 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inferencing the earth moving equipment-environment interaction in open pit mining
Feb 04, 2023
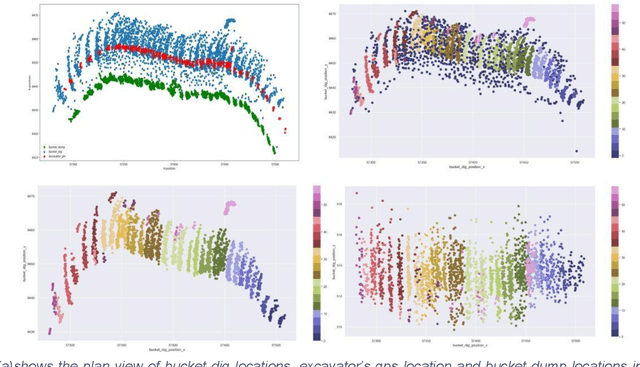
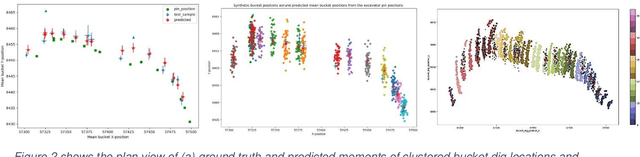
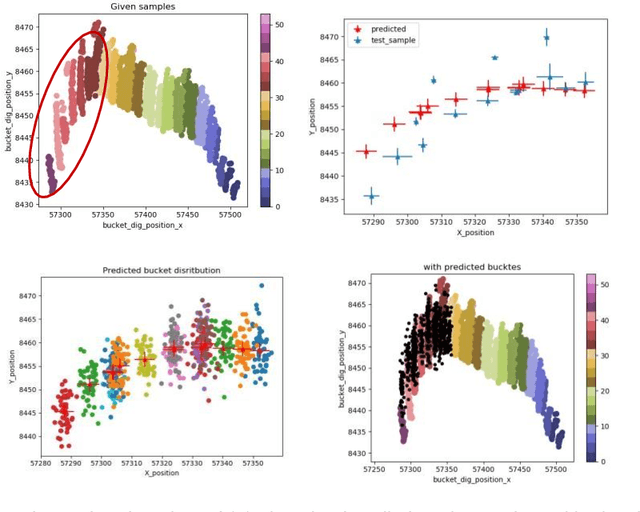
In mining, grade control generally focuses on blast hole sampling and the estimation of ore control block models with little or no attention given to how the materials are being excavated from the ground. In the process of loading trucks, the underlying variability of the individual bucket load will determine the variability of truck payload. Hence, accurate material movement demands a good knowledge of the excavation process and the buckets interaction with the environment. However, equipment frequently goes into off nominal states due to unexpected delays, disturbances or faults. The large amount of such disturbances causes information loss that reduces the statistical power and biases estimates, leading to increased uncertainty in the production. A reliable method that inferences the missing knowledge about the interaction between the machine and the environment from the available data sources, is vital to accurately model the material movement. In this study, a twostep method was implemented that performed unsupervised clustering and then predicted the missing information. The first method is DBSCAN based spatial clustering which divides the diggers and buckets positional data into connected loading segments. Clear patterns of segmented bucket dig positions were observed. The second model utilized Gaussian process regression which was trained with the clustered data and the model was then used to infer the mean locations of the test clusters. Bucket dig locations were then simulated at the inferred mean locations for different durations and compared against the known bucket dig locations. This method was tested at an open pit mine in the Pilbara of Western Australia. The results demonstrate the advantage of the proposed method in inferencing the missing information of bucket environment interactions and therefore enables miners to continuously track the material movement.
Predicting Desirable Revisions of Evidence and Reasoning in Argumentative Writing
Feb 10, 2023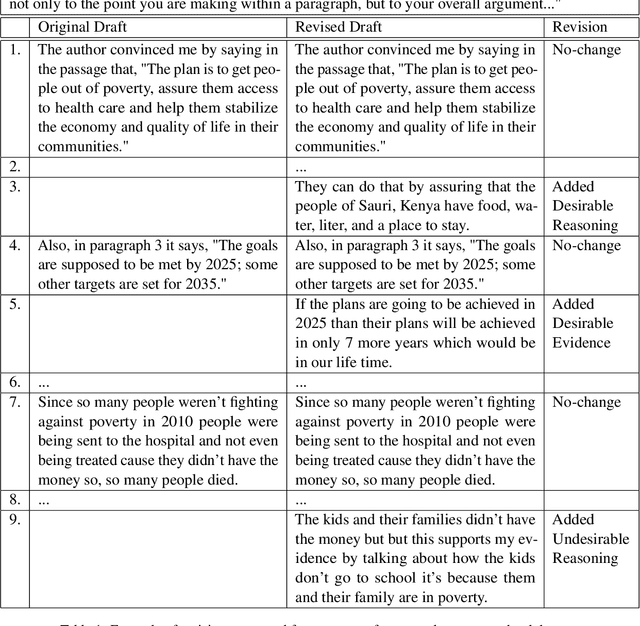
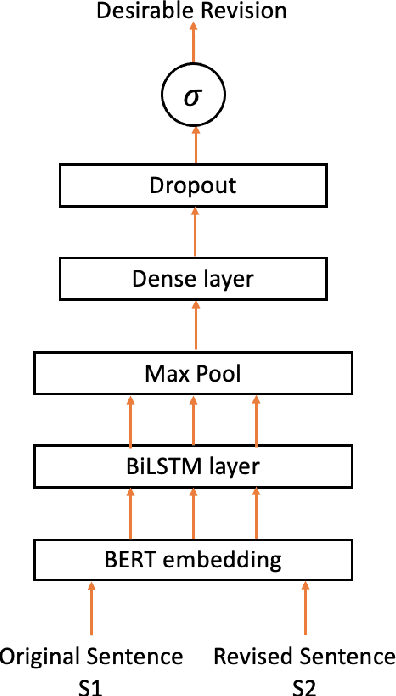

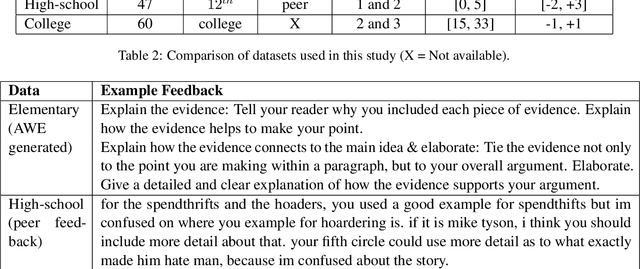
We develop models to classify desirable evidence and desirable reasoning revisions in student argumentative writing. We explore two ways to improve classifier performance - using the essay context of the revision, and using the feedback students received before the revision. We perform both intrinsic and extrinsic evaluation for each of our models and report a qualitative analysis. Our results show that while a model using feedback information improves over a baseline model, models utilizing context - either alone or with feedback - are the most successful in identifying desirable revisions.
OAMatcher: An Overlapping Areas-based Network for Accurate Local Feature Matching
Feb 12, 2023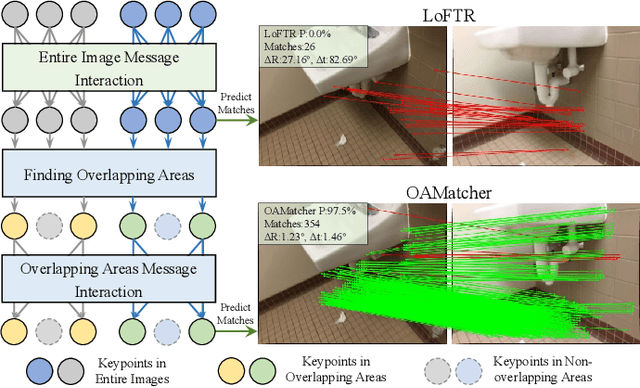
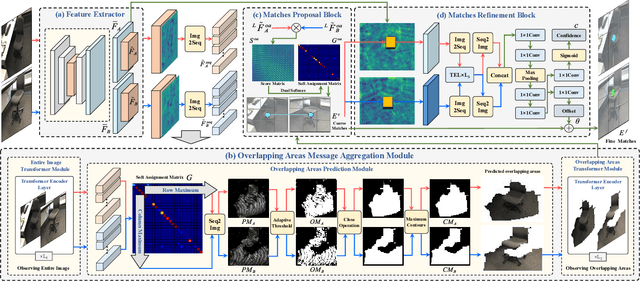
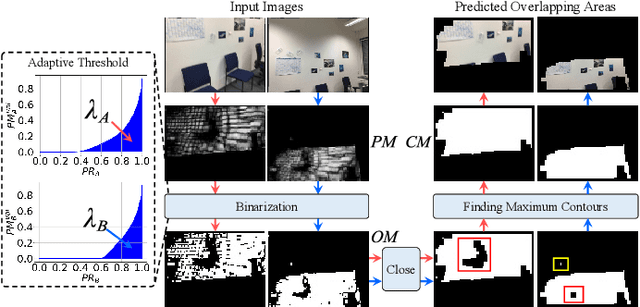

Local feature matching is an essential component in many visual applications. In this work, we propose OAMatcher, a Tranformer-based detector-free method that imitates humans behavior to generate dense and accurate matches. Firstly, OAMatcher predicts overlapping areas to promote effective and clean global context aggregation, with the key insight that humans focus on the overlapping areas instead of the entire images after multiple observations when matching keypoints in image pairs. Technically, we first perform global information integration across all keypoints to imitate the humans behavior of observing the entire images at the beginning of feature matching. Then, we propose Overlapping Areas Prediction Module (OAPM) to capture the keypoints in co-visible regions and conduct feature enhancement among them to simulate that humans transit the focus regions from the entire images to overlapping regions, hence realizeing effective information exchange without the interference coming from the keypoints in non overlapping areas. Besides, since humans tend to leverage probability to determine whether the match labels are correct or not, we propose a Match Labels Weight Strategy (MLWS) to generate the coefficients used to appraise the reliability of the ground-truth match labels, while alleviating the influence of measurement noise coming from the data. Moreover, we integrate depth-wise convolution into Tranformer encoder layers to ensure OAMatcher extracts local and global feature representation concurrently. Comprehensive experiments demonstrate that OAMatcher outperforms the state-of-the-art methods on several benchmarks, while exhibiting excellent robustness to extreme appearance variants. The source code is available at https://github.com/DK-HU/OAMatcher.
SCRIMP: Scalable Communication for Reinforcement- and Imitation-Learning-Based Multi-Agent Pathfinding
Mar 01, 2023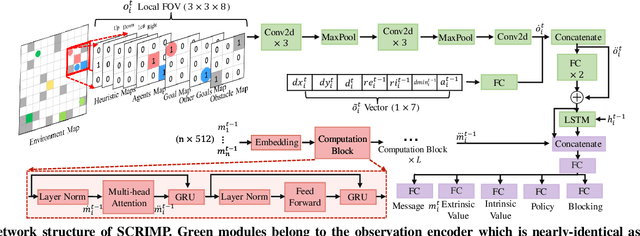
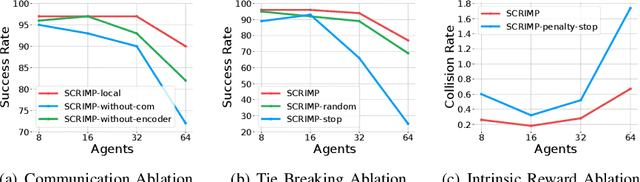
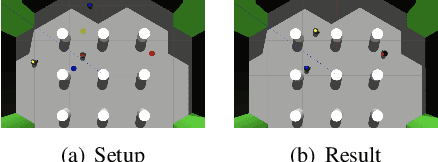
Trading off performance guarantees in favor of scalability, the Multi-Agent Path Finding (MAPF) community has recently started to embrace Multi-Agent Reinforcement Learning (MARL), where agents learn to collaboratively generate individual, collision-free (but often suboptimal) paths. Scalability is usually achieved by assuming a local field of view (FOV) around the agents, helping scale to arbitrary world sizes. However, this assumption significantly limits the amount of information available to the agents, making it difficult for them to enact the type of joint maneuvers needed in denser MAPF tasks. In this paper, we propose SCRIMP, where agents learn individual policies from even very small (down to 3x3) FOVs, by relying on a highly-scalable global/local communication mechanism based on a modified transformer. We further equip agents with a state-value-based tie-breaking strategy to further improve performance in symmetric situations, and introduce intrinsic rewards to encourage exploration while mitigating the long-term credit assignment problem. Empirical evaluations on a set of experiments indicate that SCRIMP can achieve higher performance with improved scalability compared to other state-of-the-art learning-based MAPF planners with larger FOVs, and even yields similar performance as a classical centralized planner in many cases. Ablation studies further validate the effectiveness of our proposed techniques. Finally, we show that our trained model can be directly implemented on real robots for online MAPF through high-fidelity simulations in gazebo.
Spatial-temporal Transformer-guided Diffusion based Data Augmentation for Efficient Skeleton-based Action Recognition
Feb 26, 2023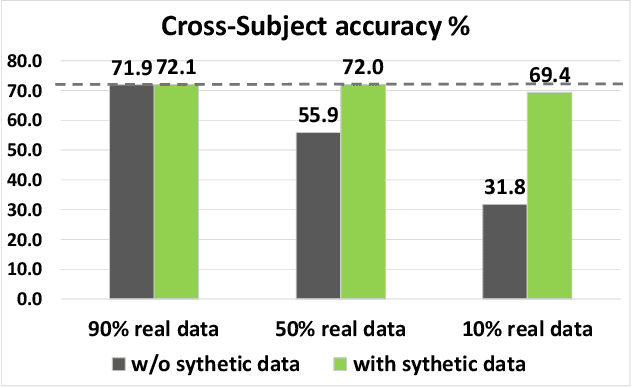
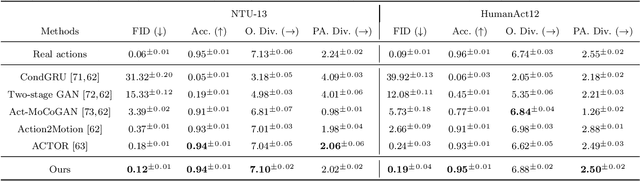
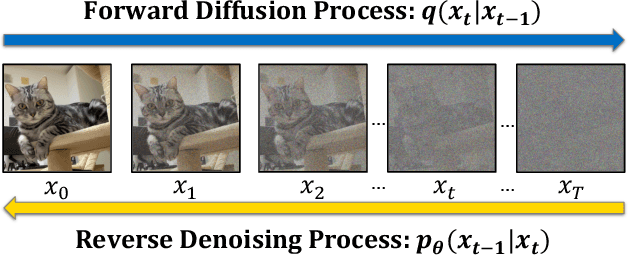
Recently, skeleton-based human action has become a hot research topic because the compact representation of human skeletons brings new blood to this research domain. As a result, researchers began to notice the importance of using RGB or other sensors to analyze human action by extracting skeleton information. Leveraging the rapid development of deep learning (DL), a significant number of skeleton-based human action approaches have been presented with fine-designed DL structures recently. However, a well-trained DL model always demands high-quality and sufficient data, which is hard to obtain without costing high expenses and human labor. In this paper, we introduce a novel data augmentation method for skeleton-based action recognition tasks, which can effectively generate high-quality and diverse sequential actions. In order to obtain natural and realistic action sequences, we propose denoising diffusion probabilistic models (DDPMs) that can generate a series of synthetic action sequences, and their generation process is precisely guided by a spatial-temporal transformer (ST-Trans). Experimental results show that our method outperforms the state-of-the-art (SOTA) motion generation approaches on different naturality and diversity metrics. It proves that its high-quality synthetic data can also be effectively deployed to existing action recognition models with significant performance improvement.
Learning Pairwise Interaction for Generalizable DeepFake Detection
Feb 26, 2023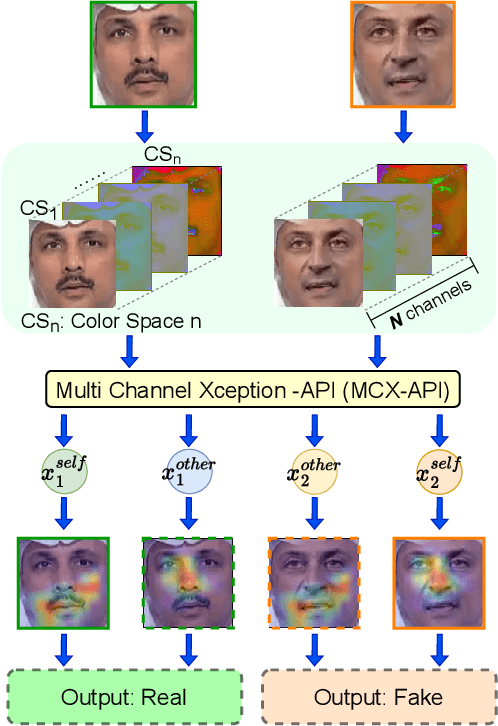
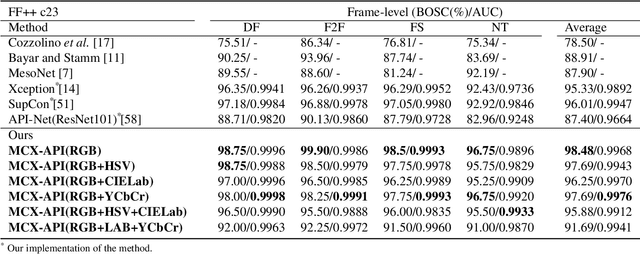
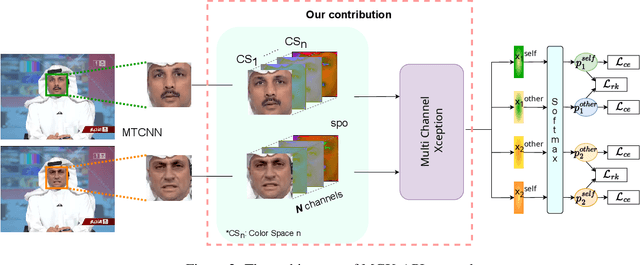
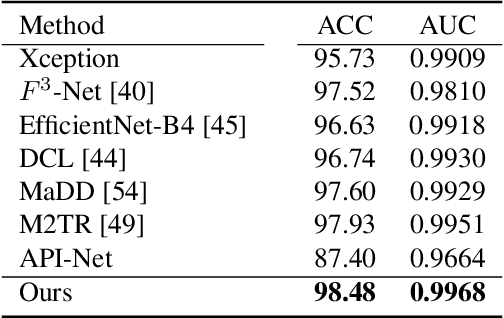
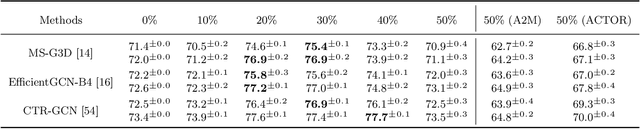
A fast-paced development of DeepFake generation techniques challenge the detection schemes designed for known type DeepFakes. A reliable Deepfake detection approach must be agnostic to generation types, which can present diverse quality and appearance. Limited generalizability across different generation schemes will restrict the wide-scale deployment of detectors if they fail to handle unseen attacks in an open set scenario. We propose a new approach, Multi-Channel Xception Attention Pairwise Interaction (MCX-API), that exploits the power of pairwise learning and complementary information from different color space representations in a fine-grained manner. We first validate our idea on a publicly available dataset in a intra-class setting (closed set) with four different Deepfake schemes. Further, we report all the results using balanced-open-set-classification (BOSC) accuracy in an inter-class setting (open-set) using three public datasets. Our experiments indicate that our proposed method can generalize better than the state-of-the-art Deepfakes detectors. We obtain 98.48% BOSC accuracy on the FF++ dataset and 90.87% BOSC accuracy on the CelebDF dataset suggesting a promising direction for generalization of DeepFake detection. We further utilize t-SNE and attention maps to interpret and visualize the decision-making process of our proposed network. https://github.com/xuyingzhongguo/MCX-API
Cross-Lingual Question Answering over Knowledge Base as Reading Comprehension
Feb 26, 2023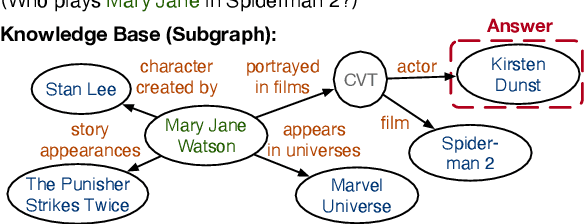

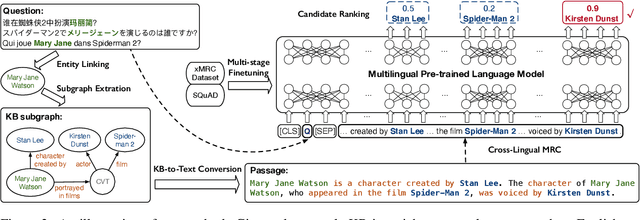
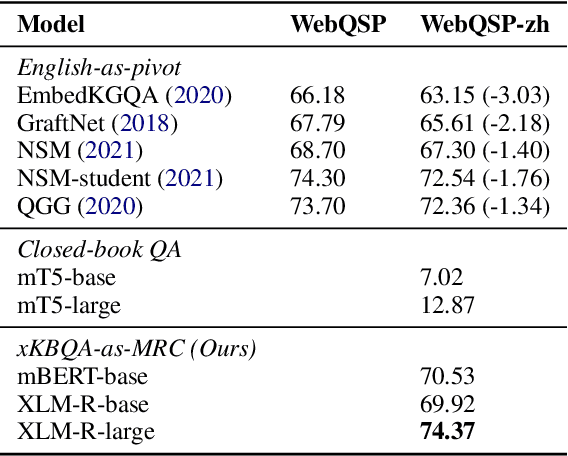
Although many large-scale knowledge bases (KBs) claim to contain multilingual information, their support for many non-English languages is often incomplete. This incompleteness gives birth to the task of cross-lingual question answering over knowledge base (xKBQA), which aims to answer questions in languages different from that of the provided KB. One of the major challenges facing xKBQA is the high cost of data annotation, leading to limited resources available for further exploration. Another challenge is mapping KB schemas and natural language expressions in the questions under cross-lingual settings. In this paper, we propose a novel approach for xKBQA in a reading comprehension paradigm. We convert KB subgraphs into passages to narrow the gap between KB schemas and questions, which enables our model to benefit from recent advances in multilingual pre-trained language models (MPLMs) and cross-lingual machine reading comprehension (xMRC). Specifically, we use MPLMs, with considerable knowledge of cross-lingual mappings, for cross-lingual reading comprehension. Existing high-quality xMRC datasets can be further utilized to finetune our model, greatly alleviating the data scarcity issue in xKBQA. Extensive experiments on two xKBQA datasets in 12 languages show that our approach outperforms various baselines and achieves strong few-shot and zero-shot performance. Our dataset and code are released for further research.
Data-Association-Free Landmark-based SLAM
Feb 26, 2023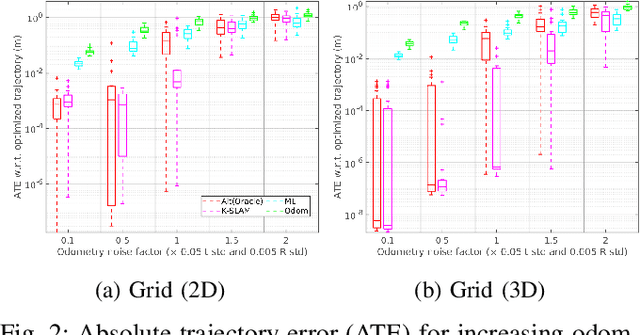
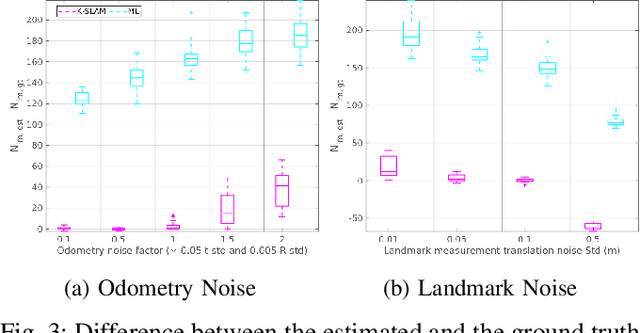
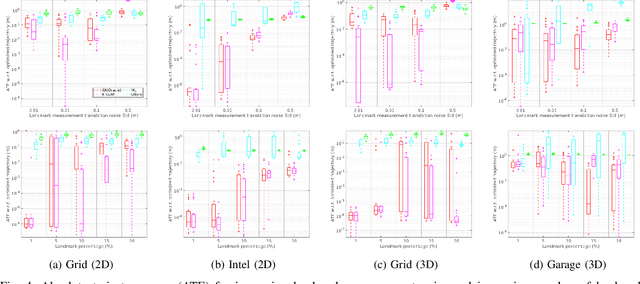
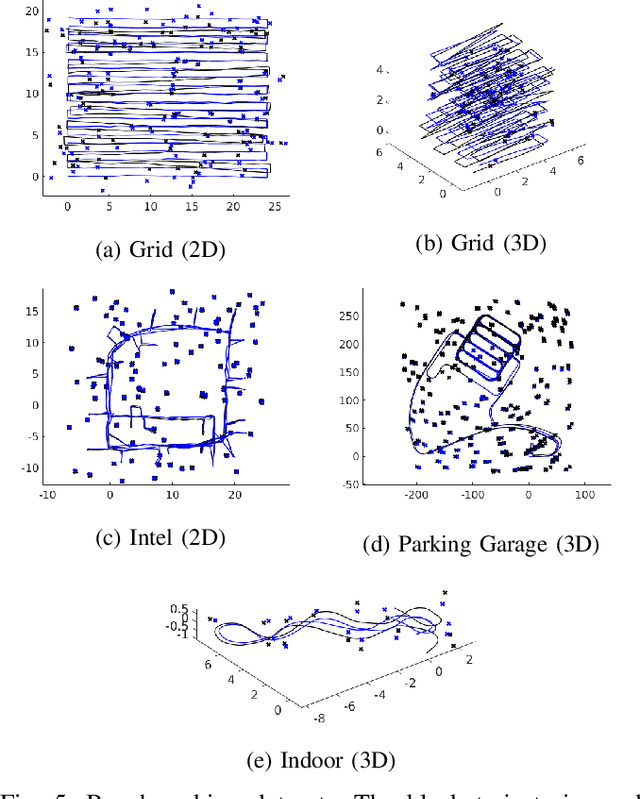
We study landmark-based SLAM with unknown data association: our robot navigates in a completely unknown environment and has to simultaneously reason over its own trajectory, the positions of an unknown number of landmarks in the environment, and potential data associations between measurements and landmarks. This setup is interesting since: (i) it arises when recovering from data association failures or from SLAM with information-poor sensors, (ii) it sheds light on fundamental limits (and hardness) of landmark-based SLAM problems irrespective of the front-end data association method, and (iii) it generalizes existing approaches where data association is assumed to be known or partially known. We approach the problem by splitting it into an inner problem of estimating the trajectory, landmark positions and data associations and an outer problem of estimating the number of landmarks. Our approach creates useful and novel connections with existing techniques from discrete-continuous optimization (e.g., k-means clustering), which has the potential to trigger novel research. We demonstrate the proposed approaches in extensive simulations and on real datasets and show that the proposed techniques outperform typical data association baselines and are even competitive against an oracle baseline which has access to the number of landmarks and an initial guess for each landmark.
Navigating the Grey Area: Expressions of Overconfidence and Uncertainty in Language Models
Feb 26, 2023
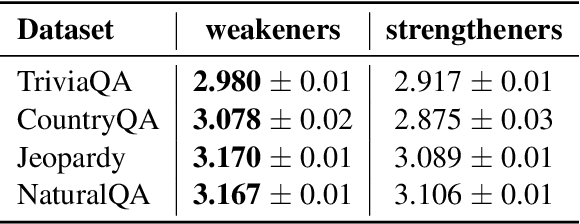
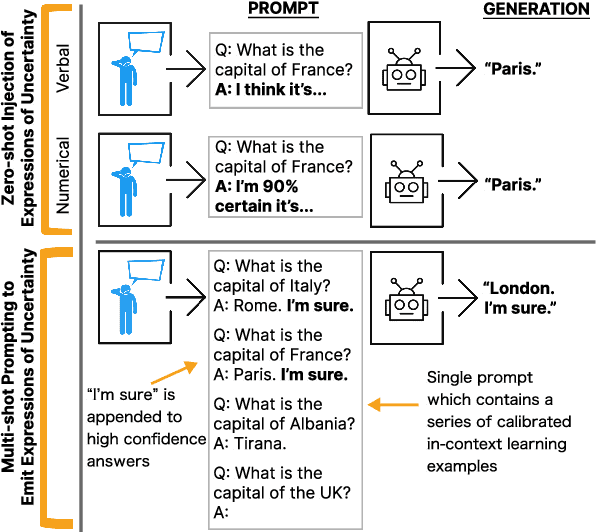
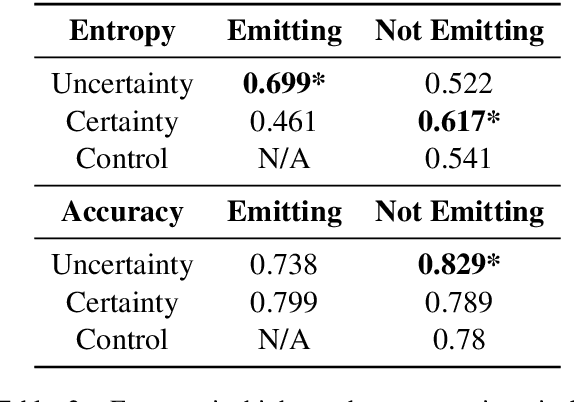
Despite increasingly fluent, relevant, and coherent language generation, major gaps remain between how humans and machines use language. We argue that a key dimension that is missing from our understanding of language models (LMs) is the model's ability to interpret and generate expressions of uncertainty. Whether it be the weatherperson announcing a chance of rain or a doctor giving a diagnosis, information is often not black-and-white and expressions of uncertainty provide nuance to support human-decision making. The increasing deployment of LMs in the wild motivates us to investigate whether LMs are capable of interpreting expressions of uncertainty and how LMs' behaviors change when learning to emit their own expressions of uncertainty. When injecting expressions of uncertainty into prompts (e.g., "I think the answer is..."), we discover that GPT3's generations vary upwards of 80% in accuracy based on the expression used. We analyze the linguistic characteristics of these expressions and find a drop in accuracy when naturalistic expressions of certainty are present. We find similar effects when teaching models to emit their own expressions of uncertainty, where model calibration suffers when teaching models to emit certainty rather than uncertainty. Together, these results highlight the challenges of building LMs that interpret and generate trustworthy expressions of uncertainty.
Discourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023
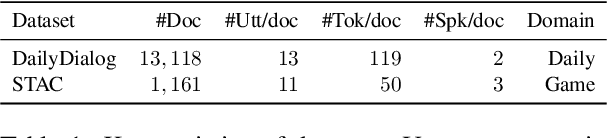
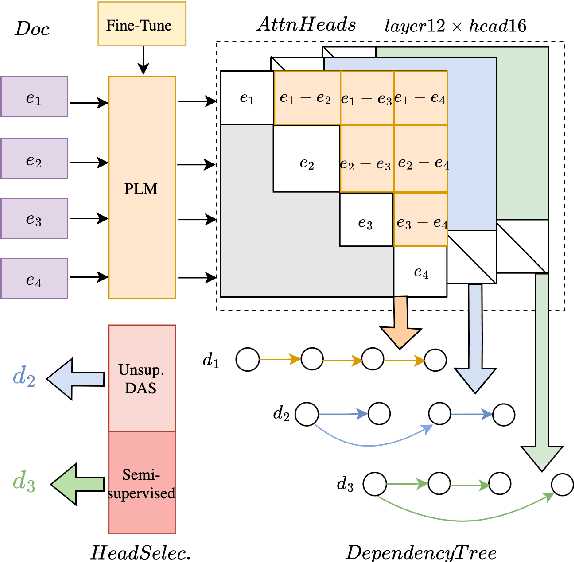
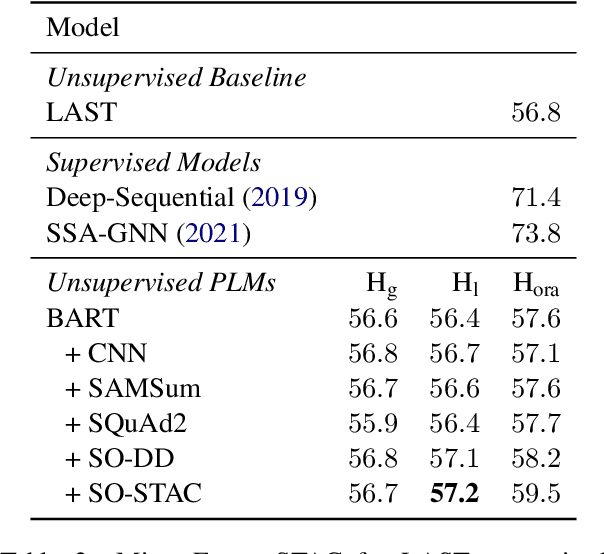
Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.