 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
Feb 28, 2023
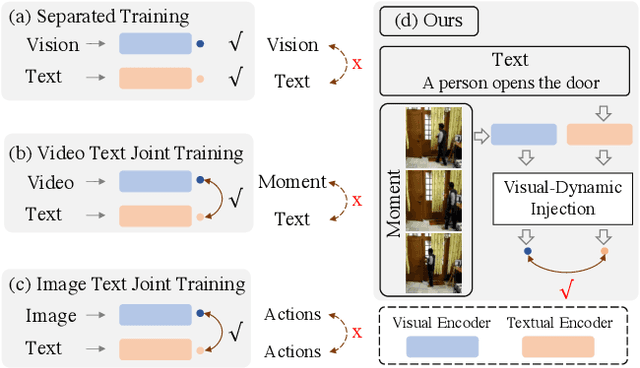
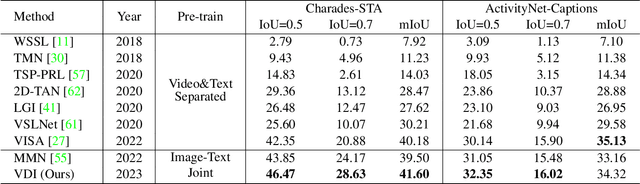
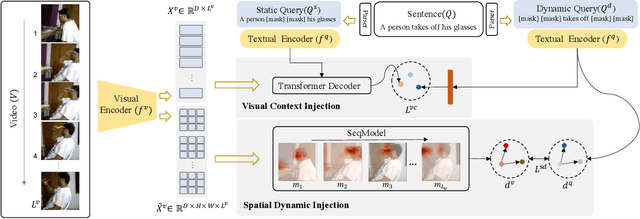
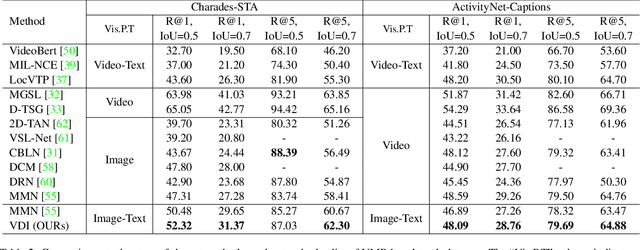
The correlation between the vision and text is essential for video moment retrieval (VMR), however, existing methods heavily rely on separate pre-training feature extractors for visual and textual understanding. Without sufficient temporal boundary annotations, it is non-trivial to learn universal video-text alignments. In this work, we explore multi-modal correlations derived from large-scale image-text data to facilitate generalisable VMR. To address the limitations of image-text pre-training models on capturing the video changes, we propose a generic method, referred to as Visual-Dynamic Injection (VDI), to empower the model's understanding of video moments. Whilst existing VMR methods are focusing on building temporal-aware video features, being aware of the text descriptions about the temporal changes is also critical but originally overlooked in pre-training by matching static images with sentences. Therefore, we extract visual context and spatial dynamic information from video frames and explicitly enforce their alignments with the phrases describing video changes (e.g. verb). By doing so, the potentially relevant visual and motion patterns in videos are encoded in the corresponding text embeddings (injected) so to enable more accurate video-text alignments. We conduct extensive experiments on two VMR benchmark datasets (Charades-STA and ActivityNet-Captions) and achieve state-of-the-art performances. Especially, VDI yields notable advantages when being tested on the out-of-distribution splits where the testing samples involve novel scenes and vocabulary.
An Efficient Tester-Learner for Halfspaces
Feb 28, 2023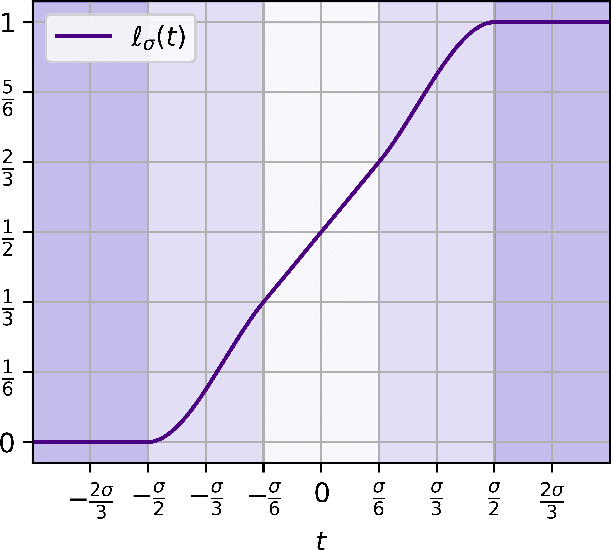
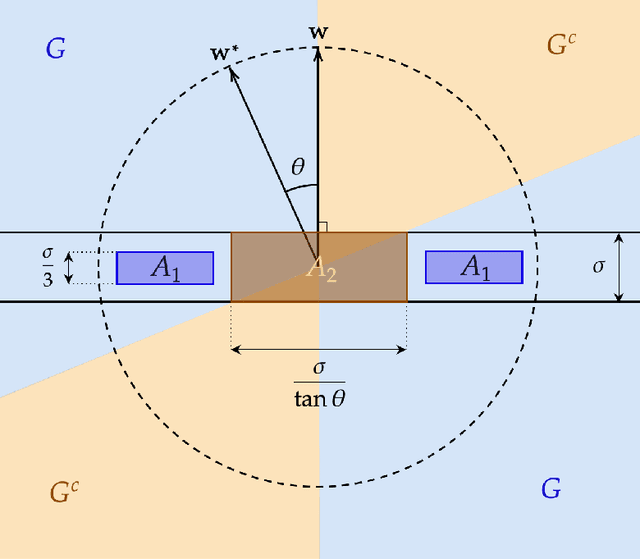
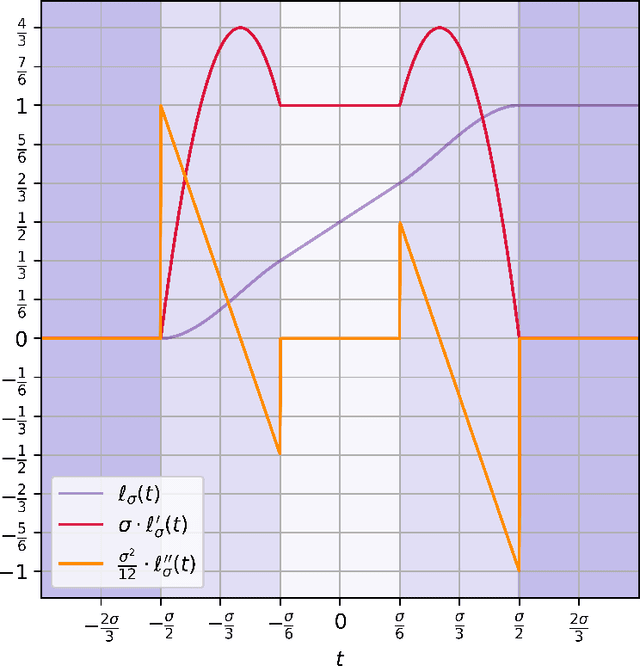
We give the first efficient algorithm for learning halfspaces in the testable learning model recently defined by Rubinfeld and Vasilyan (2023). In this model, a learner certifies that the accuracy of its output hypothesis is near optimal whenever the training set passes an associated test, and training sets drawn from some target distribution -- e.g., the Gaussian -- must pass the test. This model is more challenging than distribution-specific agnostic or Massart noise models where the learner is allowed to fail arbitrarily if the distributional assumption does not hold. We consider the setting where the target distribution is Gaussian (or more generally any strongly log-concave distribution) in $d$ dimensions and the noise model is either Massart or adversarial (agnostic). For Massart noise our tester-learner runs in polynomial time and outputs a hypothesis with error $\mathsf{opt} + \epsilon$, which is information-theoretically optimal. For adversarial noise our tester-learner has error $\tilde{O}(\mathsf{opt}) + \epsilon$ and runs in quasipolynomial time. Prior work on testable learning ignores the labels in the training set and checks that the empirical moments of the covariates are close to the moments of the base distribution. Here we develop new tests of independent interest that make critical use of the labels and combine them with the moment-matching approach of Gollakota et al. (2023). This enables us to simulate a variant of the algorithm of Diakonikolas et al. (2020) for learning noisy halfspaces using nonconvex SGD but in the testable learning setting.
Heuristic Modularity Maximization Algorithms for Community Detection Rarely Return an Optimal Partition or Anything Similar
Feb 28, 2023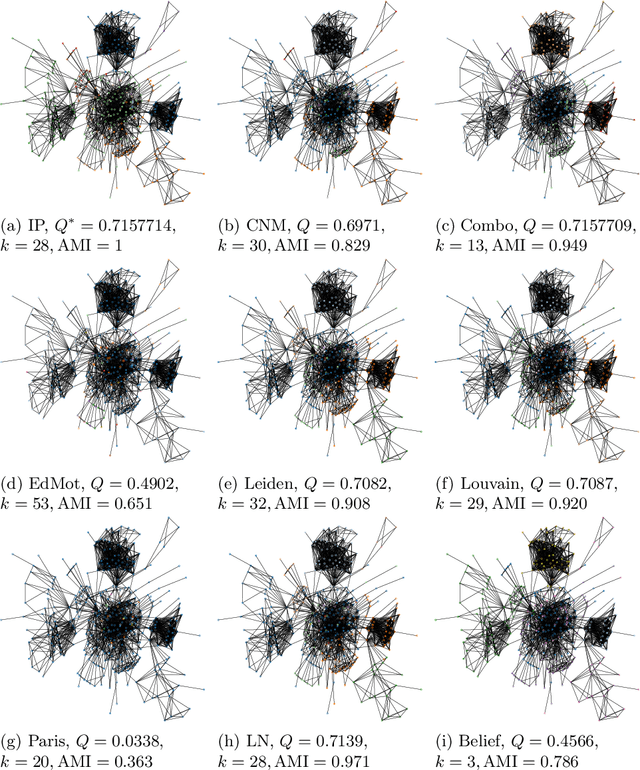

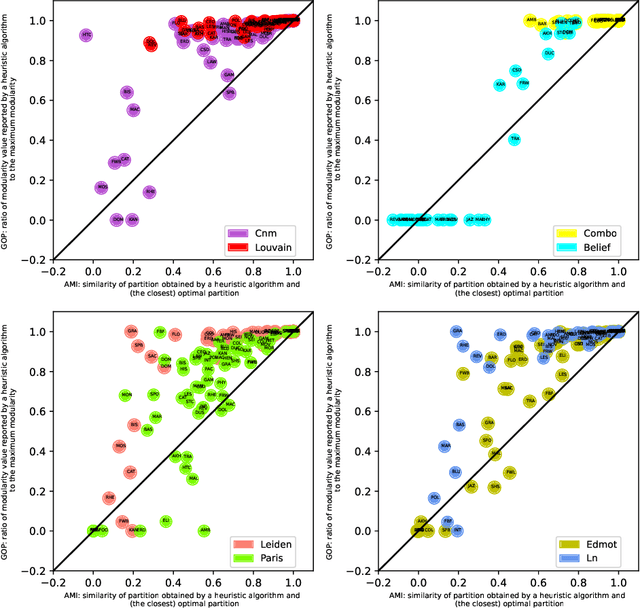
Community detection is a classic problem in network science with extensive applications in various fields. The most commonly used methods are the algorithms designed to maximize modularity over different partitions of the network nodes into communities. Using 80 real and random networks from a wide range of contexts, we investigate the extent to which current heuristic modularity maximization algorithms succeed in returning modularity-maximum (optimal) partitions. We evaluate (1) the ratio of their output modularity to the maximum modularity for each input graph and (2) the maximum similarity between their output partition and any optimal partition of that graph. Our computational experiments involve eight existing heuristic algorithms which we compare against an exact integer programming method that globally maximizes modularity. The average modularity-based heuristic algorithm returns optimal partitions for only 16.9% of the 80 graphs considered. Results on adjusted mutual information show considerable dissimilarity between the sub-optimal partitions and any optimal partitions of the graphs in our experiments. More importantly, our results show that near-optimal partitions tend to be disproportionally dissimilar to any optimal partition. Taken together, our analysis points to a crucial limitation of commonly used modularity-based algorithms for discovering communities: they rarely return an optimal partition or a partition resembling an optimal partition. Given this finding, developing an exact or approximate algorithm for modularity maximization is recommendable for a more methodologically sound usage of modularity in community detection.
Distributed Subweb Specifications for Traversing the Web
Feb 28, 2023
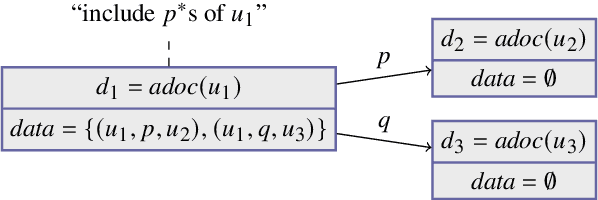
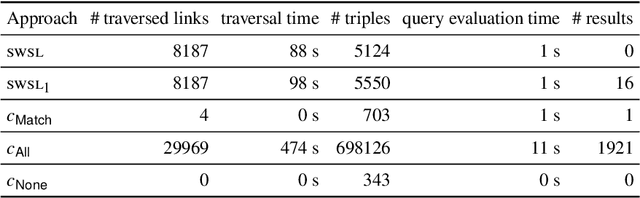
Link Traversal-based Query Processing (ltqp), in which a sparql query is evaluated over a web of documents rather than a single dataset, is often seen as a theoretically interesting yet impractical technique. However, in a time where the hypercentralization of data has increasingly come under scrutiny, a decentralized Web of Data with a simple document-based interface is appealing, as it enables data publishers to control their data and access rights. While ltqp allows evaluating complex queries over such webs, it suffers from performance issues (due to the high number of documents containing data) as well as information quality concerns (due to the many sources providing such documents). In existing ltqp approaches, the burden of finding sources to query is entirely in the hands of the data consumer. In this paper, we argue that to solve these issues, data publishers should also be able to suggest sources of interest and guide the data consumer towards relevant and trustworthy data. We introduce a theoretical framework that enables such guided link traversal and study its properties. We illustrate with a theoretic example that this can improve query results and reduce the number of network requests. We evaluate our proposal experimentally on a virtual linked web with specifications and indeed observe that not just the data quality but also the efficiency of querying improves. Under consideration in Theory and Practice of Logic Programming (TPLP).
An evaluation of Google Translate for Sanskrit to English translation via sentiment and semantic analysis
Feb 28, 2023
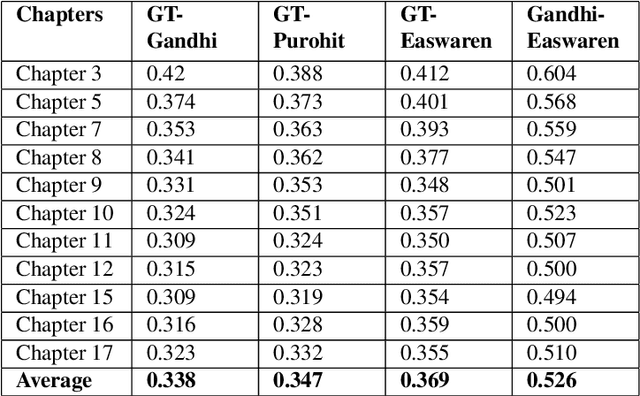
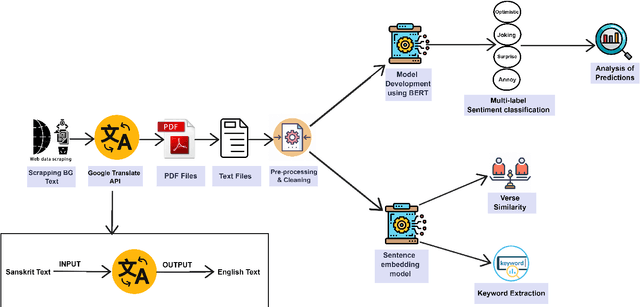
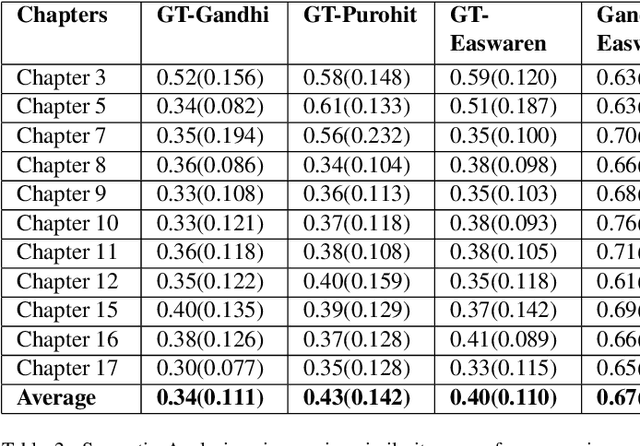
Google Translate has been prominent for language translation; however, limited work has been done in evaluating the quality of translation when compared to human experts. Sanskrit one of the oldest written languages in the world. In 2022, the Sanskrit language was added to the Google Translate engine. Sanskrit is known as the mother of languages such as Hindi and an ancient source of the Indo-European group of languages. Sanskrit is the original language for sacred Hindu texts such as the Bhagavad Gita. In this study, we present a framework that evaluates the Google Translate for Sanskrit using the Bhagavad Gita. We first publish a translation of the Bhagavad Gita in Sanskrit using Google Translate. Our framework then compares Google Translate version of Bhagavad Gita with expert translations using sentiment and semantic analysis via BERT-based language models. Our results indicate that in terms of sentiment and semantic analysis, there is low level of similarity in selected verses of Google Translate when compared to expert translations. In the qualitative evaluation, we find that Google translate is unsuitable for translation of certain Sanskrit words and phrases due to its poetic nature, contextual significance, metaphor and imagery. The mistranslations are not surprising since the Bhagavad Gita is known as a difficult text not only to translate, but also to interpret since it relies on contextual, philosophical and historical information. Our framework lays the foundation for automatic evaluation of other languages by Google Translate
Fair Attribute Completion on Graph with Missing Attributes
Feb 25, 2023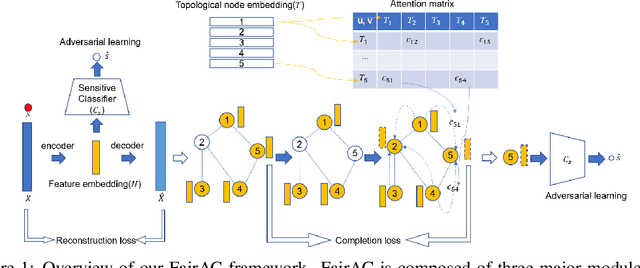
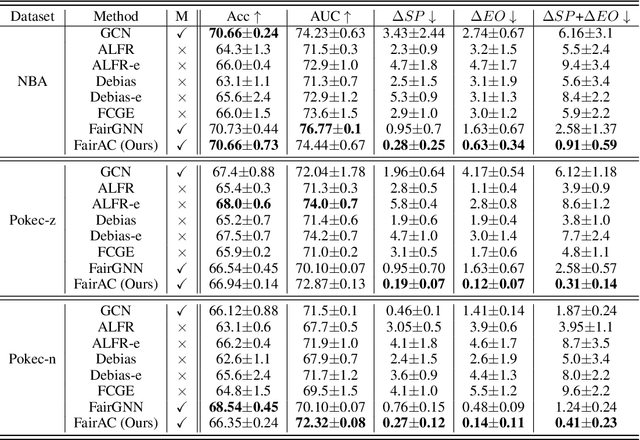
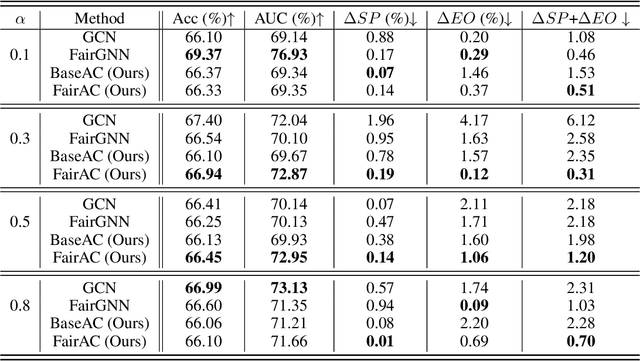
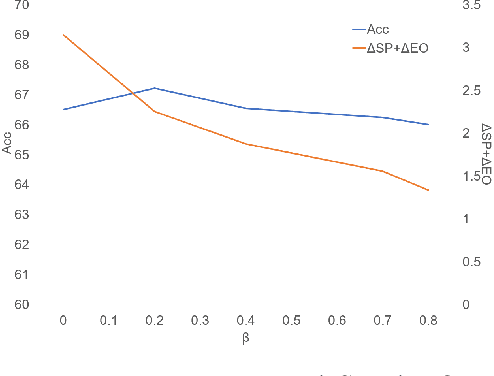
Tackling unfairness in graph learning models is a challenging task, as the unfairness issues on graphs involve both attributes and topological structures. Existing work on fair graph learning simply assumes that attributes of all nodes are available for model training and then makes fair predictions. In practice, however, the attributes of some nodes might not be accessible due to missing data or privacy concerns, which makes fair graph learning even more challenging. In this paper, we propose FairAC, a fair attribute completion method, to complement missing information and learn fair node embeddings for graphs with missing attributes. FairAC adopts an attention mechanism to deal with the attribute missing problem and meanwhile, it mitigates two types of unfairness, i.e., feature unfairness from attributes and topological unfairness due to attribute completion. FairAC can work on various types of homogeneous graphs and generate fair embeddings for them and thus can be applied to most downstream tasks to improve their fairness performance. To our best knowledge, FairAC is the first method that jointly addresses the graph attribution completion and graph unfairness problems. Experimental results on benchmark datasets show that our method achieves better fairness performance with less sacrifice in accuracy, compared with the state-of-the-art methods of fair graph learning.
Knowledge-infused Contrastive Learning for Urban Imagery-based Socioeconomic Prediction
Feb 25, 2023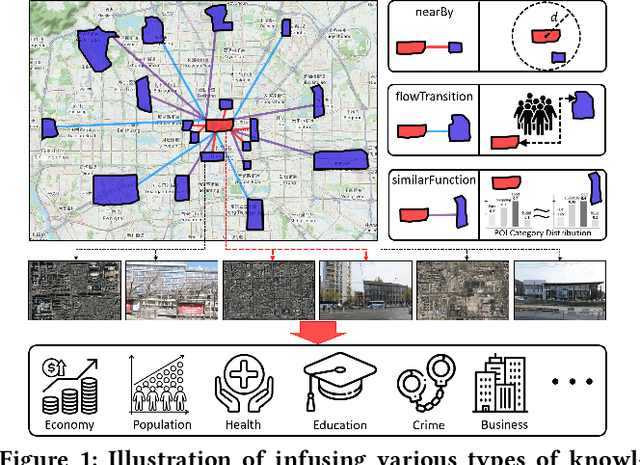
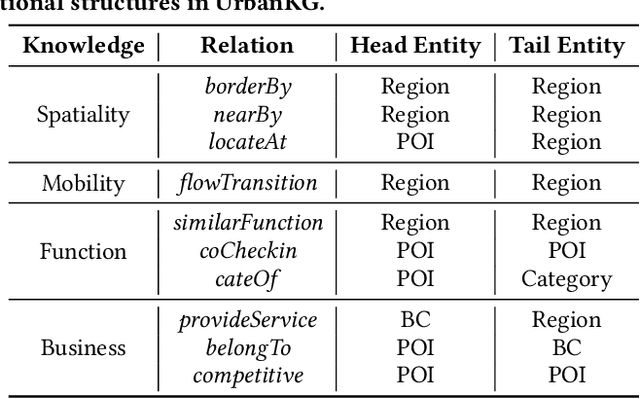
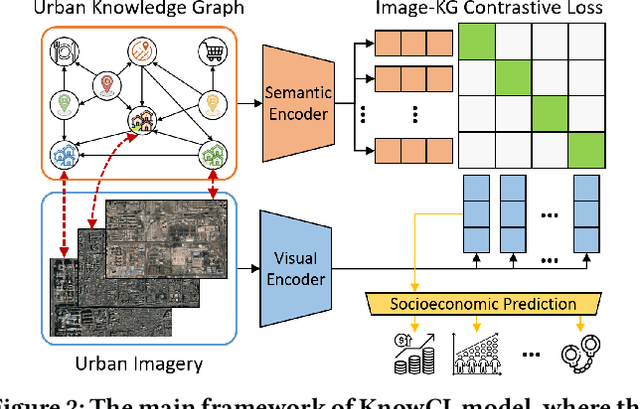
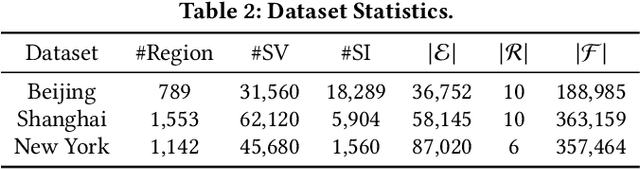
Monitoring sustainable development goals requires accurate and timely socioeconomic statistics, while ubiquitous and frequently-updated urban imagery in web like satellite/street view images has emerged as an important source for socioeconomic prediction. Especially, recent studies turn to self-supervised contrastive learning with manually designed similarity metrics for urban imagery representation learning and further socioeconomic prediction, which however suffers from effectiveness and robustness issues. To address such issues, in this paper, we propose a Knowledge-infused Contrastive Learning (KnowCL) model for urban imagery-based socioeconomic prediction. Specifically, we firstly introduce knowledge graph (KG) to effectively model the urban knowledge in spatiality, mobility, etc., and then build neural network based encoders to learn representations of an urban image in associated semantic and visual spaces, respectively. Finally, we design a cross-modality based contrastive learning framework with a novel image-KG contrastive loss, which maximizes the mutual information between semantic and visual representations for knowledge infusion. Extensive experiments of applying the learnt visual representations for socioeconomic prediction on three datasets demonstrate the superior performance of KnowCL with over 30\% improvements on $R^2$ compared with baselines. Especially, our proposed KnowCL model can apply to both satellite and street imagery with both effectiveness and transferability achieved, which provides insights into urban imagery-based socioeconomic prediction.
A Surrogate-Assisted Highly Cooperative Coevolutionary Algorithm for Hyperparameter Optimization in Deep Convolutional Neural Network
Feb 25, 2023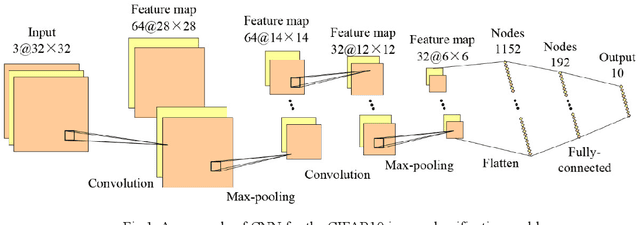
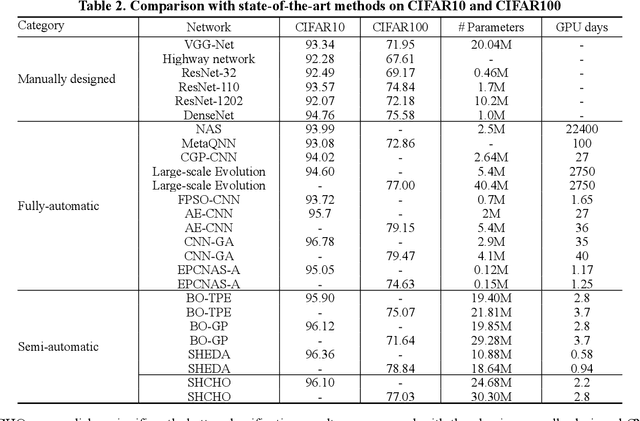

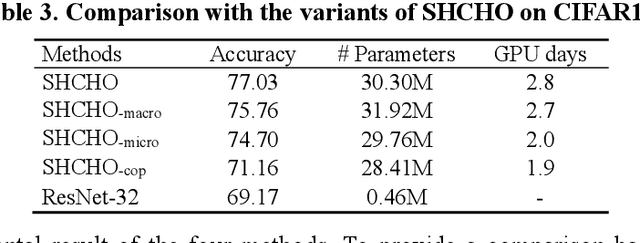
Convolutional neural networks (CNNs) have gained remarkable success in recent years. However, their performance highly relies on the architecture hyperparameters, and finding proper hyperparameters for a deep CNN is a challenging optimization problem owing to its high-dimensional and computationally expensive characteristics. Given these difficulties, this study proposes a surrogate-assisted highly cooperative hyperparameter optimization (SHCHO) algorithm for chain-styled CNNs. To narrow the large search space, SHCHO first decomposes the whole CNN into several overlapping sub-CNNs in accordance with the overlapping hyperparameter interaction structure and then cooperatively optimizes these hyperparameter subsets. Two cooperation mechanisms are designed during this process. One coordinates all the sub-CNNs to reproduce the information flow in the whole CNN and achieve macro cooperation among them, and the other tackles the overlapping components by simultaneously considering the involved two sub-CNNs and facilitates micro cooperation between them. As a result, a proper hyperparameter configuration can be effectively located for the whole CNN. Besides, SHCHO also employs the well-performing surrogate technique to assist in the hyperparameter optimization of each sub-CNN, thereby greatly reducing the expensive computational cost. Extensive experimental results on two widely-used image classification datasets indicate that SHCHO can significantly improve the performance of CNNs.
Knowledge Graph Completion with Counterfactual Augmentation
Feb 25, 2023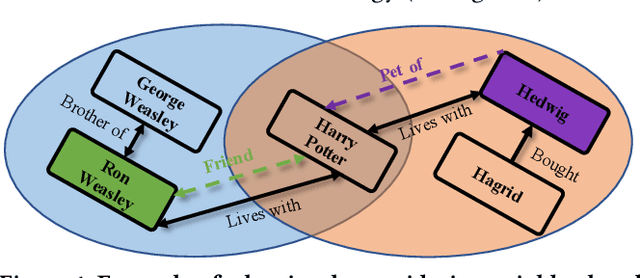
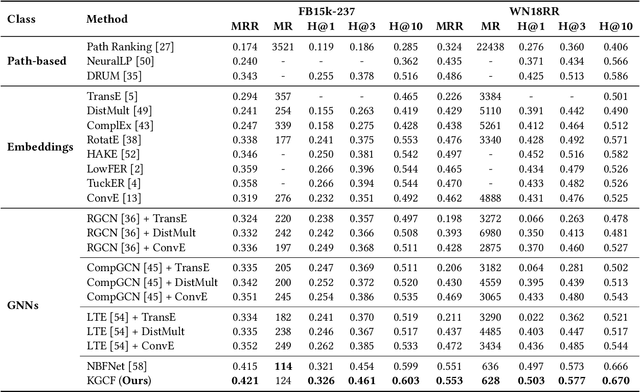
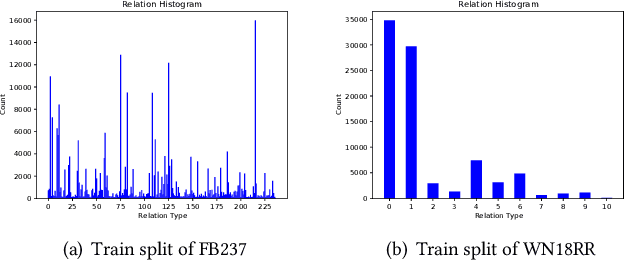

Graph Neural Networks (GNNs) have demonstrated great success in Knowledge Graph Completion (KGC) by modeling how entities and relations interact in recent years. However, most of them are designed to learn from the observed graph structure, which appears to have imbalanced relation distribution during the training stage. Motivated by the causal relationship among the entities on a knowledge graph, we explore this defect through a counterfactual question: "would the relation still exist if the neighborhood of entities became different from observation?". With a carefully designed instantiation of a causal model on the knowledge graph, we generate the counterfactual relations to answer the question by regarding the representations of entity pair given relation as context, structural information of relation-aware neighborhood as treatment, and validity of the composed triplet as the outcome. Furthermore, we incorporate the created counterfactual relations with the GNN-based framework on KGs to augment their learning of entity pair representations from both the observed and counterfactual relations. Experiments on benchmarks show that our proposed method outperforms existing methods on the task of KGC, achieving new state-of-the-art results. Moreover, we demonstrate that the proposed counterfactual relations-based augmentation also enhances the interpretability of the GNN-based framework through the path interpretations of predictions.
Time Encoding Sampling of Bandpass Signals
Feb 15, 2023This paper investigates the problem of sampling and reconstructing bandpass signals using time encoding machine(TEM). It is shown that the sampling in principle is equivalent to periodic non-uniform sampling (PNS). Then the TEM parameters can be set according to the signal bandwidth and amplitude instead of upper-edge frequency and amplitude as in the case of bandlimited/lowpass signals. For a bandpass signal of a single information band, it can be perfectly reconstructed if the TEM parameters are such that the difference between any consecutive values of the time sequence in each channel is bounded by the inverse of the signal bandwidth. A reconstruction method incorporating the interpolation functions of PNS is proposed. Numerical experiments validate the feasibility and effectiveness of the proposed TEM scheme.