 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
More Data Types More Problems: A Temporal Analysis of Complexity, Stability, and Sensitivity in Privacy Policies
Feb 17, 2023
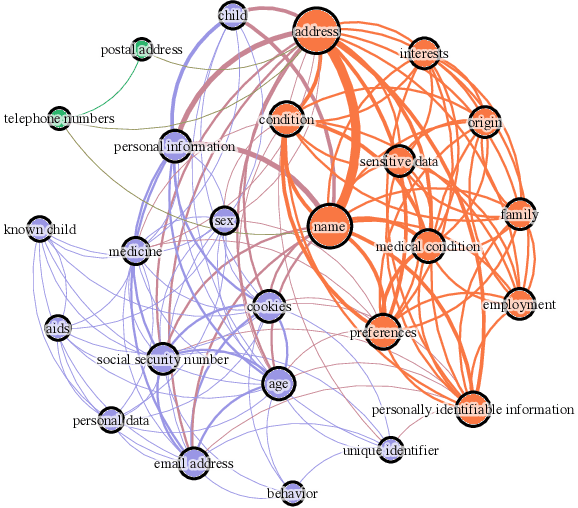
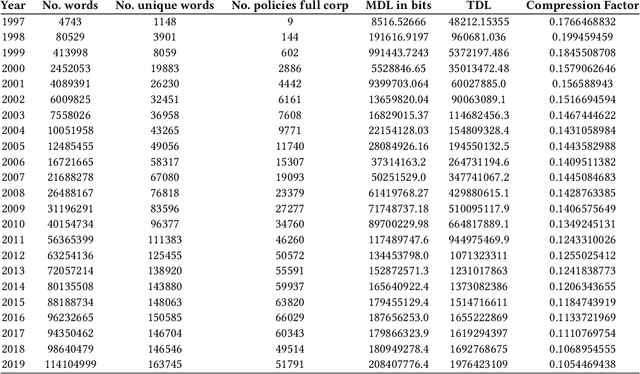

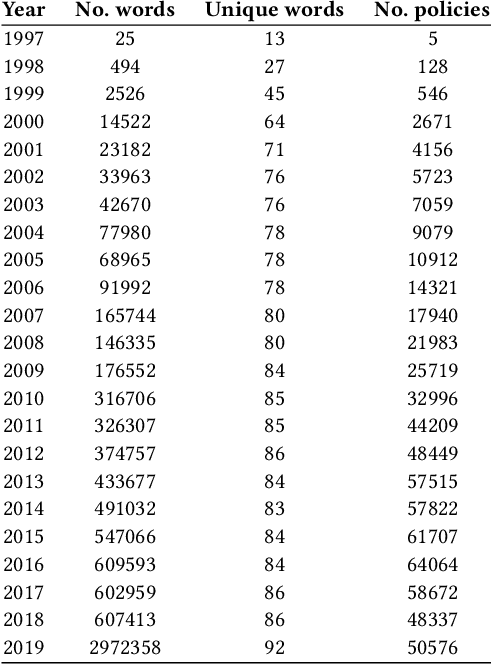
Collecting personally identifiable information (PII) on data subjects has become big business. Data brokers and data processors are part of a multi-billion-dollar industry that profits from collecting, buying, and selling consumer data. Yet there is little transparency in the data collection industry which makes it difficult to understand what types of data are being collected, used, and sold, and thus the risk to individual data subjects. In this study, we examine a large textual dataset of privacy policies from 1997-2019 in order to investigate the data collection activities of data brokers and data processors. We also develop an original lexicon of PII-related terms representing PII data types curated from legislative texts. This mesoscale analysis looks at privacy policies overtime on the word, topic, and network levels to understand the stability, complexity, and sensitivity of privacy policies over time. We find that (1) privacy legislation correlates with changes in stability and turbulence of PII data types in privacy policies; (2) the complexity of privacy policies decreases over time and becomes more regularized; (3) sensitivity rises over time and shows spikes that are correlated with events when new privacy legislation is introduced.
INSCIT: Information-Seeking Conversations with Mixed-Initiative Interactions
Jul 02, 2022

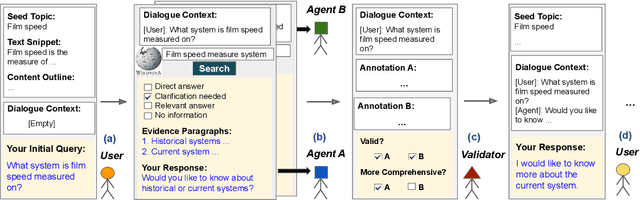
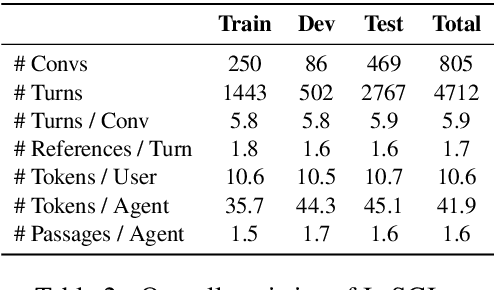
In an information-seeking conversation, a user converses with an agent to ask a series of questions that can often be under- or over-specified. An ideal agent would first identify that they were in such a situation by searching through their underlying knowledge source and then appropriately interacting with a user to resolve it. However, most existing studies either fail to or artificially incorporate such agent-side initiatives. In this work, we present INSCIT (pronounced Insight), a dataset for information-seeking conversations with mixed-initiative interactions. It contains a total of 4.7K user-agent turns from 805 human-human conversations where the agent searches over Wikipedia and either asks for clarification or provides relevant information to address user queries. We define two subtasks, namely evidence passage identification and response generation, as well as a new human evaluation protocol to assess the model performance. We report results of two strong baselines based on state-of-the-art models of conversational knowledge identification and open-domain question answering. Both models significantly underperform humans and fail to generate coherent and informative responses, suggesting ample room for improvement in future studies.
INCREASE: Inductive Graph Representation Learning for Spatio-Temporal Kriging
Feb 06, 2023
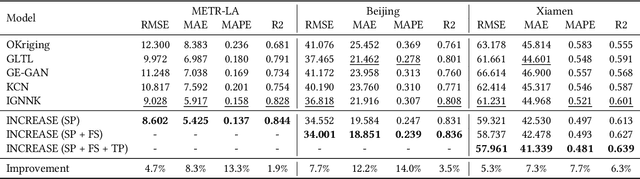
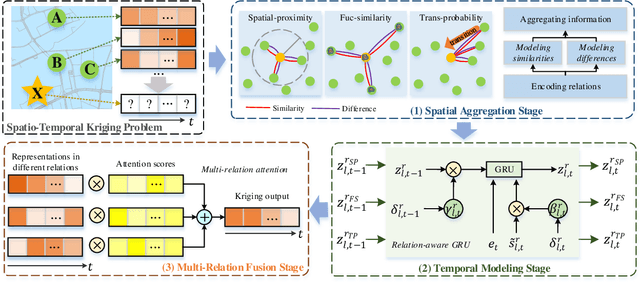
Spatio-temporal kriging is an important problem in web and social applications, such as Web or Internet of Things, where things (e.g., sensors) connected into a web often come with spatial and temporal properties. It aims to infer knowledge for (the things at) unobserved locations using the data from (the things at) observed locations during a given time period of interest. This problem essentially requires \emph{inductive learning}. Once trained, the model should be able to perform kriging for different locations including newly given ones, without retraining. However, it is challenging to perform accurate kriging results because of the heterogeneous spatial relations and diverse temporal patterns. In this paper, we propose a novel inductive graph representation learning model for spatio-temporal kriging. We first encode heterogeneous spatial relations between the unobserved and observed locations by their spatial proximity, functional similarity, and transition probability. Based on each relation, we accurately aggregate the information of most correlated observed locations to produce inductive representations for the unobserved locations, by jointly modeling their similarities and differences. Then, we design relation-aware gated recurrent unit (GRU) networks to adaptively capture the temporal correlations in the generated sequence representations for each relation. Finally, we propose a multi-relation attention mechanism to dynamically fuse the complex spatio-temporal information at different time steps from multiple relations to compute the kriging output. Experimental results on three real-world datasets show that our proposed model outperforms state-of-the-art methods consistently, and the advantage is more significant when there are fewer observed locations. Our code is available at https://github.com/zhengchuanpan/INCREASE.
Tree-Based Learning on Amperometric Time Series Data Demonstrates High Accuracy for Classification
Feb 06, 2023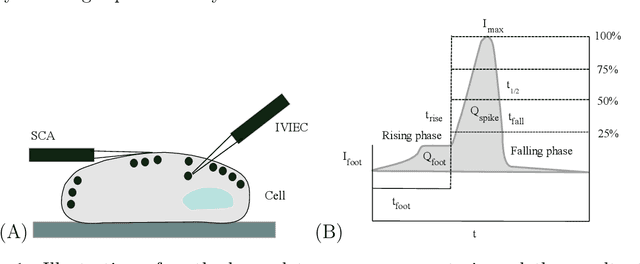
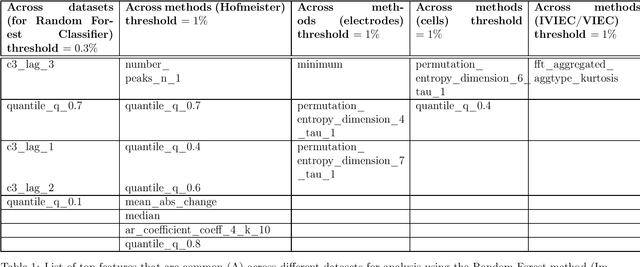
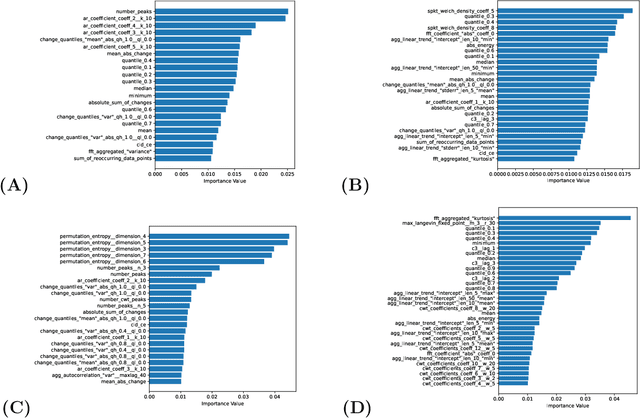
Elucidating exocytosis processes provide insights into cellular neurotransmission mechanisms, and may have potential in neurodegenerative diseases research. Amperometry is an established electrochemical method for the detection of neurotransmitters released from and stored inside cells. An important aspect of the amperometry method is the sub-millisecond temporal resolution of the current recordings which leads to several hundreds of gigabytes of high-quality data. In this study, we present a universal method for the classification with respect to diverse amperometric datasets using data-driven approaches in computational science. We demonstrate a very high prediction accuracy (greater than or equal to 95%). This includes an end-to-end systematic machine learning workflow for amperometric time series datasets consisting of pre-processing; feature extraction; model identification; training and testing; followed by feature importance evaluation - all implemented. We tested the method on heterogeneous amperometric time series datasets generated using different experimental approaches, chemical stimulations, electrode types, and varying recording times. We identified a certain overarching set of common features across these datasets which enables accurate predictions. Further, we showed that information relevant for the classification of amperometric traces are neither in the spiky segments alone, nor can it be retrieved from just the temporal structure of spikes. In fact, the transients between spikes and the trace baselines carry essential information for a successful classification, thereby strongly demonstrating that an effective feature representation of amperometric time series requires the full time series. To our knowledge, this is one of the first studies that propose a scheme for machine learning, and in particular, supervised learning on full amperometry time series data.
Intra-operative Brain Tumor Detection with Deep Learning-Optimized Hyperspectral Imaging
Feb 06, 2023
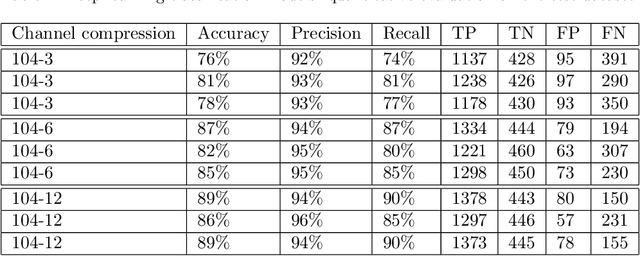
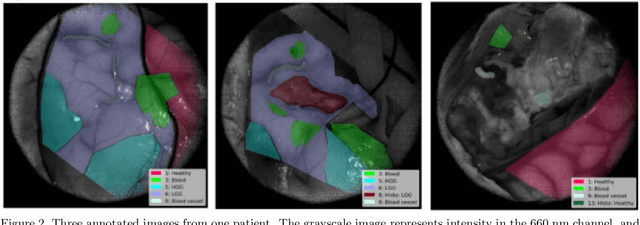
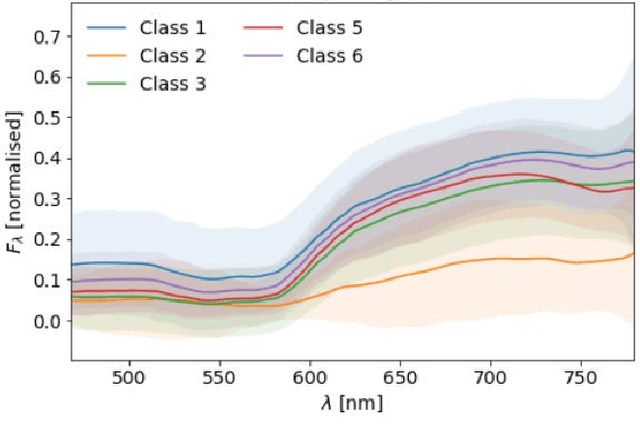
Surgery for gliomas (intrinsic brain tumors), especially when low-grade, is challenging due to the infiltrative nature of the lesion. Currently, no real-time, intra-operative, label-free and wide-field tool is available to assist and guide the surgeon to find the relevant demarcations for these tumors. While marker-based methods exist for the high-grade glioma case, there is no convenient solution available for the low-grade case; thus, marker-free optical techniques represent an attractive option. Although RGB imaging is a standard tool in surgical microscopes, it does not contain sufficient information for tissue differentiation. We leverage the richer information from hyperspectral imaging (HSI), acquired with a snapscan camera in the 468-787 nm range, coupled to a surgical microscope, to build a deep-learning-based diagnostic tool for cancer resection with potential for intra-operative guidance. However, the main limitation of the HSI snapscan camera is the image acquisition time, limiting its widespread deployment in the operation theater. Here, we investigate the effect of HSI channel reduction and pre-selection to scope the design space for the development of cheaper and faster sensors. Neural networks are used to identify the most important spectral channels for tumor tissue differentiation, optimizing the trade-off between the number of channels and precision to enable real-time intra-surgical application. We evaluate the performance of our method on a clinical dataset that was acquired during surgery on five patients. By demonstrating the possibility to efficiently detect low-grade glioma, these results can lead to better cancer resection demarcations, potentially improving treatment effectiveness and patient outcome.
Compact Transformer Tracker with Correlative Masked Modeling
Jan 26, 2023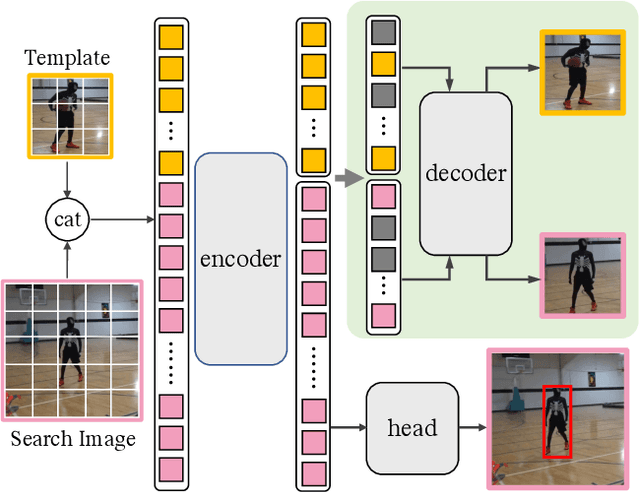
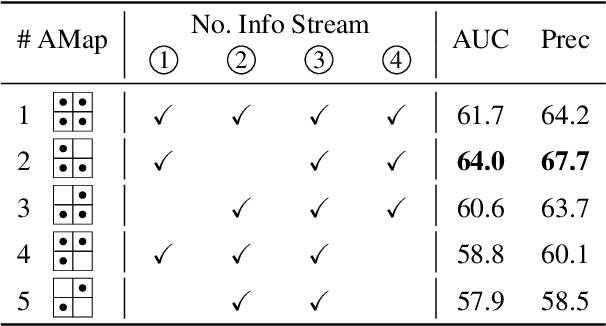
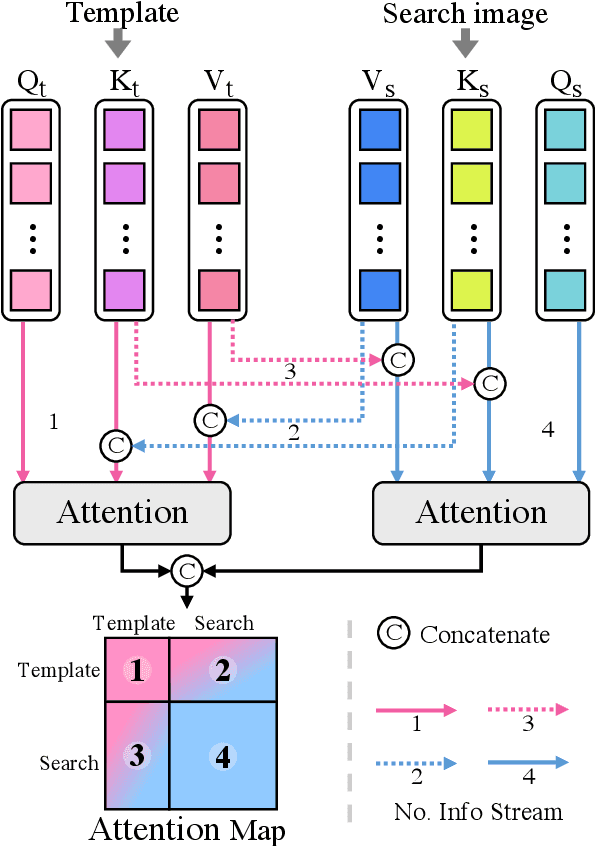
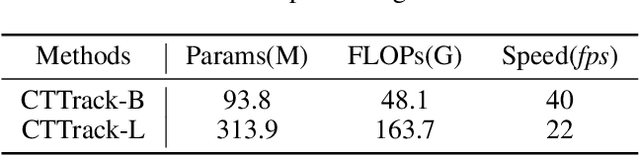
Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.
Offline-to-Online Knowledge Distillation for Video Instance Segmentation
Feb 15, 2023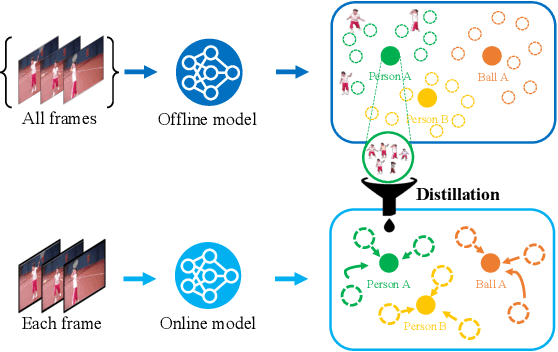
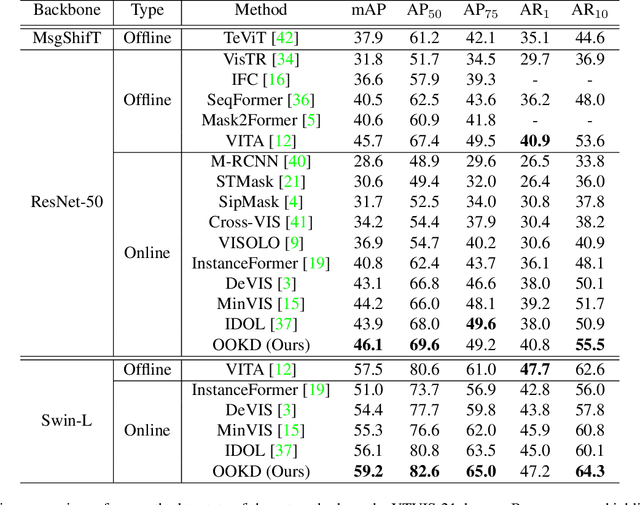

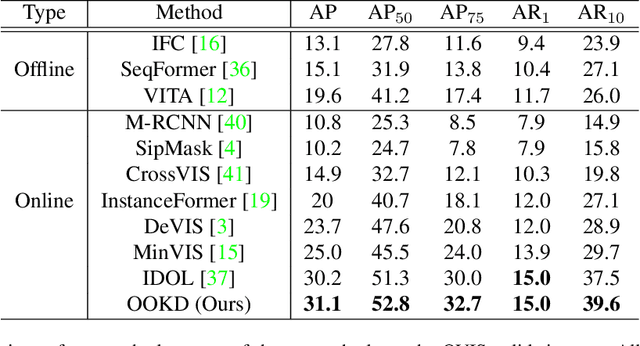
In this paper, we present offline-to-online knowledge distillation (OOKD) for video instance segmentation (VIS), which transfers a wealth of video knowledge from an offline model to an online model for consistent prediction. Unlike previous methods that having adopting either an online or offline model, our single online model takes advantage of both models by distilling offline knowledge. To transfer knowledge correctly, we propose query filtering and association (QFA), which filters irrelevant queries to exact instances. Our KD with QFA increases the robustness of feature matching by encoding object-centric features from a single frame supplemented by long-range global information. We also propose a simple data augmentation scheme for knowledge distillation in the VIS task that fairly transfers the knowledge of all classes into the online model. Extensive experiments show that our method significantly improves the performance in video instance segmentation, especially for challenging datasets including long, dynamic sequences. Our method also achieves state-of-the-art performance on YTVIS-21, YTVIS-22, and OVIS datasets, with mAP scores of 46.1%, 43.6%, and 31.1%, respectively.
Similarity, Compression and Local Steps: Three Pillars of Efficient Communications for Distributed Variational Inequalities
Feb 15, 2023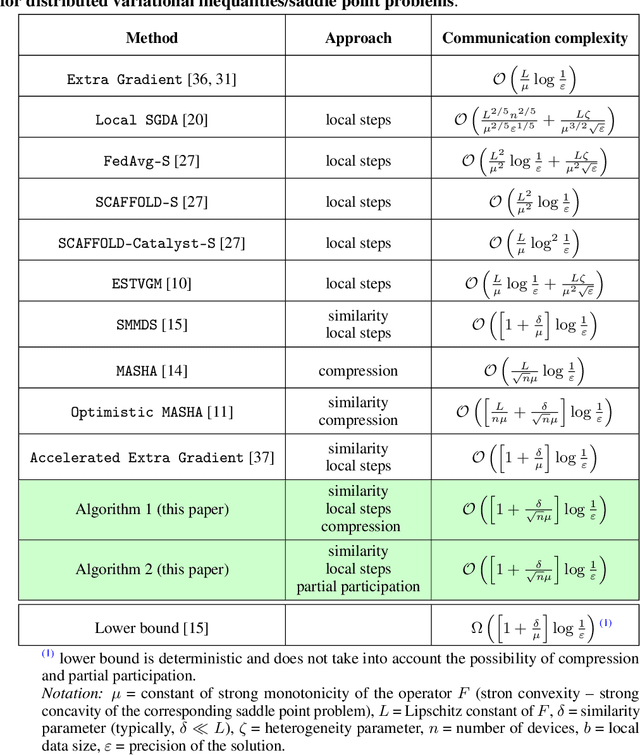
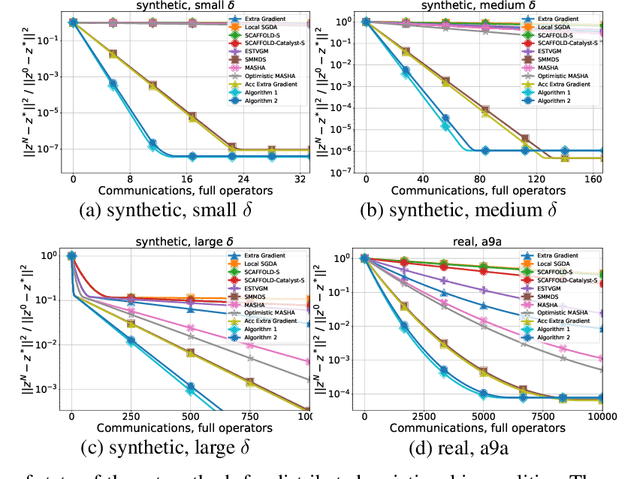
Variational inequalities are a broad and flexible class of problems that includes minimization, saddle point, fixed point problems as special cases. Therefore, variational inequalities are used in a variety of applications ranging from equilibrium search to adversarial learning. Today's realities with the increasing size of data and models demand parallel and distributed computing for real-world machine learning problems, most of which can be represented as variational inequalities. Meanwhile, most distributed approaches has a significant bottleneck - the cost of communications. The three main techniques to reduce both the total number of communication rounds and the cost of one such round are the use of similarity of local functions, compression of transmitted information and local updates. In this paper, we combine all these approaches. Such a triple synergy did not exist before for variational inequalities and saddle problems, nor even for minimization problems. The methods presented in this paper have the best theoretical guarantees of communication complexity and are significantly ahead of other methods for distributed variational inequalities. The theoretical results are confirmed by adversarial learning experiments on synthetic and real datasets.
USER: Unsupervised Structural Entropy-based Robust Graph Neural Network
Feb 12, 2023
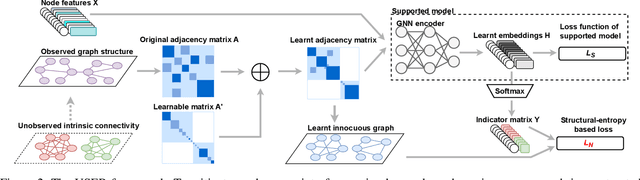
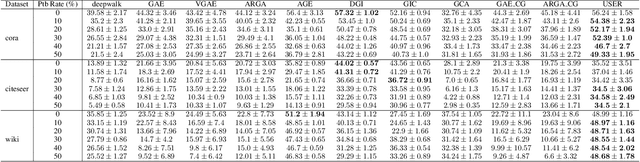
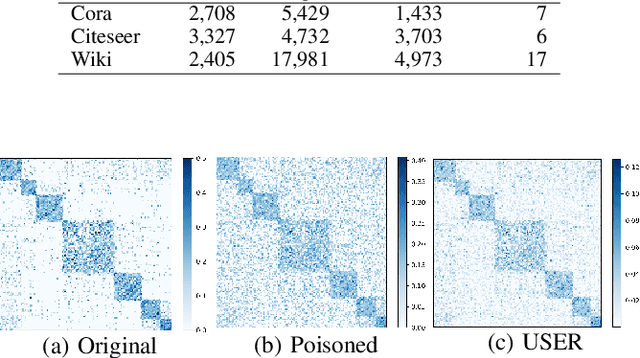
Unsupervised/self-supervised graph neural networks (GNN) are vulnerable to inherent randomness in the input graph data which greatly affects the performance of the model in downstream tasks. In this paper, we alleviate the interference of graph randomness and learn appropriate representations of nodes without label information. To this end, we propose USER, an unsupervised robust version of graph neural networks that is based on structural entropy. We analyze the property of intrinsic connectivity and define intrinsic connectivity graph. We also identify the rank of the adjacency matrix as a crucial factor in revealing a graph that provides the same embeddings as the intrinsic connectivity graph. We then introduce structural entropy in the objective function to capture such a graph. Extensive experiments conducted on clustering and link prediction tasks under random-noises and meta-attack over three datasets show USER outperforms benchmarks and is robust to heavier randomness.
Contrastive Learning and the Emergence of Attributes Associations
Feb 12, 2023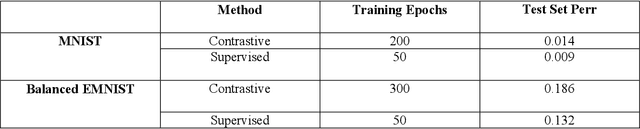
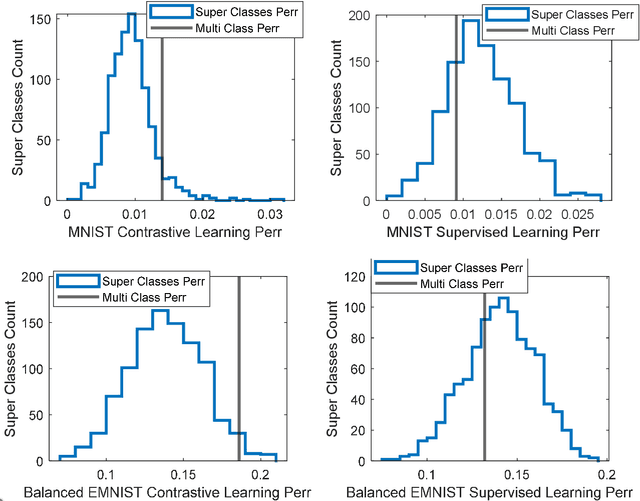
In response to an object presentation, supervised learning schemes generally respond with a parsimonious label. Upon a similar presentation we humans respond again with a label, but are flooded, in addition, by a myriad of associations. A significant portion of these consist of the presented object attributes. Contrastive learning is a semi-supervised learning scheme based on the application of identity preserving transformations on the object input representations. It is conjectured in this work that these same applied transformations preserve, in addition to the identity of the presented object, also the identity of its semantically meaningful attributes. The corollary of this is that the output representations of such a contrastive learning scheme contain valuable information not only for the classification of the presented object, but also for the presence or absence decision of any attribute of interest. Simulation results which demonstrate this idea and the feasibility of this conjecture are presented.