 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A statistically constrained internal method for single image super-resolution
Feb 03, 2023
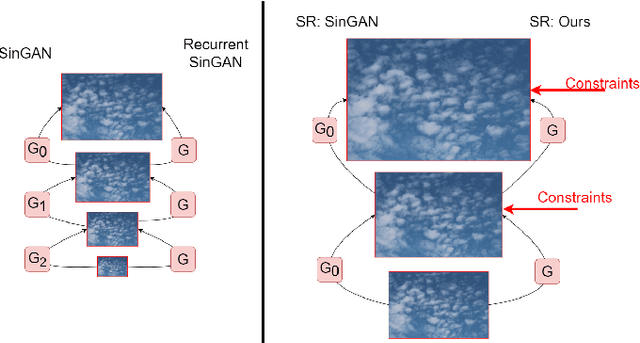


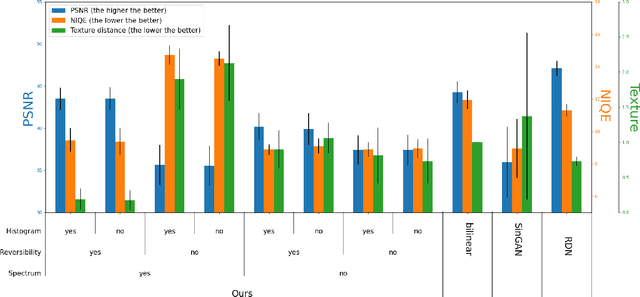
Deep learning based methods for single-image super-resolution (SR) have drawn a lot of attention lately. In particular, various papers have shown that the learning stage can be performed on a single image, resulting in the so-called internal approaches. The SinGAN method is one of these contributions, where the distribution of image patches is learnt on the image at hand and propagated at finer scales. Now, there are situations where some statistical a priori can be assumed for the final image. In particular, many natural phenomena yield images having power law Fourier spectrum, such as clouds and other texture images. In this work, we show how such a priori information can be integrated into an internal super-resolution approach, by constraining the learned up-sampling procedure of SinGAN. We consider various types of constraints, related to the Fourier power spectrum, the color histograms and the consistency of the upsampling scheme. We demonstrate on various experiments that these constraints are indeed satisfied, but also that some perceptual quality measures can be improved by the proposed approach.
A Lite Fireworks Algorithm for Optimization
Jan 07, 2023
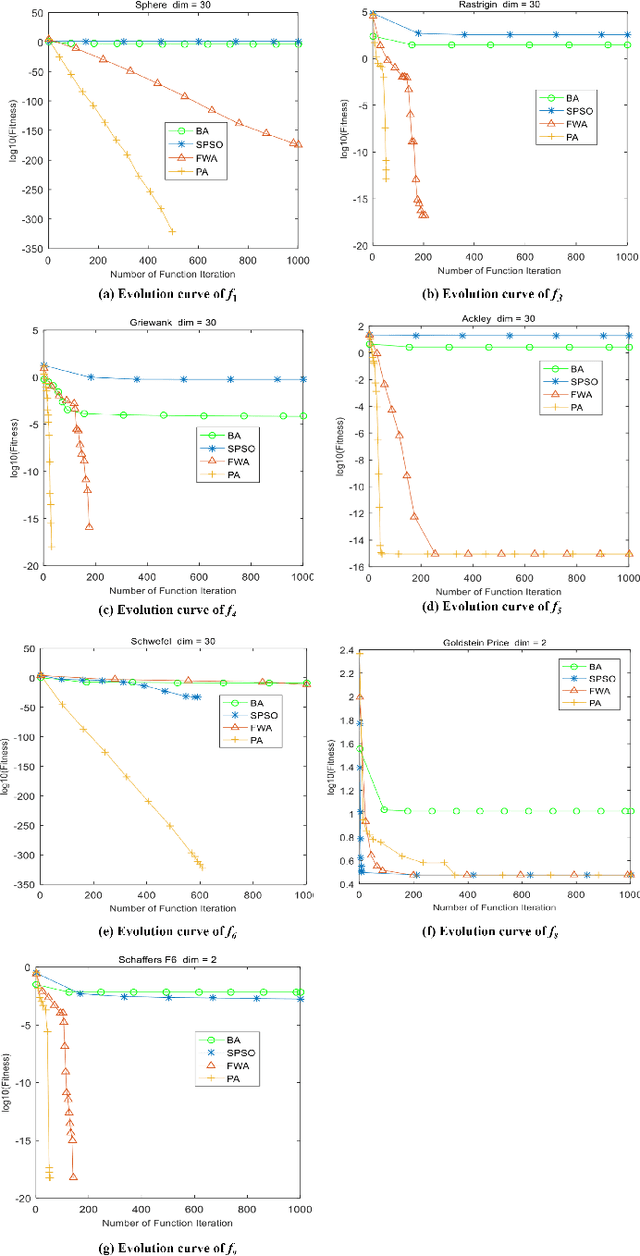
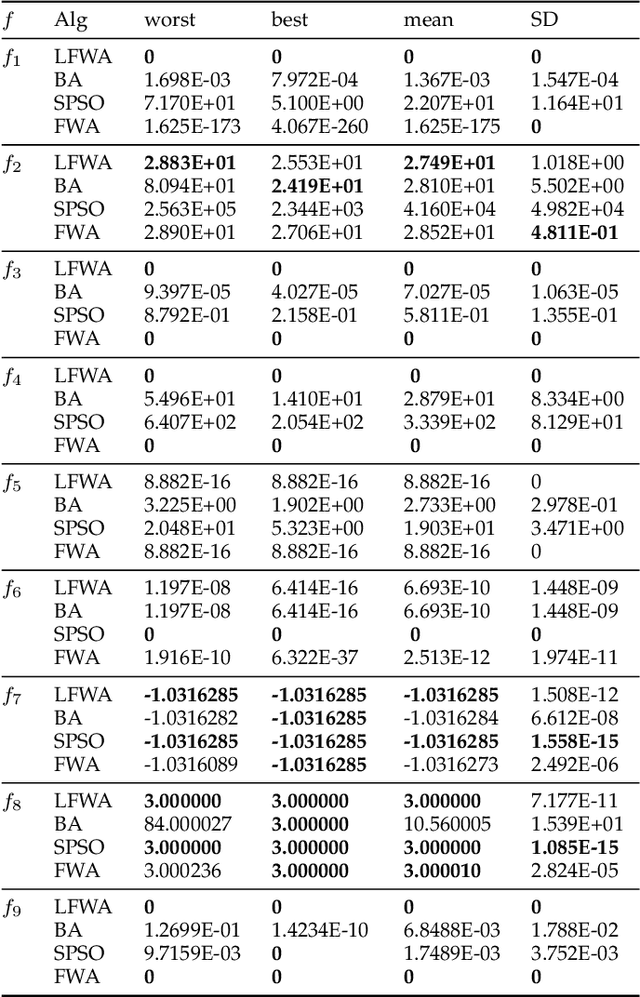

The fireworks algorithm is an optimization algorithm for simulating the explosion phenomenon of fireworks. Because of its fast convergence and high precision, it is widely used in pattern recognition, optimal scheduling, and other fields. However, most of the existing research work on the fireworks algorithm is improved based on its defects, and little consideration is given to reducing the number of parameters of the fireworks algorithm. The original fireworks algorithm has too many parameters, which increases the cost of algorithm adjustment and is not conducive to engineering applications. In addition, in the fireworks population, the unselected individuals are discarded, thus causing a waste of their location information. To reduce the number of parameters of the original Fireworks Algorithm and make full use of the location information of discarded individuals, we propose a simplified version of the Fireworks Algorithm. It reduces the number of algorithm parameters by redesigning the explosion operator of the fireworks algorithm and constructs an adaptive explosion radius by using the historical optimal information to balance the local mining and global exploration capabilities. The comparative experimental results of function optimization show that the overall performance of our proposed LFWA is better than that of comparative algorithms, such as the fireworks algorithm, particle swarm algorithm, and bat algorithm.
HiDAnet: RGB-D Salient Object Detection via Hierarchical Depth Awareness
Jan 18, 2023

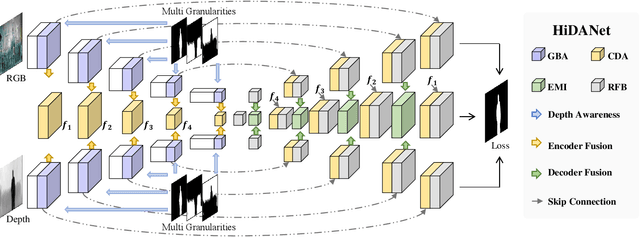
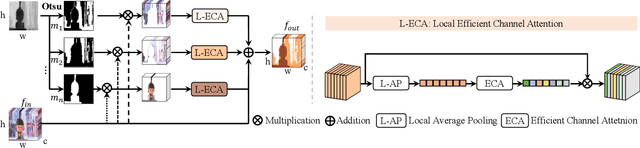
RGB-D saliency detection aims to fuse multi-modal cues to accurately localize salient regions. Existing works often adopt attention modules for feature modeling, with few methods explicitly leveraging fine-grained details to merge with semantic cues. Thus, despite the auxiliary depth information, it is still challenging for existing models to distinguish objects with similar appearances but at distinct camera distances. In this paper, from a new perspective, we propose a novel Hierarchical Depth Awareness network (HiDAnet) for RGB-D saliency detection. Our motivation comes from the observation that the multi-granularity properties of geometric priors correlate well with the neural network hierarchies. To realize multi-modal and multi-level fusion, we first use a granularity-based attention scheme to strengthen the discriminatory power of RGB and depth features separately. Then we introduce a unified cross dual-attention module for multi-modal and multi-level fusion in a coarse-to-fine manner. The encoded multi-modal features are gradually aggregated into a shared decoder. Further, we exploit a multi-scale loss to take full advantage of the hierarchical information. Extensive experiments on challenging benchmark datasets demonstrate that our HiDAnet performs favorably over the state-of-the-art methods by large margins.
Multi-compartment Neuron and Population Encoding improved Spiking Neural Network for Deep Distributional Reinforcement Learning
Jan 18, 2023
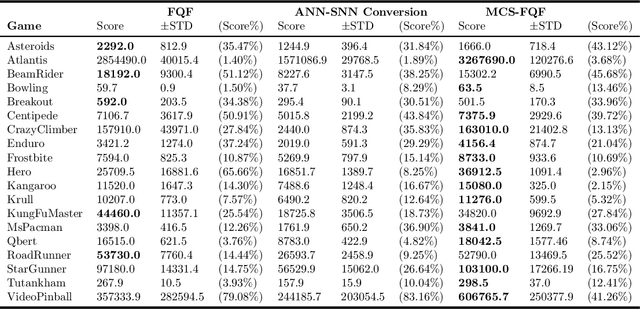
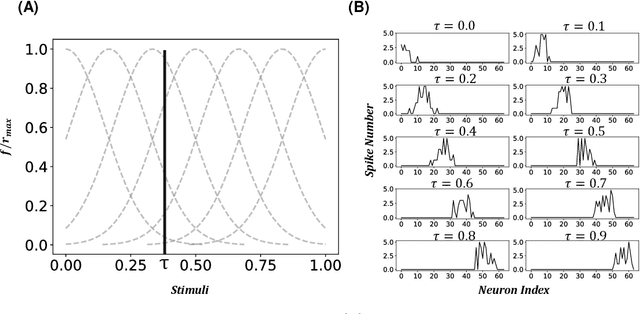
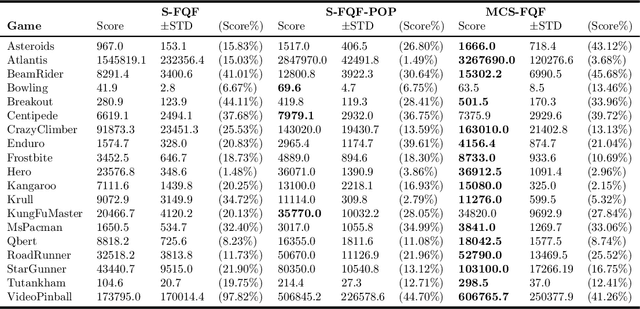
Inspired by the information processing with binary spikes in the brain, the spiking neural networks (SNNs) exhibit significant low energy consumption and are more suitable for incorporating multi-scale biological characteristics. Spiking Neurons, as the basic information processing unit of SNNs, are often simplified in most SNNs which only consider LIF point neuron and do not take into account the multi-compartmental structural properties of biological neurons. This limits the computational and learning capabilities of SNNs. In this paper, we proposed a brain-inspired SNN-based deep distributional reinforcement learning algorithm with combination of bio-inspired multi-compartment neuron (MCN) model and population coding method. The proposed multi-compartment neuron built the structure and function of apical dendritic, basal dendritic, and somatic computing compartments to achieve the computational power close to that of biological neurons. Besides, we present an implicit fractional embedding method based on spiking neuron population encoding. We tested our model on Atari games, and the experiment results show that the performance of our model surpasses the vanilla ANN-based FQF model and ANN-SNN conversion method based Spiking-FQF models. The ablation experiments show that the proposed multi-compartment neural model and quantile fraction implicit population spike representation play an important role in realizing SNN-based deep distributional reinforcement learning.
Label Inference Attack against Split Learning under Regression Setting
Jan 18, 2023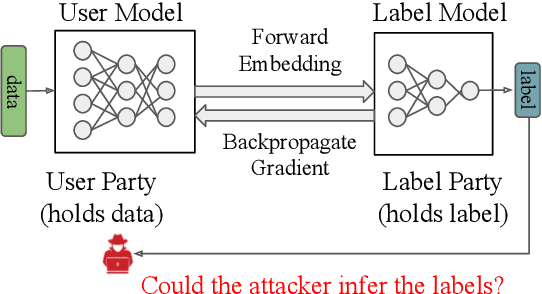
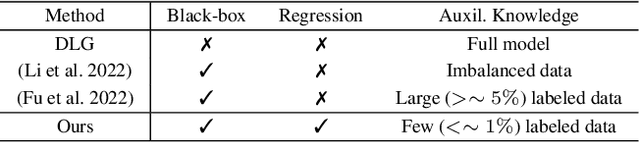
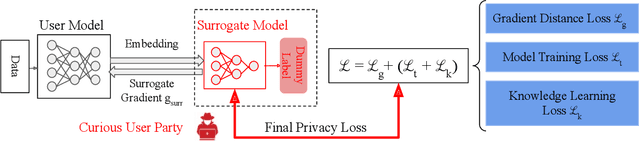
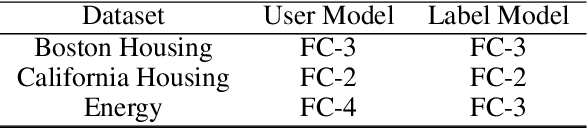
As a crucial building block in vertical Federated Learning (vFL), Split Learning (SL) has demonstrated its practice in the two-party model training collaboration, where one party holds the features of data samples and another party holds the corresponding labels. Such method is claimed to be private considering the shared information is only the embedding vectors and gradients instead of private raw data and labels. However, some recent works have shown that the private labels could be leaked by the gradients. These existing attack only works under the classification setting where the private labels are discrete. In this work, we step further to study the leakage in the scenario of the regression model, where the private labels are continuous numbers (instead of discrete labels in classification). This makes previous attacks harder to infer the continuous labels due to the unbounded output range. To address the limitation, we propose a novel learning-based attack that integrates gradient information and extra learning regularization objectives in aspects of model training properties, which can infer the labels under regression settings effectively. The comprehensive experiments on various datasets and models have demonstrated the effectiveness of our proposed attack. We hope our work can pave the way for future analyses that make the vFL framework more secure.
Chore Cutting: Envy and Truth
Jan 23, 2023We study the fair division of divisible bad resources with strategic agents who can manipulate their private information to get a better allocation. Within certain constraints, we are particularly interested in whether truthful envy-free mechanisms exist over piecewise-constant valuations. We demonstrate that no deterministic truthful envy-free mechanism can exist in the connected-piece scenario, and the same impossibility result occurs for hungry agents. We also show that no deterministic, truthful dictatorship mechanism can satisfy the envy-free criterion, and the same result remains true for non-wasteful constraints rather than dictatorship. We further address several related problems and directions.
3D Colored Shape Reconstruction from a Single RGB Image through Diffusion
Feb 11, 2023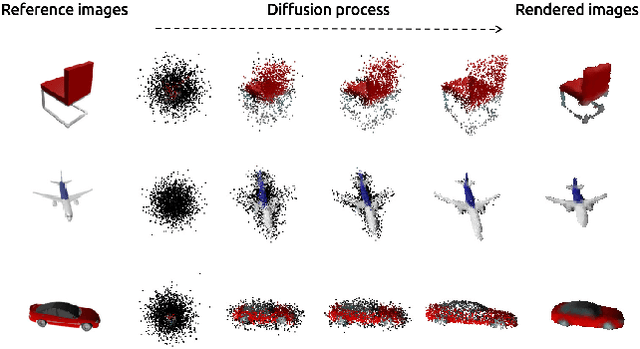
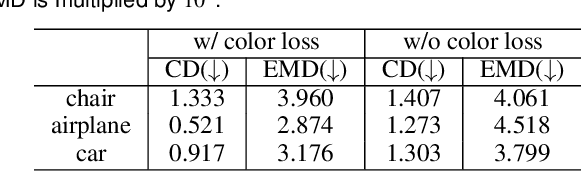
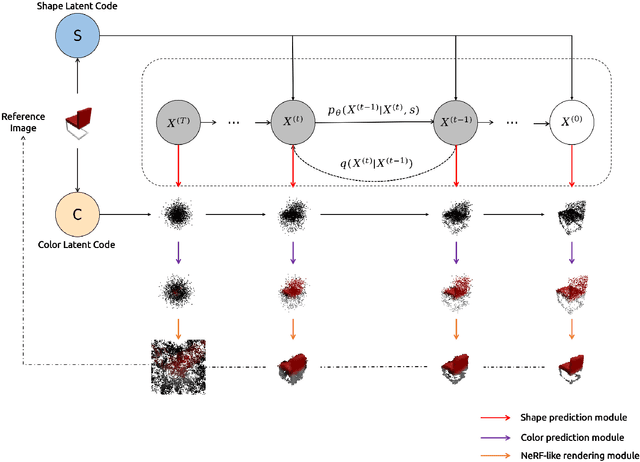
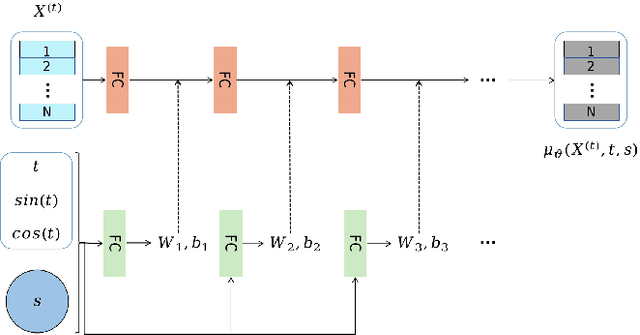
We propose a novel 3d colored shape reconstruction method from a single RGB image through diffusion model. Diffusion models have shown great development potentials for high-quality 3D shape generation. However, most existing work based on diffusion models only focus on geometric shape generation, they cannot either accomplish 3D reconstruction from a single image, or produce 3D geometric shape with color information. In this work, we propose to reconstruct a 3D colored shape from a single RGB image through a novel conditional diffusion model. The reverse process of the proposed diffusion model is consisted of three modules, shape prediction module, color prediction module and NeRF-like rendering module. In shape prediction module, the reference RGB image is first encoded into a high-level shape feature and then the shape feature is utilized as a condition to predict the reverse geometric noise in diffusion model. Then the color of each 3D point updated in shape prediction module is predicted by color prediction module. Finally, a NeRF-like rendering module is designed to render the colored point cloud predicted by the former two modules to 2D image space to guide the training conditioned only on a reference image. As far as the authors know, the proposed method is the first diffusion model for 3D colored shape reconstruction from a single RGB image. Experimental results demonstrate that the proposed method achieves competitive performance on colored 3D shape reconstruction, and the ablation study validates the positive role of the color prediction module in improving the reconstruction quality of 3D geometric point cloud.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022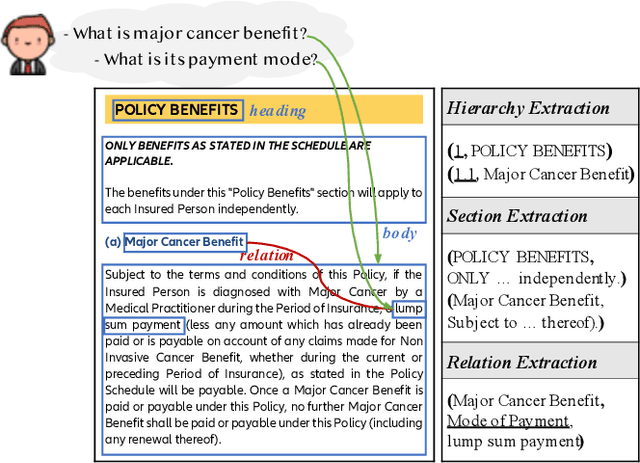
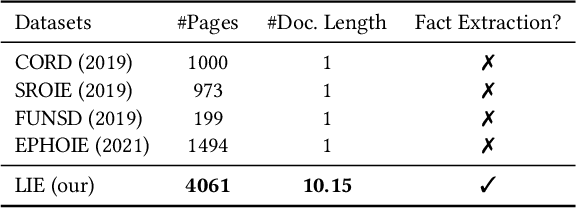

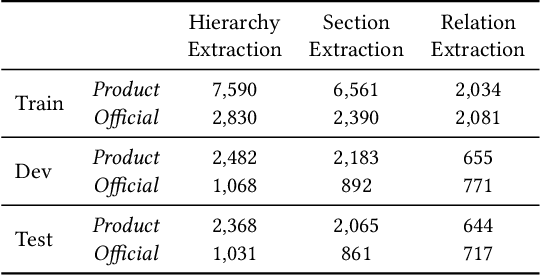
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
QS-ADN: Quasi-Supervised Artifact Disentanglement Network for Low-Dose CT Image Denoising by Local Similarity Among Unpaired Data
Feb 08, 2023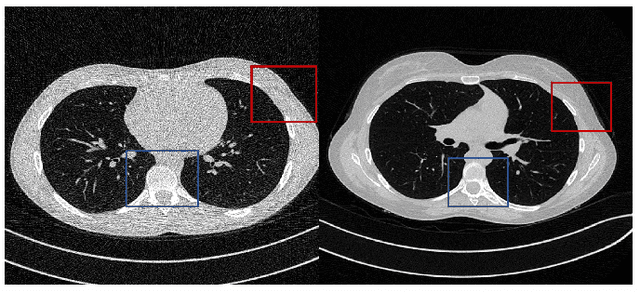
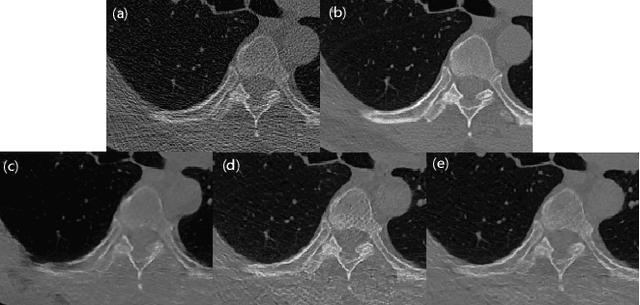
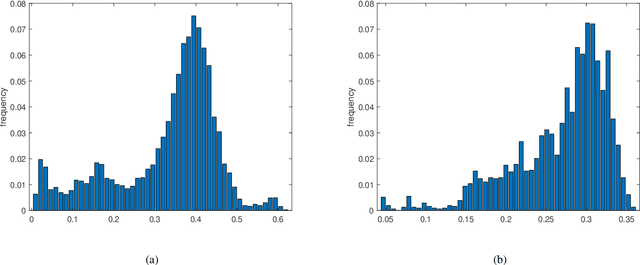
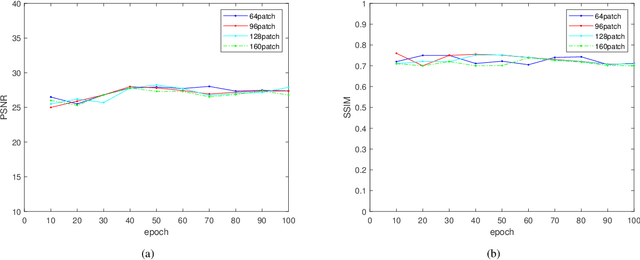
Deep learning has been successfully applied to low-dose CT (LDCT) image denoising for reducing potential radiation risk. However, the widely reported supervised LDCT denoising networks require a training set of paired images, which is expensive to obtain and cannot be perfectly simulated. Unsupervised learning utilizes unpaired data and is highly desirable for LDCT denoising. As an example, an artifact disentanglement network (ADN) relies on unparied images and obviates the need for supervision but the results of artifact reduction are not as good as those through supervised learning.An important observation is that there is often hidden similarity among unpaired data that can be utilized. This paper introduces a new learning mode, called quasi-supervised learning, to empower the ADN for LDCT image denoising.For every LDCT image, the best matched image is first found from an unpaired normal-dose CT (NDCT) dataset. Then, the matched pairs and the corresponding matching degree as prior information are used to construct and train our ADN-type network for LDCT denoising.The proposed method is different from (but compatible with) supervised and semi-supervised learning modes and can be easily implemented by modifying existing networks. The experimental results show that the method is competitive with state-of-the-art methods in terms of noise suppression and contextual fidelity. The code and working dataset are publicly available at https://github.com/ruanyuhui/ADN-QSDL.git.
Using meaning instead of words to track topics
Jan 02, 2023The ability to monitor the evolution of topics over time is extremely valuable for businesses. Currently, all existing topic tracking methods use lexical information by matching word usage. However, no studies has ever experimented with the use of semantic information for tracking topics. Hence, we explore a novel semantic-based method using word embeddings. Our results show that a semantic-based approach to topic tracking is on par with the lexical approach but makes different mistakes. This suggest that both methods may complement each other.