 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How to Understand Named Entities: Using Common Sense for News Captioning
Mar 11, 2024

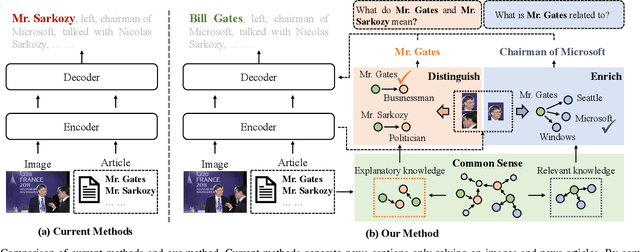
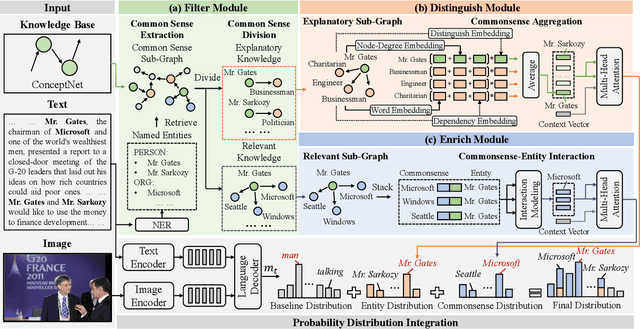
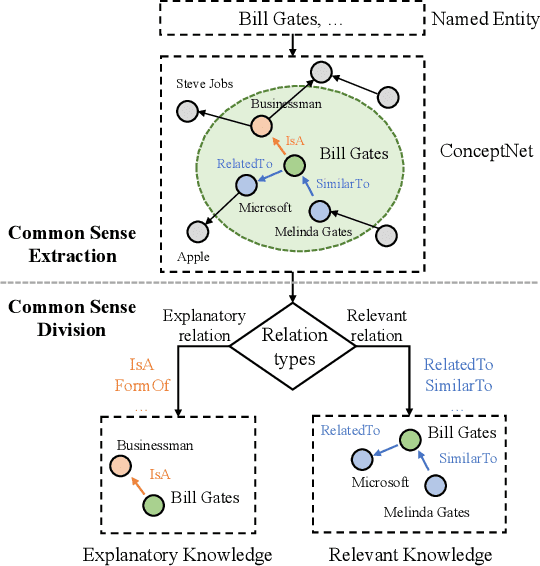
News captioning aims to describe an image with its news article body as input. It greatly relies on a set of detected named entities, including real-world people, organizations, and places. This paper exploits commonsense knowledge to understand named entities for news captioning. By ``understand'', we mean correlating the news content with common sense in the wild, which helps an agent to 1) distinguish semantically similar named entities and 2) describe named entities using words outside of training corpora. Our approach consists of three modules: (a) Filter Module aims to clarify the common sense concerning a named entity from two aspects: what does it mean? and what is it related to?, which divide the common sense into explanatory knowledge and relevant knowledge, respectively. (b) Distinguish Module aggregates explanatory knowledge from node-degree, dependency, and distinguish three aspects to distinguish semantically similar named entities. (c) Enrich Module attaches relevant knowledge to named entities to enrich the entity description by commonsense information (e.g., identity and social position). Finally, the probability distributions from both modules are integrated to generate the news captions. Extensive experiments on two challenging datasets (i.e., GoodNews and NYTimes) demonstrate the superiority of our method. Ablation studies and visualization further validate its effectiveness in understanding named entities.
BiVRec: Bidirectional View-based Multimodal Sequential Recommendation
Mar 05, 2024The integration of multimodal information into sequential recommender systems has attracted significant attention in recent research. In the initial stages of multimodal sequential recommendation models, the mainstream paradigm was ID-dominant recommendations, wherein multimodal information was fused as side information. However, due to their limitations in terms of transferability and information intrusion, another paradigm emerged, wherein multimodal features were employed directly for recommendation, enabling recommendation across datasets. Nonetheless, it overlooked user ID information, resulting in low information utilization and high training costs. To this end, we propose an innovative framework, BivRec, that jointly trains the recommendation tasks in both ID and multimodal views, leveraging their synergistic relationship to enhance recommendation performance bidirectionally. To tackle the information heterogeneity issue, we first construct structured user interest representations and then learn the synergistic relationship between them. Specifically, BivRec comprises three modules: Multi-scale Interest Embedding, comprehensively modeling user interests by expanding user interaction sequences with multi-scale patching; Intra-View Interest Decomposition, constructing highly structured interest representations using carefully designed Gaussian attention and Cluster attention; and Cross-View Interest Learning, learning the synergistic relationship between the two recommendation views through coarse-grained overall semantic similarity and fine-grained interest allocation similarity BiVRec achieves state-of-the-art performance on five datasets and showcases various practical advantages.
Robust Semantic Communications for Speech-to-Text Translation
Mar 08, 2024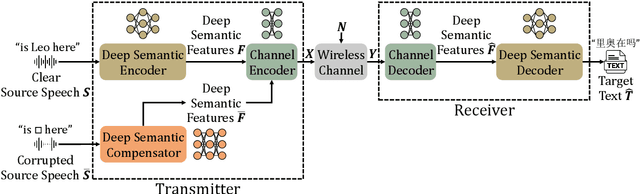
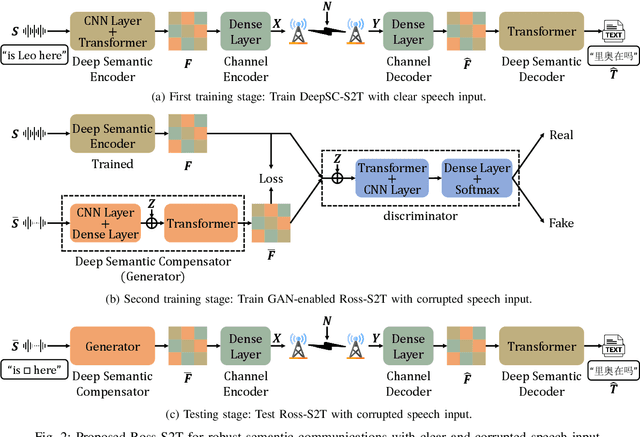
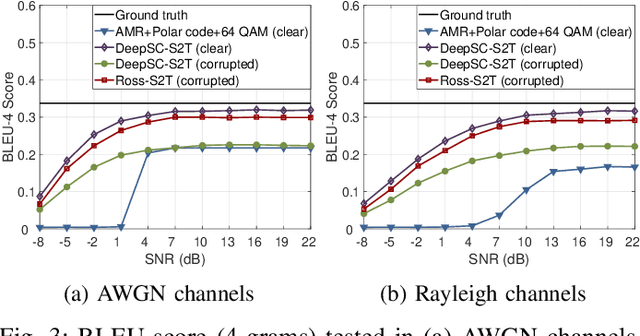
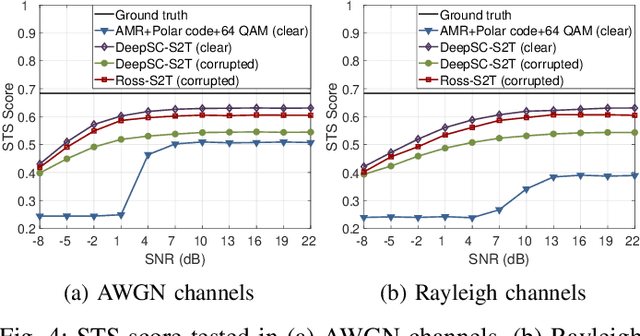
In this paper, we propose a robust semantic communication system to achieve the speech-to-text translation task, named Ross-S2T, by delivering the essential semantic information. Particularly, a deep semantic encoder is developed to directly condense and convert the speech in the source language to the textual semantic features associated with the target language, thus encouraging the design of a deep learning-enabled semantic communication system for speech-to-text translation that can be jointly trained in an end-to-end manner. Moreover, to cope with the practical communication scenario when the input speech is corrupted, a novel generative adversarial network (GAN)-enabled deep semantic compensator is proposed to predict the lost semantic information in the source speech and produce the textual semantic features in the target language simultaneously, which establishes a robust semantic transmission mechanism for dynamic speech input. According to the simulation results, the proposed Ross-S2T achieves significant speech-to-text translation performance compared to the conventional approach and exhibits high robustness against the corrupted speech input.
Face2Diffusion for Fast and Editable Face Personalization
Mar 08, 2024
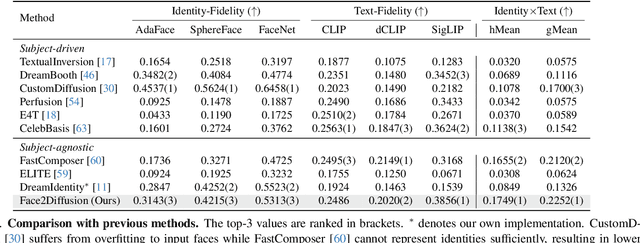


Face personalization aims to insert specific faces, taken from images, into pretrained text-to-image diffusion models. However, it is still challenging for previous methods to preserve both the identity similarity and editability due to overfitting to training samples. In this paper, we propose Face2Diffusion (F2D) for high-editability face personalization. The core idea behind F2D is that removing identity-irrelevant information from the training pipeline prevents the overfitting problem and improves editability of encoded faces. F2D consists of the following three novel components: 1) Multi-scale identity encoder provides well-disentangled identity features while keeping the benefits of multi-scale information, which improves the diversity of camera poses. 2) Expression guidance disentangles face expressions from identities and improves the controllability of face expressions. 3) Class-guided denoising regularization encourages models to learn how faces should be denoised, which boosts the text-alignment of backgrounds. Extensive experiments on the FaceForensics++ dataset and diverse prompts demonstrate our method greatly improves the trade-off between the identity- and text-fidelity compared to previous state-of-the-art methods.
3D Face Reconstruction Using A Spectral-Based Graph Convolution Encoder
Mar 08, 2024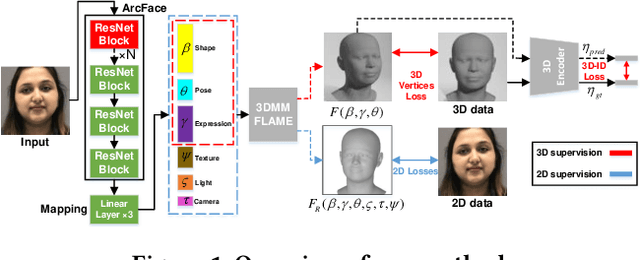
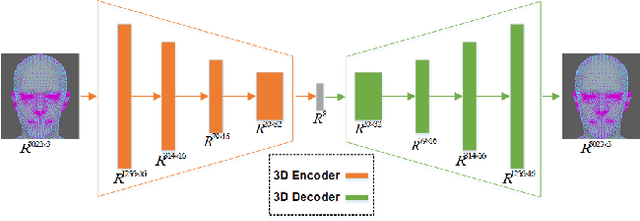
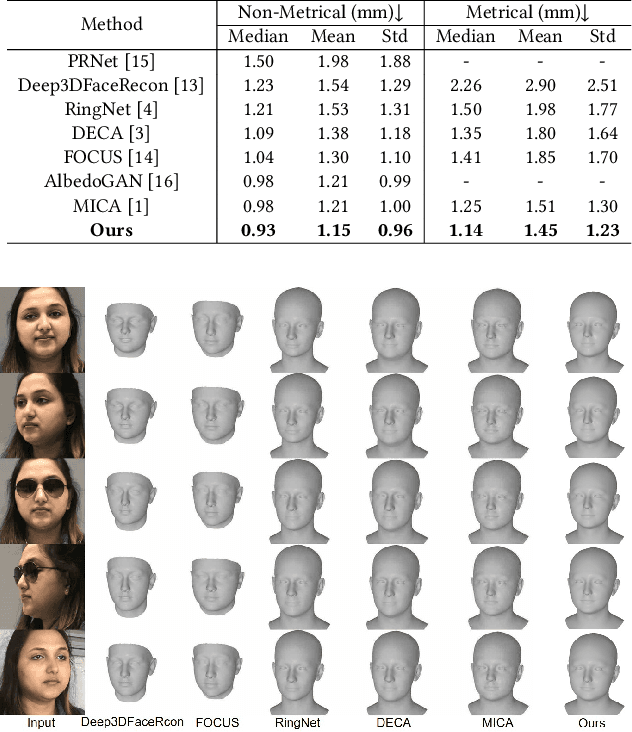
Monocular 3D face reconstruction plays a crucial role in avatar generation, with significant demand in web-related applications such as generating virtual financial advisors in FinTech. Current reconstruction methods predominantly rely on deep learning techniques and employ 2D self-supervision as a means to guide model learning. However, these methods encounter challenges in capturing the comprehensive 3D structural information of the face due to the utilization of 2D images for model training purposes. To overcome this limitation and enhance the reconstruction of 3D structural features, we propose an innovative approach that integrates existing 2D features with 3D features to guide the model learning process. Specifically, we introduce the 3D-ID Loss, which leverages the high-dimensional structure features extracted from a Spectral-Based Graph Convolution Encoder applied to the facial mesh. This approach surpasses the sole reliance on the 3D information provided by the facial mesh vertices coordinates. Our model is trained using 2D-3D data pairs from a combination of datasets and achieves state-of-the-art performance on the NoW benchmark.
Degradation Resilient LiDAR-Radar-Inertial Odometry
Mar 08, 2024
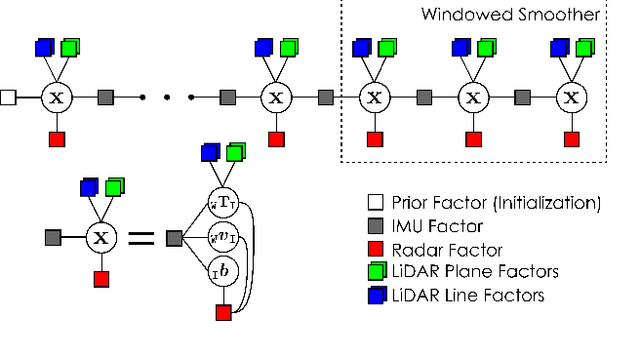
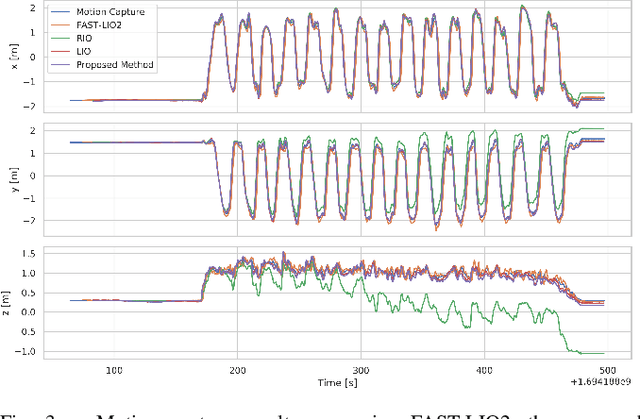

Enabling autonomous robots to operate robustly in challenging environments is necessary in a future with increased autonomy. For many autonomous systems, estimation and odometry remains a single point of failure, from which it can often be difficult, if not impossible, to recover. As such robust odometry solutions are of key importance. In this work a method for tightly-coupled LiDAR-Radar-Inertial fusion for odometry is proposed, enabling the mitigation of the effects of LiDAR degeneracy by leveraging a complementary perception modality while preserving the accuracy of LiDAR in well-conditioned environments. The proposed approach combines modalities in a factor graph-based windowed smoother with sensor information-specific factor formulations which enable, in the case of degeneracy, partial information to be conveyed to the graph along the non-degenerate axes. The proposed method is evaluated in real-world tests on a flying robot experiencing degraded conditions including geometric self-similarity as well as obscurant occlusion. For the benefit of the community we release the datasets presented: https://github.com/ntnu-arl/lidar_degeneracy_datasets.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 10, 2024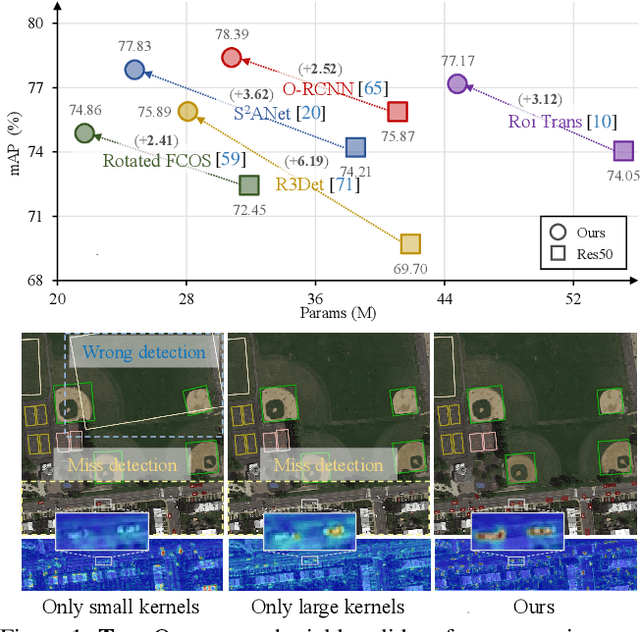
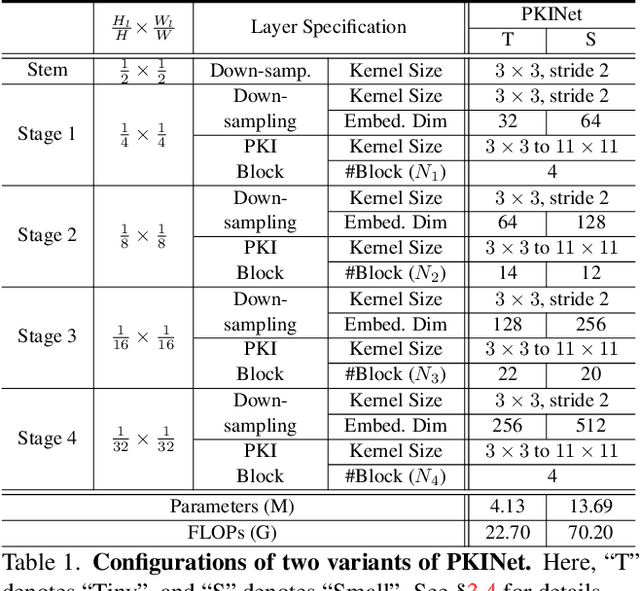
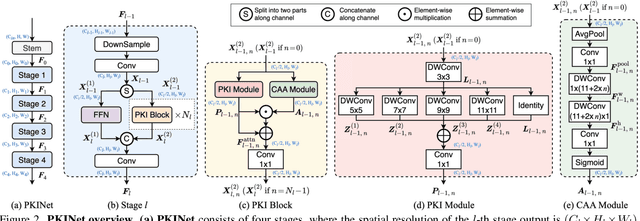
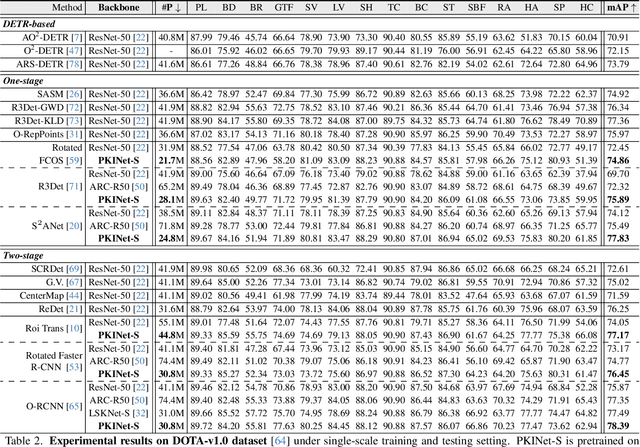
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
Ensemble Quadratic Assignment Network for Graph Matching
Mar 11, 2024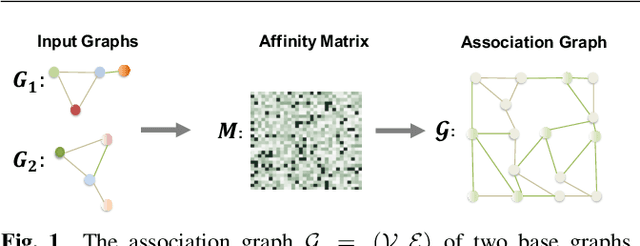

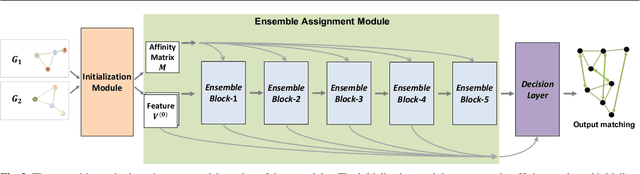
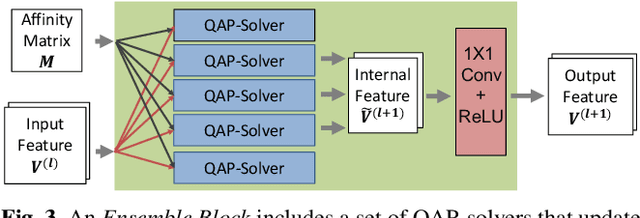
Graph matching is a commonly used technique in computer vision and pattern recognition. Recent data-driven approaches have improved the graph matching accuracy remarkably, whereas some traditional algorithm-based methods are more robust to feature noises, outlier nodes, and global transformation (e.g.~rotation). In this paper, we propose a graph neural network (GNN) based approach to combine the advantages of data-driven and traditional methods. In the GNN framework, we transform traditional graph-matching solvers as single-channel GNNs on the association graph and extend the single-channel architecture to the multi-channel network. The proposed model can be seen as an ensemble method that fuses multiple algorithms at every iteration. Instead of averaging the estimates at the end of the ensemble, in our approach, the independent iterations of the ensembled algorithms exchange their information after each iteration via a 1x1 channel-wise convolution layer. Experiments show that our model improves the performance of traditional algorithms significantly. In addition, we propose a random sampling strategy to reduce the computational complexity and GPU memory usage, so the model applies to matching graphs with thousands of nodes. We evaluate the performance of our method on three tasks: geometric graph matching, semantic feature matching, and few-shot 3D shape classification. The proposed model performs comparably or outperforms the best existing GNN-based methods.
FocusCLIP: Multimodal Subject-Level Guidance for Zero-Shot Transfer in Human-Centric Tasks
Mar 11, 2024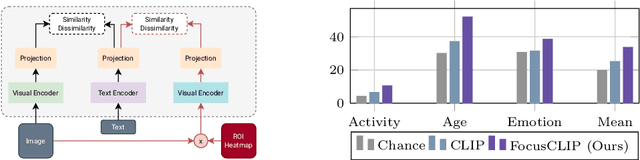
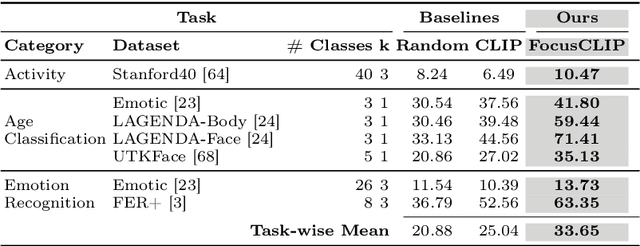
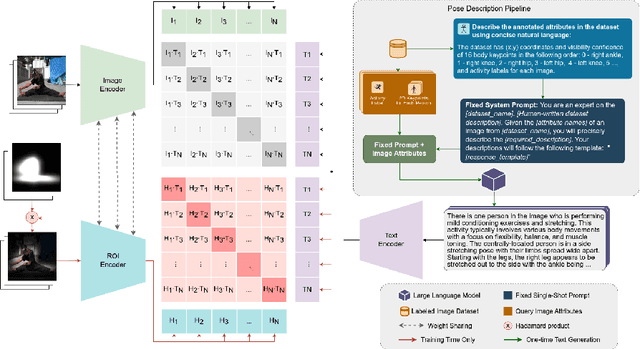
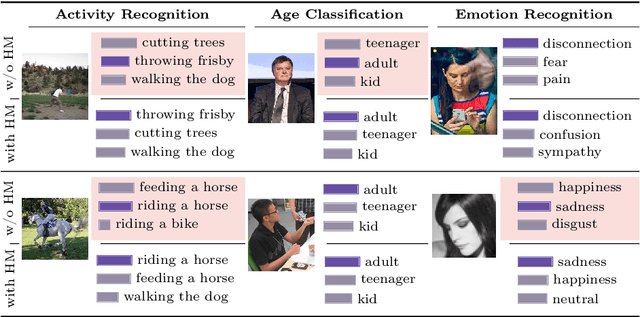
We propose FocusCLIP, integrating subject-level guidance--a specialized mechanism for target-specific supervision--into the CLIP framework for improved zero-shot transfer on human-centric tasks. Our novel contributions enhance CLIP on both the vision and text sides. On the vision side, we incorporate ROI heatmaps emulating human visual attention mechanisms to emphasize subject-relevant image regions. On the text side, we introduce human pose descriptions to provide rich contextual information. For human-centric tasks, FocusCLIP is trained with images from the MPII Human Pose dataset. The proposed approach surpassed CLIP by an average of 8.61% across five previously unseen datasets covering three human-centric tasks. FocusCLIP achieved an average accuracy of 33.65% compared to 25.04% by CLIP. We observed a 3.98% improvement in activity recognition, a 14.78% improvement in age classification, and a 7.06% improvement in emotion recognition. Moreover, using our proposed single-shot LLM prompting strategy, we release a high-quality MPII Pose Descriptions dataset to encourage further research in multimodal learning for human-centric tasks. Furthermore, we also demonstrate the effectiveness of our subject-level supervision on non-human-centric tasks. FocusCLIP shows a 2.47% improvement over CLIP in zero-shot bird classification using the CUB dataset. Our findings emphasize the potential of integrating subject-level guidance with general pretraining methods for enhanced downstream performance.
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Mar 11, 2024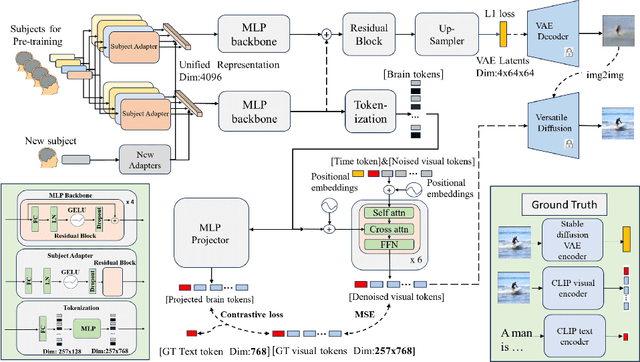
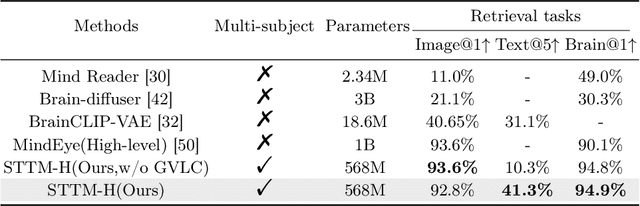

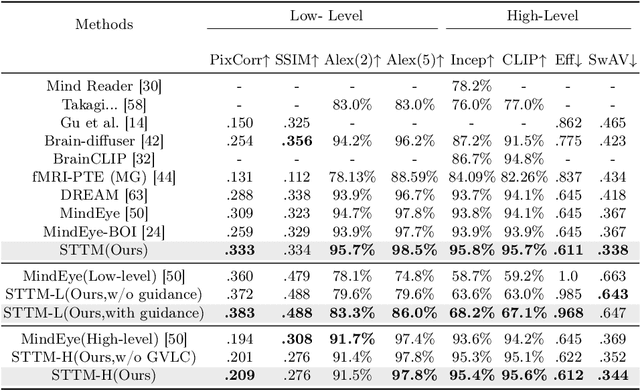
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.