 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Extraction and Human-Robot Dialogue towards Real-life Tasks: A Baseline Study with the MobileCS Dataset
Sep 27, 2022
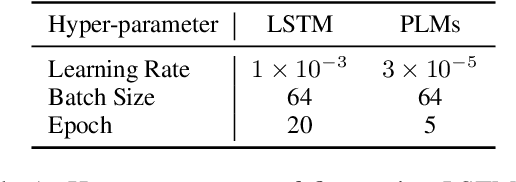
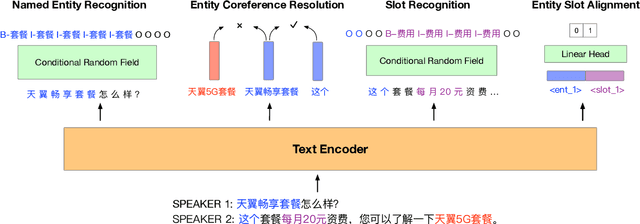
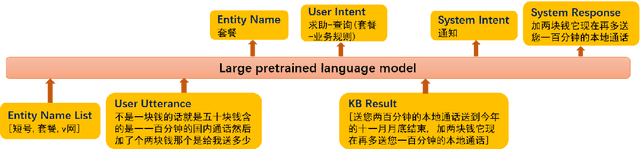

Recently, there have merged a class of task-oriented dialogue (TOD) datasets collected through Wizard-of-Oz simulated games. However, the Wizard-of-Oz data are in fact simulated data and thus are fundamentally different from real-life conversations, which are more noisy and casual. Recently, the SereTOD challenge is organized and releases the MobileCS dataset, which consists of real-world dialog transcripts between real users and customer-service staffs from China Mobile. Based on the MobileCS dataset, the SereTOD challenge has two tasks, not only evaluating the construction of the dialogue system itself, but also examining information extraction from dialog transcripts, which is crucial for building the knowledge base for TOD. This paper mainly presents a baseline study of the two tasks with the MobileCS dataset. We introduce how the two baselines are constructed, the problems encountered, and the results. We anticipate that the baselines can facilitate exciting future research to build human-robot dialogue systems for real-life tasks.
ChemVise: Maximizing Out-of-Distribution Chemical Detection with the Novel Application of Zero-Shot Learning
Feb 09, 2023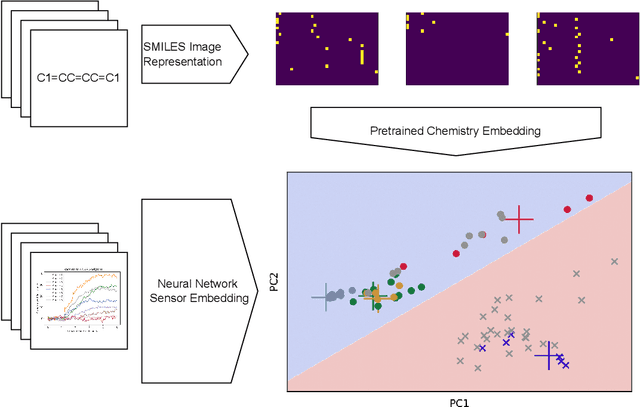
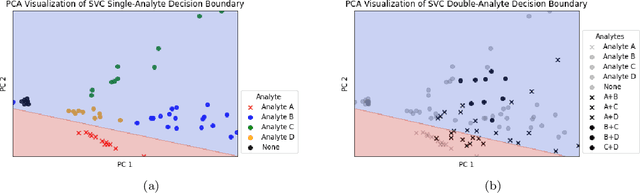
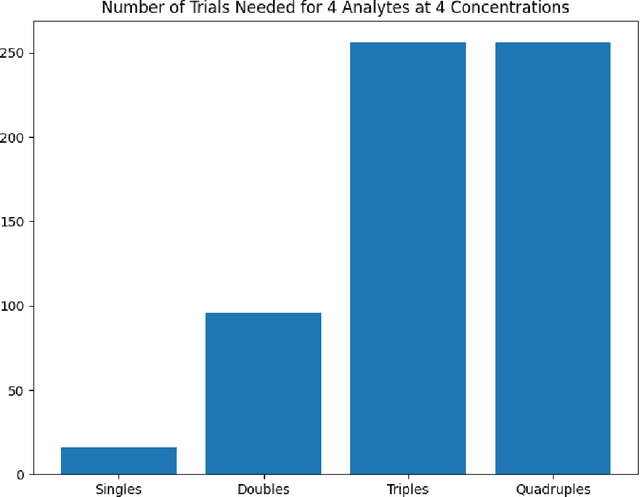
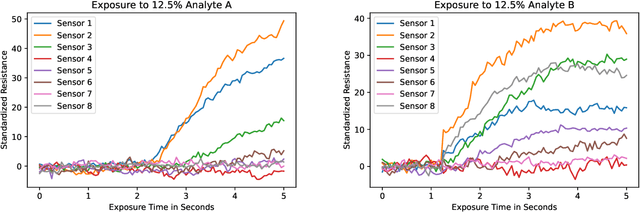
Accurate chemical sensors are vital in medical, military, and home safety applications. Training machine learning models to be accurate on real world chemical sensor data requires performing many diverse, costly experiments in controlled laboratory settings to create a data set. In practice even expensive, large data sets may be insufficient for generalization of a trained model to a real-world testing distribution. Rather than perform greater numbers of experiments requiring exhaustive mixtures of chemical analytes, this research proposes learning approximations of complex exposures from training sets of simple ones by using single-analyte exposure signals as building blocks of a multiple-analyte space. We demonstrate this approach to synthetic sensor responses surprisingly improves the detection of out-of-distribution obscured chemical analytes. Further, we pair these synthetic signals to targets in an information-dense representation space utilizing a large corpus of chemistry knowledge. Through utilization of a semantically meaningful analyte representation spaces along with synthetic targets we achieve rapid analyte classification in the presence of obscurants without corresponding obscured-analyte training data. Transfer learning for supervised learning with molecular representations makes assumptions about the input data. Instead, we borrow from the natural language and natural image processing literature for a novel approach to chemical sensor signal classification using molecular semantics for arbitrary chemical sensor hardware designs.
Layout-Aware Information Extraction for Document-Grounded Dialogue: Dataset, Method and Demonstration
Jul 14, 2022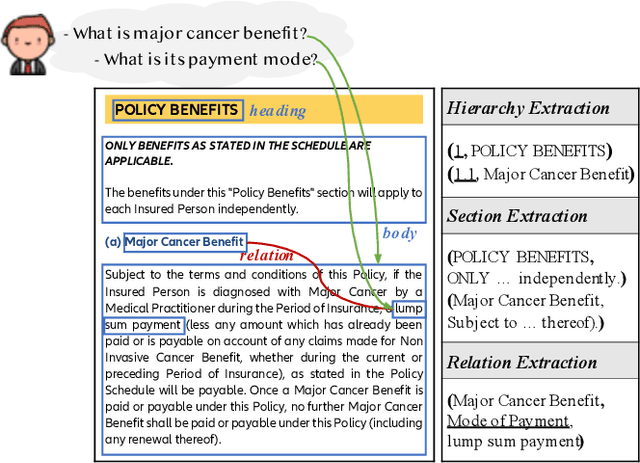
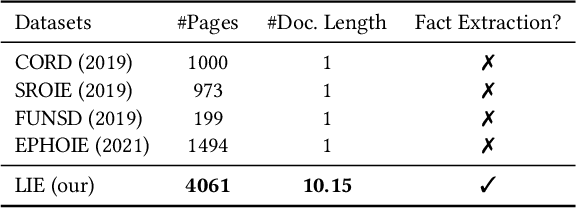

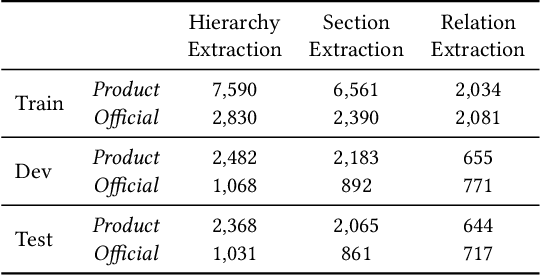
Building document-grounded dialogue systems have received growing interest as documents convey a wealth of human knowledge and commonly exist in enterprises. Wherein, how to comprehend and retrieve information from documents is a challenging research problem. Previous work ignores the visual property of documents and treats them as plain text, resulting in incomplete modality. In this paper, we propose a Layout-aware document-level Information Extraction dataset, LIE, to facilitate the study of extracting both structural and semantic knowledge from visually rich documents (VRDs), so as to generate accurate responses in dialogue systems. LIE contains 62k annotations of three extraction tasks from 4,061 pages in product and official documents, becoming the largest VRD-based information extraction dataset to the best of our knowledge. We also develop benchmark methods that extend the token-based language model to consider layout features like humans. Empirical results show that layout is critical for VRD-based extraction, and system demonstration also verifies that the extracted knowledge can help locate the answers that users care about.
Design of a Multi-User Wireless Powered Communication System Employing Either Active IRS or AF Relay
Dec 31, 2022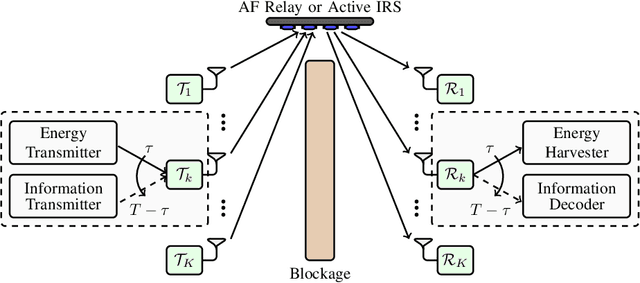
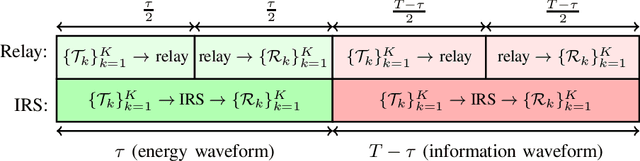
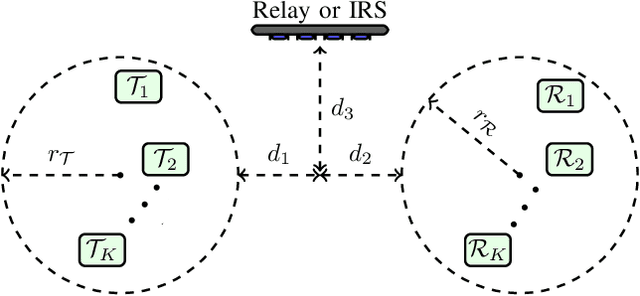
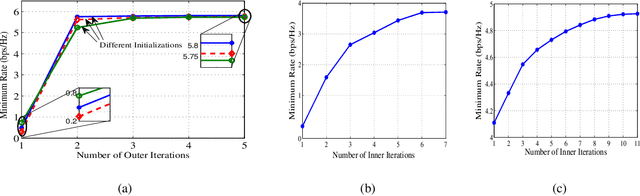
In this paper, we optimize a Wireless Powered Communication (WPC) system including multiple pair of users, where transmitters employ single-antenna to transmit their information and power to their receivers with the help of one multiple-antennas Amplify-and-Forward (AF) relay or an active Intelligent Reflecting Surface (IRS). We propose a joint Time Switching (TS) scheme in which transmitters, receivers, and the relay/IRS are either in their energy or information transmission/reception modes. The transmitted multi-carrier unmodulated and modulated waveforms are used for Energy Harvesting (EH) and Information Decoding (ID) modes, respectively. In order to design an optimal fair system, we maximize the minimum rate of all pairs for both relay and IRS systems through a unified framework. This framework allows us to simultaneously design energy waveforms, find optimal relay/IRS amplification/reflection matrices, allocate powers for information waveforms, and allocate time durations for various phases. In addition, we take into account the non-linearity of the EH circuits in our problem. This problem turns out to be non-convex. Thus, we propose an iterative algorithm by using the Minorization-Maximization (MM) technique, which quickly converges to the optimal solution. Numerical examples show that the proposed method improves the performance of the multi-pair WPC relay/IRS system under various setups.
Semantic Image Segmentation: Two Decades of Research
Feb 13, 2023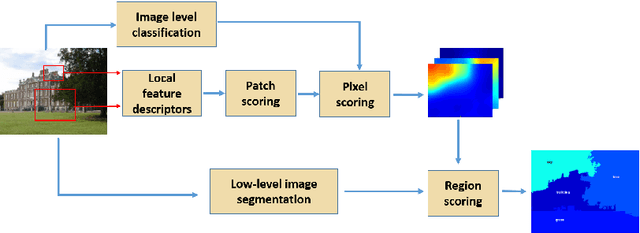
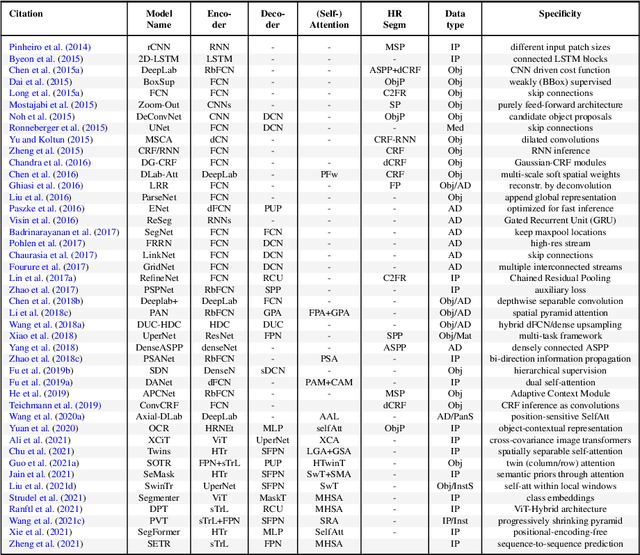
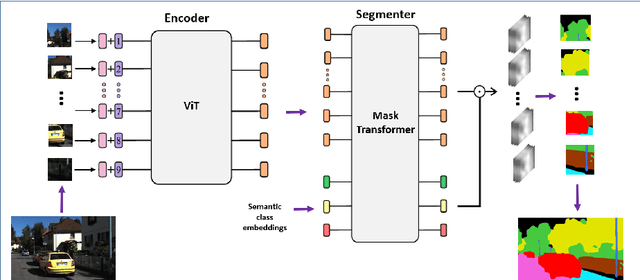

Semantic image segmentation (SiS) plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. This survey is an effort to summarize two decades of research in the field of SiS, where we propose a literature review of solutions starting from early historical methods followed by an overview of more recent deep learning methods including the latest trend of using transformers. We complement the review by discussing particular cases of the weak supervision and side machine learning techniques that can be used to improve the semantic segmentation such as curriculum, incremental or self-supervised learning. State-of-the-art SiS models rely on a large amount of annotated samples, which are more expensive to obtain than labels for tasks such as image classification. Since unlabeled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation (UDA) reached a broad success within the semantic segmentation community. Therefore, a second core contribution of this book is to summarize five years of a rapidly growing field, Domain Adaptation for Semantic Image Segmentation (DASiS) which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. In addition to providing a comprehensive survey on DASiS techniques, we unveil also newer trends such as multi-domain learning, domain generalization, domain incremental learning, test-time adaptation and source-free domain adaptation. Finally, we conclude this survey by describing datasets and benchmarks most widely used in SiS and DASiS and briefly discuss related tasks such as instance and panoptic image segmentation, as well as applications such as medical image segmentation.
Explainable artificial intelligence toward usable and trustworthy computer-aided early diagnosis of multiple sclerosis from Optical Coherence Tomography
Feb 13, 2023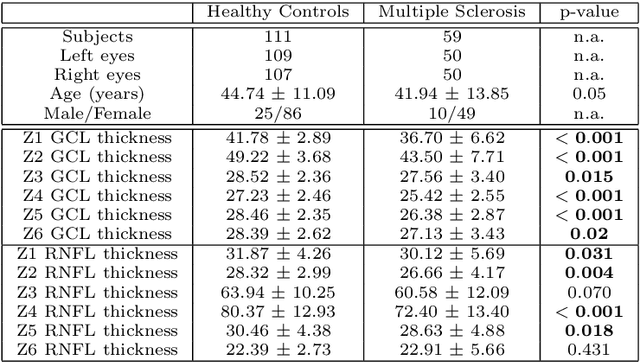
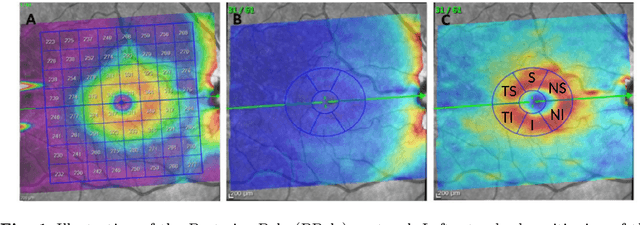
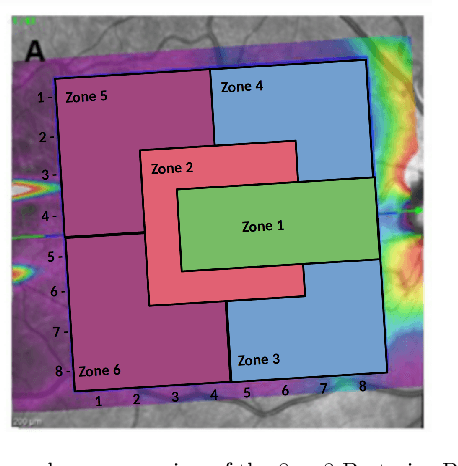
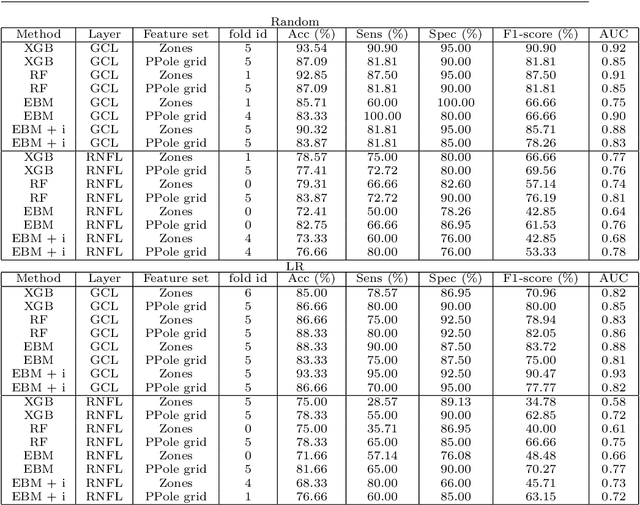
Background: Several studies indicate that the anterior visual pathway provides information about the dynamics of axonal degeneration in Multiple Sclerosis (MS). Current research in the field is focused on the quest for the most discriminative features among patients and controls and the development of machine learning models that yield computer-aided solutions widely usable in clinical practice. However, most studies are conducted with small samples and the models are used as black boxes. Clinicians should not trust machine learning decisions unless they come with comprehensive and easily understandable explanations. Materials and methods: A total of 216 eyes from 111 healthy controls and 100 eyes from 59 patients with relapsing-remitting MS were enrolled. The feature set was obtained from the thickness of the ganglion cell layer (GCL) and the retinal nerve fiber layer (RNFL). Measurements were acquired by the novel Posterior Pole protocol from Spectralis Optical Coherence Tomography (OCT) device. We compared two black-box methods (gradient boosting and random forests) with a glass-box method (explainable boosting machine). Explainability was studied using SHAP for the black-box methods and the scores of the glass-box method. Results: The best-performing models were obtained for the GCL layer. Explainability pointed out to the temporal location of the GCL layer that is usually broken or thinning in MS and the relationship between low thickness values and high probability of MS, which is coherent with clinical knowledge. Conclusions: The insights on how to use explainability shown in this work represent a first important step toward a trustworthy computer-aided solution for the diagnosis of MS with OCT.
Context Query Simulation for Smart Carparking Scenarios in the Melbourne CDB
Feb 13, 2023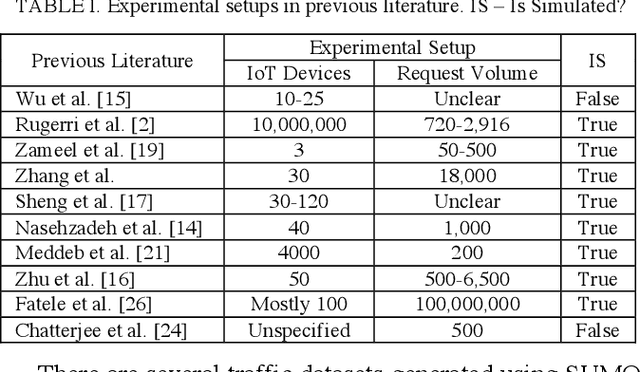
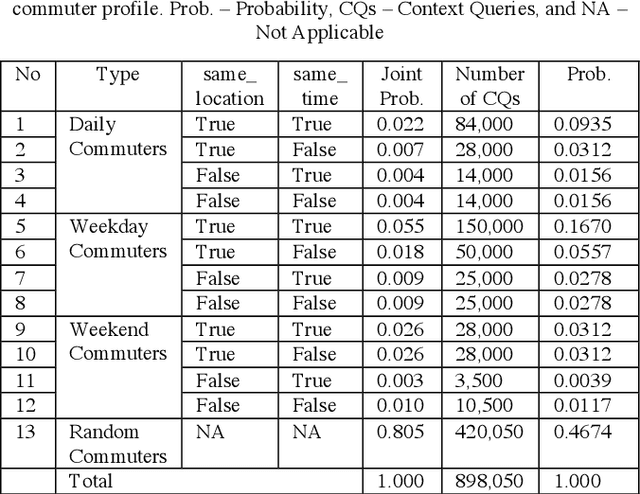
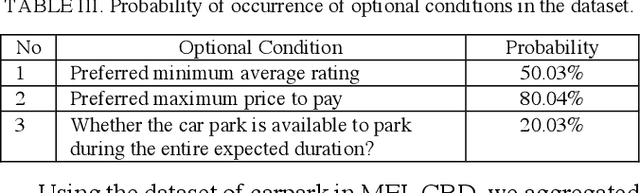

The rapid growth in Internet of Things (IoT) has ushered in the way for better context-awareness enabling more smarter applications. Although for the growth in the number of IoT devices, Context Management Platforms (CMPs) that integrate different domains of IoT to produce context information lacks scalability to cater to a high volume of context queries. Research in scalability and adaptation in CMPs are of significant importance due to this reason. However, there is limited methods to benchmarks and validate research in this area due to the lack of sizable sets of context queries that could simulate real-world situations, scenarios, and scenes. Commercially collected context query logs are not publicly accessible and deploying IoT devices, and context consumers in the real-world at scale is expensive and consumes a significant effort and time. Therefore, there is a need to develop a method to reliably generate and simulate context query loads that resembles real-world scenarios to test CMPs for scale. In this paper, we propose a context query simulator for the context-aware smart car parking scenario in Melbourne Central Business District in Australia. We present the process of generating context queries using multiple real-world datasets and publicly accessible reports, followed by the context query execution process. The context query generator matches the popularity of places with the different profiles of commuters, preferences, and traffic variations to produce a dataset of context query templates containing 898,050 records. The simulator is executable over a seven-day profile which far exceeds the simulation time of any IoT system simulator. The context query generation process is also generic and context query language independent.
Event-based Backpropagation for Analog Neuromorphic Hardware
Feb 13, 2023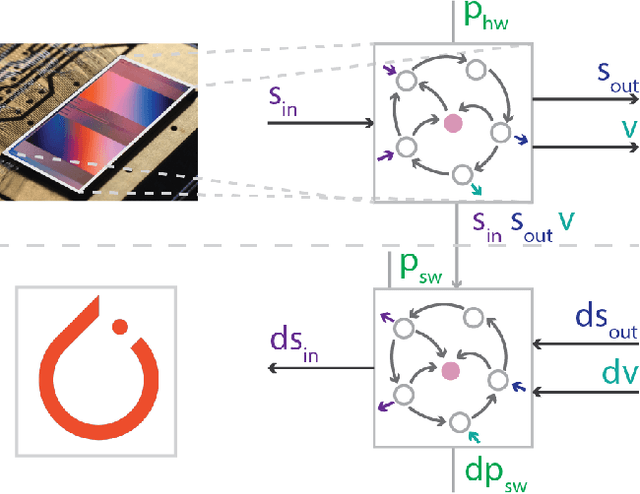

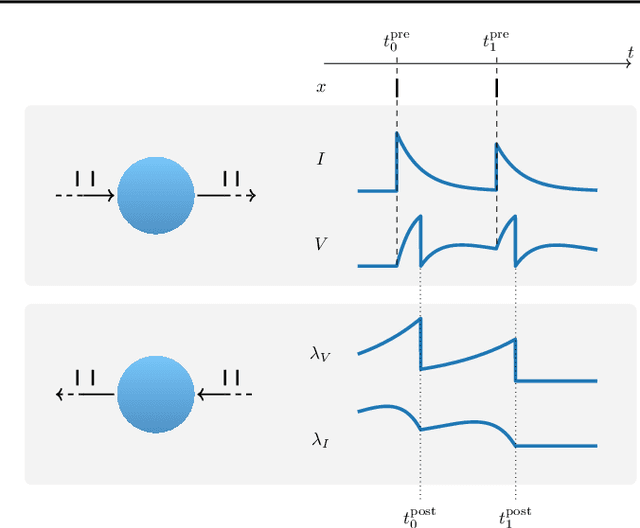
Neuromorphic computing aims to incorporate lessons from studying biological nervous systems in the design of computer architectures. While existing approaches have successfully implemented aspects of those computational principles, such as sparse spike-based computation, event-based scalable learning has remained an elusive goal in large-scale systems. However, only then the potential energy-efficiency advantages of neuromorphic systems relative to other hardware architectures can be realized during learning. We present our progress implementing the EventProp algorithm using the example of the BrainScaleS-2 analog neuromorphic hardware. Previous gradient-based approaches to learning used "surrogate gradients" and dense sampling of observables or were limited by assumptions on the underlying dynamics and loss functions. In contrast, our approach only needs spike time observations from the system while being able to incorporate other system observables, such as membrane voltage measurements, in a principled way. This leads to a one-order-of-magnitude improvement in the information efficiency of the gradient estimate, which would directly translate to corresponding energy efficiency improvements in an optimized hardware implementation. We present the theoretical framework for estimating gradients and results verifying the correctness of the estimation, as well as results on a low-dimensional classification task using the BrainScaleS-2 system. Building on this work has the potential to enable scalable gradient estimation in large-scale neuromorphic hardware as a continuous measurement of the system state would be prohibitive and energy-inefficient in such instances. It also suggests the feasibility of a full on-device implementation of the algorithm that would enable scalable, energy-efficient, event-based learning in large-scale analog neuromorphic hardware.
Improved Regret for Efficient Online Reinforcement Learning with Linear Function Approximation
Jan 30, 2023We study reinforcement learning with linear function approximation and adversarially changing cost functions, a setup that has mostly been considered under simplifying assumptions such as full information feedback or exploratory conditions.We present a computationally efficient policy optimization algorithm for the challenging general setting of unknown dynamics and bandit feedback, featuring a combination of mirror-descent and least squares policy evaluation in an auxiliary MDP used to compute exploration bonuses.Our algorithm obtains an $\widetilde O(K^{6/7})$ regret bound, improving significantly over previous state-of-the-art of $\widetilde O (K^{14/15})$ in this setting. In addition, we present a version of the same algorithm under the assumption a simulator of the environment is available to the learner (but otherwise no exploratory assumptions are made), and prove it obtains state-of-the-art regret of $\widetilde O (K^{2/3})$.
Robust Precoding via Characteristic Functions for VSAT to Multi-Satellite Uplink Transmission
Jan 30, 2023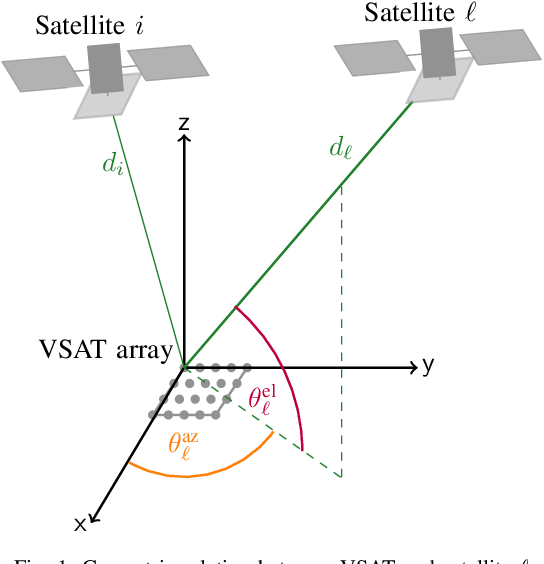
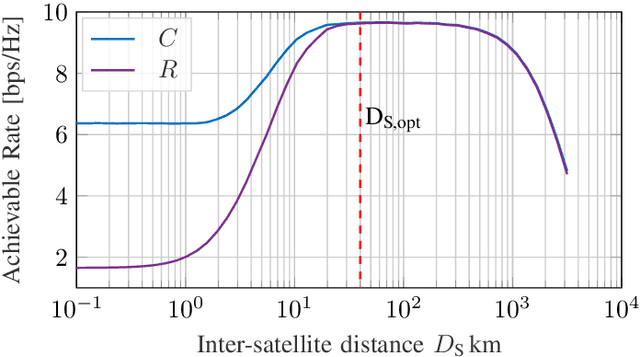
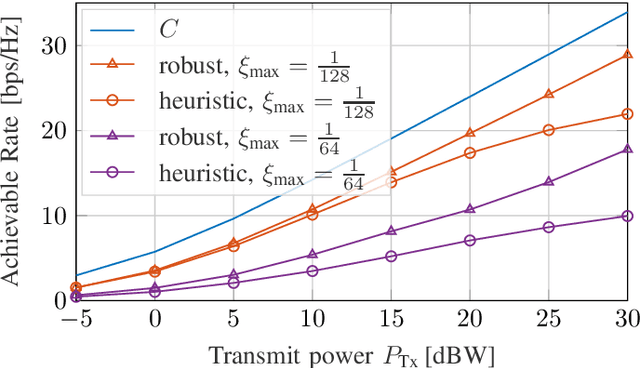
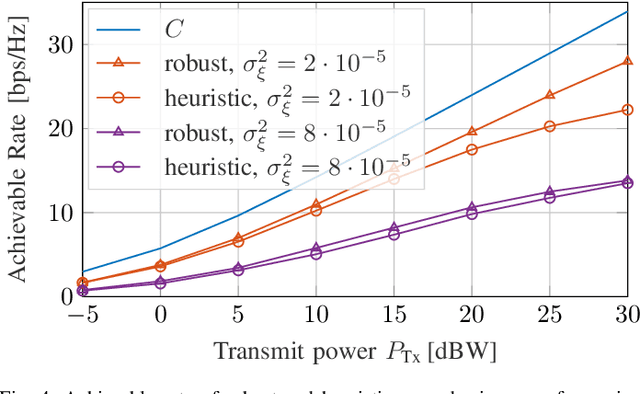
The uplink from a very small aperture terminal (VSAT) towards multiple satellites is considered, in this paper. VSATs can be equipped with multiple antennas, allowing parallel transmission to multiple satellites. A low-complexity precoder based on imperfect positional information of the satellites is presented. The probability distribution of the position uncertainty and the statistics of the channel elements are related by the characteristic function of the position uncertainty. This knowledge is included in the precoder design to maximize the mean signal-to-leakage-and-noise ratio (SLNR) at the satellites. Furthermore, the performance w.r.t. the inter-satellite distance is numerically evaluated. It is shown that the proposed approach achieves the capacity for perfect position knowledge and sufficiently large inter-satellite distances. In case of imperfect position knowledge, the performance degradation of the robust precoder is relatively small.