 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adapting to Continuous Covariate Shift via Online Density Ratio Estimation
Feb 06, 2023
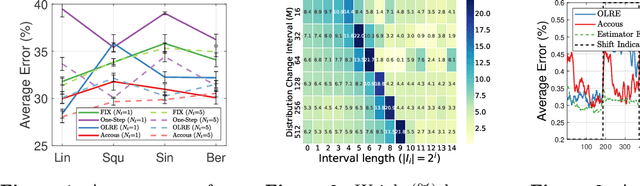
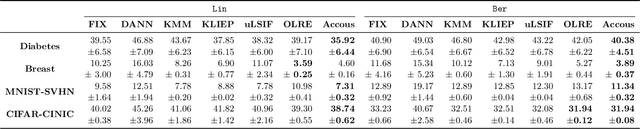
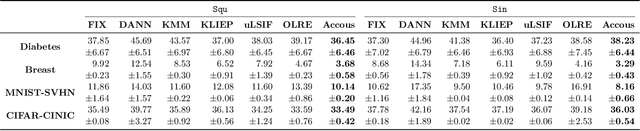
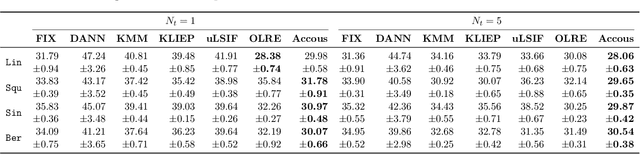
Dealing with distribution shifts is one of the central challenges for modern machine learning. One fundamental situation is the \emph{covariate shift}, where the input distributions of data change from training to testing stages while the input-conditional output distribution remains unchanged. In this paper, we initiate the study of a more challenging scenario -- \emph{continuous} covariate shift -- in which the test data appear sequentially, and their distributions can shift continuously. Our goal is to adaptively train the predictor such that its prediction risk accumulated over time can be minimized. Starting with the importance-weighted learning, we show the method works effectively if the time-varying density ratios of test and train inputs can be accurately estimated. However, existing density ratio estimation methods would fail due to data scarcity at each time step. To this end, we propose an online method that can appropriately reuse historical information. Our density ratio estimation method is proven to perform well by enjoying a dynamic regret bound, which finally leads to an excess risk guarantee for the predictor. Empirical results also validate the effectiveness.
Cross-Fusion Rule for Personalized Federated Learning
Feb 06, 2023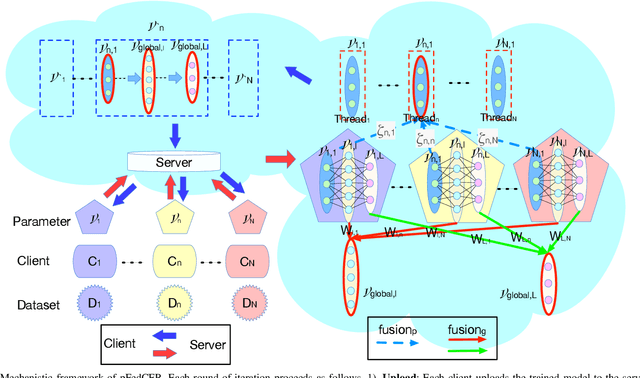
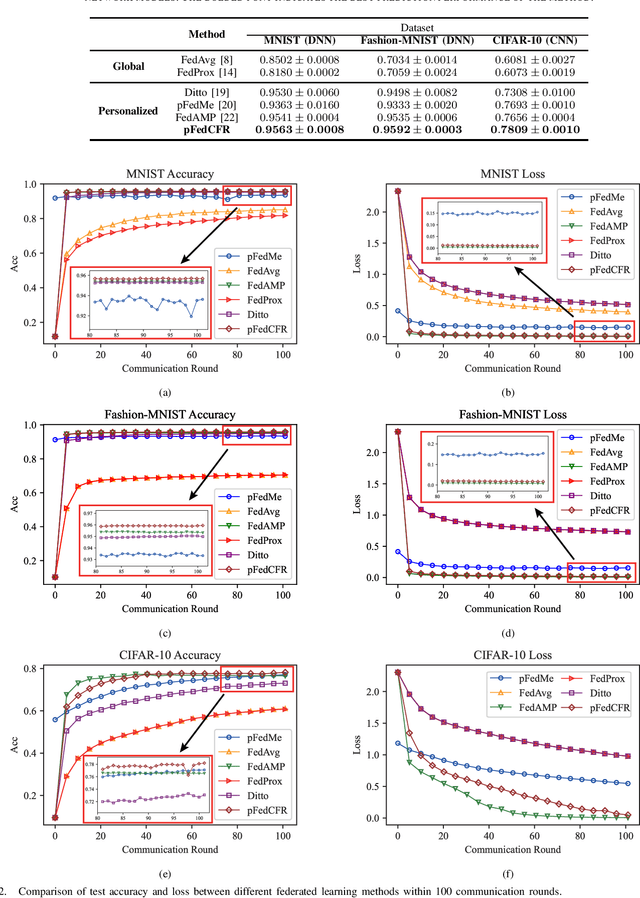
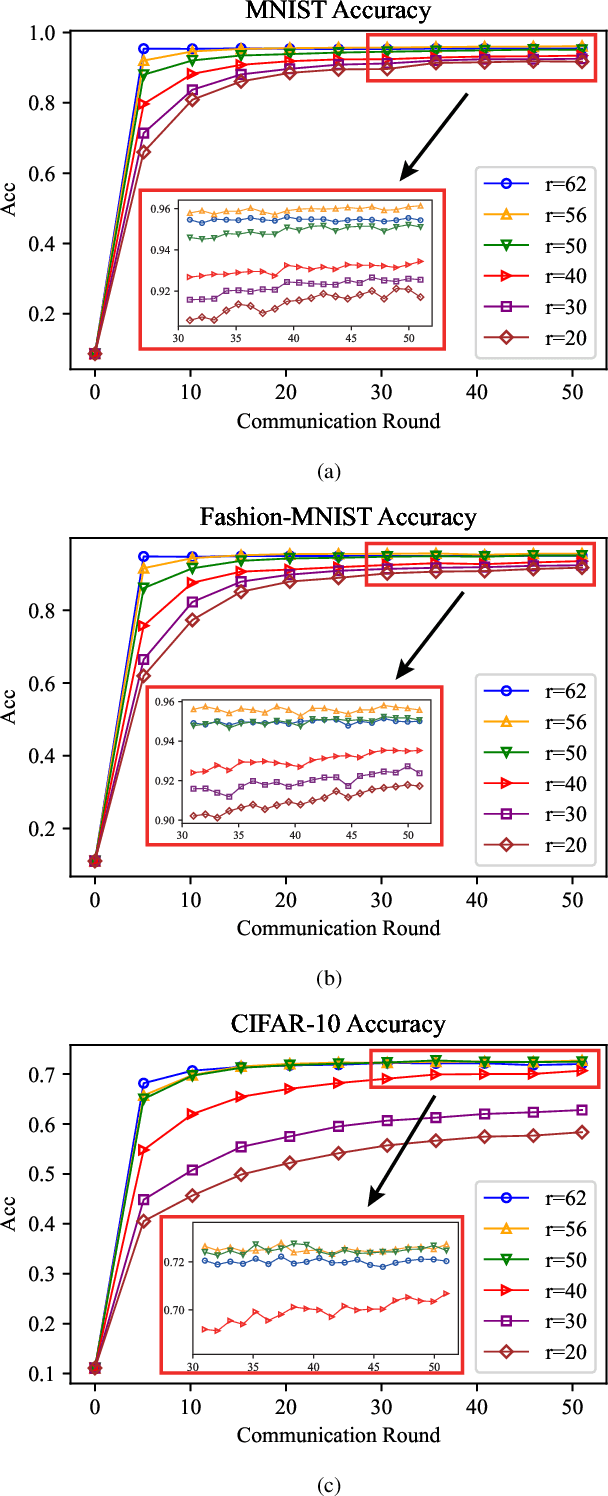

Data scarcity and heterogeneity pose significant performance challenges for personalized federated learning, and these challenges are mainly reflected in overfitting and low precision in existing methods. To overcome these challenges, a multi-layer multi-fusion strategy framework is proposed in this paper, i.e., the server adopts the network layer parameters of each client upload model as the basic unit of fusion for information-sharing calculation. Then, a new fusion strategy combining personalized and generic is purposefully proposed, and the network layer number fusion threshold of each fusion strategy is designed according to the network layer function. Under this mechanism, the L2-Norm negative exponential similarity metric is employed to calculate the fusion weights of the corresponding feature extraction layer parameters for each client, thus improving the efficiency of heterogeneous data personalized collaboration. Meanwhile, the federated global optimal model approximation fusion strategy is adopted in the network full-connect layer, and this generic fusion strategy alleviates the overfitting introduced by forceful personalized. Finally, the experimental results show that the proposed method is superior to the state-of-the-art methods.
Connectivity Enhanced Safe Neural Network Planner for Lane Changing in Mixed Traffic
Feb 06, 2023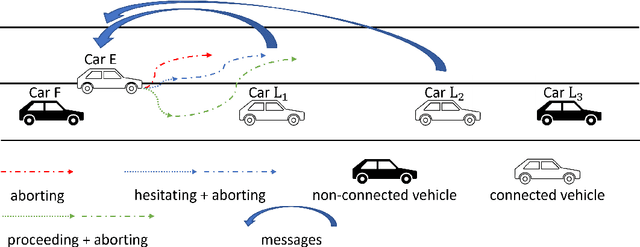
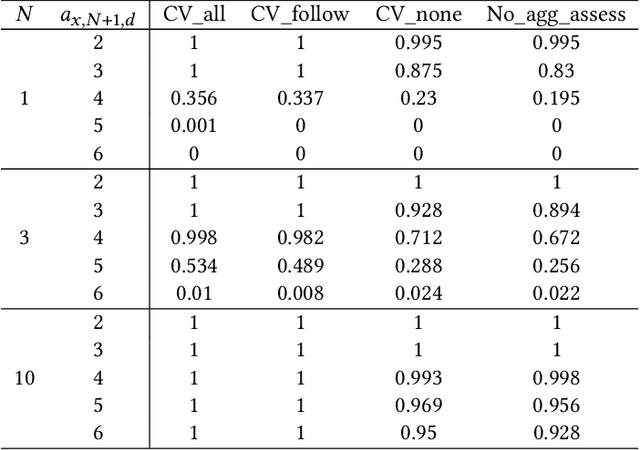
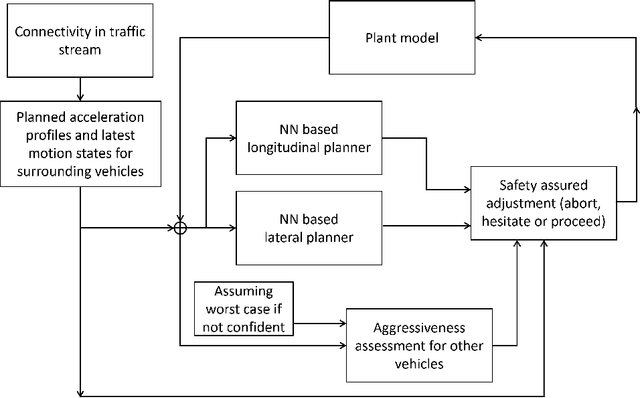
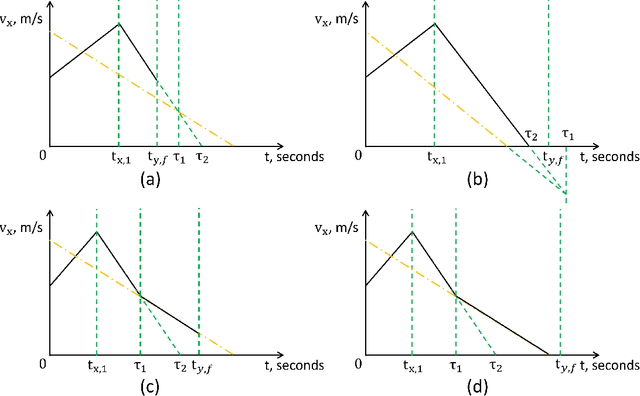
Connectivity technology has shown great potentials in improving the safety and efficiency of transportation systems by providing information beyond the perception and prediction capabilities of individual vehicles. However, it is expected that human-driven and autonomous vehicles, and connected and non-connected vehicles need to share the transportation network during the transition period to fully connected and automated transportation systems. Such mixed traffic scenarios significantly increase the complexity in analyzing system behavior and quantifying uncertainty for highly interactive scenarios, e.g., lane changing. It is even harder to ensure system safety when neural network based planners are leveraged to further improve efficiency. In this work, we propose a connectivity-enhanced neural network based lane changing planner. By cooperating with surrounding connected vehicles in dynamic environment, our proposed planner will adapt its planned trajectory according to the analysis of a safe evasion trajectory. We demonstrate the strength of our planner design in improving efficiency and ensuring safety in various mixed traffic scenarios with extensive simulations. We also analyze the system robustness when the communication or coordination is not perfect.
In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation
Feb 06, 2023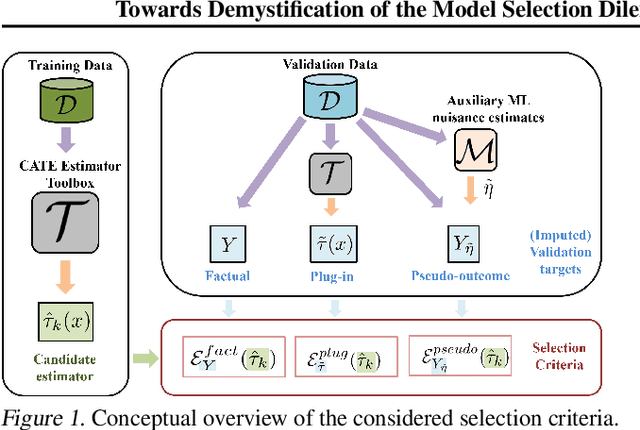
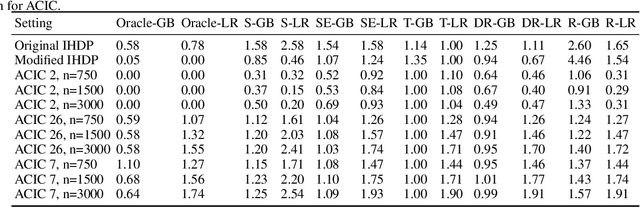

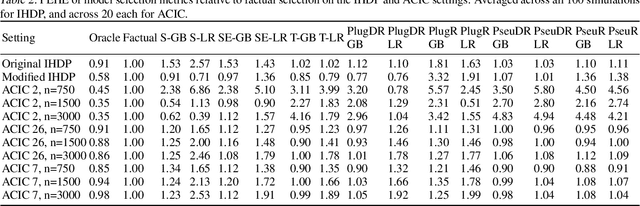
Personalized treatment effect estimates are often of interest in high-stakes applications -- thus, before deploying a model estimating such effects in practice, one needs to be sure that the best candidate from the ever-growing machine learning toolbox for this task was chosen. Unfortunately, due to the absence of counterfactual information in practice, it is usually not possible to rely on standard validation metrics for doing so, leading to a well-known model selection dilemma in the treatment effect estimation literature. While some solutions have recently been investigated, systematic understanding of the strengths and weaknesses of different model selection criteria is still lacking. In this paper, instead of attempting to declare a global `winner', we therefore empirically investigate success- and failure modes of different selection criteria. We highlight that there is a complex interplay between selection strategies, candidate estimators and the DGP used for testing, and provide interesting insights into the relative (dis)advantages of different criteria alongside desiderata for the design of further illuminating empirical studies in this context.
Fast-MC-PET: A Novel Deep Learning-aided Motion Correction and Reconstruction Framework for Accelerated PET
Feb 14, 2023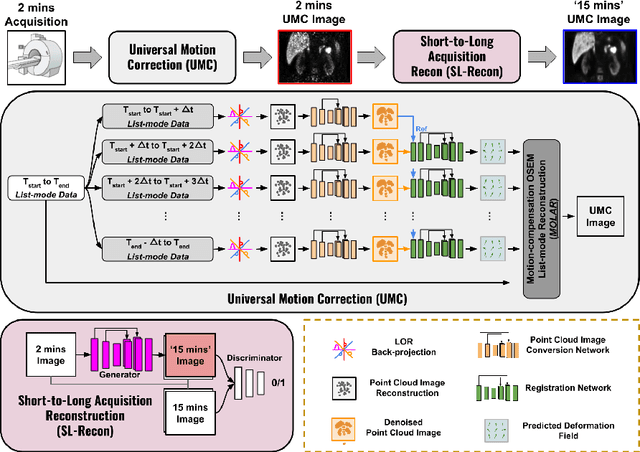
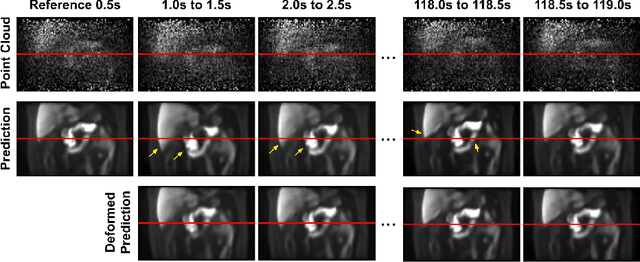

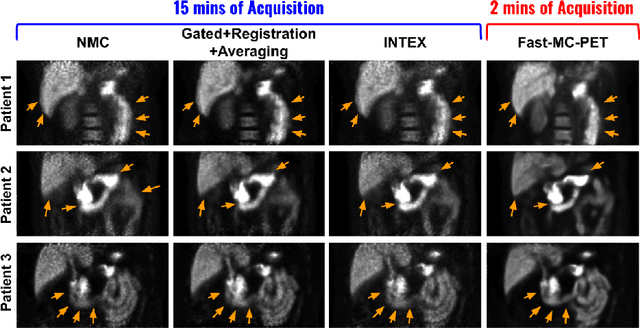
Patient motion during PET is inevitable. Its long acquisition time not only increases the motion and the associated artifacts but also the patient's discomfort, thus PET acceleration is desirable. However, accelerating PET acquisition will result in reconstructed images with low SNR, and the image quality will still be degraded by motion-induced artifacts. Most of the previous PET motion correction methods are motion type specific that require motion modeling, thus may fail when multiple types of motion present together. Also, those methods are customized for standard long acquisition and could not be directly applied to accelerated PET. To this end, modeling-free universal motion correction reconstruction for accelerated PET is still highly under-explored. In this work, we propose a novel deep learning-aided motion correction and reconstruction framework for accelerated PET, called Fast-MC-PET. Our framework consists of a universal motion correction (UMC) and a short-to-long acquisition reconstruction (SL-Reon) module. The UMC enables modeling-free motion correction by estimating quasi-continuous motion from ultra-short frame reconstructions and using this information for motion-compensated reconstruction. Then, the SL-Recon converts the accelerated UMC image with low counts to a high-quality image with high counts for our final reconstruction output. Our experimental results on human studies show that our Fast-MC-PET can enable 7-fold acceleration and use only 2 minutes acquisition to generate high-quality reconstruction images that outperform/match previous motion correction reconstruction methods using standard 15 minutes long acquisition data.
Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?
Jan 26, 2023
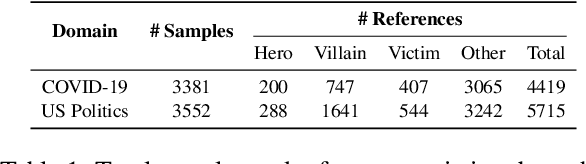
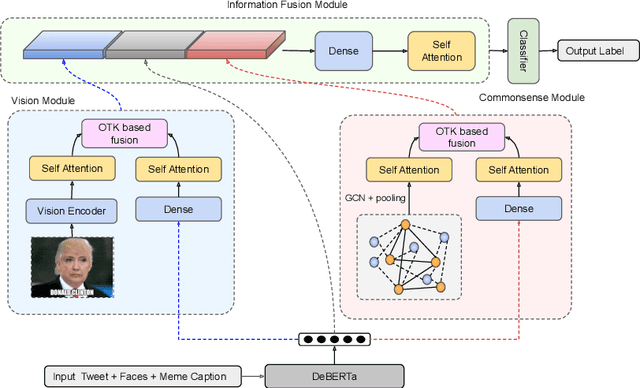
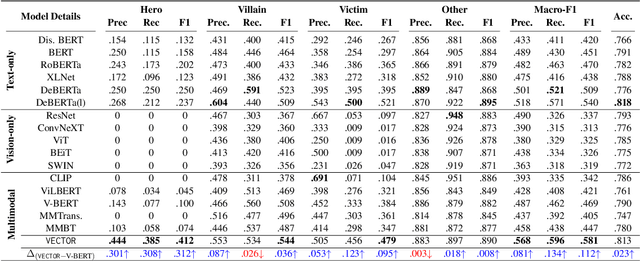
Memes can sway people's opinions over social media as they combine visual and textual information in an easy-to-consume manner. Since memes instantly turn viral, it becomes crucial to infer their intent and potentially associated harmfulness to take timely measures as needed. A common problem associated with meme comprehension lies in detecting the entities referenced and characterizing the role of each of these entities. Here, we aim to understand whether the meme glorifies, vilifies, or victimizes each entity it refers to. To this end, we address the task of role identification of entities in harmful memes, i.e., detecting who is the 'hero', the 'villain', and the 'victim' in the meme, if any. We utilize HVVMemes - a memes dataset on US Politics and Covid-19 memes, released recently as part of the CONSTRAINT@ACL-2022 shared-task. It contains memes, entities referenced, and their associated roles: hero, villain, victim, and other. We further design VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation and compare it to several standard unimodal (text-only or image-only) or multi-modal (image+text) models. Our experimental results show that our proposed model achieves an improvement of 4% over the best baseline and 1% over the best competing stand-alone submission from the shared-task. Besides divulging an extensive experimental setup with comparative analyses, we finally highlight the challenges encountered in addressing the complex task of semantic role labeling within memes.
CitationSum: Citation-aware Graph Contrastive Learning for Scientific Paper Summarization
Jan 26, 2023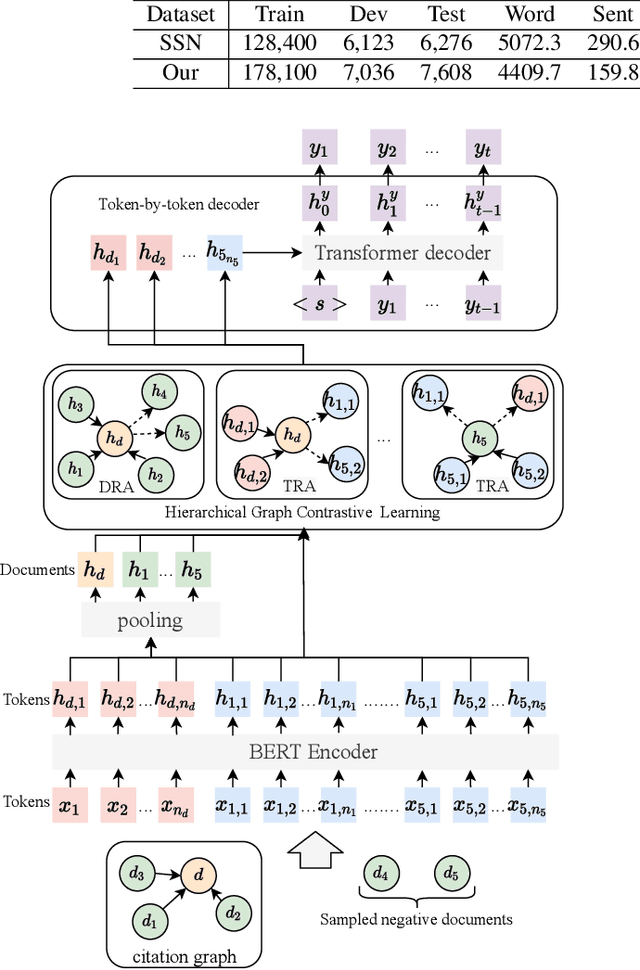

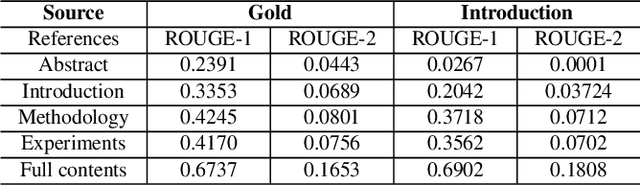
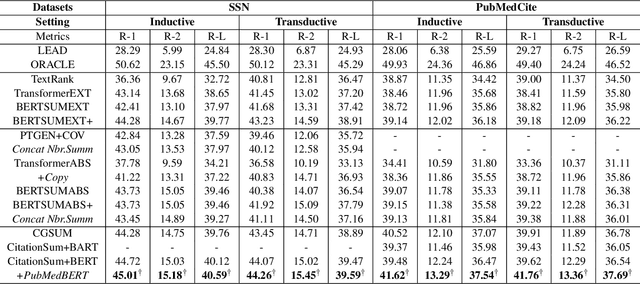
The citation graph is essential for generating high-quality summaries of scientific papers, in which references of a scientific paper and their correlations provide extra knowledge for understanding its background and main contributions. Despite the promising role of the citation graph, effectively incorporating it still remains a big challenge, given the difficulty of accurately identifying and leveraging relevant contents in references for a source paper, as well as modelling their correlations of different intensities. Existing methods either ignore or utilize only abstracts indiscriminately from references, failing to tackle the challenge mentioned above. To fill the gap, we propose a novel citation-aware scientific paper summarization framework based on the citation graph, with the ability to accurately locate and incorporate the salient contents from references, as well as capture varying relevance between source papers and their references. Specifically, we first build a domain-specific dataset PubMedCite with about 192K biomedical scientific papers and a large citation graph preserving 917K citation relationships between them. It is characterized by preserving the salient contents extracted from full texts of references, and the weighted correlation between the salient contents of references and the source paper. Based on it, we design a self-supervised citation-aware summarization framework (CitationSum) with graph contrastive learning, which boosts the summarization generation by efficiently fusing the salient information in references with source paper contents under the guidance of their correlations. Experimental results show that our model outperforms the state-of-the-art methods, due to efficiently leveraging the information of references and citation correlations.
A Concurrent CNN-RNN Approach for Multi-Step Wind Power Forecasting
Jan 02, 2023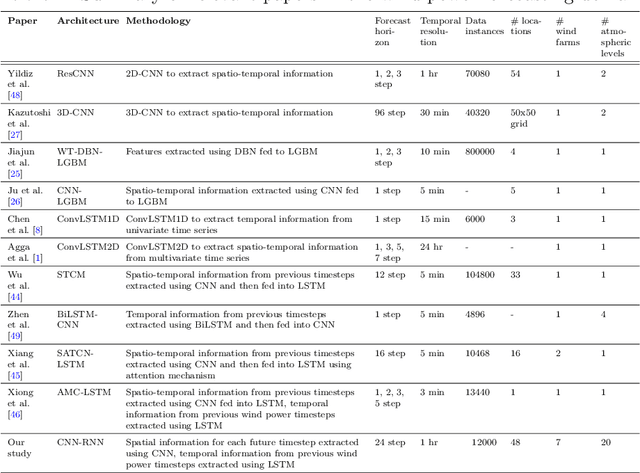
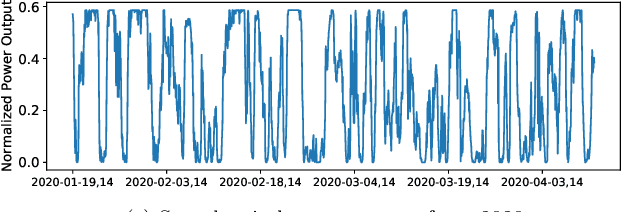

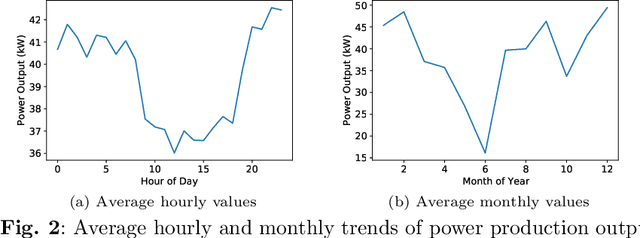
Wind power forecasting helps with the planning for the power systems by contributing to having a higher level of certainty in decision-making. Due to the randomness inherent to meteorological events (e.g., wind speeds), making highly accurate long-term predictions for wind power can be extremely difficult. One approach to remedy this challenge is to utilize weather information from multiple points across a geographical grid to obtain a holistic view of the wind patterns, along with temporal information from the previous power outputs of the wind farms. Our proposed CNN-RNN architecture combines convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract spatial and temporal information from multi-dimensional input data to make day-ahead predictions. In this regard, our method incorporates an ultra-wide learning view, combining data from multiple numerical weather prediction models, wind farms, and geographical locations. Additionally, we experiment with global forecasting approaches to understand the impact of training the same model over the datasets obtained from multiple different wind farms, and we employ a method where spatial information extracted from convolutional layers is passed to a tree ensemble (e.g., Light Gradient Boosting Machine (LGBM)) instead of fully connected layers. The results show that our proposed CNN-RNN architecture outperforms other models such as LGBM, Extra Tree regressor and linear regression when trained globally, but fails to replicate such performance when trained individually on each farm. We also observe that passing the spatial information from CNN to LGBM improves its performance, providing further evidence of CNN's spatial feature extraction capabilities.
Modeling Non-deterministic Human Behaviors in Discrete Food Choices
Jan 23, 2023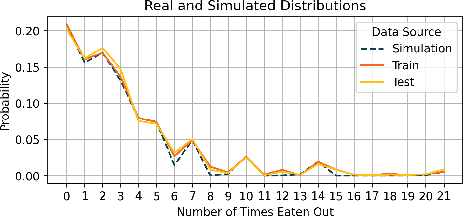
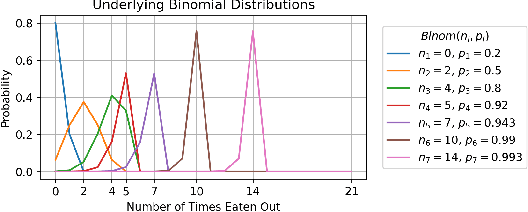
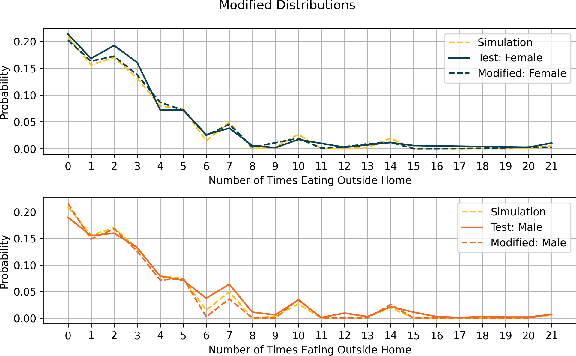
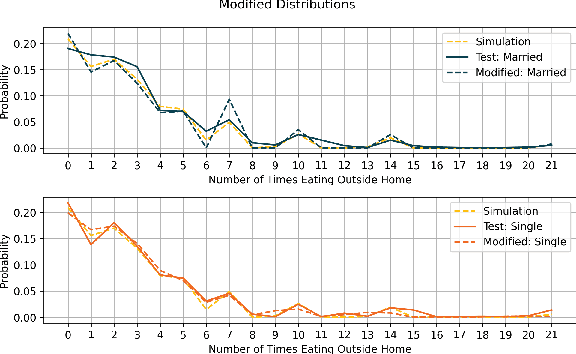
We establish a non-deterministic model that predicts a user's food preferences from their demographic information. Our simulator is based on NHANES dataset and domain expert knowledge in the form of established behavioral studies. Our model can be used to generate an arbitrary amount of synthetic datapoints that are similar in distribution to the original dataset and align with behavioral science expectations. Such a simulator can be used in a variety of machine learning tasks and especially in applications requiring human behavior prediction.
The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation
Jan 21, 2023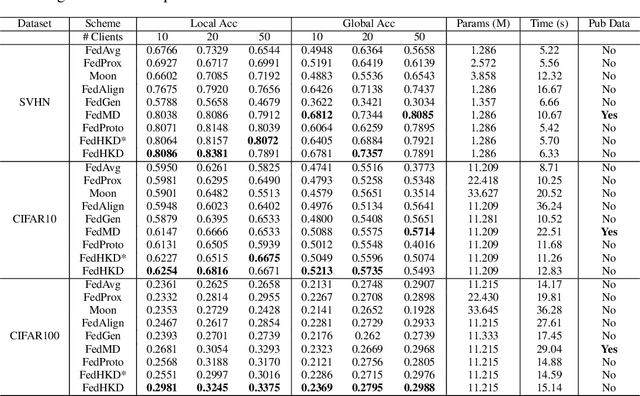
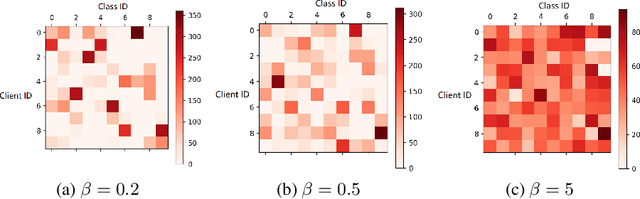
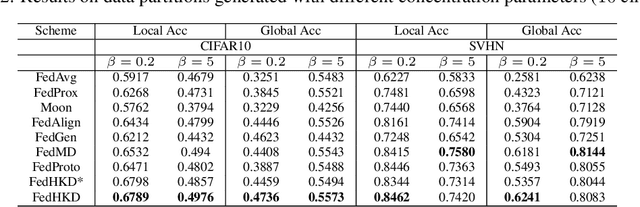
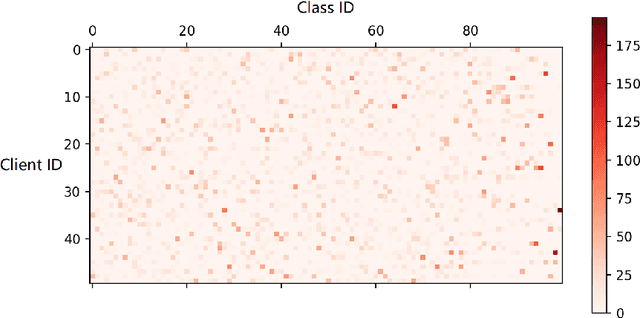
Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model's accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions -- information that we refer to as ``hyper-knowledge". The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.