 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Energy-Based Test Sample Adaptation for Domain Generalization
Feb 22, 2023
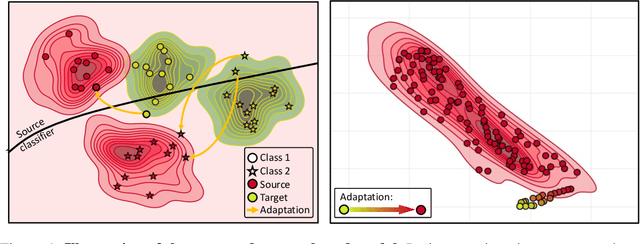

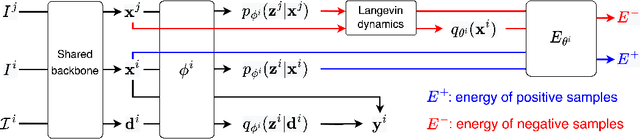
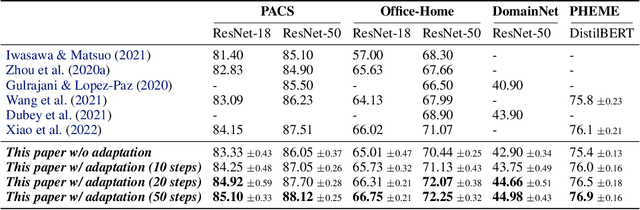
In this paper, we propose energy-based sample adaptation at test time for domain generalization. Where previous works adapt their models to target domains, we adapt the unseen target samples to source-trained models. To this end, we design a discriminative energy-based model, which is trained on source domains to jointly model the conditional distribution for classification and data distribution for sample adaptation. The model is optimized to simultaneously learn a classifier and an energy function. To adapt target samples to source distributions, we iteratively update the samples by energy minimization with stochastic gradient Langevin dynamics. Moreover, to preserve the categorical information in the sample during adaptation, we introduce a categorical latent variable into the energy-based model. The latent variable is learned from the original sample before adaptation by variational inference and fixed as a condition to guide the sample update. Experiments on six benchmarks for classification of images and microblog threads demonstrate the effectiveness of our proposal.
Faster Riemannian Newton-type Optimization by Subsampling and Cubic Regularization
Feb 22, 2023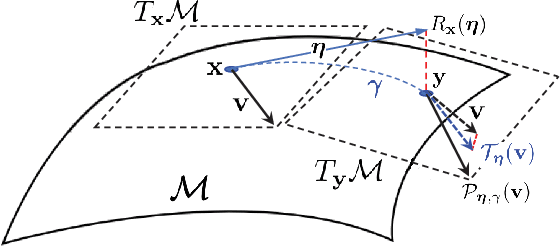
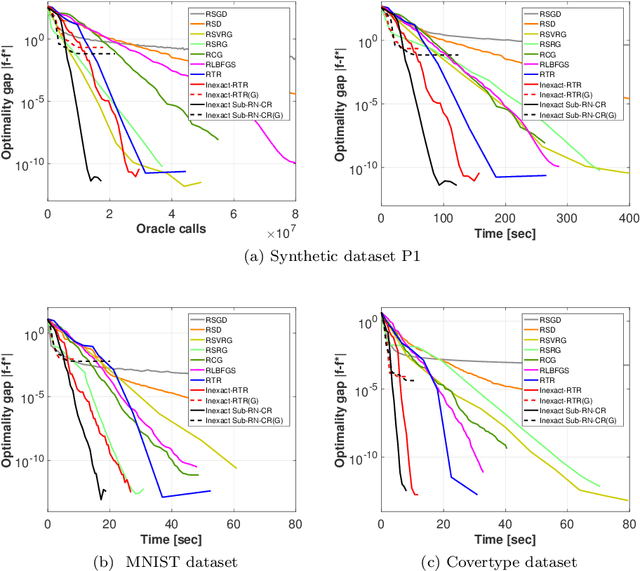
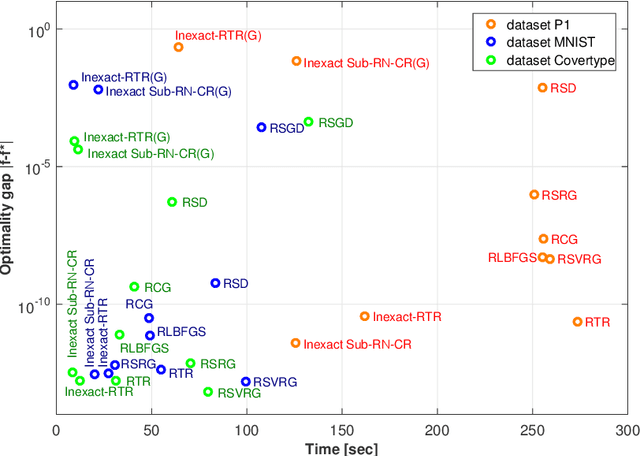
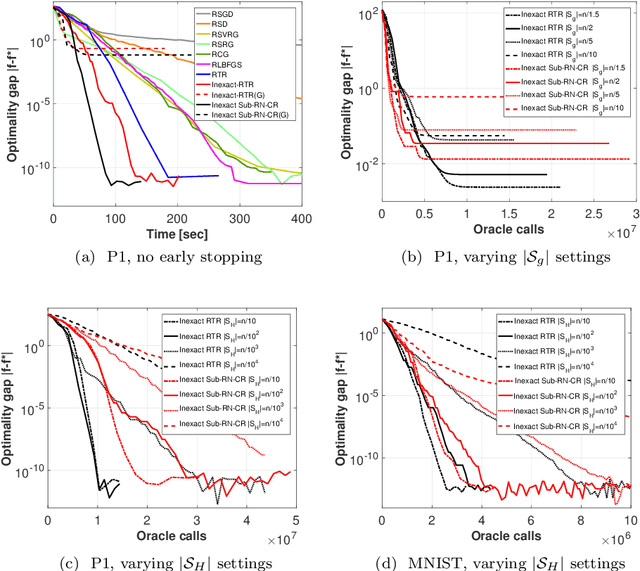
This work is on constrained large-scale non-convex optimization where the constraint set implies a manifold structure. Solving such problems is important in a multitude of fundamental machine learning tasks. Recent advances on Riemannian optimization have enabled the convenient recovery of solutions by adapting unconstrained optimization algorithms over manifolds. However, it remains challenging to scale up and meanwhile maintain stable convergence rates and handle saddle points. We propose a new second-order Riemannian optimization algorithm, aiming at improving convergence rate and reducing computational cost. It enhances the Riemannian trust-region algorithm that explores curvature information to escape saddle points through a mixture of subsampling and cubic regularization techniques. We conduct rigorous analysis to study the convergence behavior of the proposed algorithm. We also perform extensive experiments to evaluate it based on two general machine learning tasks using multiple datasets. The proposed algorithm exhibits improved computational speed and convergence behavior compared to a large set of state-of-the-art Riemannian optimization algorithms.
A Multi-Modal Neural Geometric Solver with Textual Clauses Parsed from Diagram
Feb 22, 2023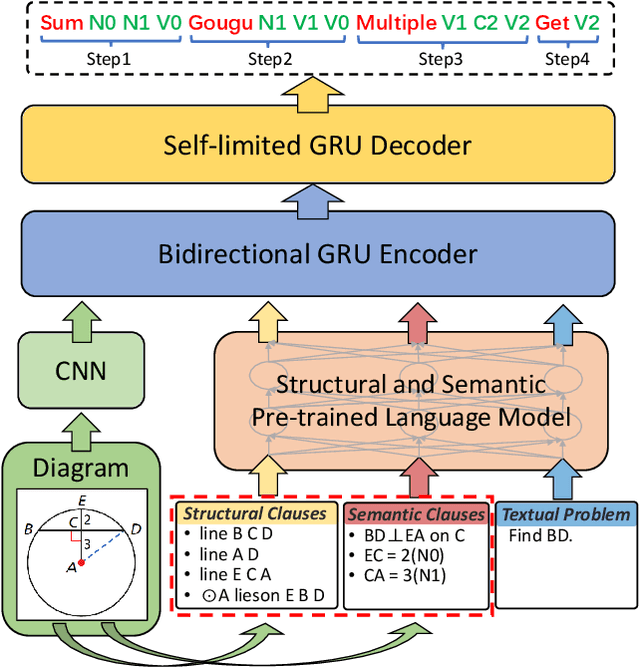


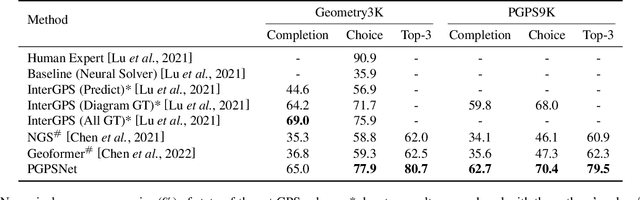
Geometry problem solving (GPS) is a high-level mathematical reasoning requiring the capacities of multi-modal fusion and geometric knowledge application. Recently, neural solvers have shown great potential in GPS but still be short in diagram presentation and modal fusion. In this work, we convert diagrams into basic textual clauses to describe diagram features effectively, and propose a new neural solver called PGPSNet to fuse multi-modal information efficiently. Combining structural and semantic pre-training, data augmentation and self-limited decoding, PGPSNet is endowed with rich knowledge of geometry theorems and geometric representation, and therefore promotes geometric understanding and reasoning. In addition, to facilitate the research of GPS, we build a new large-scale and fine-annotated GPS dataset named PGPS9K, labeled with both fine-grained diagram annotation and interpretable solution program. Experiments on PGPS9K and an existing dataset Geometry3K validate the superiority of our method over the state-of-the-art neural solvers. The code and dataset will be public available soon.
Personalized Federated Learning with Hidden Information on Personalized Prior
Nov 19, 2022



Federated learning (FL for simplification) is a distributed machine learning technique that utilizes global servers and collaborative clients to achieve privacy-preserving global model training without direct data sharing. However, heterogeneous data problem, as one of FL's main problems, makes it difficult for the global model to perform effectively on each client's local data. Thus, personalized federated learning (PFL for simplification) aims to improve the performance of the model on local data as much as possible. Bayesian learning, where the parameters of the model are seen as random variables with a prior assumption, is a feasible solution to the heterogeneous data problem due to the tendency that the more local data the model use, the more it focuses on the local data, otherwise focuses on the prior. When Bayesian learning is applied to PFL, the global model provides global knowledge as a prior to the local training process. In this paper, we employ Bayesian learning to model PFL by assuming a prior in the scaled exponential family, and therefore propose pFedBreD, a framework to solve the problem we model using Bregman divergence regularization. Empirically, our experiments show that, under the prior assumption of the spherical Gaussian and the first order strategy of mean selection, our proposal significantly outcompetes other PFL algorithms on multiple public benchmarks.
Exploiting Intelligent Reflecting Surfaces for Interference Channels with SWIPT
Mar 06, 2023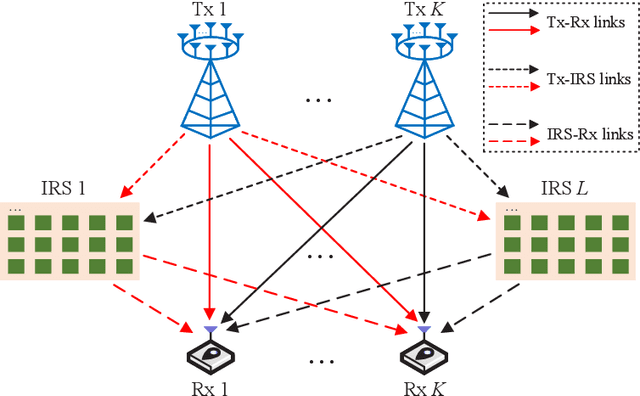
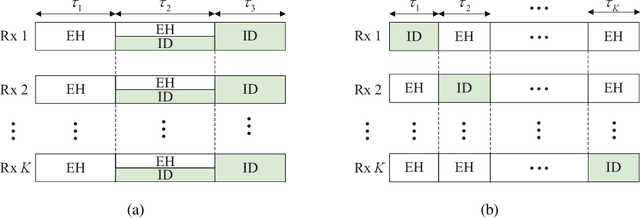
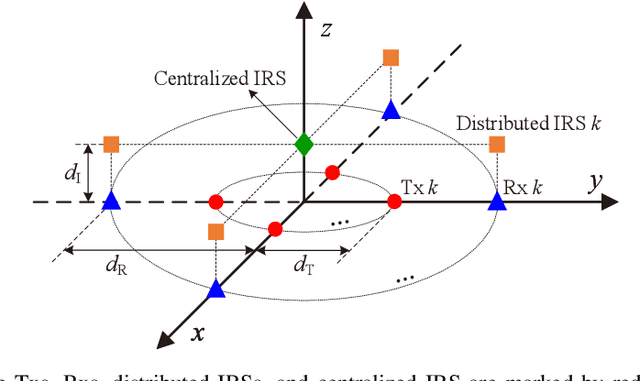
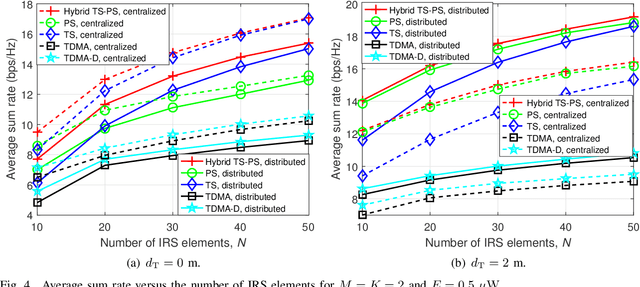
This paper considers intelligent reflecting surface (IRS)-aided simultaneous wireless information and power transfer (SWIPT) in a multi-user multiple-input single-output (MISO) interference channel (IFC), where multiple transmitters (Txs) serve their corresponding receivers (Rxs) in a shared spectrum with the aid of IRSs. Our goal is to maximize the sum rate of the Rxs by jointly optimizing the transmit covariance matrices at the Txs, the phase shifts at the IRSs, and the resource allocation subject to the individual energy harvesting (EH) constraints at the Rxs. Towards this goal and based on the well-known power splitting (PS) and time switching (TS) receiver structures, we consider three practical transmission schemes, namely the IRS-aided hybrid TS-PS scheme, the IRS-aided time-division multiple access (TDMA) scheme, and the IRS-aided TDMA-D scheme. The latter two schemes differ in whether the Txs employ deterministic energy signals known to all the Rxs. Despite the non-convexity of the three optimization problems corresponding to the three transmission schemes, we develop computationally efficient algorithms to address them suboptimally, respectively, by capitalizing on the techniques of alternating optimization (AO) and successive convex approximation (SCA). Moreover, we conceive feasibility checking methods for these problems, based on which the initial points for the proposed algorithms are constructed. Simulation results demonstrate that our proposed IRS-aided schemes significantly outperform their counterparts without IRSs in terms of sum rate and maximum EH requirements that can be satisfied under various setups. In addition, the IRS-aided hybrid TS-PS scheme generally achieves the best sum rate performance among the three proposed IRS-aided schemes, and if not, increasing the number of IRS elements can always accomplish it.
On the Role of Memory in Robust Opinion Dynamics
Feb 16, 2023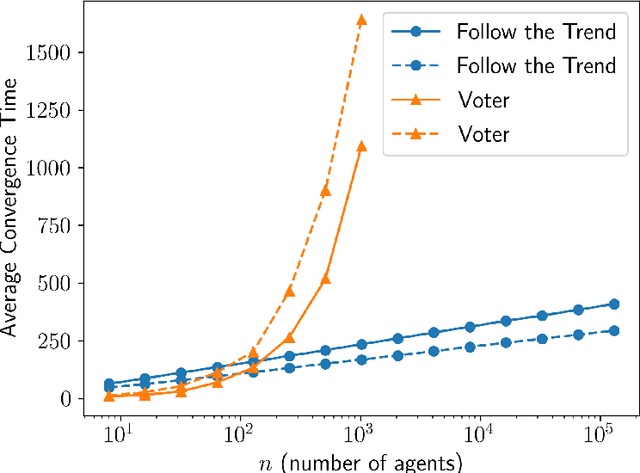
We investigate opinion dynamics in a fully-connected system, consisting of $n$ identical and anonymous agents, where one of the opinions (which is called correct) represents a piece of information to disseminate. In more detail, one source agent initially holds the correct opinion and remains with this opinion throughout the execution. The goal for non-source agents is to quickly agree on this correct opinion, and do that robustly, i.e., from any initial configuration. The system evolves in rounds. In each round, one agent chosen uniformly at random is activated: unless it is the source, the agent pulls the opinions of $\ell$ random agents and then updates its opinion according to some rule. We consider a restricted setting, in which agents have no memory and they only revise their opinions on the basis of those of the agents they currently sample. As restricted as it is, this setting encompasses very popular opinion dynamics, such as the voter model and best-of-$k$ majority rules. Qualitatively speaking, we show that lack of memory prevents efficient convergence. Specifically, we prove that no dynamics can achieve correct convergence in an expected number of steps that is sub-quadratic in $n$, even under a strong version of the model in which activated agents have complete access to the current configuration of the entire system, i.e., the case $\ell=n$. Conversely, we prove that the simple voter model (in which $\ell=1$) correctly solves the problem, while almost matching the aforementioned lower bound. These results suggest that, in contrast to symmetric consensus problems (that do not involve a notion of correct opinion), fast convergence on the correct opinion using stochastic opinion dynamics may indeed require the use of memory. This insight may reflect on natural information dissemination processes that rely on a few knowledgeable individuals.
Explainable Machine Learning: The Importance of a System-Centric Perspective
Feb 05, 2023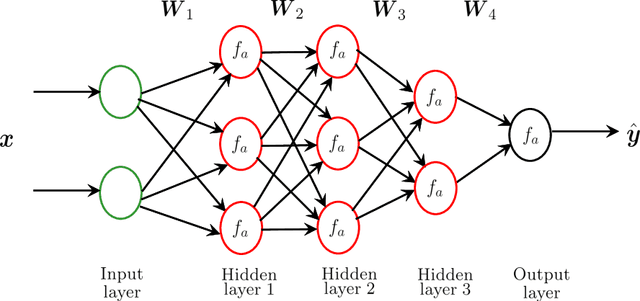
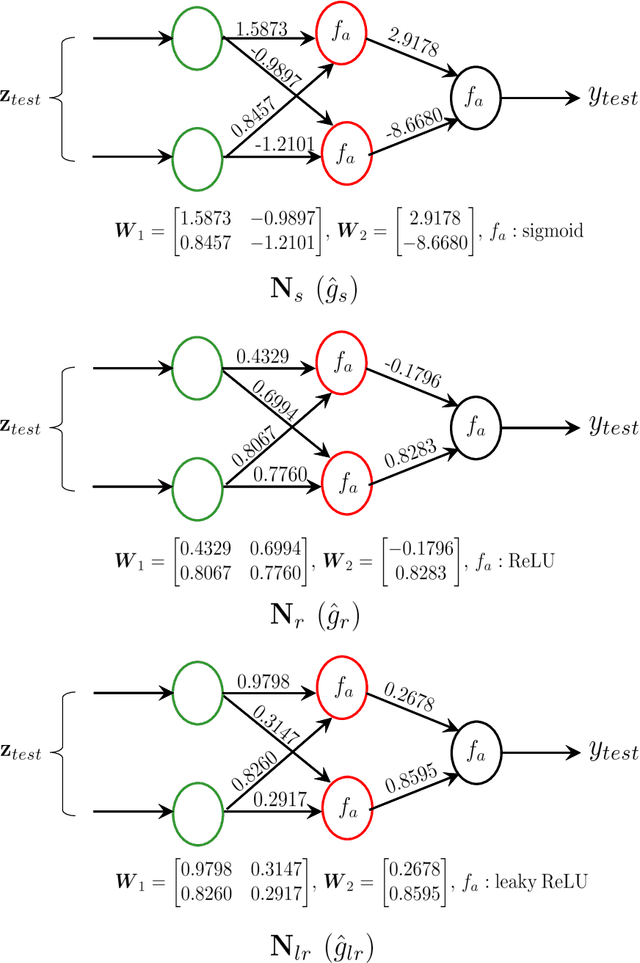
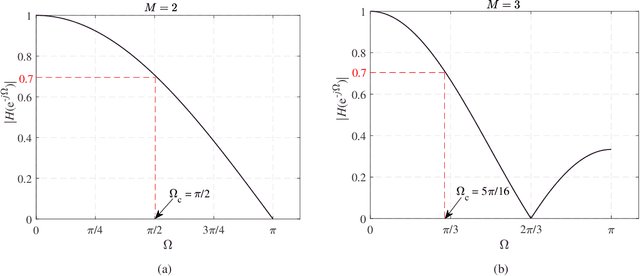
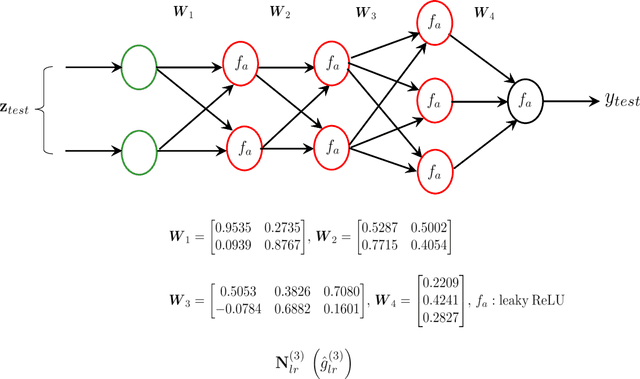
The landscape in the context of several signal processing applications and even education appears to be significantly affected by the emergence of machine learning (ML) and in particular deep learning (DL).The main reason for this is the ability of DL to model complex and unknown relationships between signals and the tasks of interest. Particularly, supervised DL algorithms have been fairly successful at recognizing perceptually or semantically useful signal information in different applications. In all of these, the training process uses labeled data to learn a mapping function (typically implicitly) from signals to the desired information (class label or target label). The trained DL model is then expected to correctly recognize/classify relevant information in a given test signal. A DL based framework is therefore, in general, very appealing since the features and characteristics of the required mapping are learned almost exclusively from the data without resorting to explicit model/system development. The focus on implicit modeling however also raises the issue of lack of explainability/interpretability of the resultant DL based mapping or the black box problem. As a result, explainable ML/DL is an active research area where the primary goal is to elaborate how the ML/DL model arrived at a prediction. We however note that despite the efforts, the commentary on black box problem appears to lack a technical discussion from the view point of: a) its origin and underlying reasons, and b) its practical implications on the design and deployment of ML/DL systems. Accordingly, a reasonable question that can be raised is as follows. Can the traditional system-centric approach (which places emphasis on explicit system modeling) provide useful insights into the nature of black box problem, and help develop more transparent ML/DL systems?
High-dimensional Location Estimation via Norm Concentration for Subgamma Vectors
Feb 05, 2023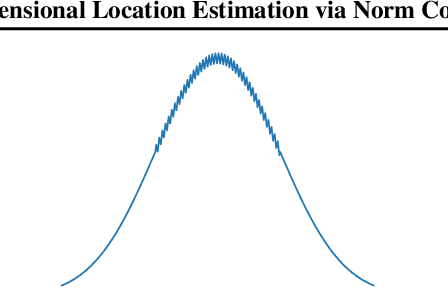
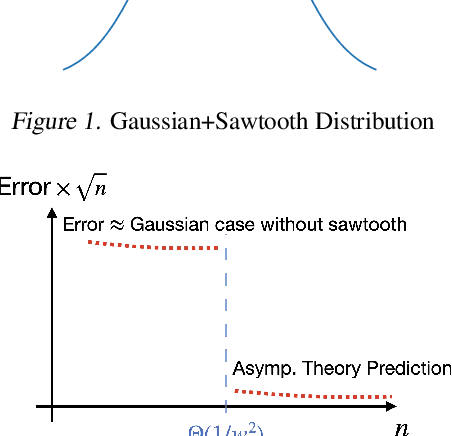
In location estimation, we are given $n$ samples from a known distribution $f$ shifted by an unknown translation $\lambda$, and want to estimate $\lambda$ as precisely as possible. Asymptotically, the maximum likelihood estimate achieves the Cram\'er-Rao bound of error $\mathcal N(0, \frac{1}{n\mathcal I})$, where $\mathcal I$ is the Fisher information of $f$. However, the $n$ required for convergence depends on $f$, and may be arbitrarily large. We build on the theory using \emph{smoothed} estimators to bound the error for finite $n$ in terms of $\mathcal I_r$, the Fisher information of the $r$-smoothed distribution. As $n \to \infty$, $r \to 0$ at an explicit rate and this converges to the Cram\'er-Rao bound. We (1) improve the prior work for 1-dimensional $f$ to converge for constant failure probability in addition to high probability, and (2) extend the theory to high-dimensional distributions. In the process, we prove a new bound on the norm of a high-dimensional random variable whose 1-dimensional projections are subgamma, which may be of independent interest.
The Inadequacy of Shapley Values for Explainability
Feb 16, 2023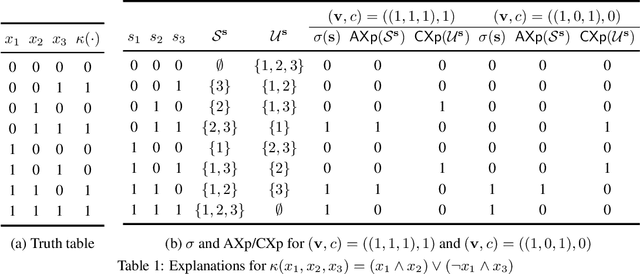
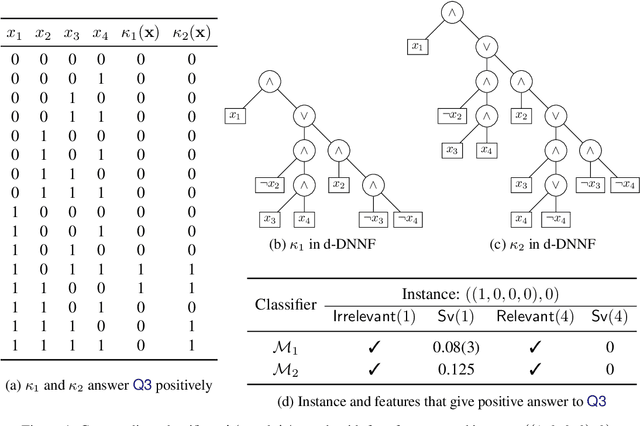

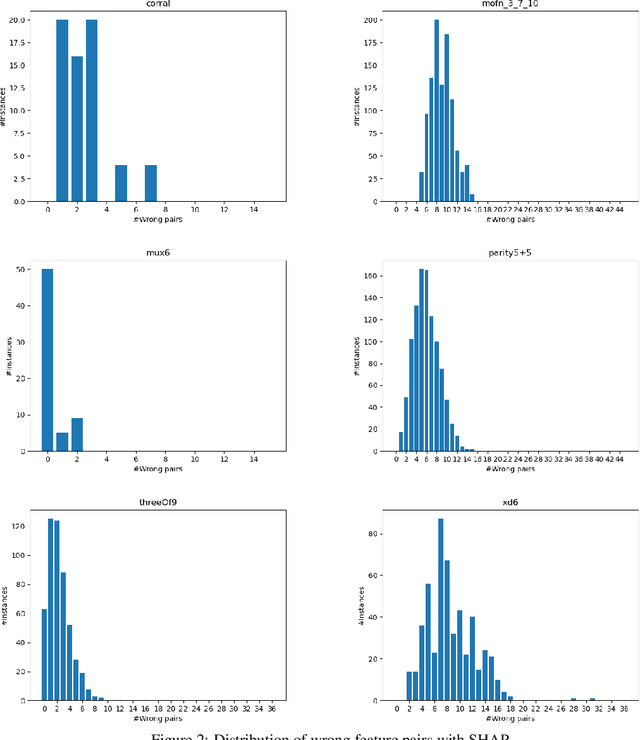
This paper develops a rigorous argument for why the use of Shapley values in explainable AI (XAI) will necessarily yield provably misleading information about the relative importance of features for predictions. Concretely, this paper demonstrates that there exist classifiers, and associated predictions, for which the relative importance of features determined by the Shapley values will incorrectly assign more importance to features that are provably irrelevant for the prediction, and less importance to features that are provably relevant for the prediction. The paper also argues that, given recent complexity results, the existence of efficient algorithms for the computation of rigorous feature attribution values in the case of some restricted classes of classifiers should be deemed unlikely at best.
CFFT-GAN: Cross-domain Feature Fusion Transformer for Exemplar-based Image Translation
Feb 03, 2023

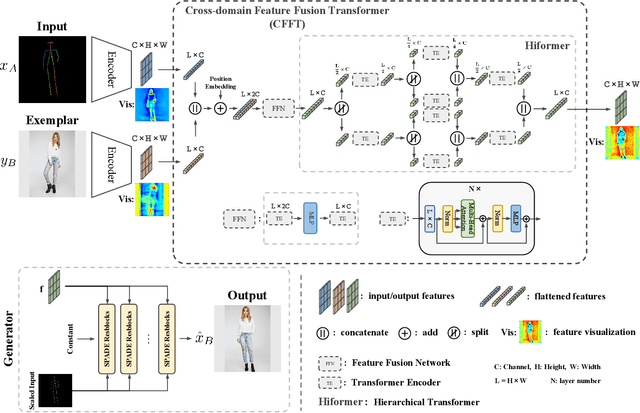
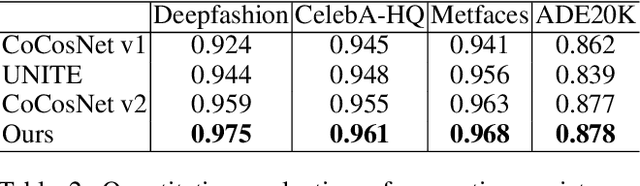
Exemplar-based image translation refers to the task of generating images with the desired style, while conditioning on certain input image. Most of the current methods learn the correspondence between two input domains and lack the mining of information within the domains. In this paper, we propose a more general learning approach by considering two domain features as a whole and learning both inter-domain correspondence and intra-domain potential information interactions. Specifically, we propose a Cross-domain Feature Fusion Transformer (CFFT) to learn inter- and intra-domain feature fusion. Based on CFFT, the proposed CFFT-GAN works well on exemplar-based image translation. Moreover, CFFT-GAN is able to decouple and fuse features from multiple domains by cascading CFFT modules. We conduct rich quantitative and qualitative experiments on several image translation tasks, and the results demonstrate the superiority of our approach compared to state-of-the-art methods. Ablation studies show the importance of our proposed CFFT. Application experimental results reflect the potential of our method.