 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RGB-D Grasp Detection via Depth Guided Learning with Cross-modal Attention
Feb 28, 2023

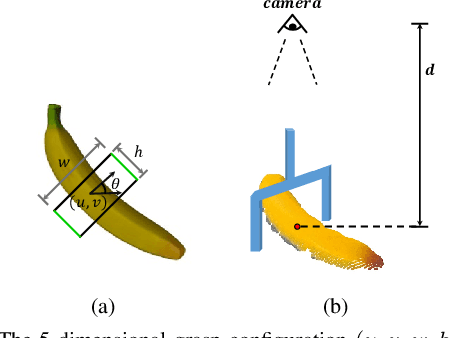
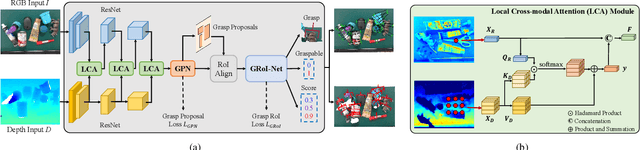

Planar grasp detection is one of the most fundamental tasks to robotic manipulation, and the recent progress of consumer-grade RGB-D sensors enables delivering more comprehensive features from both the texture and shape modalities. However, depth maps are generally of a relatively lower quality with much stronger noise compared to RGB images, making it challenging to acquire grasp depth and fuse multi-modal clues. To address the two issues, this paper proposes a novel learning based approach to RGB-D grasp detection, namely Depth Guided Cross-modal Attention Network (DGCAN). To better leverage the geometry information recorded in the depth channel, a complete 6-dimensional rectangle representation is adopted with the grasp depth dedicatedly considered in addition to those defined in the common 5-dimensional one. The prediction of the extra grasp depth substantially strengthens feature learning, thereby leading to more accurate results. Moreover, to reduce the negative impact caused by the discrepancy of data quality in two modalities, a Local Cross-modal Attention (LCA) module is designed, where the depth features are refined according to cross-modal relations and concatenated to the RGB ones for more sufficient fusion. Extensive simulation and physical evaluations are conducted and the experimental results highlight the superiority of the proposed approach.
GRAN: Ghost Residual Attention Network for Single Image Super Resolution
Feb 28, 2023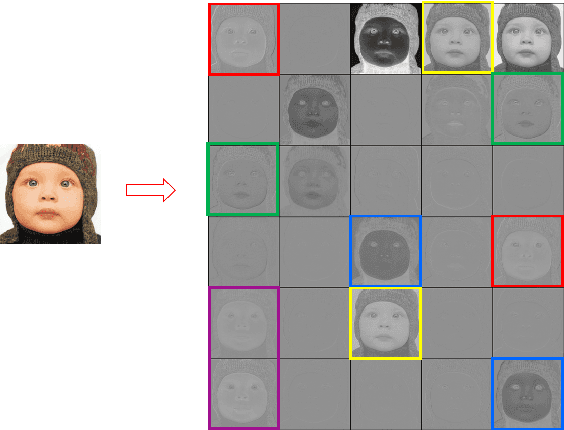
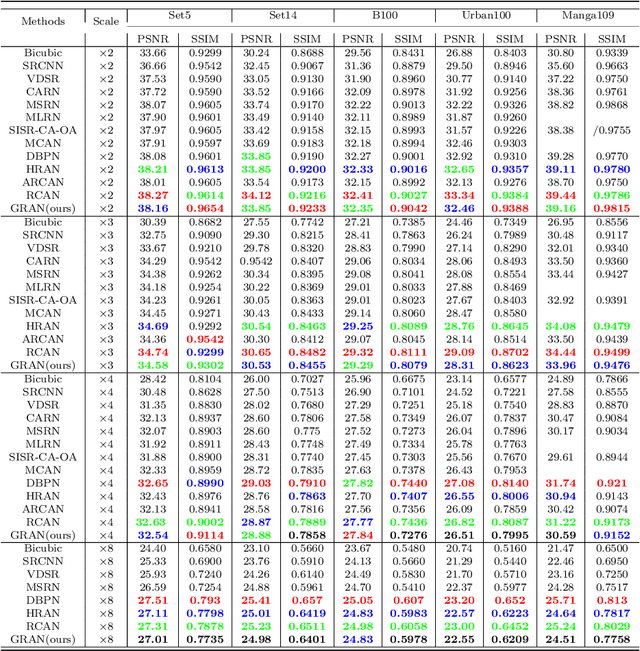

Recently, many works have designed wider and deeper networks to achieve higher image super-resolution performance. Despite their outstanding performance, they still suffer from high computational resources, preventing them from directly applying to embedded devices. To reduce the computation resources and maintain performance, we propose a novel Ghost Residual Attention Network (GRAN) for efficient super-resolution. This paper introduces Ghost Residual Attention Block (GRAB) groups to overcome the drawbacks of the standard convolutional operation, i.e., redundancy of the intermediate feature. GRAB consists of the Ghost Module and Channel and Spatial Attention Module (CSAM) to alleviate the generation of redundant features. Specifically, Ghost Module can reveal information underlying intrinsic features by employing linear operations to replace the standard convolutions. Reducing redundant features by the Ghost Module, our model decreases memory and computing resource requirements in the network. The CSAM pays more comprehensive attention to where and what the feature extraction is, which is critical to recovering the image details. Experiments conducted on the benchmark datasets demonstrate the superior performance of our method in both qualitative and quantitative. Compared to the baseline models, we achieve higher performance with lower computational resources, whose parameters and FLOPs have decreased by more than ten times.
Vertical Federated Knowledge Transfer via Representation Distillation for Healthcare Collaboration Networks
Feb 11, 2023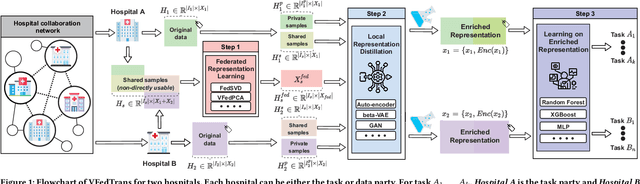
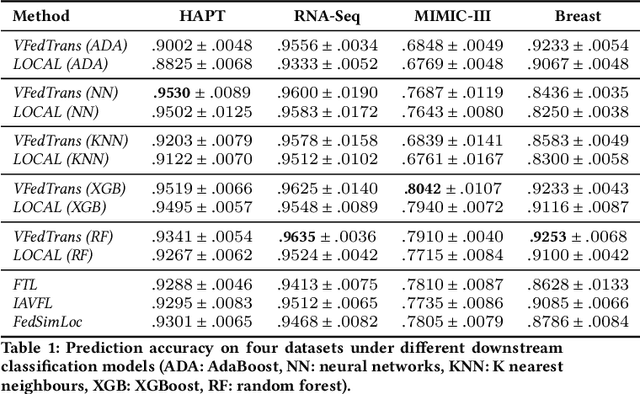
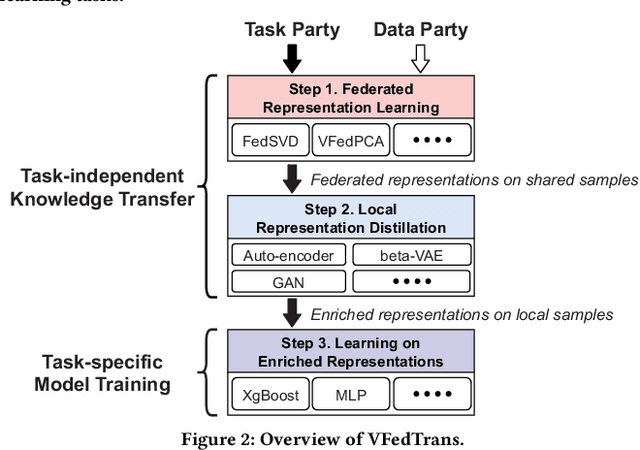
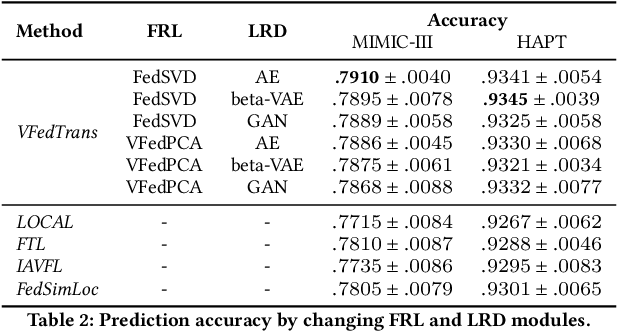
Collaboration between healthcare institutions can significantly lessen the imbalance in medical resources across various geographic areas. However, directly sharing diagnostic information between institutions is typically not permitted due to the protection of patients' highly sensitive privacy. As a novel privacy-preserving machine learning paradigm, federated learning (FL) makes it possible to maximize the data utility among multiple medical institutions. These feature-enrichment FL techniques are referred to as vertical FL (VFL). Traditional VFL can only benefit multi-parties' shared samples, which strongly restricts its application scope. In order to improve the information-sharing capability and innovation of various healthcare-related institutions, and then to establish a next-generation open medical collaboration network, we propose a unified framework for vertical federated knowledge transfer mechanism (VFedTrans) based on a novel cross-hospital representation distillation component. Specifically, our framework includes three steps. First, shared samples' federated representations are extracted by collaboratively modeling multi-parties' joint features with current efficient vertical federated representation learning methods. Second, for each hospital, we learn a local-representation-distilled module, which can transfer the knowledge from shared samples' federated representations to enrich local samples' representations. Finally, each hospital can leverage local samples' representations enriched by the distillation module to boost arbitrary downstream machine learning tasks. The experiments on real-life medical datasets verify the knowledge transfer effectiveness of our framework.
A Brief Report on LawGPT 1.0: A Virtual Legal Assistant Based on GPT-3
Feb 14, 2023LawGPT 1.0 is a virtual legal assistant built on the state-of-the-art language model GPT-3, fine-tuned for the legal domain. The system is designed to provide legal assistance to users in a conversational manner, helping them with tasks such as answering legal questions, generating legal documents, and providing legal advice. In this paper, we provide a brief overview of LawGPT 1.0, its architecture, and its performance on a set of legal benchmark tasks. Please note that the detailed information about the model is protected by a non-disclosure agreement (NDA) and cannot be disclosed in this report.
Investigating Conversational Search Behavior For Domain Exploration
Jan 10, 2023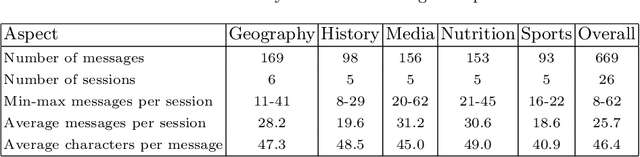
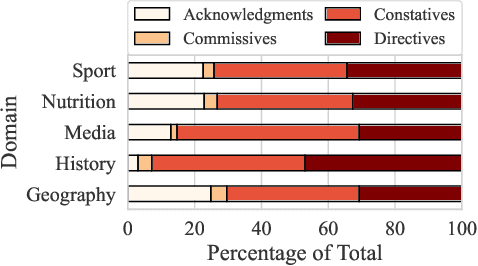
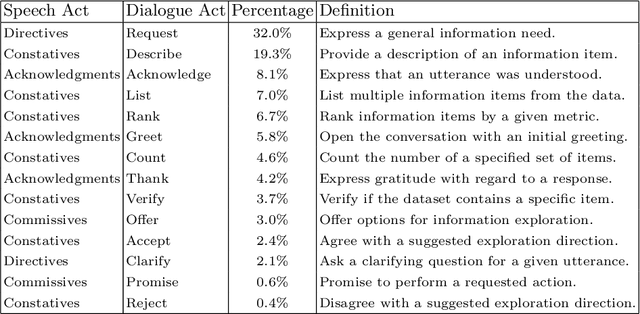
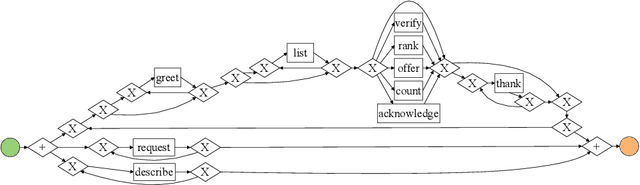
Conversational search has evolved as a new information retrieval paradigm, marking a shift from traditional search systems towards interactive dialogues with intelligent search agents. This change especially affects exploratory information-seeking contexts, where conversational search systems can guide the discovery of unfamiliar domains. In these scenarios, users find it often difficult to express their information goals due to insufficient background knowledge. Conversational interfaces can provide assistance by eliciting information needs and narrowing down the search space. However, due to the complexity of information-seeking behavior, the design of conversational interfaces for retrieving information remains a great challenge. Although prior work has employed user studies to empirically ground the system design, most existing studies are limited to well-defined search tasks or known domains, thus being less exploratory in nature. Therefore, we conducted a laboratory study to investigate open-ended search behavior for navigation through unknown information landscapes. The study comprised of 26 participants who were restricted in their search to a text chat interface. Based on the collected dialogue transcripts, we applied statistical analyses and process mining techniques to uncover general information-seeking patterns across five different domains. We not only identify core dialogue acts and their interrelations that enable users to discover domain knowledge, but also derive design suggestions for conversational search systems.
SINC: Service Information Augmented Open-Domain Conversation
Jun 28, 2022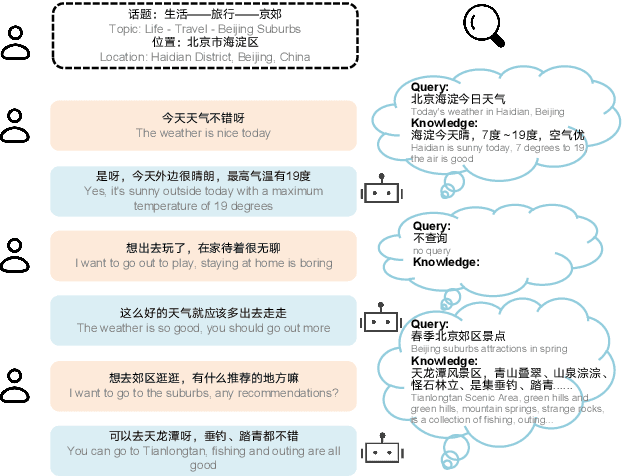
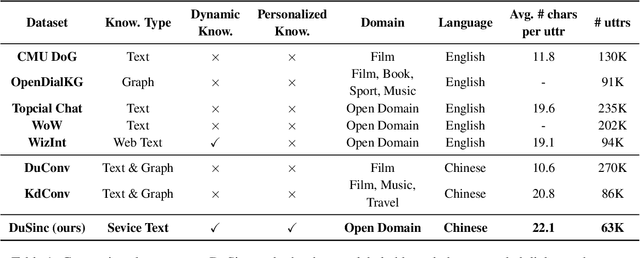
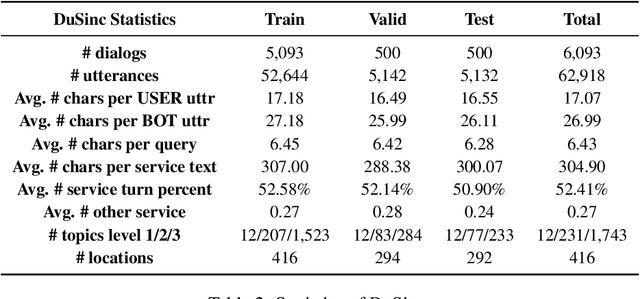
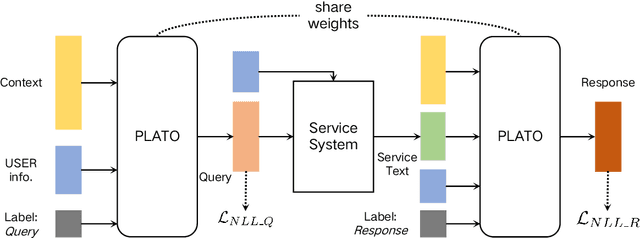
Generative open-domain dialogue systems can benefit from external knowledge, but the lack of external knowledge resources and the difficulty in finding relevant knowledge limit the development of this technology. To this end, we propose a knowledge-driven dialogue task using dynamic service information. Specifically, we use a large number of service APIs that can provide high coverage and spatiotemporal sensitivity as external knowledge sources. The dialogue system generates queries to request external services along with user information, get the relevant knowledge, and generate responses based on this knowledge. To implement this method, we collect and release the first open domain Chinese service knowledge dialogue dataset DuSinc. At the same time, we construct a baseline model PLATO-SINC, which realizes the automatic utilization of service information for dialogue. Both automatic evaluation and human evaluation show that our proposed new method can significantly improve the effect of open-domain conversation, and the session-level overall score in human evaluation is improved by 59.29% compared with the dialogue pre-training model PLATO-2. The dataset and benchmark model will be open sourced.
From Audio to Symbolic Encoding
Feb 26, 2023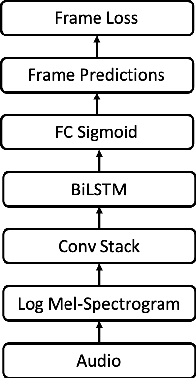
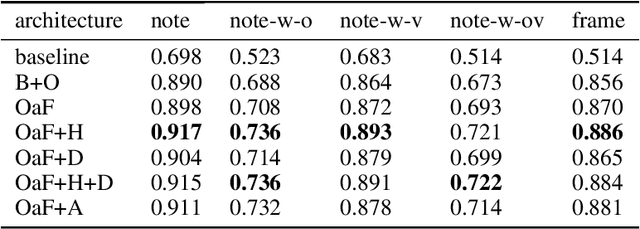
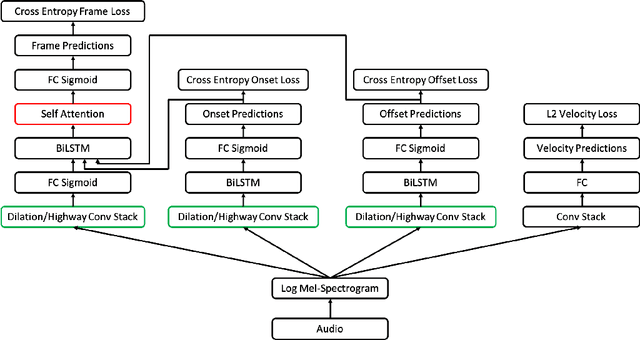
Automatic music transcription (AMT) aims to convert raw audio to symbolic music representation. As a fundamental problem of music information retrieval (MIR), AMT is considered a difficult task even for trained human experts due to overlap of multiple harmonics in the acoustic signal. On the other hand, speech recognition, as one of the most popular tasks in natural language processing, aims to translate human spoken language to texts. Based on the similar nature of AMT and speech recognition (as they both deal with tasks of translating audio signal to symbolic encoding), this paper investigated whether a generic neural network architecture could possibly work on both tasks. In this paper, we introduced our new neural network architecture built on top of the current state-of-the-art Onsets and Frames, and compared the performances of its multiple variations on AMT task. We also tested our architecture with the task of speech recognition. For AMT, our models were able to produce better results compared to the model trained using the state-of-art architecture; however, although similar architecture was able to be trained on the speech recognition task, it did not generate very ideal result compared to other task-specific models.
PaRK-Detect: Towards Efficient Multi-Task Satellite Imagery Road Extraction via Patch-Wise Keypoints Detection
Feb 26, 2023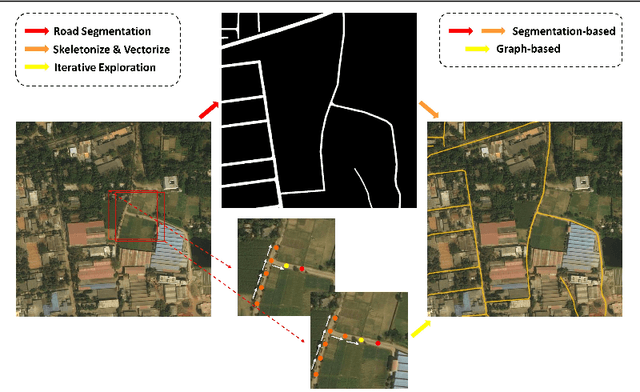
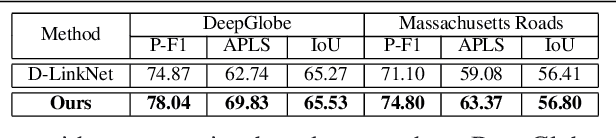
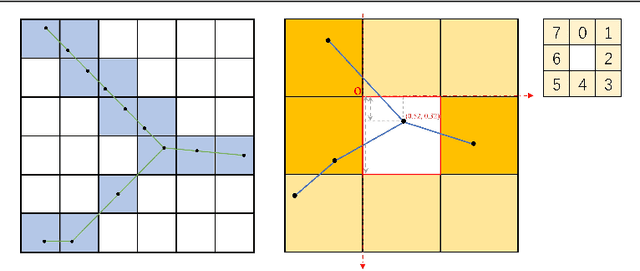
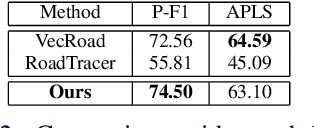
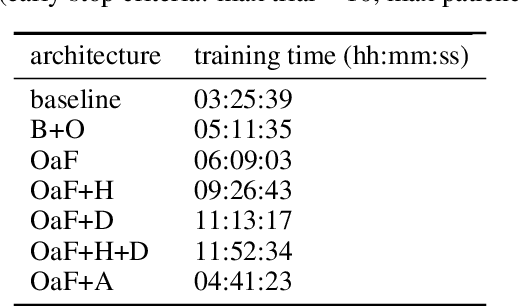
Automatically extracting roads from satellite imagery is a fundamental yet challenging computer vision task in the field of remote sensing. Pixel-wise semantic segmentation-based approaches and graph-based approaches are two prevailing schemes. However, prior works show the imperfections that semantic segmentation-based approaches yield road graphs with low connectivity, while graph-based methods with iterative exploring paradigms and smaller receptive fields focus more on local information and are also time-consuming. In this paper, we propose a new scheme for multi-task satellite imagery road extraction, Patch-wise Road Keypoints Detection (PaRK-Detect). Building on top of D-LinkNet architecture and adopting the structure of keypoint detection, our framework predicts the position of patch-wise road keypoints and the adjacent relationships between them to construct road graphs in a single pass. Meanwhile, the multi-task framework also performs pixel-wise semantic segmentation and generates road segmentation masks. We evaluate our approach against the existing state-of-the-art methods on DeepGlobe, Massachusetts Roads, and RoadTracer datasets and achieve competitive or better results. We also demonstrate a considerable outperformance in terms of inference speed.
* Accepted at BMVC 2022 (Oral). 13 pages, 5 figures. https://bmvc2022.mpi-inf.mpg.de/381/
TopoBERT: Plug and Play Toponym Recognition Module Harnessing Fine-tuned BERT
Jan 31, 2023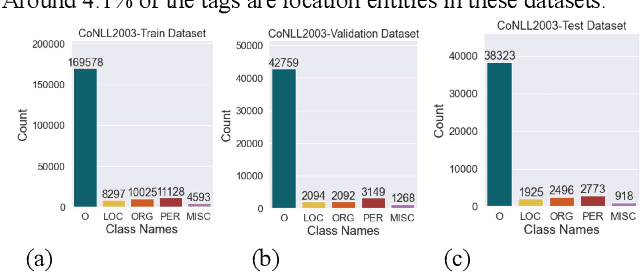
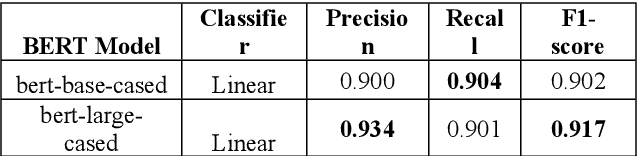
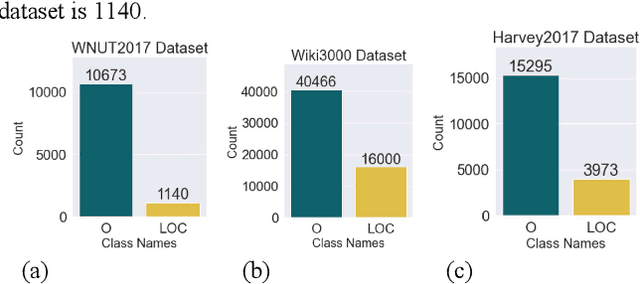
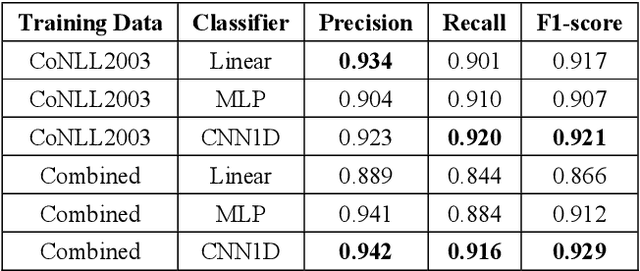
Extracting precise geographical information from textual contents is crucial in a plethora of applications. For example, during hazardous events, a robust and unbiased toponym extraction framework can provide an avenue to tie the location concerned to the topic discussed by news media posts and pinpoint humanitarian help requests or damage reports from social media. Early studies have leveraged rule-based, gazetteer-based, deep learning, and hybrid approaches to address this problem. However, the performance of existing tools is deficient in supporting operations like emergency rescue, which relies on fine-grained, accurate geographic information. The emerging pretrained language models can better capture the underlying characteristics of text information, including place names, offering a promising pathway to optimize toponym recognition to underpin practical applications. In this paper, TopoBERT, a toponym recognition module based on a one dimensional Convolutional Neural Network (CNN1D) and Bidirectional Encoder Representation from Transformers (BERT), is proposed and fine-tuned. Three datasets (CoNLL2003-Train, Wikipedia3000, WNUT2017) are leveraged to tune the hyperparameters, discover the best training strategy, and train the model. Another two datasets (CoNLL2003-Test and Harvey2017) are used to evaluate the performance. Three distinguished classifiers, linear, multi-layer perceptron, and CNN1D, are benchmarked to determine the optimal model architecture. TopoBERT achieves state-of-the-art performance (f1-score=0.865) compared to the other five baseline models and can be applied to diverse toponym recognition tasks without additional training.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023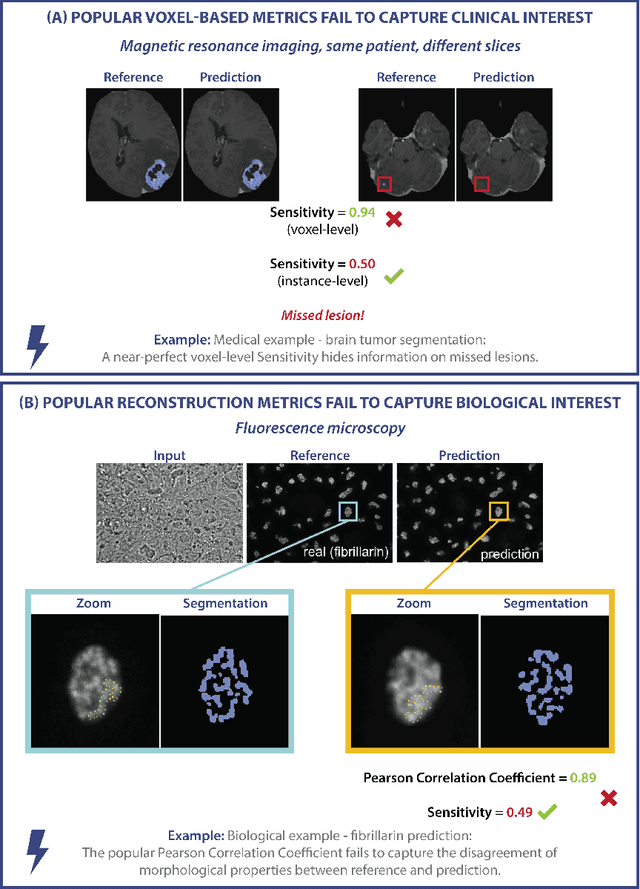
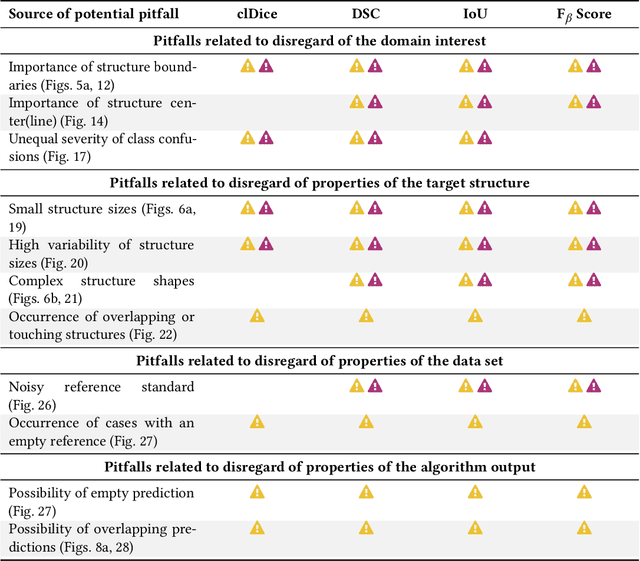

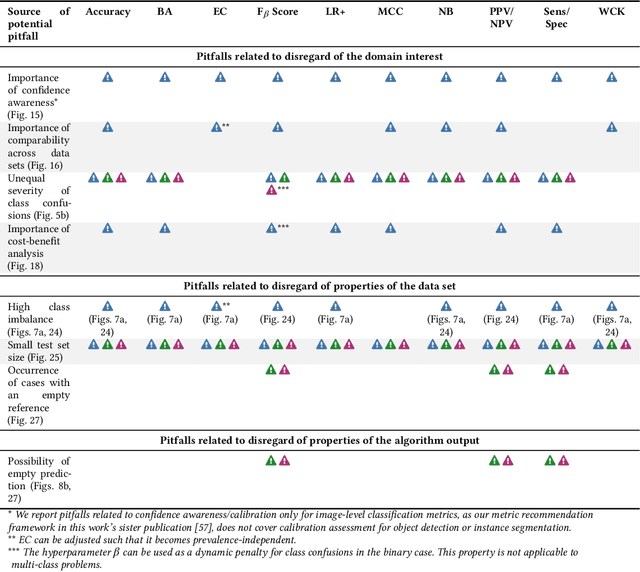
Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.