 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QS-ADN: Quasi-Supervised Artifact Disentanglement Network for Low-Dose CT Image Denoising by Local Similarity Among Unpaired Data
Feb 08, 2023
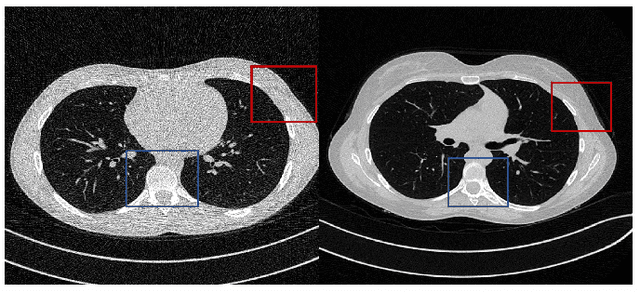
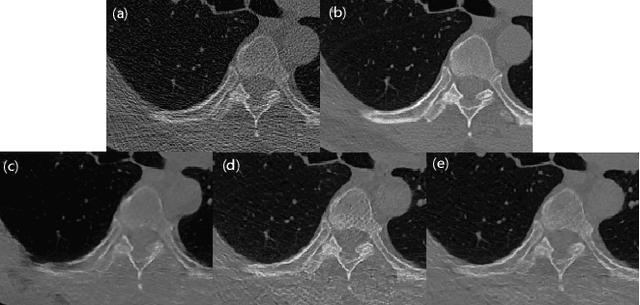
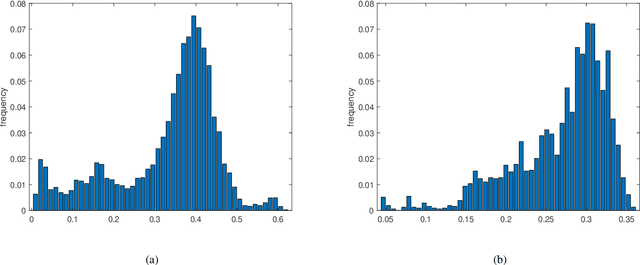
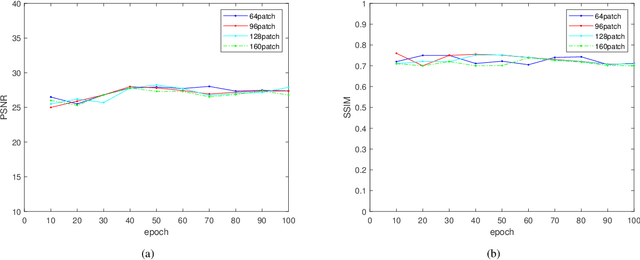
Deep learning has been successfully applied to low-dose CT (LDCT) image denoising for reducing potential radiation risk. However, the widely reported supervised LDCT denoising networks require a training set of paired images, which is expensive to obtain and cannot be perfectly simulated. Unsupervised learning utilizes unpaired data and is highly desirable for LDCT denoising. As an example, an artifact disentanglement network (ADN) relies on unparied images and obviates the need for supervision but the results of artifact reduction are not as good as those through supervised learning.An important observation is that there is often hidden similarity among unpaired data that can be utilized. This paper introduces a new learning mode, called quasi-supervised learning, to empower the ADN for LDCT image denoising.For every LDCT image, the best matched image is first found from an unpaired normal-dose CT (NDCT) dataset. Then, the matched pairs and the corresponding matching degree as prior information are used to construct and train our ADN-type network for LDCT denoising.The proposed method is different from (but compatible with) supervised and semi-supervised learning modes and can be easily implemented by modifying existing networks. The experimental results show that the method is competitive with state-of-the-art methods in terms of noise suppression and contextual fidelity. The code and working dataset are publicly available at https://github.com/ruanyuhui/ADN-QSDL.git.
Dynamic MLP for MRI Reconstruction
Jan 21, 2023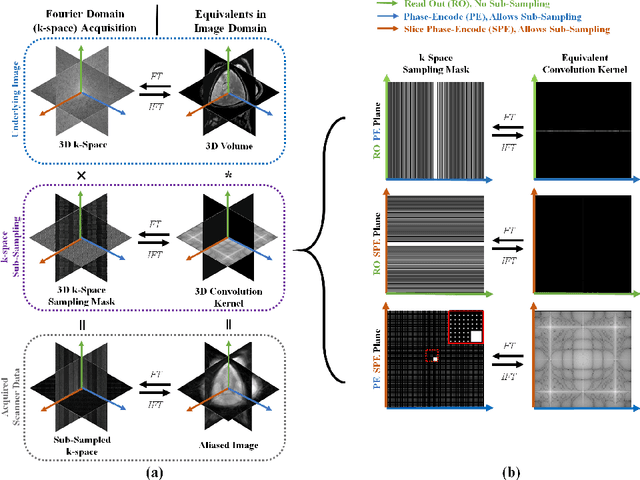
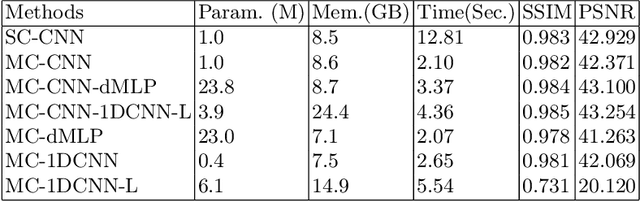
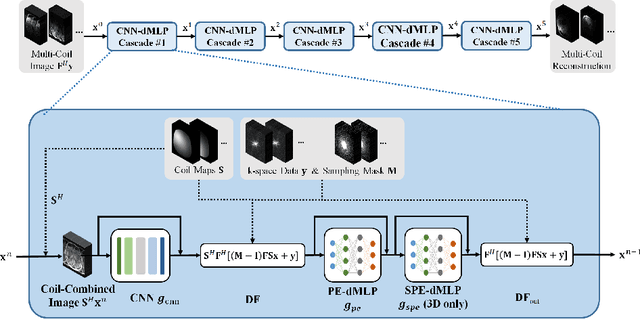
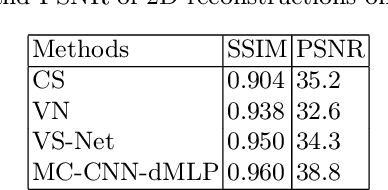
As convolutional neural networks (CNN) become the most successful reconstruction technique for accelerated Magnetic Resonance Imaging (MRI), CNN reaches its limit on image quality especially in sharpness. Further improvement on image quality often comes at massive computational costs, hindering their practicability in the clinic setting. MRI reconstruction is essentially a deconvolution problem, which demands long-distance information that is difficult to be captured by CNNs with small convolution kernels. The multi-layer perceptron (MLP) is able to model such long-distance information, but it restricts a fixed input size while the reconstruction of images in flexible resolutions is required in the clinic setting. In this paper, we proposed a hybrid CNN and MLP reconstruction strategy, featured by dynamic MLP (dMLP) that accepts arbitrary image sizes. Experiments were conducted using 3D multi-coil MRI. Our results suggested the proposed dMLP can improve image sharpness compared to its pure CNN counterpart, while costing minor additional GPU memory and computation time. We further compared the proposed dMLP with CNNs using large kernels and studied pure MLP-based reconstruction using a stack of 1D dMLPs, as well as its CNN counterpart using only 1D convolutions. We observed the enlarged receptive field has noticeably improved image quality, while simply using CNN with a large kernel leads to difficulties in training. Noticeably, the pure MLP-based method has been outperformed by CNN-involved methods, which matches the observations in other computer vision tasks for natural images.
Data efficiency and extrapolation trends in neural network interatomic potentials
Feb 12, 2023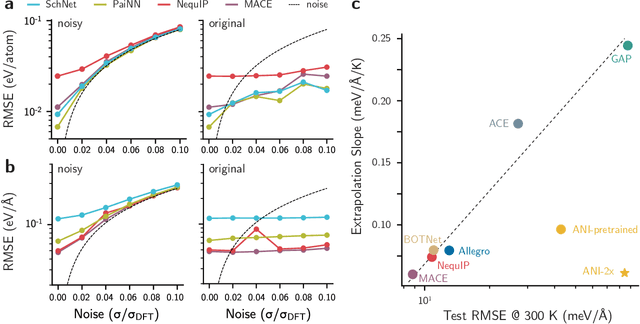
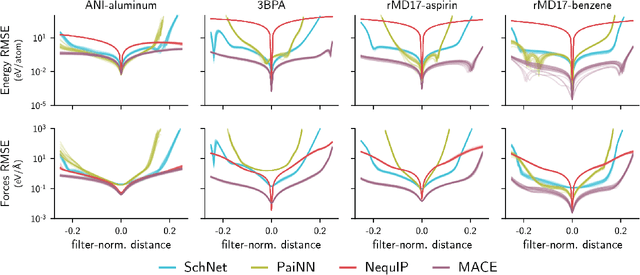

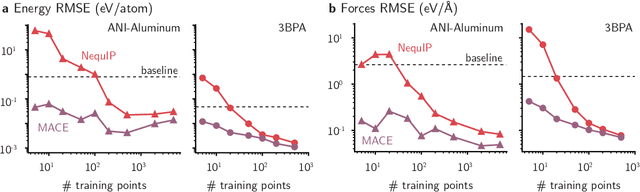
Over the last few years, key architectural advances have been proposed for neural network interatomic potentials (NNIPs), such as incorporating message-passing networks, equivariance, or many-body expansion terms. Although modern NNIP models exhibit nearly negligible differences in energy/forces errors, improvements in accuracy are still considered the main target when developing new NNIP architectures. In this work, we investigate how architectural choices influence the trainability and generalization error in NNIPs, revealing trends in extrapolation, data efficiency, and loss landscapes. First, we show that modern NNIP architectures recover the underlying potential energy surface (PES) of the training data even when trained to corrupted labels. Second, generalization metrics such as errors on high-temperature samples from the 3BPA dataset are demonstrated to follow a scaling relation for a variety of models. Thus, improvements in accuracy metrics may not bring independent information on the robust generalization of NNIPs. To circumvent this problem, we relate loss landscapes to model generalization across datasets. Using this probe, we explain why NNIPs with similar accuracy metrics exhibit different abilities to extrapolate and how training to forces improves the optimization landscape of a model. As an example, we show that MACE can predict PESes with reasonable error after being trained to as few as five data points, making it an example of a "few-shot" model for learning PESes. On the other hand, models with similar accuracy metrics such as NequIP show smaller ability to extrapolate in this extremely low-data regime. Our work provides a deep learning justification for the performance of many common NNIPs, and introduces tools beyond accuracy metrics that can be used to inform the development of next-generation models.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022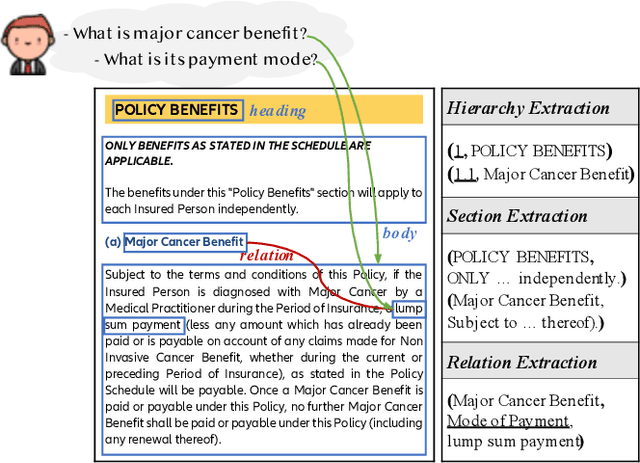
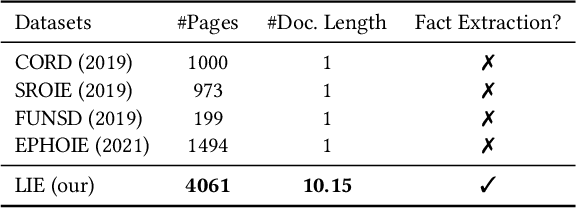

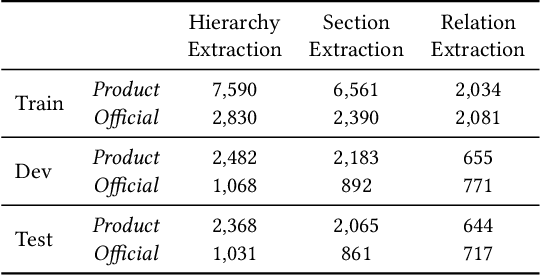
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
Temporal Disaggregation of the Cumulative Grass Growth
Dec 21, 2022Information on the grass growth over a year is essential for some models simulating the use of this resource to feed animals on pasture or at barn with hay or grass silage. Unfortunately, this information is rarely available. The challenge is to reconstruct grass growth from two sources of information: usual daily climate data (rainfall, radiation, etc.) and cumulative growth over the year. We have to be able to capture the effect of seasonal climatic events which are known to distort the growth curve within the year. In this paper, we formulate this challenge as a problem of disaggregating the cumulative growth into a time series. To address this problem, our method applies time series forecasting using climate information and grass growth from previous time steps. Several alternatives of the method are proposed and compared experimentally using a database generated from a grassland process-based model. The results show that our method can accurately reconstruct the time series, independently of the use of the cumulative growth information.
Generalization Bounds with Data-dependent Fractal Dimensions
Feb 06, 2023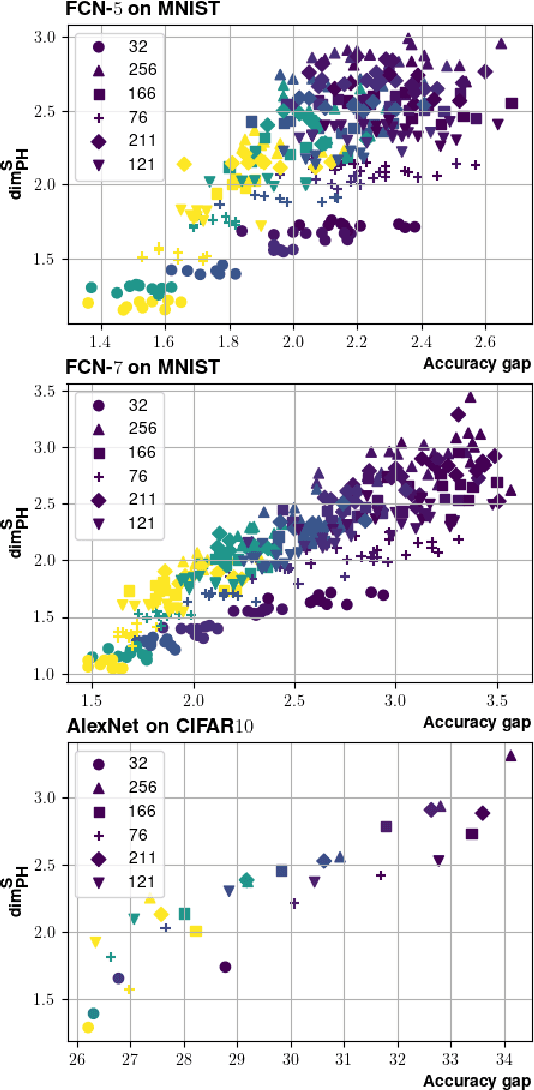
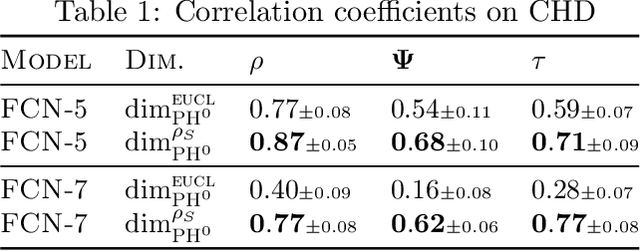
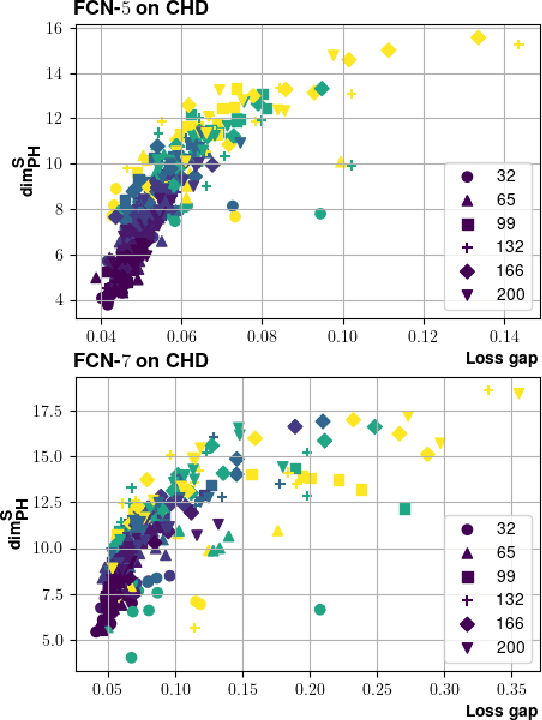
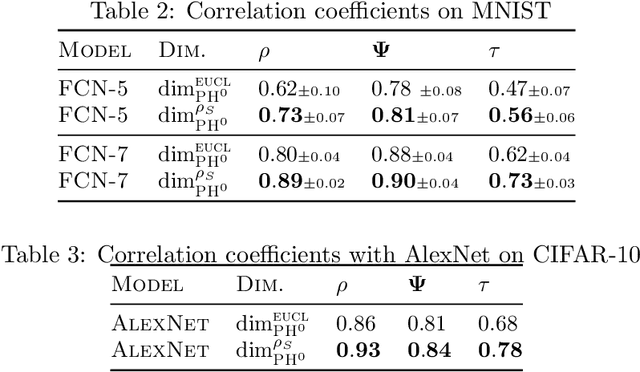
Providing generalization guarantees for modern neural networks has been a crucial task in statistical learning. Recently, several studies have attempted to analyze the generalization error in such settings by using tools from fractal geometry. While these works have successfully introduced new mathematical tools to apprehend generalization, they heavily rely on a Lipschitz continuity assumption, which in general does not hold for neural networks and might make the bounds vacuous. In this work, we address this issue and prove fractal geometry-based generalization bounds without requiring any Lipschitz assumption. To achieve this goal, we build up on a classical covering argument in learning theory and introduce a data-dependent fractal dimension. Despite introducing a significant amount of technical complications, this new notion lets us control the generalization error (over either fixed or random hypothesis spaces) along with certain mutual information (MI) terms. To provide a clearer interpretation to the newly introduced MI terms, as a next step, we introduce a notion of "geometric stability" and link our bounds to the prior art. Finally, we make a rigorous connection between the proposed data-dependent dimension and topological data analysis tools, which then enables us to compute the dimension in a numerically efficient way. We support our theory with experiments conducted on various settings.
Optimizing Energy-Harvesting Hybrid VLC/RF Networks with Random Receiver Orientation
Feb 06, 2023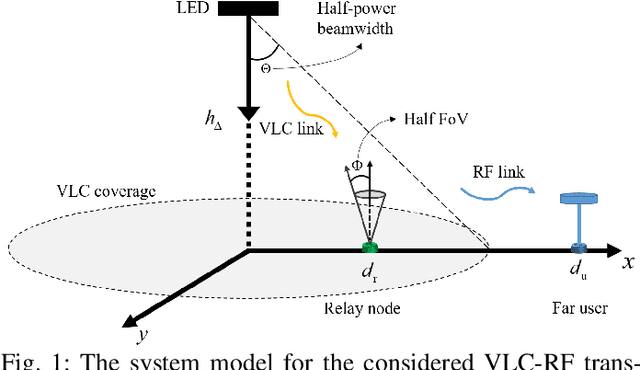
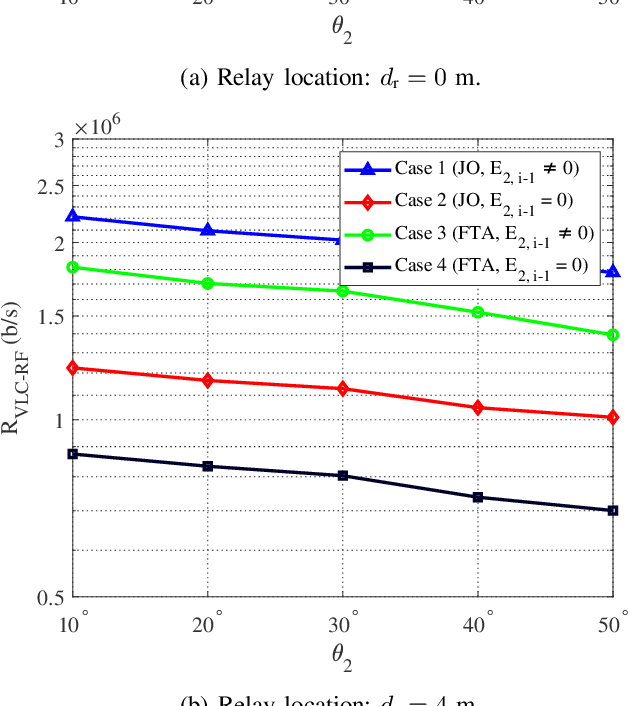
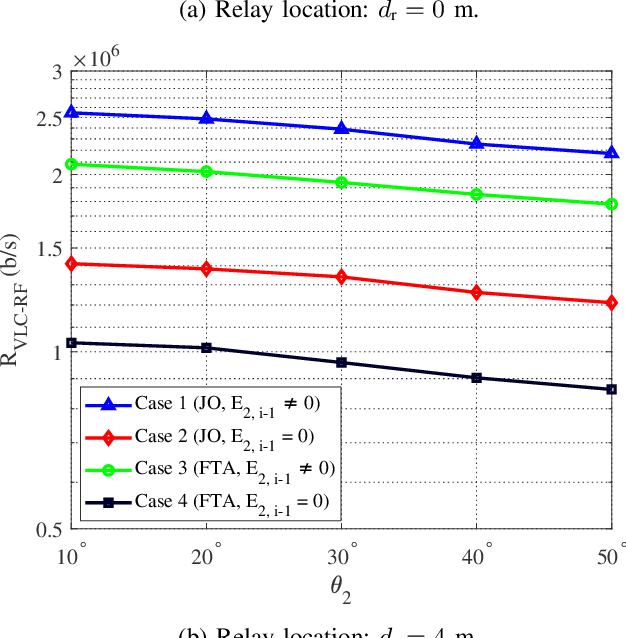
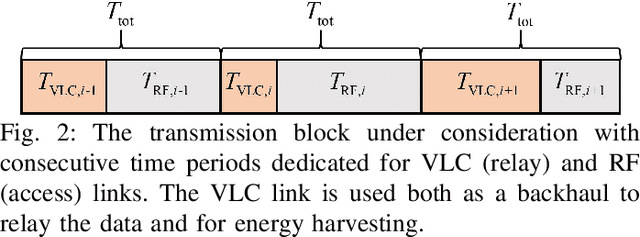
In this paper, we consider an indoor hybrid visible light communication (VLC) and radio frequency (RF) communication scenario with two-hop downlink transmission. The LED carries both data and energy in the first phase, VLC, to an energy harvester relay node, which then uses the harvested energy to re-transmit the decoded information to the RF user in the second phase, RF communication. The direct current (DC) bias and the assigned time duration for VLC transmission are taken into account as design parameters. The optimization problem is formulated to maximize the data rate with the assumption of decode-and-forward relaying for fixed receiver orientation. The non-convex optimization is split into two sub-problems and solved cyclically. It optimizes the data rate by solving two sub-problems: fixing time duration for VLC link to solve DC bias and fixing DC bias to solve time duration. The effect of random receiver orientation on the data rate is also studied, and closed-form expressions for both VLC and RF data rates are derived. The optimization is solved through an exhaustive search, and the results show that a higher data rate can be achieved by solving the joint problem of DC bias and time duration compared to solely optimizing the DC bias.
Global Flood Prediction: a Multimodal Machine Learning Approach
Jan 29, 2023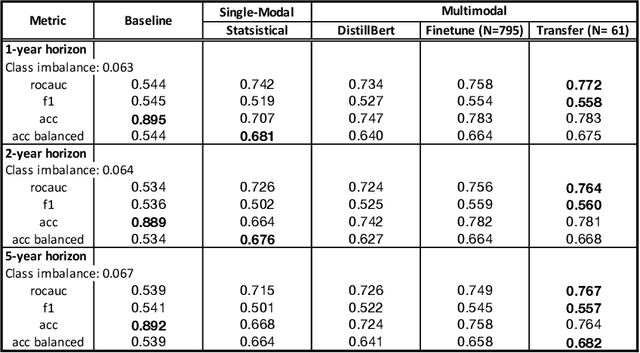
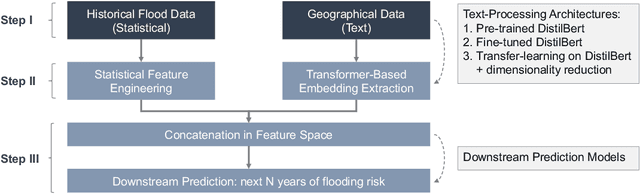
Flooding is one of the most destructive and costly natural disasters, and climate changes would further increase risks globally. This work presents a novel multimodal machine learning approach for multi-year global flood risk prediction, combining geographical information and historical natural disaster dataset. Our multimodal framework employs state-of-the-art processing techniques to extract embeddings from each data modality, including text-based geographical data and tabular-based time-series data. Experiments demonstrate that a multimodal approach, that is combining text and statistical data, outperforms a single-modality approach. Our most advanced architecture, employing embeddings extracted using transfer learning upon DistilBert model, achieves 75\%-77\% ROCAUC score in predicting the next 1-5 year flooding event in historically flooded locations. This work demonstrates the potentials of using machine learning for long-term planning in natural disaster management.
Task-Guided IRL in POMDPs that Scales
Dec 30, 2022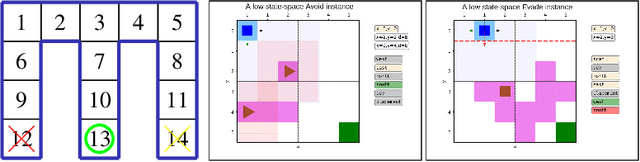
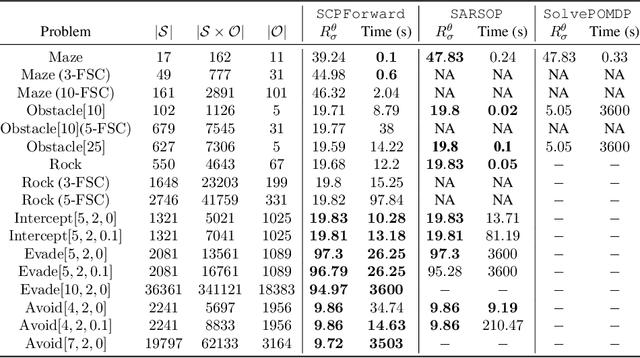
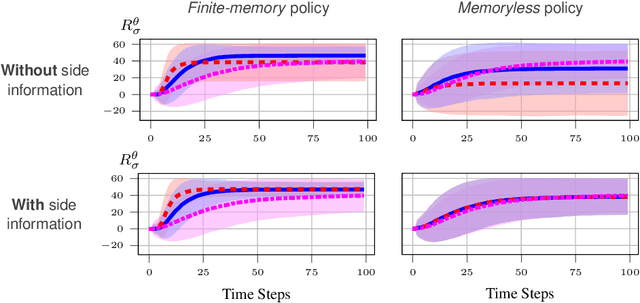
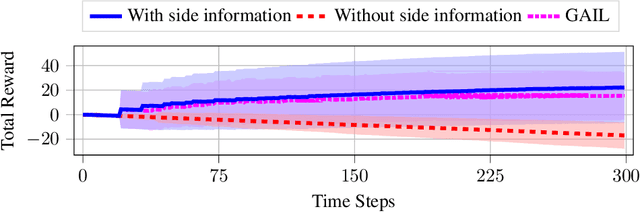
In inverse reinforcement learning (IRL), a learning agent infers a reward function encoding the underlying task using demonstrations from experts. However, many existing IRL techniques make the often unrealistic assumption that the agent has access to full information about the environment. We remove this assumption by developing an algorithm for IRL in partially observable Markov decision processes (POMDPs). We address two limitations of existing IRL techniques. First, they require an excessive amount of data due to the information asymmetry between the expert and the learner. Second, most of these IRL techniques require solving the computationally intractable forward problem -- computing an optimal policy given a reward function -- in POMDPs. The developed algorithm reduces the information asymmetry while increasing the data efficiency by incorporating task specifications expressed in temporal logic into IRL. Such specifications may be interpreted as side information available to the learner a priori in addition to the demonstrations. Further, the algorithm avoids a common source of algorithmic complexity by building on causal entropy as the measure of the likelihood of the demonstrations as opposed to entropy. Nevertheless, the resulting problem is nonconvex due to the so-called forward problem. We solve the intrinsic nonconvexity of the forward problem in a scalable manner through a sequential linear programming scheme that guarantees to converge to a locally optimal policy. In a series of examples, including experiments in a high-fidelity Unity simulator, we demonstrate that even with a limited amount of data and POMDPs with tens of thousands of states, our algorithm learns reward functions and policies that satisfy the task while inducing similar behavior to the expert by leveraging the provided side information.
Hyperspectral Image Super Resolution with Real Unaligned RGB Guidance
Feb 13, 2023

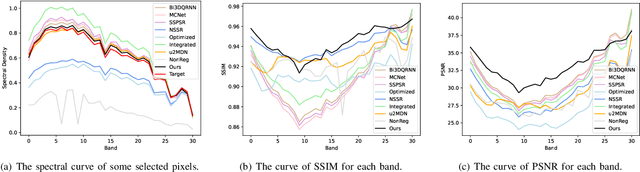
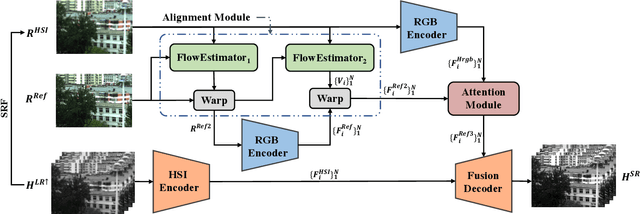
Fusion-based hyperspectral image (HSI) super-resolution has become increasingly prevalent for its capability to integrate high-frequency spatial information from the paired high-resolution (HR) RGB reference image. However, most of the existing methods either heavily rely on the accurate alignment between low-resolution (LR) HSIs and RGB images, or can only deal with simulated unaligned RGB images generated by rigid geometric transformations, which weakens their effectiveness for real scenes. In this paper, we explore the fusion-based HSI super-resolution with real RGB reference images that have both rigid and non-rigid misalignments. To properly address the limitations of existing methods for unaligned reference images, we propose an HSI fusion network with heterogenous feature extractions, multi-stage feature alignments, and attentive feature fusion. Specifically, our network first transforms the input HSI and RGB images into two sets of multi-scale features with an HSI encoder and an RGB encoder, respectively. The features of RGB reference images are then processed by a multi-stage alignment module to explicitly align the features of RGB reference with the LR HSI. Finally, the aligned features of RGB reference are further adjusted by an adaptive attention module to focus more on discriminative regions before sending them to the fusion decoder to generate the reconstructed HR HSI. Additionally, we collect a real-world HSI fusion dataset, consisting of paired HSI and unaligned RGB reference, to support the evaluation of the proposed model for real scenes. Extensive experiments are conducted on both simulated and our real-world datasets, and it shows that our method obtains a clear improvement over existing single-image and fusion-based super-resolution methods on quantitative assessment as well as visual comparison.