 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning for Hybrid Beamforming with Finite Feedback in GSM Aided mmWave MIMO Systems
Feb 15, 2023
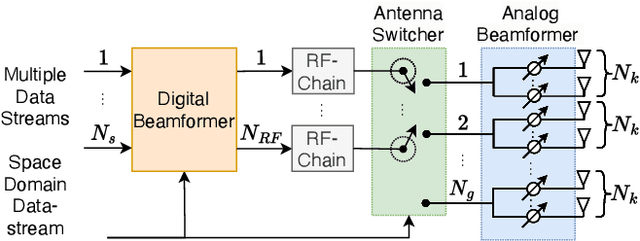
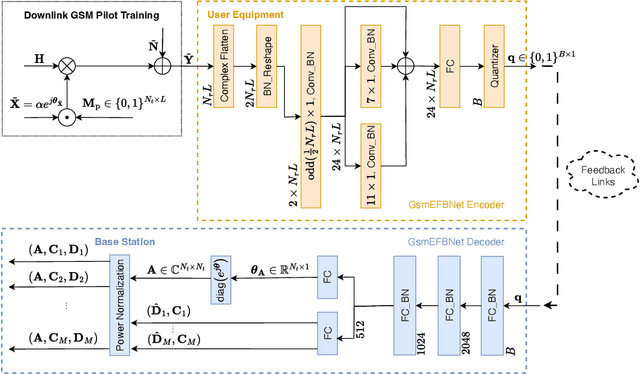
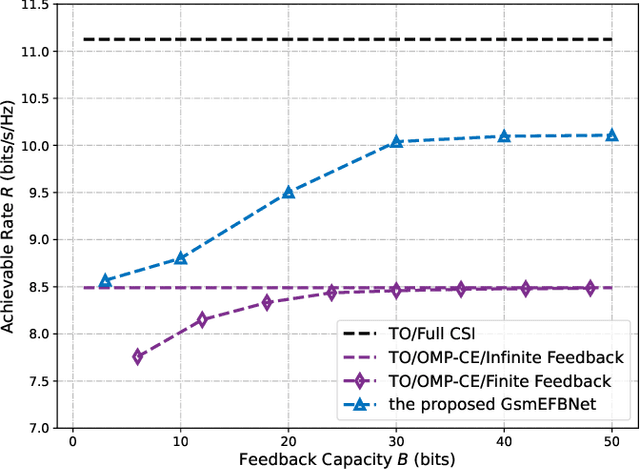
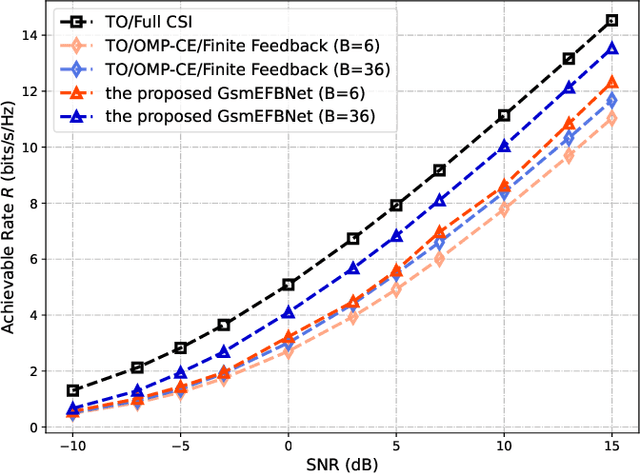
Hybrid beamforming is widely recognized as an important technique for millimeter wave (mmWave) multiple input multiple output (MIMO) systems. Generalized spatial modulation (GSM) is further introduced to improve the spectrum efficiency. However, most of the existing works on beamforming assume the perfect channel state information (CSI), which is unrealistic in practical systems. In this paper, joint optimization of downlink pilot training, channel estimation, CSI feedback, and hybrid beamforming is considered in GSM aided frequency division duplexing (FDD) mmWave MIMO systems. With the help of deep learning, the GSM hybrid beamformers are designed via unsupervised learning in an end-to-end way. Experiments show that the proposed multi-resolution network named GsmEFBNet can reach a better achievable rate with fewer feedback bits compared with the conventional algorithm.
Towards Optimal Compression: Joint Pruning and Quantization
Feb 15, 2023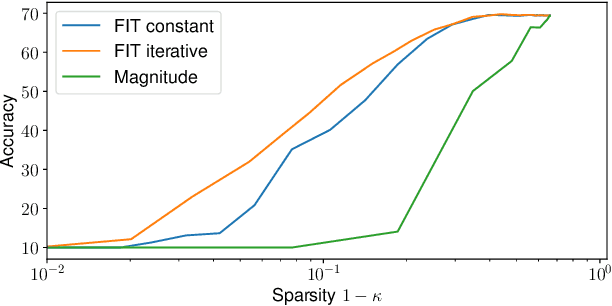
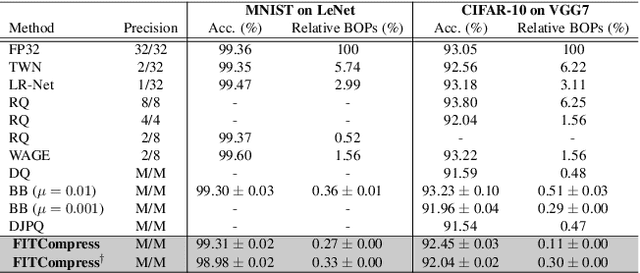
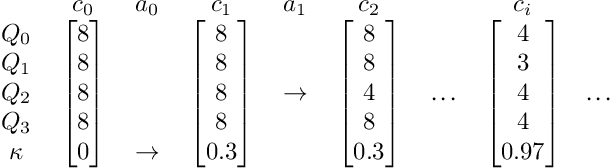
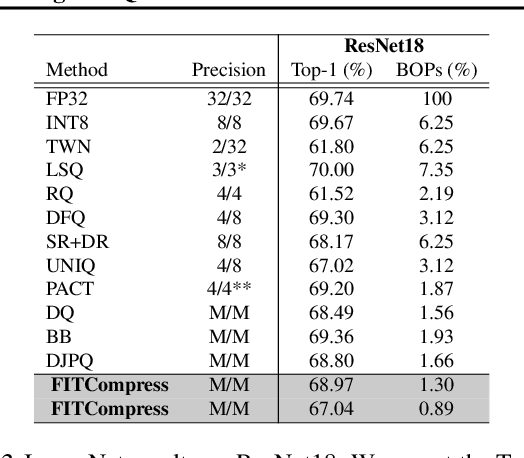
Compression of deep neural networks has become a necessary stage for optimizing model inference on resource-constrained hardware. This paper presents FITCompress, a method for unifying layer-wise mixed precision quantization and pruning under a single heuristic, as an alternative to neural architecture search and Bayesian-based techniques. FITCompress combines the Fisher Information Metric, and path planning through compression space, to pick optimal configurations given size and operation constraints with single-shot fine-tuning. Experiments on ImageNet validate the method and show that our approach yields a better trade-off between accuracy and efficiency when compared to the baselines. Besides computer vision benchmarks, we experiment with the BERT model on a language understanding task, paving the way towards its optimal compression.
Adaptive State-Dependent Diffusion for Derivative-Free Optimization
Feb 08, 2023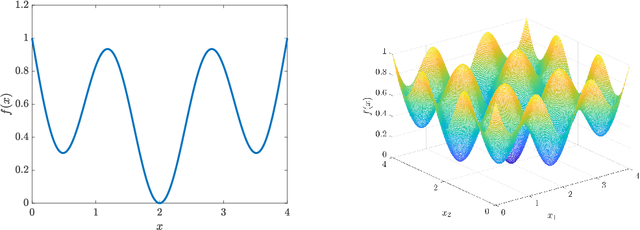
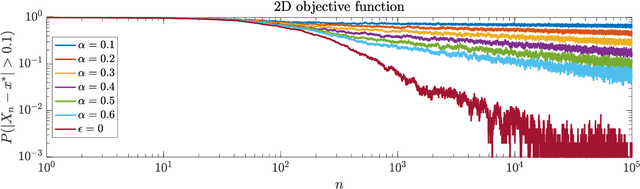
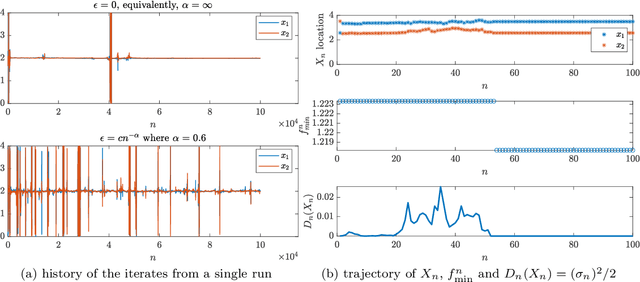
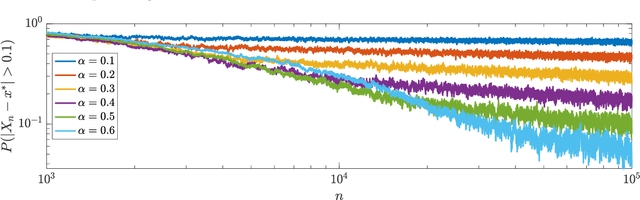
This paper develops and analyzes a stochastic derivative-free optimization strategy. A key feature is the state-dependent adaptive variance. We prove global convergence in probability with algebraic rate and give the quantitative results in numerical examples. A striking fact is that convergence is achieved without explicit information of the gradient and even without comparing different objective function values as in established methods such as the simplex method and simulated annealing. It can otherwise be compared to annealing with state-dependent temperature.
Anticipate, Ensemble and Prune: Improving Convolutional Neural Networks via Aggregated Early Exits
Jan 28, 2023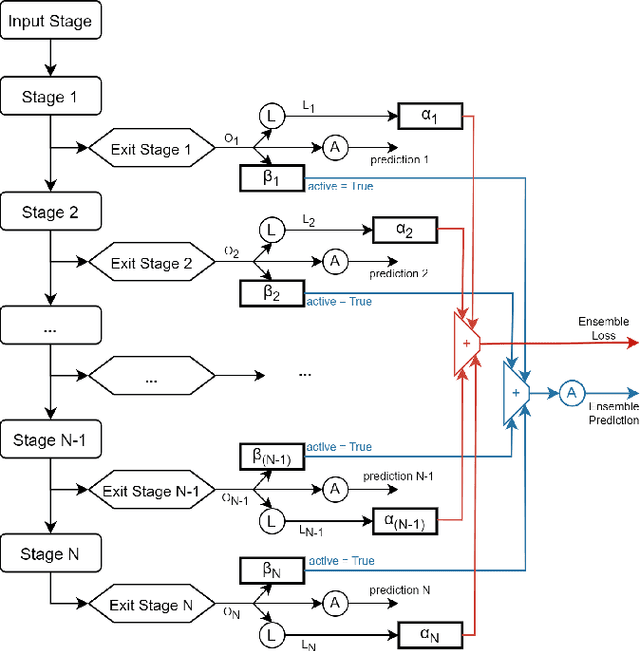

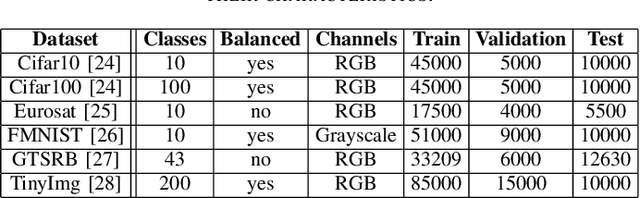
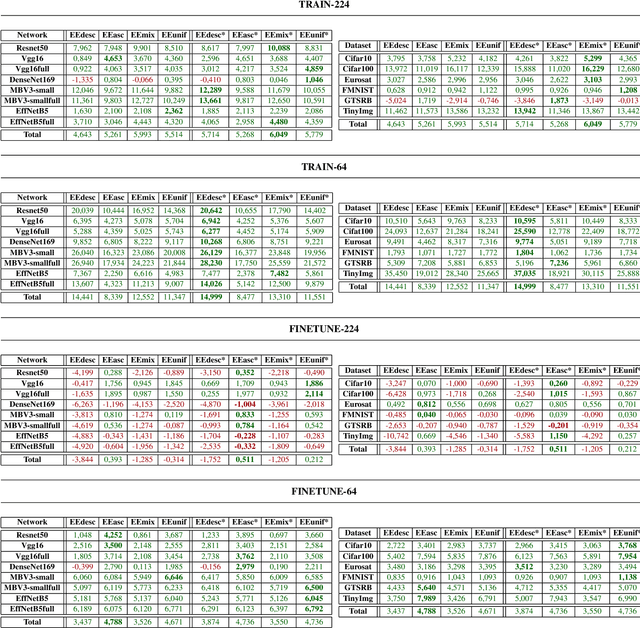
Today, artificial neural networks are the state of the art for solving a variety of complex tasks, especially in image classification. Such architectures consist of a sequence of stacked layers with the aim of extracting useful information and having it processed by a classifier to make accurate predictions. However, intermediate information within such models is often left unused. In other cases, such as in edge computing contexts, these architectures are divided into multiple partitions that are made functional by including early exits, i.e. intermediate classifiers, with the goal of reducing the computational and temporal load without extremely compromising the accuracy of the classifications. In this paper, we present Anticipate, Ensemble and Prune (AEP), a new training technique based on weighted ensembles of early exits, which aims at exploiting the information in the structure of networks to maximise their performance. Through a comprehensive set of experiments, we show how the use of this approach can yield average accuracy improvements of up to 15% over traditional training. In its hybrid-weighted configuration, AEP's internal pruning operation also allows reducing the number of parameters by up to 41%, lowering the number of multiplications and additions by 18% and the latency time to make inference by 16%. By using AEP, it is also possible to learn weights that allow early exits to achieve better accuracy values than those obtained from single-output reference models.
Counterfactual Fair Opportunity: Measuring Decision Model Fairness with Counterfactual Reasoning
Feb 16, 2023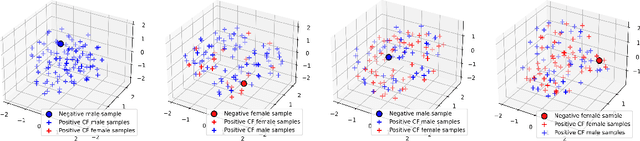

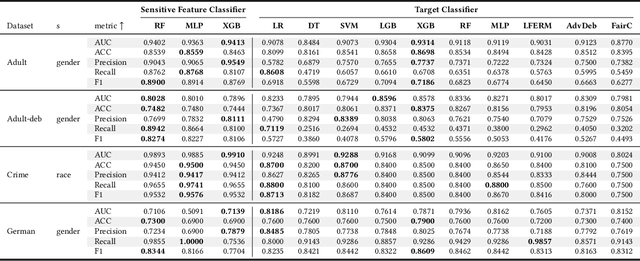
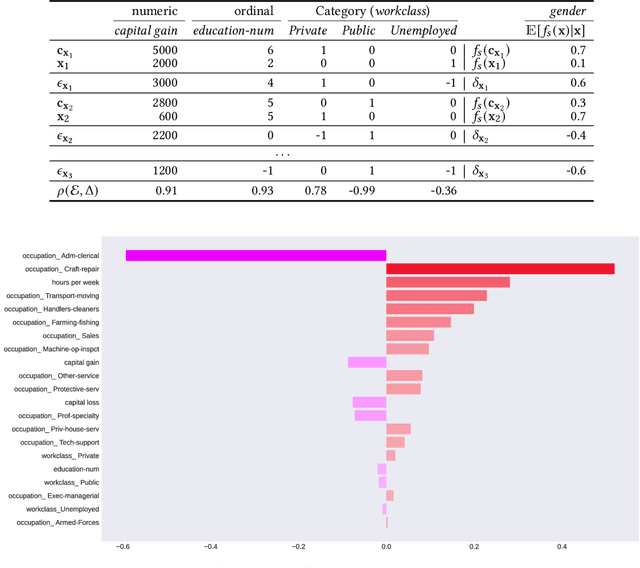
The increasing application of Artificial Intelligence and Machine Learning models poses potential risks of unfair behavior and, in light of recent regulations, has attracted the attention of the research community. Several researchers focused on seeking new fairness definitions or developing approaches to identify biased predictions. However, none try to exploit the counterfactual space to this aim. In that direction, the methodology proposed in this work aims to unveil unfair model behaviors using counterfactual reasoning in the case of fairness under unawareness setting. A counterfactual version of equal opportunity named counterfactual fair opportunity is defined and two novel metrics that analyze the sensitive information of counterfactual samples are introduced. Experimental results on three different datasets show the efficacy of our methodologies and our metrics, disclosing the unfair behavior of classic machine learning and debiasing models.
Controlled and Conditional Text to Image Generation with Diffusion Prior
Feb 23, 2023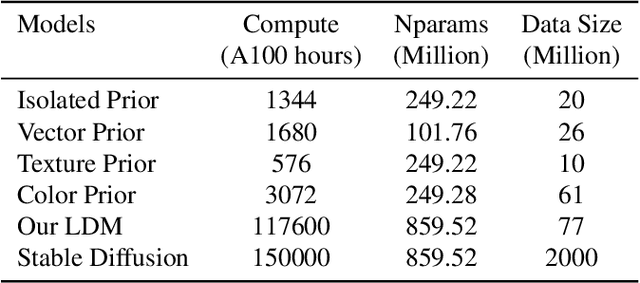
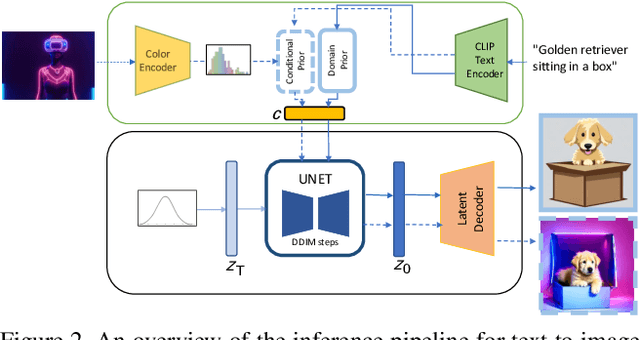
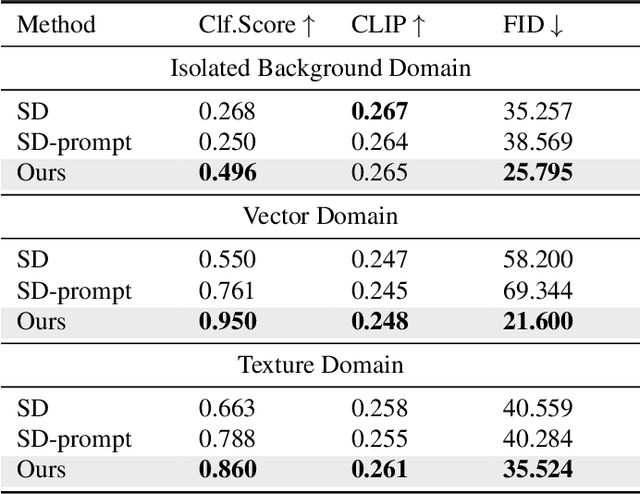

Denoising Diffusion models have shown remarkable performance in generating diverse, high quality images from text. Numerous techniques have been proposed on top of or in alignment with models like Stable Diffusion and Imagen that generate images directly from text. A lesser explored approach is DALLE-2's two step process comprising a Diffusion Prior that generates a CLIP image embedding from text and a Diffusion Decoder that generates an image from a CLIP image embedding. We explore the capabilities of the Diffusion Prior and the advantages of an intermediate CLIP representation. We observe that Diffusion Prior can be used in a memory and compute efficient way to constrain the generation to a specific domain without altering the larger Diffusion Decoder. Moreover, we show that the Diffusion Prior can be trained with additional conditional information such as color histogram to further control the generation. We show quantitatively and qualitatively that the proposed approaches perform better than prompt engineering for domain specific generation and existing baselines for color conditioned generation. We believe that our observations and results will instigate further research into the diffusion prior and uncover more of its capabilities.
Using Automated Algorithm Configuration for Parameter Control
Feb 23, 2023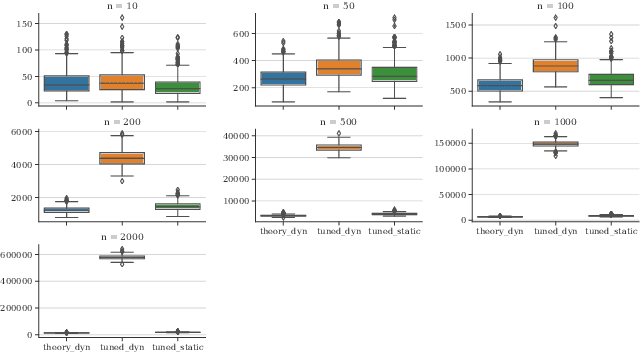
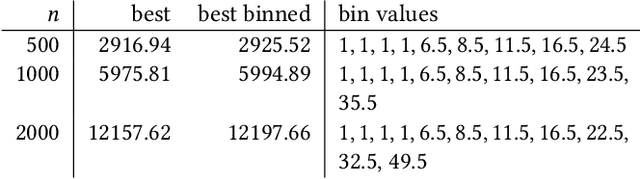
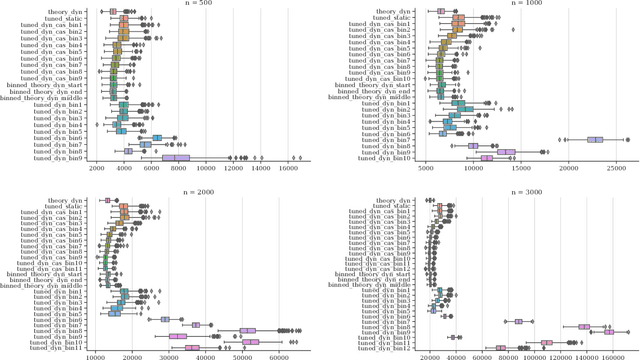
Dynamic Algorithm Configuration (DAC) tackles the question of how to automatically learn policies to control parameters of algorithms in a data-driven fashion. This question has received considerable attention from the evolutionary community in recent years. Having a good benchmark collection to gain structural understanding on the effectiveness and limitations of different solution methods for DAC is therefore strongly desirable. Following recent work on proposing DAC benchmarks with well-understood theoretical properties and ground truth information, in this work, we suggest as a new DAC benchmark the controlling of the key parameter $\lambda$ in the $(1+(\lambda,\lambda))$~Genetic Algorithm for solving OneMax problems. We conduct a study on how to solve the DAC problem via the use of (static) automated algorithm configuration on the benchmark, and propose techniques to significantly improve the performance of the approach. Our approach is able to consistently outperform the default parameter control policy of the benchmark derived from previous theoretical work on sufficiently large problem sizes. We also present new findings on the landscape of the parameter-control search policies and propose methods to compute stronger baselines for the benchmark via numerical approximations of the true optimal policies.
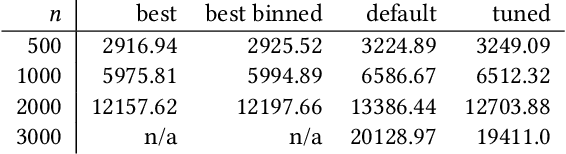
Change is Hard: A Closer Look at Subpopulation Shift
Feb 23, 2023
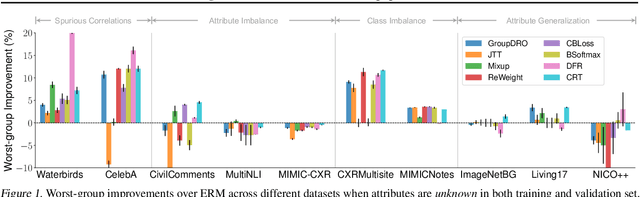
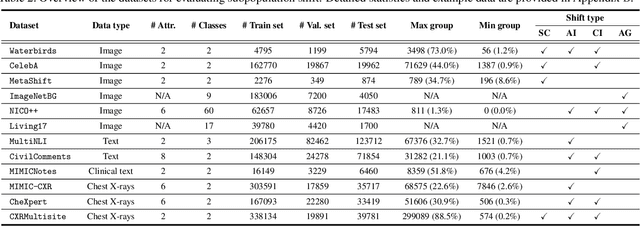
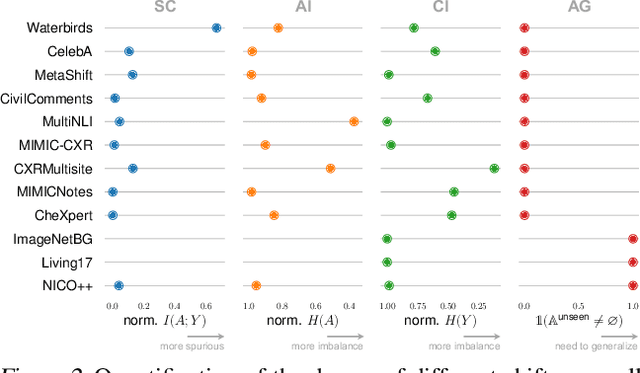
Machine learning models often perform poorly on subgroups that are underrepresented in the training data. Yet, little is understood on the variation in mechanisms that cause subpopulation shifts, and how algorithms generalize across such diverse shifts at scale. In this work, we provide a fine-grained analysis of subpopulation shift. We first propose a unified framework that dissects and explains common shifts in subgroups. We then establish a comprehensive benchmark of 20 state-of-the-art algorithms evaluated on 12 real-world datasets in vision, language, and healthcare domains. With results obtained from training over 10,000 models, we reveal intriguing observations for future progress in this space. First, existing algorithms only improve subgroup robustness over certain types of shifts but not others. Moreover, while current algorithms rely on group-annotated validation data for model selection, we find that a simple selection criterion based on worst-class accuracy is surprisingly effective even without any group information. Finally, unlike existing works that solely aim to improve worst-group accuracy (WGA), we demonstrate the fundamental tradeoff between WGA and other important metrics, highlighting the need to carefully choose testing metrics. Code and data are available at: https://github.com/YyzHarry/SubpopBench.
Cross-City Traffic Prediction via Semantic-Fused Hierarchical Graph Transfer Learning
Feb 23, 2023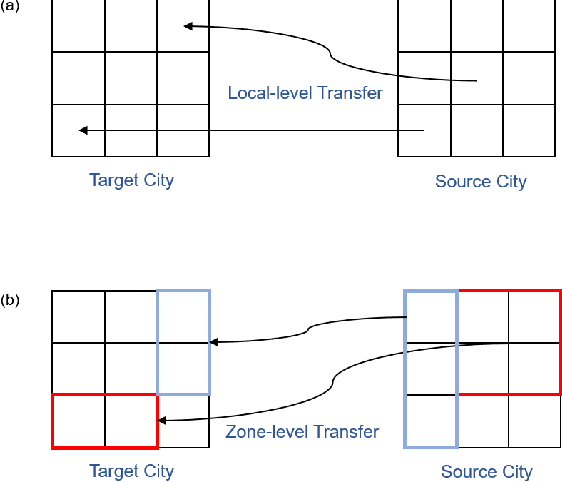
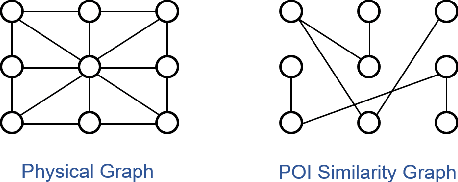
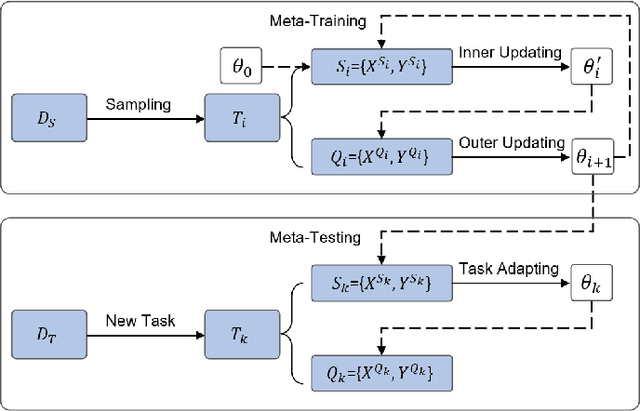
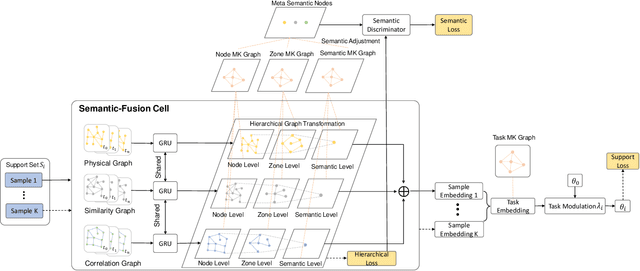
Accurate traffic prediction benefits urban management and improves transportation efficiency. Recently, data-driven methods have been widely applied in traffic prediction and outperformed traditional methods. However, data-driven methods normally require massive data for training, while data scarcity is ubiquitous in low-developmental or newly constructed regions. To tackle this problem, we can extract meta knowledge from data-rich cities to data-scarce cities via transfer learning. Besides, relations among urban regions can be organized into various semantic graphs, e.g. proximity and POI similarity, which is barely considered in previous studies. In this paper, we propose Semantic-Fused Hierarchical Graph Transfer Learning (SF-HGTL) model to achieve knowledge transfer across cities with fused semantics. In detail, we employ hierarchical graph transformation followed by meta-knowledge retrieval to achieve knowledge transfer in various granularity. In addition, we introduce meta semantic nodes to reduce the number of parameters as well as share information across semantics. Afterwards, the parameters of the base model are generated by fused semantic embeddings to predict traffic status in terms of task heterogeneity. We implement experiments on five real-world datasets and verify the effectiveness of our SF-HGTL model by comparing it with other baselines.
EquiPocket: an E(3)-Equivariant Geometric Graph Neural Network for Ligand Binding Site Prediction
Feb 23, 2023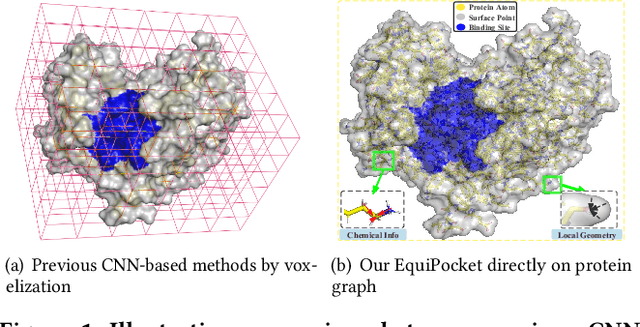
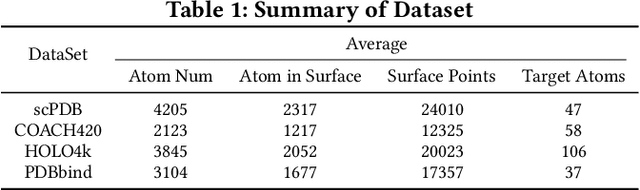
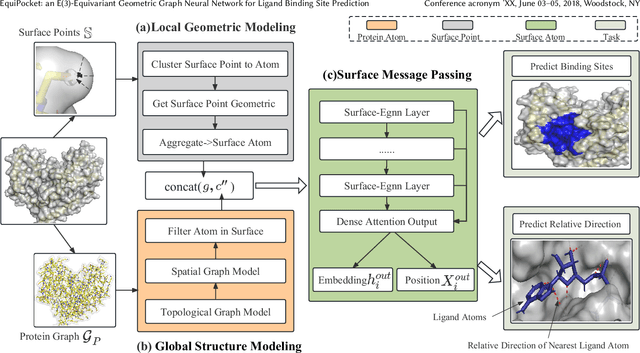
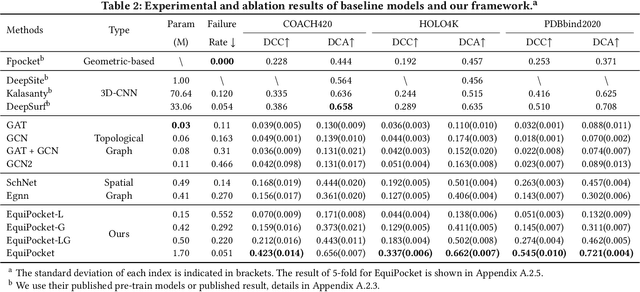
Predicting the binding sites of the target proteins plays a fundamental role in drug discovery. Most existing deep-learning methods consider a protein as a 3D image by spatially clustering its atoms into voxels and then feed the voxelized protein into a 3D CNN for prediction. However, the CNN-based methods encounter several critical issues: 1) defective in representing irregular protein structures; 2) sensitive to rotations; 3) insufficient to characterize the protein surface; 4) unaware of data distribution shift. To address the above issues, this work proposes EquiPocket, an E(3)-equivariant Graph Neural Network (GNN) for binding site prediction. In particular, EquiPocket consists of three modules: the first one to extract local geometric information for each surface atom, the second one to model both the chemical and spatial structure of the protein, and the last one to capture the geometry of the surface via equivariant message passing over the surface atoms. We further propose a dense attention output layer to better alleviate the data distribution shift effect incurred by the variable protein size. Extensive experiments on several representative benchmarks demonstrate the superiority of our framework to the state-of-the-art methods.