 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MaskSketch: Unpaired Structure-guided Masked Image Generation
Feb 10, 2023

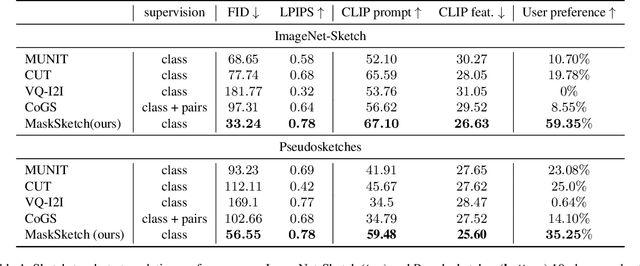

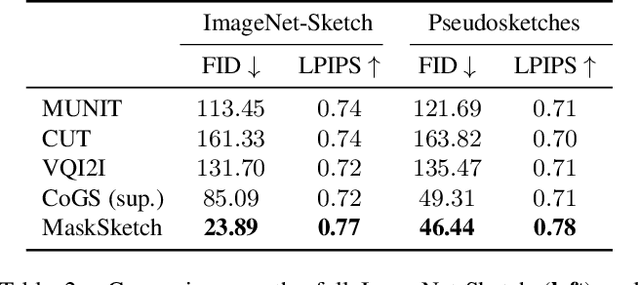
Recent conditional image generation methods produce images of remarkable diversity, fidelity and realism. However, the majority of these methods allow conditioning only on labels or text prompts, which limits their level of control over the generation result. In this paper, we introduce MaskSketch, an image generation method that allows spatial conditioning of the generation result using a guiding sketch as an extra conditioning signal during sampling. MaskSketch utilizes a pre-trained masked generative transformer, requiring no model training or paired supervision, and works with input sketches of different levels of abstraction. We show that intermediate self-attention maps of a masked generative transformer encode important structural information of the input image, such as scene layout and object shape, and we propose a novel sampling method based on this observation to enable structure-guided generation. Our results show that MaskSketch achieves high image realism and fidelity to the guiding structure. Evaluated on standard benchmark datasets, MaskSketch outperforms state-of-the-art methods for sketch-to-image translation, as well as unpaired image-to-image translation approaches.
Example-Based Sampling with Diffusion Models
Feb 10, 2023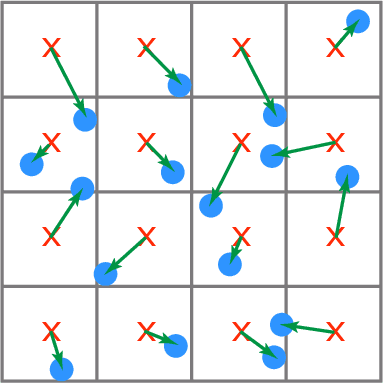
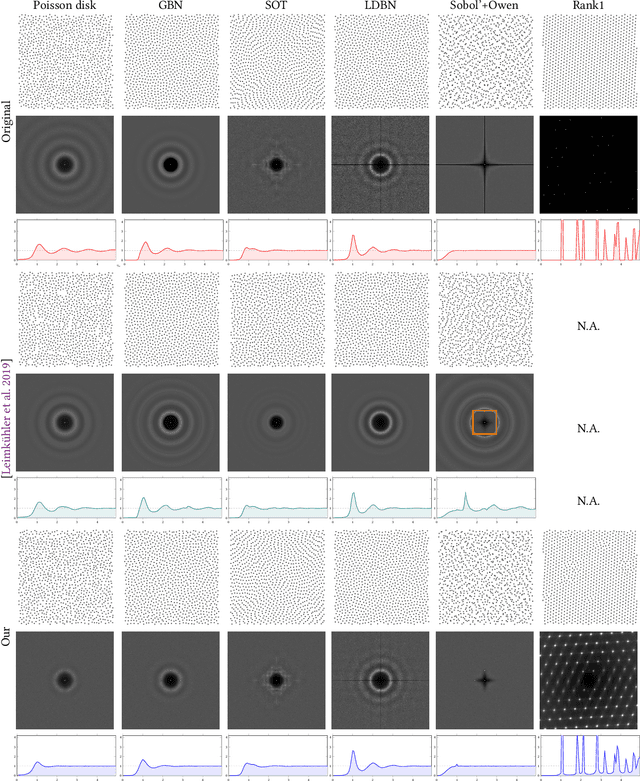
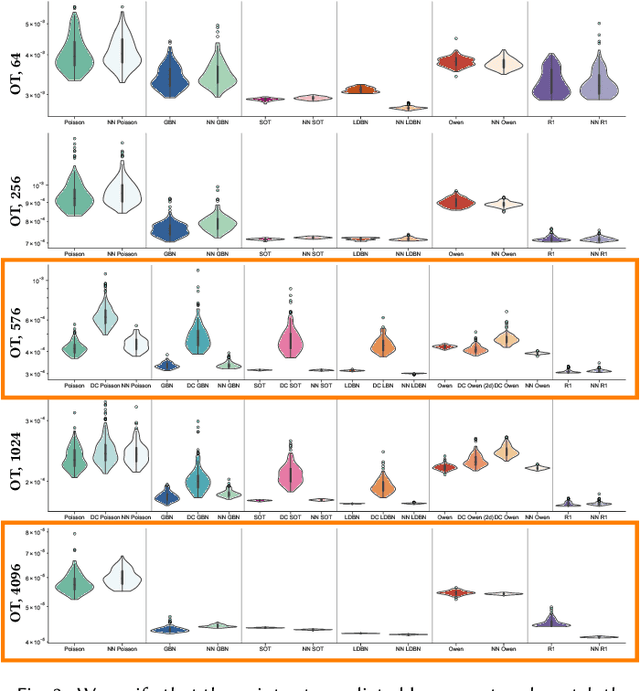
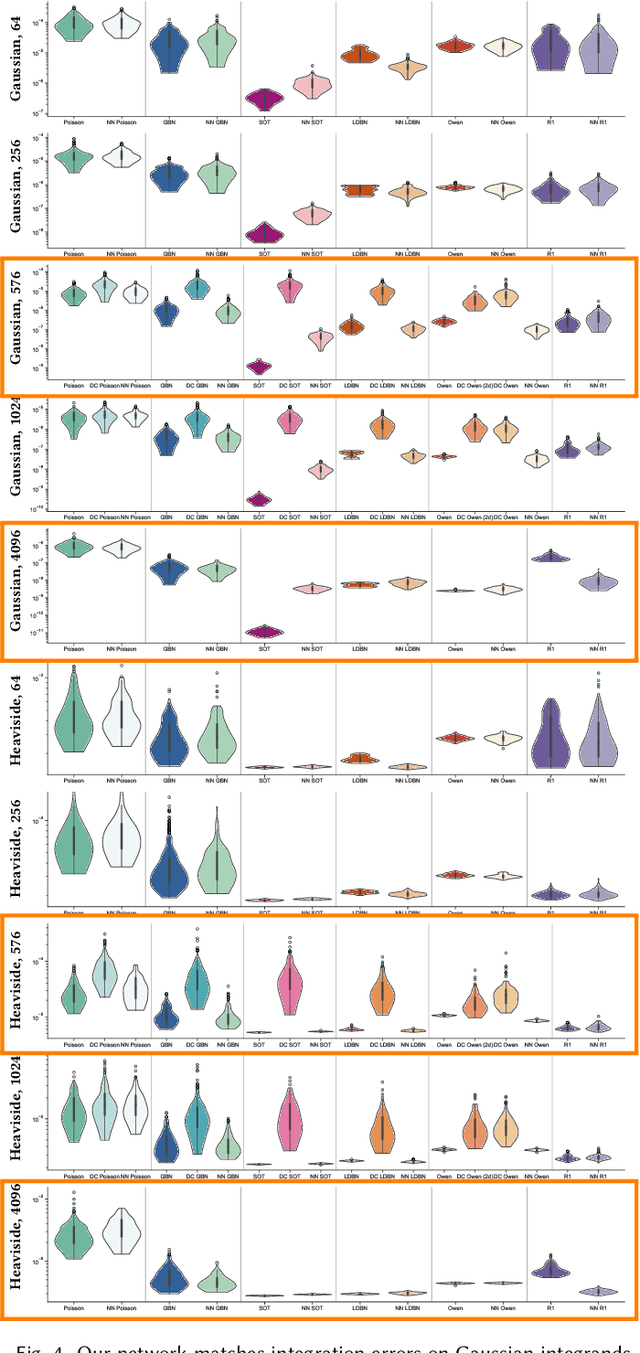
Much effort has been put into developing samplers with specific properties, such as producing blue noise, low-discrepancy, lattice or Poisson disk samples. These samplers can be slow if they rely on optimization processes, may rely on a wide range of numerical methods, are not always differentiable. The success of recent diffusion models for image generation suggests that these models could be appropriate for learning how to generate point sets from examples. However, their convolutional nature makes these methods impractical for dealing with scattered data such as point sets. We propose a generic way to produce 2-d point sets imitating existing samplers from observed point sets using a diffusion model. We address the problem of convolutional layers by leveraging neighborhood information from an optimal transport matching to a uniform grid, that allows us to benefit from fast convolutions on grids, and to support the example-based learning of non-uniform sampling patterns. We demonstrate how the differentiability of our approach can be used to optimize point sets to enforce properties.
Ablation Study on Features in Learning-based Joints Calibration of Cable-driven Surgical Robots
Feb 10, 2023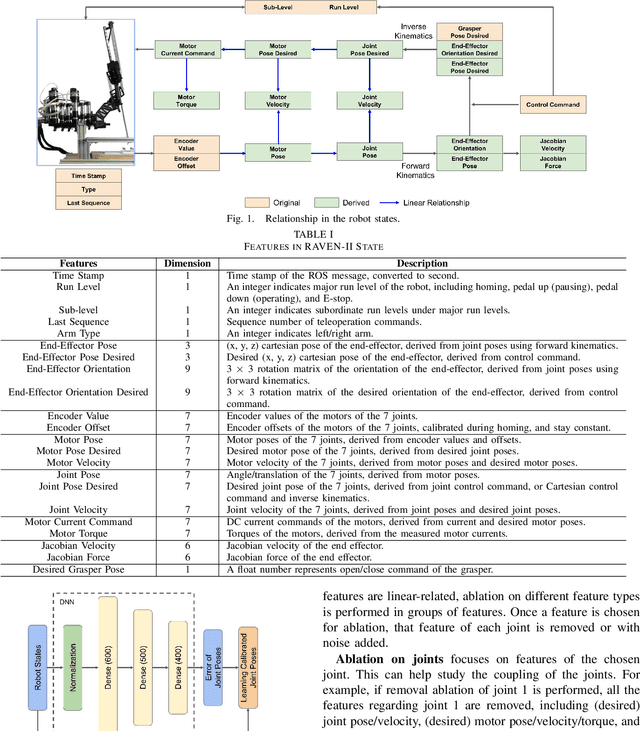
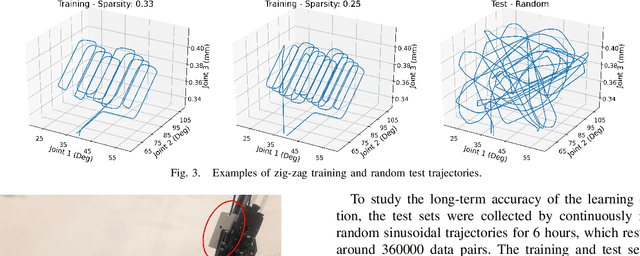
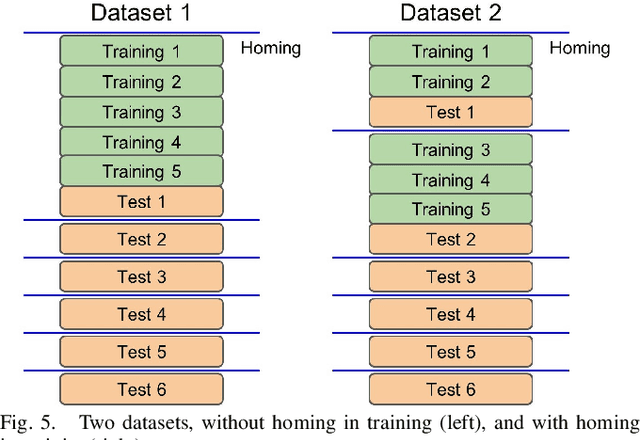
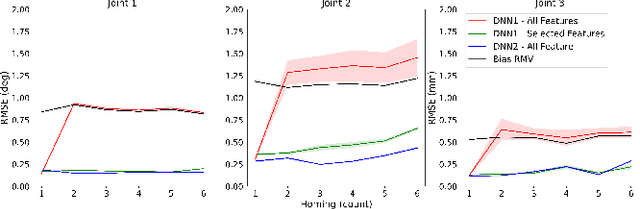
With worldwide implementation, millions of surgeries are assisted by surgical robots. The cable-drive mechanism on many surgical robots allows flexible, light, and compact arms and tools. However, the slack and stretch of the cables and the backlash of the gears introduce inevitable errors from motor poses to joint poses, and thus forwarded to the pose and orientation of the end-effector. In this paper, a learning-based calibration using a deep neural network is proposed, which reduces the unloaded pose RMSE of joints 1, 2, 3 to 0.3003 deg, 0.2888 deg, 0.1565 mm, and loaded pose RMSE of joints 1, 2, 3 to 0.4456 deg, 0.3052 deg, 0.1900 mm, respectively. Then, removal ablation and inaccurate ablation are performed to study which features of the DNN model contribute to the calibration accuracy. The results suggest that raw joint poses and motor torques are the most important features. For joint poses, the removal ablation shows that DNN model can derive this information from end-effector pose and orientation. For motor torques, the direction is much more important than amplitude.
Hyperspectral Image Compression Using Implicit Neural Representation
Feb 08, 2023
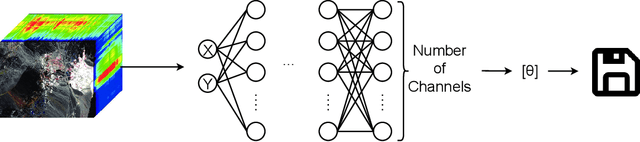

Hyperspectral images, which record the electromagnetic spectrum for a pixel in the image of a scene, often store hundreds of channels per pixel and contain an order of magnitude more information than a typical similarly-sized color image. Consequently, concomitant with the decreasing cost of capturing these images, there is a need to develop efficient techniques for storing, transmitting, and analyzing hyperspectral images. This paper develops a method for hyperspectral image compression using implicit neural representations where a multilayer perceptron network $\Phi_\theta$ with sinusoidal activation functions ``learns'' to map pixel locations to pixel intensities for a given hyperspectral image $I$. $\Phi_\theta$ thus acts as a compressed encoding of this image. The original image is reconstructed by evaluating $\Phi_\theta$ at each pixel location. We have evaluated our method on four benchmarks -- Indian Pines, Cuprite, Pavia University, and Jasper Ridge -- and we show the proposed method achieves better compression than JPEG, JPEG2000, PCA-DCT, and HVEC at low bitrates.
Diagnosing and Rectifying Vision Models using Language
Feb 08, 2023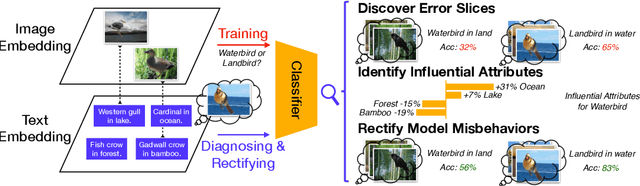

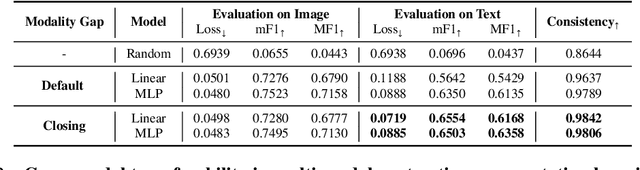
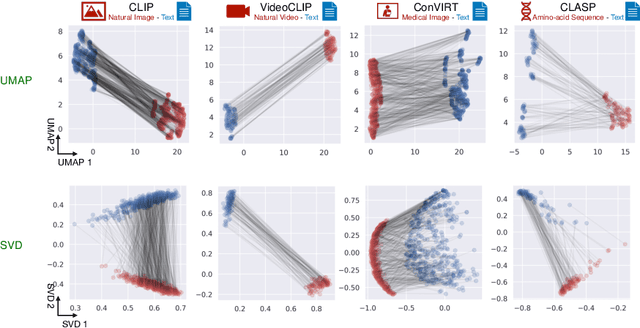
Recent multi-modal contrastive learning models have demonstrated the ability to learn an embedding space suitable for building strong vision classifiers, by leveraging the rich information in large-scale image-caption datasets. Our work highlights a distinct advantage of this multi-modal embedding space: the ability to diagnose vision classifiers through natural language. The traditional process of diagnosing model behaviors in deployment settings involves labor-intensive data acquisition and annotation. Our proposed method can discover high-error data slices, identify influential attributes and further rectify undesirable model behaviors, without requiring any visual data. Through a combination of theoretical explanation and empirical verification, we present conditions under which classifiers trained on embeddings from one modality can be equivalently applied to embeddings from another modality. On a range of image datasets with known error slices, we demonstrate that our method can effectively identify the error slices and influential attributes, and can further use language to rectify failure modes of the classifier.
Policy Evaluation in Decentralized POMDPs with Belief Sharing
Feb 08, 2023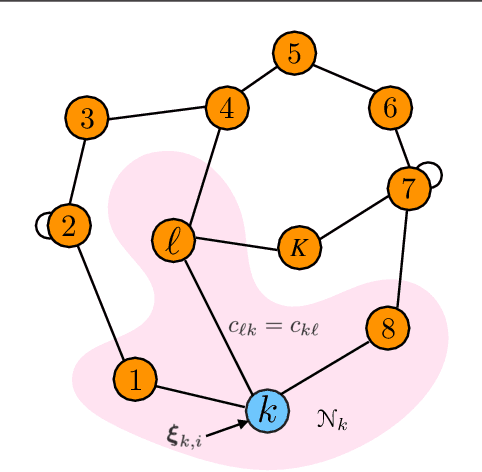
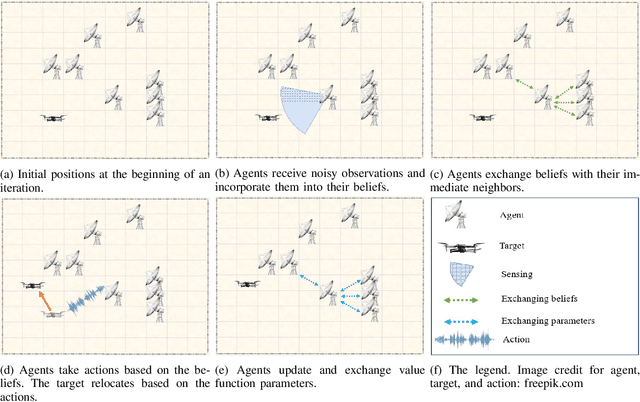
Most works on multi-agent reinforcement learning focus on scenarios where the state of the environment is fully observable. In this work, we consider a cooperative policy evaluation task in which agents are not assumed to observe the environment state directly. Instead, agents can only have access to noisy observations and to belief vectors. It is well-known that finding global posterior distributions under multi-agent settings is generally NP-hard. As a remedy, we propose a fully decentralized belief forming strategy that relies on individual updates and on localized interactions over a communication network. In addition to the exchange of the beliefs, agents exploit the communication network by exchanging value function parameter estimates as well. We analytically show that the proposed strategy allows information to diffuse over the network, which in turn allows the agents' parameters to have a bounded difference with a centralized baseline. A multi-sensor target tracking application is considered in the simulations.
Multimodal Recommender Systems: A Survey
Feb 08, 2023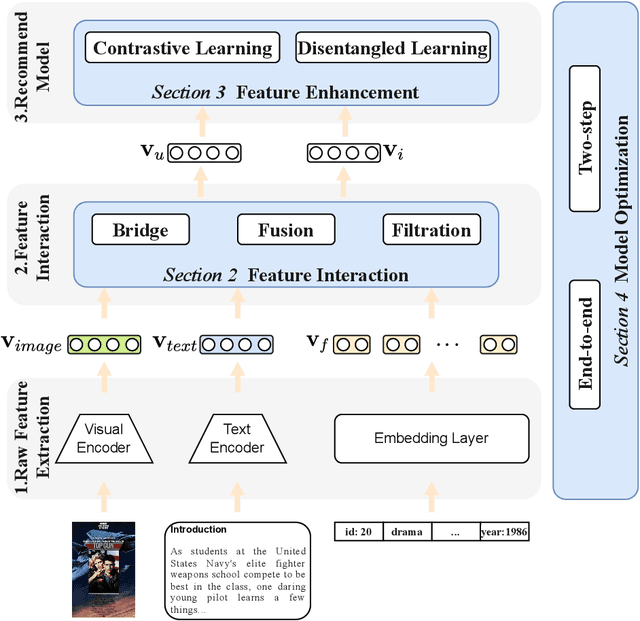
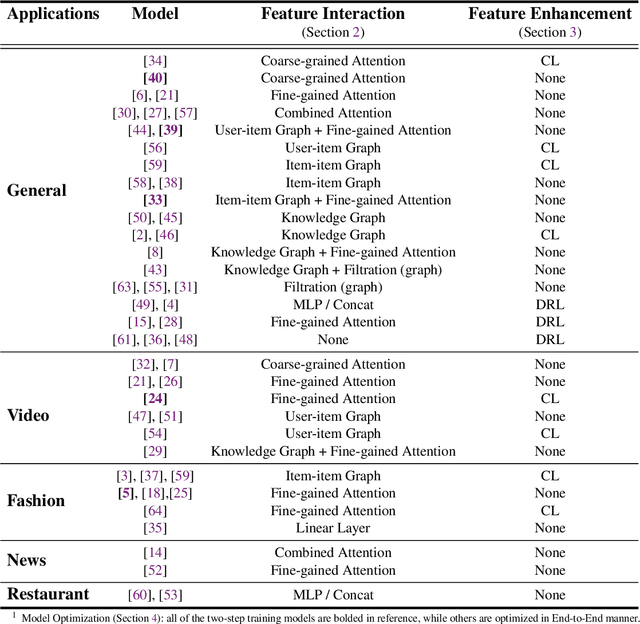
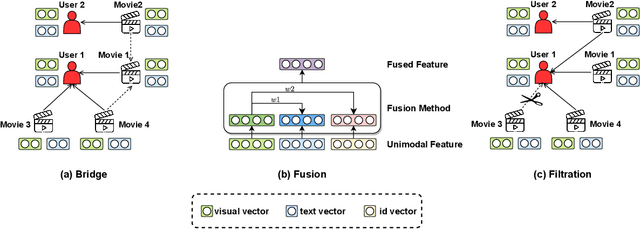
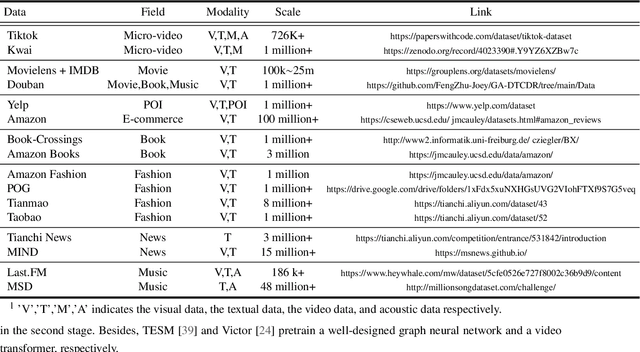
The recommender system (RS) has been an integral toolkit of online services. They are equipped with various deep learning techniques to model user preference based on identifier and attribute information. With the emergence of multimedia services, such as short video, news and etc., understanding these contents while recommending becomes critical. Besides, multimodal features are also helpful in alleviating the problem of data sparsity in RS. Thus, Multimodal Recommender System (MRS) has attracted much attention from both academia and industry recently. In this paper, we will give a comprehensive survey of the MRS models, mainly from technical views. First, we conclude the general procedures and major challenges for MRS. Then, we introduce the existing MRS models according to three categories, i.e., Feature Interaction, Feature Enhancement and Model Optimization. To make it convenient for those who want to research this field, we also summarize the dataset and code resources. Finally, we discuss some promising future directions of MRS and conclude this paper.
3D Object Detection in LiDAR Point Clouds using Graph Neural Networks
Feb 08, 2023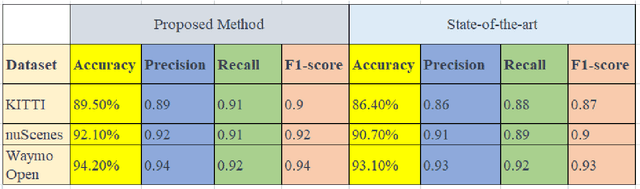
LiDAR (Light Detection and Ranging) is an advanced active remote sensing technique working on the principle of time of travel (ToT) for capturing highly accurate 3D information of the surroundings. LiDAR has gained wide attention in research and development with the LiDAR industry expected to reach 2.8 billion $ by 2025. Although the LiDAR dataset is of rich density and high spatial resolution, it is challenging to process LiDAR data due to its inherent 3D geometry and massive volume. But such a high-resolution dataset possesses immense potential in many applications and has great potential in 3D object detection and recognition. In this research we propose Graph Neural Network (GNN) based framework to learn and identify the objects in the 3D LiDAR point clouds. GNNs are class of deep learning which learns the patterns and objects based on the principle of graph learning which have shown success in various 3D computer vision tasks.
Learning How to Infer Partial MDPs for In-Context Adaptation and Exploration
Feb 08, 2023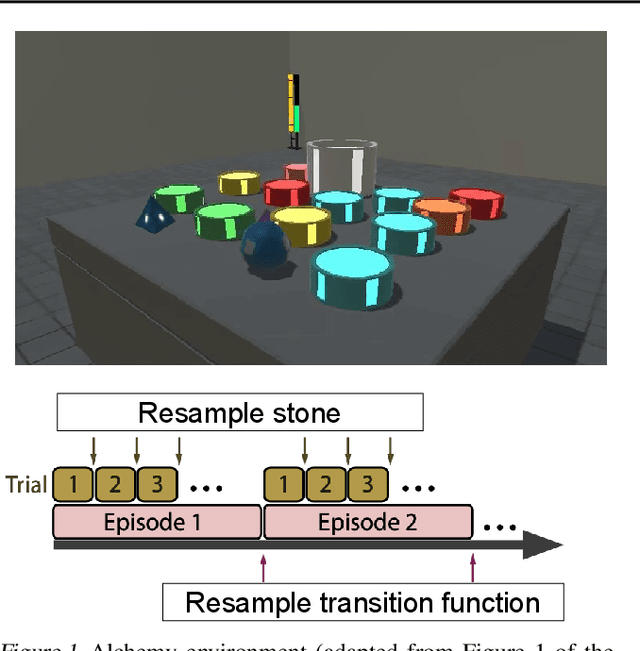
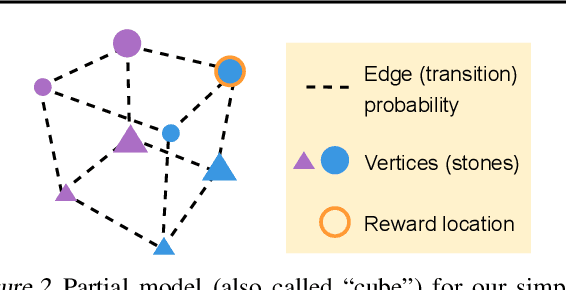

To generalize across tasks, an agent should acquire knowledge from past tasks that facilitate adaptation and exploration in future tasks. We focus on the problem of in-context adaptation and exploration, where an agent only relies on context, i.e., history of states, actions and/or rewards, rather than gradient-based updates. Posterior sampling (extension of Thompson sampling) is a promising approach, but it requires Bayesian inference and dynamic programming, which often involve unknowns (e.g., a prior) and costly computations. To address these difficulties, we use a transformer to learn an inference process from training tasks and consider a hypothesis space of partial models, represented as small Markov decision processes that are cheap for dynamic programming. In our version of the Symbolic Alchemy benchmark, our method's adaptation speed and exploration-exploitation balance approach those of an exact posterior sampling oracle. We also show that even though partial models exclude relevant information from the environment, they can nevertheless lead to good policies.
Channel Estimation for Reconfigurable Intelligent Surface with a few Active Elements
Feb 08, 2023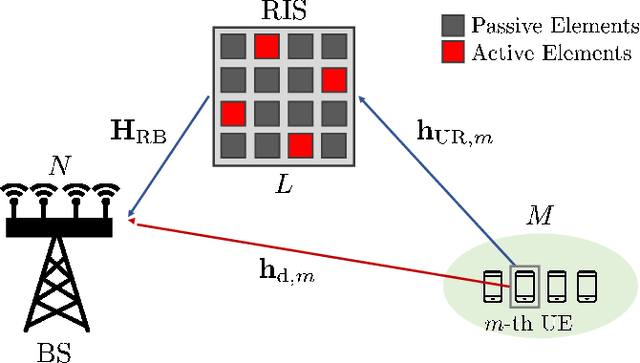
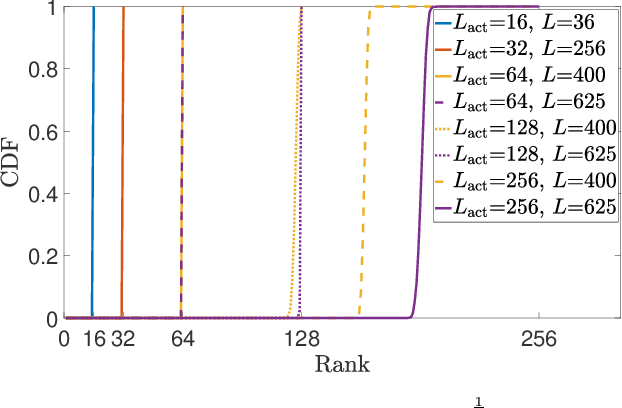
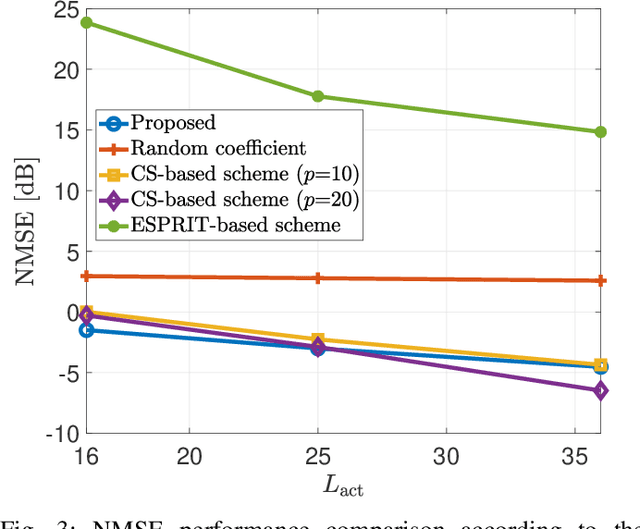
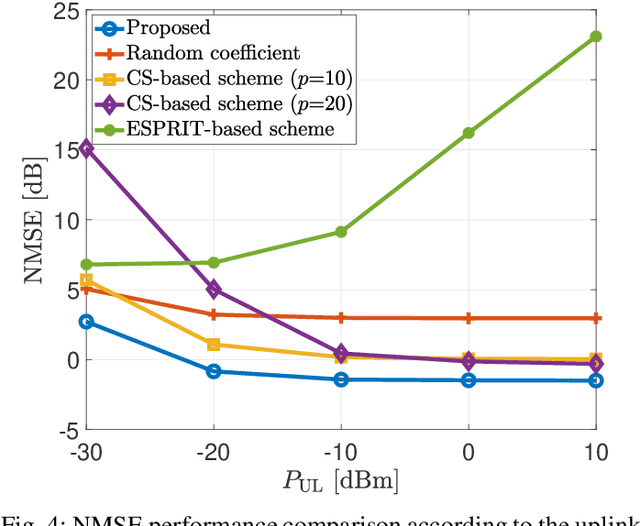
In this paper, a channel estimation technique for reconfigurable intelligent surface (RIS)-aided multi-user multiple-input single-output communication systems is proposed. By deploying a small number of active elements at the RIS, the RIS can receive and process the training signals. Through the partial channel state information (CSI) obtained from the active elements, the overall training overhead to estimate the entire channel can be dramatically reduced. To minimize the estimation complexity, the proposed technique is based on the linear combination of partial CSI, which only requires linear matrix operations. By exploiting the spatial correlation among the RIS elements, proper weights for the linear combination and normalization factors are developed. Numerical results show that the proposed technique outperforms other schemes using the active elements at the RIS in terms of the normalized mean squared error when the number of active elements is small, which is necessary to maintain the low cost and power consumption of RIS.
* Accepted to IEEE Transactions on Vehicular Technology