 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Natural Gradient Hybrid Variational Inference with Application to Deep Mixed Models
Feb 27, 2023
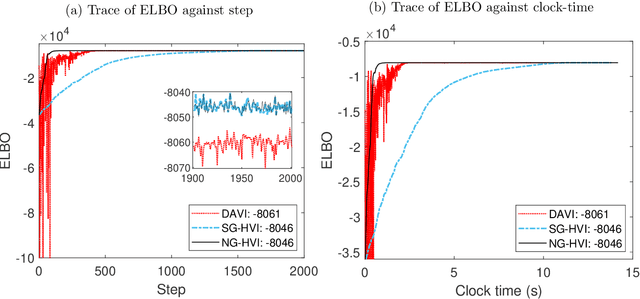
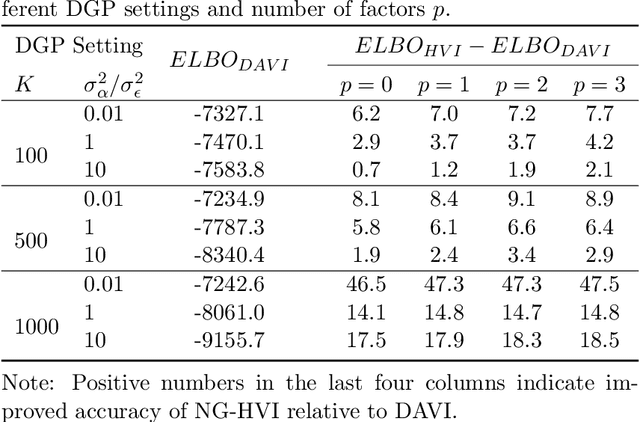
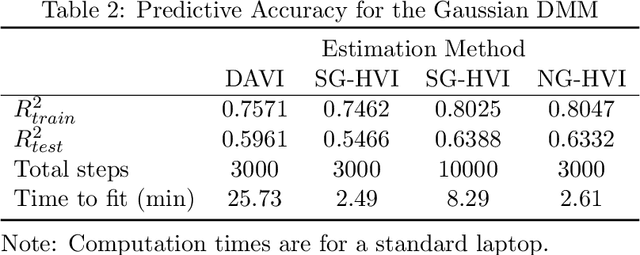
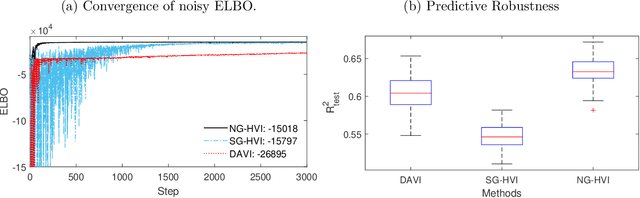
Stochastic models with global parameters $\bm{\theta}$ and latent variables $\bm{z}$ are common, and variational inference (VI) is popular for their estimation. This paper uses a variational approximation (VA) that comprises a Gaussian with factor covariance matrix for the marginal of $\bm{\theta}$, and the exact conditional posterior of $\bm{z}|\bm{\theta}$. Stochastic optimization for learning the VA only requires generation of $\bm{z}$ from its conditional posterior, while $\bm{\theta}$ is updated using the natural gradient, producing a hybrid VI method. We show that this is a well-defined natural gradient optimization algorithm for the joint posterior of $(\bm{z},\bm{\theta})$. Fast to compute expressions for the Tikhonov damped Fisher information matrix required to compute a stable natural gradient update are derived. We use the approach to estimate probabilistic Bayesian neural networks with random output layer coefficients to allow for heterogeneity. Simulations show that using the natural gradient is more efficient than using the ordinary gradient, and that the approach is faster and more accurate than two leading benchmark natural gradient VI methods. In a financial application we show that accounting for industry level heterogeneity using the deep model improves the accuracy of probabilistic prediction of asset pricing models.
Multimodal Deep Learning to Differentiate Tumor Recurrence from Treatment Effect in Human Glioblastoma
Feb 27, 2023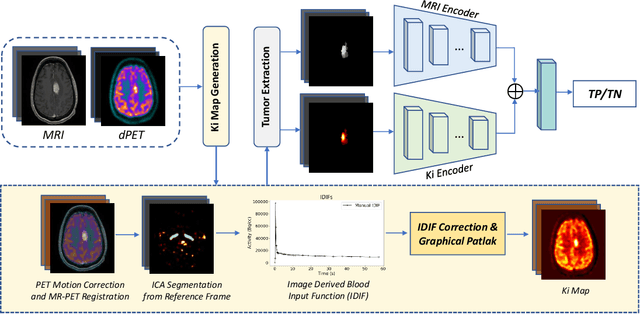
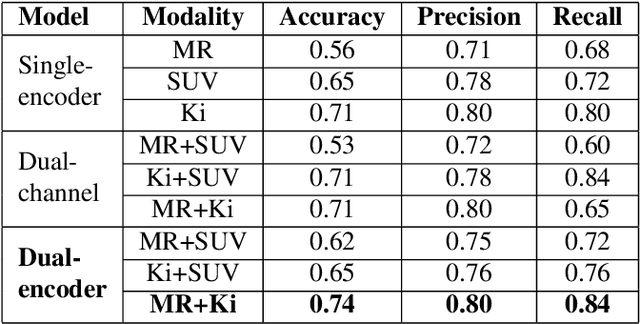

Differentiating tumor progression (TP) from treatment-related necrosis (TN) is critical for clinical management decisions in glioblastoma (GBM). Dynamic FDG PET (dPET), an advance from traditional static FDG PET, may prove advantageous in clinical staging. dPET includes novel methods of a model-corrected blood input function that accounts for partial volume averaging to compute parametric maps that reveal kinetic information. In a preliminary study, a convolution neural network (CNN) was trained to predict classification accuracy between TP and TN for $35$ brain tumors from $26$ subjects in the PET-MR image space. 3D parametric PET Ki (from dPET), traditional static PET standardized uptake values (SUV), and also the brain tumor MR voxels formed the input for the CNN. The average test accuracy across all leave-one-out cross-validation iterations adjusting for class weights was $0.56$ using only the MR, $0.65$ using only the SUV, and $0.71$ using only the Ki voxels. Combining SUV and MR voxels increased the test accuracy to $0.62$. On the other hand, MR and Ki voxels increased the test accuracy to $0.74$. Thus, dPET features alone or with MR features in deep learning models would enhance prediction accuracy in differentiating TP vs TN in GBM.
A Multi-Format Transfer Learning Model for Event Argument Extraction via Variational Information Bottleneck
Aug 30, 2022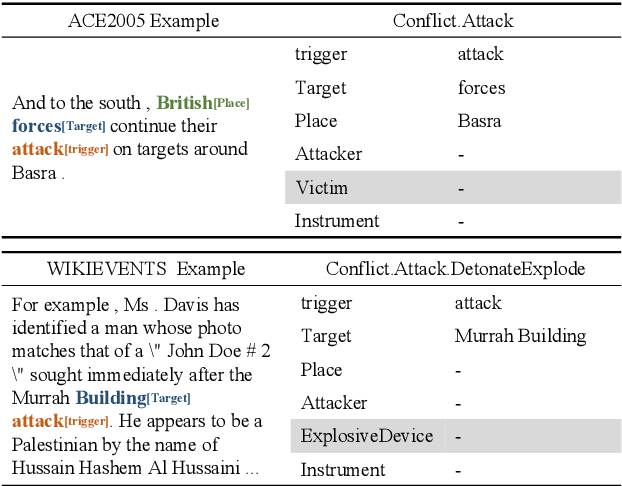
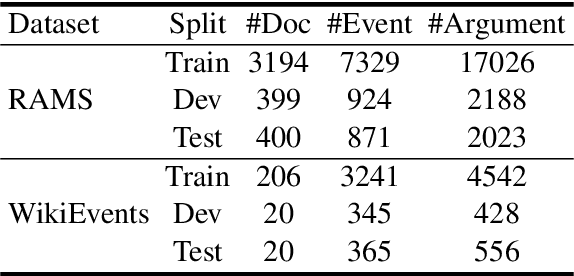
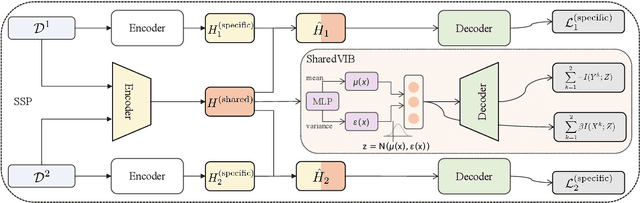
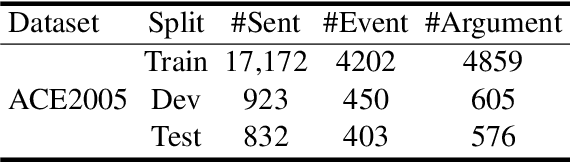
Event argument extraction (EAE) aims to extract arguments with given roles from texts, which have been widely studied in natural language processing. Most previous works have achieved good performance in specific EAE datasets with dedicated neural architectures. Whereas, these architectures are usually difficult to adapt to new datasets/scenarios with various annotation schemas or formats. Furthermore, they rely on large-scale labeled data for training, which is unavailable due to the high labelling cost in most cases. In this paper, we propose a multi-format transfer learning model with variational information bottleneck, which makes use of the information especially the common knowledge in existing datasets for EAE in new datasets. Specifically, we introduce a shared-specific prompt framework to learn both format-shared and format-specific knowledge from datasets with different formats. In order to further absorb the common knowledge for EAE and eliminate the irrelevant noise, we integrate variational information bottleneck into our architecture to refine the shared representation. We conduct extensive experiments on three benchmark datasets, and obtain new state-of-the-art performance on EAE.
Multimodal Chain-of-Thought Reasoning in Language Models
Feb 17, 2023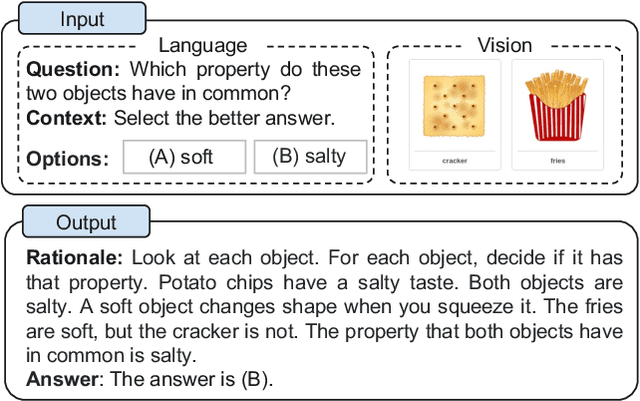
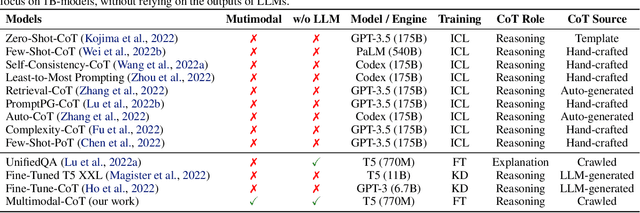


Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. With Multimodal-CoT, our model under 1 billion parameters outperforms the previous state-of-the-art LLM (GPT-3.5) by 16 percentage points (75.17%->91.68% accuracy) on the ScienceQA benchmark and even surpasses human performance. Code is publicly available available at https://github.com/amazon-science/mm-cot.
SEER: Safe Efficient Exploration for Aerial Robots using Learning to Predict Information Gain
Sep 22, 2022
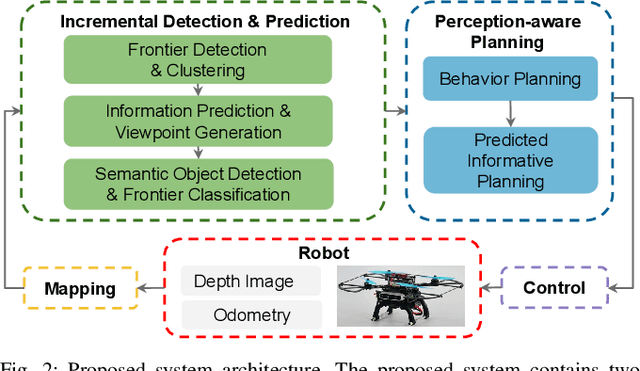
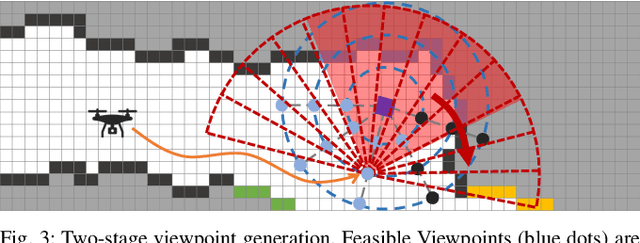
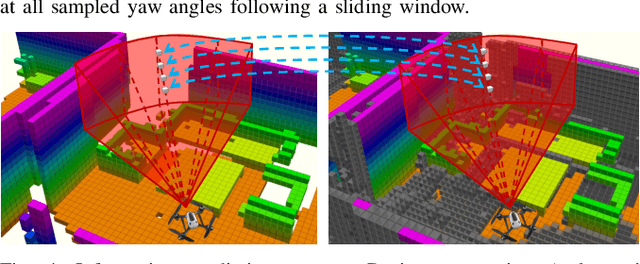
We address the problem of efficient 3-D exploration in indoor environments for micro aerial vehicles with limited sensing capabilities and payload/power constraints. We develop an indoor exploration framework that uses learning to predict the occupancy of unseen areas, extracts semantic features, samples viewpoints to predict information gains for different exploration goals, and plans informative trajectories to enable safe and smart exploration. Extensive experimentation in simulated and real-world environments shows the proposed approach outperforms the state-of-the-art exploration framework by 24% in terms of the total path length in a structured indoor environment and with a higher success rate during exploration.
Range Resolution Enhanced Method with Spectral Properties for Hyperspectral Lidar
Mar 03, 2023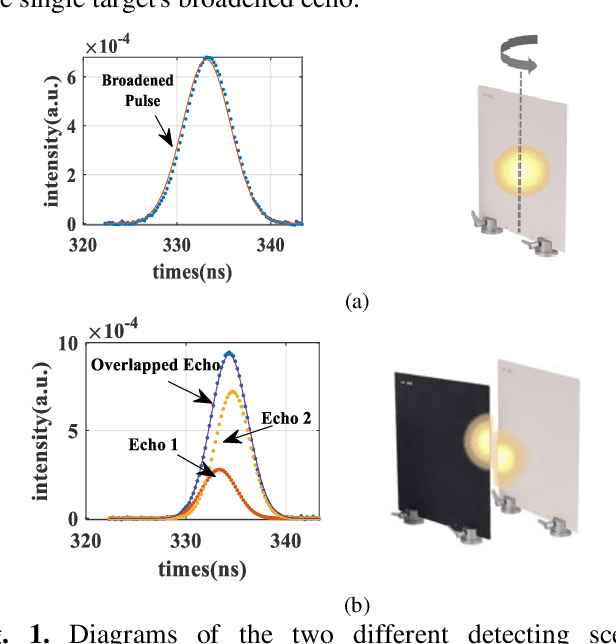
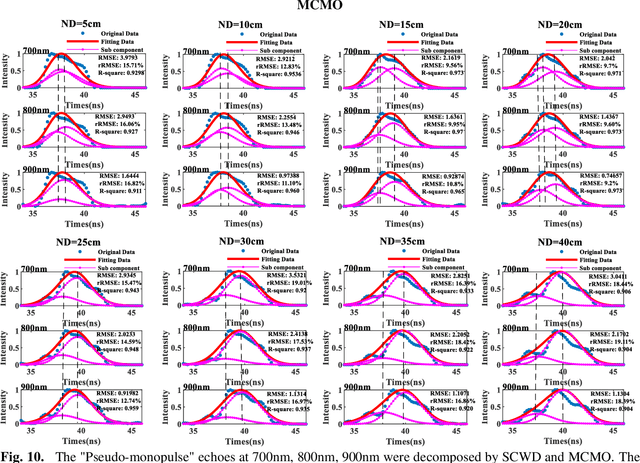
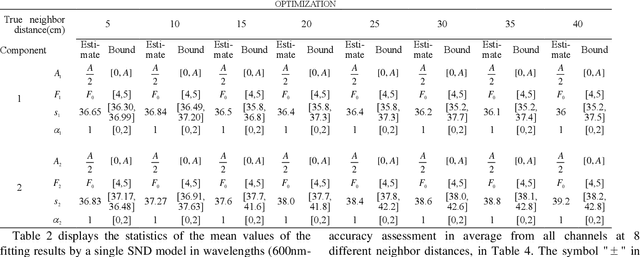
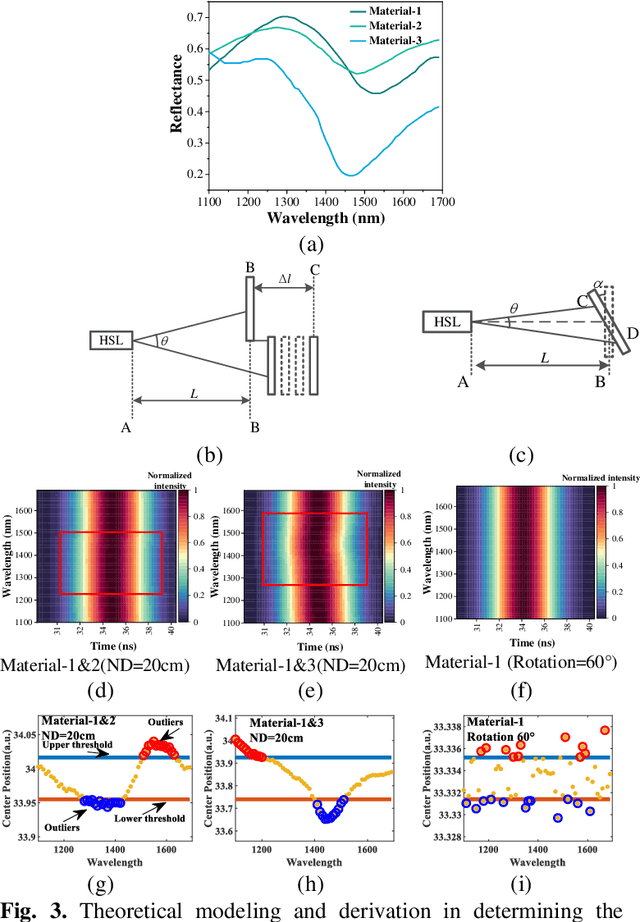
Waveform decomposition is needed as a first step in the extraction of various types of geometric and spectral information from hyperspectral full-waveform LiDAR echoes. We present a new approach to deal with the "Pseudo-monopulse" waveform formed by the overlapped waveforms from multi-targets when they are very close. We use one single skew-normal distribution (SND) model to fit waveforms of all spectral channels first and count the geometric center position distribution of the echoes to decide whether it contains multi-targets. The geometric center position distribution of the "Pseudo-monopulse" presents aggregation and asymmetry with the change of wavelength, while such an asymmetric phenomenon cannot be found from the echoes of the single target. Both theoretical and experimental data verify the point. Based on such observation, we further propose a hyperspectral waveform decomposition method utilizing the SND mixture model with: 1) initializing new waveform component parameters and their ranges based on the distinction of the three characteristics (geometric center position, pulse width, and skew-coefficient) between the echo and fitted SND waveform and 2) conducting single-channel waveform decomposition for all channels and 3) setting thresholds to find outlier channels based on statistical parameters of all single-channel decomposition results (the standard deviation and the means of geometric center position) and 4) re-conducting single-channel waveform decomposition for these outlier channels. The proposed method significantly improves the range resolution from 60cm to 5cm at most for a 4ns width laser pulse and represents the state-of-the-art in "Pseudo-monopulse" waveform decomposition.
Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation
Mar 03, 2023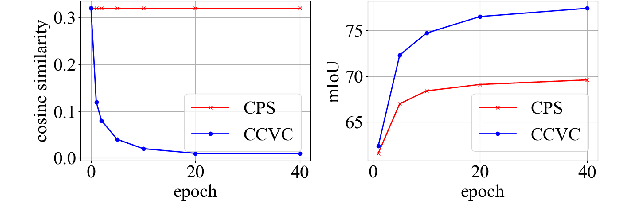

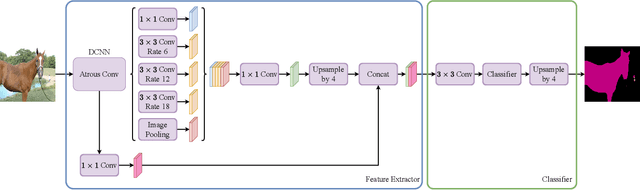
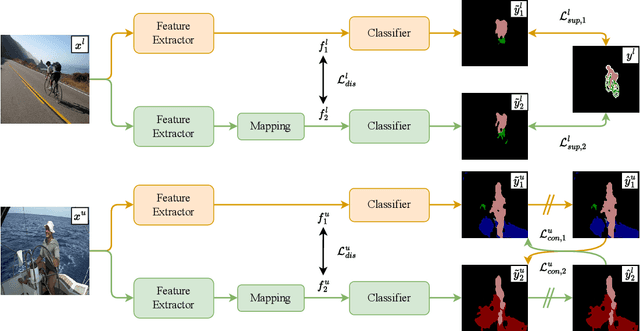
Semi-supervised semantic segmentation has recently gained increasing research interest as it can reduce the requirement for large-scale fully-annotated training data by effectively exploiting large amounts of unlabelled data. The current methods often suffer from the confirmation bias from the pseudo-labelling process, which can be alleviated by the co-training framework. The current co-training-based semi-supervised semantic segmentation methods rely on hand-crafted perturbations to prevent the different sub-nets from collapsing into each other, but these artificial perturbations cannot lead to the optimal solution. In this work, we propose a new conflict-based cross-view consistency (CCVC) method based on a two-branch co-training framework for semi-supervised semantic segmentation. Our work aims at enforcing the two sub-nets to learn informative features from irrelevant views. In particular, we first propose a new cross-view consistency (CVC) strategy that encourages the two sub-nets to learn distinct features from the same input by introducing a feature discrepancy loss, while these distinct features are expected to generate consistent prediction scores of the input. The CVC strategy helps to prevent the two sub-nets from stepping into the collapse. In addition, we further propose a conflict-based pseudo-labelling (CPL) method to guarantee the model will learn more useful information from conflicting predictions, which will lead to a stable training process. We validate our new semi-supervised semantic segmentation approach on the widely used benchmark datasets PASCAL VOC 2012 and Cityscapes, where our method achieves new state-of-the-art performance.
Automated Structural-level Alignment of Multi-view TLS and ALS Point Clouds in Forestry
Feb 25, 2023
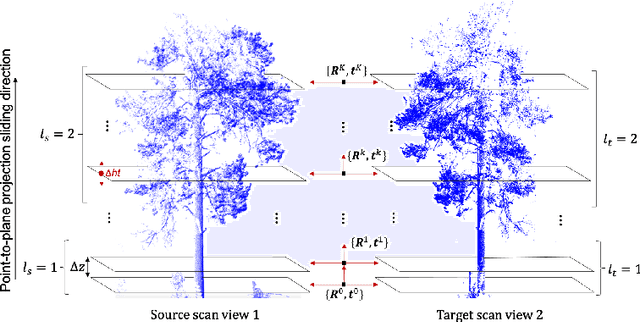
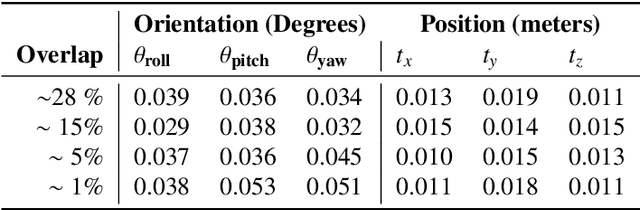
Access to highly detailed models of heterogeneous forests from the near surface to above the tree canopy at varying scales is of increasing demand as it enables more advanced computational tools for analysis, planning, and ecosystem management. LiDAR sensors available through different scanning platforms including terrestrial, mobile and aerial have become established as one of the primary technologies for forest mapping due to their inherited capability to collect direct, precise and rapid 3D information of a scene. However, their scalability to large forest areas is highly dependent upon use of effective and efficient methods of co-registration of multiple scan sources. Surprisingly, work in forestry in GPS denied areas has mostly resorted to methods of co-registration that use reference based targets (e.g., reflective, marked trees), a process far from scalable in practice. In this work, we propose an effective, targetless and fully automatic method based on an incremental co-registration strategy matching and grouping points according to levels of structural complexity. Empirical evidence shows the method's effectiveness in aligning both TLS-to-TLS and TLS-to-ALS scans under a variety of ecosystem conditions including pre/post fire treatment effects, of interest to forest inventory surveyors.
Lifting the Information Ratio: An Information-Theoretic Analysis of Thompson Sampling for Contextual Bandits
May 27, 2022We study the Bayesian regret of the renowned Thompson Sampling algorithm in contextual bandits with binary losses and adversarially-selected contexts. We adapt the information-theoretic perspective of Russo and Van Roy [2016] to the contextual setting by introducing a new concept of information ratio based on the mutual information between the unknown model parameter and the observed loss. This allows us to bound the regret in terms of the entropy of the prior distribution through a remarkably simple proof, and with no structural assumptions on the likelihood or the prior. The extension to priors with infinite entropy only requires a Lipschitz assumption on the log-likelihood. An interesting special case is that of logistic bandits with d-dimensional parameters, K actions, and Lipschitz logits, for which we provide a $\widetilde{O}(\sqrt{dKT})$ regret upper-bound that does not depend on the smallest slope of the sigmoid link function.
The Role of Semantic Parsing in Understanding Procedural Text
Feb 14, 2023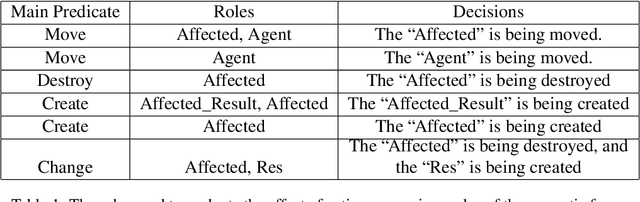
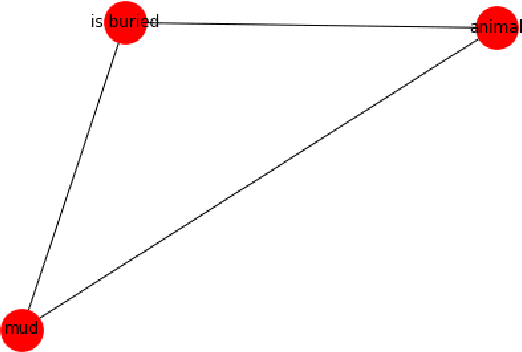

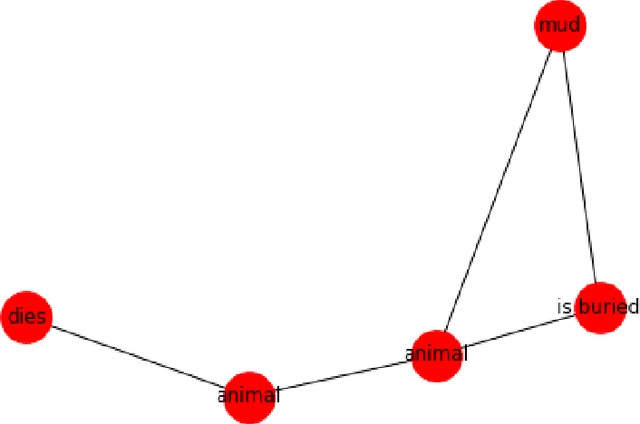
In this paper, we investigate whether symbolic semantic representations, extracted from deep semantic parsers, can help reasoning over the states of involved entities in a procedural text. We consider a deep semantic parser~(TRIPS) and semantic role labeling as two sources of semantic parsing knowledge. First, we propose PROPOLIS, a symbolic parsing-based procedural reasoning framework. Second, we integrate semantic parsing information into state-of-the-art neural models to conduct procedural reasoning. Our experiments indicate that explicitly incorporating such semantic knowledge improves procedural understanding. This paper presents new metrics for evaluating procedural reasoning tasks that clarify the challenges and identify differences among neural, symbolic, and integrated models.