 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video-SwinUNet: Spatio-temporal Deep Learning Framework for VFSS Instance Segmentation
Feb 22, 2023
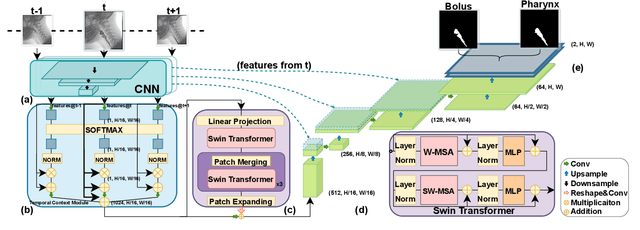
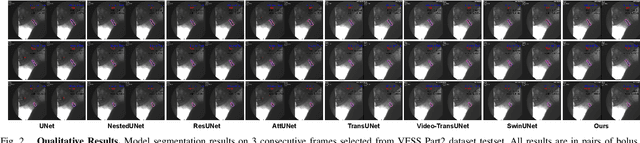
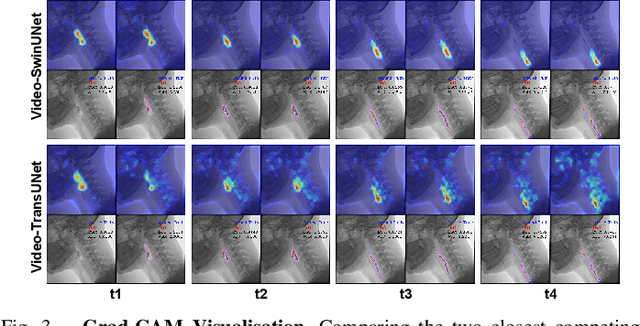
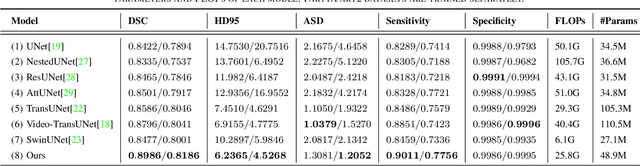
This paper presents a deep learning framework for medical video segmentation. Convolution neural network (CNN) and transformer-based methods have achieved great milestones in medical image segmentation tasks due to their incredible semantic feature encoding and global information comprehension abilities. However, most existing approaches ignore a salient aspect of medical video data - the temporal dimension. Our proposed framework explicitly extracts features from neighbouring frames across the temporal dimension and incorporates them with a temporal feature blender, which then tokenises the high-level spatio-temporal feature to form a strong global feature encoded via a Swin Transformer. The final segmentation results are produced via a UNet-like encoder-decoder architecture. Our model outperforms other approaches by a significant margin and improves the segmentation benchmarks on the VFSS2022 dataset, achieving a dice coefficient of 0.8986 and 0.8186 for the two datasets tested. Our studies also show the efficacy of the temporal feature blending scheme and cross-dataset transferability of learned capabilities. Code and models are fully available at https://github.com/SimonZeng7108/Video-SwinUNet.
Aggregation of Disentanglement: Reconsidering Domain Variations in Domain Generalization
Feb 05, 2023
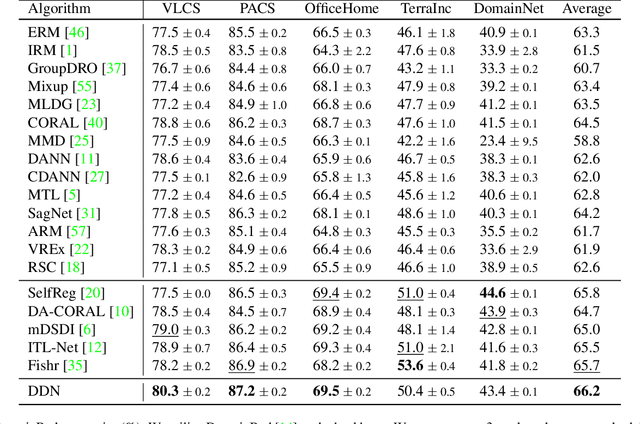
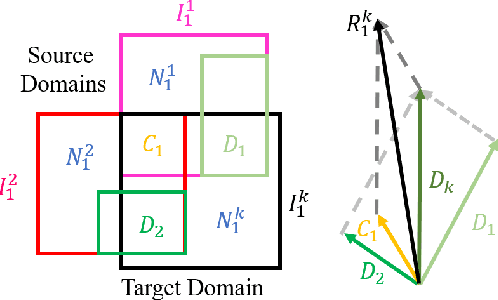

Domain Generalization (DG) is a fundamental challenge for machine learning models, which aims to improve model generalization on various domains. Previous methods focus on generating domain invariant features from various source domains. However, we argue that the domain variantions also contain useful information, ie, classification-aware information, for downstream tasks, which has been largely ignored. Different from learning domain invariant features from source domains, we decouple the input images into Domain Expert Features and noise. The proposed domain expert features lie in a learned latent space where the images in each domain can be classified independently, enabling the implicit use of classification-aware domain variations. Based on the analysis, we proposed a novel paradigm called Domain Disentanglement Network (DDN) to disentangle the domain expert features from the source domain images and aggregate the source domain expert features for representing the target test domain. We also propound a new contrastive learning method to guide the domain expert features to form a more balanced and separable feature space. Experiments on the widely-used benchmarks of PACS, VLCS, OfficeHome, DomainNet, and TerraIncognita demonstrate the competitive performance of our method compared to the recently proposed alternatives.
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 20, 2023
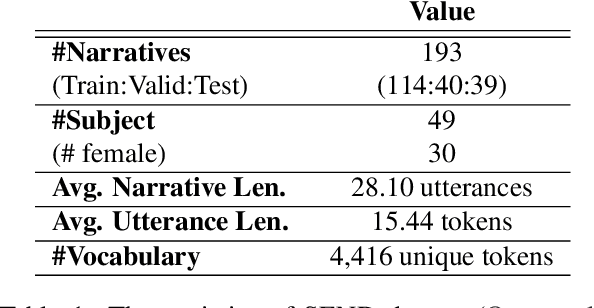

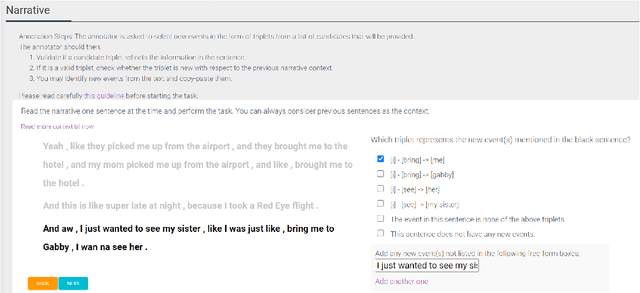
Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
3D Target Detection and Spectral Classification for Single-photon LiDAR Data
Feb 20, 2023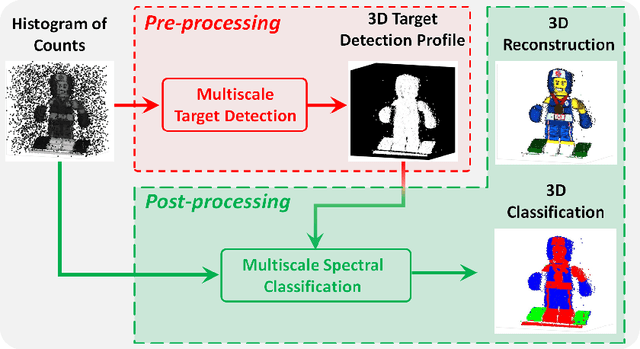
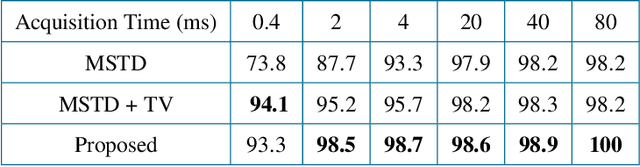
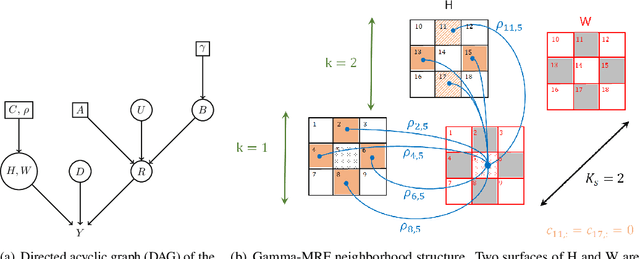
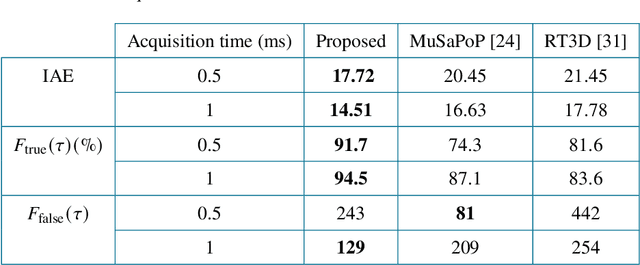
3D single-photon LiDAR imaging has an important role in many applications. However, full deployment of this modality will require the analysis of low signal to noise ratio target returns and a very high volume of data. This is particularly evident when imaging through obscurants or in high ambient background light conditions. This paper proposes a multiscale approach for 3D surface detection from the photon timing histogram to permit a significant reduction in data volume. The resulting surfaces are background-free and can be used to infer depth and reflectivity information about the target. We demonstrate this by proposing a hierarchical Bayesian model for 3D reconstruction and spectral classification of multispectral single-photon LiDAR data. The reconstruction method promotes spatial correlation between point-cloud estimates and uses a coordinate gradient descent algorithm for parameter estimation. Results on simulated and real data show the benefits of the proposed target detection and reconstruction approaches when compared to state-of-the-art processing algorithms
Efficient Algorithms for Boundary Defense with Heterogeneous Defenders
Feb 20, 2023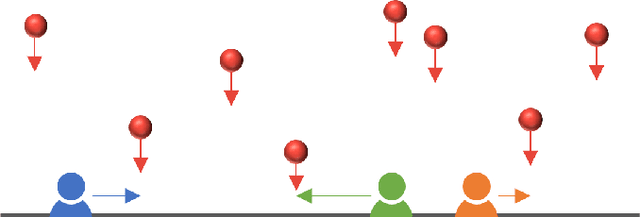
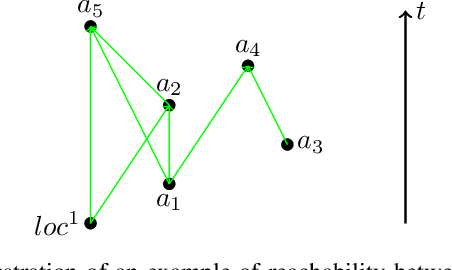
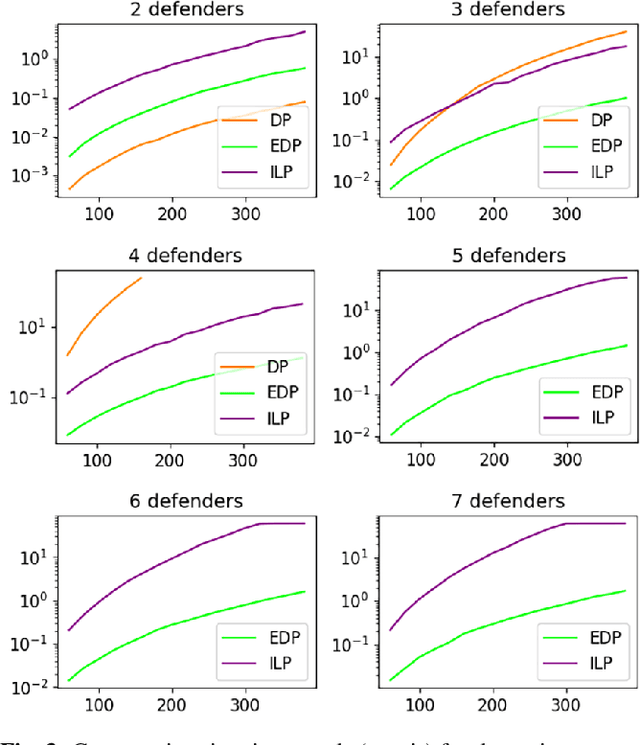
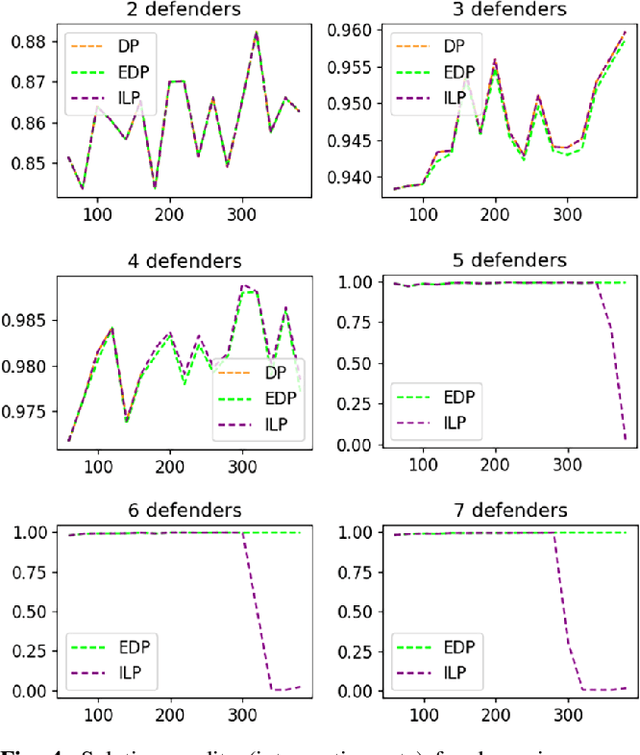
This paper studies the problem of defending (1D and 2D) boundaries against a large number of continuous attacks with a heterogeneous group of defenders. The defender team has perfect information of the attack events within some time (finite or infinite) horizon, with the goal of intercepting as many attacks as possible. An attack is considered successfully intercepted if a defender is present at the boundary location when and where the attack happens. Through proposing a network-flow and integer programming-based method for computing optimal solutions, and an exhaustive defender pairing heuristic method for computing near-optimal solutions, we are able to significantly reduce the computation burden in solving the problem in comparison to the previous state of the art. Extensive simulation experiments confirm the effectiveness of the algorithms. Leveraging our efficient methods, we also characterize the solution structures, revealing the relationships between the attack interception rate and the various problem parameters, e.g., the heterogeneity of the defenders, attack rate, boundary topology, and the look-ahead horizon.
Finding Heterophilic Neighbors via Confidence-based Subgraph Matching for Semi-supervised Node Classification
Feb 20, 2023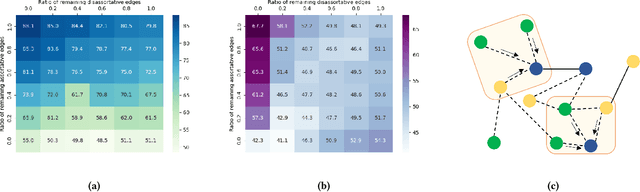
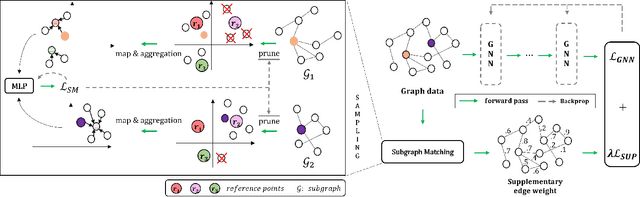
Graph Neural Networks (GNNs) have proven to be powerful in many graph-based applications. However, they fail to generalize well under heterophilic setups, where neighbor nodes have different labels. To address this challenge, we employ a confidence ratio as a hyper-parameter, assuming that some of the edges are disassortative (heterophilic). Here, we propose a two-phased algorithm. Firstly, we determine edge coefficients through subgraph matching using a supplementary module. Then, we apply GNNs with a modified label propagation mechanism to utilize the edge coefficients effectively. Specifically, our supplementary module identifies a certain proportion of task-irrelevant edges based on a given confidence ratio. Using the remaining edges, we employ the widely used optimal transport to measure the similarity between two nodes with their subgraphs. Finally, using the coefficients as supplementary information on GNNs, we improve the label propagation mechanism which can prevent two nodes with smaller weights from being closer. The experiments on benchmark datasets show that our model alleviates over-smoothing and improves performance.
Efficient and Low Overhead Website Fingerprinting Attacks and Defenses based on TCP/IP Traffic
Feb 27, 2023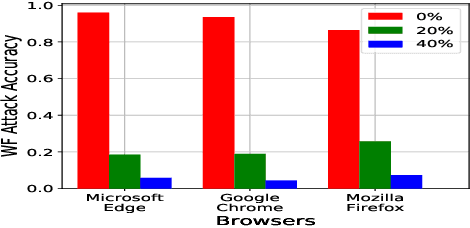
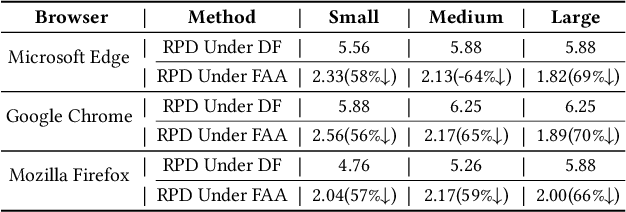
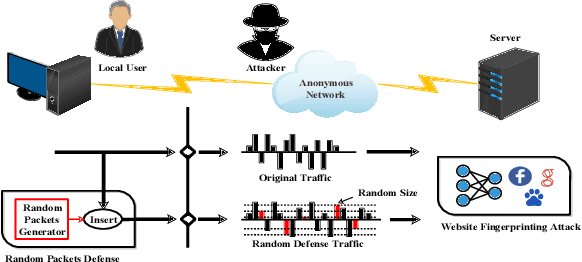
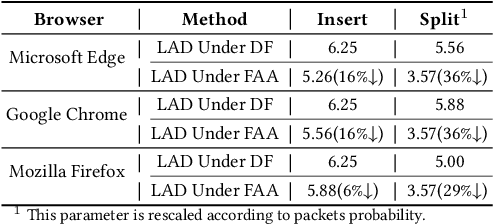
Website fingerprinting attack is an extensively studied technique used in a web browser to analyze traffic patterns and thus infer confidential information about users. Several website fingerprinting attacks based on machine learning and deep learning tend to use the most typical features to achieve a satisfactory performance of attacking rate. However, these attacks suffer from several practical implementation factors, such as a skillfully pre-processing step or a clean dataset. To defend against such attacks, random packet defense (RPD) with a high cost of excessive network overhead is usually applied. In this work, we first propose a practical filter-assisted attack against RPD, which can filter out the injected noises using the statistical characteristics of TCP/IP traffic. Then, we propose a list-assisted defensive mechanism to defend the proposed attack method. To achieve a configurable trade-off between the defense and the network overhead, we further improve the list-based defense by a traffic splitting mechanism, which can combat the mentioned attacks as well as save a considerable amount of network overhead. In the experiments, we collect real-life traffic patterns using three mainstream browsers, i.e., Microsoft Edge, Google Chrome, and Mozilla Firefox, and extensive results conducted on the closed and open-world datasets show the effectiveness of the proposed algorithms in terms of defense accuracy and network efficiency.
DuEqNet: Dual-Equivariance Network in Outdoor 3D Object Detection for Autonomous Driving
Feb 27, 2023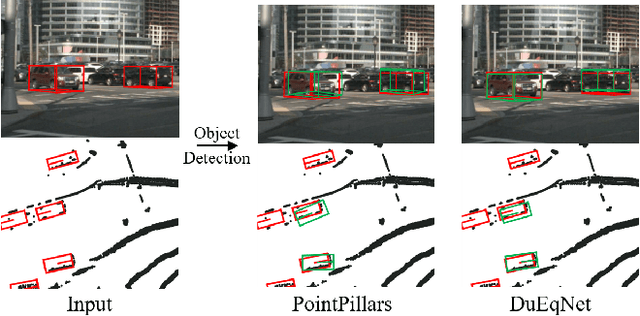
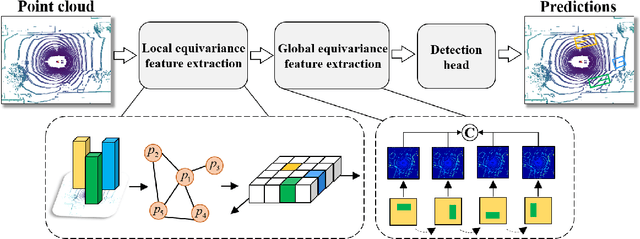
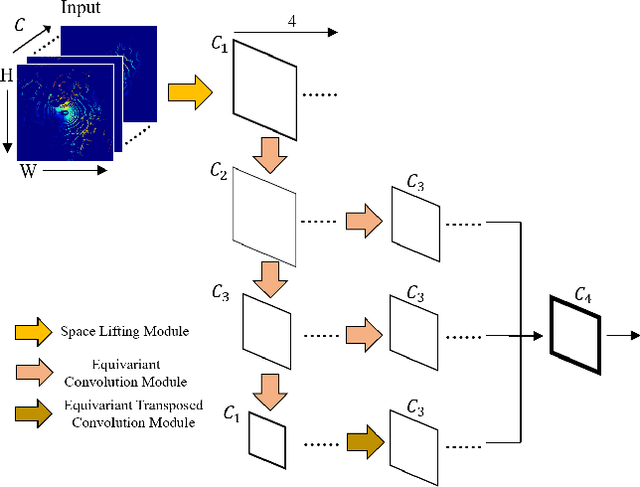
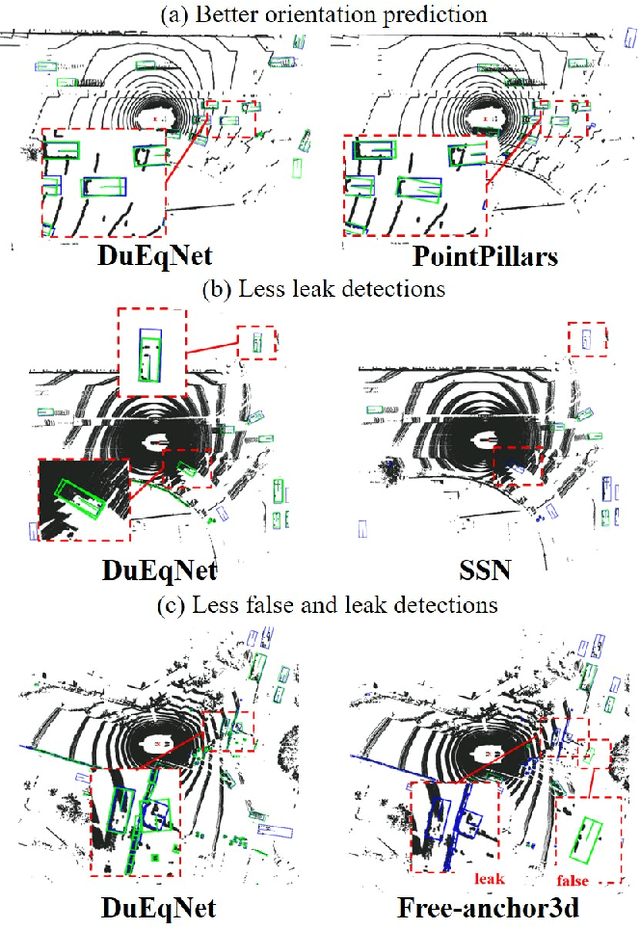
Outdoor 3D object detection has played an essential role in the environment perception of autonomous driving. In complicated traffic situations, precise object recognition provides indispensable information for prediction and planning in the dynamic system, improving self-driving safety and reliability. However, with the vehicle's veering, the constant rotation of the surrounding scenario makes a challenge for the perception systems. Yet most existing methods have not focused on alleviating the detection accuracy impairment brought by the vehicle's rotation, especially in outdoor 3D detection. In this paper, we propose DuEqNet, which first introduces the concept of equivariance into 3D object detection network by leveraging a hierarchical embedded framework. The dual-equivariance of our model can extract the equivariant features at both local and global levels, respectively. For the local feature, we utilize the graph-based strategy to guarantee the equivariance of the feature in point cloud pillars. In terms of the global feature, the group equivariant convolution layers are adopted to aggregate the local feature to achieve the global equivariance. In the experiment part, we evaluate our approach with different baselines in 3D object detection tasks and obtain State-Of-The-Art performance. According to the results, our model presents higher accuracy on orientation and better prediction efficiency. Moreover, our dual-equivariance strategy exhibits the satisfied plug-and-play ability on various popular object detection frameworks to improve their performance.
Unleashing Text-to-Image Diffusion Models for Visual Perception
Mar 03, 2023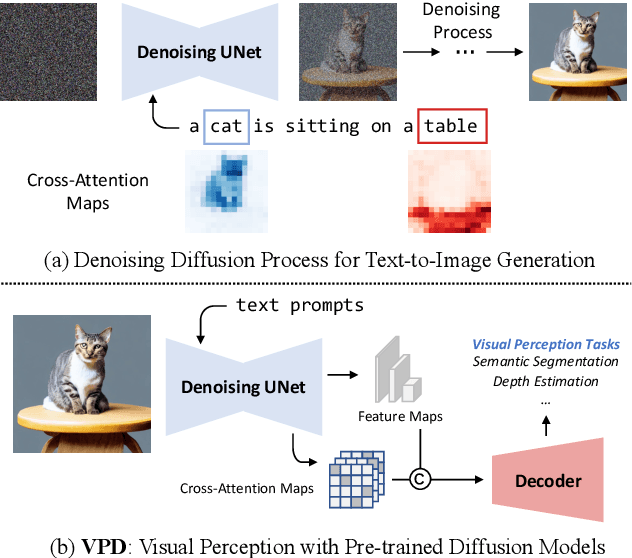
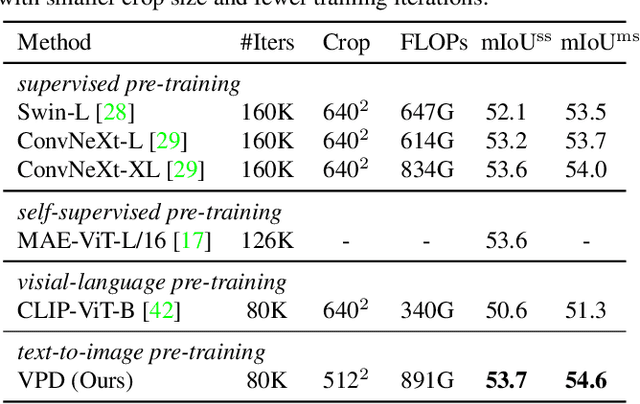
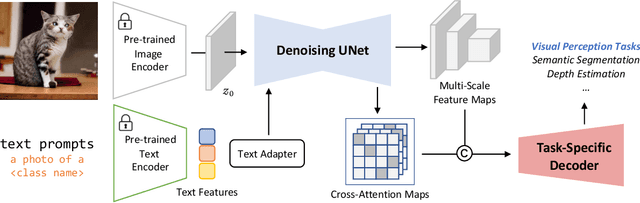
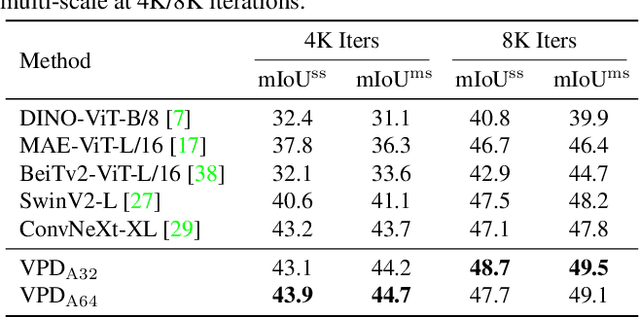
Diffusion models (DMs) have become the new trend of generative models and have demonstrated a powerful ability of conditional synthesis. Among those, text-to-image diffusion models pre-trained on large-scale image-text pairs are highly controllable by customizable prompts. Unlike the unconditional generative models that focus on low-level attributes and details, text-to-image diffusion models contain more high-level knowledge thanks to the vision-language pre-training. In this paper, we propose VPD (Visual Perception with a pre-trained Diffusion model), a new framework that exploits the semantic information of a pre-trained text-to-image diffusion model in visual perception tasks. Instead of using the pre-trained denoising autoencoder in a diffusion-based pipeline, we simply use it as a backbone and aim to study how to take full advantage of the learned knowledge. Specifically, we prompt the denoising decoder with proper textual inputs and refine the text features with an adapter, leading to a better alignment to the pre-trained stage and making the visual contents interact with the text prompts. We also propose to utilize the cross-attention maps between the visual features and the text features to provide explicit guidance. Compared with other pre-training methods, we show that vision-language pre-trained diffusion models can be faster adapted to downstream visual perception tasks using the proposed VPD. Extensive experiments on semantic segmentation, referring image segmentation and depth estimation demonstrates the effectiveness of our method. Notably, VPD attains 0.254 RMSE on NYUv2 depth estimation and 73.3% oIoU on RefCOCO-val referring image segmentation, establishing new records on these two benchmarks. Code is available at https://github.com/wl-zhao/VPD
AutoMatch: A Large-scale Audio Beat Matching Benchmark for Boosting Deep Learning Assistant Video Editing
Mar 03, 2023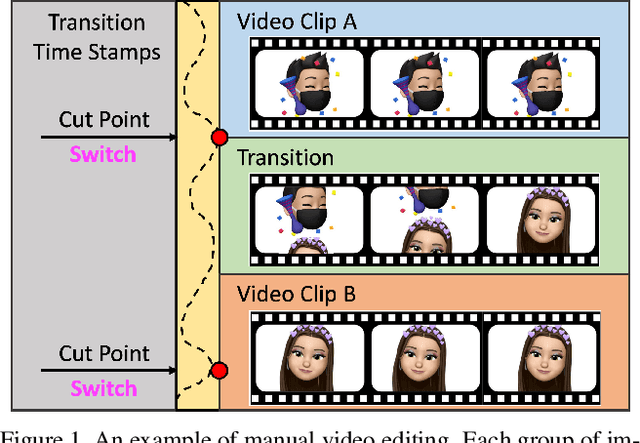
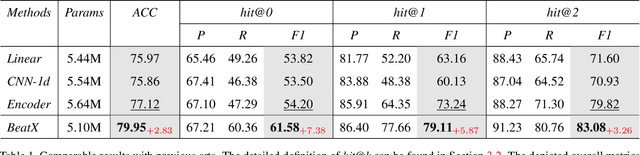
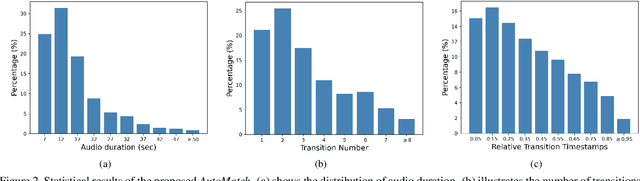
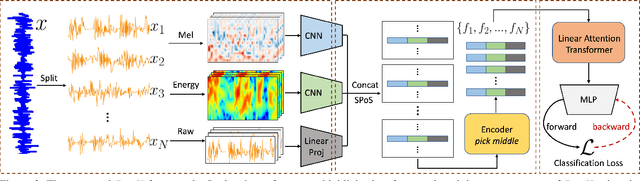
The explosion of short videos has dramatically reshaped the manners people socialize, yielding a new trend for daily sharing and access to the latest information. These rich video resources, on the one hand, benefited from the popularization of portable devices with cameras, but on the other, they can not be independent of the valuable editing work contributed by numerous video creators. In this paper, we investigate a novel and practical problem, namely audio beat matching (ABM), which aims to recommend the proper transition time stamps based on the background music. This technique helps to ease the labor-intensive work during video editing, saving energy for creators so that they can focus more on the creativity of video content. We formally define the ABM problem and its evaluation protocol. Meanwhile, a large-scale audio dataset, i.e., the AutoMatch with over 87k finely annotated background music, is presented to facilitate this newly opened research direction. To further lay solid foundations for the following study, we also propose a novel model termed BeatX to tackle this challenging task. Alongside, we creatively present the concept of label scope, which eliminates the data imbalance issues and assigns adaptive weights for the ground truth during the training procedure in one stop. Though plentiful short video platforms have flourished for a long time, the relevant research concerning this scenario is not sufficient, and to the best of our knowledge, AutoMatch is the first large-scale dataset to tackle the audio beat matching problem. We hope the released dataset and our competitive baseline can encourage more attention to this line of research. The dataset and codes will be made publicly available.