 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diversity matters: Robustness of bias measurements in Wikidata
Feb 27, 2023
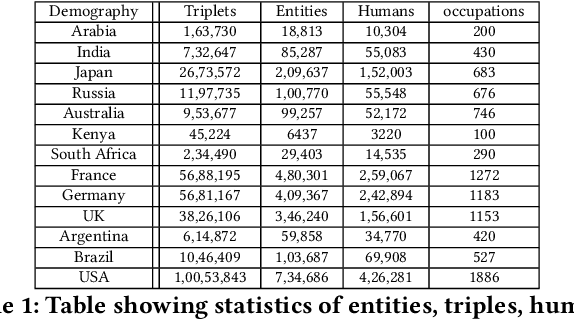


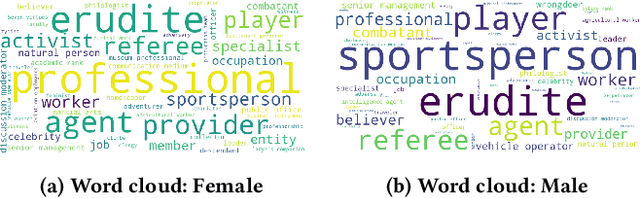
With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
* 11 pages
An atrium segmentation network with location guidance and siamese adjustment
Jan 11, 2023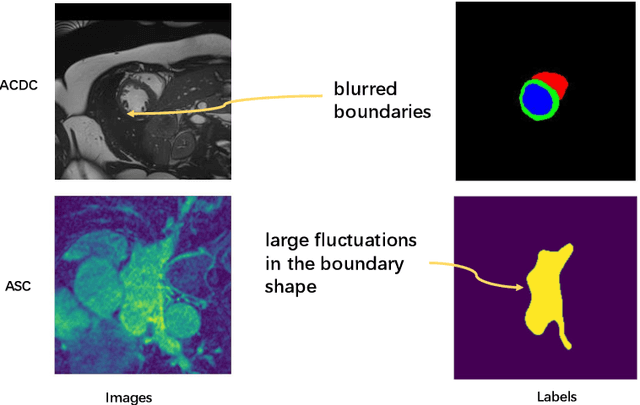
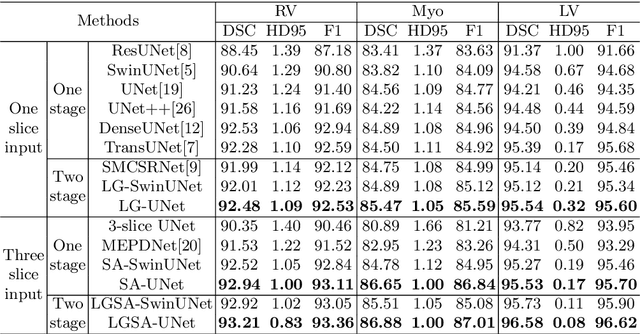
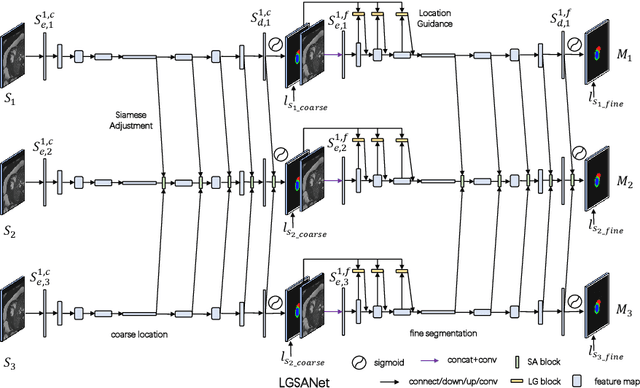
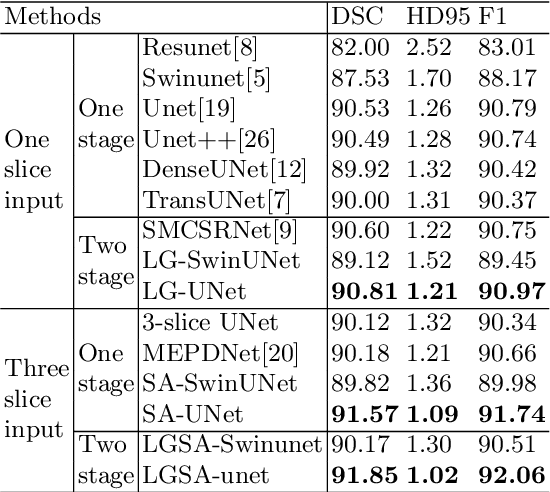
The segmentation of atrial scan images is of great significance for the three-dimensional reconstruction of the atrium and the surgical positioning. Most of the existing segmentation networks adopt a 2D structure and only take original images as input, ignoring the context information of 3D images and the role of prior information. In this paper, we propose an atrium segmentation network LGSANet with location guidance and siamese adjustment, which takes adjacent three slices of images as input and adopts an end-to-end approach to achieve coarse-to-fine atrial segmentation. The location guidance(LG) block uses the prior information of the localization map to guide the encoding features of the fine segmentation stage, and the siamese adjustment(SA) block uses the context information to adjust the segmentation edges. On the atrium datasets of ACDC and ASC, sufficient experiments prove that our method can adapt to many classic 2D segmentation networks, so that it can obtain significant performance improvements.
Semi-decentralized Inference in Heterogeneous Graph Neural Networks for Traffic Demand Forecasting: An Edge-Computing Approach
Feb 28, 2023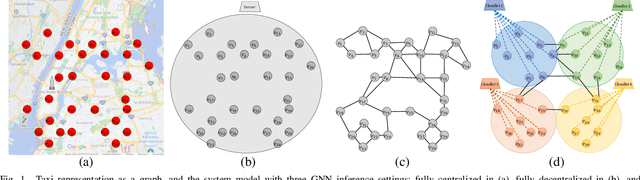
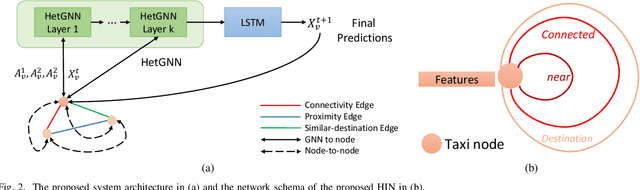
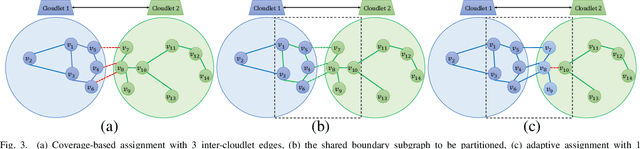
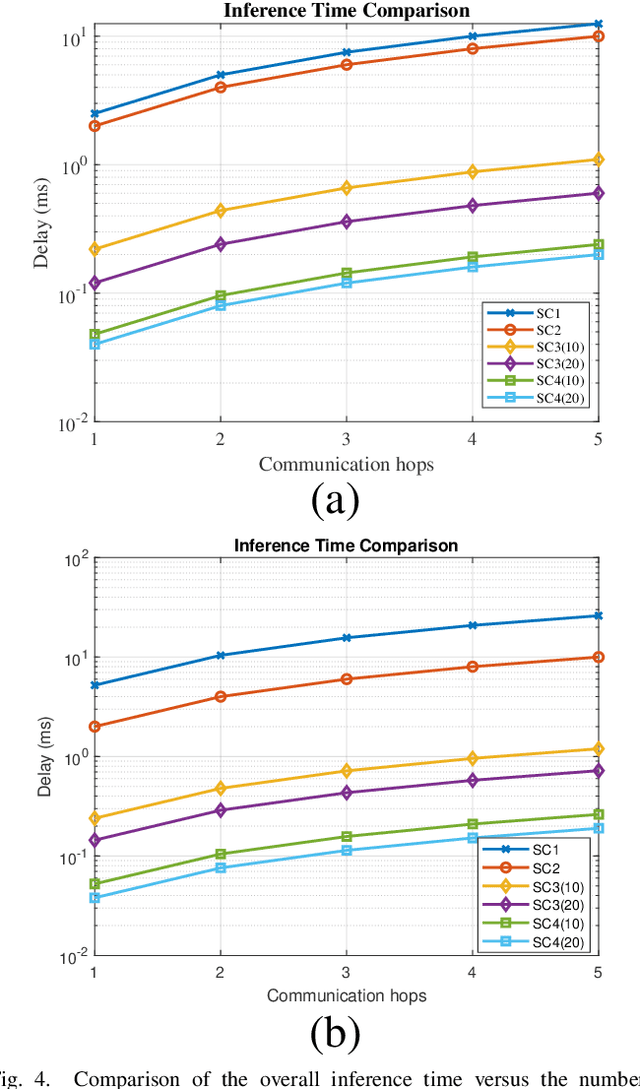
Accurate and timely prediction of transportation demand and supply is essential for improving customer experience and raising the provider's profit. Recently, graph neural networks (GNNs) have been shown promising in predicting traffic demand and supply in small city regions. This awes their capability in modeling both a node's historical features and its relational information with other nodes. However, more efficient taxi demand and supply forecasting can still be achieved by following two main routes. First, is extending the scale of the prediction graph to include more regions. Second, is the simultaneous exploitation of multiple node and edge types to better expose and exploit the complex and diverse set of relations in a traffic system. Nevertheless, the applicability of both approaches is challenged by the scalability of system-wide GNN training and inference. An immediate remedy to the scalability challenge is to decentralize the GNN operation. However, decentralizing GNN operation creates excessive node-to-node communication overhead which hinders the potential of this approach. In this paper, we propose a semi-decentralized approach based on the use of multiple, moderately sized, and high-throughout cloudlet communication networks on the edge. This approach combines the best features of the centralized and decentralized settings; it may minimize the inter-cloudlet communication thereby alleviating the communication overhead of the decentralized approach while promoting scalability due to cloudlet-level decentralization. Also, we propose a heterogeneous GNN-LSTM algorithm for improved taxi-level demand and supply forecasting. This approach allows for handling dynamic taxi graphs where nodes are taxis. Through a set of experiments over real data, we show the advantage of the semi-decentralized approach as tested over our GNN-LSTM algorithm for taxi demand and supply prediction.
Maximum Consensus Localization using an Objective Function based on Helmert's Point Error
Feb 21, 2023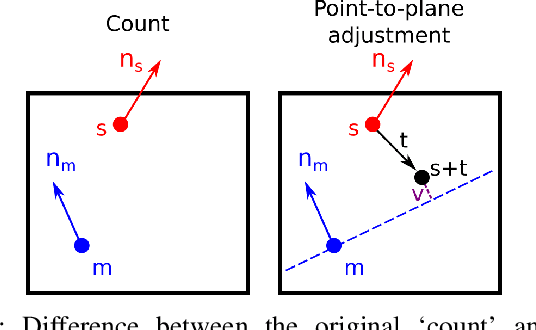
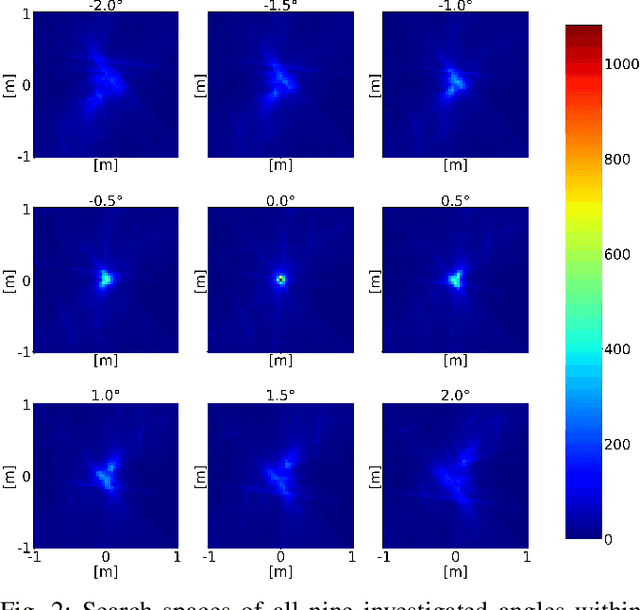

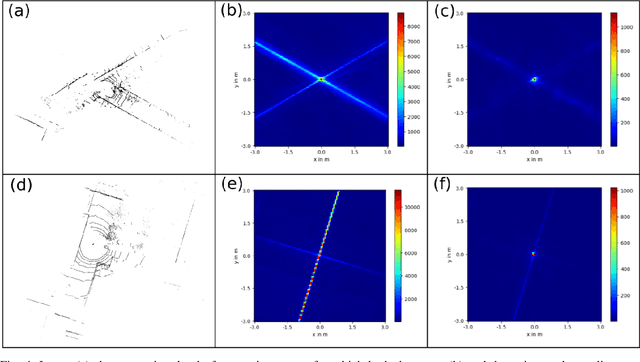
Ego-localization is a crucial task for autonomous vehicles. On the one hand, it needs to be very accurate, and on the other hand, very robust to provide reliable pose (position and orientation) information, even in challenging environments. Finding the best ego-position is usually tied to optimizing an objective function based on the sensor measurements. The most common approach is to maximize the likelihood, which leads under the assumption of normally distributed random variables to the well-known least squares minimization, often used in conjunction with recursive estimation, e. g. using a Kalman filter. However, least squares minimization is inherently sensitive to outliers, and consequently, more robust loss functions, such as L1 norm or Huber loss have been proposed. Arguably the most robust loss function is the outlier count, also known as maximum consensus optimization, where the outcome is independent of the outlier magnitude. In this paper, we investigate in detail the performance of maximum consensus localization based on LiDAR data. We elaborate on its shortcomings and propose a novel objective function based on Helmert's point error. In an experiment using 3001 measurement epochs, we show that the maximum consensus localization based on the introduced objective function provides superior results with respect to robustness.
Learning Physical Models that Can Respect Conservation Laws
Feb 21, 2023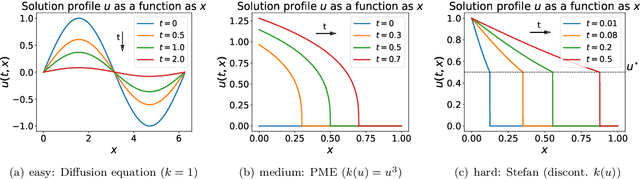
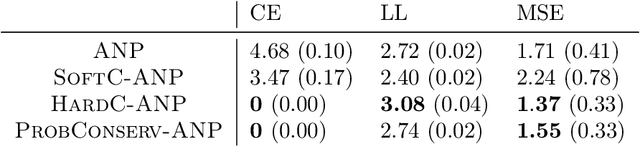
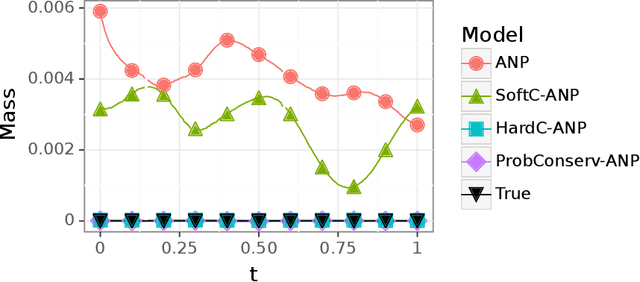

Recent work in scientific machine learning (SciML) has focused on incorporating partial differential equation (PDE) information into the learning process. Much of this work has focused on relatively ``easy'' PDE operators (e.g., elliptic and parabolic), with less emphasis on relatively ``hard'' PDE operators (e.g., hyperbolic). Within numerical PDEs, the latter problem class requires control of a type of volume element or conservation constraint, which is known to be challenging. Delivering on the promise of SciML requires seamlessly incorporating both types of problems into the learning process. To address this issue, we propose ProbConserv, a framework for incorporating conservation constraints into a generic SciML architecture. To do so, ProbConserv combines the integral form of a conservation law with a Bayesian update. We provide a detailed analysis of ProbConserv on learning with the Generalized Porous Medium Equation (GPME), a widely-applicable parameterized family of PDEs that illustrates the qualitative properties of both easier and harder PDEs. ProbConserv is effective for easy GPME variants, performing well with state-of-the-art competitors; and for harder GPME variants it outperforms other approaches that do not guarantee volume conservation. ProbConserv seamlessly enforces physical conservation constraints, maintains probabilistic uncertainty quantification (UQ), and deals well with shocks and heteroscedasticities. In each case, it achieves superior predictive performance on downstream tasks.
Membership Inference Attacks against Synthetic Data through Overfitting Detection
Feb 24, 2023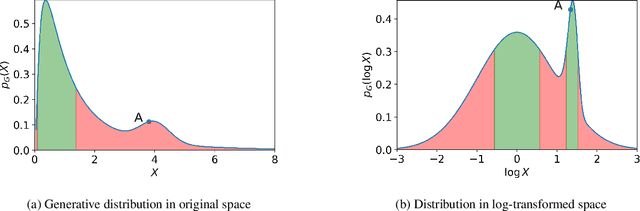
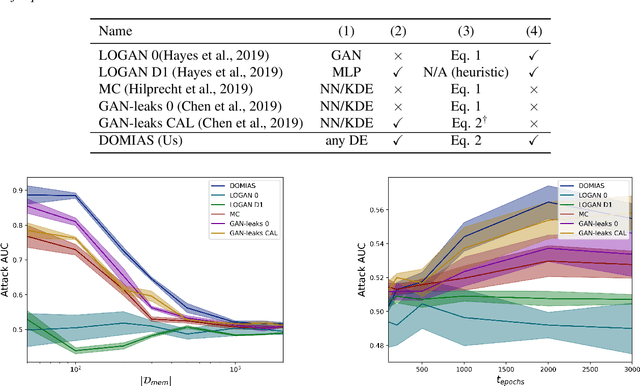
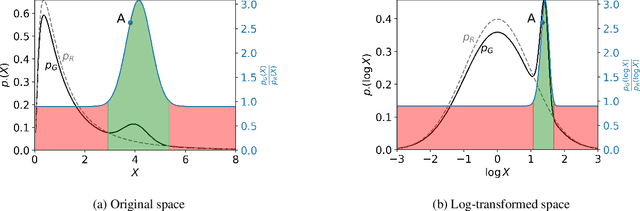
Data is the foundation of most science. Unfortunately, sharing data can be obstructed by the risk of violating data privacy, impeding research in fields like healthcare. Synthetic data is a potential solution. It aims to generate data that has the same distribution as the original data, but that does not disclose information about individuals. Membership Inference Attacks (MIAs) are a common privacy attack, in which the attacker attempts to determine whether a particular real sample was used for training of the model. Previous works that propose MIAs against generative models either display low performance -- giving the false impression that data is highly private -- or need to assume access to internal generative model parameters -- a relatively low-risk scenario, as the data publisher often only releases synthetic data, not the model. In this work we argue for a realistic MIA setting that assumes the attacker has some knowledge of the underlying data distribution. We propose DOMIAS, a density-based MIA model that aims to infer membership by targeting local overfitting of the generative model. Experimentally we show that DOMIAS is significantly more successful at MIA than previous work, especially at attacking uncommon samples. The latter is disconcerting since these samples may correspond to underrepresented groups. We also demonstrate how DOMIAS' MIA performance score provides an interpretable metric for privacy, giving data publishers a new tool for achieving the desired privacy-utility trade-off in their synthetic data.
Video Waterdrop Removal via Spatio-Temporal Fusion in Driving Scenes
Feb 12, 2023
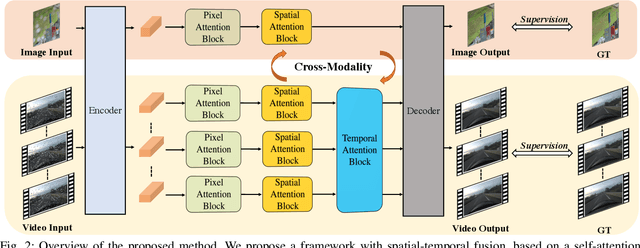

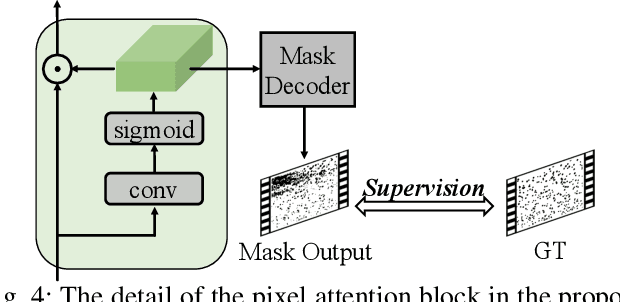
The waterdrops on windshields during driving can cause severe visual obstructions, which may lead to car accidents. Meanwhile, the waterdrops can also degrade the performance of a computer vision system in autonomous driving. To address these issues, we propose an attention-based framework that fuses the spatio-temporal representations from multiple frames to restore visual information occluded by waterdrops. Due to the lack of training data for video waterdrop removal, we propose a large-scale synthetic dataset with simulated waterdrops in complex driving scenes on rainy days. To improve the generality of our proposed method, we adopt a cross-modality training strategy that combines synthetic videos and real-world images. Extensive experiments show that our proposed method can generalize well and achieve the best waterdrop removal performance in complex real-world driving scenes.
See You Soon: Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image
Feb 05, 2023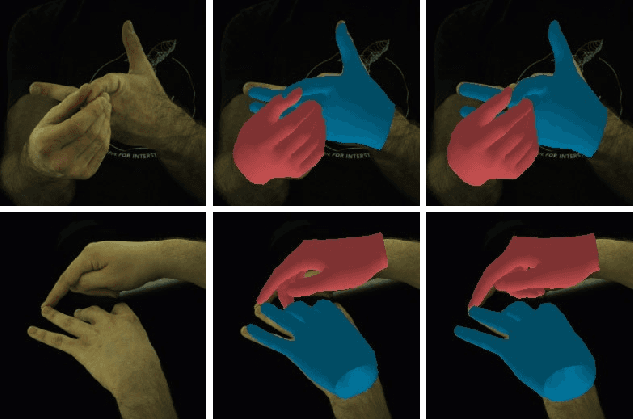


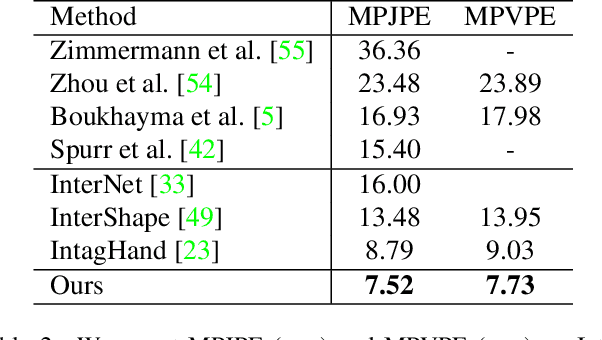
Reconstructing interacting hands from a single RGB image is a very challenging task. On the one hand, severe mutual occlusion and similar local appearance between two hands confuse the extraction of visual features, resulting in the misalignment of estimated hand meshes and the image. On the other hand, there are complex interaction patterns between interacting hands, which significantly increases the solution space of hand poses and increases the difficulty of network learning. In this paper, we propose a decoupled iterative refinement framework to achieve pixel-alignment hand reconstruction while efficiently modeling the spatial relationship between hands. Specifically, we define two feature spaces with different characteristics, namely 2D visual feature space and 3D joint feature space. First, we obtain joint-wise features from the visual feature map and utilize a graph convolution network and a transformer to perform intra- and inter-hand information interaction in the 3D joint feature space, respectively. Then, we project the joint features with global information back into the 2D visual feature space in an obfuscation-free manner and utilize the 2D convolution for pixel-wise enhancement. By performing multiple alternate enhancements in the two feature spaces, our method can achieve an accurate and robust reconstruction of interacting hands. Our method outperforms all existing two-hand reconstruction methods by a large margin on the InterHand2.6M dataset. Meanwhile, our method shows a strong generalization ability for in-the-wild images.
Local Feature Extraction from Salient Regions by Feature Map Transformation
Jan 25, 2023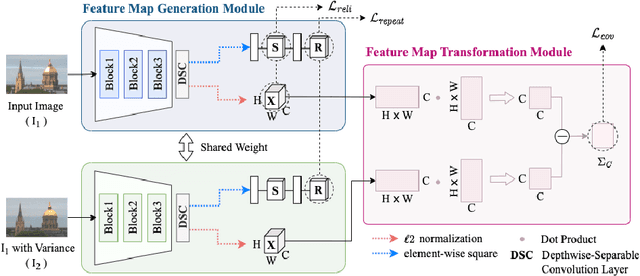
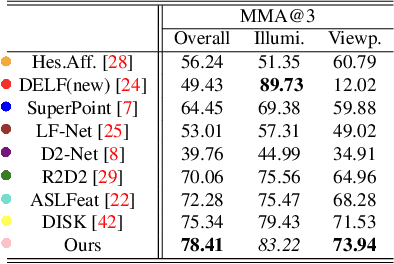

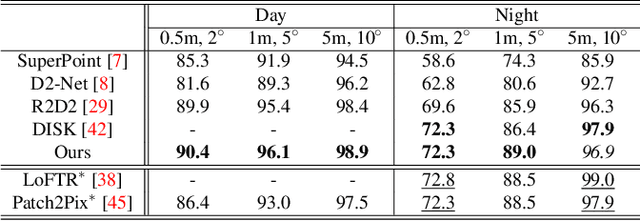
Local feature matching is essential for many applications, such as localization and 3D reconstruction. However, it is challenging to match feature points accurately in various camera viewpoints and illumination conditions. In this paper, we propose a framework that robustly extracts and describes salient local features regardless of changing light and viewpoints. The framework suppresses illumination variations and encourages structural information to ignore the noise from light and to focus on edges. We classify the elements in the feature covariance matrix, an implicit feature map information, into two components. Our model extracts feature points from salient regions leading to reduced incorrect matches. In our experiments, the proposed method achieved higher accuracy than the state-of-the-art methods in the public dataset, such as HPatches, Aachen Day-Night, and ETH, which especially show highly variant viewpoints and illumination.
3D-aware Blending with Generative NeRFs
Feb 13, 2023

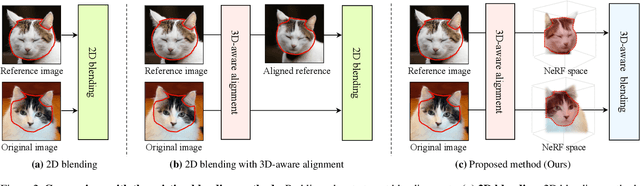
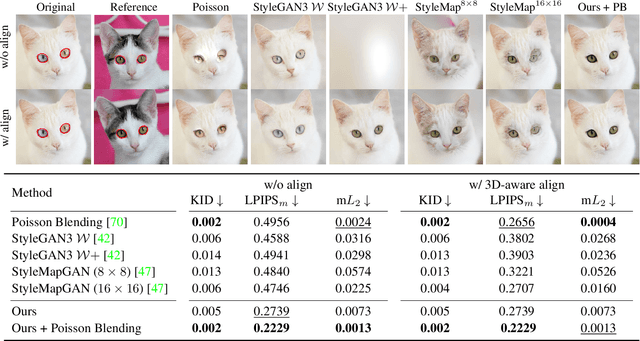
Image blending aims to combine multiple images seamlessly. It remains challenging for existing 2D-based methods, especially when input images are misaligned due to differences in 3D camera poses and object shapes. To tackle these issues, we propose a 3D-aware blending method using generative Neural Radiance Fields (NeRF), including two key components: 3D-aware alignment and 3D-aware blending. For 3D-aware alignment, we first estimate the camera pose of the reference image with respect to generative NeRFs and then perform 3D local alignment for each part. To further leverage 3D information of the generative NeRF, we propose 3D-aware blending that directly blends images on the NeRF's latent representation space, rather than raw pixel space. Collectively, our method outperforms existing 2D baselines, as validated by extensive quantitative and qualitative evaluations with FFHQ and AFHQ-Cat.