 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fine-grained Affordance Annotation for Egocentric Hand-Object Interaction Videos
Feb 10, 2023
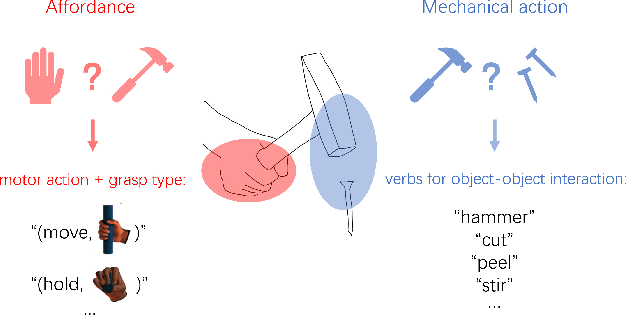


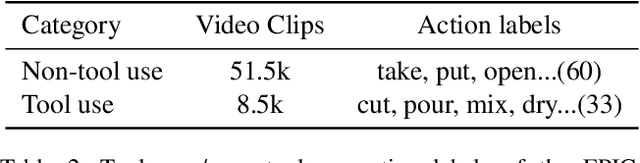
Object affordance is an important concept in hand-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, the definition of affordance in existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition, hand-object interaction hotspots prediction, and cross-domain evaluation of affordance. The results show that models trained with our annotation can distinguish affordance from other concepts, predict fine-grained interaction possibilities on objects, and generalize through different domains.
Exploiting Graph Structured Cross-Domain Representation for Multi-Domain Recommendation
Feb 12, 2023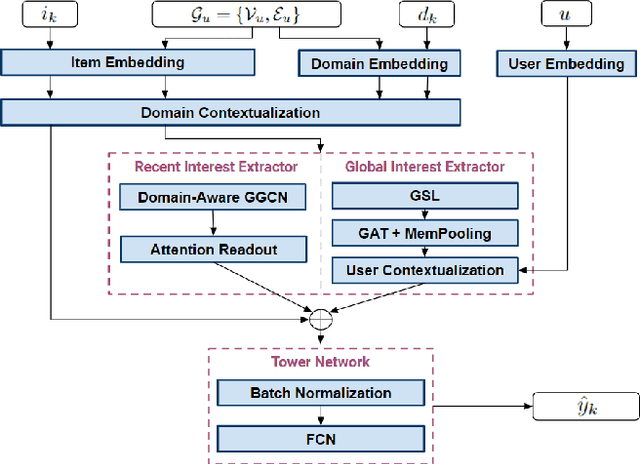
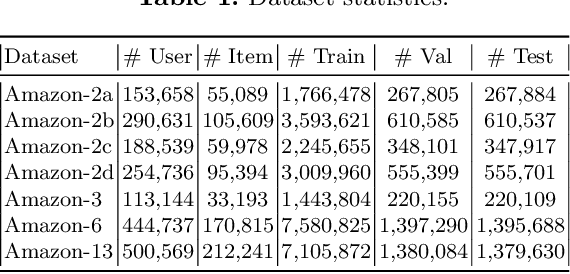
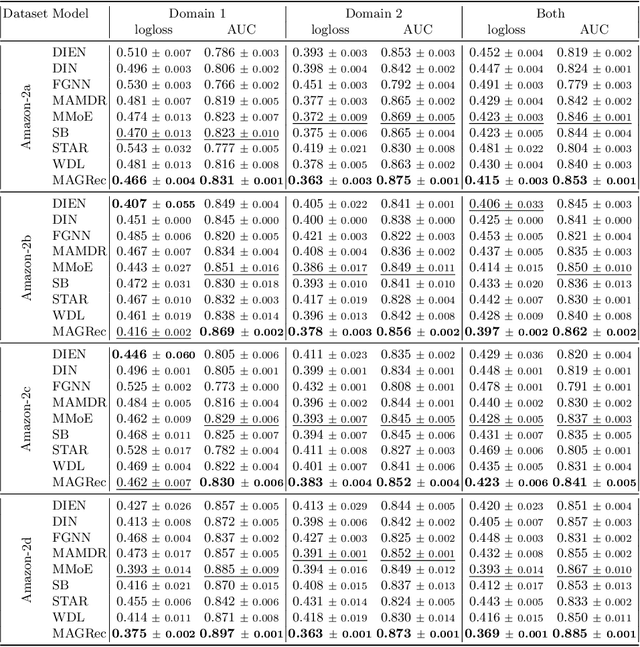
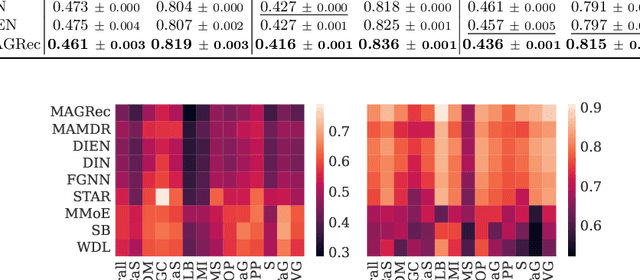
Multi-domain recommender systems benefit from cross-domain representation learning and positive knowledge transfer. Both can be achieved by introducing a specific modeling of input data (i.e. disjoint history) or trying dedicated training regimes. At the same time, treating domains as separate input sources becomes a limitation as it does not capture the interplay that naturally exists between domains. In this work, we efficiently learn multi-domain representation of sequential users' interactions using graph neural networks. We use temporal intra- and inter-domain interactions as contextual information for our method called MAGRec (short for Multi-domAin Graph-based Recommender). To better capture all relations in a multi-domain setting, we learn two graph-based sequential representations simultaneously: domain-guided for recent user interest, and general for long-term interest. This approach helps to mitigate the negative knowledge transfer problem from multiple domains and improve overall representation. We perform experiments on publicly available datasets in different scenarios where MAGRec consistently outperforms state-of-the-art methods. Furthermore, we provide an ablation study and discuss further extensions of our method.
Neural Node Matching for Multi-Target Cross Domain Recommendation
Feb 12, 2023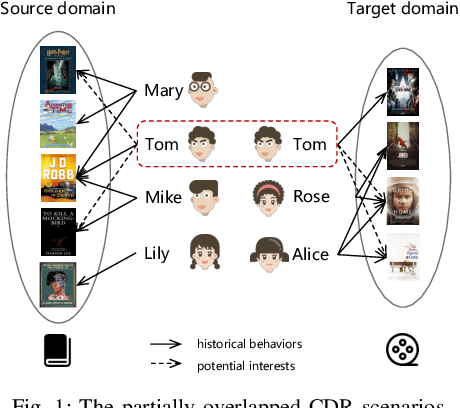
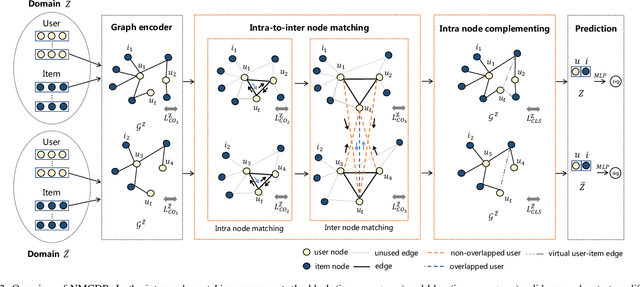
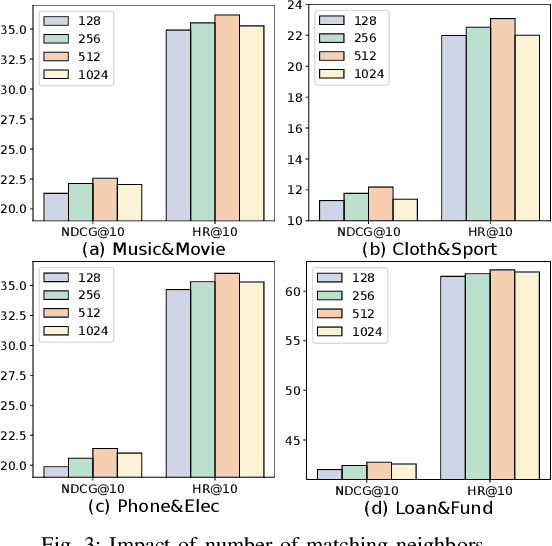
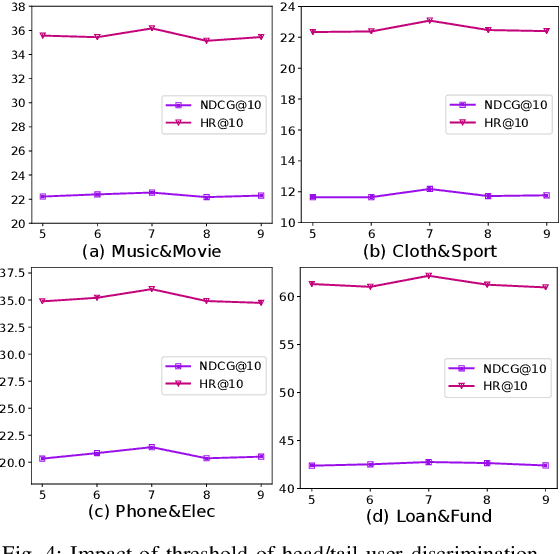
Multi-Target Cross Domain Recommendation(CDR) has attracted a surge of interest recently, which intends to improve the recommendation performance in multiple domains (or systems) simultaneously. Most existing multi-target CDR frameworks primarily rely on the existence of the majority of overlapped users across domains. However, general practical CDR scenarios cannot meet the strictly overlapping requirements and only share a small margin of common users across domains}. Additionally, the majority of users have quite a few historical behaviors in such small-overlapping CDR scenarios}. To tackle the aforementioned issues, we propose a simple-yet-effective neural node matching based framework for more general CDR settings, i.e., only (few) partially overlapped users exist across domains and most overlapped as well as non-overlapped users do have sparse interactions. The present framework} mainly contains two modules: (i) intra-to-inter node matching module, and (ii) intra node complementing module. Concretely, the first module conducts intra-knowledge fusion within each domain and subsequent inter-knowledge fusion across domains by fully connected user-user homogeneous graph information aggregating.
* 13pages
Digging Deeper: Operator Analysis for Optimizing Nonlinearity of Boolean Functions
Feb 12, 2023

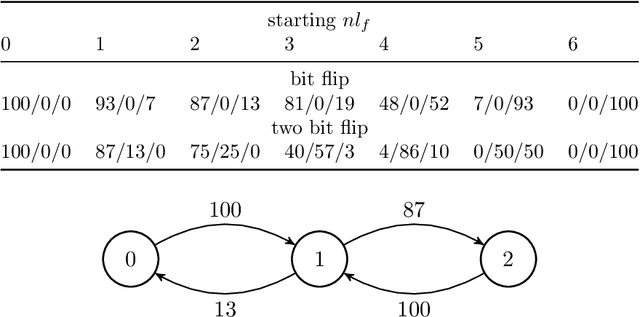
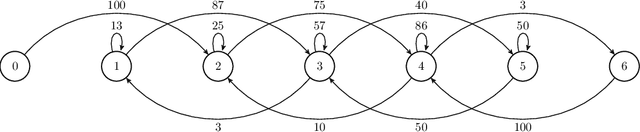
Boolean functions are mathematical objects with numerous applications in domains like coding theory, cryptography, and telecommunications. Finding Boolean functions with specific properties is a complex combinatorial optimization problem where the search space grows super-exponentially with the number of input variables. One common property of interest is the nonlinearity of Boolean functions. Constructing highly nonlinear Boolean functions is difficult as it is not always known what nonlinearity values can be reached in practice. In this paper, we investigate the effects of the genetic operators for bit-string encoding in optimizing nonlinearity. While several mutation and crossover operators have commonly been used, the link between the genotype they operate on and the resulting phenotype changes is mostly obscure. By observing the range of possible changes an operator can provide, as well as relative probabilities of specific transitions in the objective space, one can use this information to design a more effective combination of genetic operators. The analysis reveals interesting insights into operator effectiveness and indicates how algorithm design may improve convergence compared to an operator-agnostic genetic algorithm.
TAP: The Attention Patch for Cross-Modal Knowledge Transfer from Unlabeled Data
Feb 04, 2023
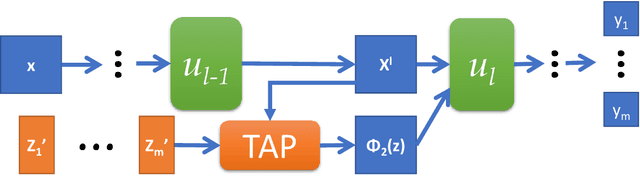
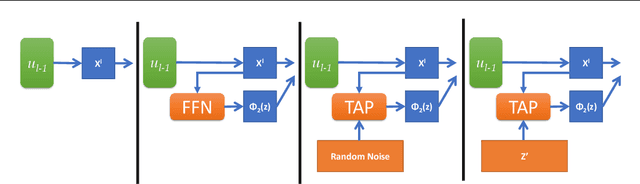
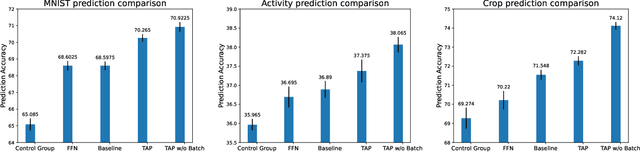
This work investigates the intersection of cross modal learning and semi supervised learning, where we aim to improve the supervised learning performance of the primary modality by borrowing missing information from an unlabeled modality. We investigate this problem from a Nadaraya Watson (NW) kernel regression perspective and show that this formulation implicitly leads to a kernelized cross attention module. To this end, we propose The Attention Patch (TAP), a simple neural network plugin that allows data level knowledge transfer from the unlabeled modality. We provide numerical simulations on three real world datasets to examine each aspect of TAP and show that a TAP integration in a neural network can improve generalization performance using the unlabeled modality.
CitationSum: Citation-aware Graph Contrastive Learning for Scientific Paper Summarization
Feb 01, 2023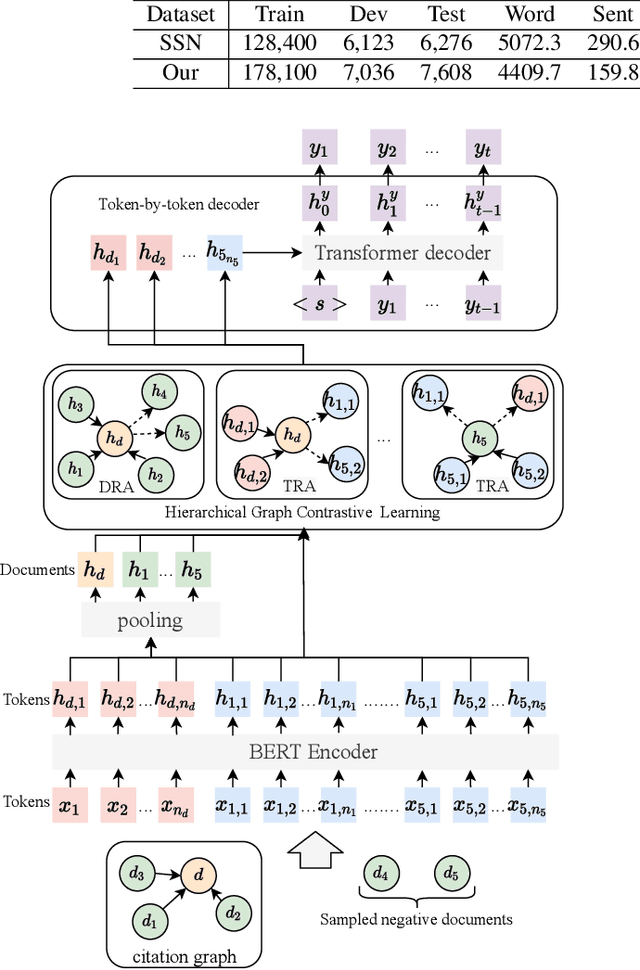

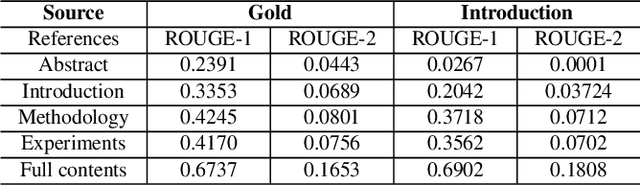
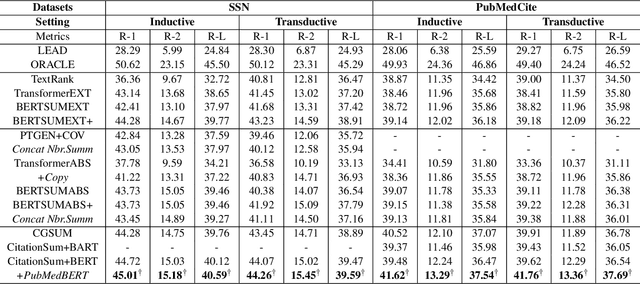
The citation graph is essential for generating high-quality summaries of scientific papers, in which references of a scientific paper and their correlations provide extra knowledge for understanding its background and main contributions. Despite the promising role of the citation graph, effectively incorporating it still remains a big challenge, given the difficulty of accurately identifying and leveraging relevant contents in references for a source paper, as well as modelling their correlations of different intensities. Existing methods either ignore or utilize only abstracts indiscriminately from references, failing to tackle the challenge mentioned above. To fill the gap, we propose a novel citation-aware scientific paper summarization framework based on the citation graph, with the ability to accurately locate and incorporate the salient contents from references, as well as capture varying relevance between source papers and their references. Specifically, we first build a domain-specific dataset PubMedCite with about 192K biomedical scientific papers and a large citation graph preserving 917K citation relationships between them. It is characterized by preserving the salient contents extracted from full texts of references, and the weighted correlation between the salient contents of references and the source paper. Based on it, we design a self-supervised citation-aware summarization framework (CitationSum) with graph contrastive learning, which boosts the summarization generation by efficiently fusing the salient information in references with source paper contents under the guidance of their correlations. Experimental results show that our model outperforms the state-of-the-art methods, due to efficiently leveraging the information of references and citation correlations.
Adaptive Test Generation Using a Large Language Model
Feb 20, 2023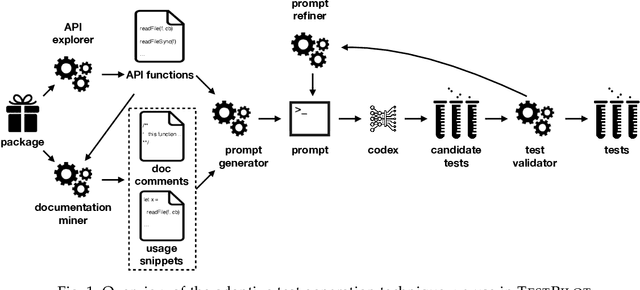
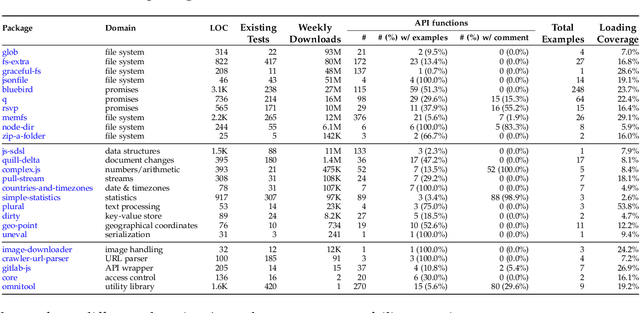

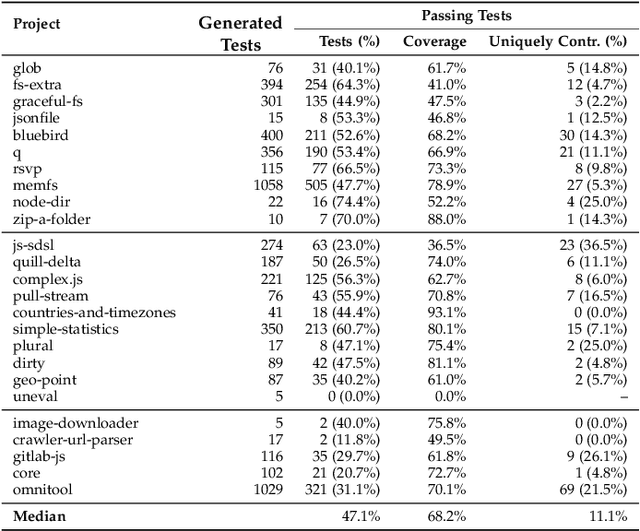
Unit tests play a key role in ensuring the correctness of software. However, manually creating unit tests is a laborious task, motivating the need for automation. This paper presents TestPilot, an adaptive test generation technique that leverages Large Language Models (LLMs). TestPilot uses Codex, an off-the-shelf LLM, to automatically generate unit tests for a given program without requiring additional training or few-shot learning on examples of existing tests. In our approach, Codex is provided with prompts that include the signature and implementation of a function under test, along with usage examples extracted from documentation. If a generated test fails, TestPilot's adaptive component attempts to generate a new test that fixes the problem by re-prompting the model with the failing test and error message. We created an implementation of TestPilot for JavaScript and evaluated it on 25 npm packages with a total of 1,684 API functions to generate tests for. Our results show that the generated tests achieve up to 93.1% statement coverage (median 68.2%). Moreover, on average, 58.5% of the generated tests contain at least one assertion that exercises functionality from the package under test. Our experiments with excluding parts of the information included in the prompts show that all components contribute towards the generation of effective test suites. Finally, we find that TestPilot does not generate memorized tests: 92.7% of our generated tests have $\leq$ 50% similarity with existing tests (as measured by normalized edit distance), with none of them being exact copies.
Exploiting Hierarchical Dependence Structures for Unsupervised Rank Fusion in Information Retrieval
Aug 10, 2022
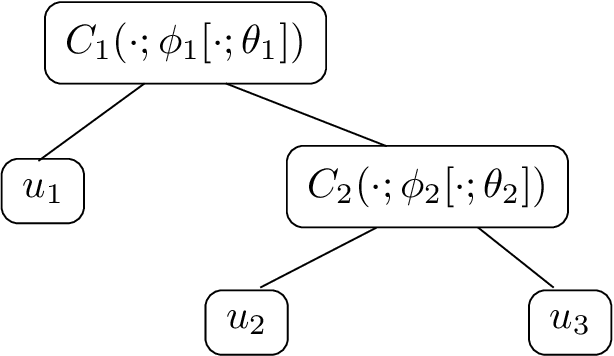
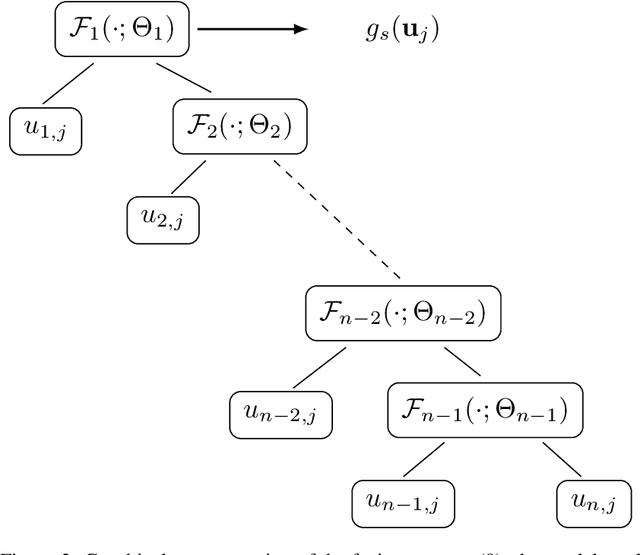
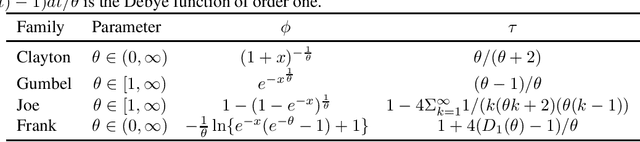
The goal of rank fusion in information retrieval (IR) is to deliver a single output list from multiple search results. Improving performance by combining the outputs of various IR systems is a challenging task. A central point is the fact that many non-obvious factors are involved in the estimation of relevance, inducing nonlinear interrelations between the data. The ability to model complex dependency relationships between random variables has become increasingly popular in the realm of information retrieval, and the need to further explore these dependencies for data fusion has been recently acknowledged. Copulas provide a framework to separate the dependence structure from the margins. Inspired by the theory of copulas, we propose a new unsupervised, dynamic, nonlinear, rank fusion method, based on a nested composition of non-algebraic function pairs. The dependence structure of the model is tailored by leveraging query-document correlations on a per-query basis. We experimented with three topic sets over CLEF corpora fusing 3 and 6 retrieval systems, comparing our method against the CombMNZ technique and other nonlinear unsupervised strategies. The experiments show that our fusion approach improves performance under explicit conditions, providing insight about the circumstances under which linear fusion techniques have comparable performance to nonlinear methods.
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023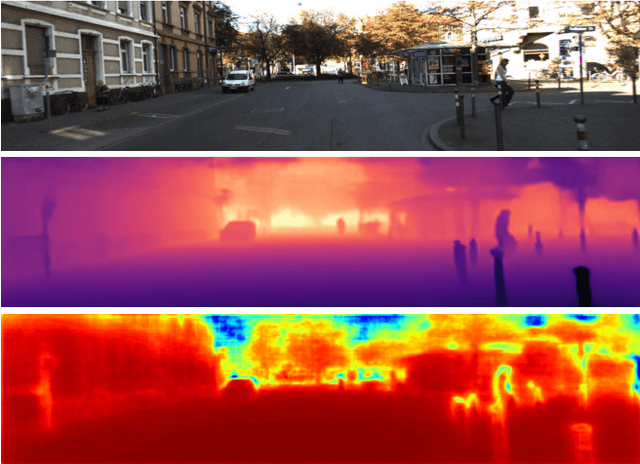
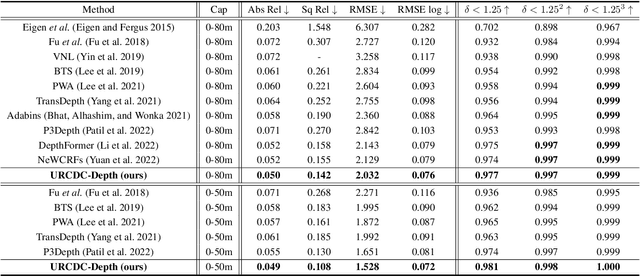
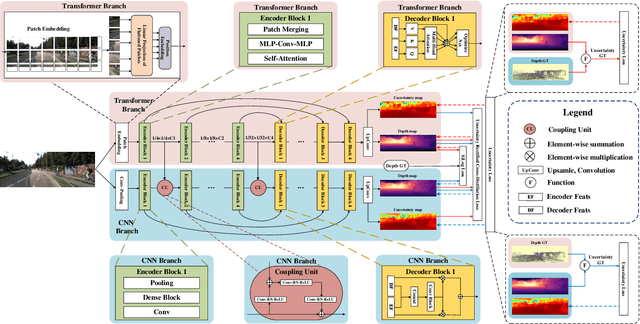
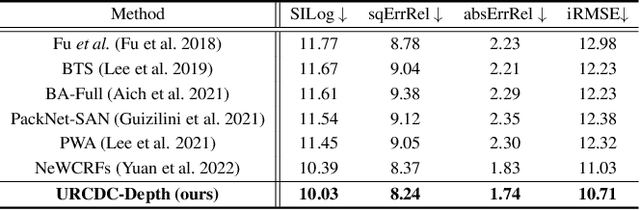
This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.
Detection of Epilepsy Seizure using Different Dimensionality Reduction Techniques and Machine Learning on Transform Domain
Feb 17, 2023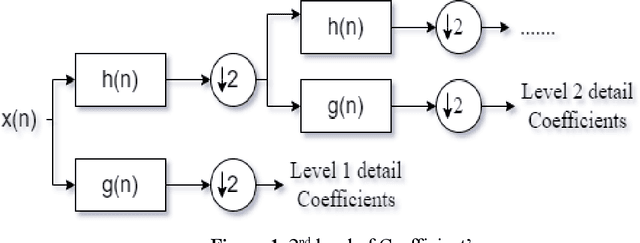
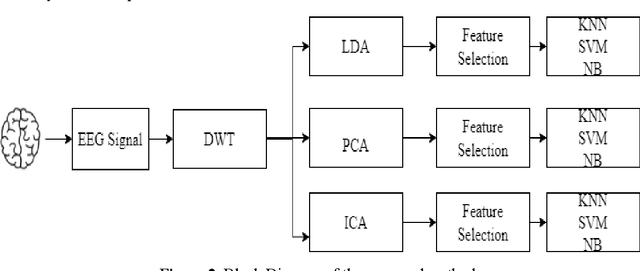
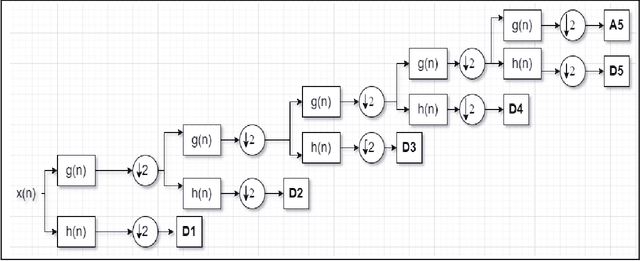
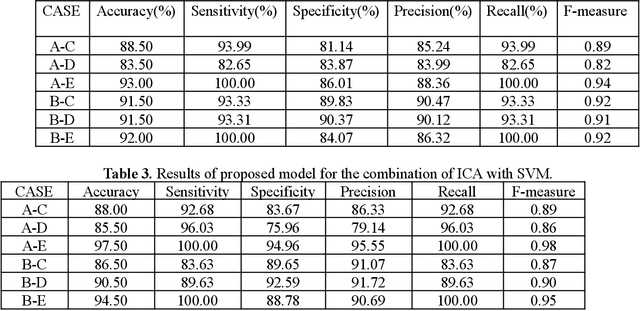
An Electroencephalogram (EEG) is a non-invasive exam that records the electrical activity of the brain. This exam is used to help diagnose conditions such as different brain problems. EEG signals are taken for the purpose of epilepsy detection and with Discrete Wavelet Transform (DWT) and machine learning classifier, they perform epilepsy detection. In Epilepsy seizure detection, mainly machine learning classifiers and statistical features are used. The hidden information in the EEG signal is useful for detecting diseases affecting the brain. Sometimes it is very difficult to identify the minimum changes in the EEG in time and frequency domains purpose. The DWT can give a good decomposition of the signals in different frequency bands and feature extraction. We use the tri-dimensionality reduction algorithm.; Principal Component Analysis (PCA), Independent Component Analysis (ICA) and Linear Discriminant Analysis (LDA). Finally, features are selected by using a fusion rule and at the last step three different classifiers Support Vector Machine (SVM), Naive Bayes (NB) and K-Nearest-Neighbor (KNN) has been used for the classification. The proposed framework is tested on the Bonn dataset and the simulation results provide the maximum accuracy for the combination of LDA and NB for 10-fold cross validation technique. It shows the maximum average sensitivity, specificity, accuracy, Precision and Recall of 100%, 100%, 100%, 100% and 100%. The results prove the effectiveness of this model.