3D object detection and panoptic segmentation. In this method, a dual-task 3D backbone is developed to extract both panoptic- and detection-level features from the input LiDAR point cloud. Also, a new 2D backbone that intertwines Multi-Layer Perceptron (MLP) and convolution layers is designed to further improve the detection task performance. Finally, a novel module is proposed to guide the detection head by recovering useful features discarded during down-sampling operations in the 3D backbone. This module leverages estimated instance segmentation masks to recover detailed information from each candidate object. The AOP-Net achieves state-of-the-art performance for published works on the nuScenes benchmark for both 3D object detection and panoptic segmentation tasks. Also, experiments show that our method easily adapts to and significantly improves the performance of any BEV-based 3D object detection method.
Molecular Geometry-aware Transformer for accurate 3D Atomic System modeling
Feb 02, 2023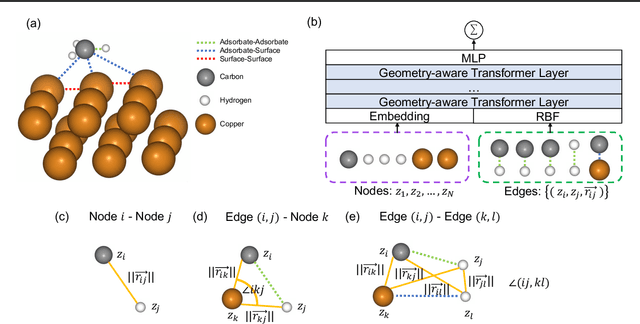
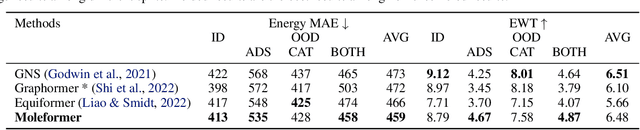
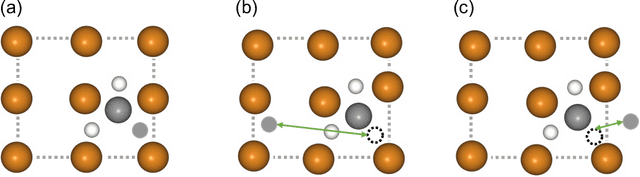
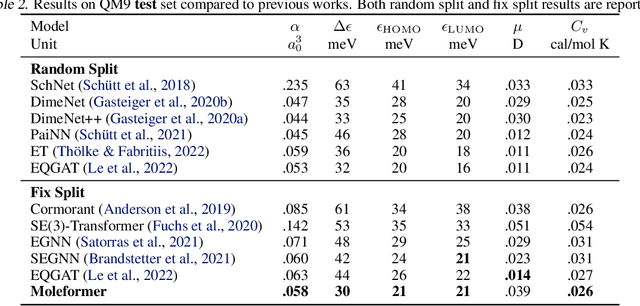
Molecular dynamic simulations are important in computational physics, chemistry, material, and biology. Machine learning-based methods have shown strong abilities in predicting molecular energy and properties and are much faster than DFT calculations. Molecular energy is at least related to atoms, bonds, bond angles, torsion angles, and nonbonding atom pairs. Previous Transformer models only use atoms as inputs which lack explicit modeling of the aforementioned factors. To alleviate this limitation, we propose Moleformer, a novel Transformer architecture that takes nodes (atoms) and edges (bonds and nonbonding atom pairs) as inputs and models the interactions among them using rotational and translational invariant geometry-aware spatial encoding. Proposed spatial encoding calculates relative position information including distances and angles among nodes and edges. We benchmark Moleformer on OC20 and QM9 datasets, and our model achieves state-of-the-art on the initial state to relaxed energy prediction of OC20 and is very competitive in QM9 on predicting quantum chemical properties compared to other Transformer and Graph Neural Network (GNN) methods which proves the effectiveness of the proposed geometry-aware spatial encoding in Moleformer.
CREPES: Cooperative RElative Pose EStimation towards Real-World Multi-Robot Systems
Feb 02, 2023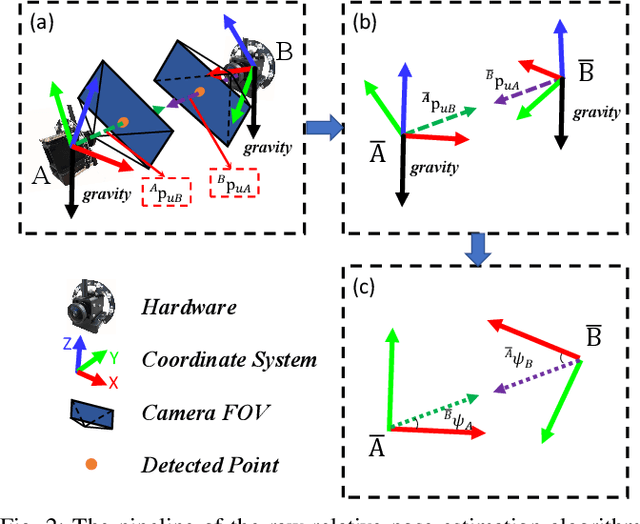
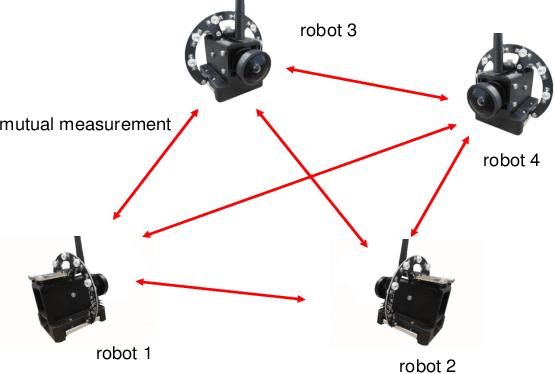
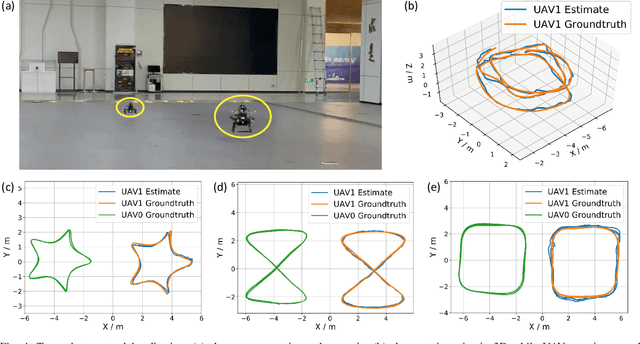
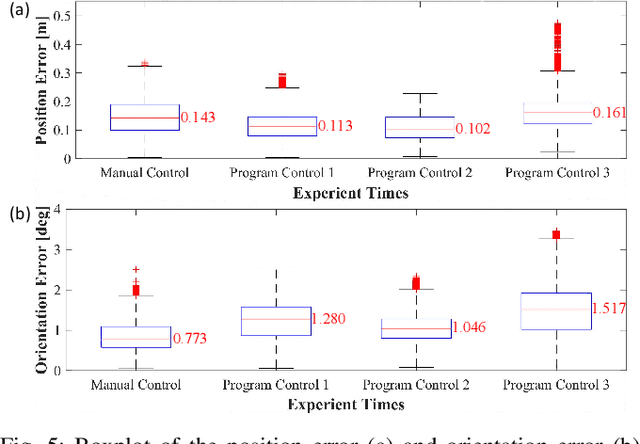
Mutual localization plays a crucial role in multi-robot systems. In this work, we propose a novel system to estimate the 3D relative pose targeting real-world applications. We design and implement a compact hardware module using active infrared (IR) LEDs, an IR fish-eye camera, an ultra-wideband (UWB) module and an inertial measurement unit (IMU). By leveraging IR light communication, the system solves data association between visual detection and UWB ranging. Ranging measurements from the UWB and directional information from the camera offer relative 3D position estimation. Combining the mutual relative position with neighbors and the gravity constraints provided by IMUs, we can estimate the 3D relative pose from every single frame of sensor fusion. In addition, we design an estimator based on the error-state Kalman filter (ESKF) to enhance system accuracy and robustness. When multiple neighbors are available, a Pose Graph Optimization (PGO) algorithm is applied to further improve system accuracy. We conduct experiments in various environments, and the results show that our system outperforms state-of-the-art accuracy and robustness, especially in challenging environments.