 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
STENCIL: Submodular Mutual Information Based Weak Supervision for Cold-Start Active Learning
Feb 21, 2024
As supervised fine-tuning of pre-trained models within NLP applications increases in popularity, larger corpora of annotated data are required, especially with increasing parameter counts in large language models. Active learning, which attempts to mine and annotate unlabeled instances to improve model performance maximally fast, is a common choice for reducing the annotation cost; however, most methods typically ignore class imbalance and either assume access to initial annotated data or require multiple rounds of active learning selection before improving rare classes. We present STENCIL, which utilizes a set of text exemplars and the recently proposed submodular mutual information to select a set of weakly labeled rare-class instances that are then strongly labeled by an annotator. We show that STENCIL improves overall accuracy by $10\%-24\%$ and rare-class F-1 score by $17\%-40\%$ on multiple text classification datasets over common active learning methods within the class-imbalanced cold-start setting.
Survey in Characterization of Semantic Change
Mar 11, 2024Live languages continuously evolve to integrate the cultural change of human societies. This evolution manifests through neologisms (new words) or \textbf{semantic changes} of words (new meaning to existing words). Understanding the meaning of words is vital for interpreting texts coming from different cultures (regionalism or slang), domains (e.g., technical terms), or periods. In computer science, these words are relevant to computational linguistics algorithms such as translation, information retrieval, question answering, etc. Semantic changes can potentially impact the quality of the outcomes of these algorithms. Therefore, it is important to understand and characterize these changes formally. The study of this impact is a recent problem that has attracted the attention of the computational linguistics community. Several approaches propose methods to detect semantic changes with good precision, but more effort is needed to characterize how the meaning of words changes and to reason about how to reduce the impact of semantic change. This survey provides an understandable overview of existing approaches to the \textit{characterization of semantic changes} and also formally defines three classes of characterizations: if the meaning of a word becomes more general or narrow (change in dimension) if the word is used in a more pejorative or positive/ameliorated sense (change in orientation), and if there is a trend to use the word in a, for instance, metaphoric or metonymic context (change in relation). We summarized the main aspects of the selected publications in a table and discussed the needs and trends in the research activities on semantic change characterization.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Mar 11, 2024
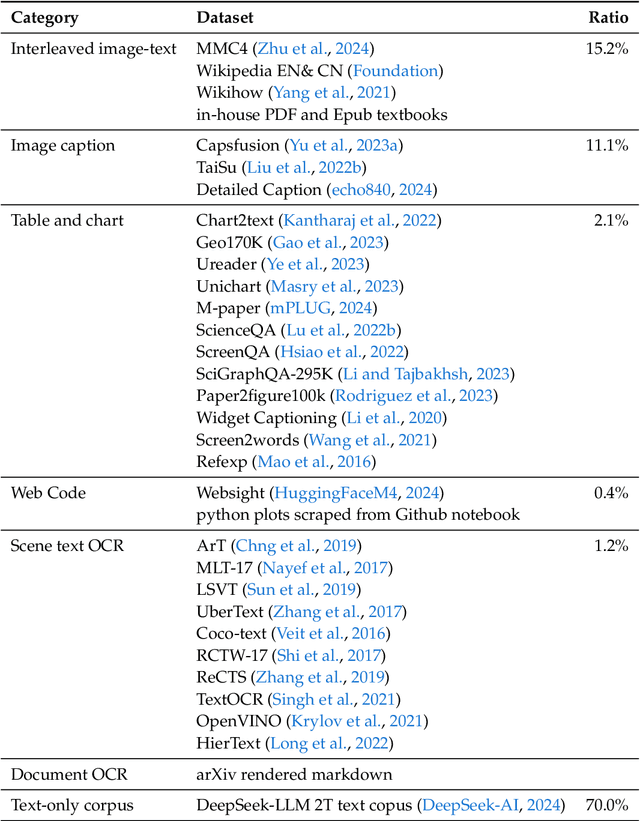
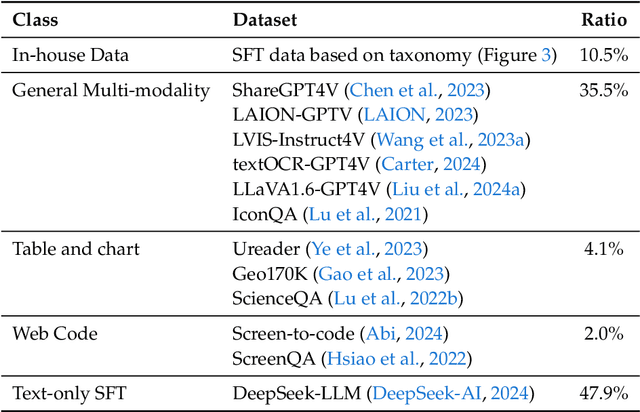
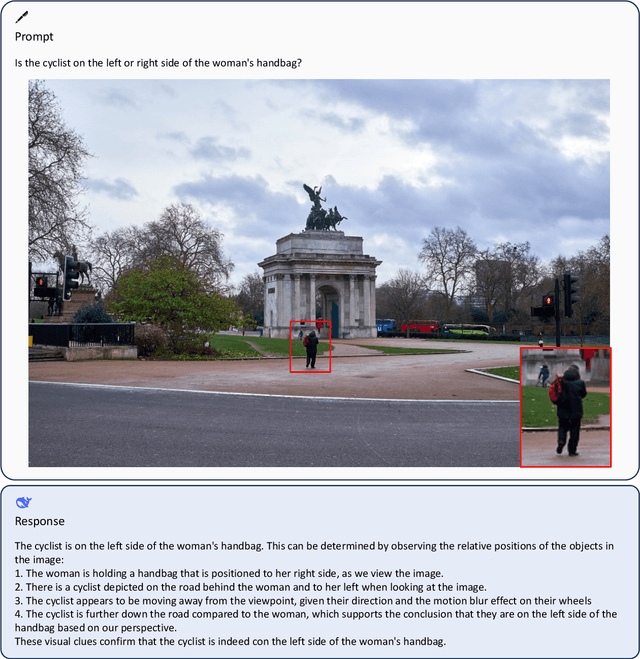
We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model's user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model's ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.
Heterogeneous Image-based Classification Using Distributional Data Analysis
Mar 11, 2024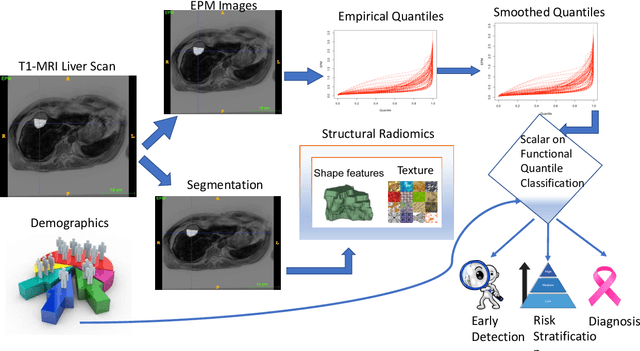
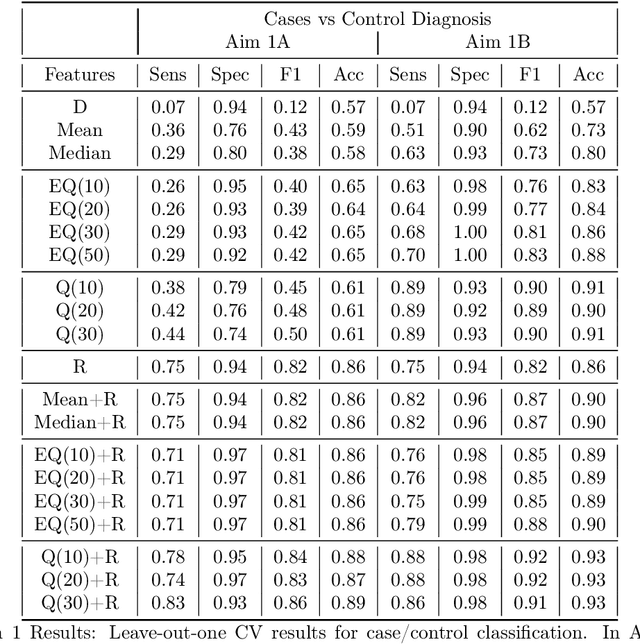
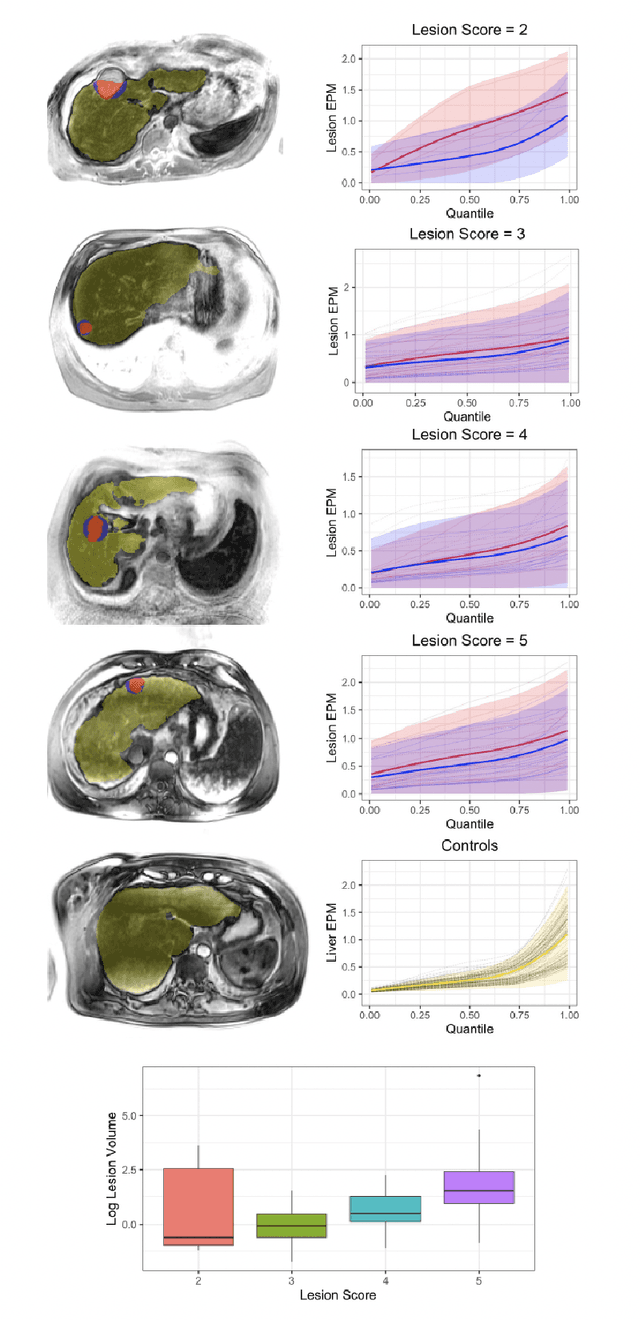
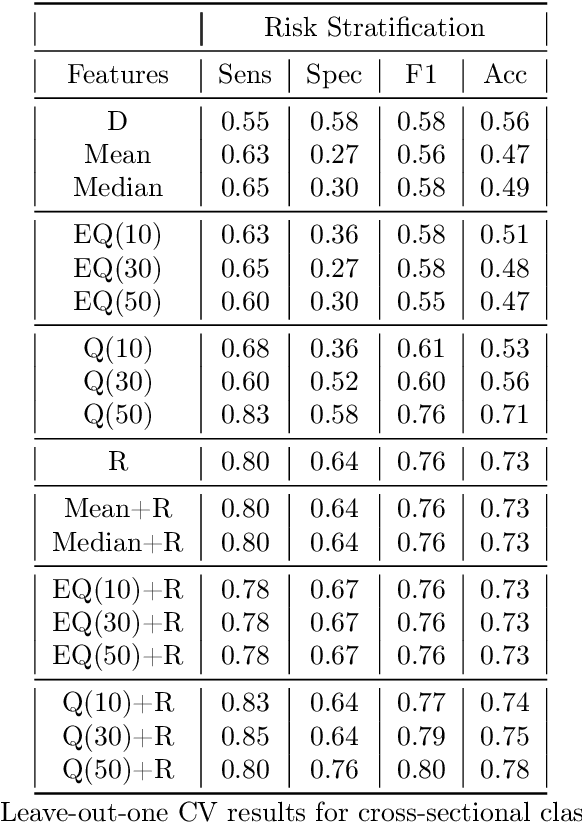
Diagnostic imaging has gained prominence as potential biomarkers for early detection and diagnosis in a diverse array of disorders including cancer. However, existing methods routinely face challenges arising from various factors such as image heterogeneity. We develop a novel imaging-based distributional data analysis (DDA) approach that incorporates the probability (quantile) distribution of the pixel-level features as covariates. The proposed approach uses a smoothed quantile distribution (via a suitable basis representation) as functional predictors in a scalar-on-functional quantile regression model. Some distinctive features of the proposed approach include the ability to: (i) account for heterogeneity within the image; (ii) incorporate granular information spanning the entire distribution; and (iii) tackle variability in image sizes for unregistered images in cancer applications. Our primary goal is risk prediction in Hepatocellular carcinoma that is achieved via predicting the change in tumor grades at post-diagnostic visits using pre-diagnostic enhancement pattern mapping (EPM) images of the liver. Along the way, the proposed DDA approach is also used for case versus control diagnosis and risk stratification objectives. Our analysis reveals that when coupled with global structural radiomics features derived from the corresponding T1-MRI scans, the proposed smoothed quantile distributions derived from EPM images showed considerable improvements in sensitivity and comparable specificity in contrast to classification based on routinely used summary measures that do not account for image heterogeneity. Given that there are limited predictive modeling approaches based on heterogeneous images in cancer, the proposed method is expected to provide considerable advantages in image-based early detection and risk prediction.
Disentangled Diffusion-Based 3D Human Pose Estimation with Hierarchical Spatial and Temporal Denoiser
Mar 07, 2024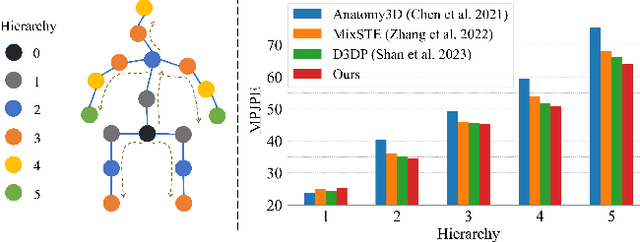
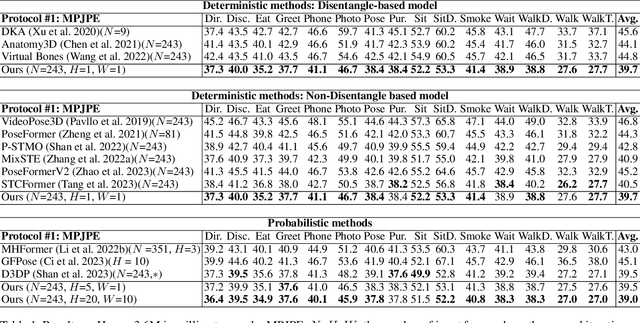
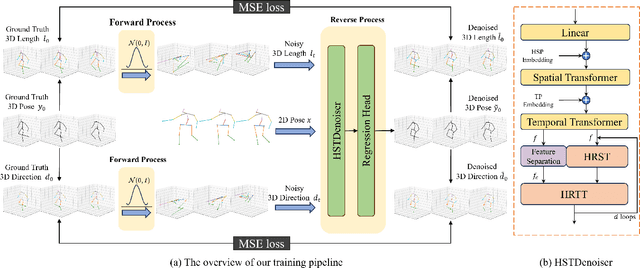

Recently, diffusion-based methods for monocular 3D human pose estimation have achieved state-of-the-art (SOTA) performance by directly regressing the 3D joint coordinates from the 2D pose sequence. Although some methods decompose the task into bone length and bone direction prediction based on the human anatomical skeleton to explicitly incorporate more human body prior constraints, the performance of these methods is significantly lower than that of the SOTA diffusion-based methods. This can be attributed to the tree structure of the human skeleton. Direct application of the disentangled method could amplify the accumulation of hierarchical errors, propagating through each hierarchy. Meanwhile, the hierarchical information has not been fully explored by the previous methods. To address these problems, a Disentangled Diffusion-based 3D Human Pose Estimation method with Hierarchical Spatial and Temporal Denoiser is proposed, termed DDHPose. In our approach: (1) We disentangle the 3D pose and diffuse the bone length and bone direction during the forward process of the diffusion model to effectively model the human pose prior. A disentanglement loss is proposed to supervise diffusion model learning. (2) For the reverse process, we propose Hierarchical Spatial and Temporal Denoiser (HSTDenoiser) to improve the hierarchical modeling of each joint. Our HSTDenoiser comprises two components: the Hierarchical-Related Spatial Transformer (HRST) and the Hierarchical-Related Temporal Transformer (HRTT). HRST exploits joint spatial information and the influence of the parent joint on each joint for spatial modeling, while HRTT utilizes information from both the joint and its hierarchical adjacent joints to explore the hierarchical temporal correlations among joints.
Model-Predictive Trajectory Generation for Autonomous Aerial Search and Coverage
Mar 09, 2024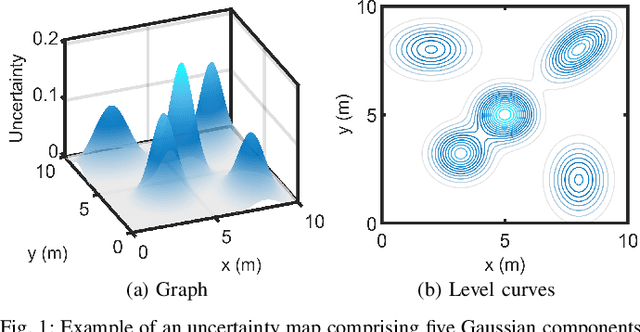
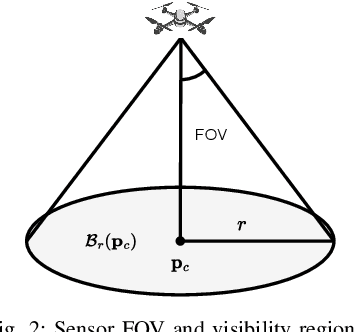
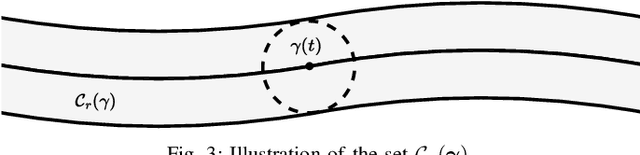
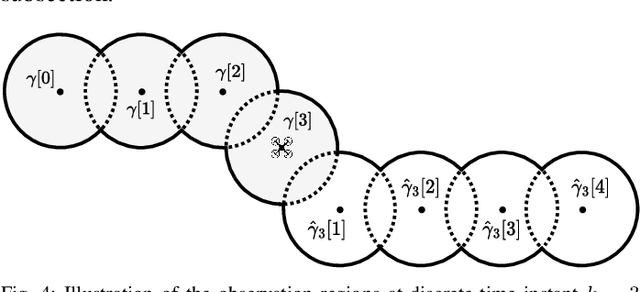
This paper addresses the trajectory planning problem for search and coverage missions with an Unmanned Aerial Vehicle (UAV). The objective is to devise optimal coverage trajectories based on a utility map describing prior region information, assumed to be effectively approximated by a Gaussian Mixture Model (GMM). We introduce a Model Predictive Control (MPC) algorithm employing a relaxed formulation that promotes the exploration of the map by preventing the UAV from revisiting previously covered areas. This is achieved by penalizing intersections between the UAV's visibility regions along its trajectory. The algorithm is assessed in MATLAB and validated in Gazebo, as well as in outdoor experimental tests. The results show that the proposed strategy can generate efficient and smooth trajectories for search and coverage missions.
DP-TabICL: In-Context Learning with Differentially Private Tabular Data
Mar 08, 2024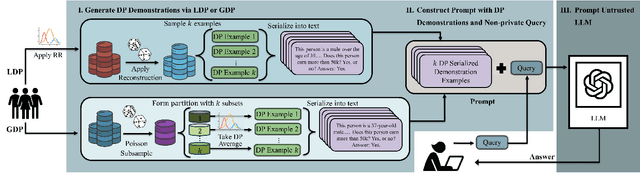

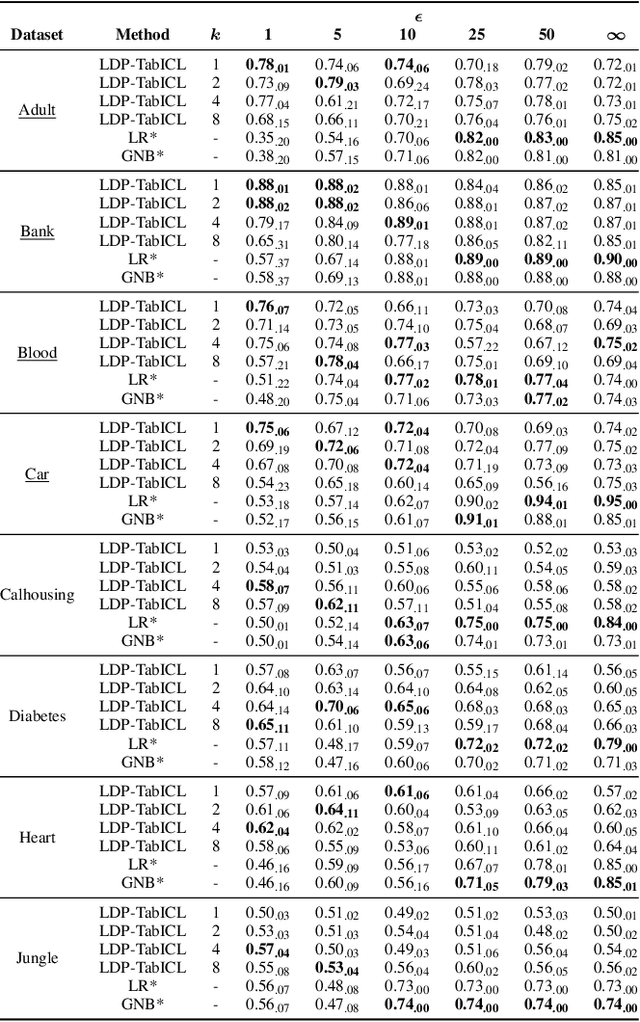
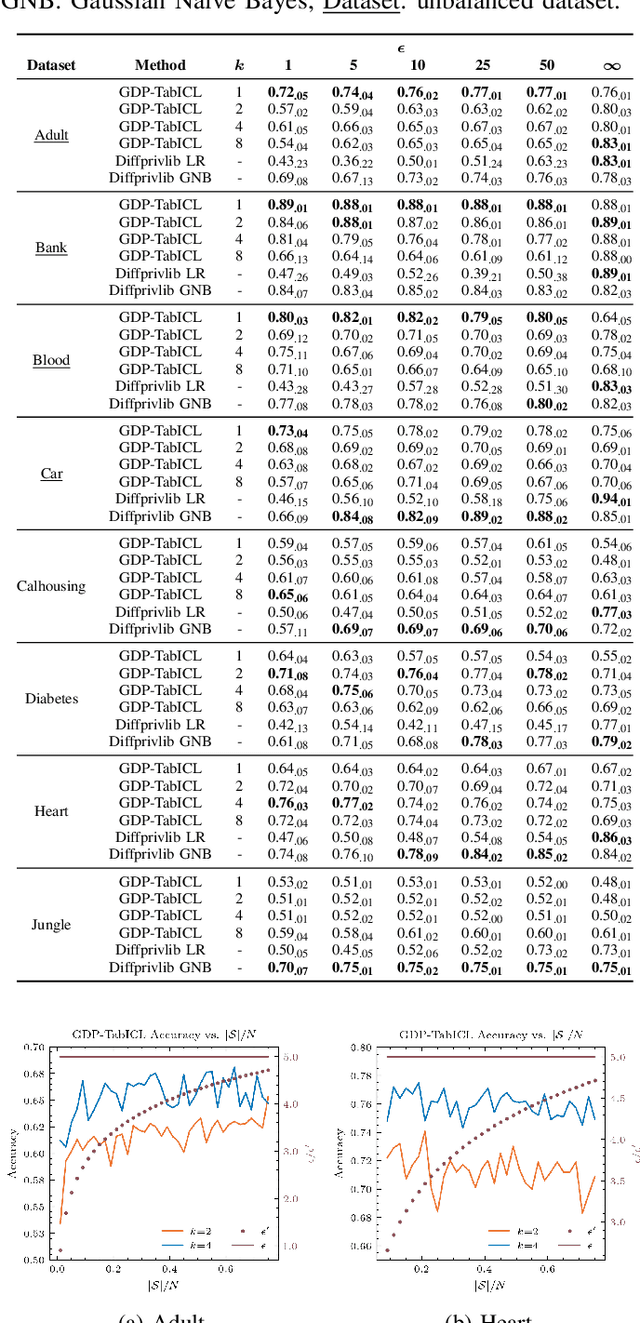
In-context learning (ICL) enables large language models (LLMs) to adapt to new tasks by conditioning on demonstrations of question-answer pairs and it has been shown to have comparable performance to costly model retraining and fine-tuning. Recently, ICL has been extended to allow tabular data to be used as demonstration examples by serializing individual records into natural language formats. However, it has been shown that LLMs can leak information contained in prompts, and since tabular data often contain sensitive information, understanding how to protect the underlying tabular data used in ICL is a critical area of research. This work serves as an initial investigation into how to use differential privacy (DP) -- the long-established gold standard for data privacy and anonymization -- to protect tabular data used in ICL. Specifically, we investigate the application of DP mechanisms for private tabular ICL via data privatization prior to serialization and prompting. We formulate two private ICL frameworks with provable privacy guarantees in both the local (LDP-TabICL) and global (GDP-TabICL) DP scenarios via injecting noise into individual records or group statistics, respectively. We evaluate our DP-based frameworks on eight real-world tabular datasets and across multiple ICL and DP settings. Our evaluations show that DP-based ICL can protect the privacy of the underlying tabular data while achieving comparable performance to non-LLM baselines, especially under high privacy regimes.
Persona Extraction Through Semantic Similarity for Emotional Support Conversation Generation
Mar 07, 2024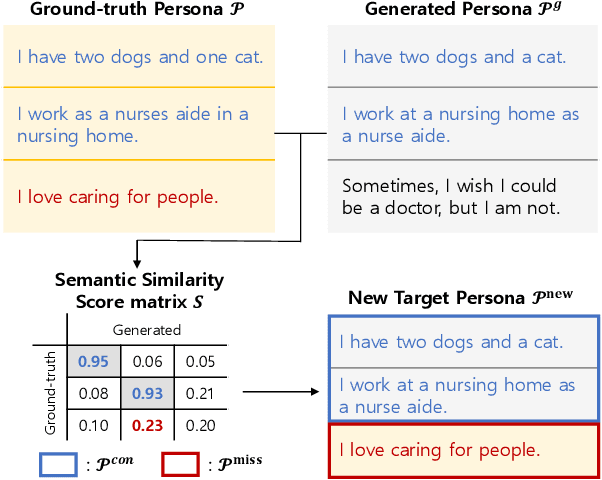


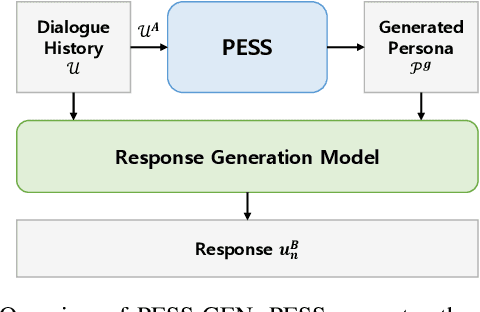
Providing emotional support through dialogue systems is becoming increasingly important in today's world, as it can support both mental health and social interactions in many conversation scenarios. Previous works have shown that using persona is effective for generating empathetic and supportive responses. They have often relied on pre-provided persona rather than inferring them during conversations. However, it is not always possible to obtain a user persona before the conversation begins. To address this challenge, we propose PESS (Persona Extraction through Semantic Similarity), a novel framework that can automatically infer informative and consistent persona from dialogues. We devise completeness loss and consistency loss based on semantic similarity scores. The completeness loss encourages the model to generate missing persona information, and the consistency loss guides the model to distinguish between consistent and inconsistent persona. Our experimental results demonstrate that high-quality persona information inferred by PESS is effective in generating emotionally supportive responses.
ColBERT-XM: A Modular Multi-Vector Representation Model for Zero-Shot Multilingual Information Retrieval
Feb 23, 2024State-of-the-art neural retrievers predominantly focus on high-resource languages like English, which impedes their adoption in retrieval scenarios involving other languages. Current approaches circumvent the lack of high-quality labeled data in non-English languages by leveraging multilingual pretrained language models capable of cross-lingual transfer. However, these models require substantial task-specific fine-tuning across multiple languages, often perform poorly in languages with minimal representation in the pretraining corpus, and struggle to incorporate new languages after the pretraining phase. In this work, we present a novel modular dense retrieval model that learns from the rich data of a single high-resource language and effectively zero-shot transfers to a wide array of languages, thereby eliminating the need for language-specific labeled data. Our model, ColBERT-XM, demonstrates competitive performance against existing state-of-the-art multilingual retrievers trained on more extensive datasets in various languages. Further analysis reveals that our modular approach is highly data-efficient, effectively adapts to out-of-distribution data, and significantly reduces energy consumption and carbon emissions. By demonstrating its proficiency in zero-shot scenarios, ColBERT-XM marks a shift towards more sustainable and inclusive retrieval systems, enabling effective information accessibility in numerous languages. We publicly release our code and models for the community.
The 6th Affective Behavior Analysis in-the-wild (ABAW) Competition
Mar 10, 2024This paper describes the 6th Affective Behavior Analysis in-the-wild (ABAW) Competition, which is part of the respective Workshop held in conjunction with IEEE CVPR 2024. The 6th ABAW Competition addresses contemporary challenges in understanding human emotions and behaviors, crucial for the development of human-centered technologies. In more detail, the Competition focuses on affect related benchmarking tasks and comprises of five sub-challenges: i) Valence-Arousal Estimation (the target is to estimate two continuous affect dimensions, valence and arousal), ii) Expression Recognition (the target is to recognise between the mutually exclusive classes of the 7 basic expressions and 'other'), iii) Action Unit Detection (the target is to detect 12 action units), iv) Compound Expression Recognition (the target is to recognise between the 7 mutually exclusive compound expression classes), and v) Emotional Mimicry Intensity Estimation (the target is to estimate six continuous emotion dimensions). In the paper, we present these Challenges, describe their respective datasets and challenge protocols (we outline the evaluation metrics) and present the baseline systems as well as their obtained performance. More information for the Competition can be found in: https://affective-behavior-analysis-in-the-wild.github.io/6th.