 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
To Switch or not to Switch: Predicting the Benefit of Switching between Algorithms based on Trajectory Features
Feb 17, 2023
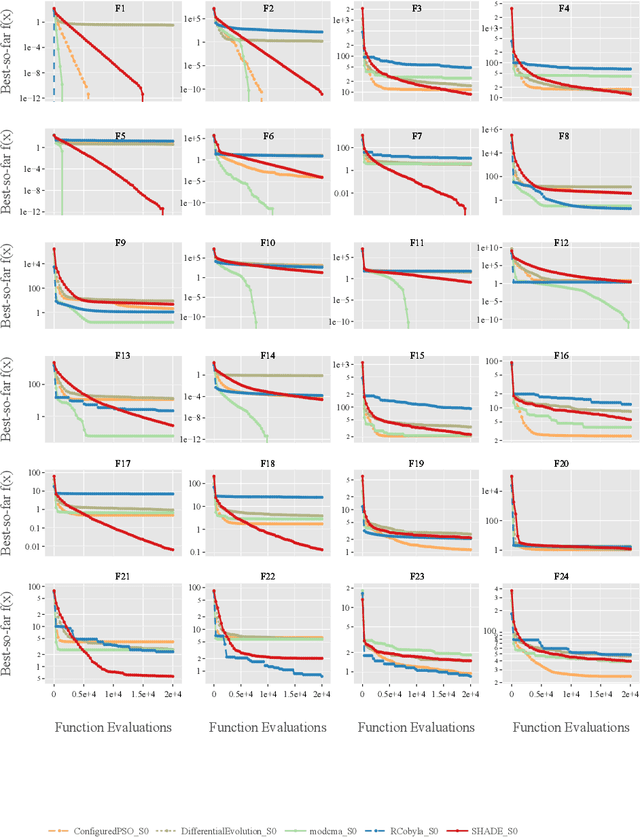
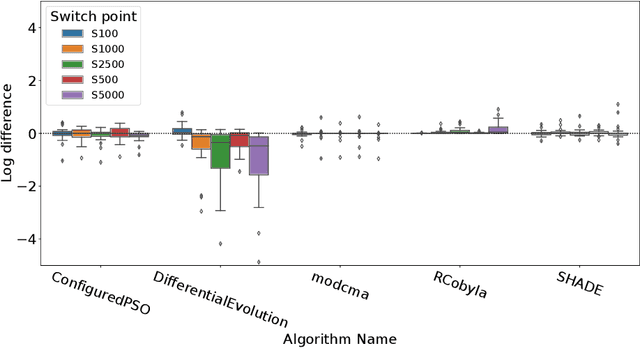
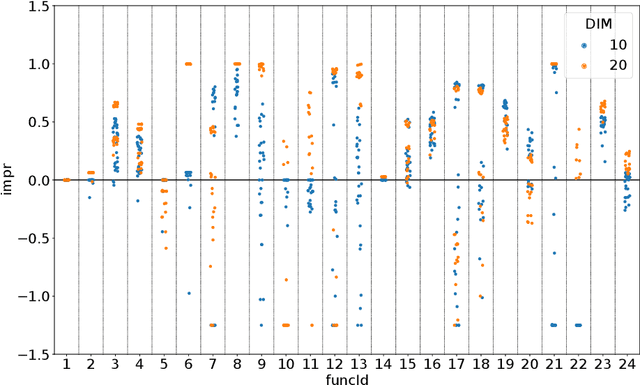
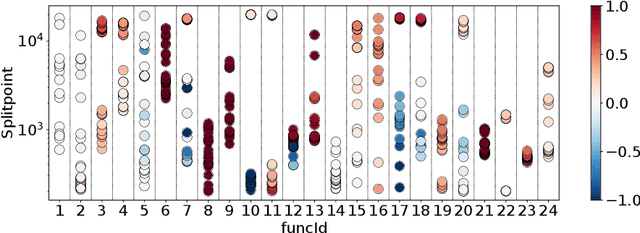
Dynamic algorithm selection aims to exploit the complementarity of multiple optimization algorithms by switching between them during the search. While these kinds of dynamic algorithms have been shown to have potential to outperform their component algorithms, it is still unclear how this potential can best be realized. One promising approach is to make use of landscape features to enable a per-run trajectory-based switch. Here, the samples seen by the first algorithm are used to create a set of features which describe the landscape from the perspective of the algorithm. These features are then used to predict what algorithm to switch to. In this work, we extend this per-run trajectory-based approach to consider a wide variety of potential points at which to perform the switch. We show that using a sliding window to capture the local landscape features contains information which can be used to predict whether a switch at that point would be beneficial to future performance. By analyzing the resulting models, we identify what features are most important to these predictions. Finally, by evaluating the importance of features and comparing these values between multiple algorithms, we show clear differences in the way the second algorithm interacts with the local landscape features found before the switch.
Aircraft Skin Inspections: Towards a New Model for Dent Evaluation
Jan 25, 2023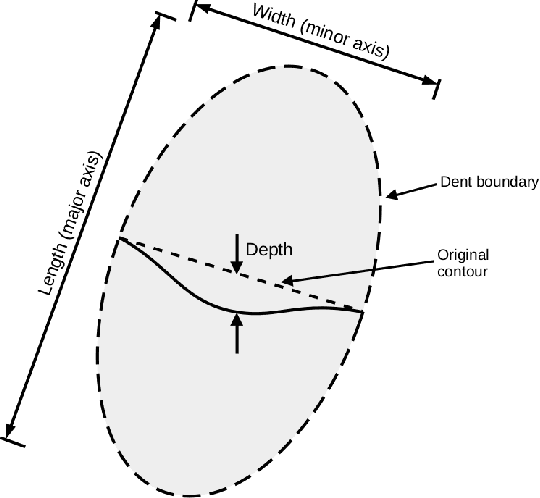
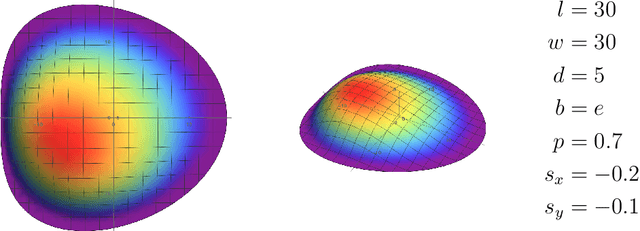
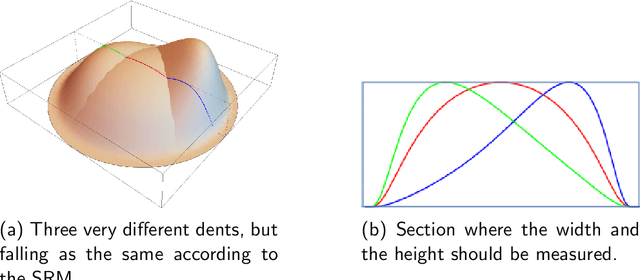

Aircraft maintenance, repair and overhaul (MRO) industry is gradually switching to 3D scanning for dent inspection. High-accuracy devices allow quick and repeatable measurements, which translate into efficient reporting and more objective damage evaluations. However, the potential of 3D scanners is far from being exploited. This is due to the traditional way in which the structural repair manual (SRM) deals with dents, that is, considering length, width and depth as the only relevant measures. Being equivalent to describing a dent similarly to a "box", the current approach discards any information about the actual shape. This causes high degrees of ambiguity, with very different shapes (and corresponding fatigue life) being classified as the same, and nullifies the effort of acquiring such great amount of information from high-accuracy 3D scanners. In this paper a $7$-parameter model is proposed to describe the actual dent shape, thus enabling the exploitation of the high fidelity data produced by 3D scanners. The compact set of values can then be compared against historical data and structural evaluations based on the same model.
InOR-Net: Incremental 3D Object Recognition Network for Point Cloud Representation
Feb 20, 2023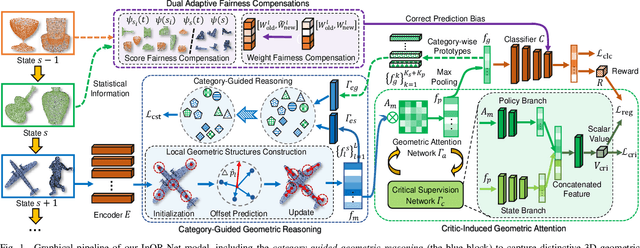

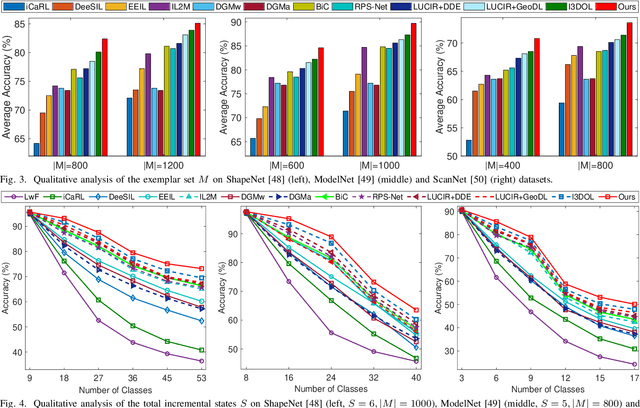
3D object recognition has successfully become an appealing research topic in the real-world. However, most existing recognition models unreasonably assume that the categories of 3D objects cannot change over time in the real-world. This unrealistic assumption may result in significant performance degradation for them to learn new classes of 3D objects consecutively, due to the catastrophic forgetting on old learned classes. Moreover, they cannot explore which 3D geometric characteristics are essential to alleviate the catastrophic forgetting on old classes of 3D objects. To tackle the above challenges, we develop a novel Incremental 3D Object Recognition Network (i.e., InOR-Net), which could recognize new classes of 3D objects continuously via overcoming the catastrophic forgetting on old classes. Specifically, a category-guided geometric reasoning is proposed to reason local geometric structures with distinctive 3D characteristics of each class by leveraging intrinsic category information. We then propose a novel critic-induced geometric attention mechanism to distinguish which 3D geometric characteristics within each class are beneficial to overcome the catastrophic forgetting on old classes of 3D objects, while preventing the negative influence of useless 3D characteristics. In addition, a dual adaptive fairness compensations strategy is designed to overcome the forgetting brought by class imbalance, by compensating biased weights and predictions of the classifier. Comparison experiments verify the state-of-the-art performance of the proposed InOR-Net model on several public point cloud datasets.
Faster Region-Based CNN Spectrum Sensing and Signal Identification in Cluttered RF Environments
Feb 20, 2023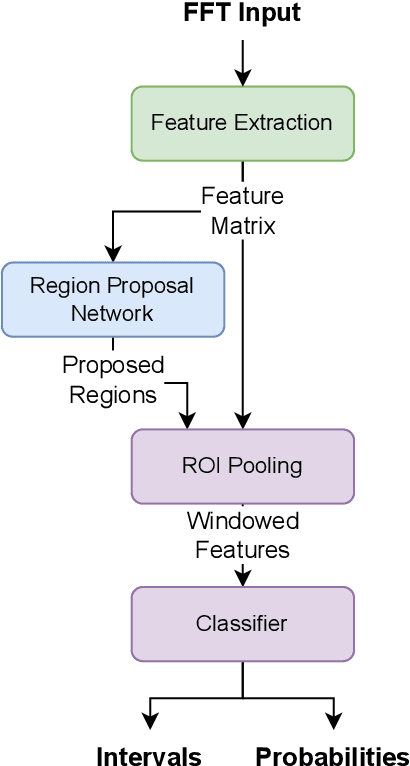
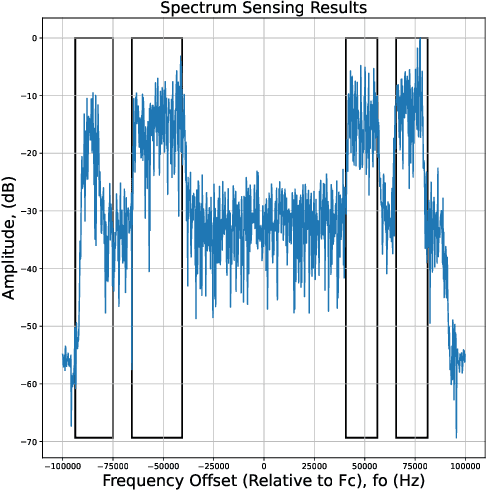
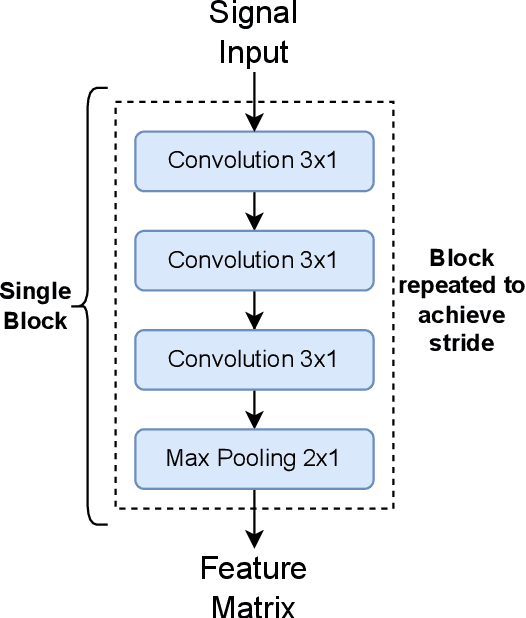
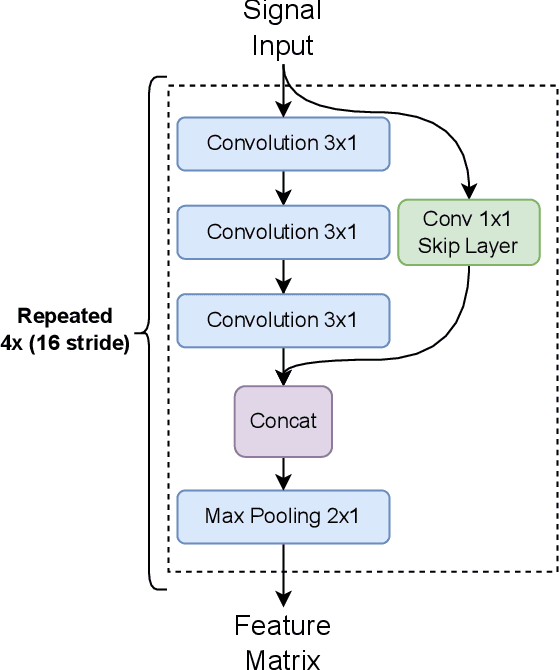
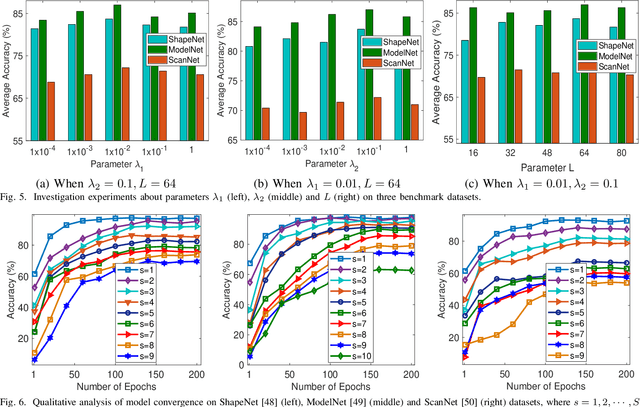
In this paper, we optimize a faster region-based convolutional neural network (FRCNN) for 1-dimensional (1D) signal processing and electromagnetic spectrum sensing. We target a cluttered radio frequency (RF) environment, where multiple RF transmission can be present at various frequencies with different bandwidths. The challenge is to accurately and quickly detect and localize each signal with minimal prior information of the signal within a band of interest. As the number of wireless devices grow, and devices become more complex from advances such as software defined radio (SDR), this task becomes increasingly difficult. It is important for sensing devices to keep up with this change, to ensure optimal spectrum usage, to monitor traffic over-the-air for security concerns, and for identifying devices in electronic warfare. Machine learning object detection has shown to be effective for spectrum sensing, however current techniques can be slow and use excessive resources. FRCNN has been applied to perform spectrum sensing using 2D spectrograms, however is unable to be applied directly to 1D signals. We optimize FRCNN to handle 1D signals, including fast Fourier transform (FFT) for spectrum sensing. Our results show that our method has better localization performance, and is faster than the 2D equivalent. Additionally, we show a use case where the modulation type of multiple uncooperative transmissions is identified. Finally, we prove our method generalizes to real world scenarios, by testing it over-the-air using SDR.
Four ways to recover the symbol of a non-binary localization operator
Jan 27, 2023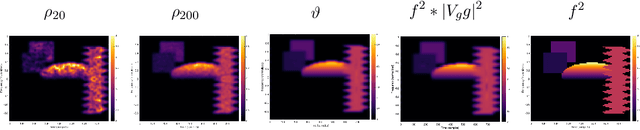
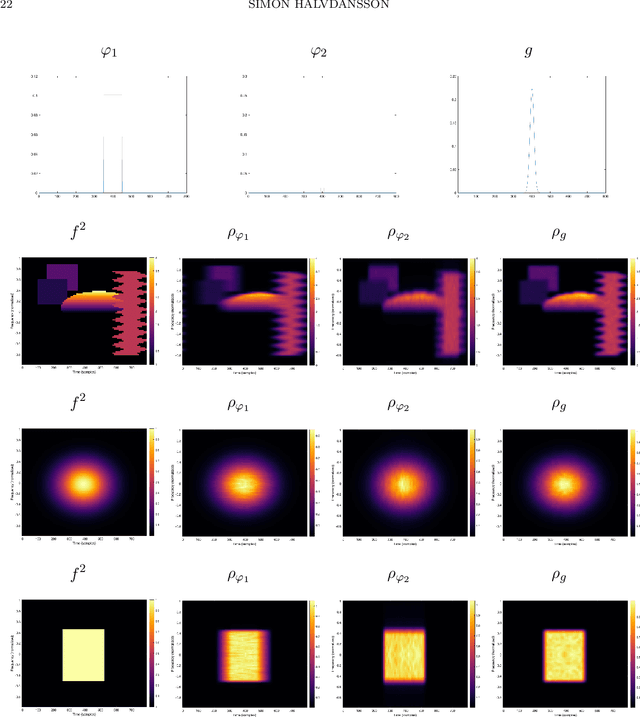
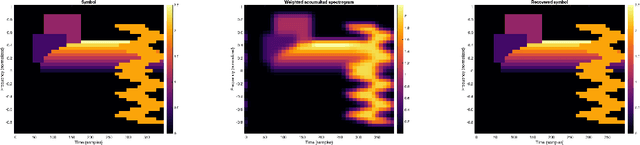
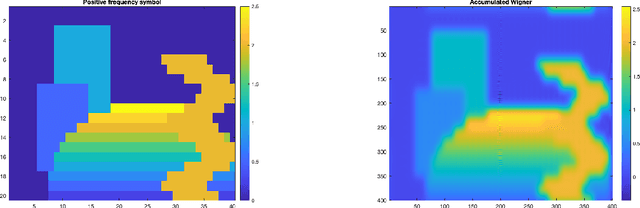
We present a set of results on how the symbol of a localization operator can be recovered from spectral information, the image of white noise or the image of an orthonormal basis. This extends earlier results which have been limited to the case where the symbol is a binary mask. Moreover, we present some numerical aspects of the different methods and discuss their performance.
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022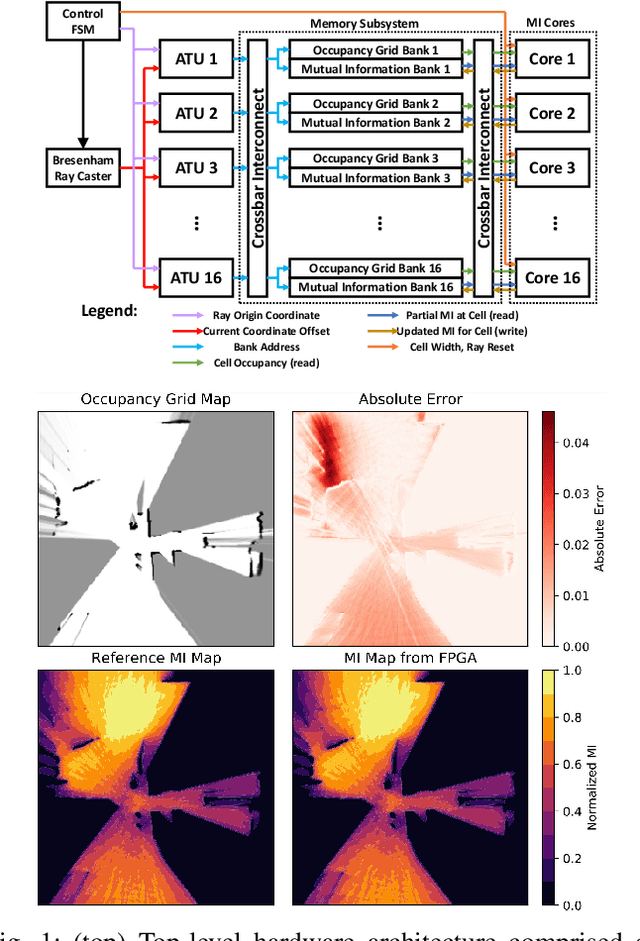
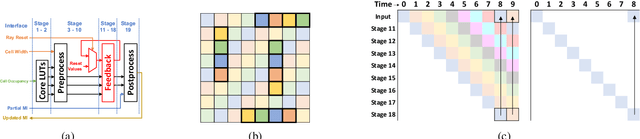
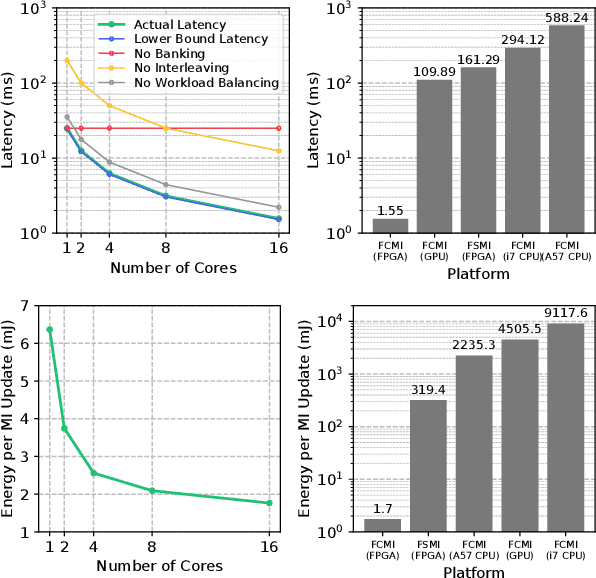
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.
Self-supervised Likelihood Estimation with Energy Guidance for Anomaly Segmentation in Urban Scenes
Feb 15, 2023
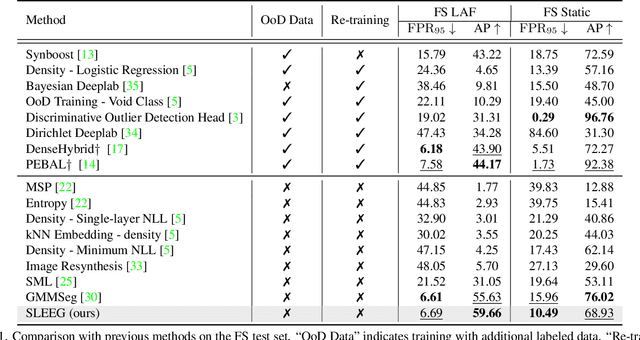
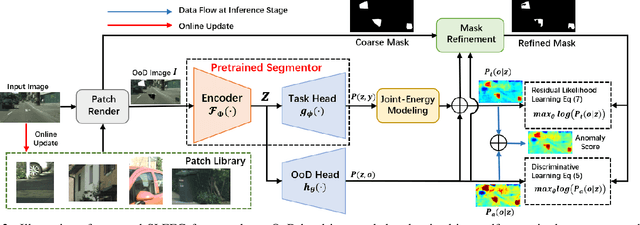
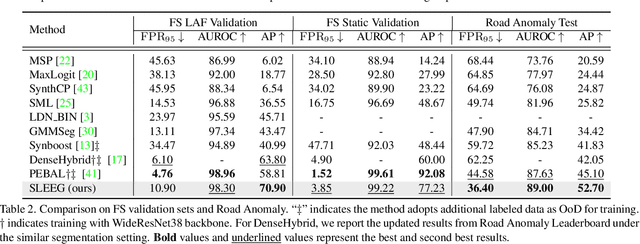
Robust autonomous driving requires agents to accurately identify unexpected areas in urban scenes. To this end, some critical issues remain open: how to design advisable metric to measure anomalies, and how to properly generate training samples of anomaly data? Previous effort usually resorts to uncertainty estimation and sample synthesis from classification tasks, which ignore the context information and sometimes requires auxiliary datasets with fine-grained annotations. On the contrary, in this paper, we exploit the strong context-dependent nature of segmentation task and design an energy-guided self-supervised frameworks for anomaly segmentation, which optimizes an anomaly head by maximizing the likelihood of self-generated anomaly pixels. To this end, we design two estimators for anomaly likelihood estimation, one is a simple task-agnostic binary estimator and the other depicts anomaly likelihood as residual of task-oriented energy model. Based on proposed estimators, we further incorporate our framework with likelihood-guided mask refinement process to extract informative anomaly pixels for model training. We conduct extensive experiments on challenging Fishyscapes and Road Anomaly benchmarks, demonstrating that without any auxiliary data or synthetic models, our method can still achieves competitive performance to other SOTA schemes.
Platform-Independent and Curriculum-Oriented Intelligent Assistant for Higher Education
Feb 15, 2023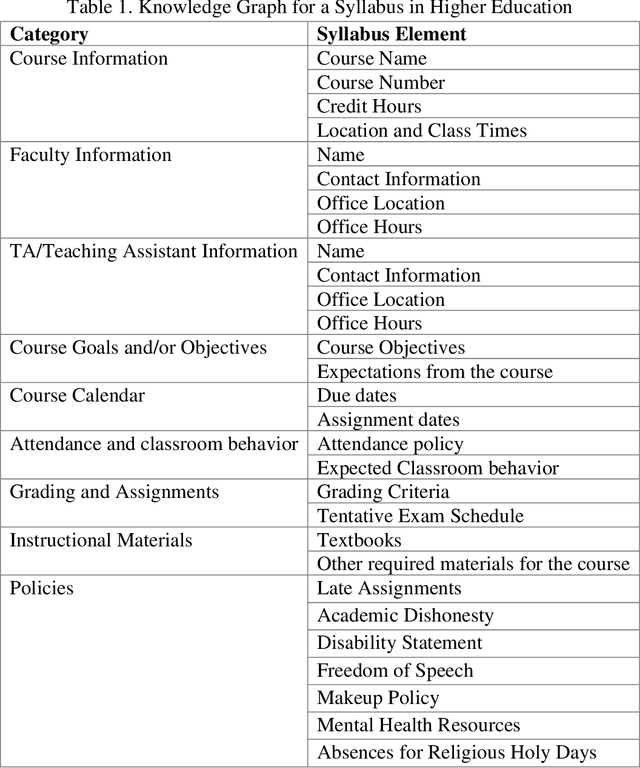
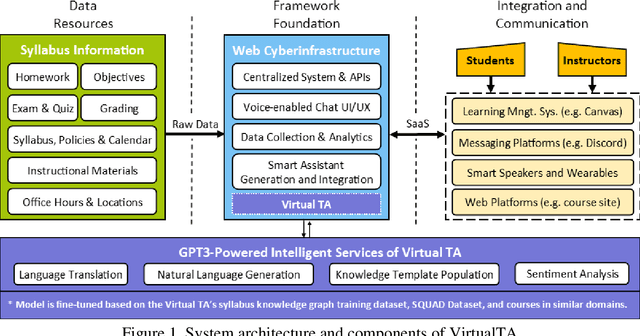

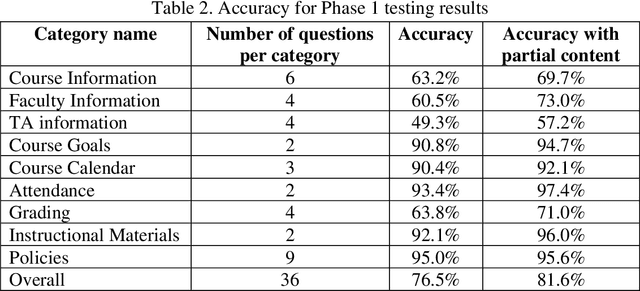
Miscommunication and communication challenges between instructors and students represents one of the primary barriers to post-secondary learning. Students often avoid or miss opportunities to ask questions during office hours due to insecurities or scheduling conflicts. Moreover, students need to work at their own pace to have the freedom and time for the self-contemplation needed to build conceptual understanding and develop creative thinking skills. To eliminate barriers to student engagement, academic institutions need to redefine their fundamental approach to education by proposing flexible educational pathways that recognize continuous learning. To this end, we developed an AI-augmented intelligent educational assistance framework based on a power language model (i.e., GPT-3) that automatically generates course-specific intelligent assistants regardless of discipline or academic level. The virtual intelligent teaching assistant (TA) system will serve as a voice-enabled helper capable of answering course-specific questions concerning curriculum, logistics and course policies. It is envisioned to improve access to course-related information for the students and reduce logistical workload for the instructors and TAs. Its GPT-3-based knowledge discovery component as well as the generalized system architecture is presented accompanied by a methodical evaluation of the system accuracy and performance.
Bayesian Federated Inference for Statistical Models
Feb 15, 2023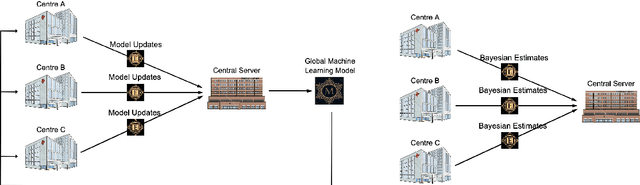
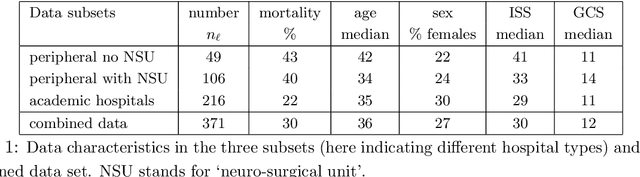
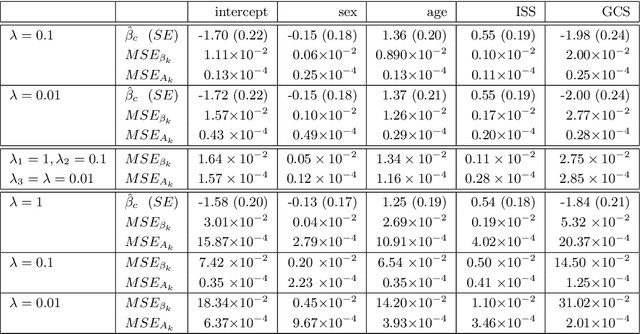
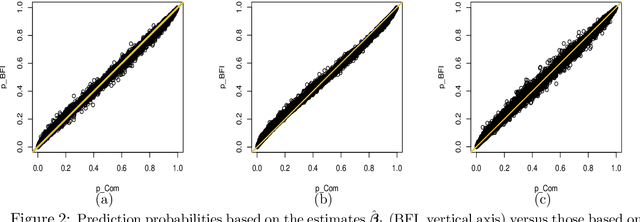
Identifying predictive factors via multivariable statistical analysis is for rare diseases often impossible because the data sets available are too small. Combining data from different medical centers into a single (larger) database would alleviate this problem, but is in practice challenging due to regulatory and logistic problems. Federated Learning (FL) is a machine learning approach that aims to construct from local inferences in separate data centers what would have been inferred had the data sets been merged. It seeks to harvest the statistical power of larger data sets without actually creating them. The FL strategy is not always feasible for small data sets. Therefore, in this paper we refine and implement an alternative Bayesian Federated Inference (BFI) framework for multi center data with the same aim as FL. The BFI framework is designed to cope with small data sets by inferring locally not only the optimal parameter values, but also additional features of the posterior parameter distribution, capturing information beyond that is used in FL. BFI has the additional benefit that a single inference cycle across the centers is sufficient, whereas FL needs multiple cycles. We quantify the performance of the proposed methodology on simulated and real life data.
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


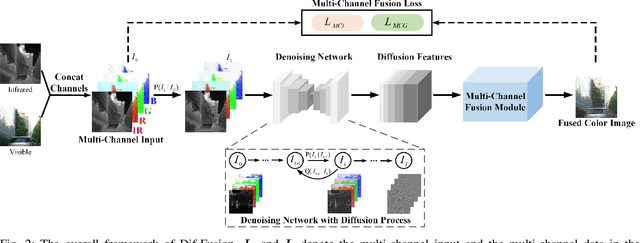
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.