 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023
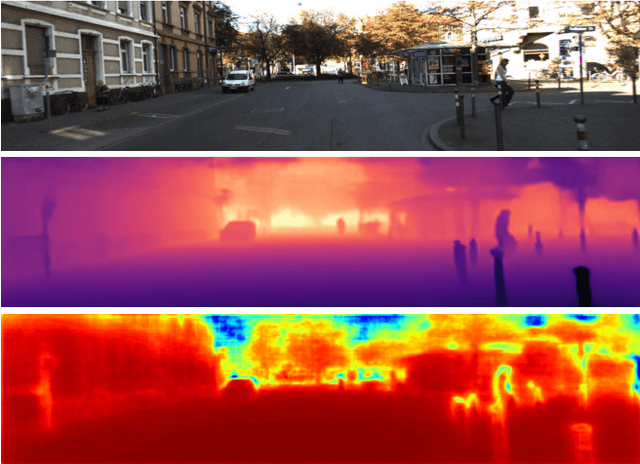
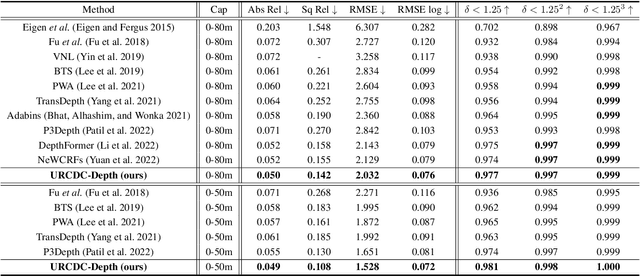
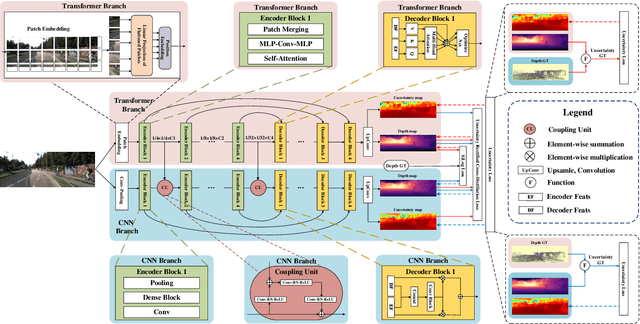
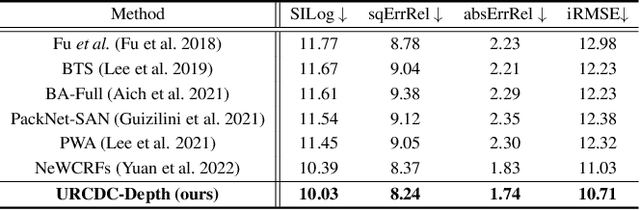
This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.
Detection of Epilepsy Seizure using Different Dimensionality Reduction Techniques and Machine Learning on Transform Domain
Feb 17, 2023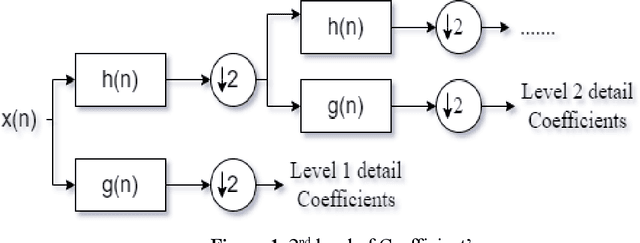
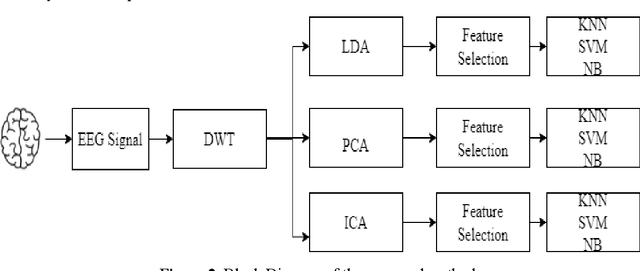
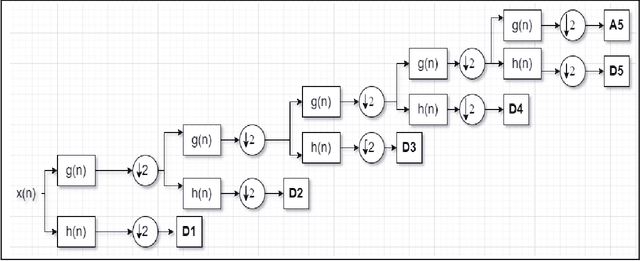
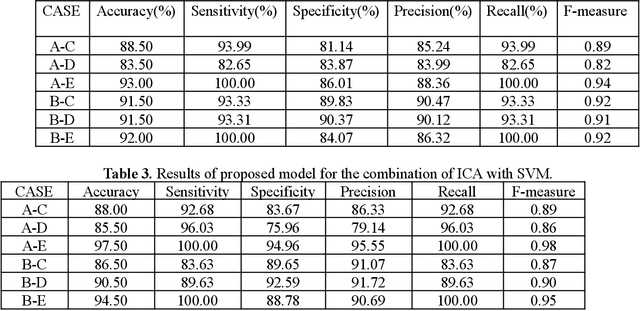
An Electroencephalogram (EEG) is a non-invasive exam that records the electrical activity of the brain. This exam is used to help diagnose conditions such as different brain problems. EEG signals are taken for the purpose of epilepsy detection and with Discrete Wavelet Transform (DWT) and machine learning classifier, they perform epilepsy detection. In Epilepsy seizure detection, mainly machine learning classifiers and statistical features are used. The hidden information in the EEG signal is useful for detecting diseases affecting the brain. Sometimes it is very difficult to identify the minimum changes in the EEG in time and frequency domains purpose. The DWT can give a good decomposition of the signals in different frequency bands and feature extraction. We use the tri-dimensionality reduction algorithm.; Principal Component Analysis (PCA), Independent Component Analysis (ICA) and Linear Discriminant Analysis (LDA). Finally, features are selected by using a fusion rule and at the last step three different classifiers Support Vector Machine (SVM), Naive Bayes (NB) and K-Nearest-Neighbor (KNN) has been used for the classification. The proposed framework is tested on the Bonn dataset and the simulation results provide the maximum accuracy for the combination of LDA and NB for 10-fold cross validation technique. It shows the maximum average sensitivity, specificity, accuracy, Precision and Recall of 100%, 100%, 100%, 100% and 100%. The results prove the effectiveness of this model.
Apple scab detection in orchards using deep learning on colour and multispectral images
Feb 17, 2023


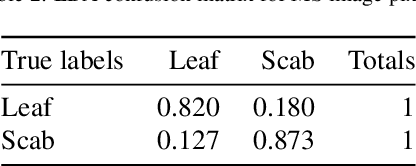
Apple scab is a fungal disease caused by Venturia inaequalis. Disease is of particular concern for growers, as it causes significant damage to fruit and leaves, leading to loss of fruit and yield. This article examines the ability of deep learning and hyperspectral imaging to accurately identify an apple symptom infection in apple trees. In total, 168 image scenes were collected using conventional RGB and Visible to Near-infrared (VIS-NIR) spectral imaging (8 channels) in infected orchards. Spectral data were preprocessed with an Artificial Neural Network (ANN) trained in segmentation to detect scab pixels based on spectral information. Linear Discriminant Analysis (LDA) was used to find the most discriminating channels in spectral data based on the healthy leaf and scab infested leaf spectra. Five combinations of false-colour images were created from the spectral data and the segmentation net results. The images were trained and evaluated with a modified version of the YOLOv5 network. Despite the promising results of deep learning using RGB images (P=0.8, mAP@50=0.73), the detection of apple scab in apple trees using multispectral imaging proved to be a difficult task. The high-light environment of the open field made it difficult to collect a balanced spectrum from the multispectral camera, since the infrared channel and the visible channels needed to be constantly balanced so that they did not overexpose in the images.
SF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 21, 2023
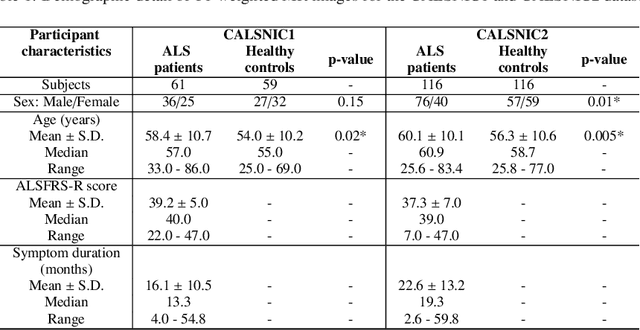
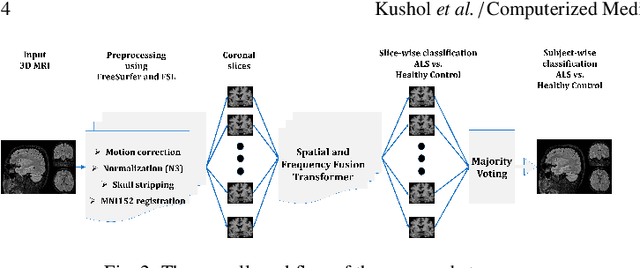
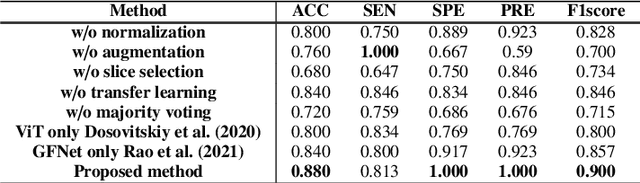
Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.
Towards a Sustainable Internet-of-Underwater-Things based on AUVs, SWIPT, and Reinforcement Learning
Feb 21, 2023
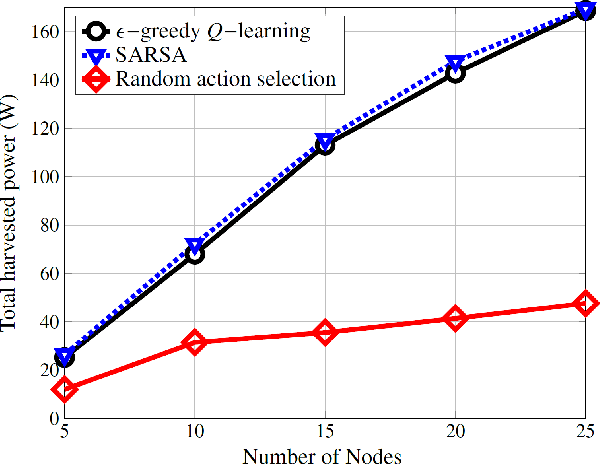
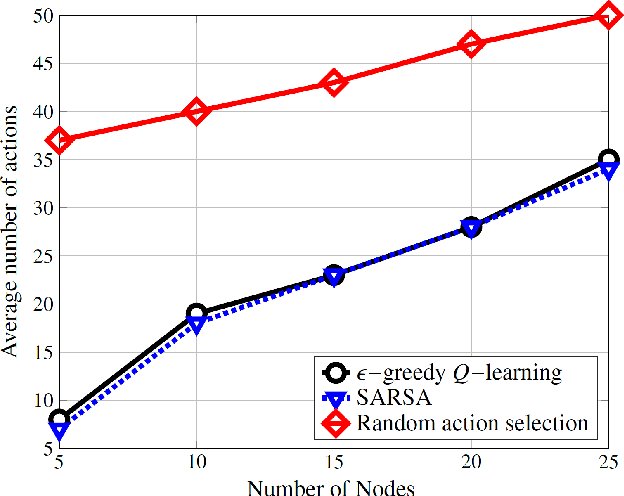
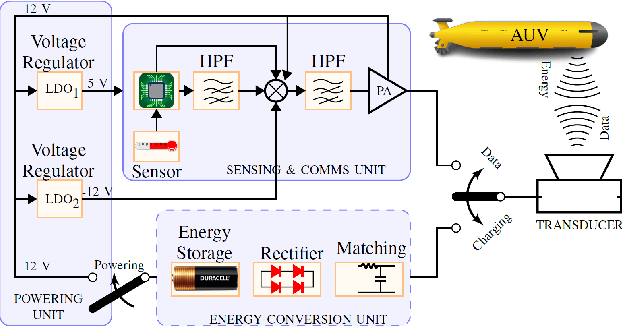
Life on earth depends on healthy oceans, which supply a large percentage of the planet's oxygen, food, and energy. However, the oceans are under threat from climate change, which is devastating the marine ecosystem and the economic and social systems that depend on it. The Internet-of-underwater-things (IoUTs), a global interconnection of underwater objects, enables round-the-clock monitoring of the oceans. It provides high-resolution data for training machine learning (ML) algorithms for rapidly evaluating potential climate change solutions and speeding up decision-making. The sensors in conventional IoUTs are battery-powered, which limits their lifetime, and constitutes environmental hazards when they die. In this paper, we propose a sustainable scheme to improve the throughput and lifetime of underwater networks, enabling them to potentially operate indefinitely. The scheme is based on simultaneous wireless information and power transfer (SWIPT) from an autonomous underwater vehicle (AUV) used for data collection. We model the problem of jointly maximising throughput and harvested power as a Markov Decision Process (MDP), and develop a model-free reinforcement learning (RL) algorithm as a solution. The model's reward function incentivises the AUV to find optimal trajectories that maximise throughput and power transfer to the underwater nodes while minimising energy consumption. To the best of our knowledge, this is the first attempt at using RL to ensure sustainable underwater networks via SWIPT. The scheme is implemented in an open 3D RL environment specifically developed in MATLAB for this study. The performance results show up 207% improvement in energy efficiency compared to those of a random trajectory scheme used as a baseline model.
Spatial gradient consistency for unsupervised learning of hyperspectral demosaicking: Application to surgical imaging
Feb 21, 2023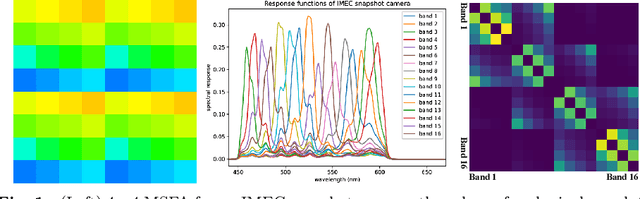
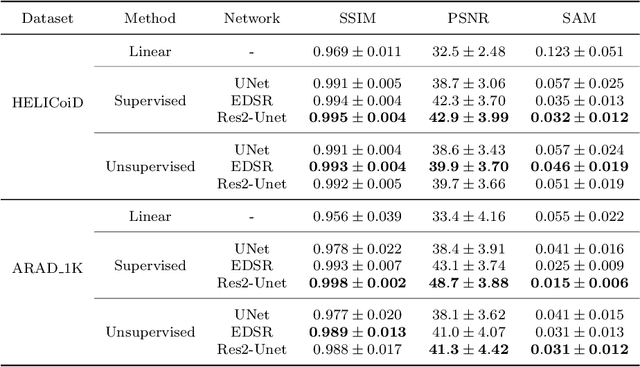
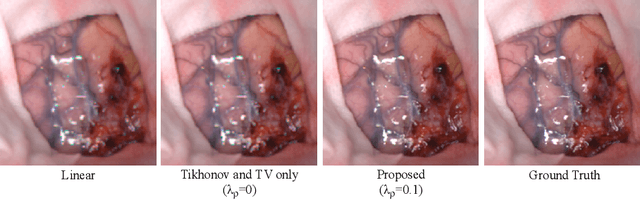
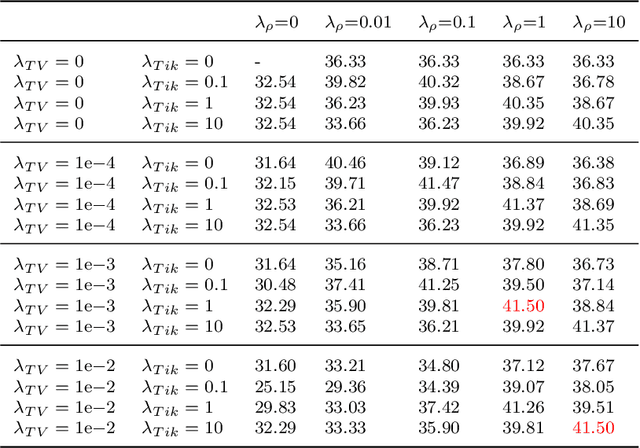
Hyperspectral imaging has the potential to improve intraoperative decision making if tissue characterisation is performed in real-time and with high-resolution. Hyperspectral snapshot mosaic sensors offer a promising approach due to their fast acquisition speed and compact size. However, a demosaicking algorithm is required to fully recover the spatial and spectral information of the snapshot images. Most state-of-the-art demosaicking algorithms require ground-truth training data with paired snapshot and high-resolution hyperspectral images, but such imagery pairs with the exact same scene are physically impossible to acquire in intraoperative settings. In this work, we present a fully unsupervised hyperspectral image demosaicking algorithm which only requires exemplar snapshot images for training purposes. We regard hyperspectral demosaicking as an ill-posed linear inverse problem which we solve using a deep neural network. We take advantage of the spectral correlation occurring in natural scenes to design a novel inter spectral band regularisation term based on spatial gradient consistency. By combining our proposed term with standard regularisation techniques and exploiting a standard data fidelity term, we obtain an unsupervised loss function for training deep neural networks, which allows us to achieve real-time hyperspectral image demosaicking. Quantitative results on hyperspetral image datasets show that our unsupervised demosaicking approach can achieve similar performance to its supervised counter-part, and significantly outperform linear demosaicking. A qualitative user study on real snapshot hyperspectral surgical images confirms the results from the quantitative analysis. Our results suggest that the proposed unsupervised algorithm can achieve promising hyperspectral demosaicking in real-time thus advancing the suitability of the modality for intraoperative use.
Criminal Investigation Tracker with Suspect Prediction using Machine Learning
Feb 21, 2023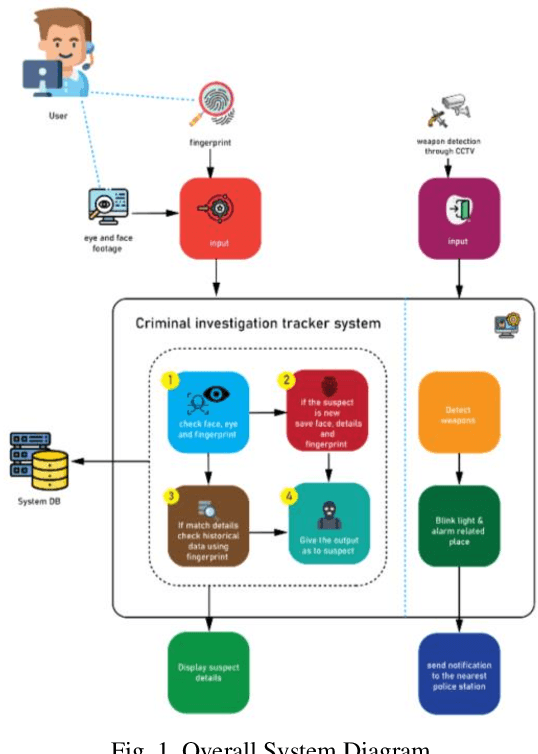

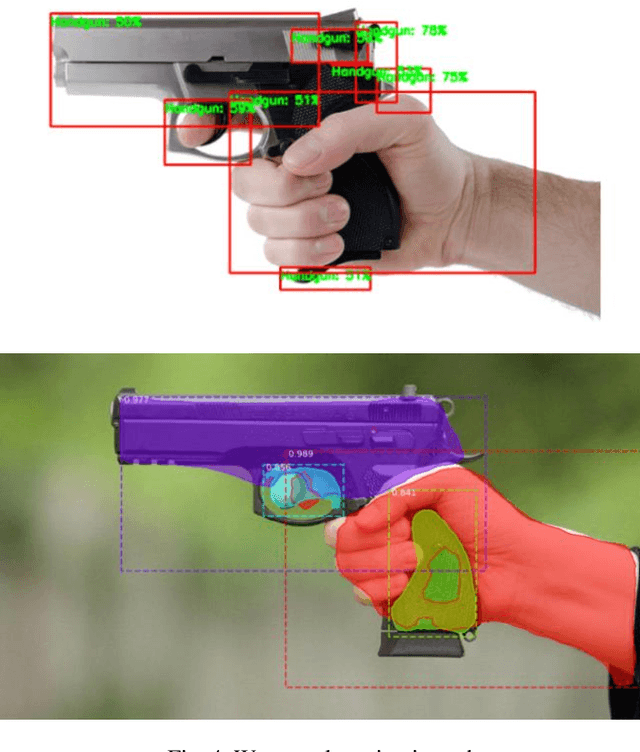
An automated approach to identifying offenders in Sri Lanka would be better than the current system. Obtaining information from eyewitnesses is one of the less reliable approaches and procedures still in use today. Automated criminal identification has the ability to save lives, notwithstanding Sri Lankan culture's lack of awareness of the issue. Using cutting-edge technology like biometrics to finish this task would be the most accurate strategy. The most notable outcomes will be obtained by applying fingerprint and face recognition as biometric techniques. The main responsibilities will be image optimization and criminality. CCTV footage may be used to identify a person's fingerprint, identify a person's face, and identify crimes involving weapons. Additionally, we unveil a notification system and condense the police report to Additionally, to make it simpler for police officers to understand the essential points of the crime, we develop a notification system and condense the police report. Additionally, if an incident involving a weapon is detected, an automated notice of the crime with all the relevant facts is sent to the closest police station. The summarization of the police report is what makes this the most original. In order to improve the efficacy of the overall image, the system will quickly and precisely identify the full crime scene, identify, and recognize the suspects using their faces and fingerprints, and detect firearms. This study provides a novel approach for crime prediction based on real-world data, and criminality incorporation. A crime or occurrence should be reported to the appropriate agencies, and the suggested web application should be improved further to offer a workable channel of communication.
End-to-End Voice Conversion with Information Perturbation
Jun 15, 2022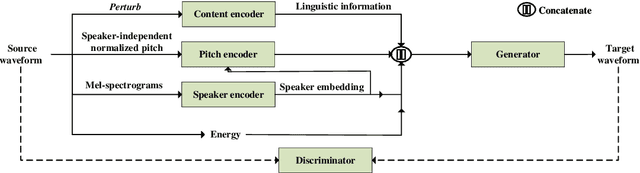
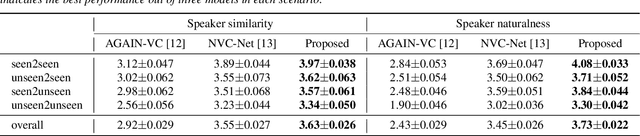
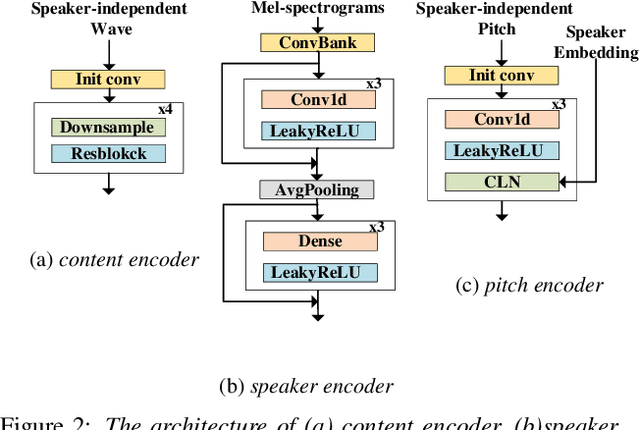
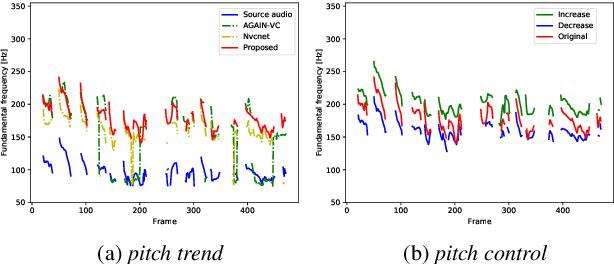
The ideal goal of voice conversion is to convert the source speaker's speech to sound naturally like the target speaker while maintaining the linguistic content and the prosody of the source speech. However, current approaches are insufficient to achieve comprehensive source prosody transfer and target speaker timbre preservation in the converted speech, and the quality of the converted speech is also unsatisfied due to the mismatch between the acoustic model and the vocoder. In this paper, we leverage the recent advances in information perturbation and propose a fully end-to-end approach to conduct high-quality voice conversion. We first adopt information perturbation to remove speaker-related information in the source speech to disentangle speaker timbre and linguistic content and thus the linguistic information is subsequently modeled by a content encoder. To better transfer the prosody of the source speech to the target, we particularly introduce a speaker-related pitch encoder which can maintain the general pitch pattern of the source speaker while flexibly modifying the pitch intensity of the generated speech. Finally, one-shot voice conversion is set up through continuous speaker space modeling. Experimental results indicate that the proposed end-to-end approach significantly outperforms the state-of-the-art models in terms of intelligibility, naturalness, and speaker similarity.
TAP: The Attention Patch for Cross-Modal Knowledge Transfer from Unlabeled Data
Feb 04, 2023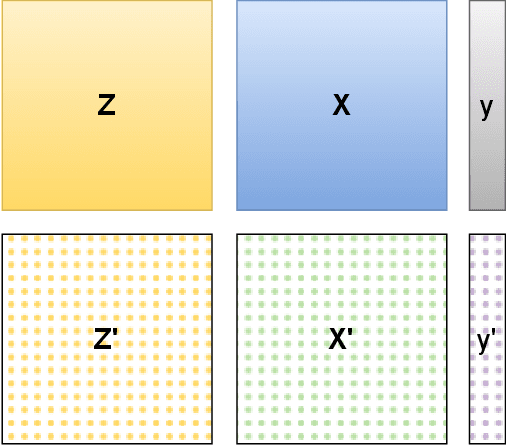
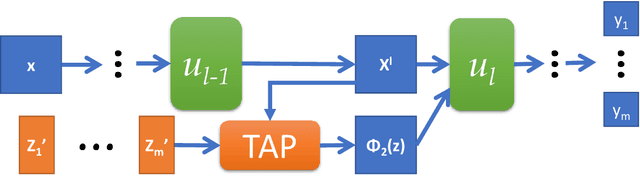
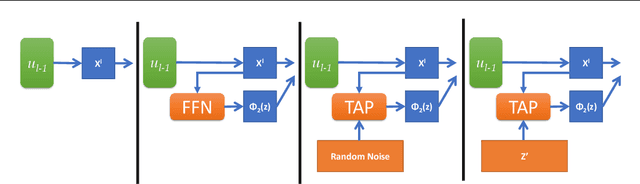
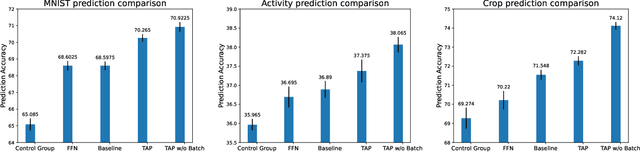
This work investigates the intersection of cross modal learning and semi supervised learning, where we aim to improve the supervised learning performance of the primary modality by borrowing missing information from an unlabeled modality. We investigate this problem from a Nadaraya Watson (NW) kernel regression perspective and show that this formulation implicitly leads to a kernelized cross attention module. To this end, we propose The Attention Patch (TAP), a simple neural network plugin that allows data level knowledge transfer from the unlabeled modality. We provide numerical simulations on three real world datasets to examine each aspect of TAP and show that a TAP integration in a neural network can improve generalization performance using the unlabeled modality.
The Cosmic Graph: Optimal Information Extraction from Large-Scale Structure using Catalogues
Jul 11, 2022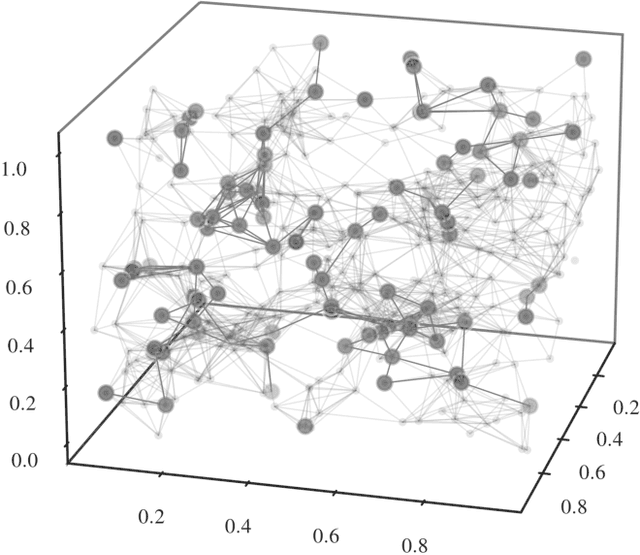
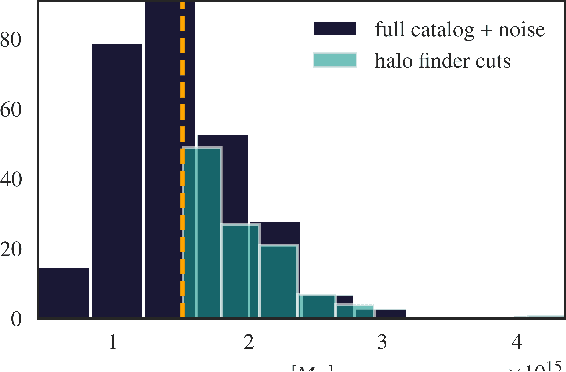
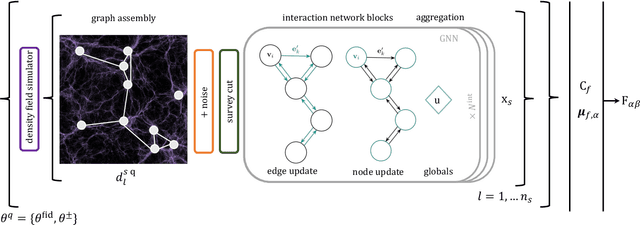
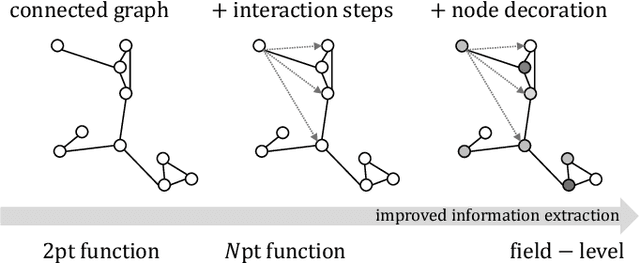
We present an implicit likelihood approach to quantifying cosmological information over discrete catalogue data, assembled as graphs. To do so, we explore cosmological inference using mock dark matter halo catalogues. We employ Information Maximising Neural Networks (IMNNs) to quantify Fisher information extraction as a function of graph representation. We a) demonstrate the high sensitivity of modular graph structure to the underlying cosmology in the noise-free limit, b) show that networks automatically combine mass and clustering information through comparisons to traditional statistics, c) demonstrate that graph neural networks can still extract information when catalogues are subject to noisy survey cuts, and d) illustrate how nonlinear IMNN summaries can be used as asymptotically optimal compressed statistics for Bayesian implicit likelihood inference. We reduce the area of joint $\Omega_m, \sigma_8$ parameter constraints with small ($\sim$100 object) halo catalogues by a factor of 42 over the two-point correlation function, and demonstrate that the networks automatically combine mass and clustering information. This work utilises a new IMNN implementation over graph data in Jax, which can take advantage of either numerical or auto-differentiability. We also show that graph IMNNs successfully compress simulations far from the fiducial model at which the network is fitted, indicating a promising alternative to $n$-point statistics in catalogue-based analyses.