 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Does Search Engine Optimization come along with high-quality content? A comparison between optimized and non-optimized health-related web pages
Jan 24, 2023
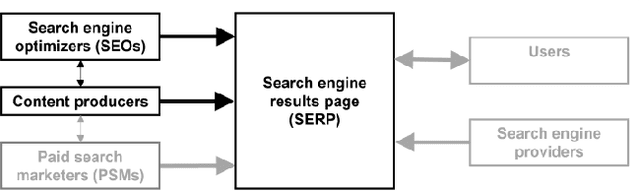

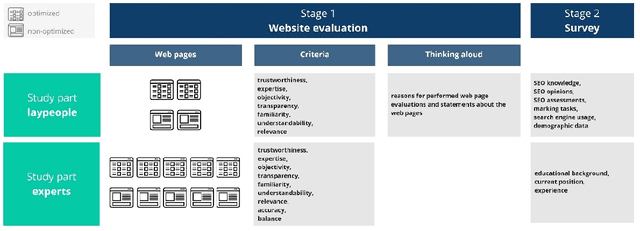
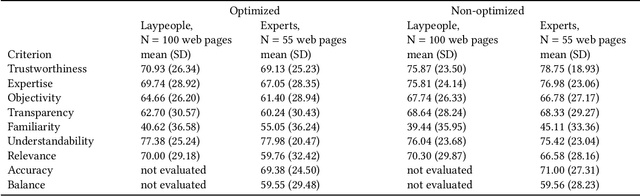
Searching for medical information is both a common and important activity since it influences decisions people make about their healthcare. Using search engine optimization (SEO), content producers seek to increase the visibility of their content. SEO is more likely to be practiced by commercially motivated content producers such as pharmaceutical companies than by non-commercial providers such as governmental bodies. In this study, we ask whether content quality correlates with the presence or absence of SEO measures on a web page. We conducted a user study in which N = 61 participants comprising laypeople as well as experts in health information assessment evaluated health-related web pages classified as either optimized or non-optimized. The subjects rated the expertise of non-optimized web pages as higher than the expertise of optimized pages, justifying their appraisal by the more competent and reputable appearance of non-optimized pages. In addition, comments about the website operators of the non-optimized pages were exclusively positive, while optimized pages tended to receive positive as well as negative assessments. We found no differences between the ratings of laypeople and experts. Since non-optimized, but high-quality content may be outranked by optimized content of lower quality, trusted sources should be prioritized in rankings.
Deep Correlation-Aware Kernelized Autoencoders for Anomaly Detection in Cybersecurity
Jan 01, 2023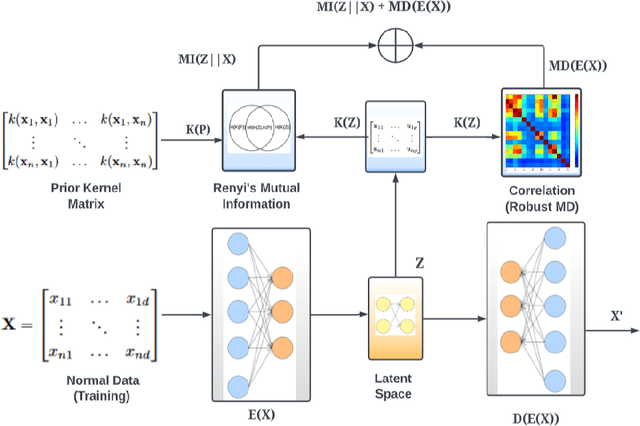

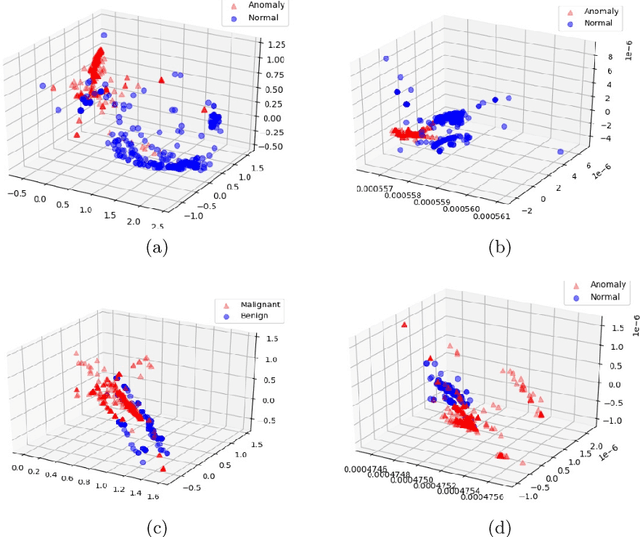
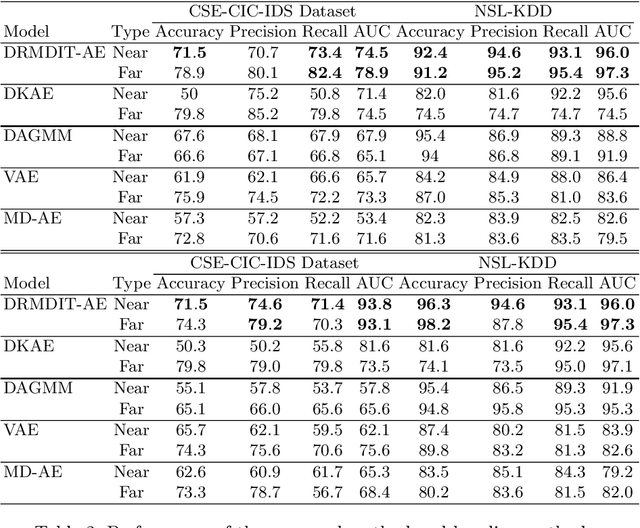
Unsupervised learning-based anomaly detection in latent space has gained importance since discriminating anomalies from normal data becomes difficult in high-dimensional space. Both density estimation and distance-based methods to detect anomalies in latent space have been explored in the past. These methods prove that retaining valuable properties of input data in latent space helps in the better reconstruction of test data. Moreover, real-world sensor data is skewed and non-Gaussian in nature, making mean-based estimators unreliable for skewed data. Again, anomaly detection methods based on reconstruction error rely on Euclidean distance, which does not consider useful correlation information in the feature space and also fails to accurately reconstruct the data when it deviates from the training distribution. In this work, we address the limitations of reconstruction error-based autoencoders and propose a kernelized autoencoder that leverages a robust form of Mahalanobis distance (MD) to measure latent dimension correlation to effectively detect both near and far anomalies. This hybrid loss is aided by the principle of maximizing the mutual information gain between the latent dimension and the high-dimensional prior data space by maximizing the entropy of the latent space while preserving useful correlation information of the original data in the low-dimensional latent space. The multi-objective function has two goals -- it measures correlation information in the latent feature space in the form of robust MD distance and simultaneously tries to preserve useful correlation information from the original data space in the latent space by maximizing mutual information between the prior and latent space.
Multi-Frequency Information Enhanced Channel Attention Module for Speaker Representation Learning
Jul 10, 2022

Recently, attention mechanisms have been applied successfully in neural network-based speaker verification systems. Incorporating the Squeeze-and-Excitation block into convolutional neural networks has achieved remarkable performance. However, it uses global average pooling (GAP) to simply average the features along time and frequency dimensions, which is incapable of preserving sufficient speaker information in the feature maps. In this study, we show that GAP is a special case of a discrete cosine transform (DCT) on time-frequency domain mathematically using only the lowest frequency component in frequency decomposition. To strengthen the speaker information extraction ability, we propose to utilize multi-frequency information and design two novel and effective attention modules, called Single-Frequency Single-Channel (SFSC) attention module and Multi-Frequency Single-Channel (MFSC) attention module. The proposed attention modules can effectively capture more speaker information from multiple frequency components on the basis of DCT. We conduct comprehensive experiments on the VoxCeleb datasets and a probe evaluation on the 1st 48-UTD forensic corpus. Experimental results demonstrate that our proposed SFSC and MFSC attention modules can efficiently generate more discriminative speaker representations and outperform ResNet34-SE and ECAPA-TDNN systems with relative 20.9% and 20.2% reduction in EER, without adding extra network parameters.
Randomized prior wavelet neural operator for uncertainty quantification
Feb 02, 2023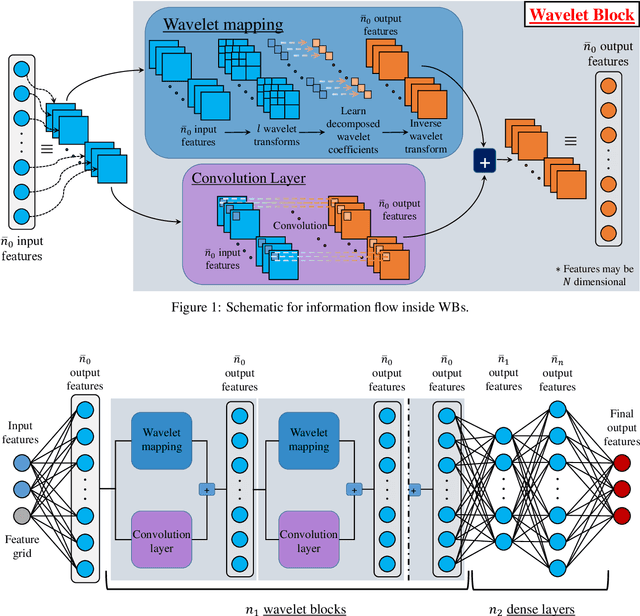


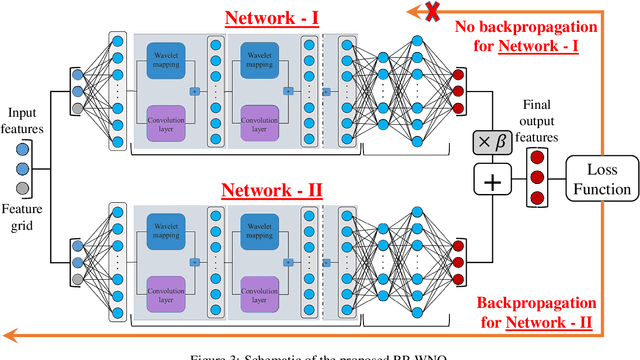
In this paper, we propose a novel data-driven operator learning framework referred to as the \textit{Randomized Prior Wavelet Neural Operator} (RP-WNO). The proposed RP-WNO is an extension of the recently proposed wavelet neural operator, which boasts excellent generalizing capabilities but cannot estimate the uncertainty associated with its predictions. RP-WNO, unlike the vanilla WNO, comes with inherent uncertainty quantification module and hence, is expected to be extremely useful for scientists and engineers alike. RP-WNO utilizes randomized prior networks, which can account for prior information and is easier to implement for large, complex deep-learning architectures than its Bayesian counterpart. Four examples have been solved to test the proposed framework, and the results produced advocate favorably for the efficacy of the proposed framework.
Improving Generalization of Adapter-Based Cross-lingual Transfer with Scheduled Unfreezing
Jan 13, 2023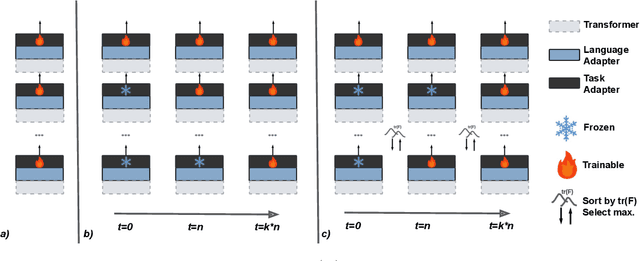
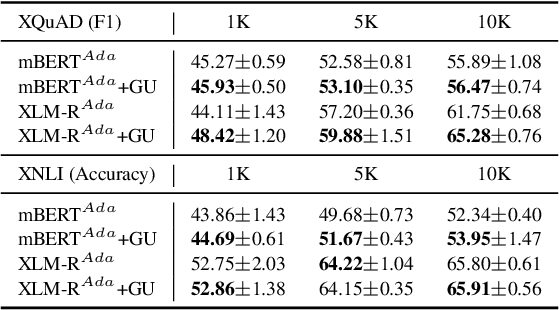
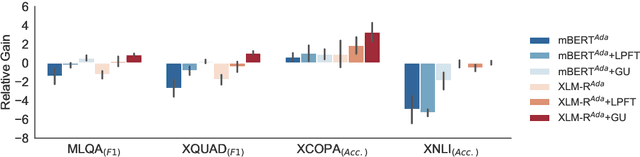
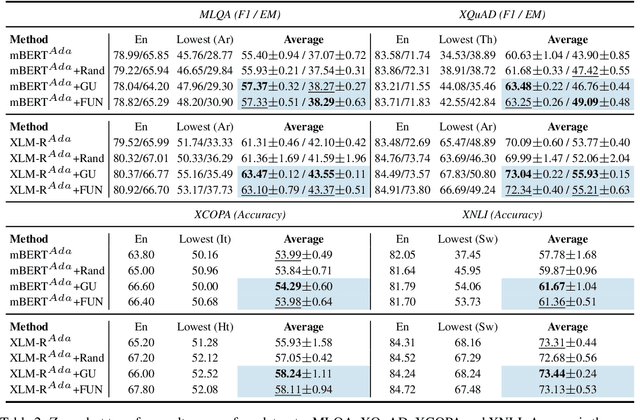
Standard fine-tuning of language models typically performs well on in-distribution data, but suffers with generalization to distribution shifts. In this work, we aim to improve generalization of adapter-based cross-lingual task transfer where such cross-language distribution shifts are imminent. We investigate scheduled unfreezing algorithms -- originally proposed to mitigate catastrophic forgetting in transfer learning -- for fine-tuning task adapters in cross-lingual transfer. Our experiments show that scheduled unfreezing methods close the gap to full fine-tuning and achieve state-of-the-art transfer performance, suggesting that these methods can go beyond just mitigating catastrophic forgetting. Next, aiming to delve deeper into those empirical findings, we investigate the learning dynamics of scheduled unfreezing using Fisher Information. Our in-depth experiments reveal that scheduled unfreezing induces different learning dynamics compared to standard fine-tuning, and provide evidence that the dynamics of Fisher Information during training correlate with cross-lingual generalization performance. We additionally propose a general scheduled unfreezing algorithm that achieves an average of 2 points improvement over four datasets compared to standard fine-tuning and provides strong empirical evidence for a theory-based justification of the heuristic unfreezing schedule (i.e., the heuristic schedule is implicitly maximizing Fisher Information). Our code will be publicly available.
A Dataset of Coordinated Cryptocurrency-Related Social Media Campaigns
Jan 16, 2023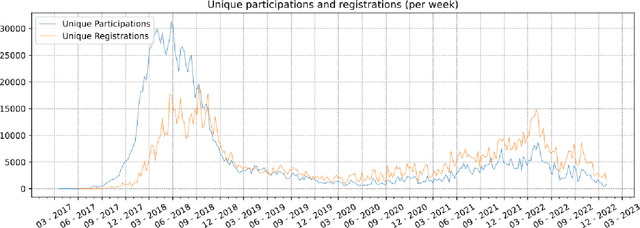
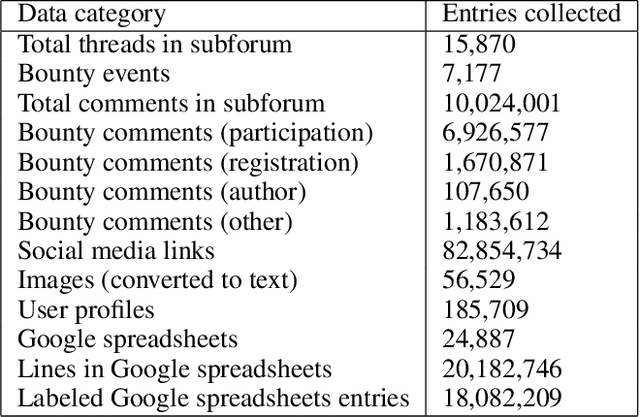
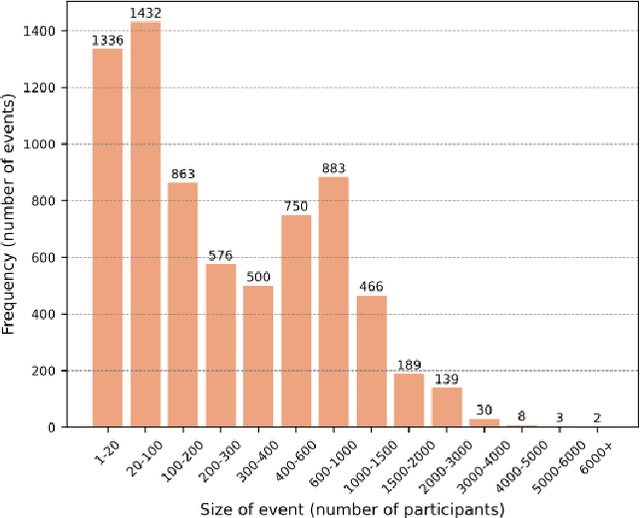
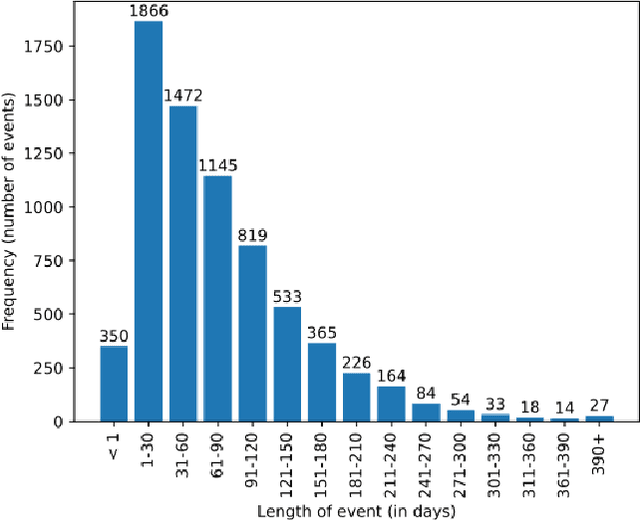
The rise in adoption of cryptoassets has brought many new and inexperienced investors in the cryptocurrency space. These investors can be disproportionally influenced by information they receive online, and particularly from social media. This paper presents a dataset of crypto-related bounty events and the users that participate in them. These events coordinate social media campaigns to create artificial "hype" around a crypto project in order to influence the price of its token. The dataset consists of information about 15.8K cross-media bounty events, 185K participants, 10M forum comments and 82M social media URLs collected from the Bounties(Altcoins) subforum of the BitcoinTalk online forum from May 2014 to December 2022. We describe the data collection and the data processing methods employed, we present a basic characterization of the dataset, and we describe potential research opportunities afforded by the dataset across many disciplines.
A Correct-and-Certify Approach to Self-Supervise Object Pose Estimators via Ensemble Self-Training
Feb 12, 2023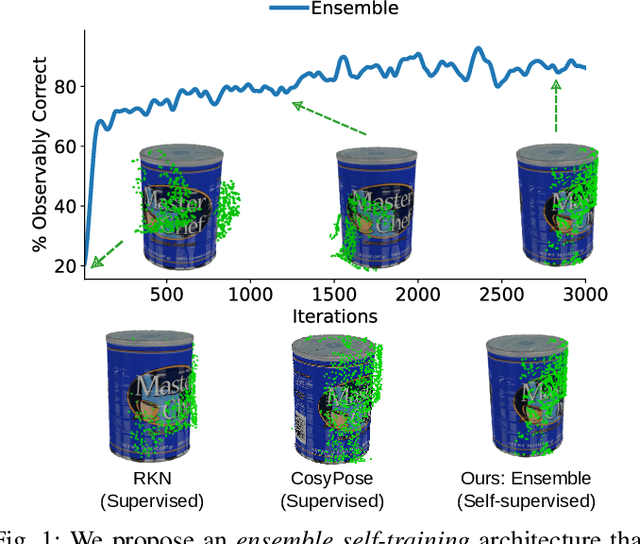
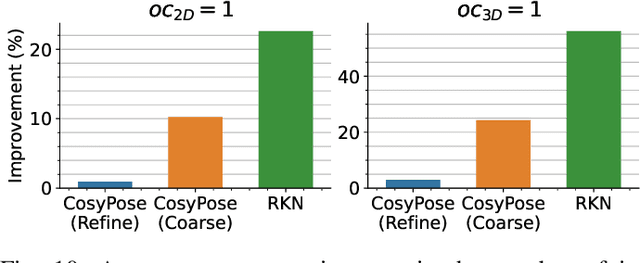
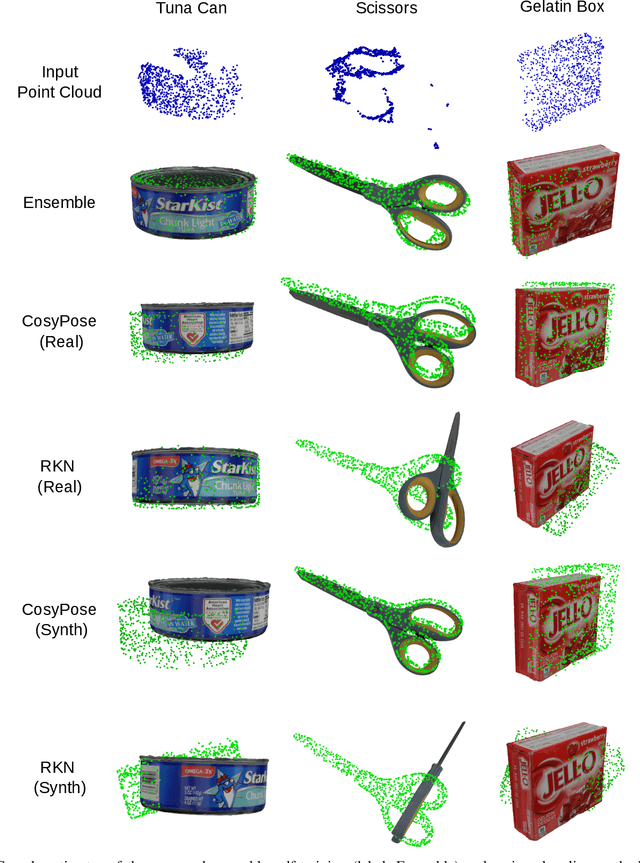

Real-world robotics applications demand object pose estimation methods that work reliably across a variety of scenarios. Modern learning-based approaches require large labeled datasets and tend to perform poorly outside the training domain. Our first contribution is to develop a robust corrector module that corrects pose estimates using depth information, thus enabling existing methods to better generalize to new test domains; the corrector operates on semantic keypoints (but is also applicable to other pose estimators) and is fully differentiable. Our second contribution is an ensemble self-training approach that simultaneously trains multiple pose estimators in a self-supervised manner. Our ensemble self-training architecture uses the robust corrector to refine the output of each pose estimator; then, it evaluates the quality of the outputs using observable correctness certificates; finally, it uses the observably correct outputs for further training, without requiring external supervision. As an additional contribution, we propose small improvements to a regression-based keypoint detection architecture, to enhance its robustness to outliers; these improvements include a robust pooling scheme and a robust centroid computation. Experiments on the YCBV and TLESS datasets show the proposed ensemble self-training outperforms fully supervised baselines while not requiring 3D annotations on real data.
Training Full Spike Neural Networks via Auxiliary Accumulation Pathway
Jan 27, 2023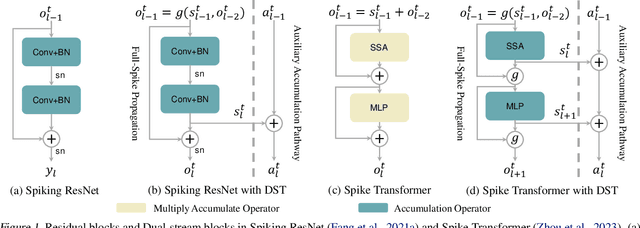

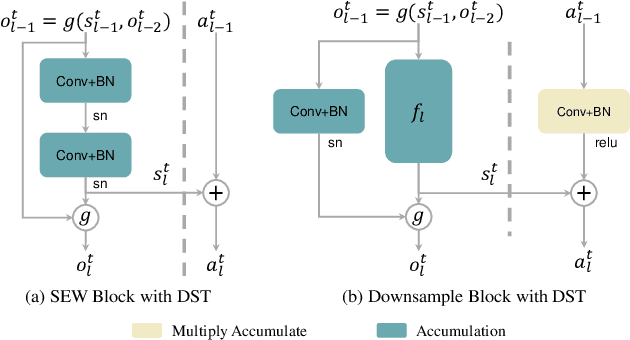
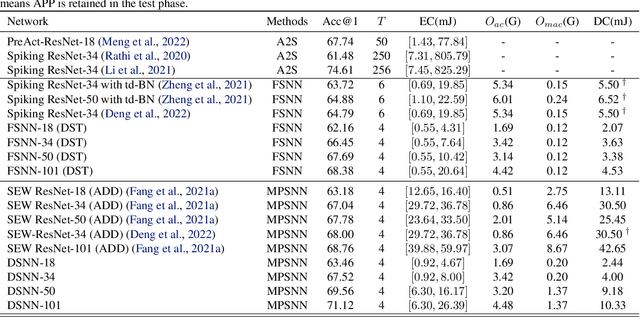
Due to the binary spike signals making converting the traditional high-power multiply-accumulation (MAC) into a low-power accumulation (AC) available, the brain-inspired Spiking Neural Networks (SNNs) are gaining more and more attention. However, the binary spike propagation of the Full-Spike Neural Networks (FSNN) with limited time steps is prone to significant information loss. To improve performance, several state-of-the-art SNN models trained from scratch inevitably bring many non-spike operations. The non-spike operations cause additional computational consumption and may not be deployed on some neuromorphic hardware where only spike operation is allowed. To train a large-scale FSNN with high performance, this paper proposes a novel Dual-Stream Training (DST) method which adds a detachable Auxiliary Accumulation Pathway (AAP) to the full spiking residual networks. The accumulation in AAP could compensate for the information loss during the forward and backward of full spike propagation, and facilitate the training of the FSNN. In the test phase, the AAP could be removed and only the FSNN remained. This not only keeps the lower energy consumption but also makes our model easy to deploy. Moreover, for some cases where the non-spike operations are available, the APP could also be retained in test inference and improve feature discrimination by introducing a little non-spike consumption. Extensive experiments on ImageNet, DVS Gesture, and CIFAR10-DVS datasets demonstrate the effectiveness of DST.
Learning in POMDPs is Sample-Efficient with Hindsight Observability
Feb 03, 2023
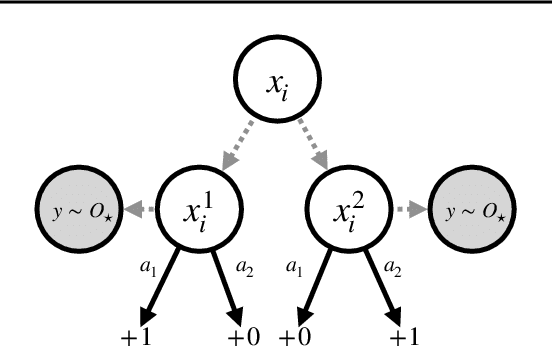
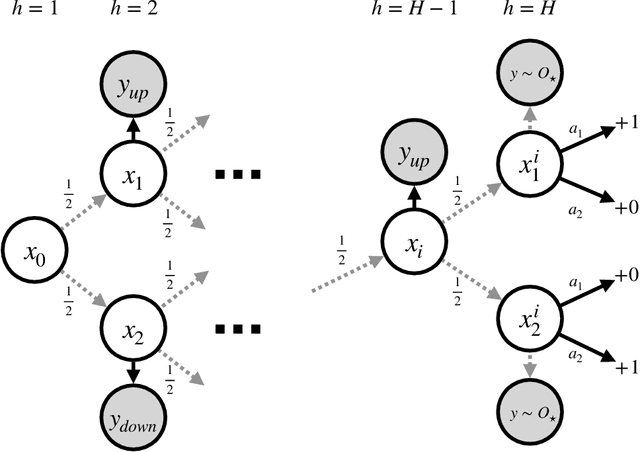
POMDPs capture a broad class of decision making problems, but hardness results suggest that learning is intractable even in simple settings due to the inherent partial observability. However, in many realistic problems, more information is either revealed or can be computed during some point of the learning process. Motivated by diverse applications ranging from robotics to data center scheduling, we formulate a Hindsight Observable Markov Decision Process (HOMDP) as a POMDP where the latent states are revealed to the learner in hindsight and only during training. We introduce new algorithms for the tabular and function approximation settings that are provably sample-efficient with hindsight observability, even in POMDPs that would otherwise be statistically intractable. We give a lower bound showing that the tabular algorithm is optimal in its dependence on latent state and observation cardinalities.
Operator Learning Framework for Digital Twin and Complex Engineering Systems
Jan 18, 2023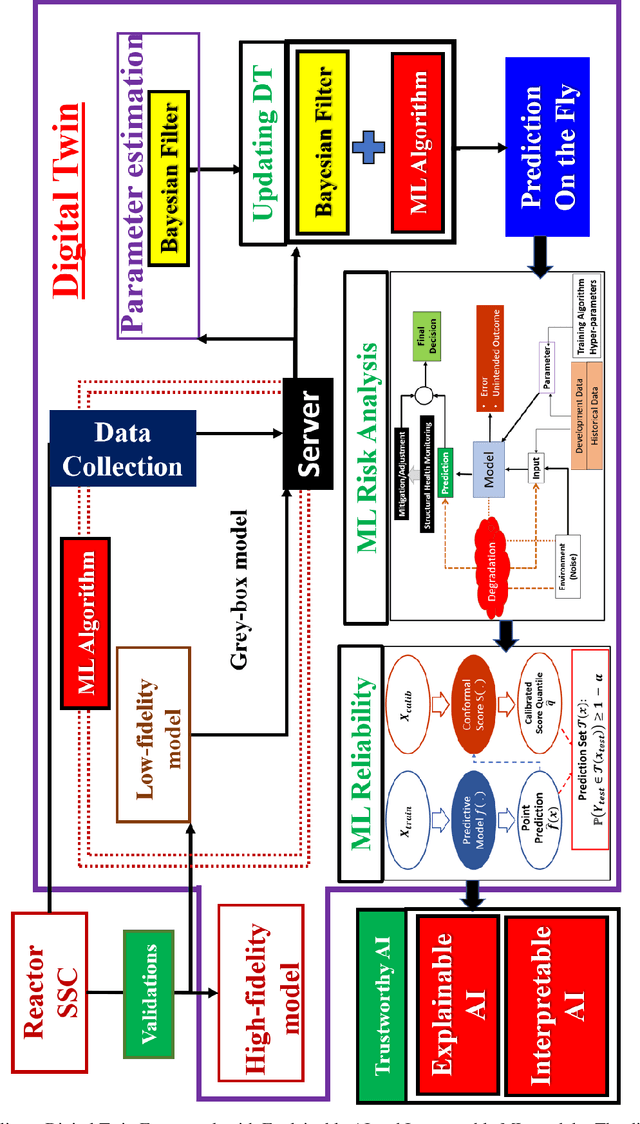
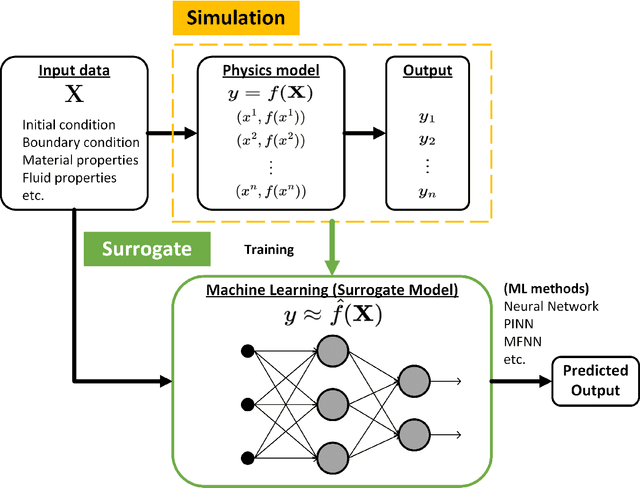
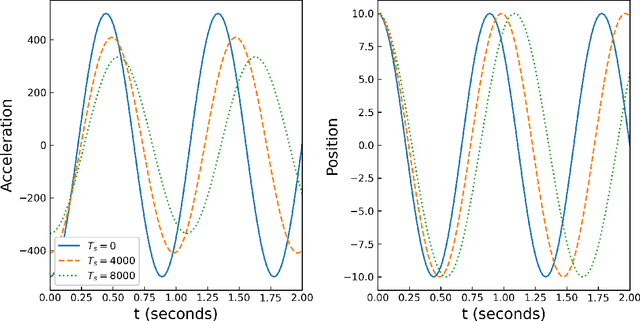
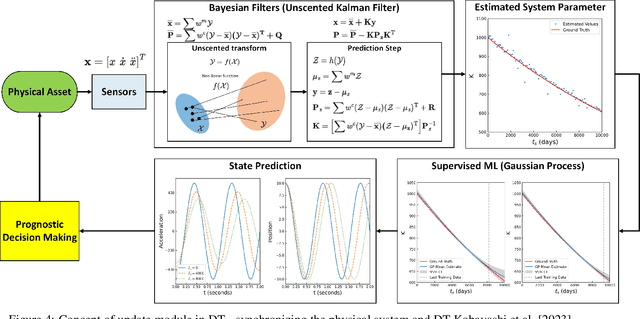
With modern computational advancements and statistical analysis methods, machine learning algorithms have become a vital part of engineering modeling. Neural Operator Networks (ONets) is an emerging machine learning algorithm as a "faster surrogate" for approximating solutions to partial differential equations (PDEs) due to their ability to approximate mathematical operators versus the direct approximation of Neural Networks (NN). ONets use the Universal Approximation Theorem to map finite-dimensional inputs to infinite-dimensional space using the branch-trunk architecture, which encodes domain and feature information separately before using a dot product to combine the information. ONets are expected to occupy a vital niche for surrogate modeling in physical systems and Digital Twin (DT) development. Three test cases are evaluated using ONets for operator approximation, including a 1-dimensional ordinary differential equations (ODE), general diffusion system, and convection-diffusion (Burger) system. Solutions for ODE and diffusion systems yield accurate and reliable results (R2>0.95), while solutions for Burger systems need further refinement in the ONet algorithm.