 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Practical Cross-system Shilling Attacks with Limited Access to Data
Feb 14, 2023
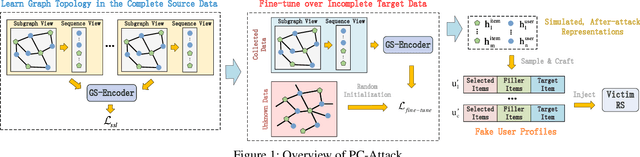
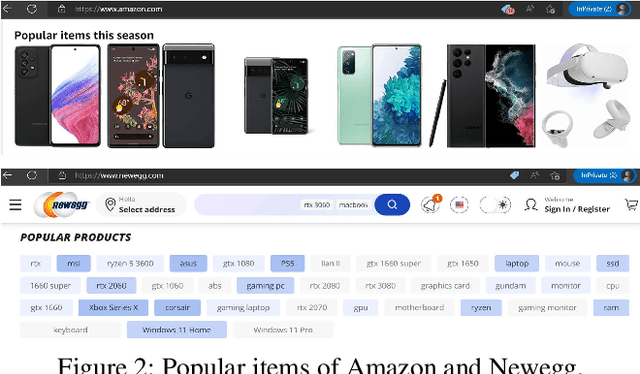
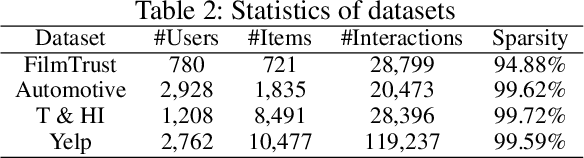
In shilling attacks, an adversarial party injects a few fake user profiles into a Recommender System (RS) so that the target item can be promoted or demoted. Although much effort has been devoted to developing shilling attack methods, we find that existing approaches are still far from practical. In this paper, we analyze the properties a practical shilling attack method should have and propose a new concept of Cross-system Attack. With the idea of Cross-system Attack, we design a Practical Cross-system Shilling Attack (PC-Attack) framework that requires little information about the victim RS model and the target RS data for conducting attacks. PC-Attack is trained to capture graph topology knowledge from public RS data in a self-supervised manner. Then, it is fine-tuned on a small portion of target data that is easy to access to construct fake profiles. Extensive experiments have demonstrated the superiority of PC-Attack over state-of-the-art baselines. Our implementation of PC-Attack is available at https://github.com/KDEGroup/PC-Attack.
Visibility-Aware Pixelwise View Selection for Multi-View Stereo Matching
Feb 14, 2023The performance of PatchMatch-based multi-view stereo algorithms depends heavily on the source views selected for computing matching costs. Instead of modeling the visibility of different views, most existing approaches handle occlusions in an ad-hoc manner. To address this issue, we propose a novel visibility-guided pixelwise view selection scheme in this paper. It progressively refines the set of source views to be used for each pixel in the reference view based on visibility information provided by already validated solutions. In addition, the Artificial Multi-Bee Colony (AMBC) algorithm is employed to search for optimal solutions for different pixels in parallel. Inter-colony communication is performed both within the same image and among different images. Fitness rewards are added to validated and propagated solutions, effectively enforcing the smoothness of neighboring pixels and allowing better handling of textureless areas. Experimental results on the DTU dataset show our method achieves state-of-the-art performance among non-learning-based methods and retrieves more details in occluded and low-textured regions.
PrefixMol: Target- and Chemistry-aware Molecule Design via Prefix Embedding
Feb 14, 2023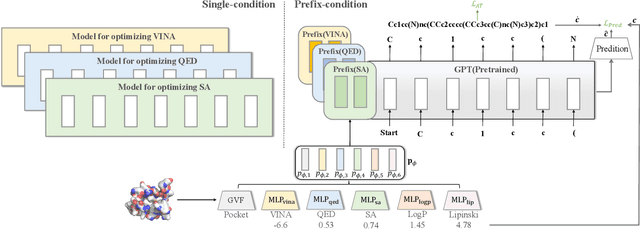
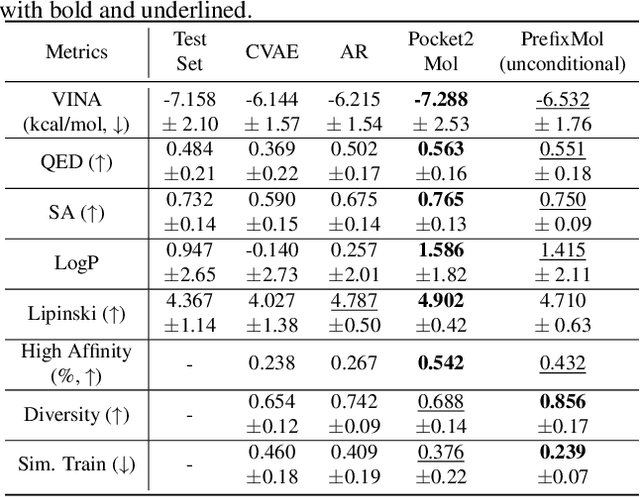

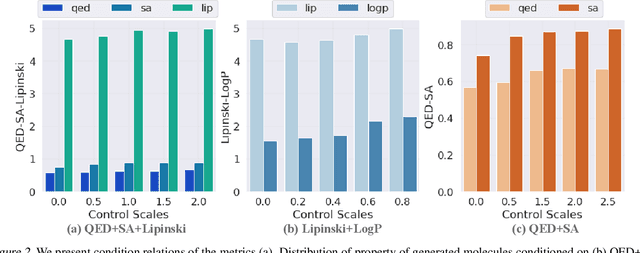
Is there a unified model for generating molecules considering different conditions, such as binding pockets and chemical properties? Although target-aware generative models have made significant advances in drug design, they do not consider chemistry conditions and cannot guarantee the desired chemical properties. Unfortunately, merging the target-aware and chemical-aware models into a unified model to meet customized requirements may lead to the problem of negative transfer. Inspired by the success of multi-task learning in the NLP area, we use prefix embeddings to provide a novel generative model that considers both the targeted pocket's circumstances and a variety of chemical properties. All conditional information is represented as learnable features, which the generative model subsequently employs as a contextual prompt. Experiments show that our model exhibits good controllability in both single and multi-conditional molecular generation. The controllability enables us to outperform previous structure-based drug design methods. More interestingly, we open up the attention mechanism and reveal coupling relationships between conditions, providing guidance for multi-conditional molecule generation.
Multi-Source Contrastive Learning from Musical Audio
Feb 14, 2023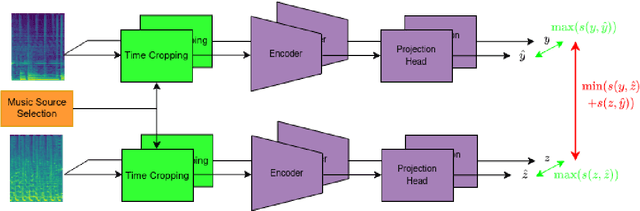
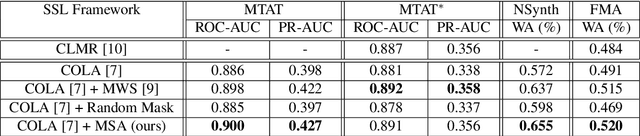
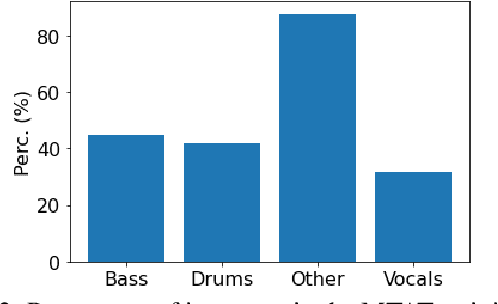
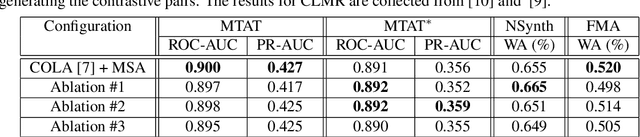
Contrastive learning constitutes an emerging branch of self-supervised learning that leverages large amounts of unlabeled data, by learning a latent space, where pairs of different views of the same sample are associated. In this paper, we propose musical source association as a pair generation strategy in the context of contrastive music representation learning. To this end, we modify COLA, a widely used contrastive learning audio framework, to learn to associate a song excerpt with a stochastically selected and automatically extracted vocal or instrumental source. We further introduce a novel modification to the contrastive loss to incorporate information about the existence or absence of specific sources. Our experimental evaluation in three different downstream tasks (music auto-tagging, instrument classification and music genre classification) using the publicly available Magna-Tag-A-Tune (MTAT) as a source dataset yields competitive results to existing literature methods, as well as faster network convergence. The results also show that this pre-training method can be steered towards specific features, according to the selected musical source, while also being dependent on the quality of the separated sources.
Noise-Augmented $\ell_0$ Regularization of Tensor Regression with Tucker Decomposition
Feb 19, 2023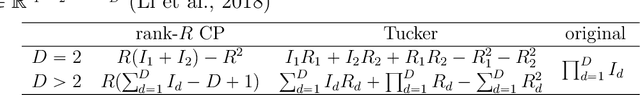


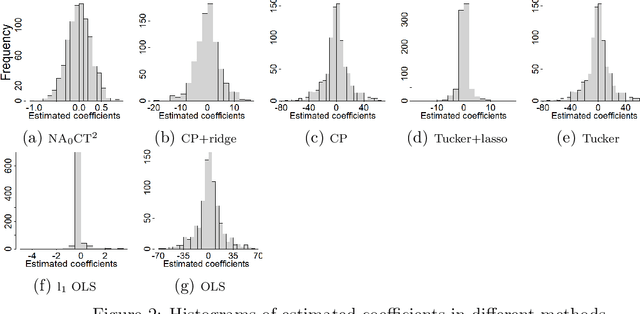
Tensor data are multi-dimension arrays. Low-rank decomposition-based regression methods with tensor predictors exploit the structural information in tensor predictors while significantly reducing the number of parameters in tensor regression. We propose a method named NA$_0$CT$^2$ (Noise Augmentation for $\ell_0$ regularization on Core Tensor in Tucker decomposition) to regularize the parameters in tensor regression (TR), coupled with Tucker decomposition. We establish theoretically that NA$_0$CT$^2$ achieves exact $\ell_0$ regularization in linear TR and generalized linear TR on the core tensor from the Tucker decomposition. To our knowledge, NA$_0$CT$^2$ is the first Tucker decomposition-based regularization method in TR to achieve $\ell_0$ in core tensor. NA$_0$CT$^2$ is implemented through an iterative procedure and involves two simple steps in each iteration -- generating noisy data based on the core tensor from the Tucker decomposition of the updated parameter estimate and running a regular GLM on noise-augmented data on vectorized predictors. We demonstrate the implementation of NA$_0$CT$^2$ and its $\ell_0$ regularization effect in both simulation studies and real data applications. The results suggest that NA$_0$CT$^2$ improves predictions compared to other decomposition-based TR approaches, with or without regularization and it also helps to identify important predictors though not designed for that purpose.
Table Tennis Stroke Detection and Recognition Using Ball Trajectory Data
Feb 19, 2023
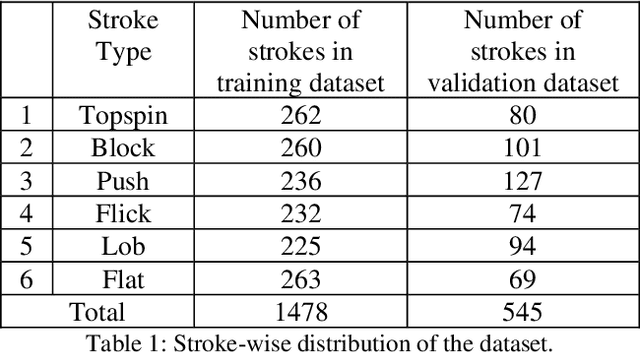
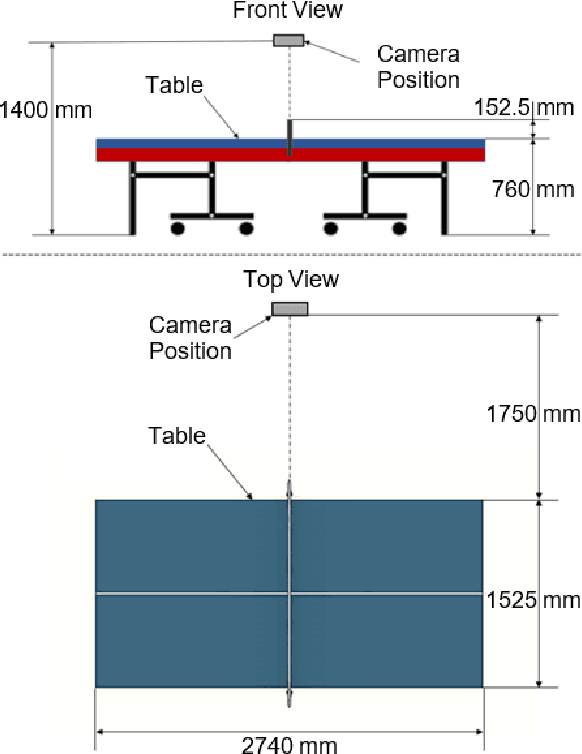
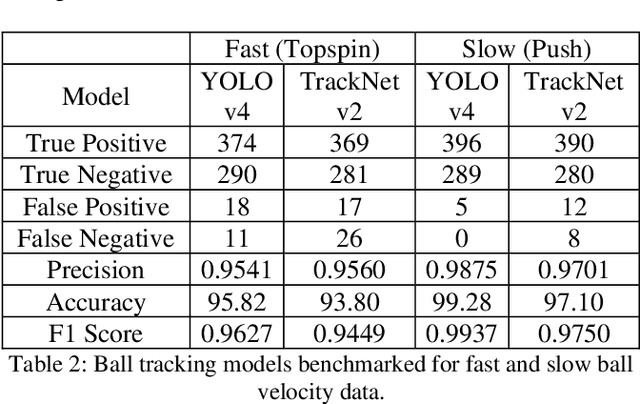
In this work, the novel task of detecting and classifying table tennis strokes solely using the ball trajectory has been explored. A single camera setup positioned in the umpire's view has been employed to procure a dataset consisting of six stroke classes executed by four professional table tennis players. Ball tracking using YOLOv4, a traditional object detection model, and TrackNetv2, a temporal heatmap based model, have been implemented on our dataset and their performances have been benchmarked. A mathematical approach developed to extract temporal boundaries of strokes using the ball trajectory data yielded a total of 2023 valid strokes in our dataset, while also detecting services and missed strokes successfully. The temporal convolutional network developed performed stroke recognition on completely unseen data with an accuracy of 87.155%. Several machine learning and deep learning based model architectures have been trained for stroke recognition using ball trajectory input and benchmarked based on their performances. While stroke recognition in the field of table tennis has been extensively explored based on human action recognition using video data focused on the player's actions, the use of ball trajectory data for the same is an unexplored characteristic of the sport. Hence, the motivation behind the work is to demonstrate that meaningful inferences such as stroke detection and recognition can be drawn using minimal input information.
Mutual Exclusive Modulator for Long-Tailed Recognition
Feb 19, 2023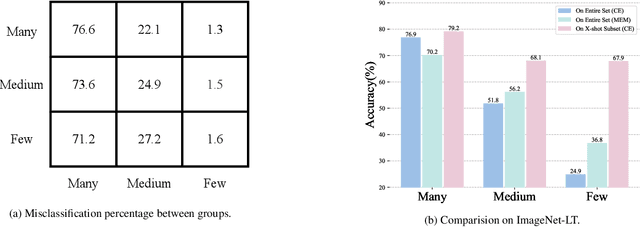
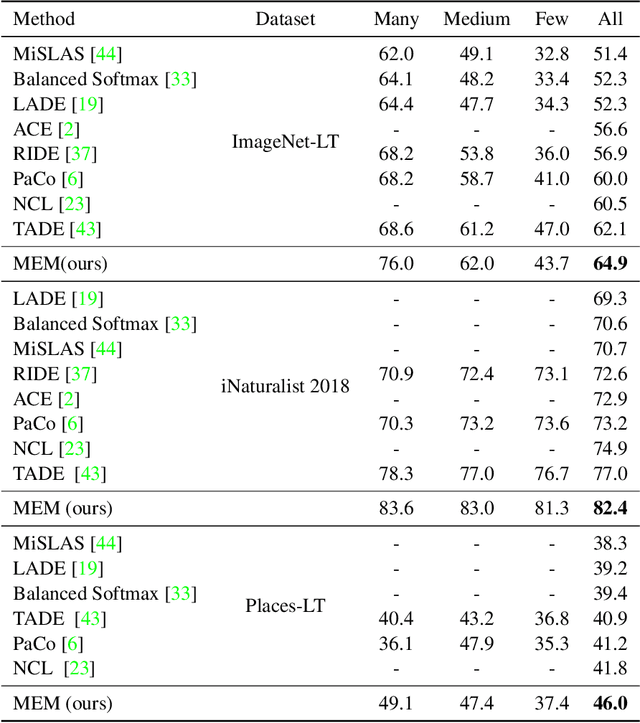
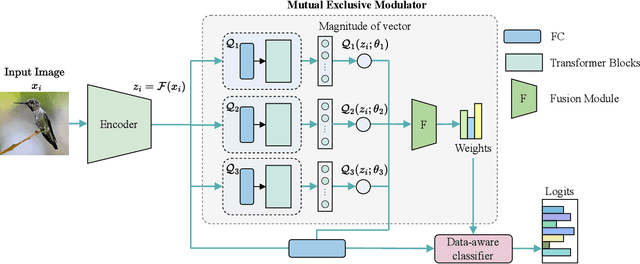
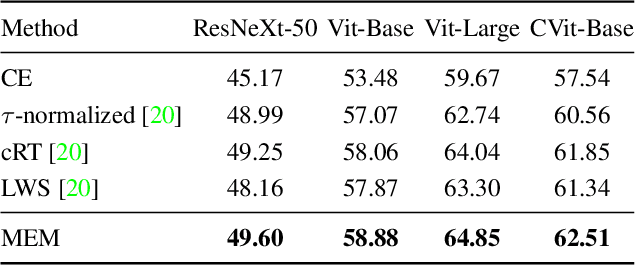
The long-tailed recognition (LTR) is the task of learning high-performance classifiers given extremely imbalanced training samples between categories. Most of the existing works address the problem by either enhancing the features of tail classes or re-balancing the classifiers to reduce the inductive bias. In this paper, we try to look into the root cause of the LTR task, i.e., training samples for each class are greatly imbalanced, and propose a straightforward solution. We split the categories into three groups, i.e., many, medium and few, according to the number of training images. The three groups of categories are separately predicted to reduce the difficulty for classification. This idea naturally arises a new problem of how to assign a given sample to the right class groups? We introduce a mutual exclusive modulator which can estimate the probability of an image belonging to each group. Particularly, the modulator consists of a light-weight module and learned with a mutual exclusive objective. Hence, the output probabilities of the modulator encode the data volume clues of the training dataset. They are further utilized as prior information to guide the prediction of the classifier. We conduct extensive experiments on multiple datasets, e.g., ImageNet-LT, Place-LT and iNaturalist 2018 to evaluate the proposed approach. Our method achieves competitive performance compared to the state-of-the-art benchmarks.
The Story of QoS Prediction in Vehicular Communication: From Radio Environment Statistics to Network-Access Throughput Prediction
Feb 23, 2023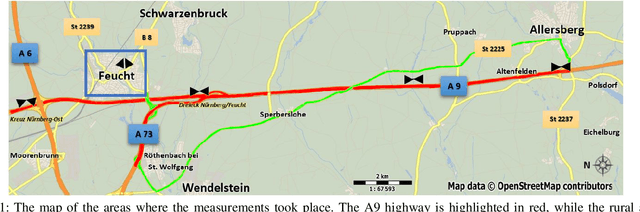
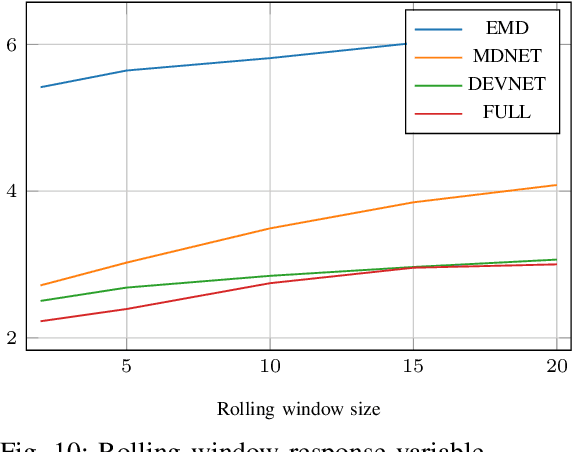
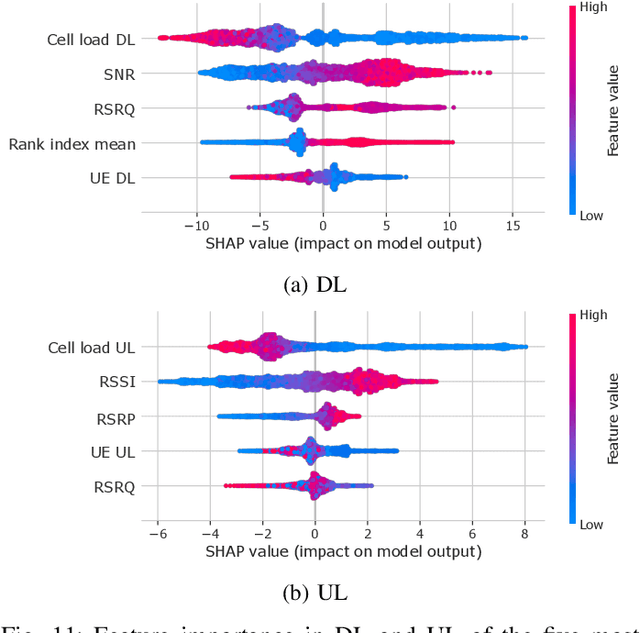
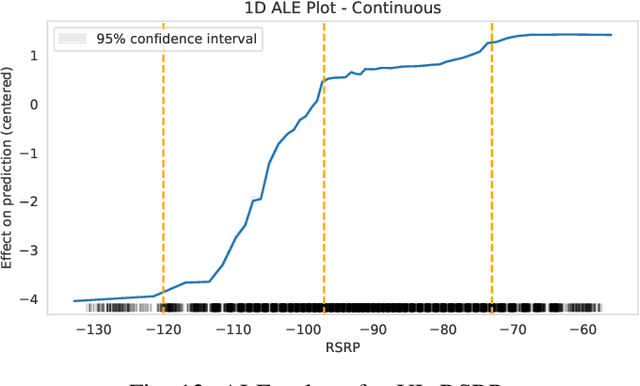
As cellular networks evolve towards the 6th Generation (6G), Machine Learning (ML) is seen as a key enabling technology to improve the capabilities of the network. ML provides a methodology for predictive systems, which, in turn, can make networks become proactive. This proactive behavior of the network can be leveraged to sustain, for example, a specific Quality of Service (QoS) requirement. With predictive Quality of Service (pQoS), a wide variety of new use cases, both safety- and entertainment-related, are emerging, especially in the automotive sector. Therefore, in this work, we consider maximum throughput prediction enhancing, for example, streaming or HD mapping applications. We discuss the entire ML workflow highlighting less regarded aspects such as the detailed sampling procedures, the in-depth analysis of the dataset characteristics, the effects of splits in the provided results, and the data availability. Reliable ML models need to face a lot of challenges during their lifecycle. We highlight how confidence can be built on ML technologies by better understanding the underlying characteristics of the collected data. We discuss feature engineering and the effects of different splits for the training processes, showcasing that random splits might overestimate performance by more than twofold. Moreover, we investigate diverse sets of input features, where network information proved to be most effective, cutting the error by half. Part of our contribution is the validation of multiple ML models within diverse scenarios. We also use Explainable AI (XAI) to show that ML can learn underlying principles of wireless networks without being explicitly programmed. Our data is collected from a deployed network that was under full control of the measurement team and covered different vehicular scenarios and radio environments.
Beyond Moments: Robustly Learning Affine Transformations with Asymptotically Optimal Error
Feb 23, 2023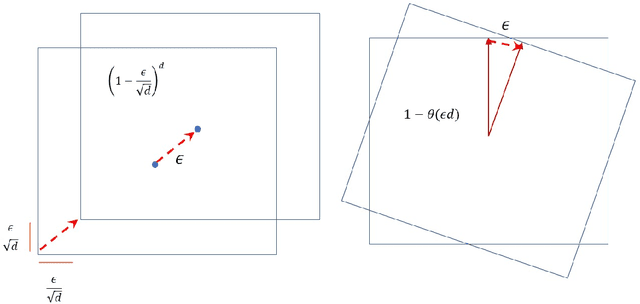
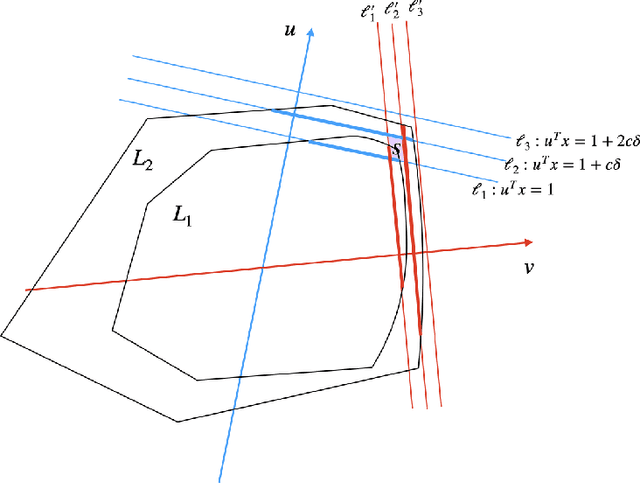
We present a polynomial-time algorithm for robustly learning an unknown affine transformation of the standard hypercube from samples, an important and well-studied setting for independent component analysis (ICA). Specifically, given an $\epsilon$-corrupted sample from a distribution $D$ obtained by applying an unknown affine transformation $x \rightarrow Ax+s$ to the uniform distribution on a $d$-dimensional hypercube $[-1,1]^d$, our algorithm constructs $\hat{A}, \hat{s}$ such that the total variation distance of the distribution $\hat{D}$ from $D$ is $O(\epsilon)$ using poly$(d)$ time and samples. Total variation distance is the information-theoretically strongest possible notion of distance in our setting and our recovery guarantees in this distance are optimal up to the absolute constant factor multiplying $\epsilon$. In particular, if the columns of $A$ are normalized to be unit length, our total variation distance guarantee implies a bound on the sum of the $\ell_2$ distances between the column vectors of $A$ and $A'$, $\sum_{i =1}^d \|a_i-\hat{a}_i\|_2 = O(\epsilon)$. In contrast, the strongest known prior results only yield a $\epsilon^{O(1)}$ (relative) bound on the distance between individual $a_i$'s and their estimates and translate into an $O(d\epsilon)$ bound on the total variation distance. Our key innovation is a new approach to ICA (even to outlier-free ICA) that circumvents the difficulties in the classical method of moments and instead relies on a new geometric certificate of correctness of an affine transformation. Our algorithm is based on a new method that iteratively improves an estimate of the unknown affine transformation whenever the requirements of the certificate are not met.
An Aligned Multi-Temporal Multi-Resolution Satellite Image Dataset for Change Detection Research
Feb 23, 2023
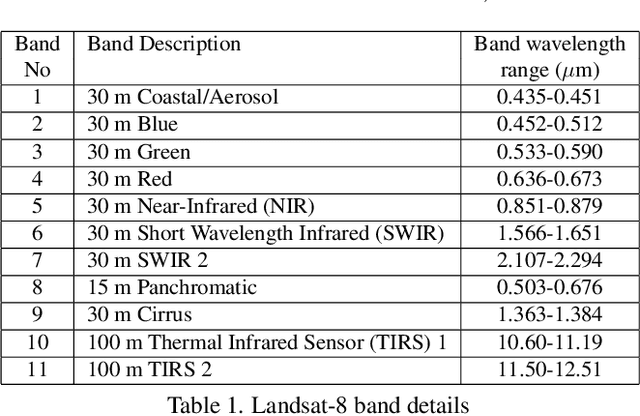
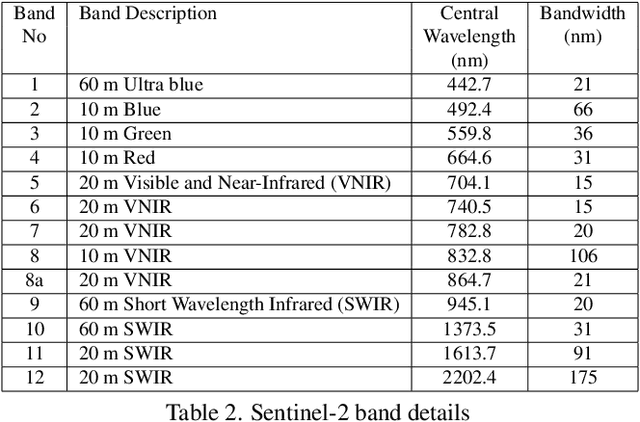
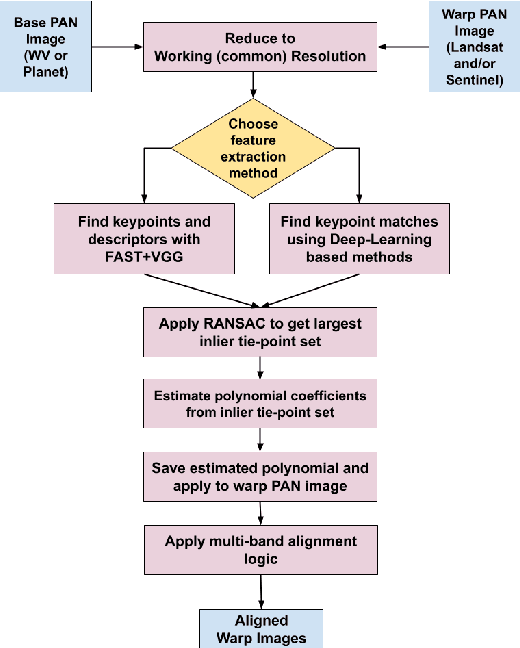
This paper presents an aligned multi-temporal and multi-resolution satellite image dataset for research in change detection. We expect our dataset to be useful to researchers who want to fuse information from multiple satellites for detecting changes on the surface of the earth that may not be fully visible in any single satellite. The dataset we present was created by augmenting the SpaceNet-7 dataset with temporally parallel stacks of Landsat and Sentinel images. The SpaceNet-7 dataset consists of time-sequenced Planet images recorded over 101 AOIs (Areas-of-Interest). In our dataset, for each of the 60 AOIs that are meant for training, we augment the Planet datacube with temporally parallel datacubes of Landsat and Sentinel images. The temporal alignments between the high-res Planet images, on the one hand, and the Landsat and Sentinel images, on the other, are approximate since the temporal resolution for the Planet images is one month -- each image being a mosaic of the best data collected over a month. Whenever we have a choice regarding which Landsat and Sentinel images to pair up with the Planet images, we have chosen those that had the least cloud cover. A particularly important feature of our dataset is that the high-res and the low-res images are spatially aligned together with our MuRA framework presented in this paper. Foundational to the alignment calculation is the modeling of inter-satellite misalignment errors with polynomials as in NASA's AROP algorithm. We have named our dataset MuRA-T for the MuRA framework that is used for aligning the cross-satellite images and "T" for the temporal dimension in the dataset.