 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Feasibility of Out-of-Band Spatial Channel Information for Millimeter-Wave Beam Search
Aug 11, 2022

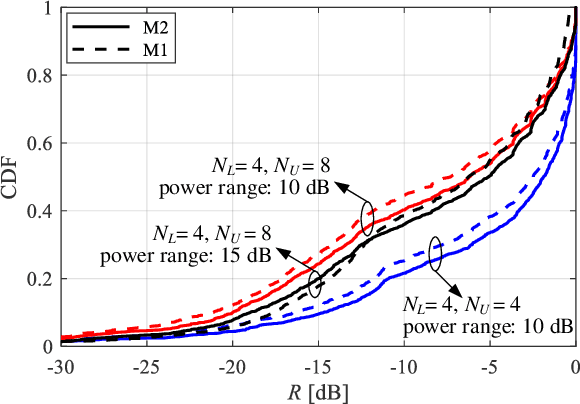
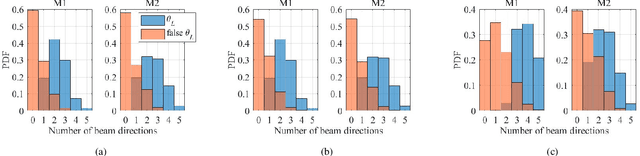
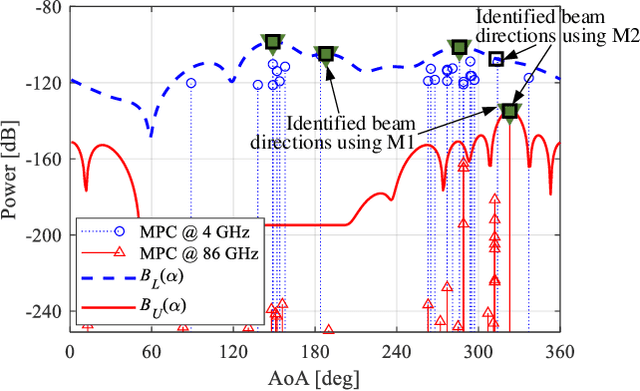
The rollout of millimeter-wave (mmWave) cellular network enables us to realize the full potential of 5G/6G with vastly improved throughput and ultra-low latency. MmWave communication relies on highly directional transmission, which significantly increase the training overhead for fine beam alignment. The concept of using out-of-band spatial information to aid mmWave beam search is developed when multi-band systems operating in parallel. The feasibility of leveraging low-band channel information for coarse estimation of high-band beam directions strongly depends on the spatial congruence between two frequency bands. In this paper, we try to provide insights into the answers of two important questions. First, how similar is the power angular spectra (PAS) of radio channels between two well-separated frequency bands? Then, what is the impact of practical system configurations on spatial channel similarity? Specifically, the beam direction-based metric is proposed to measure the power loss and number of false directions if out-of-band spatial information is used instead of in-band information. This metric is more practical and useful than comparing normalized PAS directly. Point cloud ray-tracing and measurement results across multiple frequency bands and environments show that the degree of spatial similarity of beamformed channels is related to antenna beamwidth, frequency gap, and radio link conditions.
Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition
Feb 16, 2023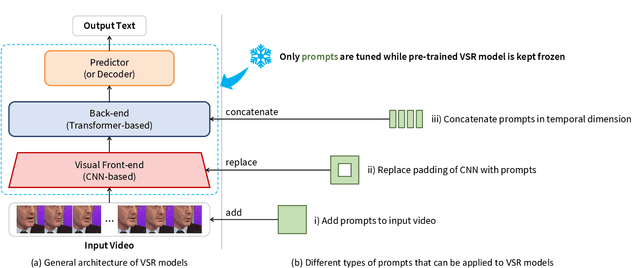
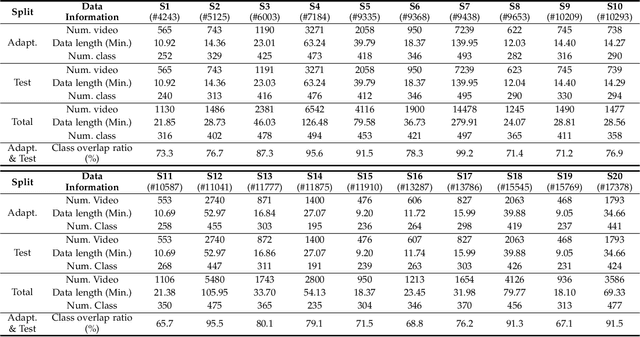
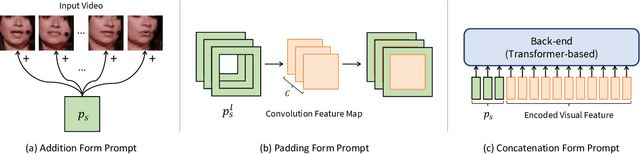
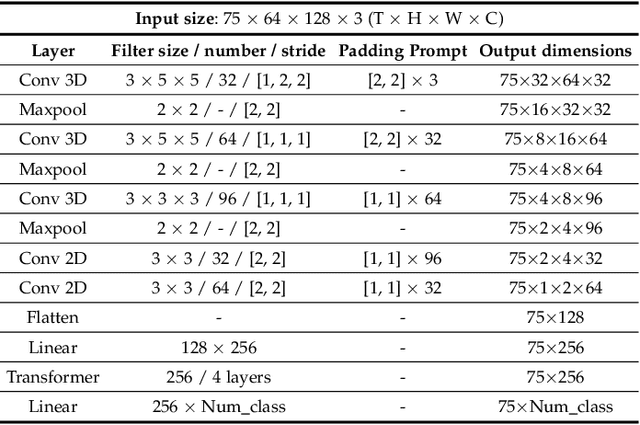
Visual Speech Recognition (VSR) aims to infer speech into text depending on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements, and this makes the VSR models show degraded performance when they are applied to unseen speakers. In this paper, to remedy the performance degradation of the VSR model on unseen speakers, we propose prompt tuning methods of Deep Neural Networks (DNNs) for speaker-adaptive VSR. Specifically, motivated by recent advances in Natural Language Processing (NLP), we finetune prompts on adaptation data of target speakers instead of modifying the pre-trained model parameters. Different from the previous prompt tuning methods mainly limited to Transformer variant architecture, we explore different types of prompts, the addition, the padding, and the concatenation form prompts that can be applied to the VSR model which is composed of CNN and Transformer in general. With the proposed prompt tuning, we show that the performance of the pre-trained VSR model on unseen speakers can be largely improved by using a small amount of adaptation data (e.g., less than 5 minutes), even if the pre-trained model is already developed with large speaker variations. Moreover, by analyzing the performance and parameters of different types of prompts, we investigate when the prompt tuning is preferred over the finetuning methods. The effectiveness of the proposed method is evaluated on both word- and sentence-level VSR databases, LRW-ID and GRID.
A Minimax Approach Against Multi-Armed Adversarial Attacks Detection
Feb 04, 2023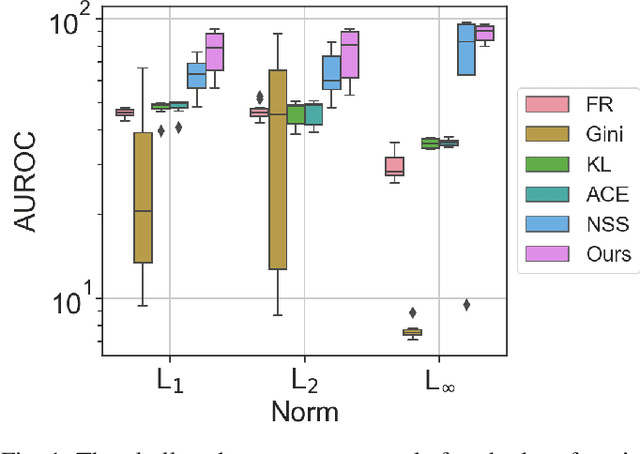
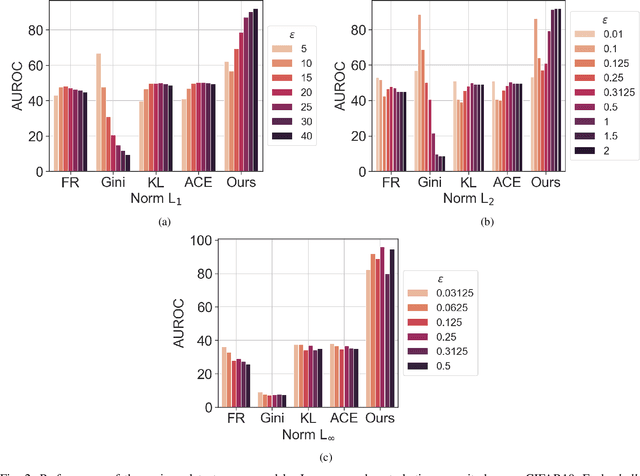
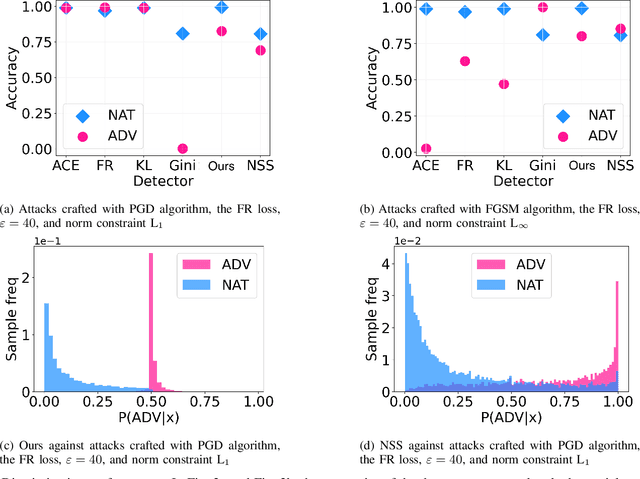
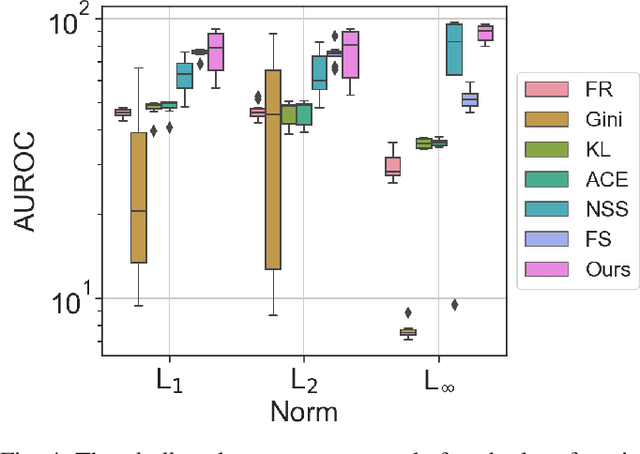
Multi-armed adversarial attacks, in which multiple algorithms and objective loss functions are simultaneously used at evaluation time, have been shown to be highly successful in fooling state-of-the-art adversarial examples detectors while requiring no specific side information about the detection mechanism. By formalizing the problem at hand, we can propose a solution that aggregates the soft-probability outputs of multiple pre-trained detectors according to a minimax approach. The proposed framework is mathematically sound, easy to implement, and modular, allowing for integrating existing or future detectors. Through extensive evaluation on popular datasets (e.g., CIFAR10 and SVHN), we show that our aggregation consistently outperforms individual state-of-the-art detectors against multi-armed adversarial attacks, making it an effective solution to improve the resilience of available methods.
Medical Dialogue Response Generation with Pivotal Information Recalling
Jun 17, 2022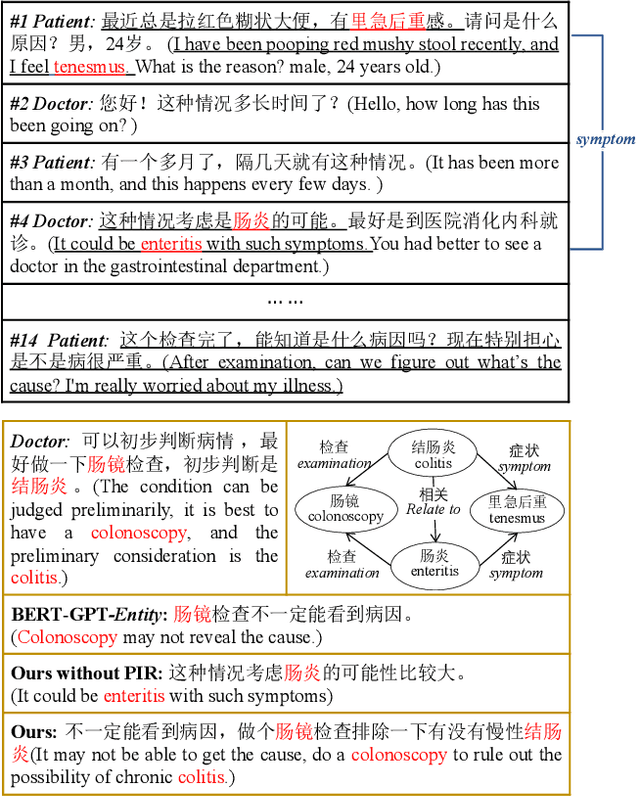
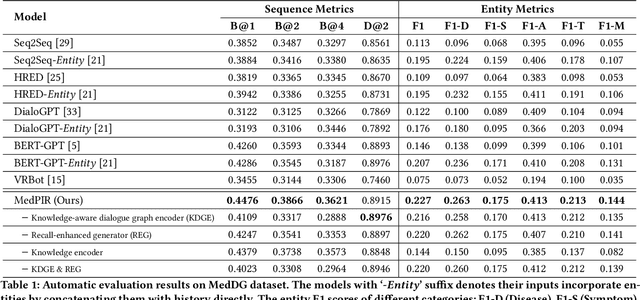

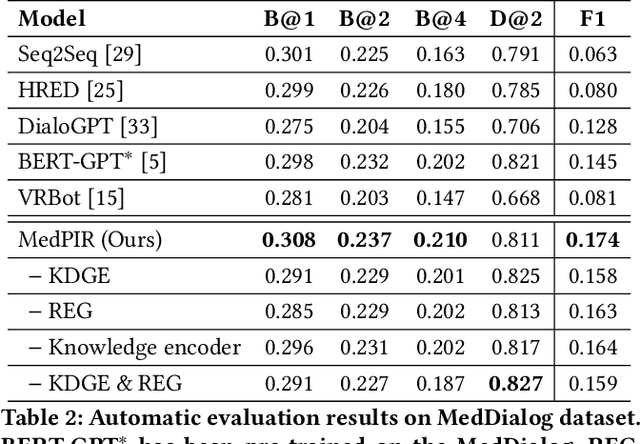
Medical dialogue generation is an important yet challenging task. Most previous works rely on the attention mechanism and large-scale pretrained language models. However, these methods often fail to acquire pivotal information from the long dialogue history to yield an accurate and informative response, due to the fact that the medical entities usually scatters throughout multiple utterances along with the complex relationships between them. To mitigate this problem, we propose a medical response generation model with Pivotal Information Recalling (MedPIR), which is built on two components, i.e., knowledge-aware dialogue graph encoder and recall-enhanced generator. The knowledge-aware dialogue graph encoder constructs a dialogue graph by exploiting the knowledge relationships between entities in the utterances, and encodes it with a graph attention network. Then, the recall-enhanced generator strengthens the usage of these pivotal information by generating a summary of the dialogue before producing the actual response. Experimental results on two large-scale medical dialogue datasets show that MedPIR outperforms the strong baselines in BLEU scores and medical entities F1 measure.
A Method For Eliminating Contour Errors In Self-Encoder Reconstructed Images
Jan 25, 2023
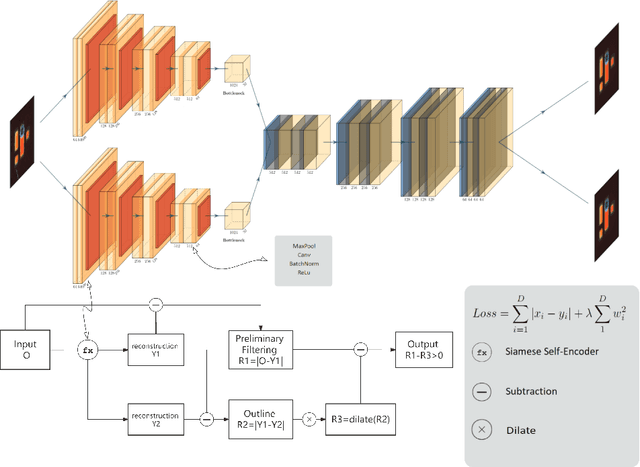
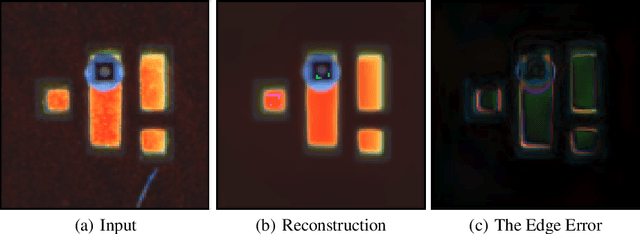
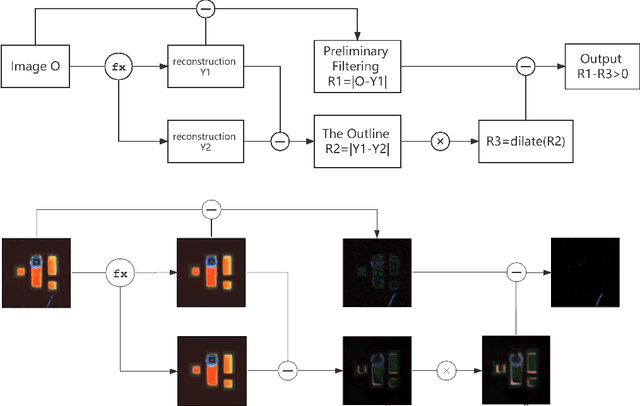
In this paper, we propose a self-supervised twin network approach based on this a priori. The method of generating the approximate10 edge information of an image and then differentially eliminating the edge errors11 in the reconstructed image with a dilate algorithm. This is used to improve the12 accuracy of the reconstructed image and to separate foreign matter and noise from13 the original image, so that it can be visualized in a more practical scene
Towards Efficient Subarray Hybrid Beamforming: Attention Network-based Practical Feedback in FDD Massive MU-MIMO Systems
Feb 05, 2023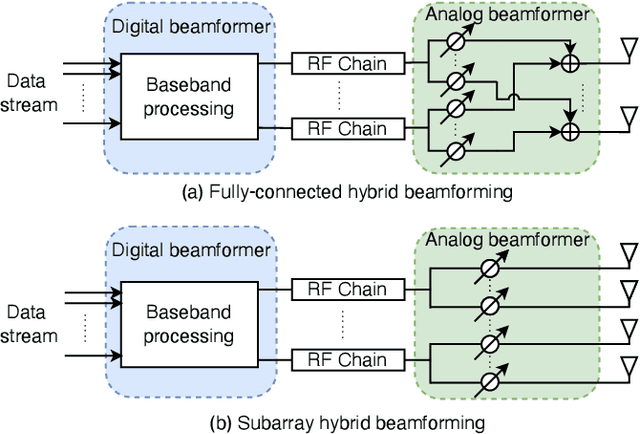
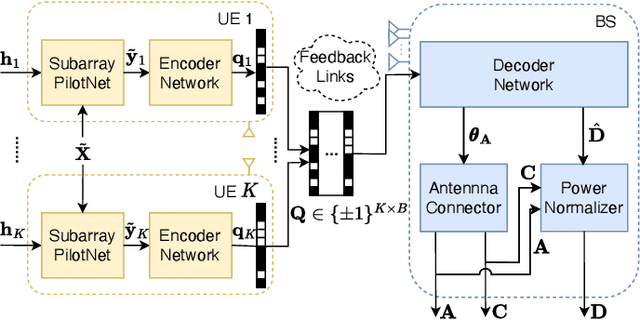
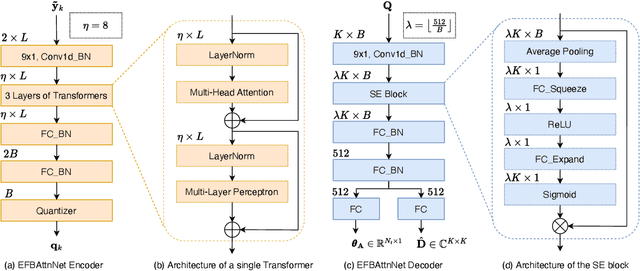
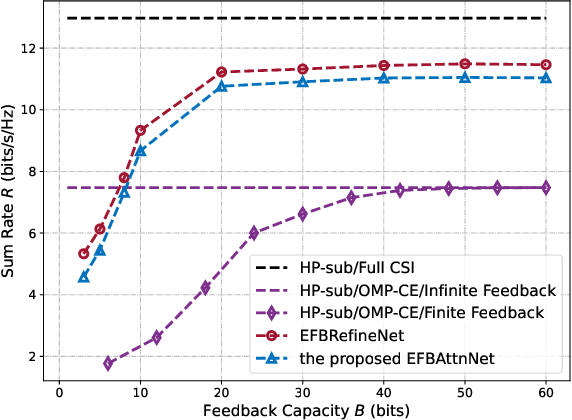
Channel state information (CSI) feedback is necessary for the frequency division duplexing (FDD) multiple input multiple output (MIMO) systems due to the channel non-reciprocity. With the help of deep learning, many works have succeeded in rebuilding the compressed ideal CSI for massive MIMO. However, simple CSI reconstruction is of limited practicality since the channel estimation and the targeted beamforming design are not considered. In this paper, a jointly optimized network is introduced for channel estimation and feedback so that a spectral-efficient beamformer can be learned. Moreover, the deployment-friendly subarray hybrid beamforming architecture is applied and a practical lightweight end-to-end network is specially designed. Experiments show that the proposed network is over 10 times lighter at the resource-sensitive user equipment compared with the previous state-of-the-art method with only a minor performance loss.
Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models
Feb 11, 2023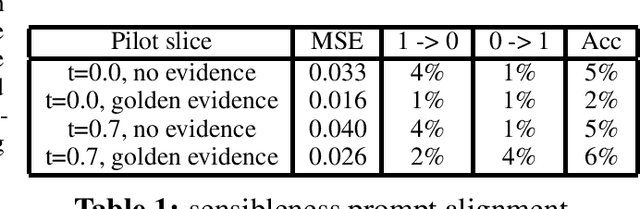
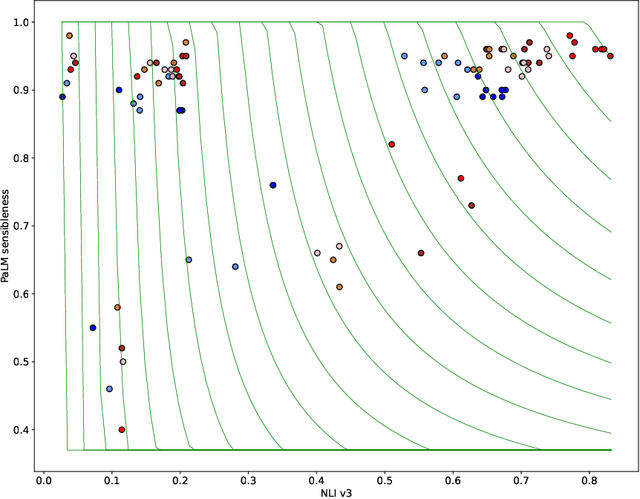

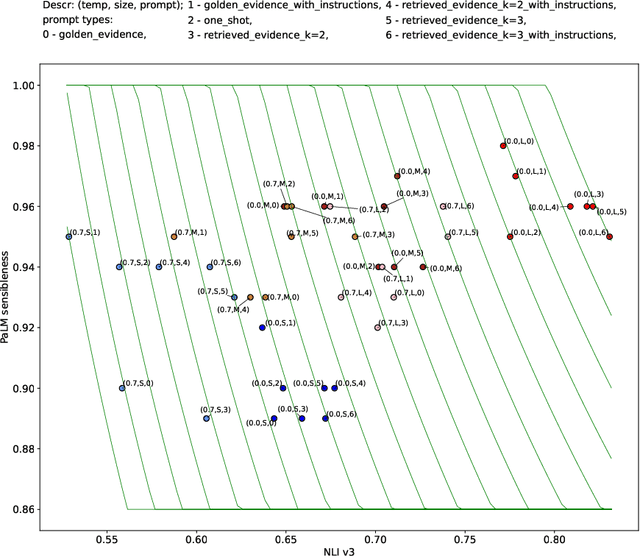
Despite recent progress, it has been difficult to prevent semantic hallucinations in generative Large Language Models. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information. Given this new added constraint, it is plausible to expect that the overall quality of the output will be affected, for example, in terms of fluency. Can scaling language models help? Here we examine the relationship between fluency and attribution in LLMs prompted with retrieved evidence in knowledge-heavy dialog settings. Our experiments were implemented with a set of auto-metrics that are aligned with human preferences. They were used to evaluate a large set of generations, produced under varying parameters of LLMs and supplied context. We show that larger models tend to do much better in both fluency and attribution, and that (naively) using top-k retrieval versus top-1 retrieval improves attribution but hurts fluency. We next propose a recipe that could allow smaller models to both close the gap with larger models and preserve the benefits of top-k retrieval while avoiding its drawbacks.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023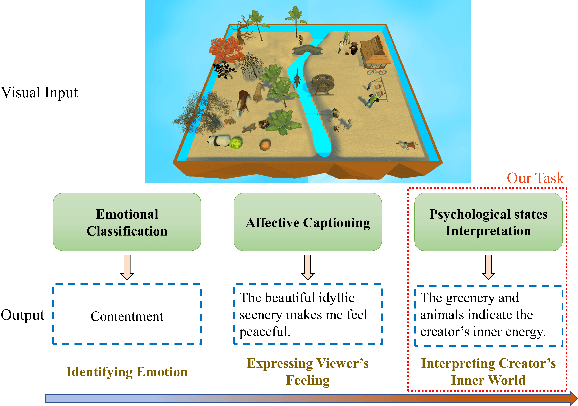

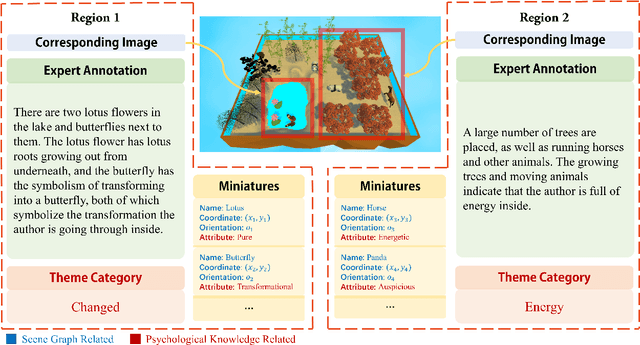
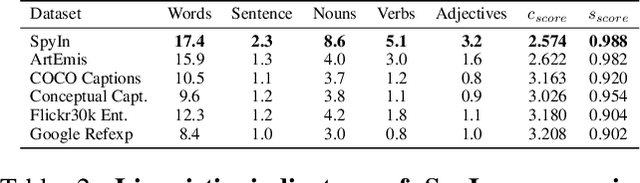
In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.
Is Distance Matrix Enough for Geometric Deep Learning?
Feb 11, 2023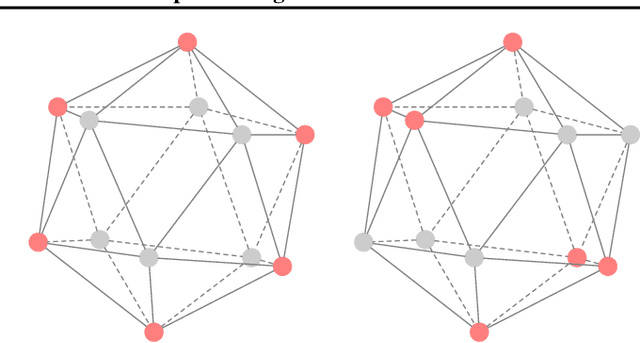
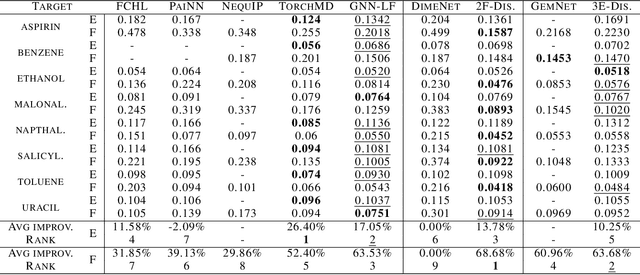
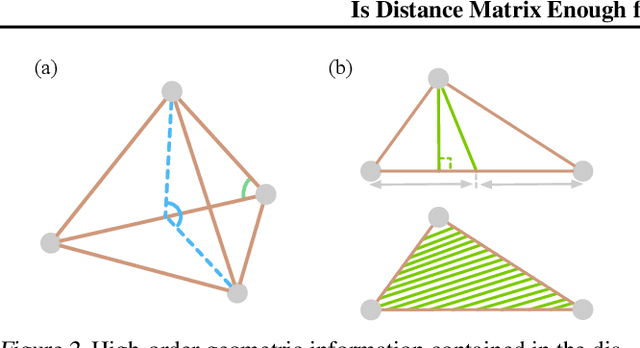
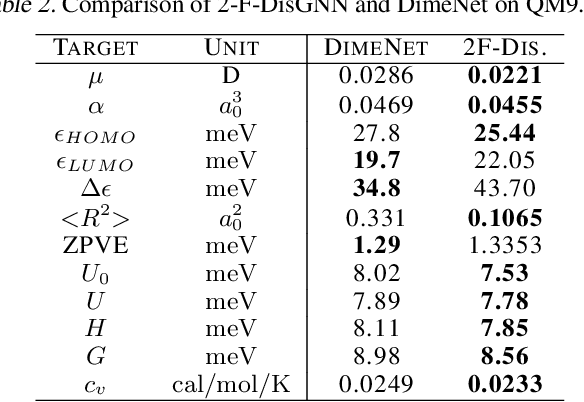
Graph Neural Networks (GNNs) are often used for tasks involving the geometry of a given graph, such as molecular dynamics simulation. While the distance matrix of a graph contains the complete geometric structure information, whether GNNs can learn this geometry solely from the distance matrix has yet to be studied. In this work, we first demonstrate that Message Passing Neural Networks (MPNNs) are insufficient for learning the geometry of a graph from its distance matrix by constructing families of geometric graphs which cannot be distinguished by MPNNs. We then propose $k$-DisGNNs, which can effectively exploit the rich geometry contained in the distance matrix. We demonstrate the high expressive power of our models and prove that some existing well-designed geometric models can be unified by $k$-DisGNNs as special cases. Most importantly, we establish a connection between geometric deep learning and traditional graph representation learning, showing that those highly expressive GNN models originally designed for graph structure learning can also be applied to geometric deep learning problems with impressive performance, and that existing complex, equivariant models are not the only solution. Experimental results verify our theory.
Sequential Underspecified Instrument Selection for Cause-Effect Estimation
Feb 11, 2023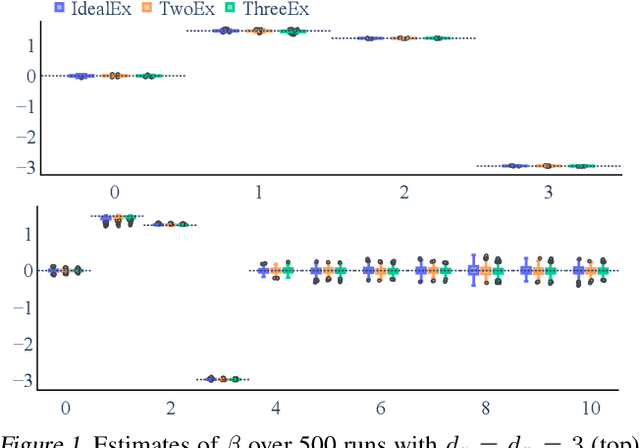
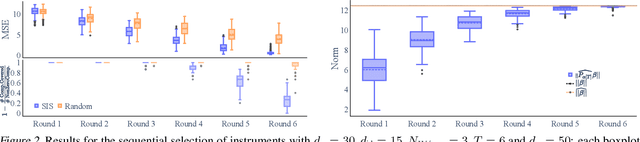
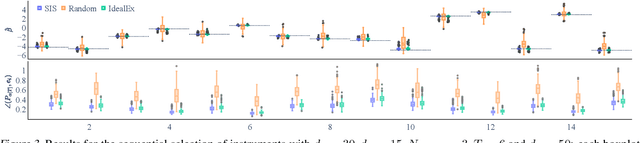
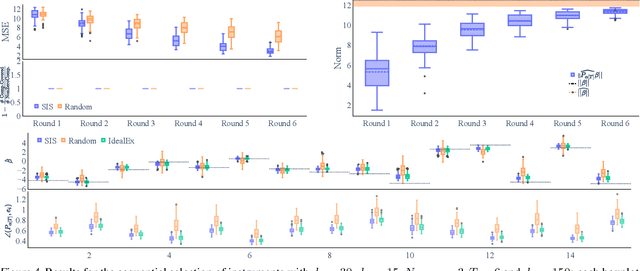
Instrumental variable (IV) methods are used to estimate causal effects in settings with unobserved confounding, where we cannot directly experiment on the treatment variable. Instruments are variables which only affect the outcome indirectly via the treatment variable(s). Most IV applications focus on low-dimensional treatments and crucially require at least as many instruments as treatments. This assumption is restrictive: in the natural sciences we often seek to infer causal effects of high-dimensional treatments (e.g., the effect of gene expressions or microbiota on health and disease), but can only run few experiments with a limited number of instruments (e.g., drugs or antibiotics). In such underspecified problems, the full treatment effect is not identifiable in a single experiment even in the linear case. We show that one can still reliably recover the projection of the treatment effect onto the instrumented subspace and develop techniques to consistently combine such partial estimates from different sets of instruments. We then leverage our combined estimators in an algorithm that iteratively proposes the most informative instruments at each round of experimentation to maximize the overall information about the full causal effect.