 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncovering Adversarial Risks of Test-Time Adaptation
Feb 04, 2023
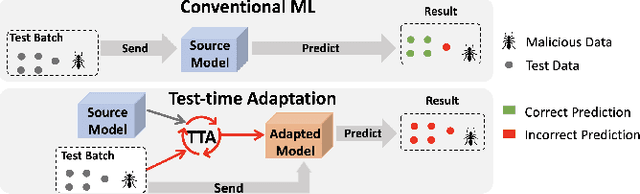
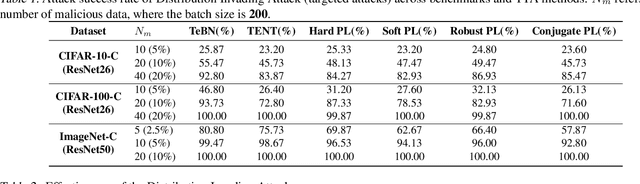
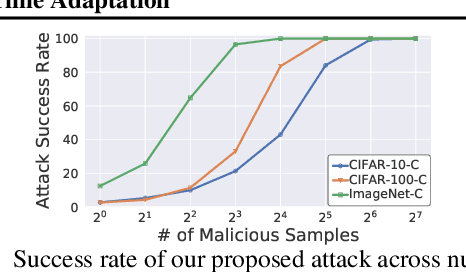
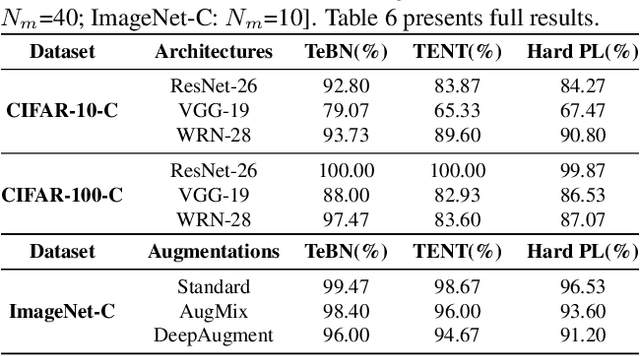
Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.
State Machine-based Waveforms for Channels With 1-Bit Quantization and Oversampling With Time-Instance Zero-Crossing Modulation
Feb 04, 2023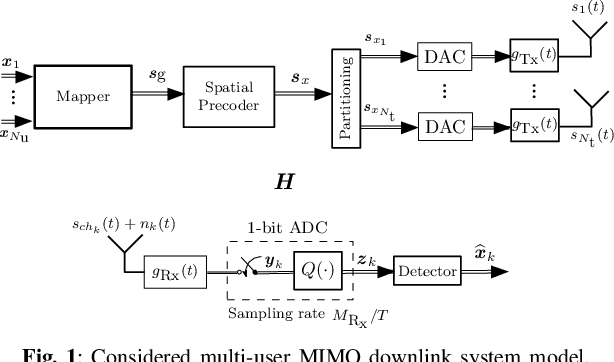
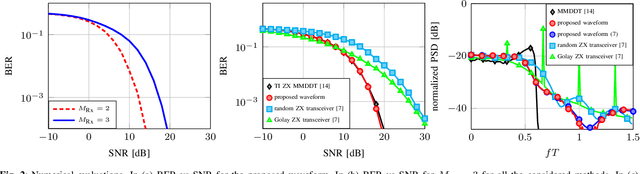
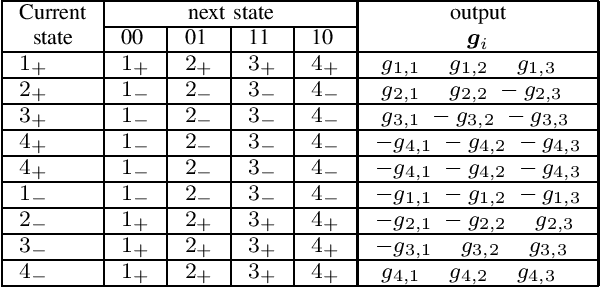

Systems with 1-bit quantization and oversampling are promising for the Internet of Things (IoT) devices in order to reduce the power consumption of the analog-to-digital-converters. The novel time-instance zero-crossing (TI ZX) modulation is a promising approach for this kind of channels but existing studies rely on optimization problems with high computational complexity and delay. In this work, we propose a practical waveform design based on the established TI ZX modulation for a multiuser multi-input multi-output (MIMO) downlink scenario with 1-bit quantization and temporal oversampling at the receivers. In this sense, the proposed temporal transmit signals are constructed by concatenating segments of coefficients which convey the information into the time-instances of zero-crossings according to the TI ZX mapping rules. The proposed waveform design is compared with other methods from the literature. The methods are compared in terms of bit error rate and normalized power spectral density. Numerical results show that the proposed technique is suitable for multiuser MIMO system with 1-bit quantization while tolerating some small amount of out-of-band radiation.
Alignment with human representations supports robust few-shot learning
Jan 27, 2023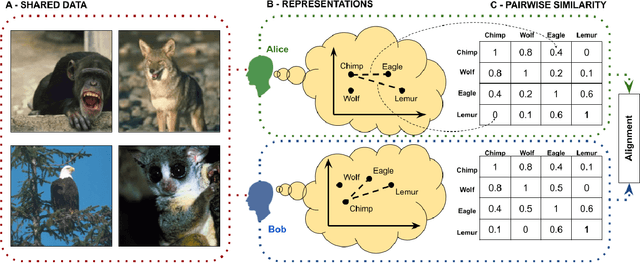
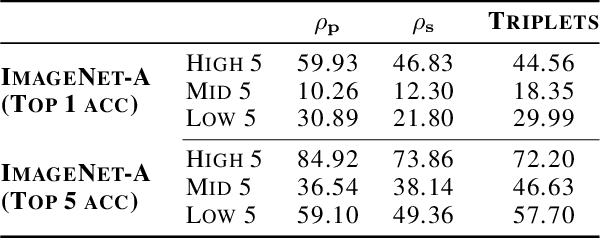
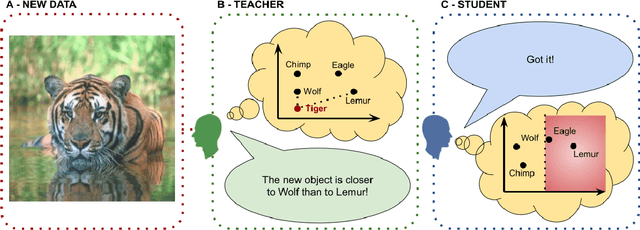
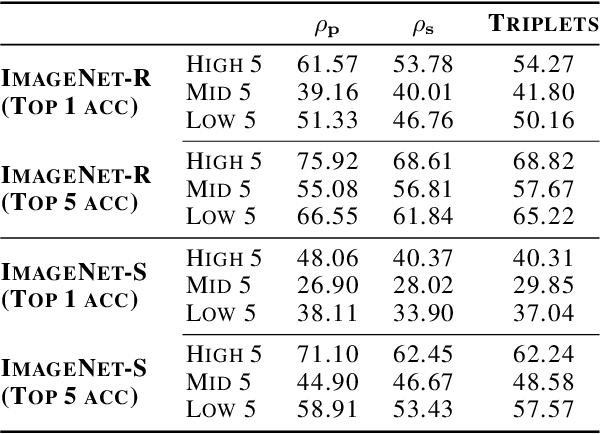
Should we care whether AI systems have representations of the world that are similar to those of humans? We provide an information-theoretic analysis that suggests that there should be a U-shaped relationship between the degree of representational alignment with humans and performance on few-shot learning tasks. We confirm this prediction empirically, finding such a relationship in an analysis of the performance of 491 computer vision models. We also show that highly-aligned models are more robust to both adversarial attacks and domain shifts. Our results suggest that human-alignment is often a sufficient, but not necessary, condition for models to make effective use of limited data, be robust, and generalize well.
Proceedings of the NeurIPS 2021 Workshop on Machine Learning for the Developing World: Global Challenges
Jan 10, 2023These are the proceedings of the 5th workshop on Machine Learning for the Developing World (ML4D), held as part of the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) on December 14th, 2021.
Denoising and Prompt-Tuning for Multi-Behavior Recommendation
Feb 12, 2023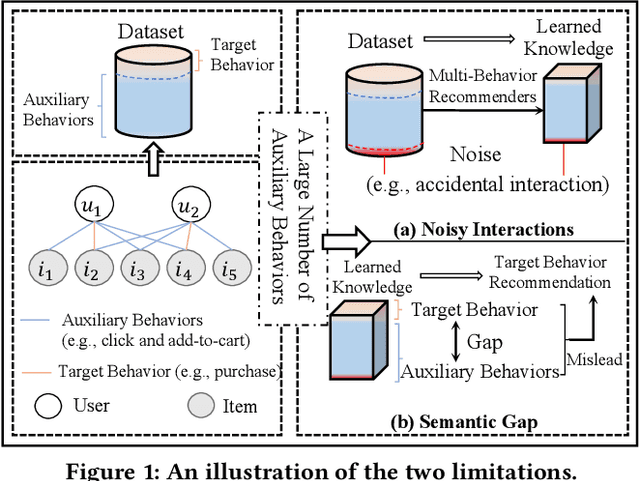

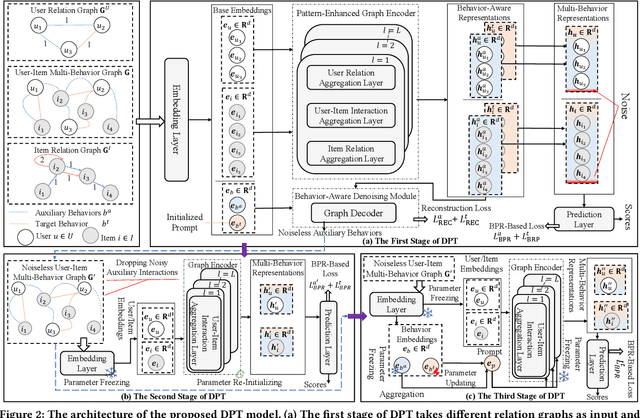

In practical recommendation scenarios, users often interact with items under multi-typed behaviors (e.g., click, add-to-cart, and purchase). Traditional collaborative filtering techniques typically assume that users only have a single type of behavior with items, making it insufficient to utilize complex collaborative signals to learn informative representations and infer actual user preferences. Consequently, some pioneer studies explore modeling multi-behavior heterogeneity to learn better representations and boost the performance of recommendations for a target behavior. However, a large number of auxiliary behaviors (i.e., click and add-to-cart) could introduce irrelevant information to recommenders, which could mislead the target behavior (i.e., purchase) recommendation, rendering two critical challenges: (i) denoising auxiliary behaviors and (ii) bridging the semantic gap between auxiliary and target behaviors. Motivated by the above observation, we propose a novel framework-Denoising and Prompt-Tuning (DPT) with a three-stage learning paradigm to solve the aforementioned challenges. In particular, DPT is equipped with a pattern-enhanced graph encoder in the first stage to learn complex patterns as prior knowledge in a data-driven manner to guide learning informative representation and pinpointing reliable noise for subsequent stages. Accordingly, we adopt different lightweight tuning approaches with effectiveness and efficiency in the following stages to further attenuate the influence of noise and alleviate the semantic gap among multi-typed behaviors. Extensive experiments on two real-world datasets demonstrate the superiority of DPT over a wide range of state-of-the-art methods. The implementation code is available online at https://github.com/zc-97/DPT.
IT-RUDA: Information Theory Assisted Robust Unsupervised Domain Adaptation
Oct 24, 2022
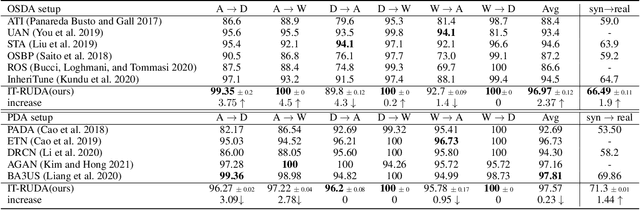

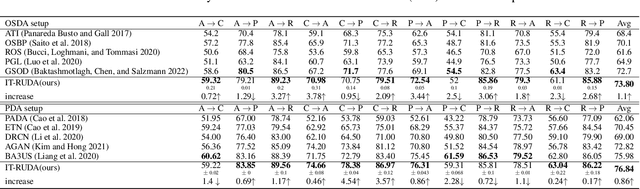
Distribution shift between train (source) and test (target) datasets is a common problem encountered in machine learning applications. One approach to resolve this issue is to use the Unsupervised Domain Adaptation (UDA) technique that carries out knowledge transfer from a label-rich source domain to an unlabeled target domain. Outliers that exist in either source or target datasets can introduce additional challenges when using UDA in practice. In this paper, $\alpha$-divergence is used as a measure to minimize the discrepancy between the source and target distributions while inheriting robustness, adjustable with a single parameter $\alpha$, as the prominent feature of this measure. Here, it is shown that the other well-known divergence-based UDA techniques can be derived as special cases of the proposed method. Furthermore, a theoretical upper bound is derived for the loss in the target domain in terms of the source loss and the initial $\alpha$-divergence between the two domains. The robustness of the proposed method is validated through testing on several benchmarked datasets in open-set and partial UDA setups where extra classes existing in target and source datasets are considered as outliers.
ChemVise: Maximizing Out-of-Distribution Chemical Detection with the Novel Application of Zero-Shot Learning
Feb 09, 2023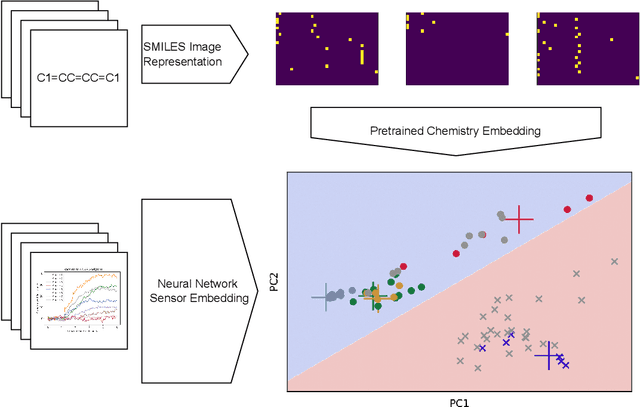
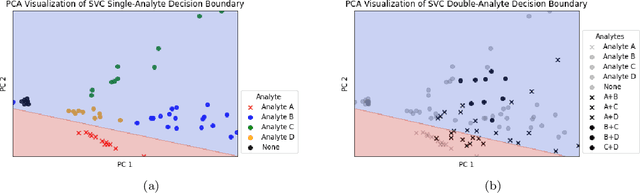
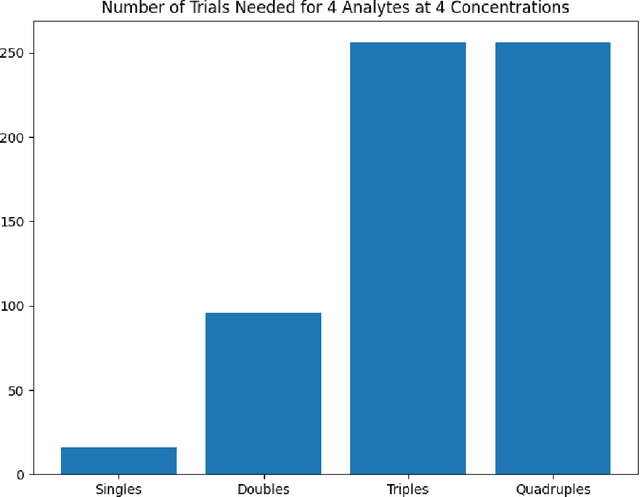
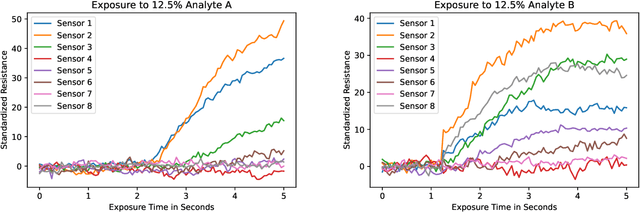
Accurate chemical sensors are vital in medical, military, and home safety applications. Training machine learning models to be accurate on real world chemical sensor data requires performing many diverse, costly experiments in controlled laboratory settings to create a data set. In practice even expensive, large data sets may be insufficient for generalization of a trained model to a real-world testing distribution. Rather than perform greater numbers of experiments requiring exhaustive mixtures of chemical analytes, this research proposes learning approximations of complex exposures from training sets of simple ones by using single-analyte exposure signals as building blocks of a multiple-analyte space. We demonstrate this approach to synthetic sensor responses surprisingly improves the detection of out-of-distribution obscured chemical analytes. Further, we pair these synthetic signals to targets in an information-dense representation space utilizing a large corpus of chemistry knowledge. Through utilization of a semantically meaningful analyte representation spaces along with synthetic targets we achieve rapid analyte classification in the presence of obscurants without corresponding obscured-analyte training data. Transfer learning for supervised learning with molecular representations makes assumptions about the input data. Instead, we borrow from the natural language and natural image processing literature for a novel approach to chemical sensor signal classification using molecular semantics for arbitrary chemical sensor hardware designs.
Generalizable Natural Language Processing Framework for Migraine Reporting from Social Media
Dec 23, 2022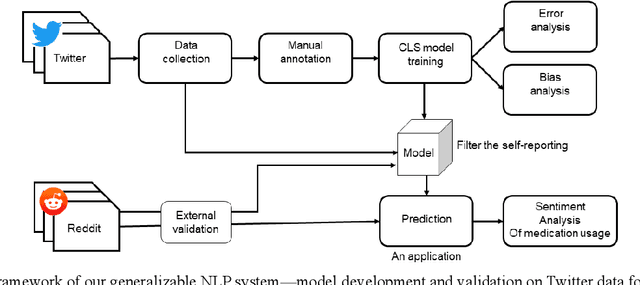
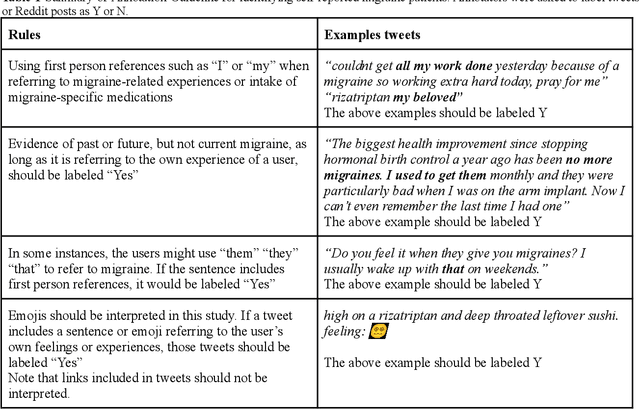
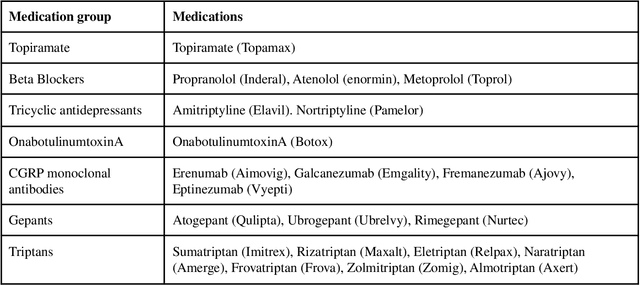
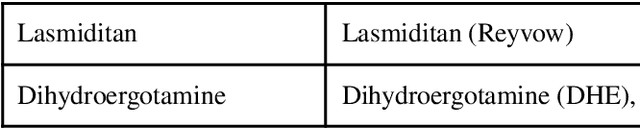
Migraine is a high-prevalence and disabling neurological disorder. However, information migraine management in real-world settings could be limited to traditional health information sources. In this paper, we (i) verify that there is substantial migraine-related chatter available on social media (Twitter and Reddit), self-reported by migraine sufferers; (ii) develop a platform-independent text classification system for automatically detecting self-reported migraine-related posts, and (iii) conduct analyses of the self-reported posts to assess the utility of social media for studying this problem. We manually annotated 5750 Twitter posts and 302 Reddit posts. Our system achieved an F1 score of 0.90 on Twitter and 0.93 on Reddit. Analysis of information posted by our 'migraine cohort' revealed the presence of a plethora of relevant information about migraine therapies and patient sentiments associated with them. Our study forms the foundation for conducting an in-depth analysis of migraine-related information using social media data.
Semantic Image Segmentation: Two Decades of Research
Feb 13, 2023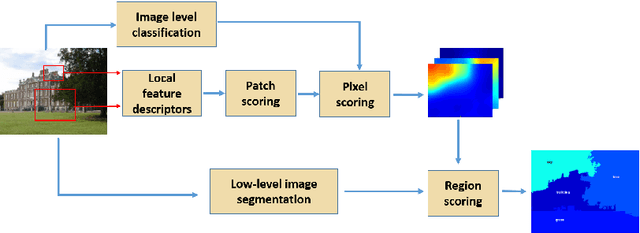
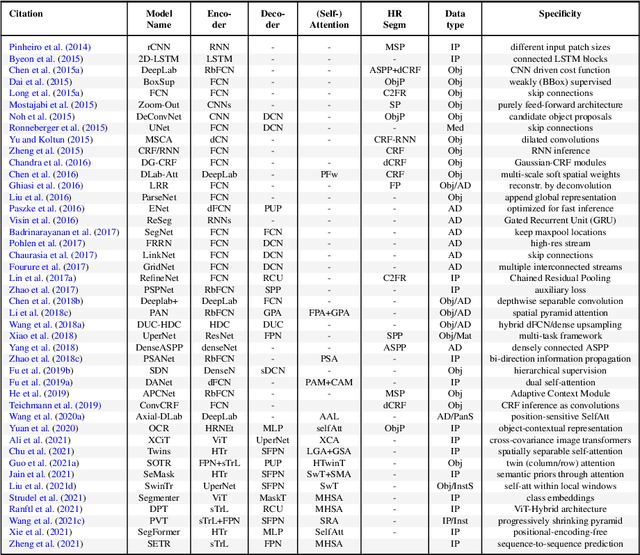
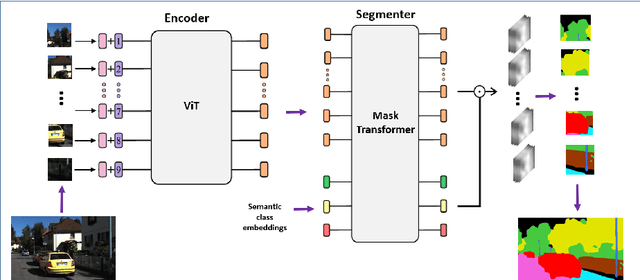

Semantic image segmentation (SiS) plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. This survey is an effort to summarize two decades of research in the field of SiS, where we propose a literature review of solutions starting from early historical methods followed by an overview of more recent deep learning methods including the latest trend of using transformers. We complement the review by discussing particular cases of the weak supervision and side machine learning techniques that can be used to improve the semantic segmentation such as curriculum, incremental or self-supervised learning. State-of-the-art SiS models rely on a large amount of annotated samples, which are more expensive to obtain than labels for tasks such as image classification. Since unlabeled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation (UDA) reached a broad success within the semantic segmentation community. Therefore, a second core contribution of this book is to summarize five years of a rapidly growing field, Domain Adaptation for Semantic Image Segmentation (DASiS) which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. In addition to providing a comprehensive survey on DASiS techniques, we unveil also newer trends such as multi-domain learning, domain generalization, domain incremental learning, test-time adaptation and source-free domain adaptation. Finally, we conclude this survey by describing datasets and benchmarks most widely used in SiS and DASiS and briefly discuss related tasks such as instance and panoptic image segmentation, as well as applications such as medical image segmentation.
Event-based Backpropagation for Analog Neuromorphic Hardware
Feb 13, 2023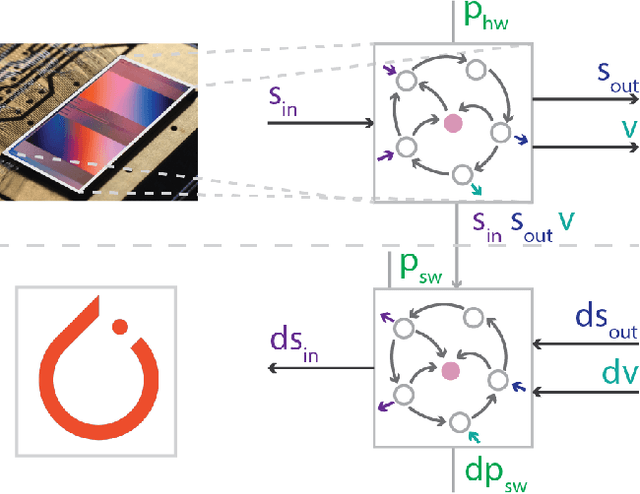

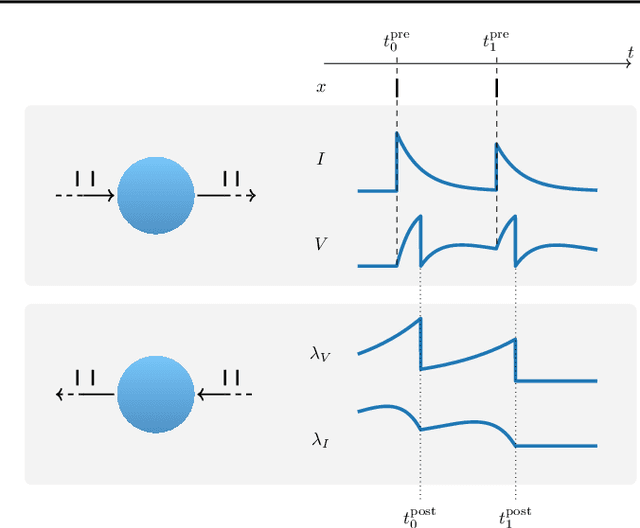
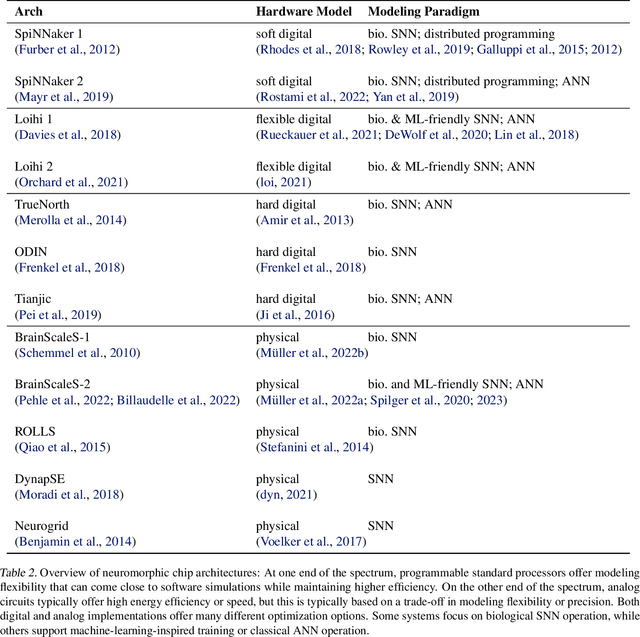
Neuromorphic computing aims to incorporate lessons from studying biological nervous systems in the design of computer architectures. While existing approaches have successfully implemented aspects of those computational principles, such as sparse spike-based computation, event-based scalable learning has remained an elusive goal in large-scale systems. However, only then the potential energy-efficiency advantages of neuromorphic systems relative to other hardware architectures can be realized during learning. We present our progress implementing the EventProp algorithm using the example of the BrainScaleS-2 analog neuromorphic hardware. Previous gradient-based approaches to learning used "surrogate gradients" and dense sampling of observables or were limited by assumptions on the underlying dynamics and loss functions. In contrast, our approach only needs spike time observations from the system while being able to incorporate other system observables, such as membrane voltage measurements, in a principled way. This leads to a one-order-of-magnitude improvement in the information efficiency of the gradient estimate, which would directly translate to corresponding energy efficiency improvements in an optimized hardware implementation. We present the theoretical framework for estimating gradients and results verifying the correctness of the estimation, as well as results on a low-dimensional classification task using the BrainScaleS-2 system. Building on this work has the potential to enable scalable gradient estimation in large-scale neuromorphic hardware as a continuous measurement of the system state would be prohibitive and energy-inefficient in such instances. It also suggests the feasibility of a full on-device implementation of the algorithm that would enable scalable, energy-efficient, event-based learning in large-scale analog neuromorphic hardware.