 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023
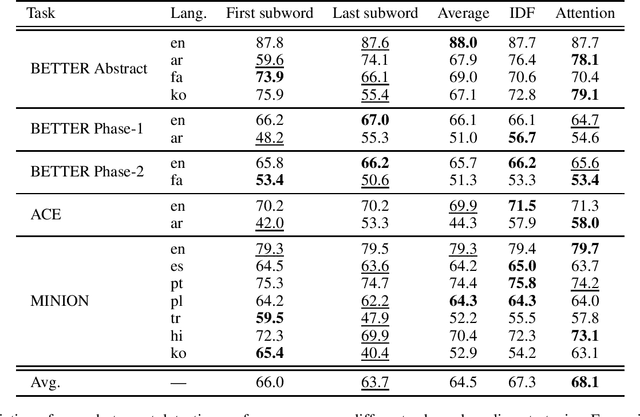
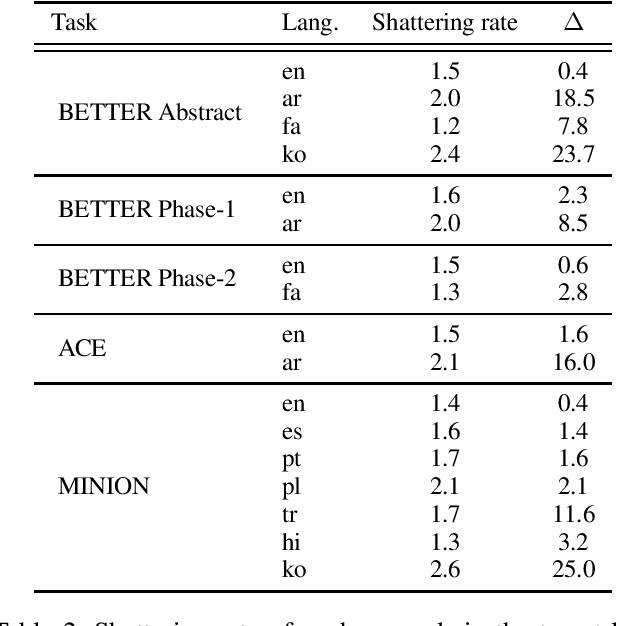


Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.
Saliency Guided Contrastive Learning on Scene Images
Feb 23, 2023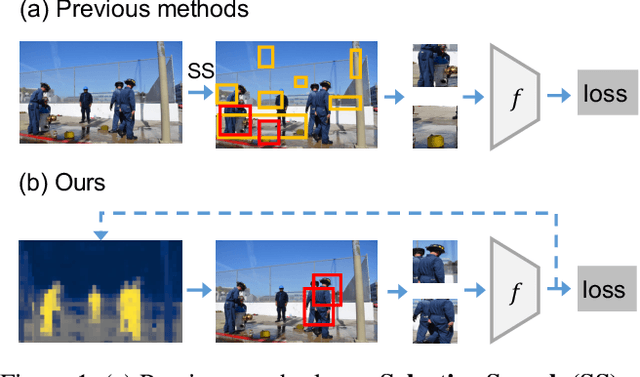
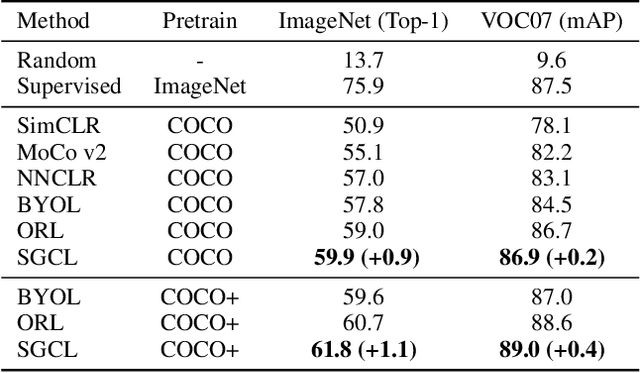
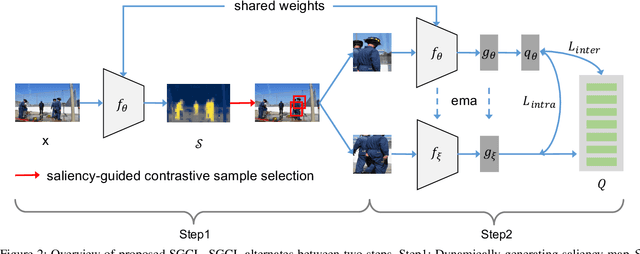
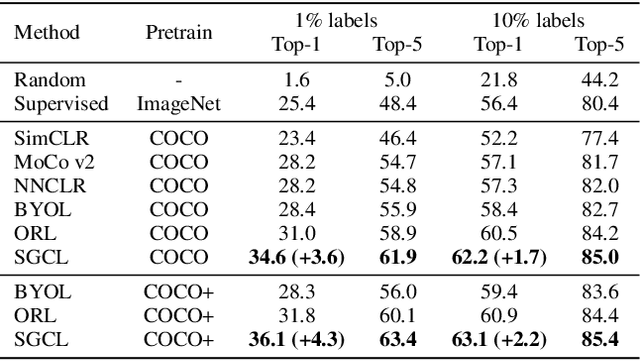
Self-supervised learning holds promise in leveraging large numbers of unlabeled data. However, its success heavily relies on the highly-curated dataset, e.g., ImageNet, which still needs human cleaning. Directly learning representations from less-curated scene images is essential for pushing self-supervised learning to a higher level. Different from curated images which include simple and clear semantic information, scene images are more complex and mosaic because they often include complex scenes and multiple objects. Despite being feasible, recent works largely overlooked discovering the most discriminative regions for contrastive learning to object representations in scene images. In this work, we leverage the saliency map derived from the model's output during learning to highlight these discriminative regions and guide the whole contrastive learning. Specifically, the saliency map first guides the method to crop its discriminative regions as positive pairs and then reweighs the contrastive losses among different crops by its saliency scores. Our method significantly improves the performance of self-supervised learning on scene images by +1.1, +4.3, +2.2 Top1 accuracy in ImageNet linear evaluation, Semi-supervised learning with 1% and 10% ImageNet labels, respectively. We hope our insights on saliency maps can motivate future research on more general-purpose unsupervised representation learning from scene data.
Detecting Signs of Model Change with Continuous Model Selection Based on Descriptive Dimensionality
Feb 23, 2023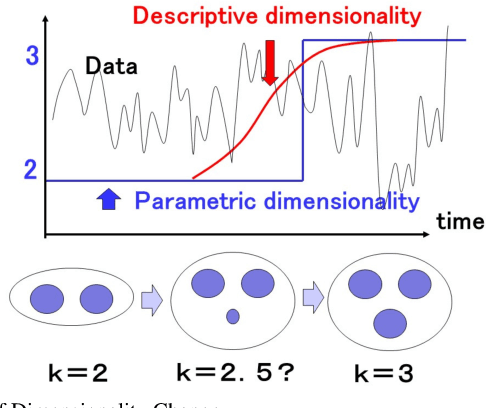
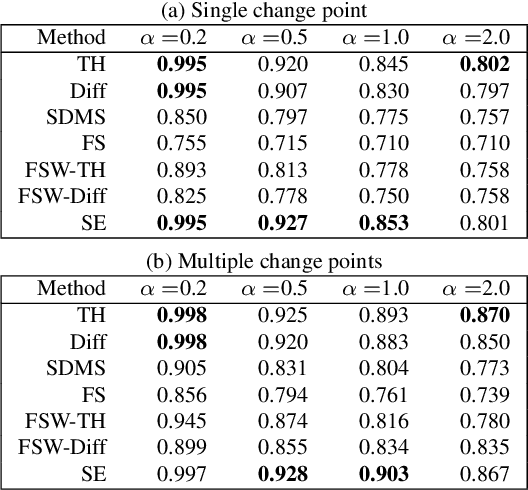
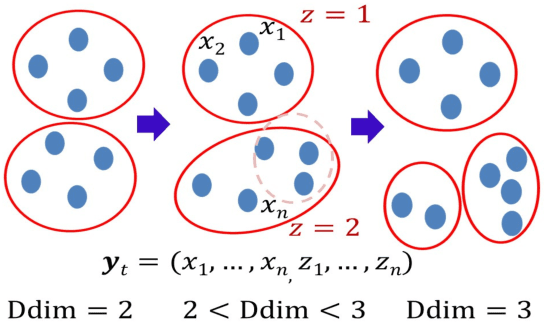
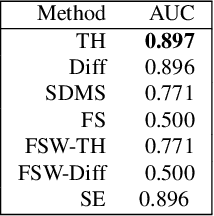
We address the issue of detecting changes of models that lie behind a data stream. The model refers to an integer-valued structural information such as the number of free parameters in a parametric model. Specifically we are concerned with the problem of how we can detect signs of model changes earlier than they are actualized. To this end, we employ {\em continuous model selection} on the basis of the notion of {\em descriptive dimensionality}~(Ddim). It is a real-valued model dimensionality, which is designed for quantifying the model dimensionality in the model transition period. Continuous model selection is to determine the real-valued model dimensionality in terms of Ddim from a given data. We propose a novel methodology for detecting signs of model changes by tracking the rise-up of Ddim in a data stream. We apply this methodology to detecting signs of changes of the number of clusters in a Gaussian mixture model and those of the order in an auto regression model. With synthetic and real data sets, we empirically demonstrate its effectiveness by showing that it is able to visualize well how rapidly model dimensionality moves in the transition period and to raise early warning signals of model changes earlier than they are detected with existing methods.
FTM: A Frame-level Timeline Modeling Method for Temporal Graph Representation Learning
Feb 23, 2023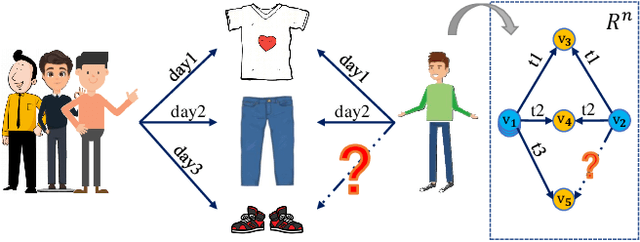
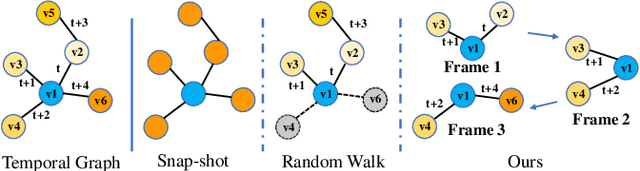

Learning representations for graph-structured data is essential for graph analytical tasks. While remarkable progress has been made on static graphs, researches on temporal graphs are still in its beginning stage. The bottleneck of the temporal graph representation learning approach is the neighborhood aggregation strategy, based on which graph attributes share and gather information explicitly. Existing neighborhood aggregation strategies fail to capture either the short-term features or the long-term features of temporal graph attributes, leading to unsatisfactory model performance and even poor robustness and domain generality of the representation learning method. To address this problem, we propose a Frame-level Timeline Modeling (FTM) method that helps to capture both short-term and long-term features and thus learns more informative representations on temporal graphs. In particular, we present a novel link-based framing technique to preserve the short-term features and then incorporate a timeline aggregator module to capture the intrinsic dynamics of graph evolution as long-term features. Our method can be easily assembled with most temporal GNNs. Extensive experiments on common datasets show that our method brings great improvements to the capability, robustness, and domain generality of backbone methods in downstream tasks. Our code can be found at https://github.com/yeeeqichen/FTM.
MDF-Net: Multimodal Dual-Fusion Network for Abnormality Detection using CXR Images and Clinical Data
Feb 26, 2023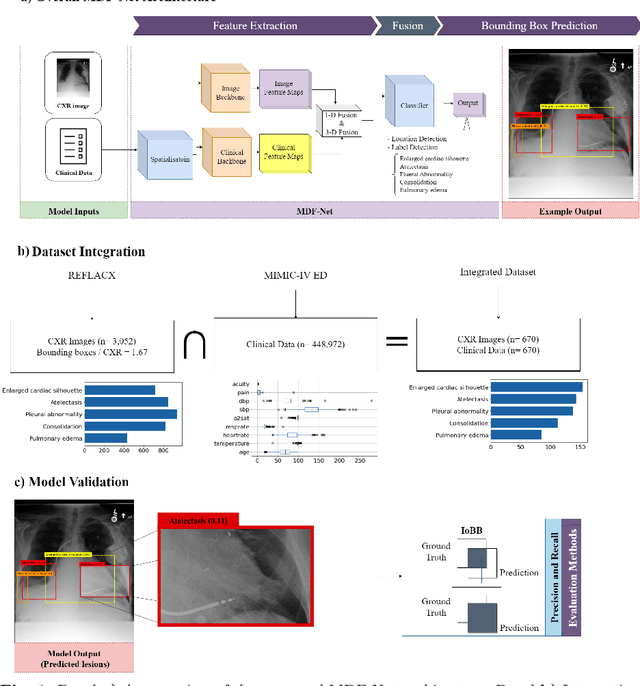
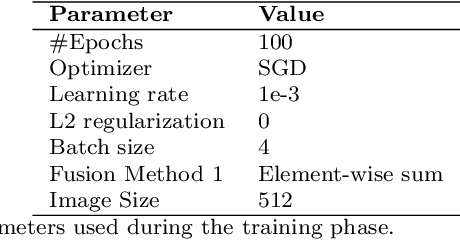
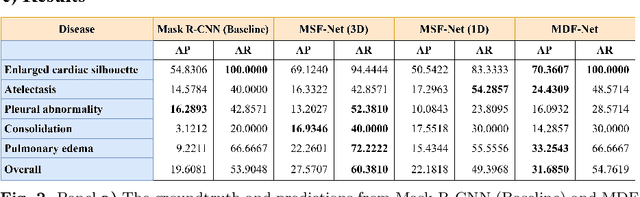
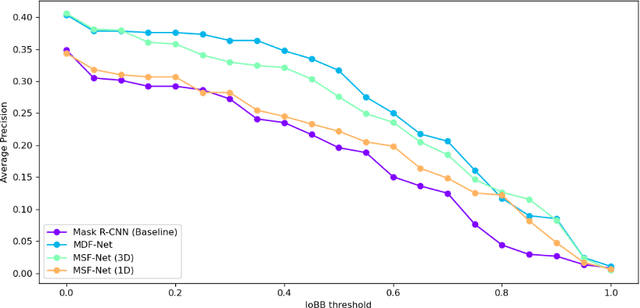
This study aims to investigate the effects of including patients' clinical information on the performance of deep learning (DL) classifiers for disease location in chest X-ray images. Although current classifiers achieve high performance using chest X-ray images alone, our interviews with radiologists indicate that clinical data is highly informative and essential for interpreting images and making proper diagnoses. In this work, we propose a novel architecture consisting of two fusion methods that enable the model to simultaneously process patients' clinical data (structured data) and chest X-rays (image data). Since these data modalities are in different dimensional spaces, we propose a spatial arrangement strategy, termed spatialization, to facilitate the multimodal learning process in a Mask R-CNN model. We performed an extensive experimental evaluation comprising three datasets with different modalities: MIMIC CXR (chest X-ray images), MIMIC IV-ED (patients' clinical data), and REFLACX (annotations of disease locations in chest X-rays). Results show that incorporating patients' clinical data in a DL model together with the proposed fusion methods improves the performance of disease localization in chest X-rays by 12\% in terms of Average Precision compared to a standard Mask R-CNN using only chest X-rays. Further ablation studies also emphasize the importance of multimodal DL architectures and the incorporation of patients' clinical data in disease localisation. The architecture proposed in this work is publicly available to promote the scientific reproducibility of our study (https://github.com/ChihchengHsieh/multimodal-abnormalities-detection).
Autonomous particles
Jan 24, 2023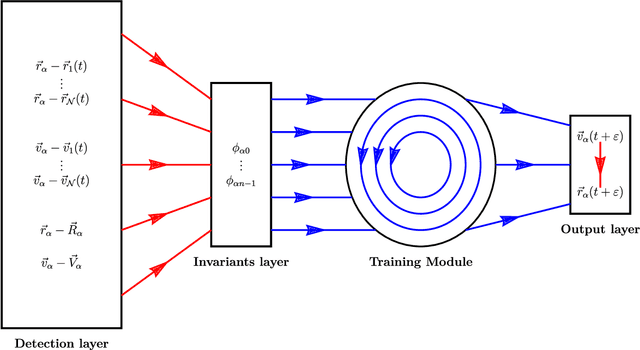
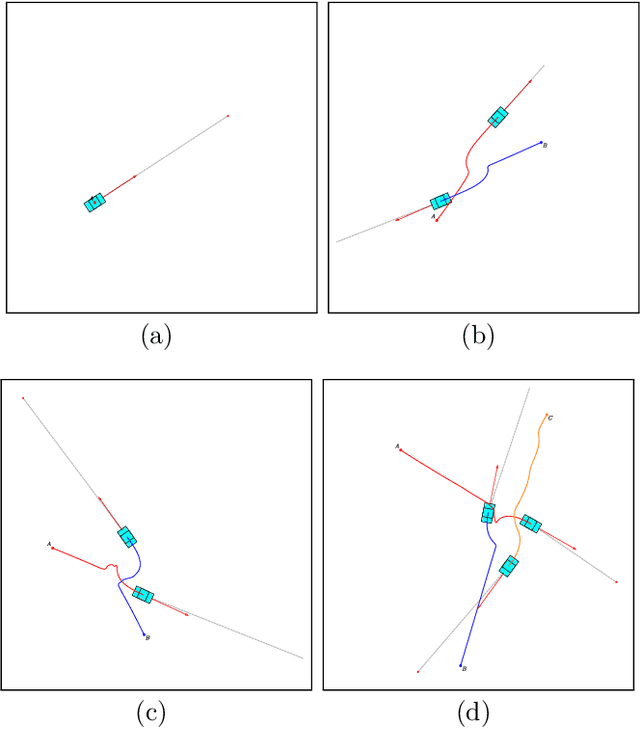
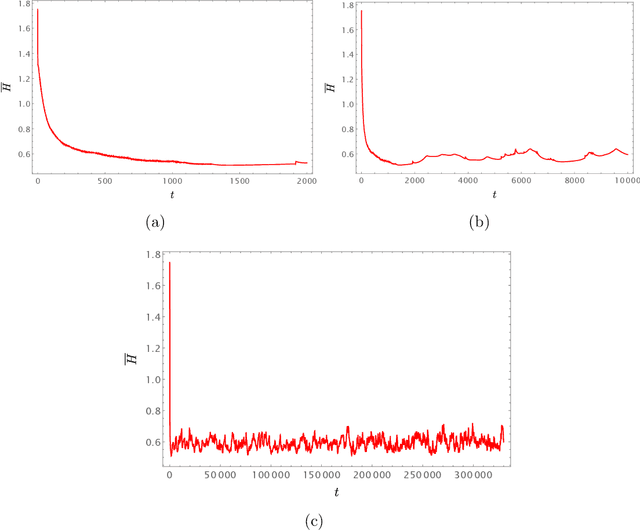
Consider a reinforcement learning problem where an agent has access to a very large amount of information about the environment, but it can only take very few actions to accomplish its task and to maximize its reward. Evidently, the main problem for the agent is to learn a map from a very high-dimensional space (which represents its environment) to a very low-dimensional space (which represents its actions). The high-to-low dimensional map implies that most of the information about the environment is irrelevant for the actions to be taken, and only a small fraction of information is relevant. In this paper we argue that the relevant information need not be learned by brute force (which is the standard approach), but can be identified from the intrinsic symmetries of the system. We analyze in details a reinforcement learning problem of autonomous driving, where the corresponding symmetry is the Galilean symmetry, and argue that the learning task can be accomplished with very few relevant parameters, or, more precisely, invariants. For a numerical demonstration, we show that the autonomous vehicles (which we call autonomous particles since they describe very primitive vehicles) need only four relevant invariants to learn how to drive very well without colliding with other particles. The simple model can be easily generalized to include different types of particles (e.g. for cars, for pedestrians, for buildings, for road signs, etc.) with different types of relevant invariants describing interactions between them. We also argue that there must exist a field theory description of the learning system where autonomous particles would be described by fermionic degrees of freedom and interactions mediated by the relevant invariants would be described by bosonic degrees of freedom.
GDB: Gated convolutions-based Document Binarization
Feb 04, 2023
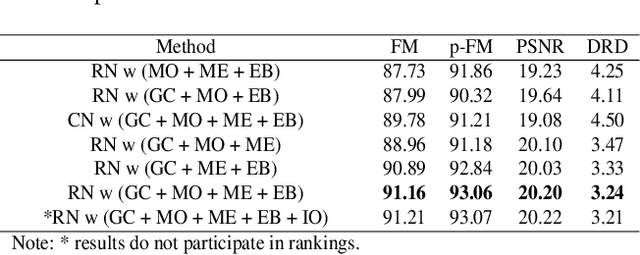
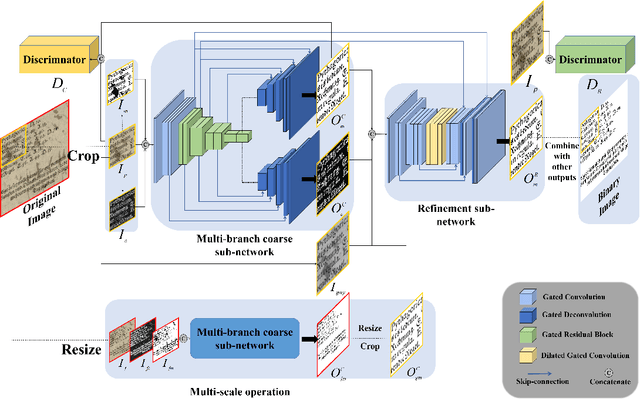
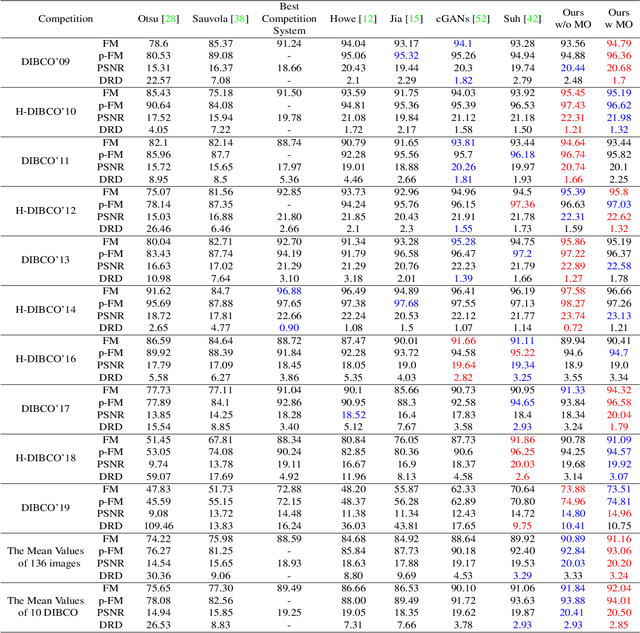
Document binarization is a key pre-processing step for many document analysis tasks. However, existing methods can not extract stroke edges finely, mainly due to the fair-treatment nature of vanilla convolutions and the extraction of stroke edges without adequate supervision by boundary-related information. In this paper, we formulate text extraction as the learning of gating values and propose an end-to-end gated convolutions-based network (GDB) to solve the problem of imprecise stroke edge extraction. The gated convolutions are applied to selectively extract the features of strokes with different attention. Our proposed framework consists of two stages. Firstly, a coarse sub-network with an extra edge branch is trained to get more precise feature maps by feeding a priori mask and edge. Secondly, a refinement sub-network is cascaded to refine the output of the first stage by gated convolutions based on the sharp edge. For global information, GDB also contains a multi-scale operation to combine local and global features. We conduct comprehensive experiments on ten Document Image Binarization Contest (DIBCO) datasets from 2009 to 2019. Experimental results show that our proposed methods outperform the state-of-the-art methods in terms of all metrics on average and achieve top ranking on six benchmark datasets.
Semi-decentralized Federated Ego Graph Learning for Recommendation
Feb 10, 2023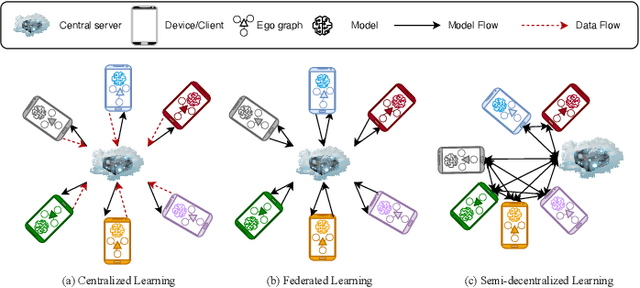
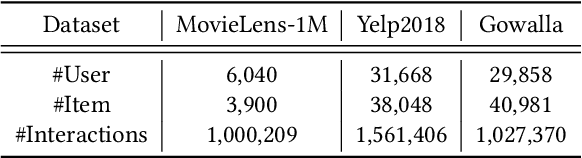
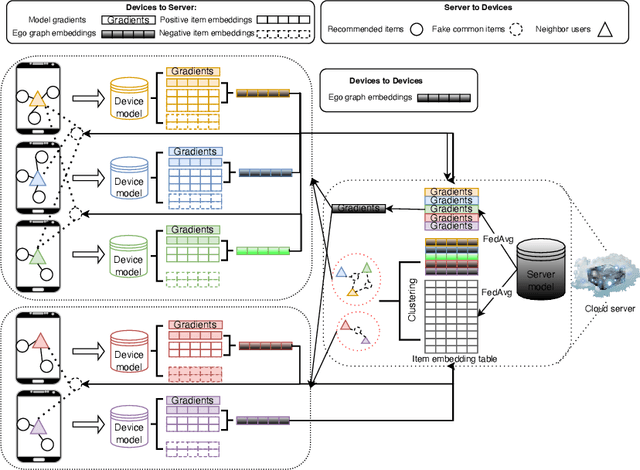
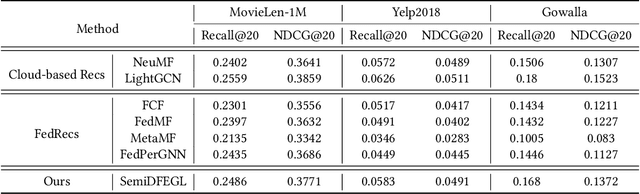
Collaborative filtering (CF) based recommender systems are typically trained based on personal interaction data (e.g., clicks and purchases) that could be naturally represented as ego graphs. However, most existing recommendation methods collect these ego graphs from all users to compose a global graph to obtain high-order collaborative information between users and items, and these centralized CF recommendation methods inevitably lead to a high risk of user privacy leakage. Although recently proposed federated recommendation systems can mitigate the privacy problem, they either restrict the on-device local training to an isolated ego graph or rely on an additional third-party server to access other ego graphs resulting in a cumbersome pipeline, which is hard to work in practice. In addition, existing federated recommendation systems require resource-limited devices to maintain the entire embedding tables resulting in high communication costs. In light of this, we propose a semi-decentralized federated ego graph learning framework for on-device recommendations, named SemiDFEGL, which introduces new device-to-device collaborations to improve scalability and reduce communication costs and innovatively utilizes predicted interacted item nodes to connect isolated ego graphs to augment local subgraphs such that the high-order user-item collaborative information could be used in a privacy-preserving manner. Furthermore, the proposed framework is model-agnostic, meaning that it could be seamlessly integrated with existing graph neural network-based recommendation methods and privacy protection techniques. To validate the effectiveness of the proposed SemiDFEGL, extensive experiments are conducted on three public datasets, and the results demonstrate the superiority of the proposed SemiDFEGL compared to other federated recommendation methods.
UnifySpeech: A Unified Framework for Zero-shot Text-to-Speech and Voice Conversion
Jan 10, 2023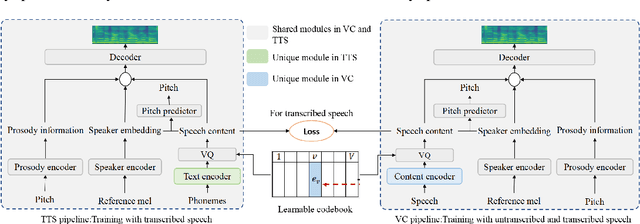

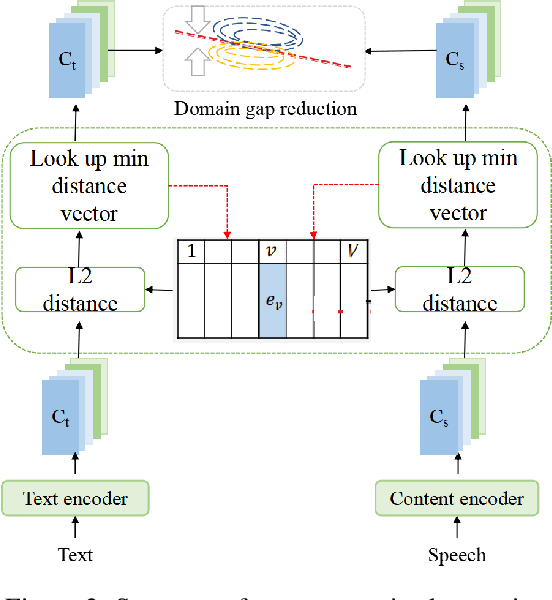
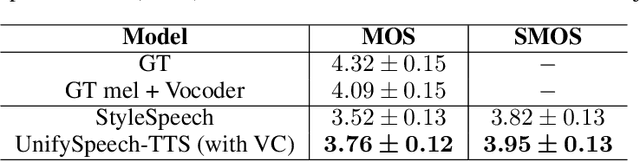
Text-to-speech (TTS) and voice conversion (VC) are two different tasks both aiming at generating high quality speaking voice according to different input modality. Due to their similarity, this paper proposes UnifySpeech, which brings TTS and VC into a unified framework for the first time. The model is based on the assumption that speech can be decoupled into three independent components: content information, speaker information, prosody information. Both TTS and VC can be regarded as mining these three parts of information from the input and completing the reconstruction of speech. For TTS, the speech content information is derived from the text, while in VC it's derived from the source speech, so all the remaining units are shared except for the speech content extraction module in the two tasks. We applied vector quantization and domain constrain to bridge the gap between the content domains of TTS and VC. Objective and subjective evaluation shows that by combining the two task, TTS obtains better speaker modeling ability while VC gets hold of impressive speech content decoupling capability.
A Dynamic Temporal Self-attention Graph Convolutional Network for Traffic Prediction
Feb 21, 2023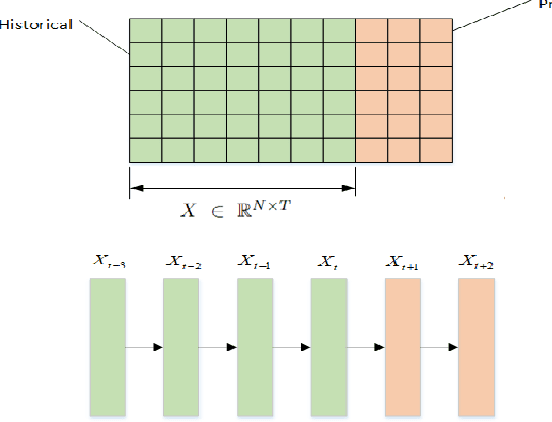
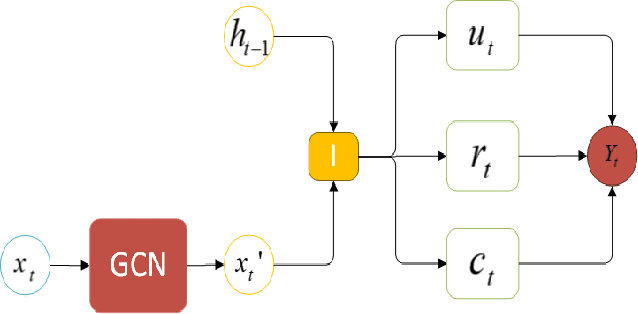
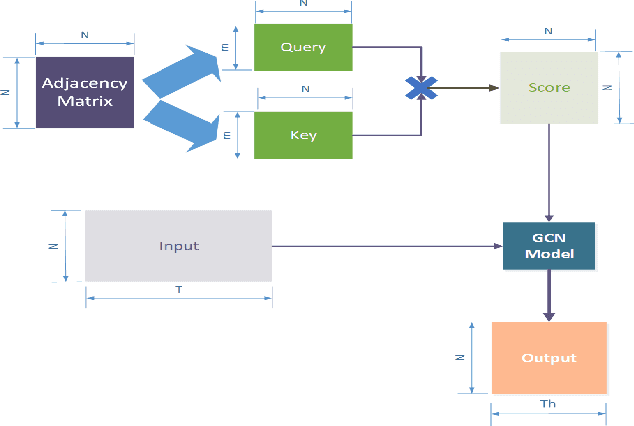
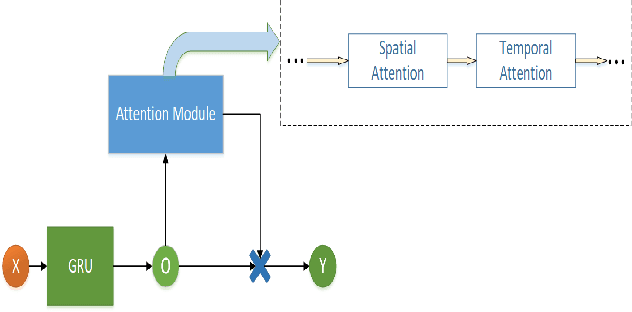
Accurate traffic prediction in real time plays an important role in Intelligent Transportation System (ITS) and travel navigation guidance. There have been many attempts to predict short-term traffic status which consider the spatial and temporal dependencies of traffic information such as temporal graph convolutional network (T-GCN) model and convolutional long short-term memory (Conv-LSTM) model. However, most existing methods use simple adjacent matrix consisting of 0 and 1 to capture the spatial dependence which can not meticulously describe the urban road network topological structure and the law of dynamic change with time. In order to tackle the problem, this paper proposes a dynamic temporal self-attention graph convolutional network (DT-SGN) model which considers the adjacent matrix as a trainable attention score matrix and adapts network parameters to different inputs. Specially, self-attention graph convolutional network (SGN) is chosen to capture the spatial dependence and the dynamic gated recurrent unit (Dynamic-GRU) is chosen to capture temporal dependence and learn dynamic changes of input data. Experiments demonstrate the superiority of our method over state-of-art model-driven model and data-driven models on real-world traffic datasets.