 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Training Full Spike Neural Networks via Auxiliary Accumulation Pathway
Jan 27, 2023
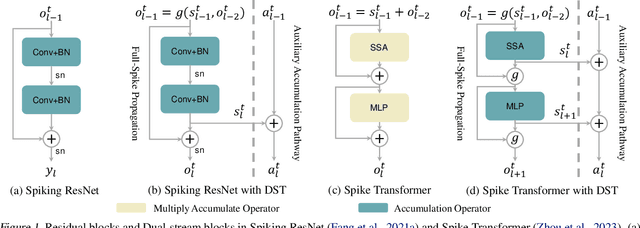

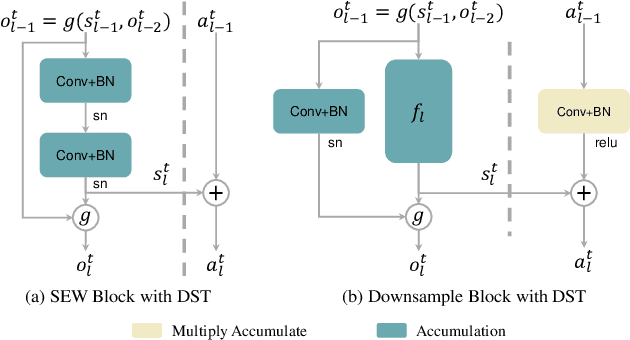
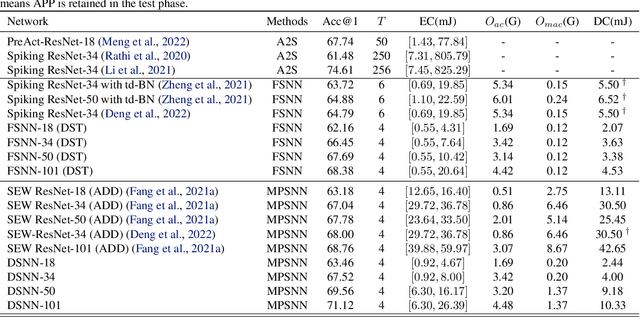
Due to the binary spike signals making converting the traditional high-power multiply-accumulation (MAC) into a low-power accumulation (AC) available, the brain-inspired Spiking Neural Networks (SNNs) are gaining more and more attention. However, the binary spike propagation of the Full-Spike Neural Networks (FSNN) with limited time steps is prone to significant information loss. To improve performance, several state-of-the-art SNN models trained from scratch inevitably bring many non-spike operations. The non-spike operations cause additional computational consumption and may not be deployed on some neuromorphic hardware where only spike operation is allowed. To train a large-scale FSNN with high performance, this paper proposes a novel Dual-Stream Training (DST) method which adds a detachable Auxiliary Accumulation Pathway (AAP) to the full spiking residual networks. The accumulation in AAP could compensate for the information loss during the forward and backward of full spike propagation, and facilitate the training of the FSNN. In the test phase, the AAP could be removed and only the FSNN remained. This not only keeps the lower energy consumption but also makes our model easy to deploy. Moreover, for some cases where the non-spike operations are available, the APP could also be retained in test inference and improve feature discrimination by introducing a little non-spike consumption. Extensive experiments on ImageNet, DVS Gesture, and CIFAR10-DVS datasets demonstrate the effectiveness of DST.
A Dataset of Coordinated Cryptocurrency-Related Social Media Campaigns
Jan 16, 2023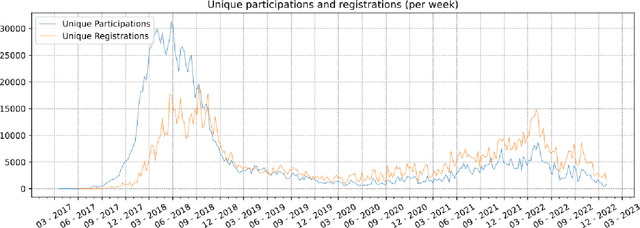
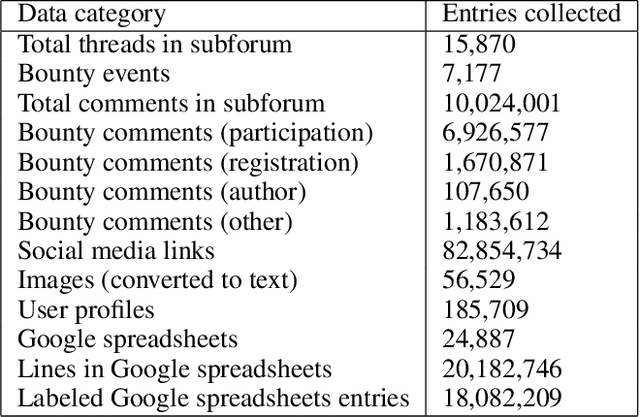
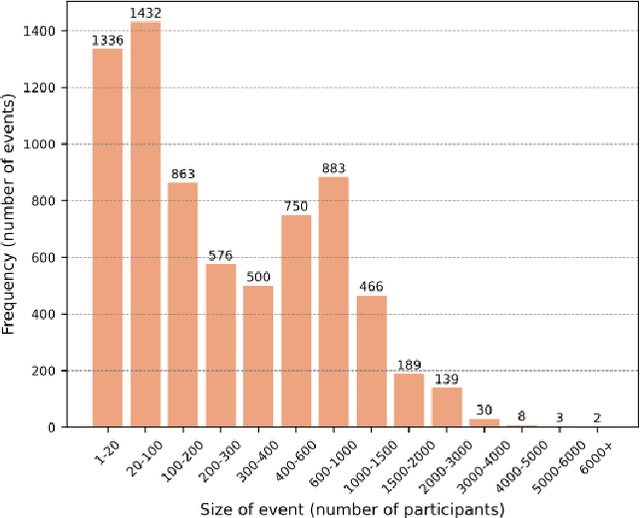
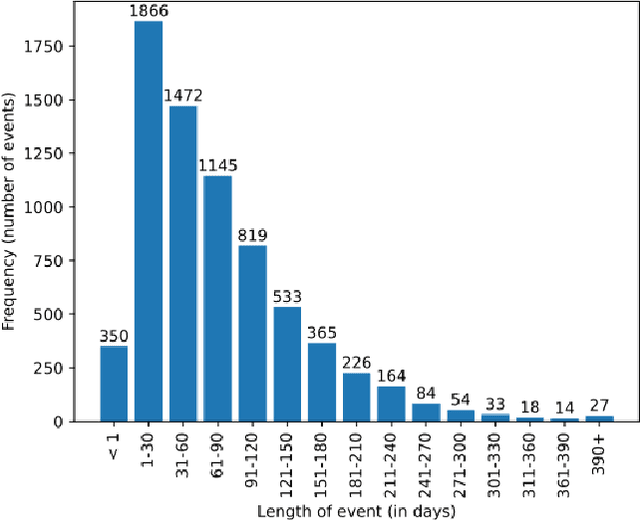
The rise in adoption of cryptoassets has brought many new and inexperienced investors in the cryptocurrency space. These investors can be disproportionally influenced by information they receive online, and particularly from social media. This paper presents a dataset of crypto-related bounty events and the users that participate in them. These events coordinate social media campaigns to create artificial "hype" around a crypto project in order to influence the price of its token. The dataset consists of information about 15.8K cross-media bounty events, 185K participants, 10M forum comments and 82M social media URLs collected from the Bounties(Altcoins) subforum of the BitcoinTalk online forum from May 2014 to December 2022. We describe the data collection and the data processing methods employed, we present a basic characterization of the dataset, and we describe potential research opportunities afforded by the dataset across many disciplines.
Teleoperated Robot Grasping in Virtual Reality Spaces
Jan 30, 2023

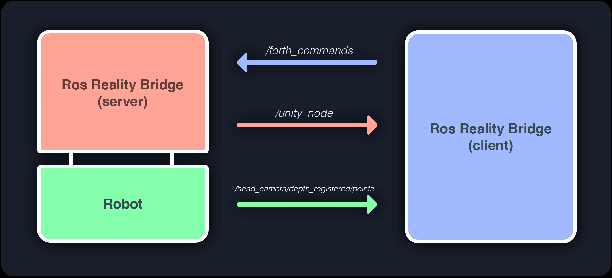
Despite recent advancement in virtual reality technology, teleoperating a high DoF robot to complete dexterous tasks in cluttered scenes remains difficult. In this work, we propose a system that allows the user to teleoperate a Fetch robot to perform grasping in an easy and intuitive way, through exploiting the rich environment information provided by the virtual reality space. Our system has the benefit of easy transferability to different robots and different tasks, and can be used without any expert knowledge. We tested the system on a real fetch robot, and a video demonstrating the effectiveness of our system can be seen at https://youtu.be/1-xW2Bx_Cms.
Operator Learning Framework for Digital Twin and Complex Engineering Systems
Jan 18, 2023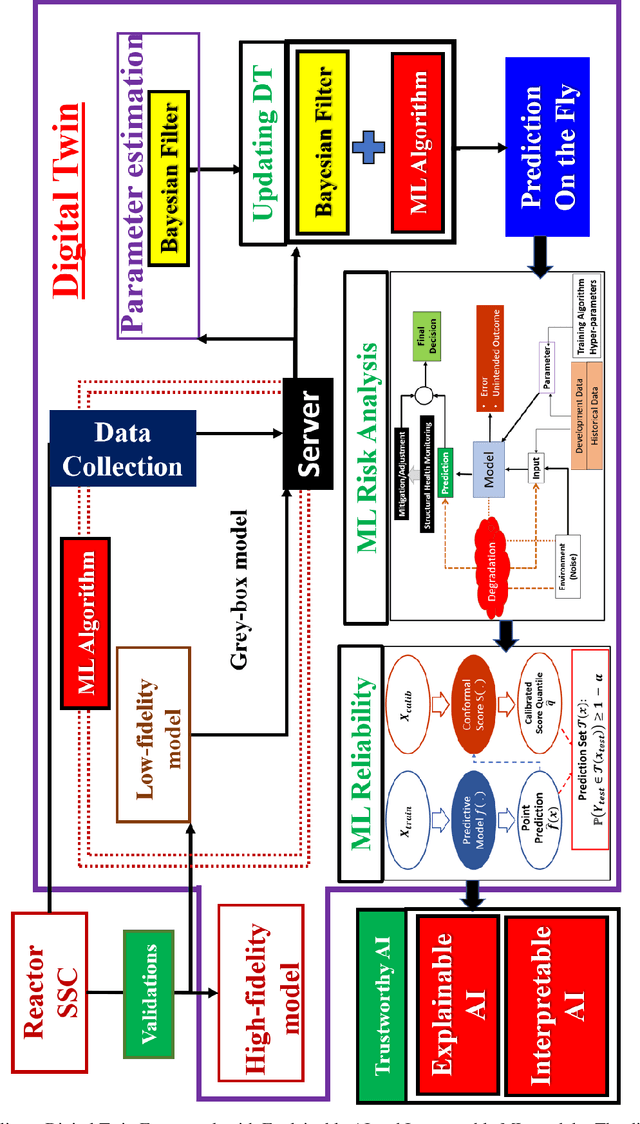
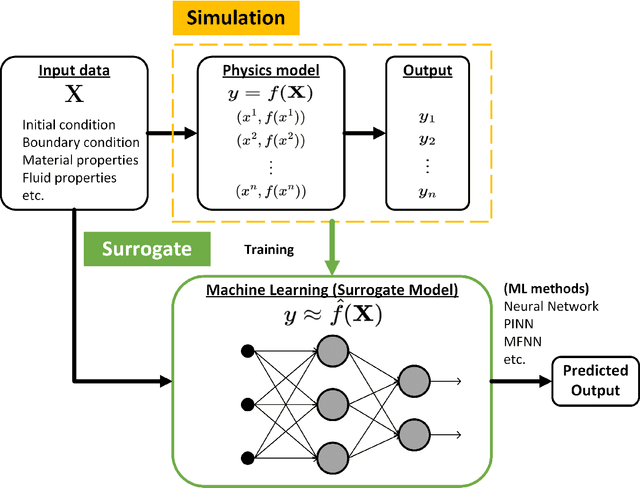
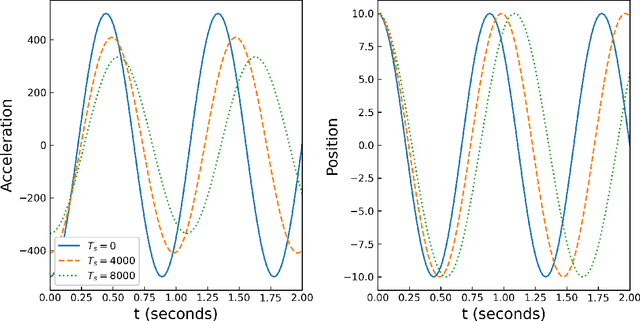
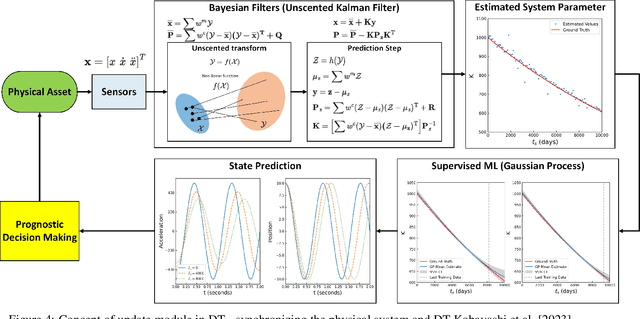
With modern computational advancements and statistical analysis methods, machine learning algorithms have become a vital part of engineering modeling. Neural Operator Networks (ONets) is an emerging machine learning algorithm as a "faster surrogate" for approximating solutions to partial differential equations (PDEs) due to their ability to approximate mathematical operators versus the direct approximation of Neural Networks (NN). ONets use the Universal Approximation Theorem to map finite-dimensional inputs to infinite-dimensional space using the branch-trunk architecture, which encodes domain and feature information separately before using a dot product to combine the information. ONets are expected to occupy a vital niche for surrogate modeling in physical systems and Digital Twin (DT) development. Three test cases are evaluated using ONets for operator approximation, including a 1-dimensional ordinary differential equations (ODE), general diffusion system, and convection-diffusion (Burger) system. Solutions for ODE and diffusion systems yield accurate and reliable results (R2>0.95), while solutions for Burger systems need further refinement in the ONet algorithm.
Monte Carlo Neural Operator for Learning PDEs via Probabilistic Representation
Feb 10, 2023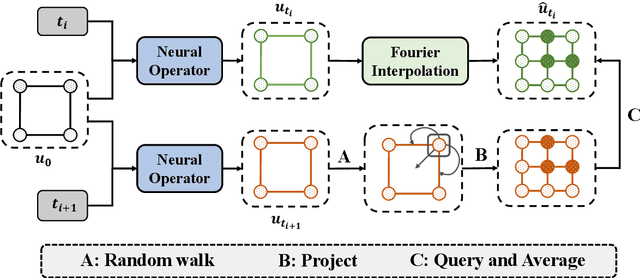
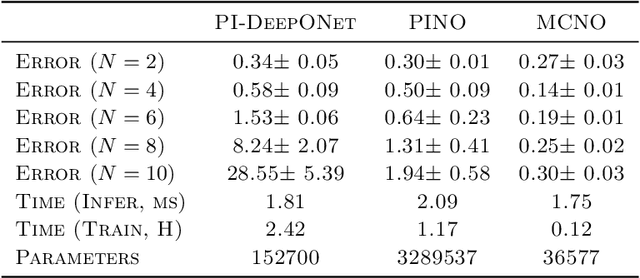
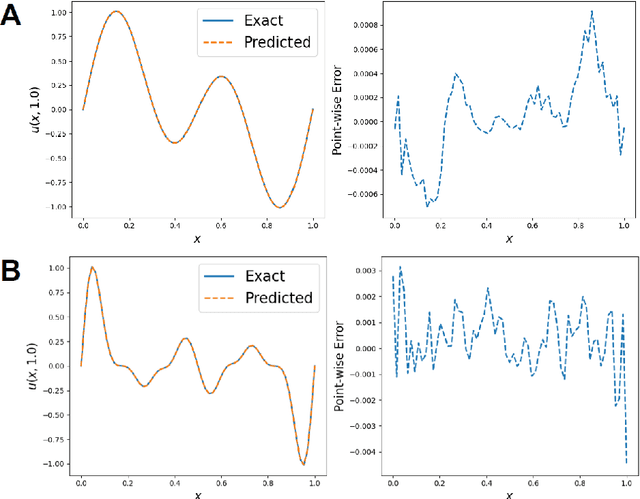
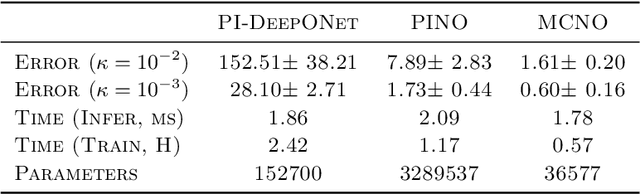
Neural operators, which use deep neural networks to approximate the solution mappings of partial differential equation (PDE) systems, are emerging as a new paradigm for PDE simulation. The neural operators could be trained in supervised or unsupervised ways, i.e., by using the generated data or the PDE information. The unsupervised training approach is essential when data generation is costly or the data is less qualified (e.g., insufficient and noisy). However, its performance and efficiency have plenty of room for improvement. To this end, we design a new loss function based on the Feynman-Kac formula and call the developed neural operator Monte-Carlo Neural Operator (MCNO), which can allow larger temporal steps and efficiently handle fractional diffusion operators. Our analyses show that MCNO has advantages in handling complex spatial conditions and larger temporal steps compared with other unsupervised methods. Furthermore, MCNO is more robust with the perturbation raised by the numerical scheme and operator approximation. Numerical experiments on the diffusion equation and Navier-Stokes equation show significant accuracy improvement compared with other unsupervised baselines, especially for the vibrated initial condition and long-time simulation settings.
Beyond In-Domain Scenarios: Robust Density-Aware Calibration
Feb 10, 2023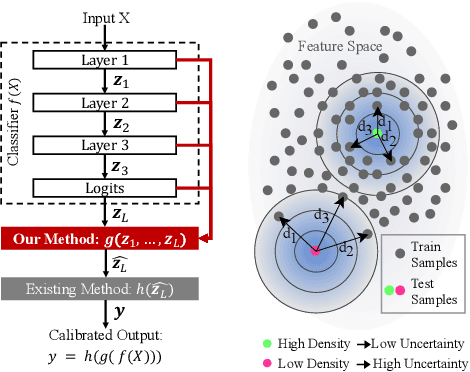
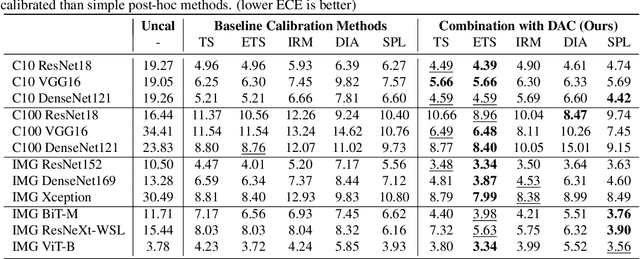
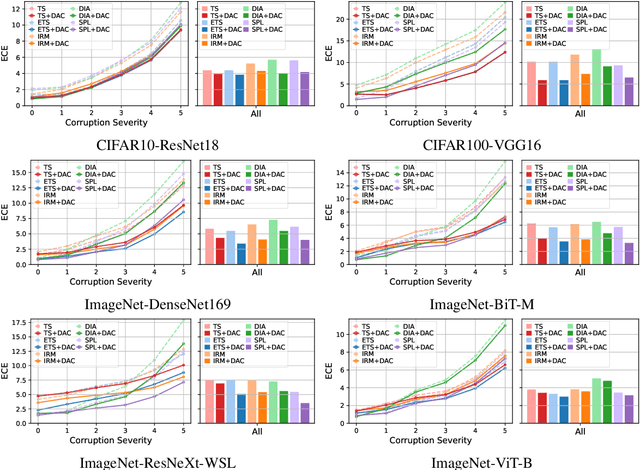
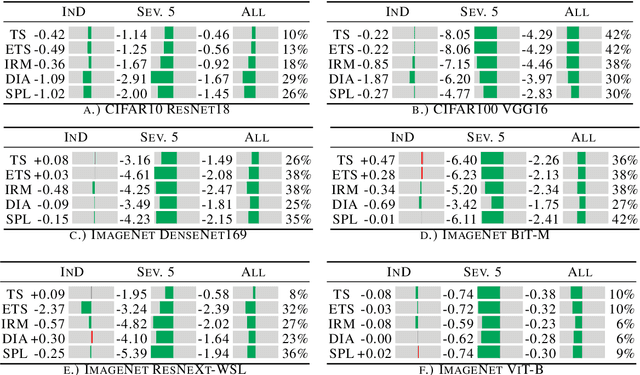
Calibrating deep learning models to yield uncertainty-aware predictions is crucial as deep neural networks get increasingly deployed in safety-critical applications. While existing post-hoc calibration methods achieve impressive results on in-domain test datasets, they are limited by their inability to yield reliable uncertainty estimates in domain-shift and out-of-domain (OOD) scenarios. We aim to bridge this gap by proposing DAC, an accuracy-preserving as well as Density-Aware Calibration method based on k-nearest-neighbors (KNN). In contrast to existing post-hoc methods, we utilize hidden layers of classifiers as a source for uncertainty-related information and study their importance. We show that DAC is a generic method that can readily be combined with state-of-the-art post-hoc methods. DAC boosts the robustness of calibration performance in domain-shift and OOD, while maintaining excellent in-domain predictive uncertainty estimates. We demonstrate that DAC leads to consistently better calibration across a large number of model architectures, datasets, and metrics. Additionally, we show that DAC improves calibration substantially on recent large-scale neural networks pre-trained on vast amounts of data.
ShapeWordNet: An Interpretable Shapelet Neural Network for Physiological Signal Classification
Feb 10, 2023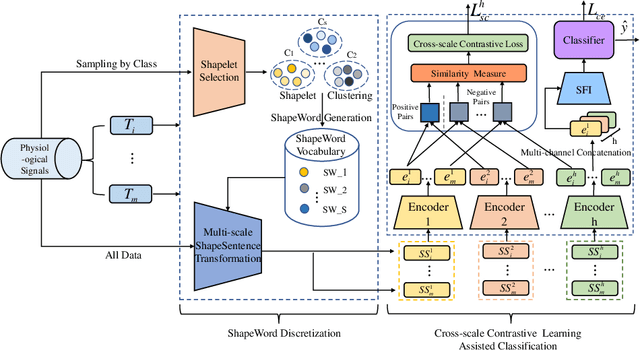
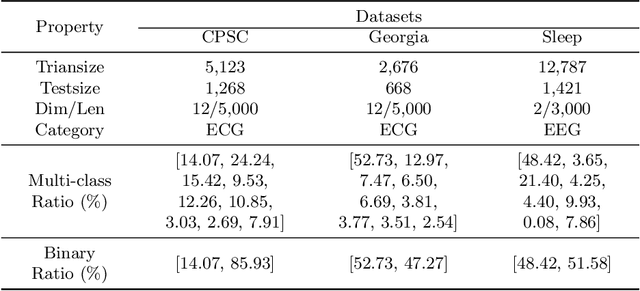
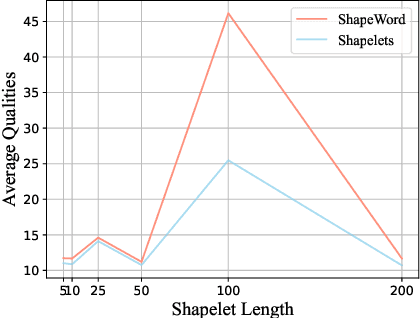
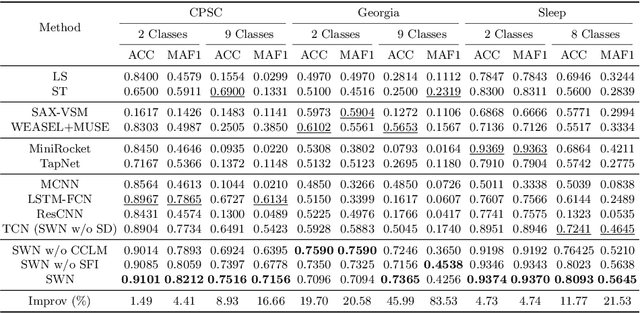
Physiological signals are high-dimensional time series of great practical values in medical and healthcare applications. However, previous works on its classification fail to obtain promising results due to the intractable data characteristics and the severe label sparsity issues. In this paper, we try to address these challenges by proposing a more effective and interpretable scheme tailored for the physiological signal classification task. Specifically, we exploit the time series shapelets to extract prominent local patterns and perform interpretable sequence discretization to distill the whole-series information. By doing so, the long and continuous raw signals are compressed into short and discrete token sequences, where both local patterns and global contexts are well preserved. Moreover, to alleviate the label sparsity issue, a multi-scale transformation strategy is adaptively designed to augment data and a cross-scale contrastive learning mechanism is accordingly devised to guide the model training. We name our method as ShapeWordNet and conduct extensive experiments on three real-world datasets to investigate its effectiveness. Comparative results show that our proposed scheme remarkably outperforms four categories of cutting-edge approaches. Visualization analysis further witnesses the good interpretability of the sequence discretization idea based on shapelets.
Confidence-based Reliable Learning under Dual Noises
Feb 10, 2023
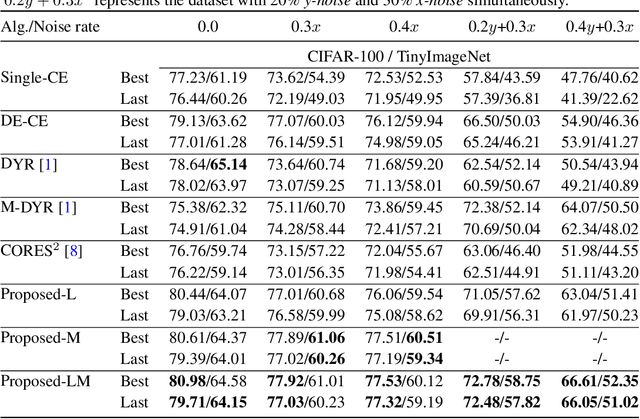
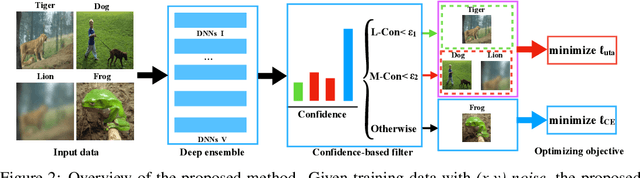

Deep neural networks (DNNs) have achieved remarkable success in a variety of computer vision tasks, where massive labeled images are routinely required for model optimization. Yet, the data collected from the open world are unavoidably polluted by noise, which may significantly undermine the efficacy of the learned models. Various attempts have been made to reliably train DNNs under data noise, but they separately account for either the noise existing in the labels or that existing in the images. A naive combination of the two lines of works would suffer from the limitations in both sides, and miss the opportunities to handle the two kinds of noise in parallel. This work provides a first, unified framework for reliable learning under the joint (image, label)-noise. Technically, we develop a confidence-based sample filter to progressively filter out noisy data without the need of pre-specifying noise ratio. Then, we penalize the model uncertainty of the detected noisy data instead of letting the model continue over-fitting the misleading information in them. Experimental results on various challenging synthetic and real-world noisy datasets verify that the proposed method can outperform competing baselines in the aspect of classification performance.
Robust Knowledge Transfer in Tiered Reinforcement Learning
Feb 10, 2023In this paper, we study the Tiered Reinforcement Learning setting, a parallel transfer learning framework, where the goal is to transfer knowledge from the low-tier (source) task to the high-tier (target) task to reduce the exploration risk of the latter while solving the two tasks in parallel. Unlike previous work, we do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on the task similarity. We identify a natural and necessary condition called the "Optimal Value Dominance" for our objective. Under this condition, we propose novel online learning algorithms such that, for the high-tier task, it can achieve constant regret on partial states depending on the task similarity and retain near-optimal regret when the two tasks are dissimilar, while for the low-tier task, it can keep near-optimal without making sacrifice. Moreover, we further study the setting with multiple low-tier tasks, and propose a novel transfer source selection mechanism, which can ensemble the information from all low-tier tasks and allow provable benefits on a much larger state-action space.
A survey on facial image deblurring
Feb 10, 2023
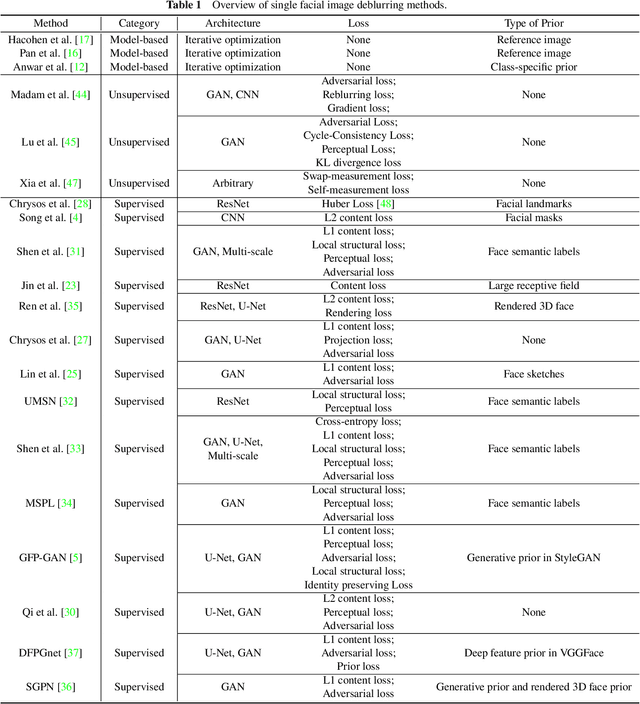
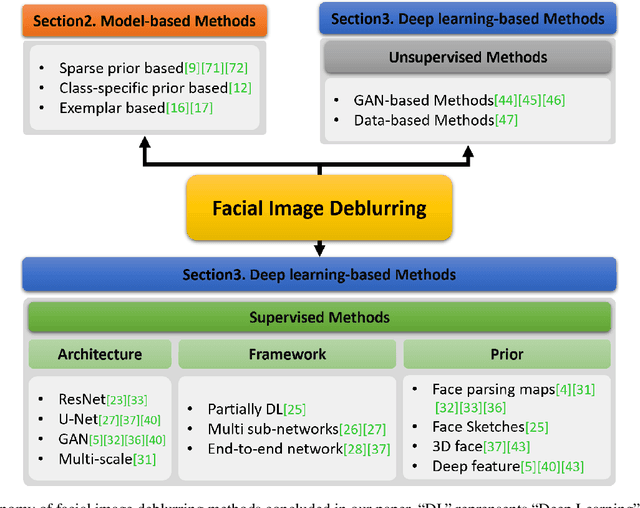
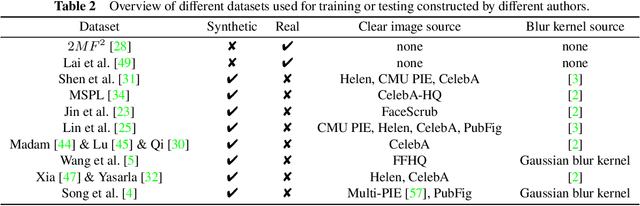
When the facial image is blurred, it has a great impact on high-level vision tasks such as face recognition. The purpose of facial image deblurring is to recover a clear image from a blurry input image, which can improve the recognition accuracy and so on. General deblurring methods can not perform well on facial images. So some face deblurring methods are proposed to improve the performance by adding semantic or structural information as specific priors according to the characteristics of facial images. This paper surveys and summarizes recently published methods for facial image deblurring, most of which are based on deep learning. Firstly, we give a brief introduction to the modeling of image blur. Next, we summarize face deblurring methods into two categories, namely model-based methods and deep learning-based methods. Furthermore, we summarize the datasets, loss functions, and performance evaluation metrics commonly used in the neural network training process. We show the performance of classical methods on these datasets and metrics and give a brief discussion on the differences of model-based and learning-based methods. Finally, we discuss current challenges and possible future research directions.