 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adapting Step-size: A Unified Perspective to Analyze and Improve Gradient-based Methods for Adversarial Attacks
Jan 30, 2023
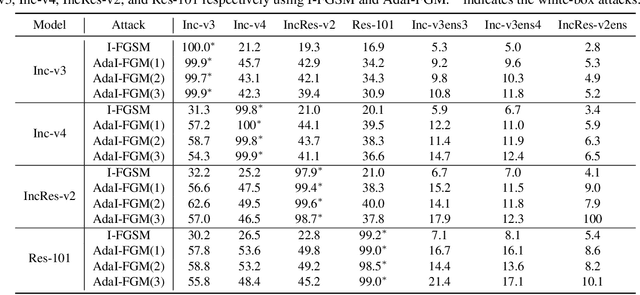
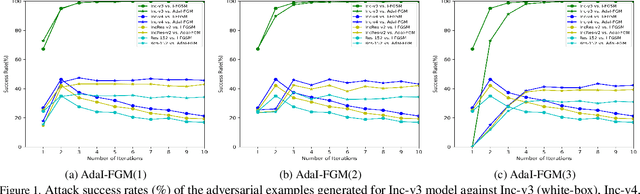
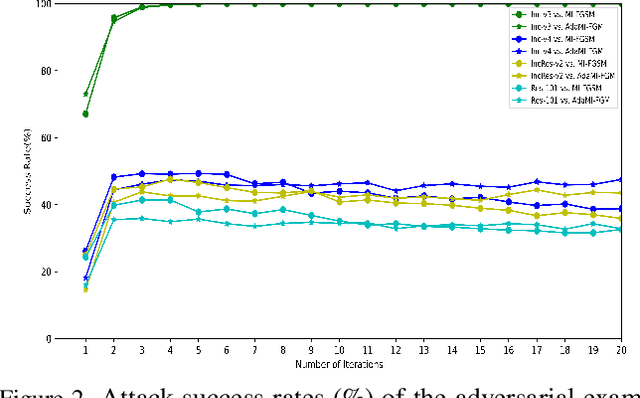

Learning adversarial examples can be formulated as an optimization problem of maximizing the loss function with some box-constraints. However, for solving this induced optimization problem, the state-of-the-art gradient-based methods such as FGSM, I-FGSM and MI-FGSM look different from their original methods especially in updating the direction, which makes it difficult to understand them and then leaves some theoretical issues to be addressed in viewpoint of optimization. In this paper, from the perspective of adapting step-size, we provide a unified theoretical interpretation of these gradient-based adversarial learning methods. We show that each of these algorithms is in fact a specific reformulation of their original gradient methods but using the step-size rules with only current gradient information. Motivated by such analysis, we present a broad class of adaptive gradient-based algorithms based on the regular gradient methods, in which the step-size strategy utilizing information of the accumulated gradients is integrated. Such adaptive step-size strategies directly normalize the scale of the gradients rather than use some empirical operations. The important benefit is that convergence for the iterative algorithms is guaranteed and then the whole optimization process can be stabilized. The experiments demonstrate that our AdaI-FGM consistently outperforms I-FGSM and AdaMI-FGM remains competitive with MI-FGSM for black-box attacks.
A Biomedical Knowledge Graph for Biomarker Discovery in Cancer
Feb 23, 2023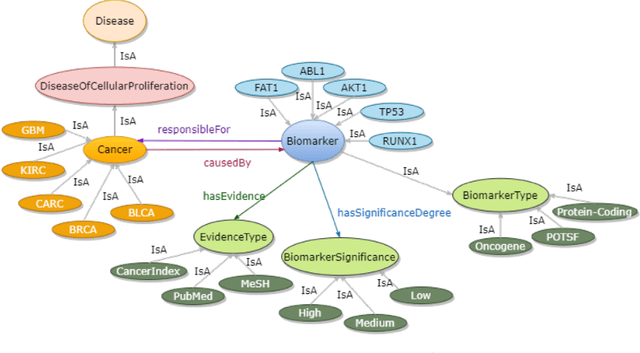
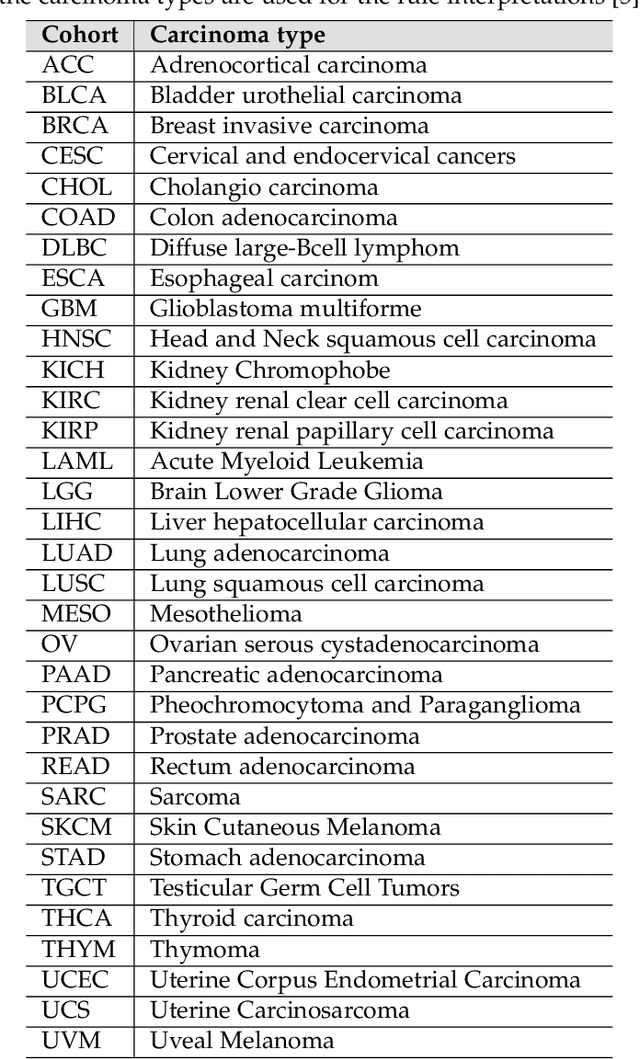
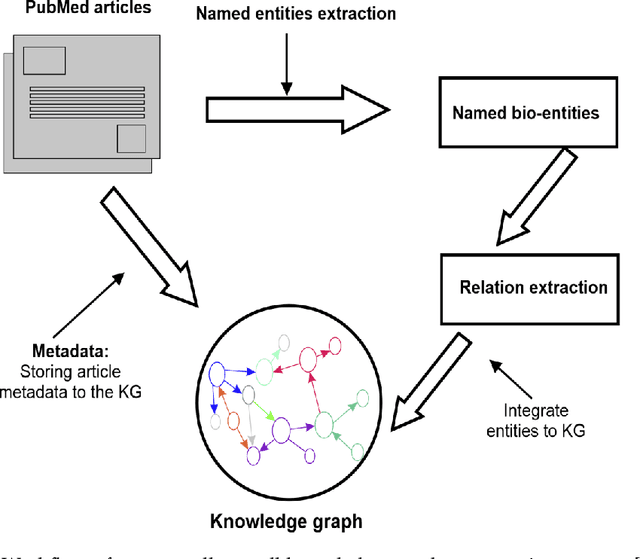

Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A domain-specific knowledge graph~(KG) is an explicit conceptualization of a specific subject-matter domain represented w.r.t semantically interrelated entities and relations. A KG can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. Such a KG will not only allow deducing new knowledge and question answering(QA) but also allows domain experts to explore. Since cross-disciplinary explanations are important for accurate diagnosis, it is important to query the KG to provide interactive explanations about learned biomarkers. Inspired by these, we construct a domain-specific KG, particularly for cancer-specific biomarker discovery. The KG is constructed by integrating cancer-related knowledge and facts from multiple sources. First, we construct a domain-specific ontology, which we call OncoNet Ontology (ONO). The ONO ontology is developed to enable semantic reasoning for verification of the predictions for relations between diseases and genes. The KG is then developed and enriched by harmonizing the ONO, additional metadata schemas, ontologies, controlled vocabularies, and additional concepts from external sources using a BERT-based information extraction method. BioBERT and SciBERT are finetuned with the selected articles crawled from PubMed. We listed down some queries and some examples of QA and deducing knowledge based on the KG.
simpleKT: A Simple But Tough-to-Beat Baseline for Knowledge Tracing
Feb 23, 2023
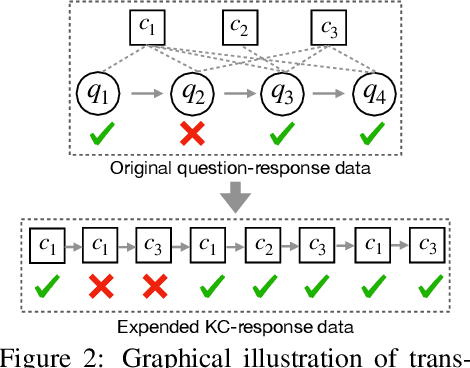
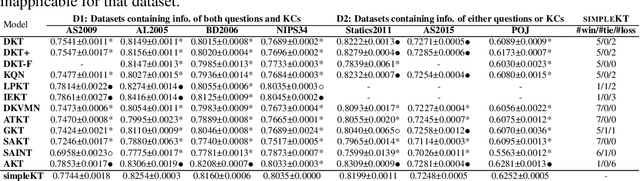
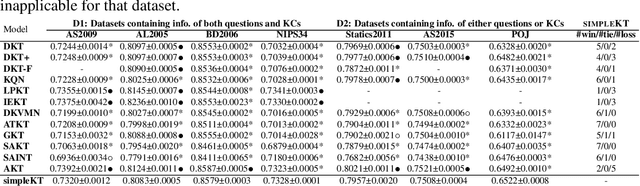
Knowledge tracing (KT) is the problem of predicting students' future performance based on their historical interactions with intelligent tutoring systems. Recently, many works present lots of special methods for applying deep neural networks to KT from different perspectives like model architecture, adversarial augmentation and etc., which make the overall algorithm and system become more and more complex. Furthermore, due to the lack of standardized evaluation protocol \citep{liu2022pykt}, there is no widely agreed KT baselines and published experimental comparisons become inconsistent and self-contradictory, i.e., the reported AUC scores of DKT on ASSISTments2009 range from 0.721 to 0.821 \citep{minn2018deep,yeung2018addressing}. Therefore, in this paper, we provide a strong but simple baseline method to deal with the KT task named \textsc{simpleKT}. Inspired by the Rasch model in psychometrics, we explicitly model question-specific variations to capture the individual differences among questions covering the same set of knowledge components that are a generalization of terms of concepts or skills needed for learners to accomplish steps in a task or a problem. Furthermore, instead of using sophisticated representations to capture student forgetting behaviors, we use the ordinary dot-product attention function to extract the time-aware information embedded in the student learning interactions. Extensive experiments show that such a simple baseline is able to always rank top 3 in terms of AUC scores and achieve 57 wins, 3 ties and 16 loss against 12 DLKT baseline methods on 7 public datasets of different domains. We believe this work serves as a strong baseline for future KT research. Code is available at \url{https://github.com/pykt-team/pykt-toolkit}\footnote{We merged our model to the \textsc{pyKT} benchmark at \url{https://pykt.org/}.}.
Efficient Context Integration through Factorized Pyramidal Learning for Ultra-Lightweight Semantic Segmentation
Feb 23, 2023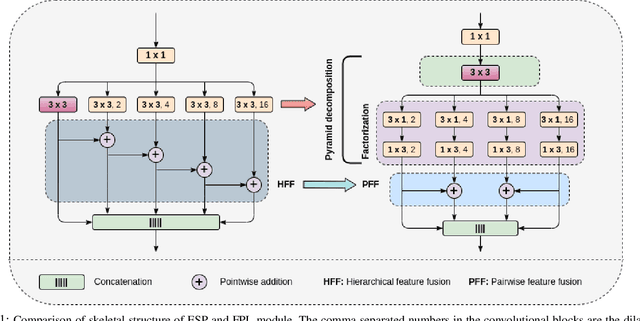
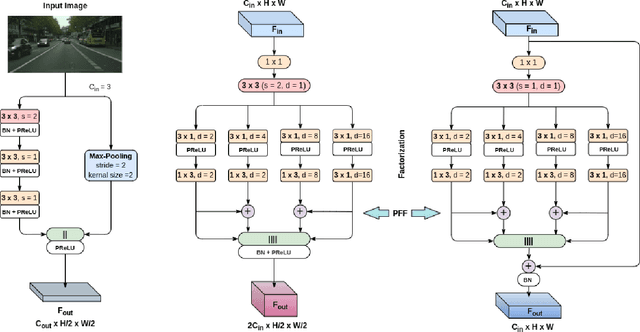
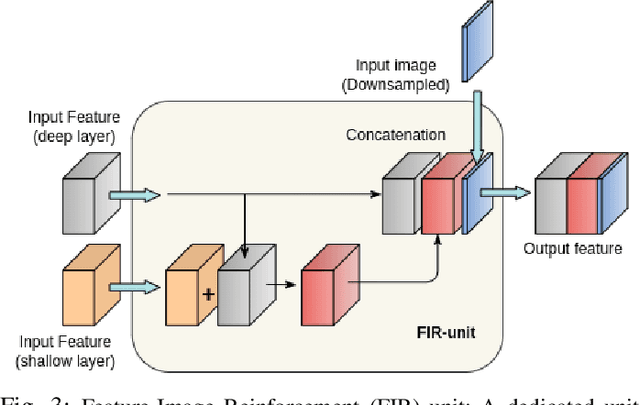
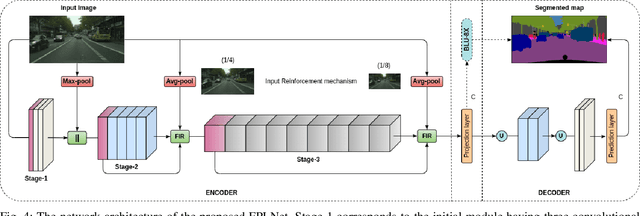
Semantic segmentation is a pixel-level prediction task to classify each pixel of the input image. Deep learning models, such as convolutional neural networks (CNNs), have been extremely successful in achieving excellent performances in this domain. However, mobile application, such as autonomous driving, demand real-time processing of incoming stream of images. Hence, achieving efficient architectures along with enhanced accuracy is of paramount importance. Since, accuracy and model size of CNNs are intrinsically contentious in nature, the challenge is to achieve a decent trade-off between accuracy and model size. To address this, we propose a novel Factorized Pyramidal Learning (FPL) module to aggregate rich contextual information in an efficient manner. On one hand, it uses a bank of convolutional filters with multiple dilation rates which leads to multi-scale context aggregation; crucial in achieving better accuracy. On the other hand, parameters are reduced by a careful factorization of the employed filters; crucial in achieving lightweight models. Moreover, we decompose the spatial pyramid into two stages which enables a simple and efficient feature fusion within the module to solve the notorious checkerboard effect. We also design a dedicated Feature-Image Reinforcement (FIR) unit to carry out the fusion operation of shallow and deep features with the downsampled versions of the input image. This gives an accuracy enhancement without increasing model parameters. Based on the FPL module and FIR unit, we propose an ultra-lightweight real-time network, called FPLNet, which achieves state-of-the-art accuracy-efficiency trade-off. More specifically, with only less than 0.5 million parameters, the proposed network achieves 66.93\% and 66.28\% mIoU on Cityscapes validation and test set, respectively. Moreover, FPLNet has a processing speed of 95.5 frames per second (FPS).
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


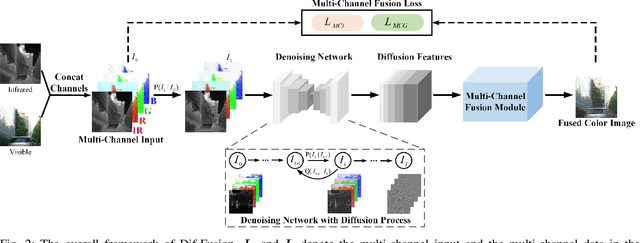
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.
Pretraining Language Models with Human Preferences
Feb 16, 2023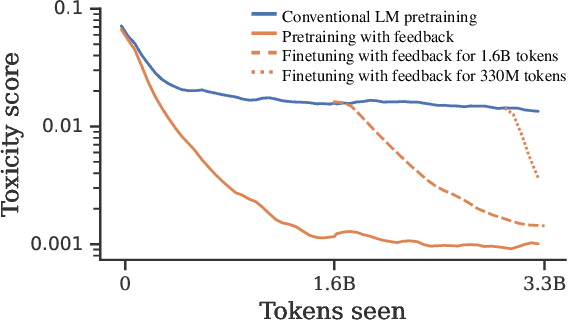
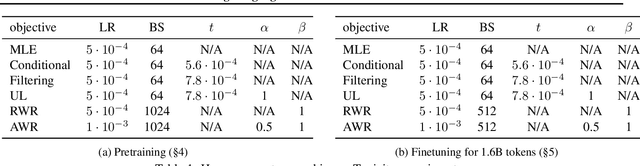
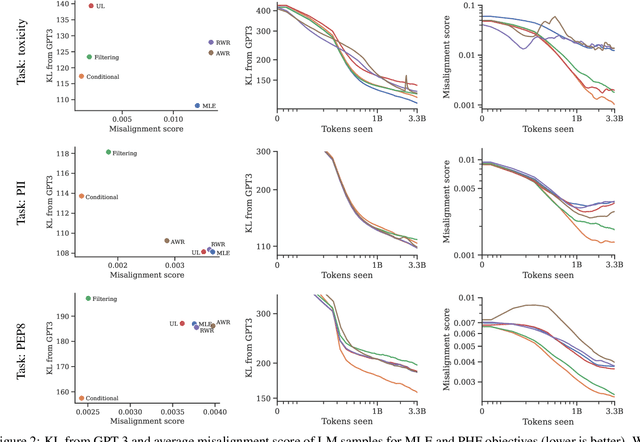
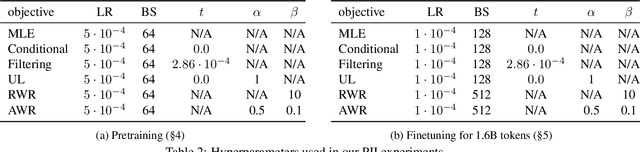
Language models (LMs) are pretrained to imitate internet text, including content that would violate human preferences if generated by an LM: falsehoods, offensive comments, personally identifiable information, low-quality or buggy code, and more. Here, we explore alternative objectives for pretraining LMs in a way that also guides them to generate text aligned with human preferences. We benchmark five objectives for pretraining with human feedback across three tasks and study how they affect the trade-off between alignment and capabilities of pretrained LMs. We find a Pareto-optimal and simple approach among those we explored: conditional training, or learning distribution over tokens conditional on their human preference scores given by a reward model. Conditional training reduces the rate of undesirable content by up to an order of magnitude, both when generating without a prompt and with an adversarially-chosen prompt. Moreover, conditional training maintains the downstream task performance of standard LM pretraining, both before and after task-specific finetuning. Pretraining with human feedback results in much better preference satisfaction than standard LM pretraining followed by finetuning with feedback, i.e., learning and then unlearning undesirable behavior. Our results suggest that we should move beyond imitation learning when pretraining LMs and incorporate human preferences from the start of training.
Exploring the Limits of ChatGPT for Query or Aspect-based Text Summarization
Feb 16, 2023
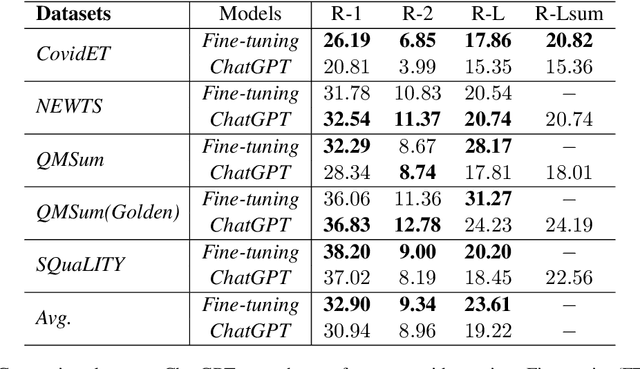
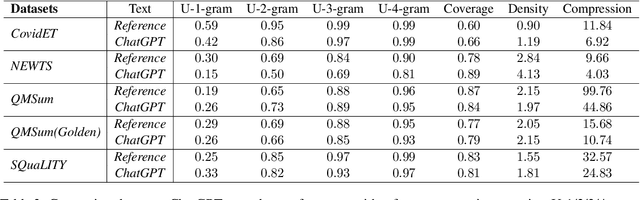
Text summarization has been a crucial problem in natural language processing (NLP) for several decades. It aims to condense lengthy documents into shorter versions while retaining the most critical information. Various methods have been proposed for text summarization, including extractive and abstractive summarization. The emergence of large language models (LLMs) like GPT3 and ChatGPT has recently created significant interest in using these models for text summarization tasks. Recent studies \cite{goyal2022news, zhang2023benchmarking} have shown that LLMs-generated news summaries are already on par with humans. However, the performance of LLMs for more practical applications like aspect or query-based summaries is underexplored. To fill this gap, we conducted an evaluation of ChatGPT's performance on four widely used benchmark datasets, encompassing diverse summaries from Reddit posts, news articles, dialogue meetings, and stories. Our experiments reveal that ChatGPT's performance is comparable to traditional fine-tuning methods in terms of Rouge scores. Moreover, we highlight some unique differences between ChatGPT-generated summaries and human references, providing valuable insights into the superpower of ChatGPT for diverse text summarization tasks. Our findings call for new directions in this area, and we plan to conduct further research to systematically examine the characteristics of ChatGPT-generated summaries through extensive human evaluation.
Eagle: Large-Scale Learning of Turbulent Fluid Dynamics with Mesh Transformers
Feb 16, 2023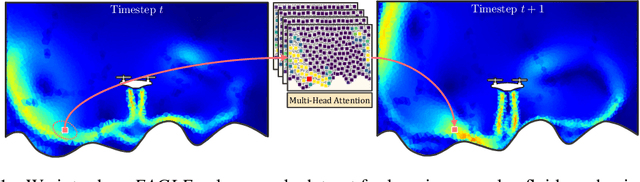
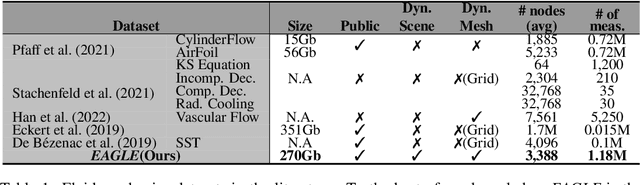
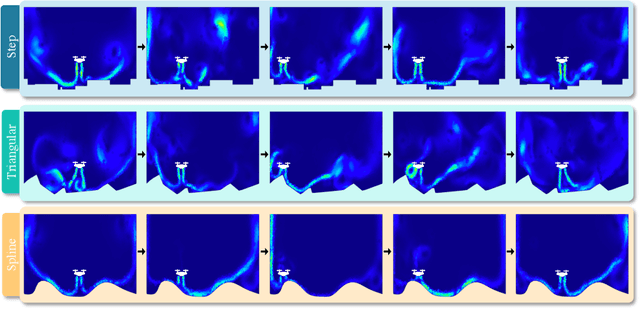
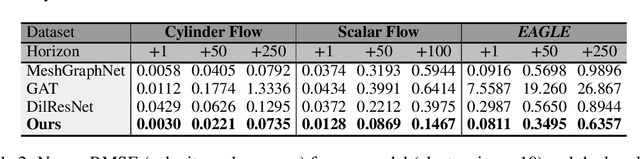
Estimating fluid dynamics is classically done through the simulation and integration of numerical models solving the Navier-Stokes equations, which is computationally complex and time-consuming even on high-end hardware. This is a notoriously hard problem to solve, which has recently been addressed with machine learning, in particular graph neural networks (GNN) and variants trained and evaluated on datasets of static objects in static scenes with fixed geometry. We attempt to go beyond existing work in complexity and introduce a new model, method and benchmark. We propose EAGLE, a large-scale dataset of 1.1 million 2D meshes resulting from simulations of unsteady fluid dynamics caused by a moving flow source interacting with nonlinear scene structure, comprised of 600 different scenes of three different types. To perform future forecasting of pressure and velocity on the challenging EAGLE dataset, we introduce a new mesh transformer. It leverages node clustering, graph pooling and global attention to learn long-range dependencies between spatially distant data points without needing a large number of iterations, as existing GNN methods do. We show that our transformer outperforms state-of-the-art performance on, both, existing synthetic and real datasets and on EAGLE. Finally, we highlight that our approach learns to attend to airflow, integrating complex information in a single iteration.
* Published as a conference paper at ICLR 2023
Classification Schemes for the Radar Reference Window: Design and Comparisons
Feb 16, 2023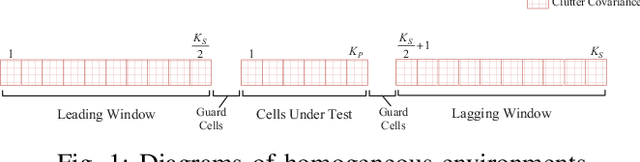
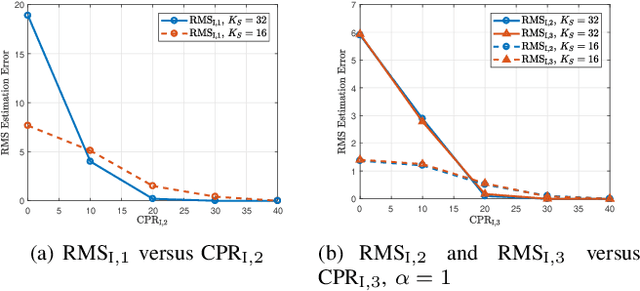
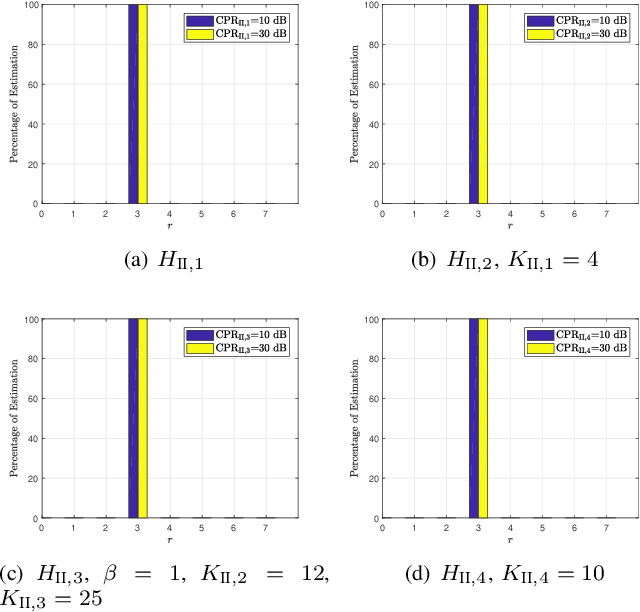
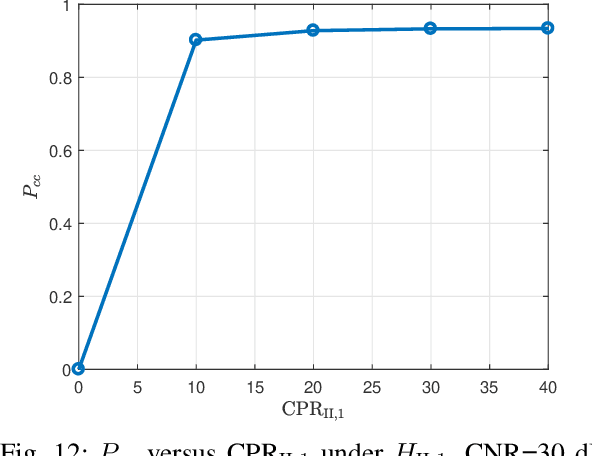
In this paper, we address the problem of classifying data within the radar reference window in terms of statistical properties. Specifically, we partition these data into statistically homogeneous subsets by identifying possible clutter power variations with respect to the cells under test (accounting for possible range-spread targets) and/or clutter edges. To this end, we consider different situations of practical interest and formulate the classification problem as multiple hypothesis tests comprising several models for the operating scenario. Then, we solve the hypothesis testing problems by resorting to suitable approximations of the model order selection rules due to the intractable mathematics associated with the maximum likelihood estimation of some parameters. Remarkably, the classification results provided by the proposed architectures represent an advanced clutter map since, besides the estimation of the clutter parameters, they contain a clustering of the range bins in terms of homogeneous subsets. In fact, such information can drive the conventional detectors towards more reliable estimates of the clutter covariance matrix according to the position of the cells under test. The performance analysis confirms that the conceived architectures represent a viable means to recognize the scenario wherein the radar is operating at least for the considered simulation parameters.
Channel Estimation for BIOS-Assisted Multi-User MIMO Systems: A Heterogeneous Two-timescale Strategy
Feb 16, 2023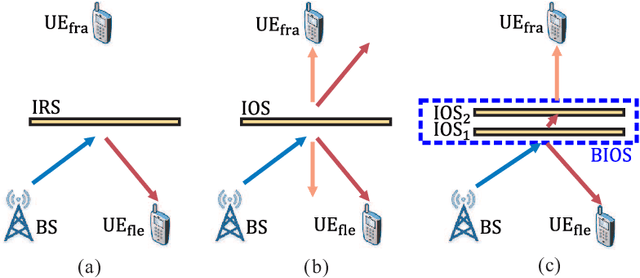
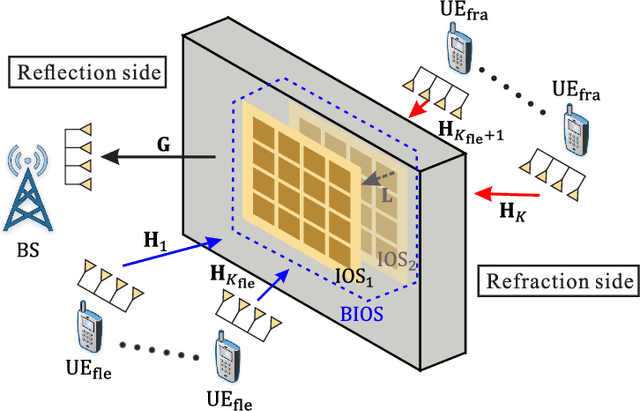
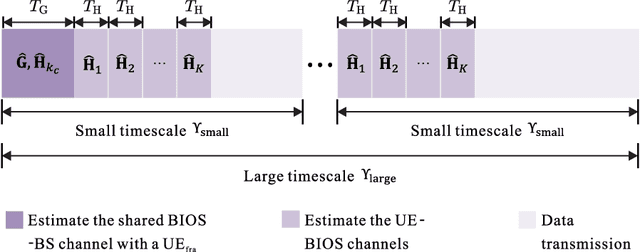
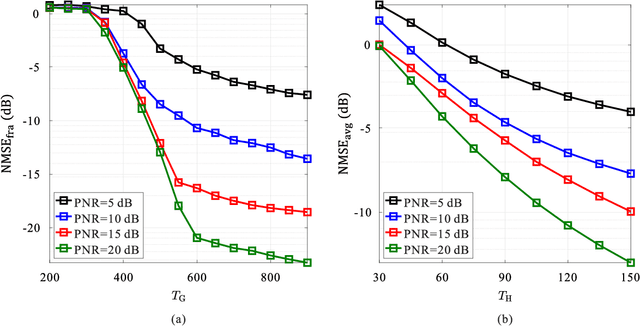
Bilayer intelligent omni-surface (BIOS) has recently attracted increasing attention due to its capability of independent beamforming on both reflection and refraction sides. However, its specific bilayer structure makes the channel estimation problem more challenging than the conventional intelligent reflecting surface (IRS) or intelligent omni-surface (IOS). In this paper, we investigate the channel estimation problem in the BIOS-assisted multi-user multiple-input multiple-output system. We find that in contrast to the IRS or IOS, where the forms of the cascaded channels of all user equipments (UEs) are the same, in the BIOS, those of the UEs on the reflection side are different from those on the refraction side, which is referred to as the heterogeneous channel property. By exploiting it along with the two-timescale and sparsity properties of channels and applying the manifold optimization method, we propose an efficient channel estimation scheme to reduce the training overhead in the BIOS-assisted system. Moreover, we investigate the joint optimization of base station digital beamforming and BIOS passive analog beamforming. Simulation results show that the proposed estimation scheme can significantly reduce the training overhead with competitive estimation quality, and thus keeps the performance advantage of BIOS over IRS and IOS with imperfect channel state information.