 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visual Privacy: Current and Emerging Regulations Around Unconsented Video Analytics in Retail
Feb 24, 2023
Video analytics is the practice of combining digital video data with machine learning models to infer various characteristics from that video. This capability has been used for years to detect objects, movement, and the number of customers in physical retail stores, but more complex machine learning models combined with more powerful computing power has unlocked new levels of possibility. Researchers claim it is now possible to infer a whole host of characteristics about an individual using video analytics, such as specific age, ethnicity, health status and emotional state. Moreover, an individuals visual identity can be augmented with information from other data providers to build out a detailed profile, all with the individual unknowingly contributing their physical presence in front of a retail store camera. Some retailers have begun to experiment with this new technology as a way to better know their customers. However, those same early adopters are caught in an evolving legal landscape around privacy and data ownership. This research looks into the current legal landscape and legislation currently in progress around the use of video analytics, specifically in the retail store setting. Because the ethical and legal norms around individualized video analytics are still heavily in flux, retailers are urged to adopt a wait and see approach or potentially incur costly legal expenses and risk damage to their brand.
SF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 28, 2023
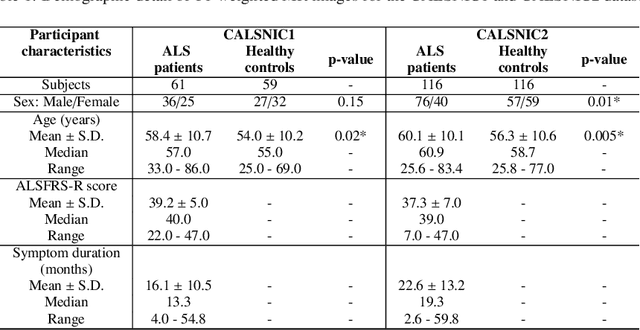
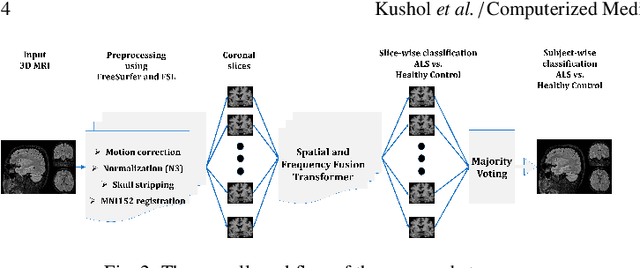
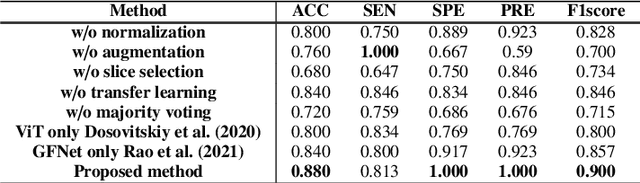
Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.
Capturing Global Structural Information in Long Document Question Answering with Compressive Graph Selector Network
Oct 11, 2022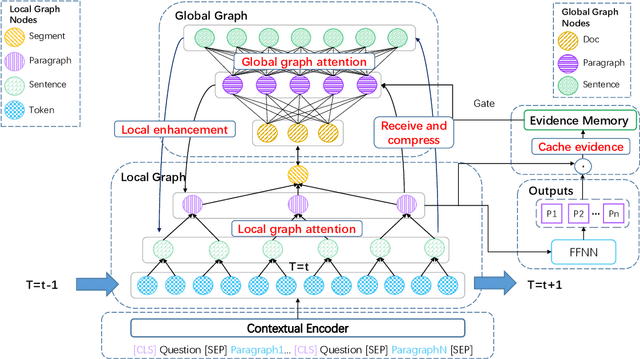
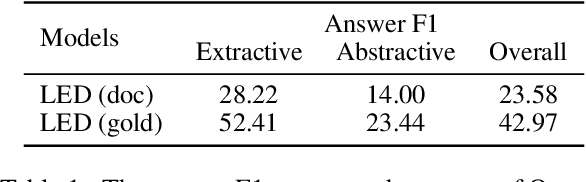
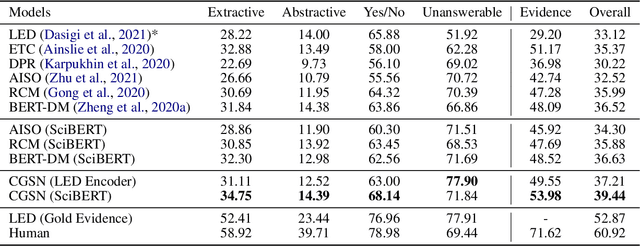
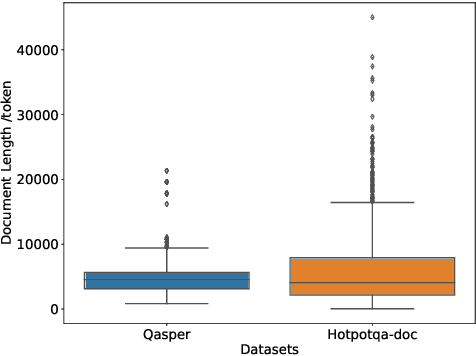
Long document question answering is a challenging task due to its demands for complex reasoning over long text. Previous works usually take long documents as non-structured flat texts or only consider the local structure in long documents. However, these methods usually ignore the global structure of the long document, which is essential for long-range understanding. To tackle this problem, we propose Compressive Graph Selector Network (CGSN) to capture the global structure in a compressive and iterative manner. Specifically, the proposed model consists of three modules: local graph network, global graph network and evidence memory network. Firstly, the local graph network builds the graph structure of the chunked segment in token, sentence, paragraph and segment levels to capture the short-term dependency of the text. Secondly, the global graph network selectively receives the information of each level from the local graph, compresses them into the global graph nodes and applies graph attention into the global graph nodes to build the long-range reasoning over the entire text in an iterative way. Thirdly, the evidence memory network is designed to alleviate the redundancy problem in the evidence selection via saving the selected result in the previous steps. Extensive experiments show that the proposed model outperforms previous methods on two datasets.
Layout-aware Webpage Quality Assessment
Feb 05, 2023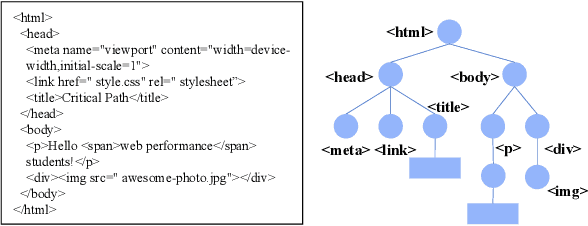
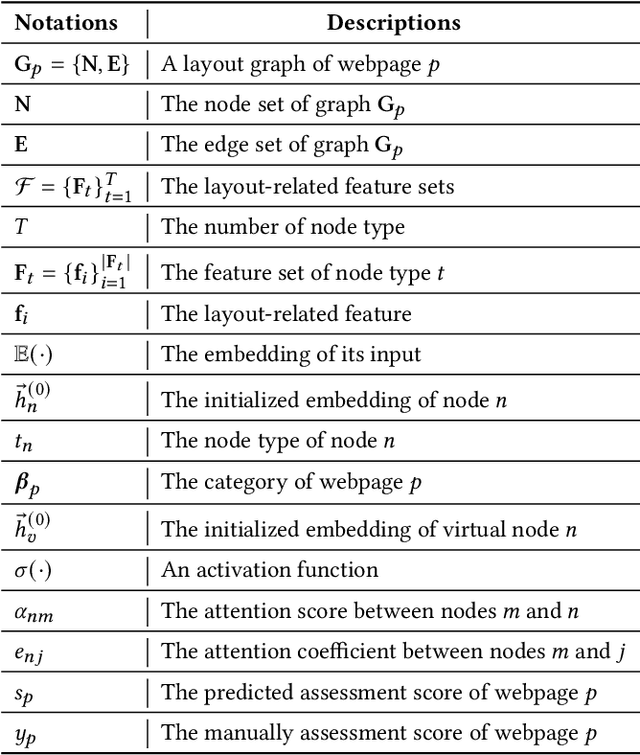

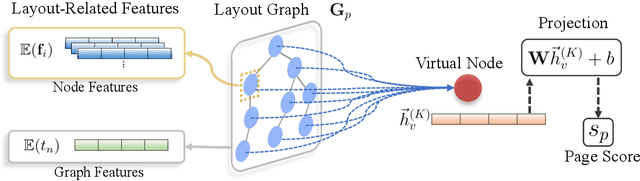
Identifying high-quality webpages is fundamental for real-world search engines, which can fulfil users' information need with the less cognitive burden. Early studies of \emph{webpage quality assessment} usually design hand-crafted features that may only work on particular categories of webpages (e.g., shopping websites, medical websites). They can hardly be applied to real-world search engines that serve trillions of webpages with various types and purposes. In this paper, we propose a novel layout-aware webpage quality assessment model currently deployed in our search engine. Intuitively, layout is a universal and critical dimension for the quality assessment of different categories of webpages. Based on this, we directly employ the meta-data that describes a webpage, i.e., Document Object Model (DOM) tree, as the input of our model. The DOM tree data unifies the representation of webpages with different categories and purposes and indicates the layout of webpages. To assess webpage quality from complex DOM tree data, we propose a graph neural network (GNN) based method that extracts rich layout-aware information that implies webpage quality in an end-to-end manner. Moreover, we improve the GNN method with an attentive readout function, external web categories and a category-aware sampling method. We conduct rigorous offline and online experiments to show that our proposed solution is effective in real search engines, improving the overall usability and user experience.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 01, 2023
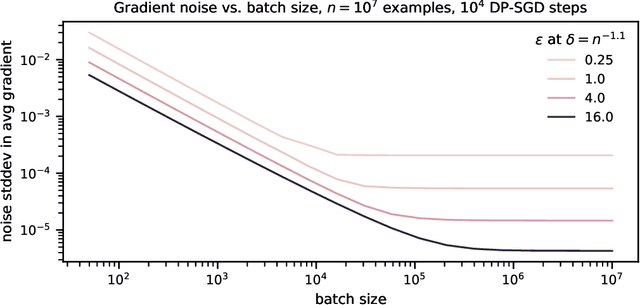

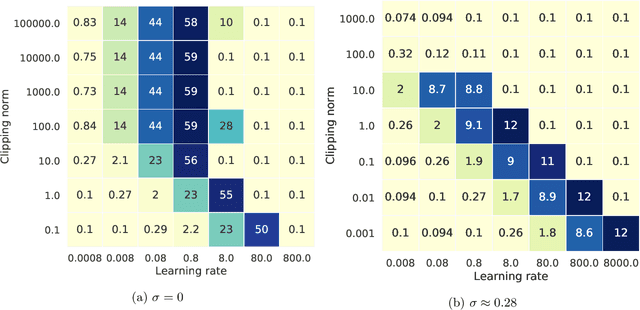
ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are ``safe'' to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
Collage Diffusion
Mar 01, 2023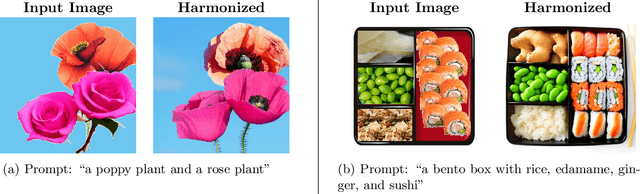
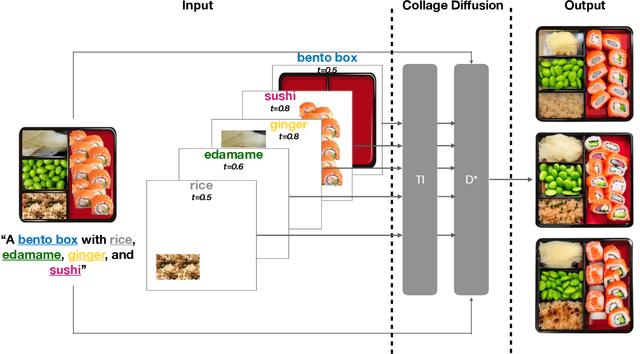
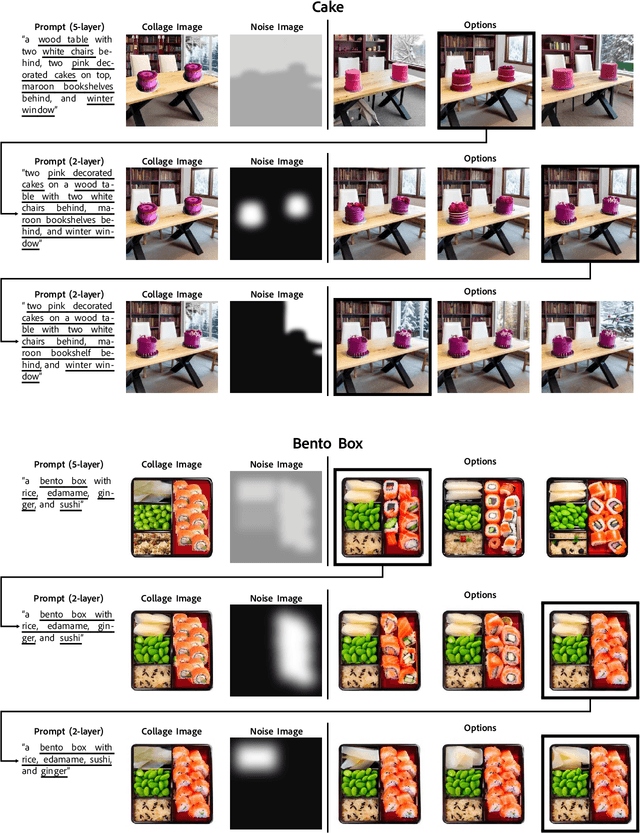

Text-conditional diffusion models generate high-quality, diverse images. However, text is often an ambiguous specification for a desired target image, creating the need for additional user-friendly controls for diffusion-based image generation. We focus on having precise control over image output for scenes with several objects. Users control image generation by defining a collage: a text prompt paired with an ordered sequence of layers, where each layer is an RGBA image and a corresponding text prompt. We introduce Collage Diffusion, a collage-conditional diffusion algorithm that allows users to control both the spatial arrangement and visual attributes of objects in the scene, and also enables users to edit individual components of generated images. To ensure that different parts of the input text correspond to the various locations specified in the input collage layers, Collage Diffusion modifies text-image cross-attention with the layers' alpha masks. To maintain characteristics of individual collage layers that are not specified in text, Collage Diffusion learns specialized text representations per layer. Collage input also enables layer-based controls that provide fine-grained control over the final output: users can control image harmonization on a layer-by-layer basis, and they can edit individual objects in generated images while keeping other objects fixed. Collage-conditional image generation requires harmonizing the input collage to make objects fit together--the key challenge involves minimizing changes in the positions and key visual attributes of objects in the input collage while allowing other attributes of the collage to change in the harmonization process. By leveraging the rich information present in layer input, Collage Diffusion generates globally harmonized images that maintain desired object locations and visual characteristics better than prior approaches.
DMMG: Dual Min-Max Games for Self-Supervised Skeleton-Based Action Recognition
Feb 22, 2023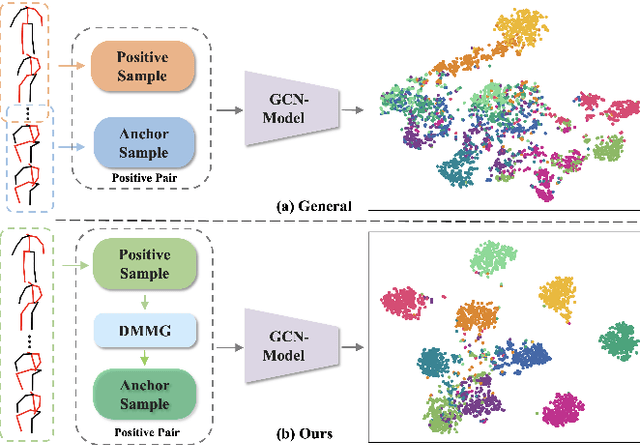
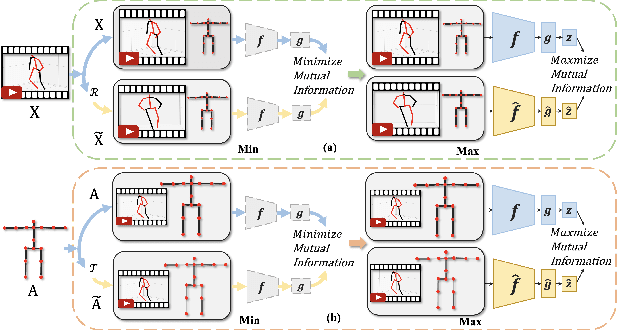
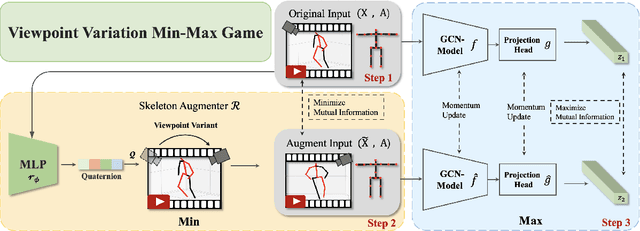

In this work, we propose a new Dual Min-Max Games (DMMG) based self-supervised skeleton action recognition method by augmenting unlabeled data in a contrastive learning framework. Our DMMG consists of a viewpoint variation min-max game and an edge perturbation min-max game. These two min-max games adopt an adversarial paradigm to perform data augmentation on the skeleton sequences and graph-structured body joints, respectively. Our viewpoint variation min-max game focuses on constructing various hard contrastive pairs by generating skeleton sequences from various viewpoints. These hard contrastive pairs help our model learn representative action features, thus facilitating model transfer to downstream tasks. Moreover, our edge perturbation min-max game specializes in building diverse hard contrastive samples through perturbing connectivity strength among graph-based body joints. The connectivity-strength varying contrastive pairs enable the model to capture minimal sufficient information of different actions, such as representative gestures for an action while preventing the model from overfitting. By fully exploiting the proposed DMMG, we can generate sufficient challenging contrastive pairs and thus achieve discriminative action feature representations from unlabeled skeleton data in a self-supervised manner. Extensive experiments demonstrate that our method achieves superior results under various evaluation protocols on widely-used NTU-RGB+D and NTU120-RGB+D datasets.
Distilling Calibrated Student from an Uncalibrated Teacher
Feb 22, 2023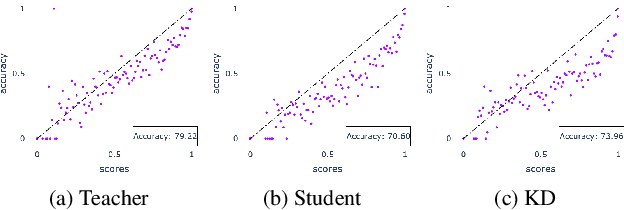
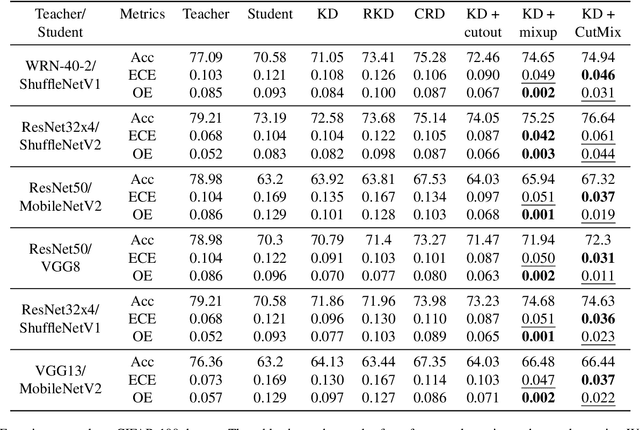
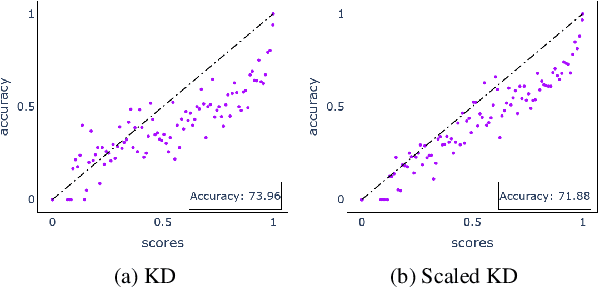
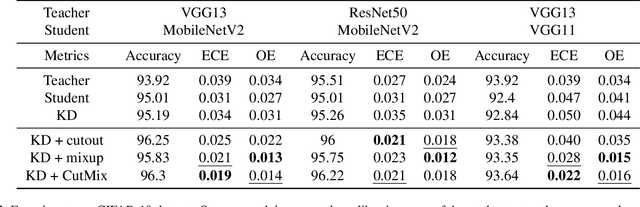
Knowledge distillation is a common technique for improving the performance of a shallow student network by transferring information from a teacher network, which in general, is comparatively large and deep. These teacher networks are pre-trained and often uncalibrated, as no calibration technique is applied to the teacher model while training. Calibration of a network measures the probability of correctness for any of its predictions, which is critical in high-risk domains. In this paper, we study how to obtain a calibrated student from an uncalibrated teacher. Our approach relies on the fusion of the data-augmentation techniques, including but not limited to cutout, mixup, and CutMix, with knowledge distillation. We extend our approach beyond traditional knowledge distillation and find it suitable for Relational Knowledge Distillation and Contrastive Representation Distillation as well. The novelty of the work is that it provides a framework to distill a calibrated student from an uncalibrated teacher model without compromising the accuracy of the distilled student. We perform extensive experiments to validate our approach on various datasets, including CIFAR-10, CIFAR-100, CINIC-10 and TinyImageNet, and obtained calibrated student models. We also observe robust performance of our approach while evaluating it on corrupted CIFAR-100C data.
Federated Radio Frequency Fingerprinting with Model Transfer and Adaptation
Feb 22, 2023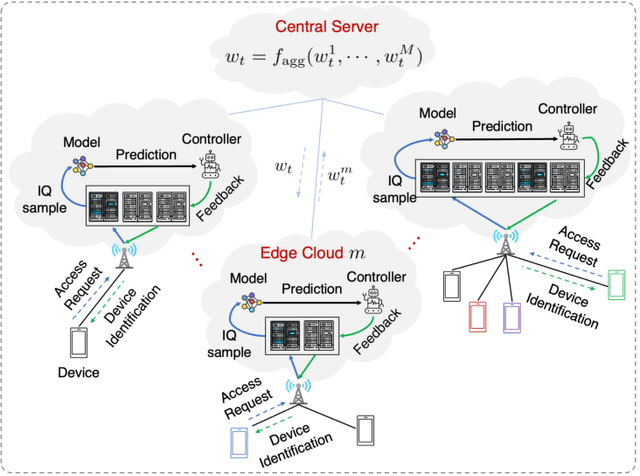
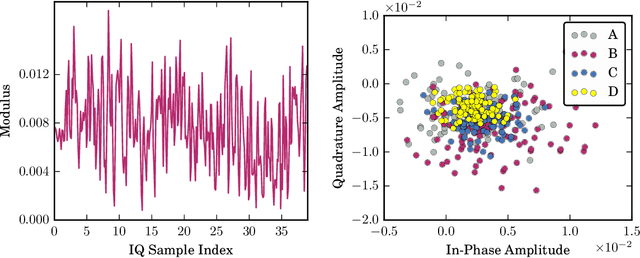
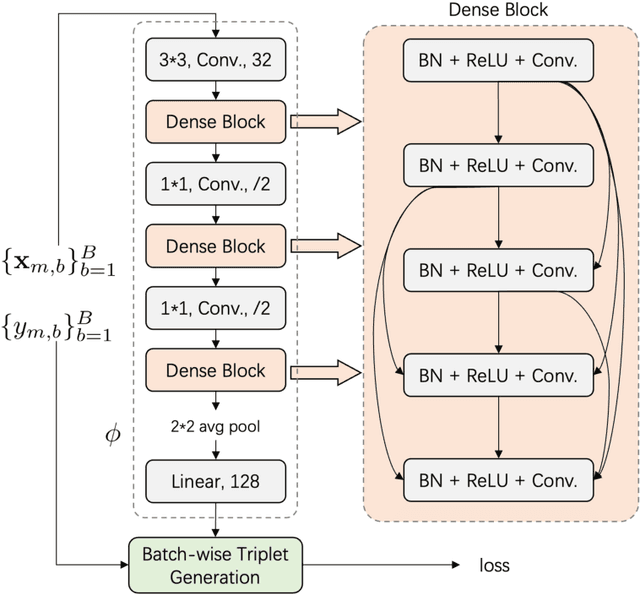
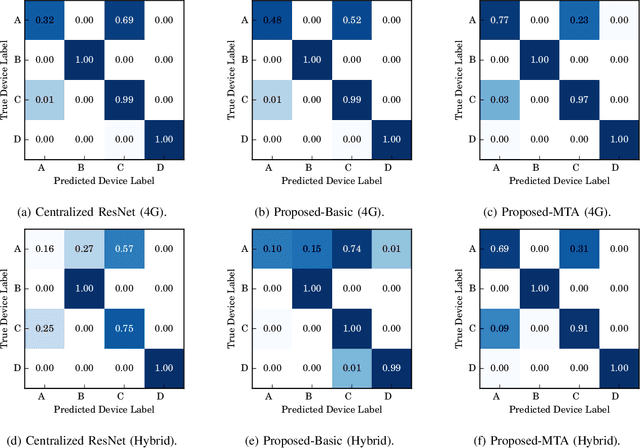
The Radio frequency (RF) fingerprinting technique makes highly secure device authentication possible for future networks by exploiting hardware imperfections introduced during manufacturing. Although this technique has received considerable attention over the past few years, RF fingerprinting still faces great challenges of channel-variation-induced data distribution drifts between the training phase and the test phase. To address this fundamental challenge and support model training and testing at the edge, we propose a federated RF fingerprinting algorithm with a novel strategy called model transfer and adaptation (MTA). The proposed algorithm introduces dense connectivity among convolutional layers into RF fingerprinting to enhance learning accuracy and reduce model complexity. Besides, we implement the proposed algorithm in the context of federated learning, making our algorithm communication efficient and privacy-preserved. To further conquer the data mismatch challenge, we transfer the learned model from one channel condition and adapt it to other channel conditions with only a limited amount of information, leading to highly accurate predictions under environmental drifts. Experimental results on real-world datasets demonstrate that the proposed algorithm is model-agnostic and also signal-irrelevant. Compared with state-of-the-art RF fingerprinting algorithms, our algorithm can improve prediction performance considerably with a performance gain of up to 15\%.
Structure Embedded Nucleus Classification for Histopathology Images
Feb 22, 2023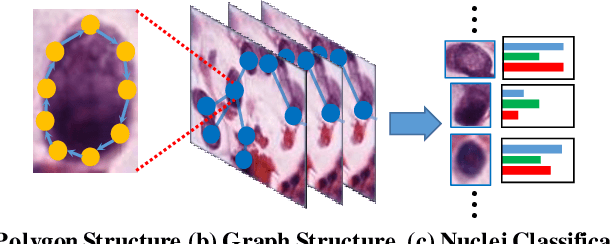
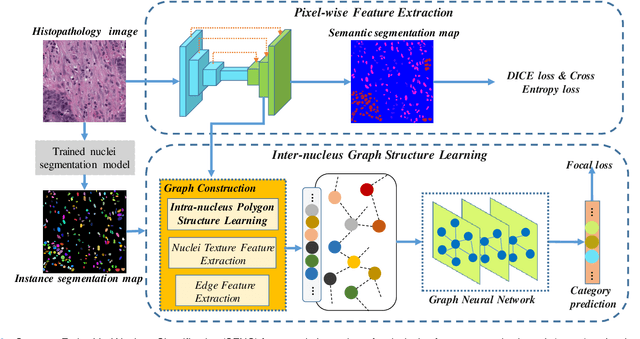
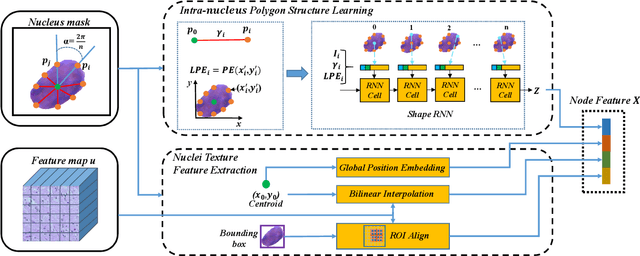
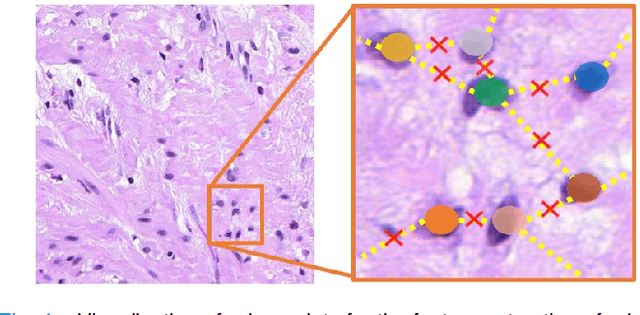
Nuclei classification provides valuable information for histopathology image analysis. However, the large variations in the appearance of different nuclei types cause difficulties in identifying nuclei. Most neural network based methods are affected by the local receptive field of convolutions, and pay less attention to the spatial distribution of nuclei or the irregular contour shape of a nucleus. In this paper, we first propose a novel polygon-structure feature learning mechanism that transforms a nucleus contour into a sequence of points sampled in order, and employ a recurrent neural network that aggregates the sequential change in distance between key points to obtain learnable shape features. Next, we convert a histopathology image into a graph structure with nuclei as nodes, and build a graph neural network to embed the spatial distribution of nuclei into their representations. To capture the correlations between the categories of nuclei and their surrounding tissue patterns, we further introduce edge features that are defined as the background textures between adjacent nuclei. Lastly, we integrate both polygon and graph structure learning mechanisms into a whole framework that can extract intra and inter-nucleus structural characteristics for nuclei classification. Experimental results show that the proposed framework achieves significant improvements compared to the state-of-the-art methods.