 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiscale Graph Neural Network Autoencoders for Interpretable Scientific Machine Learning
Feb 13, 2023
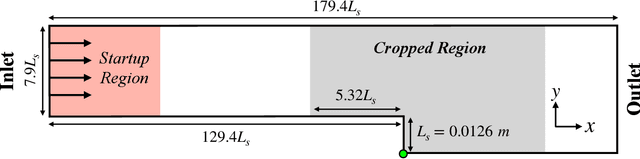
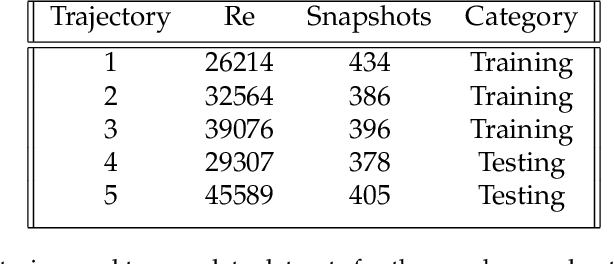
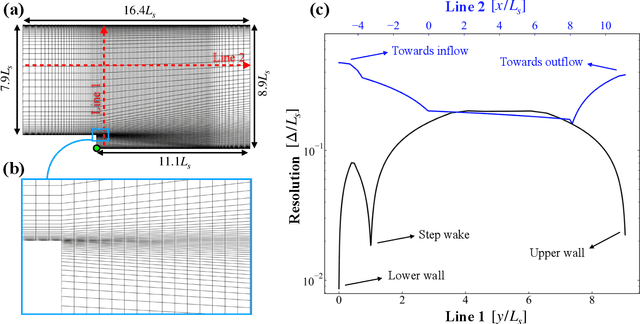
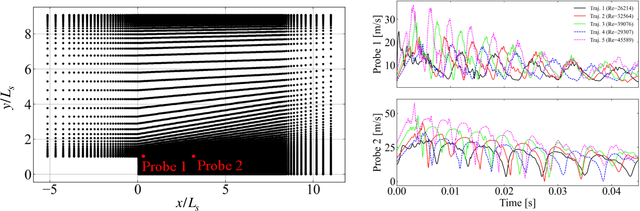
The goal of this work is to address two limitations in autoencoder-based models: latent space interpretability and compatibility with unstructured meshes. This is accomplished here with the development of a novel graph neural network (GNN) autoencoding architecture with demonstrations on complex fluid flow applications. To address the first goal of interpretability, the GNN autoencoder achieves reduction in the number nodes in the encoding stage through an adaptive graph reduction procedure. This reduction procedure essentially amounts to flowfield-conditioned node sampling and sensor identification, and produces interpretable latent graph representations tailored to the flowfield reconstruction task in the form of so-called masked fields. These masked fields allow the user to (a) visualize where in physical space a given latent graph is active, and (b) interpret the time-evolution of the latent graph connectivity in accordance with the time-evolution of unsteady flow features (e.g. recirculation zones, shear layers) in the domain. To address the goal of unstructured mesh compatibility, the autoencoding architecture utilizes a series of multi-scale message passing (MMP) layers, each of which models information exchange among node neighborhoods at various lengthscales. The MMP layer, which augments standard single-scale message passing with learnable coarsening operations, allows the decoder to more efficiently reconstruct the flowfield from the identified regions in the masked fields. Analysis of latent graphs produced by the autoencoder for various model settings are conducted using using unstructured snapshot data sourced from large-eddy simulations in a backward-facing step (BFS) flow configuration with an OpenFOAM-based flow solver at high Reynolds numbers.
Learning to Scale Temperature in Masked Self-Attention for Image Inpainting
Feb 13, 2023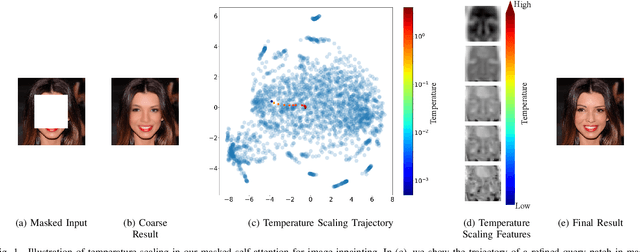

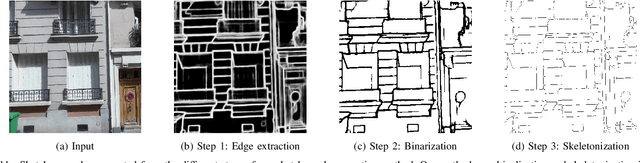
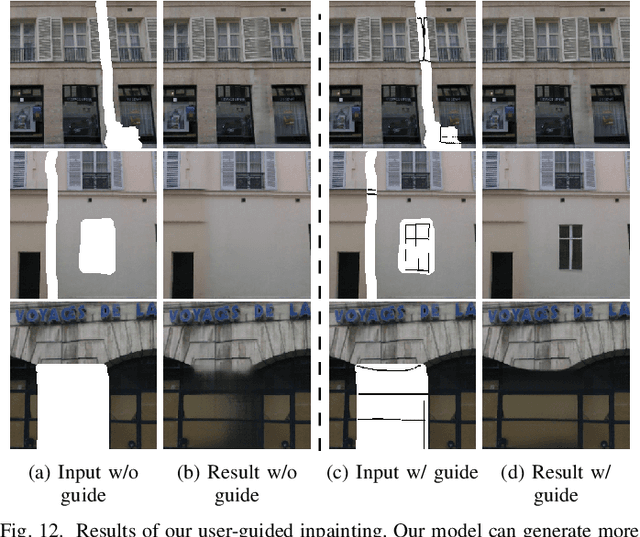
Recent advances in deep generative adversarial networks (GAN) and self-attention mechanism have led to significant improvements in the challenging task of inpainting large missing regions in an image. These methods integrate self-attention mechanism in neural networks to utilize surrounding neural elements based on their correlation and help the networks capture long-range dependencies. Temperature is a parameter in the Softmax function used in the self-attention, and it enables biasing the distribution of attention scores towards a handful of similar patches. Most existing self-attention mechanisms in image inpainting are convolution-based and set the temperature as a constant, performing patch matching in a limited feature space. In this work, we analyze the artifacts and training problems in previous self-attention mechanisms, and redesign the temperature learning network as well as the self-attention mechanism to address them. We present an image inpainting framework with a multi-head temperature masked self-attention mechanism, which provides stable and efficient temperature learning and uses multiple distant contextual information for high quality image inpainting. In addition to improving image quality of inpainting results, we generalize the proposed model to user-guided image editing by introducing a new sketch generation method. Extensive experiments on various datasets such as Paris StreetView, CelebA-HQ and Places2 clearly demonstrate that our method not only generates more natural inpainting results than previous works both in terms of perception image quality and quantitative metrics, but also enables to help users to generate more flexible results that are related to their sketch guidance.
Unified Vision-Language Representation Modeling for E-Commerce Same-Style Products Retrieval
Feb 10, 2023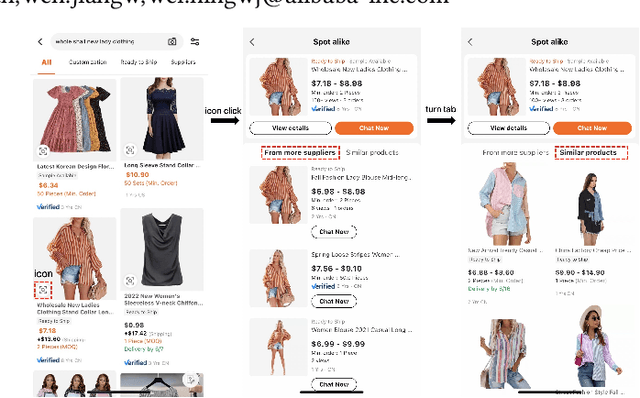
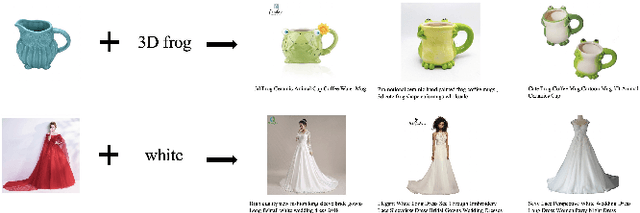
Same-style products retrieval plays an important role in e-commerce platforms, aiming to identify the same products which may have different text descriptions or images. It can be used for similar products retrieval from different suppliers or duplicate products detection of one supplier. Common methods use the image as the detected object, but they only consider the visual features and overlook the attribute information contained in the textual descriptions, and perform weakly for products in image less important industries like machinery, hardware tools and electronic component, even if an additional text matching module is added. In this paper, we propose a unified vision-language modeling method for e-commerce same-style products retrieval, which is designed to represent one product with its textual descriptions and visual contents. It contains one sampling skill to collect positive pairs from user click log with category and relevance constrained, and a novel contrastive loss unit to model the image, text, and image+text representations into one joint embedding space. It is capable of cross-modal product-to-product retrieval, as well as style transfer and user-interactive search. Offline evaluations on annotated data demonstrate its superior retrieval performance, and online testings show it can attract more clicks and conversions. Moreover, this model has already been deployed online for similar products retrieval in alibaba.com, the largest B2B e-commerce platform in the world.
PDSum: Prototype-driven Continuous Summarization of Evolving Multi-document Sets Stream
Feb 10, 2023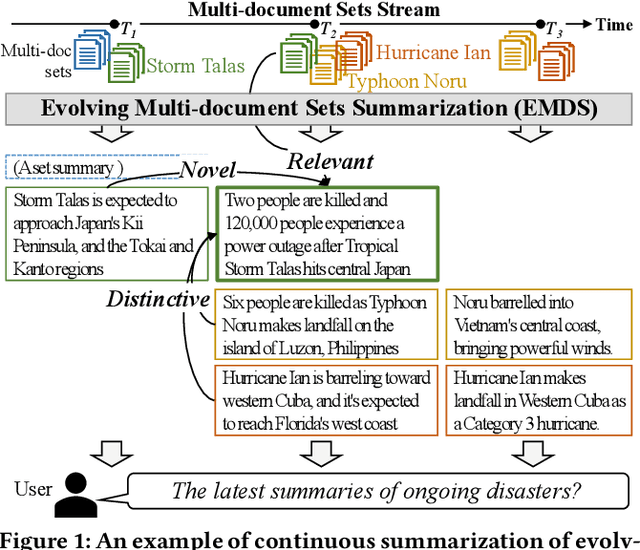

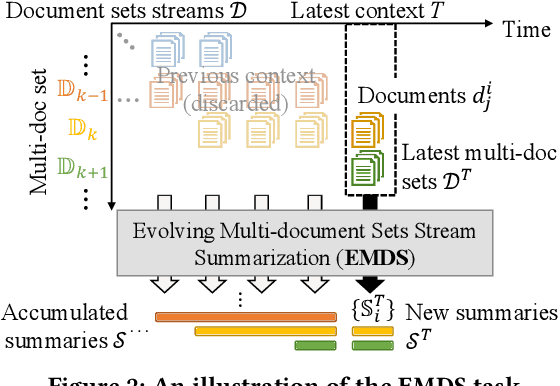

Summarizing text-rich documents has been long studied in the literature, but most of the existing efforts have been made to summarize a static and predefined multi-document set. With the rapid development of online platforms for generating and distributing text-rich documents, there arises an urgent need for continuously summarizing dynamically evolving multi-document sets where the composition of documents and sets is changing over time. This is especially challenging as the summarization should be not only effective in incorporating relevant, novel, and distinctive information from each concurrent multi-document set, but also efficient in serving online applications. In this work, we propose a new summarization problem, Evolving Multi-Document sets stream Summarization (EMDS), and introduce a novel unsupervised algorithm PDSum with the idea of prototype-driven continuous summarization. PDSum builds a lightweight prototype of each multi-document set and exploits it to adapt to new documents while preserving accumulated knowledge from previous documents. To update new summaries, the most representative sentences for each multi-document set are extracted by measuring their similarities to the prototypes. A thorough evaluation with real multi-document sets streams demonstrates that PDSum outperforms state-of-the-art unsupervised multi-document summarization algorithms in EMDS in terms of relevance, novelty, and distinctiveness and is also robust to various evaluation settings.
Effects of noise on the overparametrization of quantum neural networks
Feb 10, 2023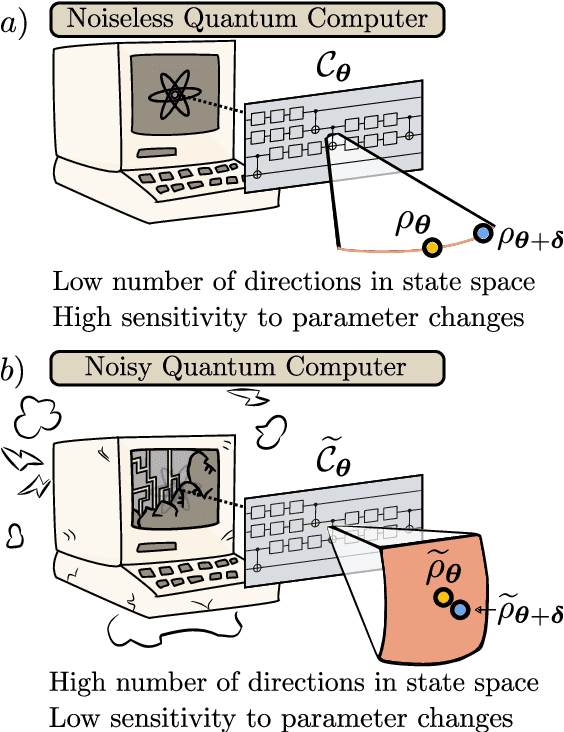
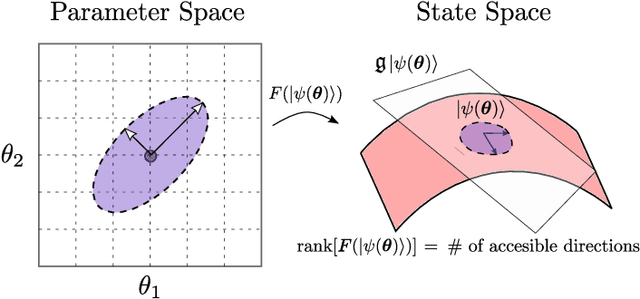
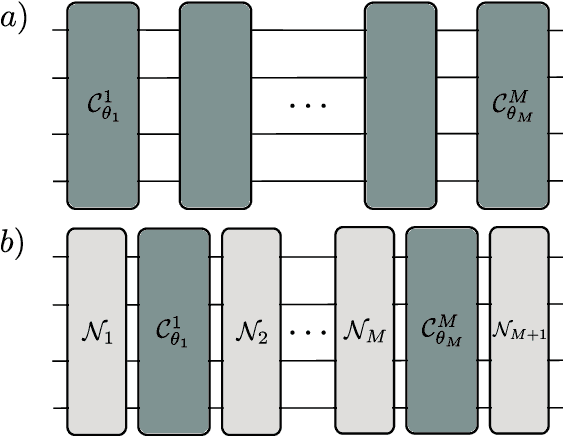
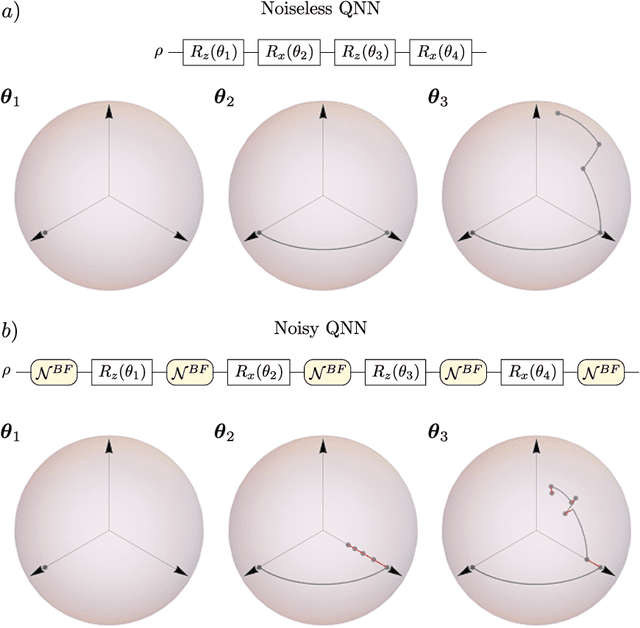
Overparametrization is one of the most surprising and notorious phenomena in machine learning. Recently, there have been several efforts to study if, and how, Quantum Neural Networks (QNNs) acting in the absence of hardware noise can be overparametrized. In particular, it has been proposed that a QNN can be defined as overparametrized if it has enough parameters to explore all available directions in state space. That is, if the rank of the Quantum Fisher Information Matrix (QFIM) for the QNN's output state is saturated. Here, we explore how the presence of noise affects the overparametrization phenomenon. Our results show that noise can "turn on" previously-zero eigenvalues of the QFIM. This enables the parametrized state to explore directions that were otherwise inaccessible, thus potentially turning an overparametrized QNN into an underparametrized one. For small noise levels, the QNN is quasi-overparametrized, as large eigenvalues coexists with small ones. Then, we prove that as the magnitude of noise increases all the eigenvalues of the QFIM become exponentially suppressed, indicating that the state becomes insensitive to any change in the parameters. As such, there is a pull-and-tug effect where noise can enable new directions, but also suppress the sensitivity to parameter updates. Finally, our results imply that current QNN capacity measures are ill-defined when hardware noise is present.
Automatic Classification of Bug Reports Based on Multiple Text Information and Reports' Intention
Aug 02, 2022With the rapid growth of software scale and complexity, a large number of bug reports are submitted to the bug tracking system. In order to speed up defect repair, these reports need to be accurately classified so that they can be sent to the appropriate developers. However, the existing classification methods only use the text information of the bug report, which leads to their low performance. To solve the above problems, this paper proposes a new automatic classification method for bug reports. The innovation is that when categorizing bug reports, in addition to using the text information of the report, the intention of the report (i.e. suggestion or explanation) is also considered, thereby improving the performance of the classification. First, we collect bug reports from four ecosystems (Apache, Eclipse, Gentoo, Mozilla) and manually annotate them to construct an experimental data set. Then, we use Natural Language Processing technology to preprocess the data. On this basis, BERT and TF-IDF are used to extract the features of the intention and the multiple text information. Finally, the features are used to train the classifiers. The experimental result on five classifiers (including K-Nearest Neighbor, Naive Bayes, Logistic Regression, Support Vector Machine, and Random Forest) show that our proposed method achieves better performance and its F-Measure achieves from 87.3% to 95.5%.
IDEAL: Toward High-efficiency Device-Cloud Collaborative and Dynamic Recommendation System
Feb 14, 2023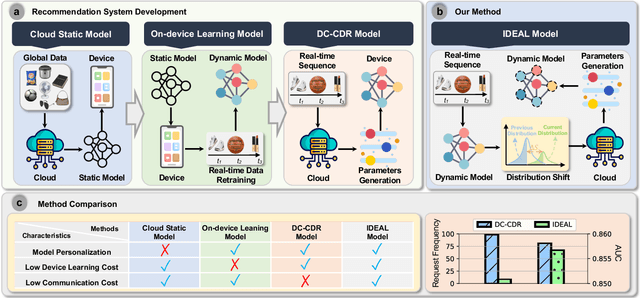
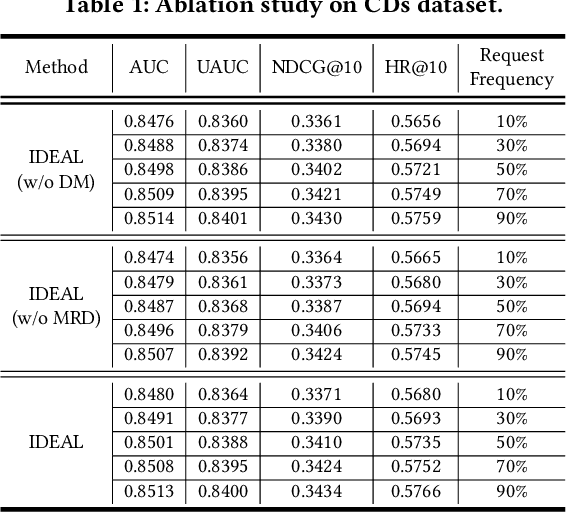
Recommendation systems have shown great potential to solve the information explosion problem and enhance user experience in various online applications, which recently present two emerging trends: (i) Collaboration: single-sided model trained on-cloud (separate learning) to the device-cloud collaborative recommendation (collaborative learning). (ii) Real-time Dynamic: the network parameters are the same across all the instances (static model) to adaptive network parameters generation conditioned on the real-time instances (dynamic model). The aforementioned two trends enable the device-cloud collaborative and dynamic recommendation, which deeply exploits the recommendation pattern among cloud-device data and efficiently characterizes different instances with different underlying distributions based on the cost of frequent device-cloud communication. Despite promising, we argue that most of the communications are unnecessary to request the new parameters of the recommendation system on the cloud since the on-device data distribution are not always changing. To alleviate this issue, we designed a Intelligent DEvice-Cloud PArameter Request ModeL (IDEAL) that can be deployed on the device to calculate the request revenue with low resource consumption, so as to ensure the adaptive device-cloud communication with high revenue. We envision a new device intelligence learning task to implement IDEAL by detecting the data out-of-domain. Moreover, we map the user's real-time behavior to a normal distribution, the uncertainty is calculated by the multi-sampling outputs to measure the generalization ability of the device model to the current user behavior. Our experimental study demonstrates IDEAL's effectiveness and generalizability on four public benchmarks, which yield a higher efficient device-cloud collaborative and dynamic recommendation paradigm.
ContrasInver: Voxel-wise Contrastive Semi-supervised Learning for Seismic Inversion
Feb 14, 2023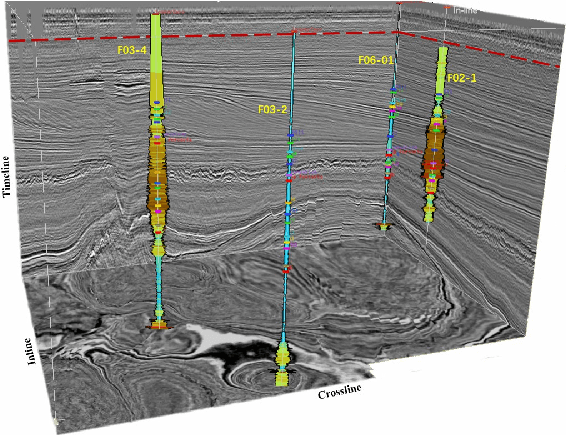
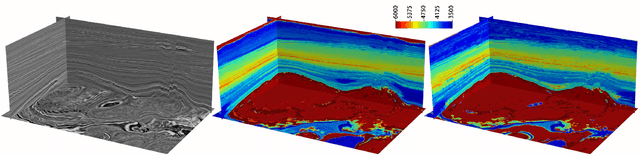
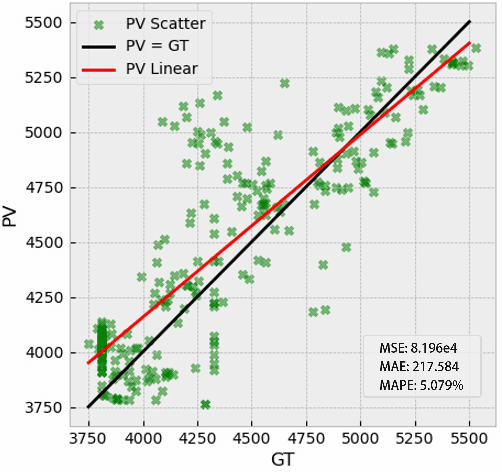
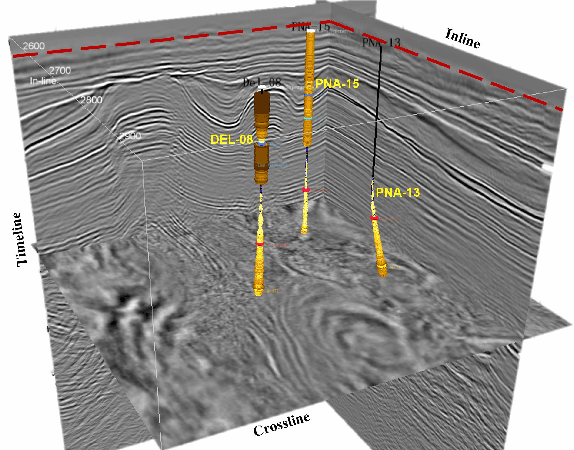
Recent studies have shown that learning theories have been very successful in hydrocarbon exploration. Inversion of seismic into various attributes through the relationship of 1D well-logs and 3D seismic is an essential step in reservoir description, among which, acoustic impedance is one of the most critical attributes, and although current deep learningbased impedance inversion obtains promising results, it relies on a large number of logs (1D labels, typically more than 30 well-logs are required per inversion), which is unacceptable in many practical explorations. In this work, we define acoustic impedance inversion as a regression task for learning sparse 1D labels from 3D volume data and propose a voxel-wise semisupervised contrastive learning framework, ContrasInver, for regression tasks under sparse labels. ConstraInver consists of several key components, including a novel pre-training method for 3D seismic data inversion, a contrastive semi-supervised strategy for diffusing well-log information to the global, and a continuous-value vectorized characterization method for a contrastive learning-based regression task, and also designed the distance TopK sampling method for improving the training efficiency. We performed a complete ablation study on SEAM Phase I synthetic data to verify the effectiveness of each component and compared our approach with the current mainstream methods on this data, and our approach demonstrated very significant advantages. In this data we achieved an SSIM of 0.92 and an MSE of 0.079 with only four well-logs. ConstraInver is the first purely data-driven approach to invert two classic field data, F3 Netherlands (only four well-logs) and Delft (only three well-logs) and achieves very reasonable and reliable results.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023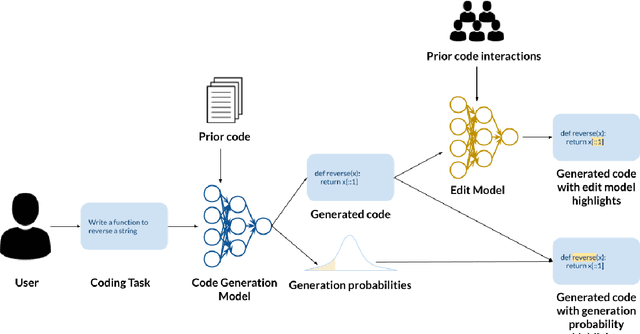
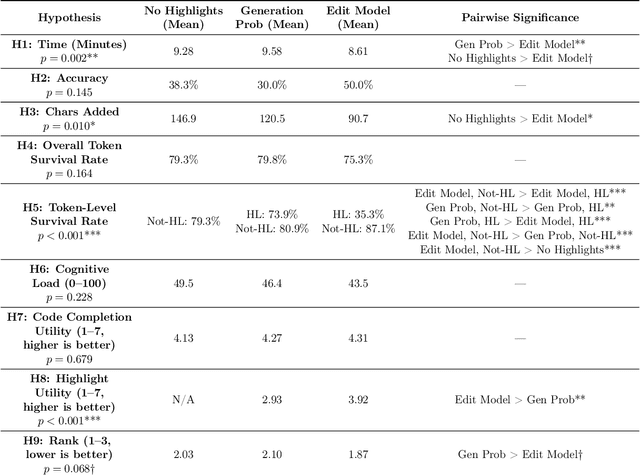


Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.
Model-based inexact graph matching on top of CNNs for semantic scene understanding
Jan 18, 2023

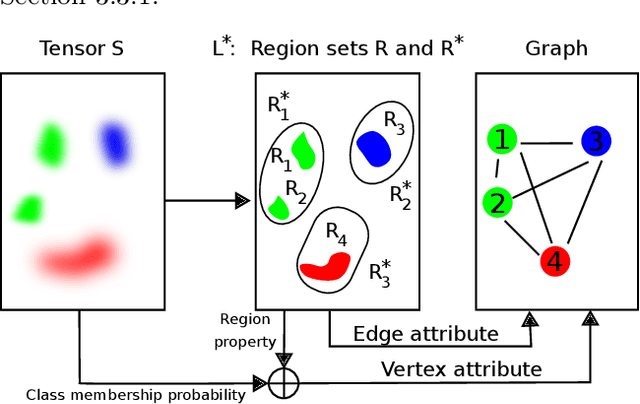
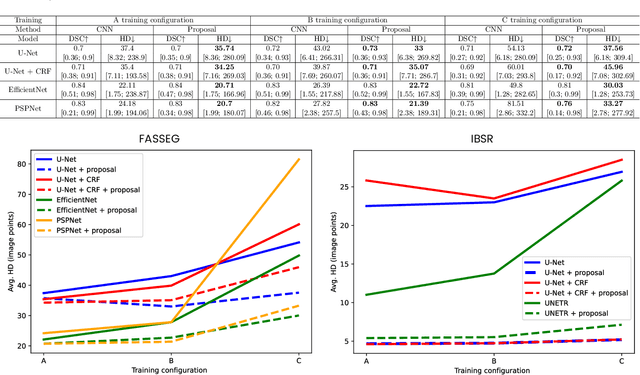
Deep learning based pipelines for semantic segmentation often ignore structural information available on annotated images used for training. We propose a novel post-processing module enforcing structural knowledge about the objects of interest to improve segmentation results provided by deep learning. This module corresponds to a "many-to-one-or-none" inexact graph matching approach, and is formulated as a quadratic assignment problem. Our approach is compared to a CNN-based segmentation (for various CNN backbones) on two public datasets, one for face segmentation from 2D RGB images (FASSEG), and the other for brain segmentation from 3D MRIs (IBSR). Evaluations are performed using two types of structural information (distances and directional relations, , this choice being a hyper-parameter of our generic framework). On FASSEG data, results show that our module improves accuracy of the CNN by about 6.3% (the Hausdorff distance decreases from 22.11 to 20.71). On IBSR data, the improvement is of 51% (the Hausdorff distance decreases from 11.01 to 5.4). In addition, our approach is shown to be resilient to small training datasets that often limit the performance of deep learning methods: the improvement increases as the size of the training dataset decreases.