 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving the Generalizability of Collaborative Dialogue Analysis with Multi-Feature Embeddings
Feb 09, 2023
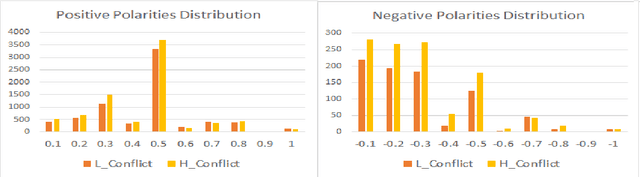
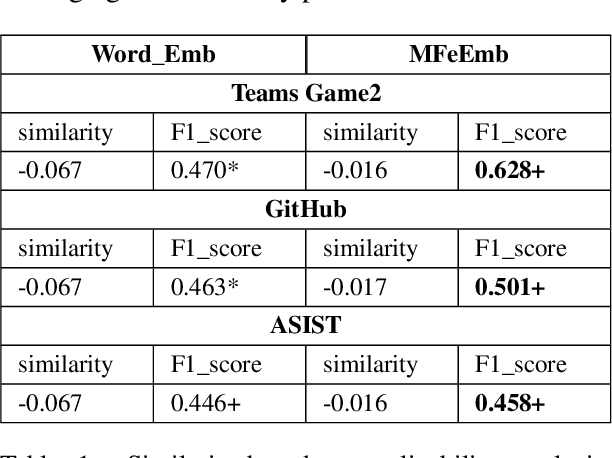
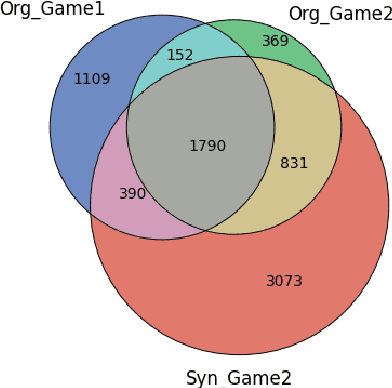
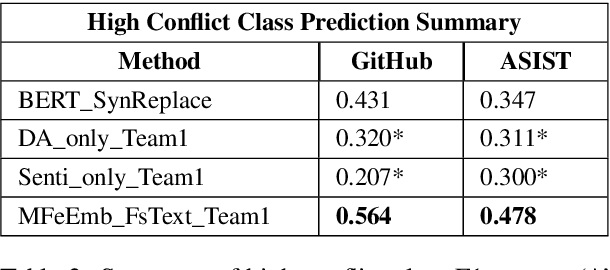
Conflict prediction in communication is integral to the design of virtual agents that support successful teamwork by providing timely assistance. The aim of our research is to analyze discourse to predict collaboration success. Unfortunately, resource scarcity is a problem that teamwork researchers commonly face since it is hard to gather a large number of training examples. To alleviate this problem, this paper introduces a multi-feature embedding (MFeEmb) that improves the generalizability of conflict prediction models trained on dialogue sequences. MFeEmb leverages textual, structural, and semantic information from the dialogues by incorporating lexical, dialogue acts, and sentiment features. The use of dialogue acts and sentiment features reduces performance loss from natural distribution shifts caused mainly by changes in vocabulary. This paper demonstrates the performance of MFeEmb on domain adaptation problems in which the model is trained on discourse from one task domain and applied to predict team performance in a different domain. The generalizability of MFeEmb is quantified using the similarity measure proposed by Bontonou et al. (2021). Our results show that MFeEmb serves as an excellent domain-agnostic representation for meta-pretraining a few-shot model on collaborative multiparty dialogues.
Incorporating Total Variation Regularization in the design of an intelligent Query by Humming system
Feb 09, 2023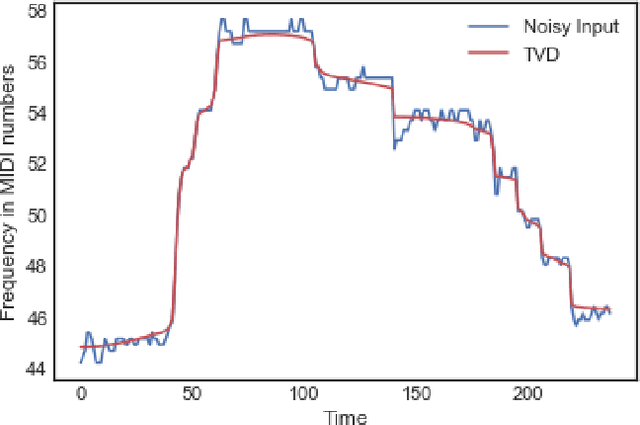
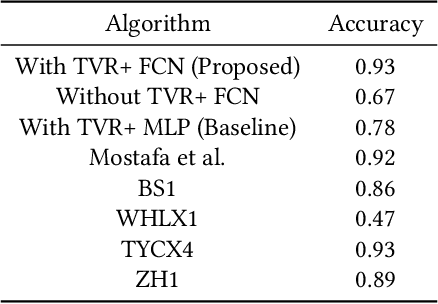
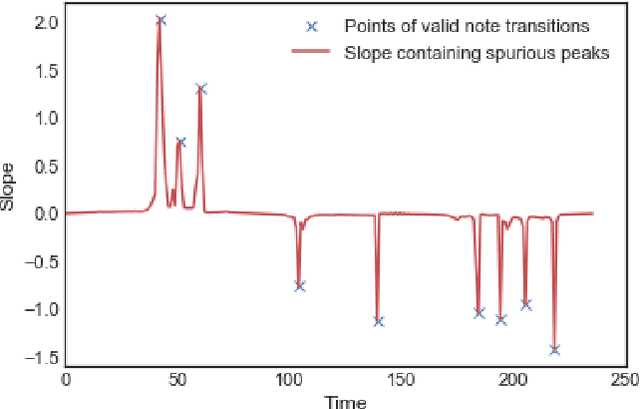
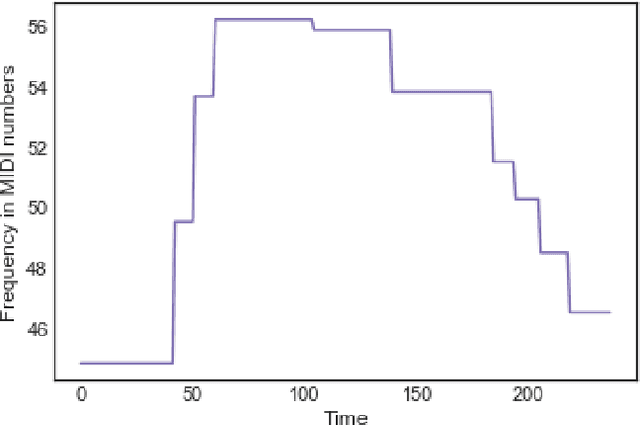
A Query-By-Humming (QBH) system constitutes a particular case of music information retrieval where the input is a user-hummed melody and the output is the original song which contains that melody. A typical QBH system consists of melody extraction and candidate melody retrieval. For melody extraction, accurate note transcription is the key enabling technology. However, current transcription methods are unable to definitively capture the melody and address inaccuracies in user-hummed queries. In this paper, we incorporate Total Variation Regularization (TVR) to denoise queries. This approach accounts for user error in humming without loss of meaningful data and reliably captures the underlying melody. For candidate melody retrieval, we employ a deep learning approach to time series classification using a Fully Convolutional Neural Network. The trained network classifies the incoming query as belonging to one of the target songs. For our experiments, we use Roger Jang's MIR-QBSH dataset which is the standard MIREX dataset. We demonstrate that inclusion of TVR denoised queries in the training set enhances the overall accuracy of the system to 93% which is higher than other state-of-the-art QBH systems.
Variational multichannel multiclass segmentation\endgraf using unsupervised lifting with CNNs
Feb 04, 2023


We propose an unsupervised image segmentation approach, that combines a variational energy functional and deep convolutional neural networks. The variational part is based on a recent multichannel multiphase Chan-Vese model, which is capable to extract useful information from multiple input images simultaneously. We implement a flexible multiclass segmentation method that divides a given image into $K$ different regions. We use convolutional neural networks (CNNs) targeting a pre-decomposition of the image. By subsequently minimising the segmentation functional, the final segmentation is obtained in a fully unsupervised manner. Special emphasis is given to the extraction of informative feature maps serving as a starting point for the segmentation. The initial results indicate that the proposed method is able to decompose and segment the different regions of various types of images, such as texture and medical images and compare its performance with another multiphase segmentation method.
VuLASTE: Long Sequence Model with Abstract Syntax Tree Embedding for vulnerability Detection
Feb 05, 2023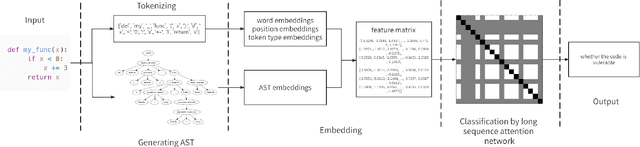
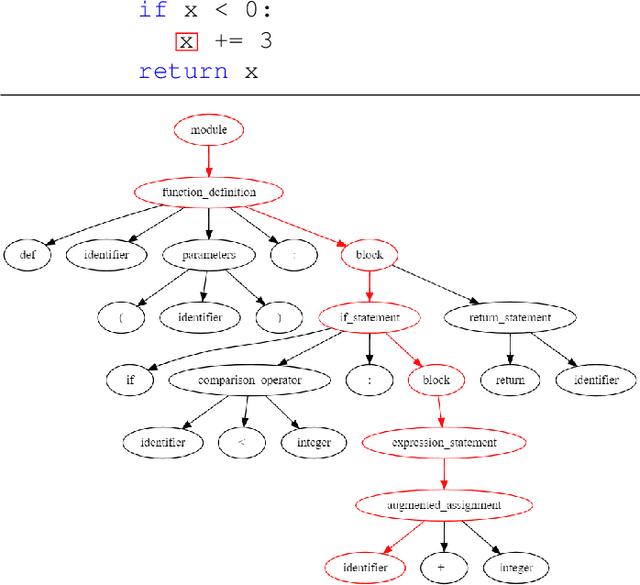
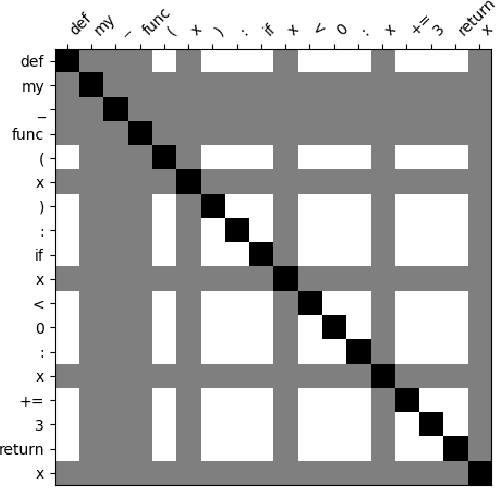

In this paper, we build a model named VuLASTE, which regards vulnerability detection as a special text classification task. To solve the vocabulary explosion problem, VuLASTE uses a byte level BPE algorithm from natural language processing. In VuLASTE, a new AST path embedding is added to represent source code nesting information. We also use a combination of global and dilated window attention from Longformer to extract long sequence semantic from source code. To solve the data imbalance problem, which is a common problem in vulnerability detection datasets, focal loss is used as loss function to make model focus on poorly classified cases during training. To test our model performance on real-world source code, we build a cross-language and multi-repository vulnerability dataset from Github Security Advisory Database. On this dataset, VuLASTE achieved top 50, top 100, top 200, top 500 hits of 29, 51, 86, 228, which are higher than state-of-art researches.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 05, 2023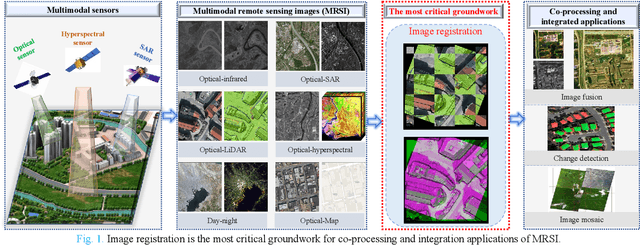
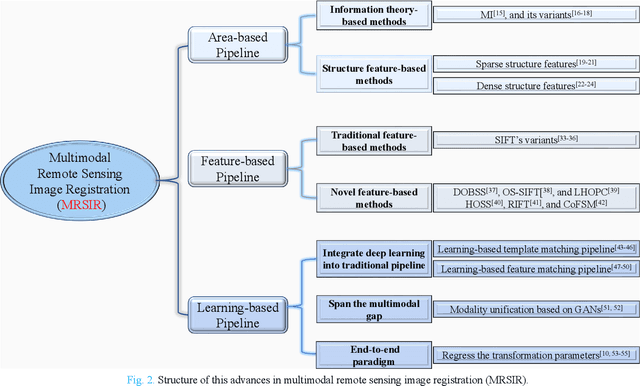
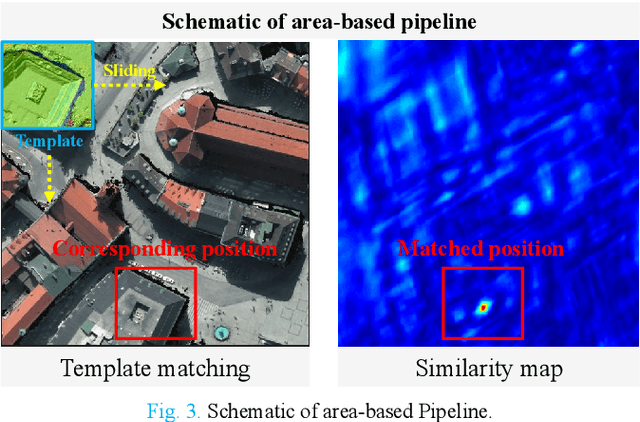

Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.
A Secure Dual-Function Radar Communication System via Time-Modulated Arrays
Feb 05, 2023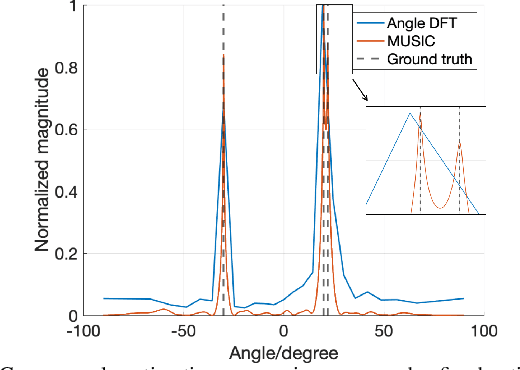
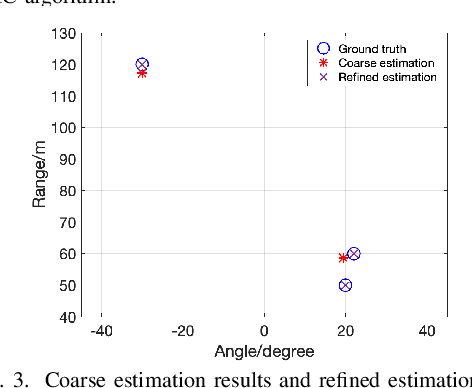
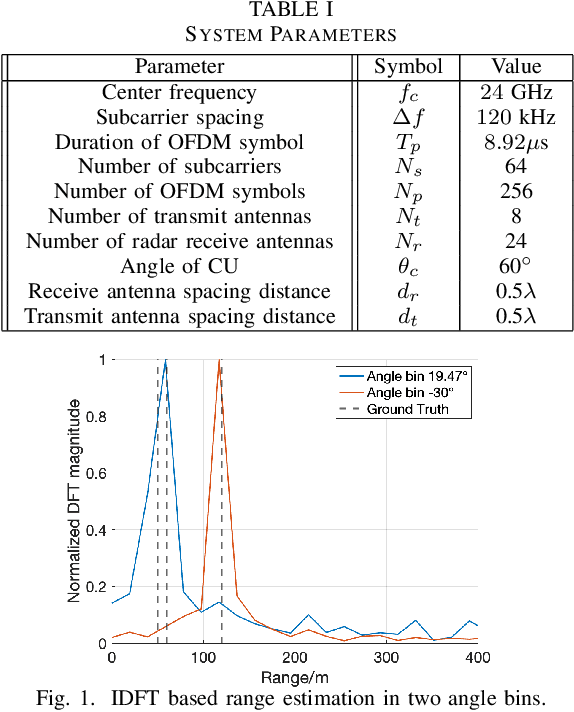
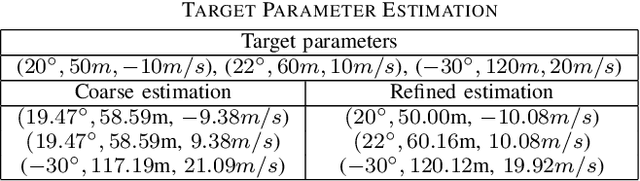
Dual-function radar-communication (DFRC) systems offer high spectral, hardware and power efficiency, as such are prime candidates for 6G wireless systems. DFRC systems use the same waveform for simultaneously probing the surroundings and communicating with other equipment. By exposing the communication information to potential targets, DFRC systems are vulnerable to eavesdropping. In this work, we propose to mitigate the problem by leveraging directional modulation (DM) enabled by a time-modulated array (TMA) that transmits OFDM waveforms. DM can scramble the signal in all directions except the directions of the legitimate user. However, the signal reflected by the targets is also scrambled, thus complicating the extraction of target parameters. We propose a novel, low-complexity target estimation method that estimates the target parameters based on the scrambled received symbols. We also propose a novel method to refine the obtained target estimates at the cost of increased complexity. With the proposed refinement algorithm, the proposed DFRC system can securely communicate with users while having high-precision sensing functionality.
Learning to Count Isomorphisms with Graph Neural Networks
Feb 15, 2023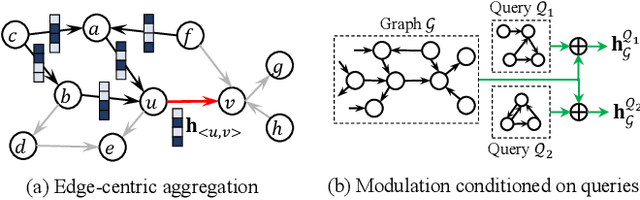
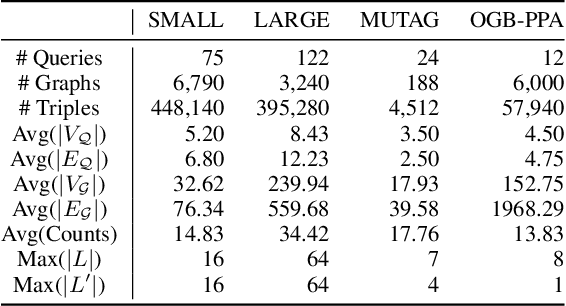
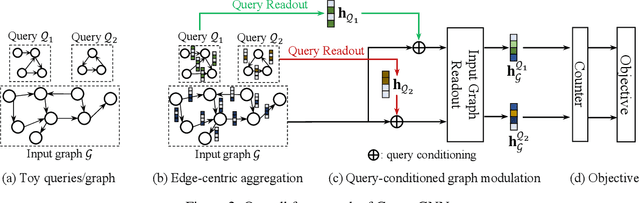
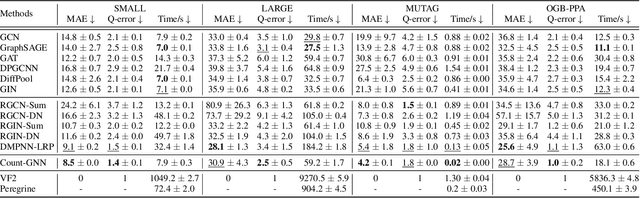
Subgraph isomorphism counting is an important problem on graphs, as many graph-based tasks exploit recurring subgraph patterns. Classical methods usually boil down to a backtracking framework that needs to navigate a huge search space with prohibitive computational costs. Some recent studies resort to graph neural networks (GNNs) to learn a low-dimensional representation for both the query and input graphs, in order to predict the number of subgraph isomorphisms on the input graph. However, typical GNNs employ a node-centric message passing scheme that receives and aggregates messages on nodes, which is inadequate in complex structure matching for isomorphism counting. Moreover, on an input graph, the space of possible query graphs is enormous, and different parts of the input graph will be triggered to match different queries. Thus, expecting a fixed representation of the input graph to match diversely structured query graphs is unrealistic. In this paper, we propose a novel GNN called Count-GNN for subgraph isomorphism counting, to deal with the above challenges. At the edge level, given that an edge is an atomic unit of encoding graph structures, we propose an edge-centric message passing scheme, where messages on edges are propagated and aggregated based on the edge adjacency to preserve fine-grained structural information. At the graph level, we modulate the input graph representation conditioned on the query, so that the input graph can be adapted to each query individually to improve their matching. Finally, we conduct extensive experiments on a number of benchmark datasets to demonstrate the superior performance of Count-GNN.
SynGraphy: Succinct Summarisation of Large Networks via Small Synthetic Representative Graphs
Feb 15, 2023
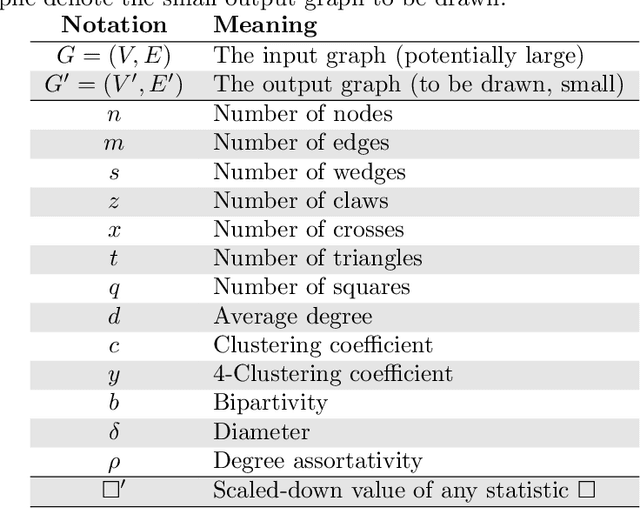
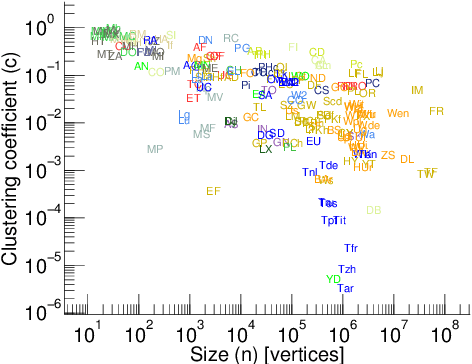
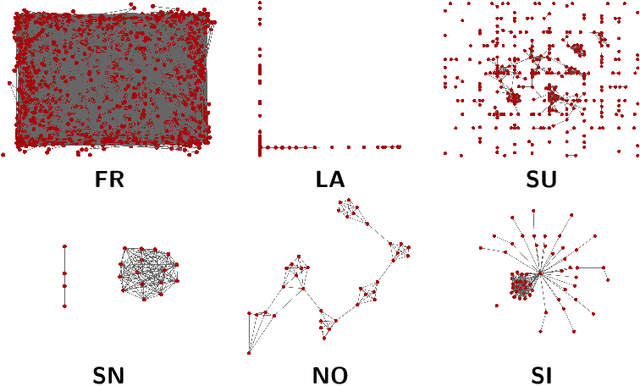
We describe SynGraphy, a method for visually summarising the structure of large network datasets that works by drawing smaller graphs generated to have similar structural properties to the input graphs. Visualising complex networks is crucial to understand and make sense of networked data and the relationships it represents. Due to the large size of many networks, visualisation is extremely difficult; the simple method of drawing large networks like those of Facebook or Twitter leads to graphics that convey little or no information. While modern graph layout algorithms can scale computationally to large networks, their output tends to a common "hairball" look, which makes it difficult to even distinguish different graphs from each other. Graph sampling and graph coarsening techniques partially address these limitations but they are only able to preserve a subset of the properties of the original graphs. In this paper we take the problem of visualising large graphs from a novel perspective: we leave the original graph's nodes and edges behind, and instead summarise its properties such as the clustering coefficient and bipartivity by generating a completely new graph whose structural properties match that of the original graph. To verify the utility of this approach as compared to other graph visualisation algorithms, we perform an experimental evaluation in which we repeatedly asked experimental subjects (professionals in graph mining and related areas) to determine which of two given graphs has a given structural property and then assess which visualisation algorithm helped in identifying the correct answer. Our summarisation approach SynGraphy compares favourably to other techniques on a variety of networks.
Deep Convolutional Neural Network for Plume Rise Measurements in Industrial Environments
Feb 15, 2023
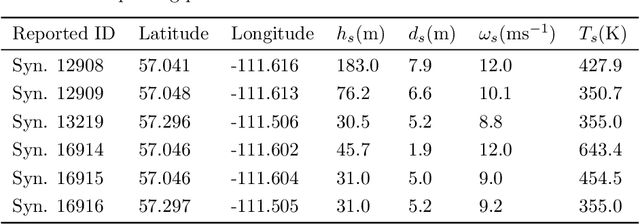
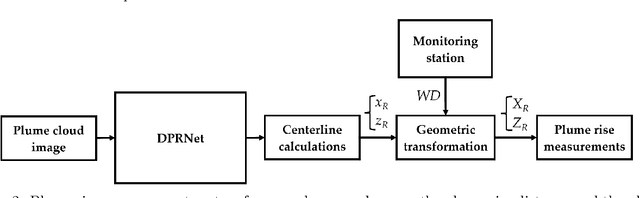
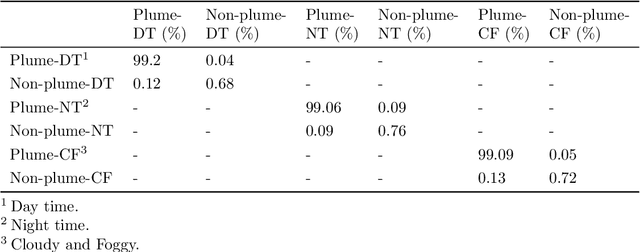
The estimation of plume cloud height is essential for air-quality transport models, local environmental assessment cases, and global climate models. When pollutants are released by a smokestack, plume rise is the constant height at which the plume cloud is carried downwind as its momentum dissipates and the temperatures of the plume cloud and the ambient equalize. Although different parameterizations and equations are used in most air quality models to predict plume rise, verification of these parameterizations has been limited in the past three decades. Beyond validation, there is also value in real-time measurement of plume rise to improve the accuracy of air quality forecasting. In this paper, we propose a low-cost measurement technology that can monitor smokestack plumes and make long-term, real-time measurements of plume rise, improving predictability. To do this, a two-stage method is developed based on deep convolutional neural networks. In the first stage, an improved Mask R-CNN is applied to detect the plume cloud borders and distinguish the plume from its background and other objects. This proposed model is called Deep Plume Rise Net (DPRNet). In the second stage, a geometric transformation phase is applied through the wind direction information from a nearby monitoring station to obtain real-life measurements of different parameters. Finally, the plume cloud boundaries are obtained to calculate the plume rise. Various images with different atmospheric conditions, including day, night, cloudy, and foggy, have been selected for DPRNet training algorithm. Obtained results show the proposed method outperforms widely-used networks in plume cloud border detection and recognition.
Effective and Interpretable Information Aggregation with Capacity Networks
Jul 25, 2022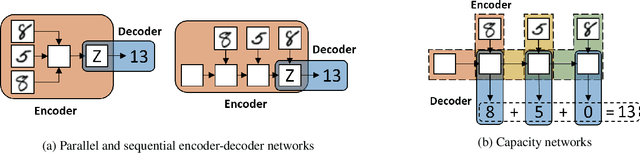
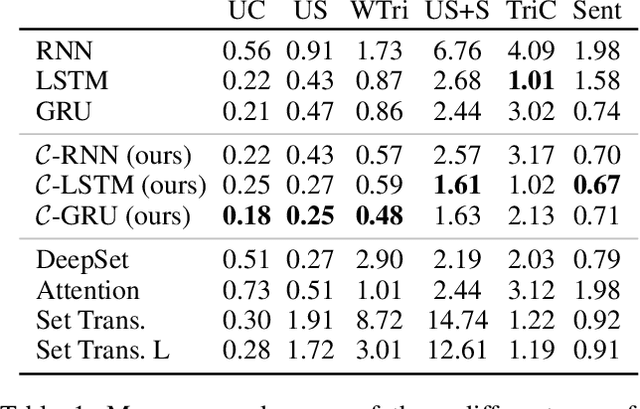
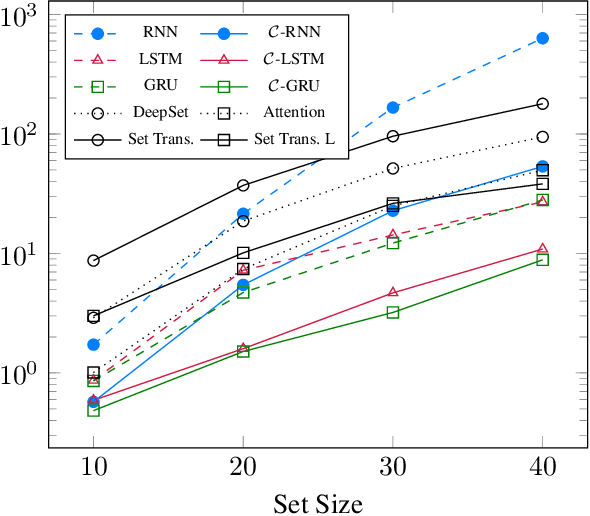
How to aggregate information from multiple instances is a key question multiple instance learning. Prior neural models implement different variants of the well-known encoder-decoder strategy according to which all input features are encoded a single, high-dimensional embedding which is then decoded to generate an output. In this work, inspired by Choquet capacities, we propose Capacity networks. Unlike encoder-decoders, Capacity networks generate multiple interpretable intermediate results which can be aggregated in a semantically meaningful space to obtain the final output. Our experiments show that implementing this simple inductive bias leads to improvements over different encoder-decoder architectures in a wide range of experiments. Moreover, the interpretable intermediate results make Capacity networks interpretable by design, which allows a semantically meaningful inspection, evaluation, and regularization of the network internals.