 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 15, 2023

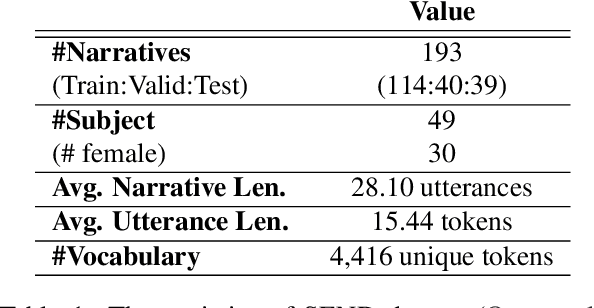

Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
Enhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation
Feb 09, 2023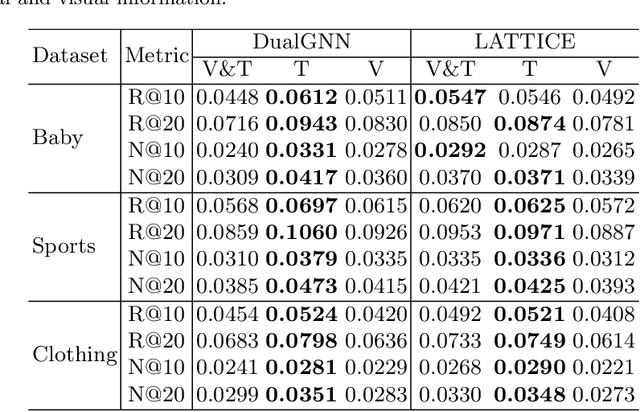
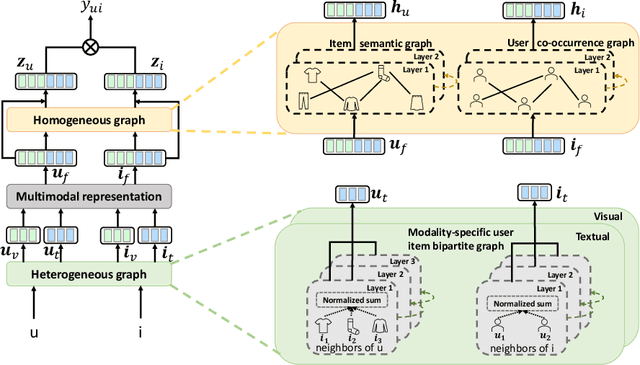
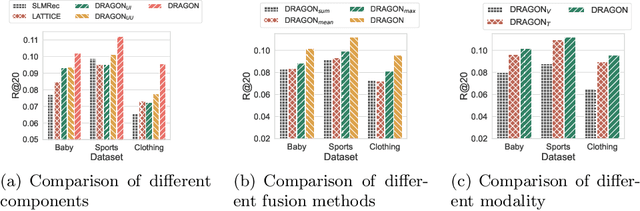
User interaction data in recommender systems is a form of dyadic relation that reflects the preferences of users with items. Learning the representations of these two discrete sets of objects, users and items, is critical for recommendation. Recent multimodal recommendation models leveraging multimodal features (e.g., images and text descriptions) have been demonstrated to be effective in improving recommendation accuracy. However, state-of-the-art models enhance the dyadic relations between users and items by considering either user-user or item-item relations, leaving the high-order relations of the other side (i.e., users or items) unexplored. Furthermore, we experimentally reveal that the current multimodality fusion methods in the state-of-the-art models may degrade their recommendation performance. That is, without tainting the model architectures, these models can achieve even better recommendation accuracy with uni-modal information. On top of the finding, we propose a model that enhances the dyadic relations by learning Dual RepresentAtions of both users and items via constructing homogeneous Graphs for multimOdal recommeNdation. We name our model as DRAGON. Specifically, DRAGON constructs the user-user graph based on the commonly interacted items and the item-item graph from item multimodal features. It then utilizes graph learning on both the user-item heterogeneous graph and the homogeneous graphs (user-user and item-item) to obtain the dual representations of users and items. To capture information from each modality, DRAGON employs a simple yet effective fusion method, attentive concatenation, to derive the representations of users and items. Extensive experiments on three public datasets and seven baselines show that DRAGON can outperform the strongest baseline by 22.03% on average. Various ablation studies are conducted on DRAGON to validate its effectiveness.
TransNet: Transferable Neural Networks for Partial Differential Equations
Jan 27, 2023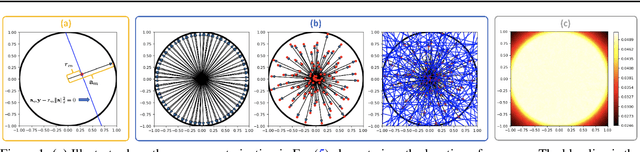

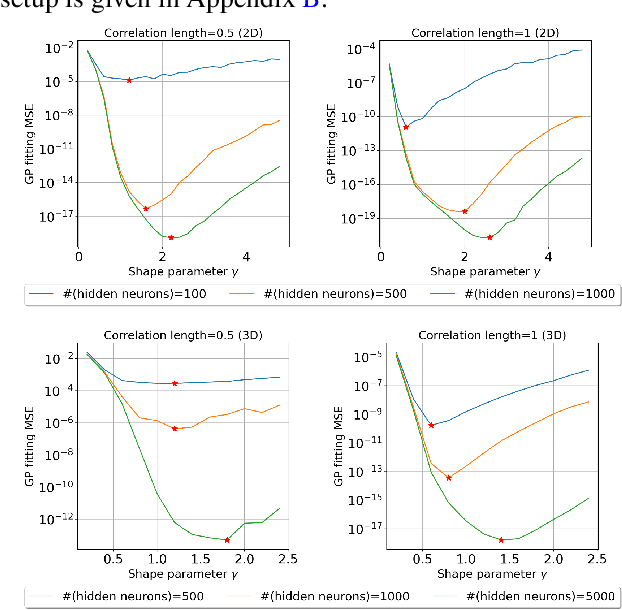
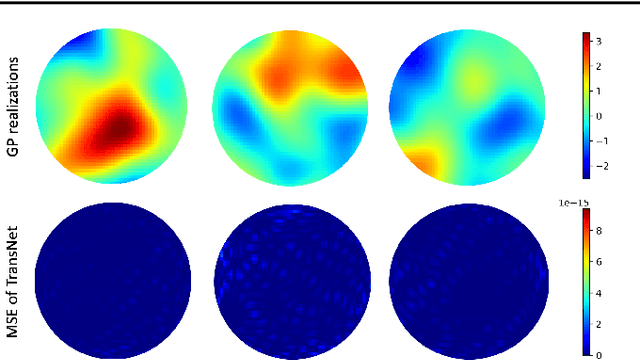
Transfer learning for partial differential equations (PDEs) is to develop a pre-trained neural network that can be used to solve a wide class of PDEs. Existing transfer learning approaches require much information of the target PDEs such as its formulation and/or data of its solution for pre-training. In this work, we propose to construct transferable neural feature spaces from purely function approximation perspectives without using PDE information. The construction of the feature space involves re-parameterization of the hidden neurons and uses auxiliary functions to tune the resulting feature space. Theoretical analysis shows the high quality of the produced feature space, i.e., uniformly distributed neurons. Extensive numerical experiments verify the outstanding performance of our method, including significantly improved transferability, e.g., using the same feature space for various PDEs with different domains and boundary conditions, and the superior accuracy, e.g., several orders of magnitude smaller mean squared error than the state of the art methods.
Event Causality Extraction with Event Argument Correlations
Jan 27, 2023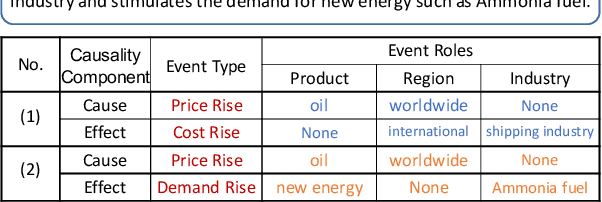
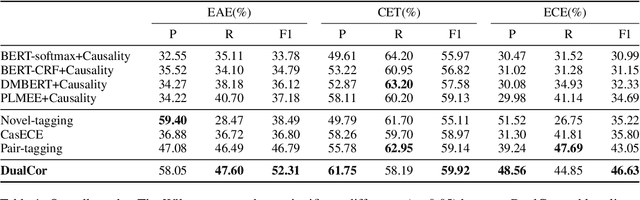
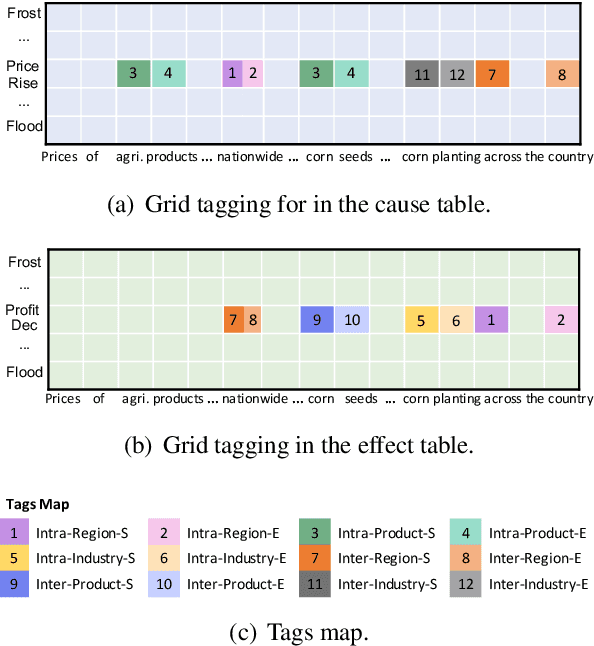
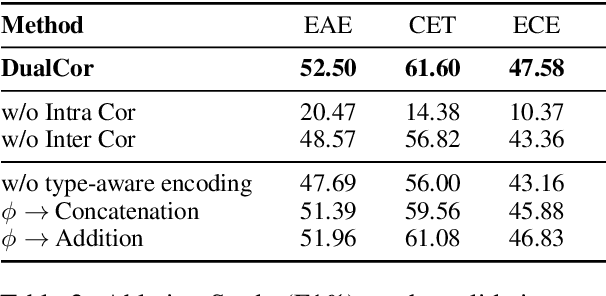
Event Causality Identification (ECI), which aims to detect whether a causality relation exists between two given textual events, is an important task for event causality understanding. However, the ECI task ignores crucial event structure and cause-effect causality component information, making it struggle for downstream applications. In this paper, we explore a novel task, namely Event Causality Extraction (ECE), aiming to extract the cause-effect event causality pairs with their structured event information from plain texts. The ECE task is more challenging since each event can contain multiple event arguments, posing fine-grained correlations between events to decide the causeeffect event pair. Hence, we propose a method with a dual grid tagging scheme to capture the intra- and inter-event argument correlations for ECE. Further, we devise a event type-enhanced model architecture to realize the dual grid tagging scheme. Experiments demonstrate the effectiveness of our method, and extensive analyses point out several future directions for ECE.
Towards More Realistic Generation of Information-Seeking Conversations
May 25, 2022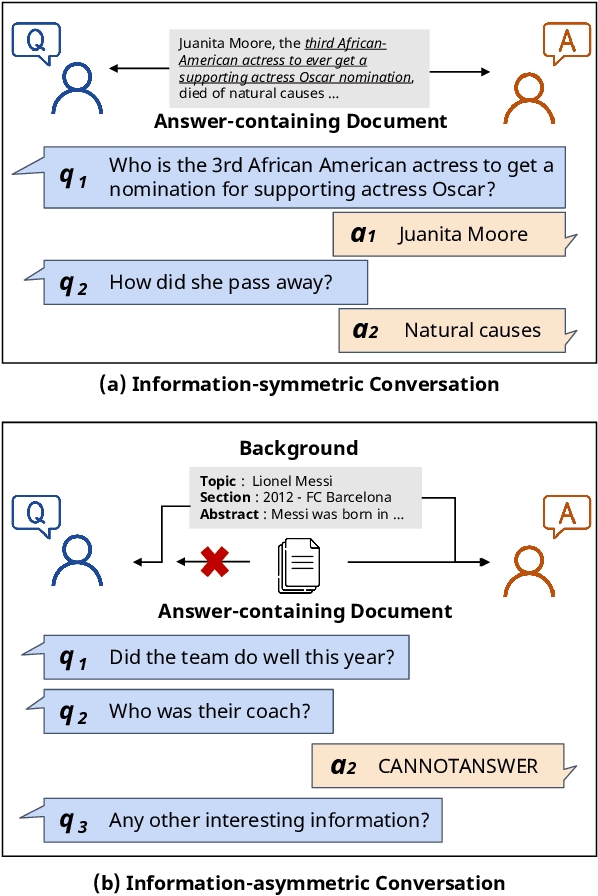
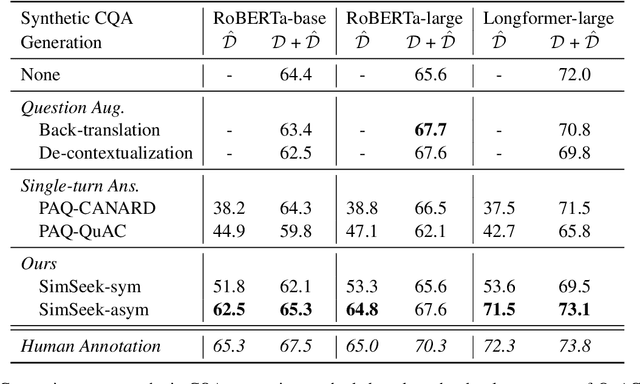

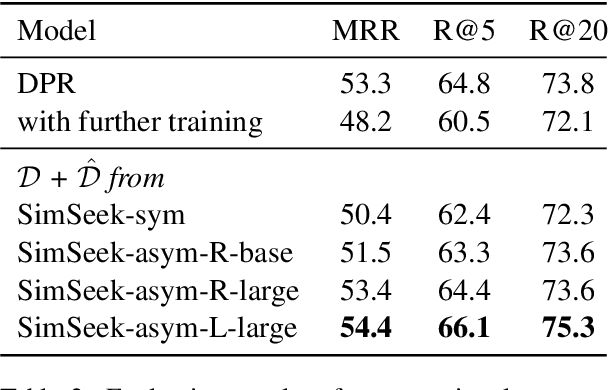
In this paper, we introduce a novel framework SimSeek (simulating information-seeking conversation from unlabeled documents) and compare two variants of it to provide a deeper perspective into the information-seeking behavior. We first introduce a strong simulator for information-symmetric conversation, SimSeek-sym, where questioner and answerer share all knowledge when conversing with one another. Although it simulates reasonable conversations, we take a further step toward more realistic information-seeking conversation. Hence, we propose SimSeek-asym that assumes information asymmetry between two agents, which encourages the questioner to seek new information from an inaccessible document. In our experiments, we demonstrate that SimSeek-asym successfully generates information-seeking conversations for two downstream tasks, CQA and conversational search. In particular, SimSeek-asym improves baseline models by 1.1-1.9 F1 score in QuAC, and by 1.1 of MRR in OR-QuAC. Moreover, we thoroughly analyze our synthetic datasets to identify crucial factors for realistic information-seeking conversation.
DNG: Taxonomy Expansion by Exploring the Intrinsic Directed Structure on Non-Gaussian Space
Feb 22, 2023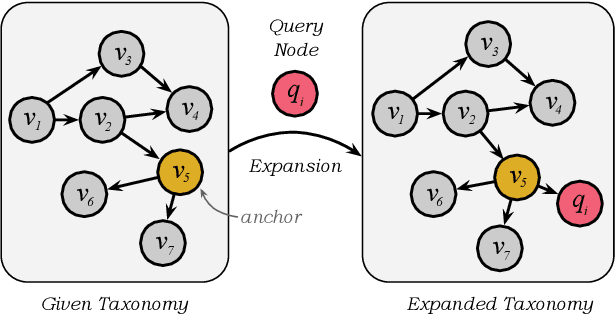

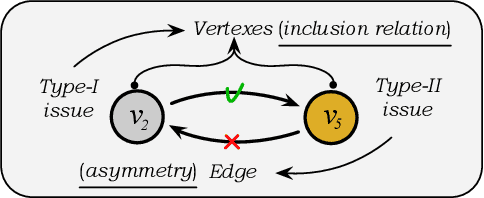

Taxonomy expansion is the process of incorporating a large number of additional nodes (i.e., "queries") into an existing taxonomy (i.e., "seed"), with the most important step being the selection of appropriate positions for each query. Enormous efforts have been made by exploring the seed's structure. However, existing approaches are deficient in their mining of structural information in two ways: poor modeling of the hierarchical semantics and failure to capture directionality of is-a relation. This paper seeks to address these issues by explicitly denoting each node as the combination of inherited feature (i.e., structural part) and incremental feature (i.e., supplementary part). Specifically, the inherited feature originates from "parent" nodes and is weighted by an inheritance factor. With this node representation, the hierarchy of semantics in taxonomies (i.e., the inheritance and accumulation of features from "parent" to "child") could be embodied. Additionally, based on this representation, the directionality of is-a relation could be easily translated into the irreversible inheritance of features. Inspired by the Darmois-Skitovich Theorem, we implement this irreversibility by a non-Gaussian constraint on the supplementary feature. A log-likelihood learning objective is further utilized to optimize the proposed model (dubbed DNG), whereby the required non-Gaussianity is also theoretically ensured. Extensive experimental results on two real-world datasets verify the superiority of DNG relative to several strong baselines.
Using the profile of publishers to predict barriers across news articles
Jan 13, 2023


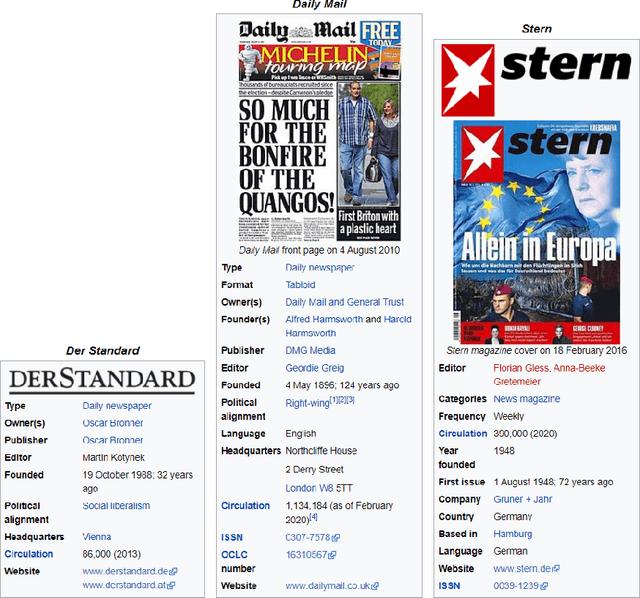
Detection of news propagation barriers, being economical, cultural, political, time zonal, or geographical, is still an open research issue. We present an approach to barrier detection in news spreading by utilizing Wikipedia-concepts and metadata associated with each barrier. Solving this problem can not only convey the information about the coverage of an event but it can also show whether an event has been able to cross a specific barrier or not. Experimental results on IPoNews dataset (dataset for information spreading over the news) reveals that simple classification models are able to detect barriers with high accuracy. We believe that our approach can serve to provide useful insights which pave the way for the future development of a system for predicting information spreading barriers over the news.
An Application of Stereo Thermal Vision for Preliminary Inspection of Electrical Power Lines by MAVs
Feb 09, 2023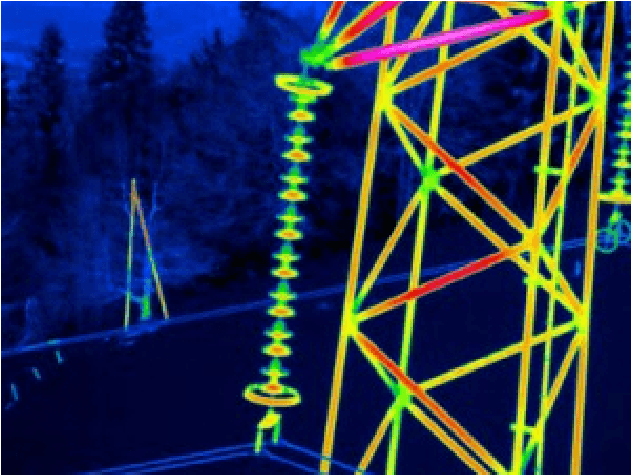

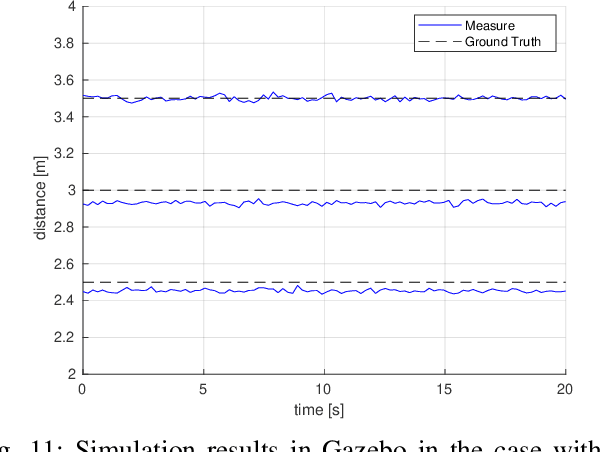
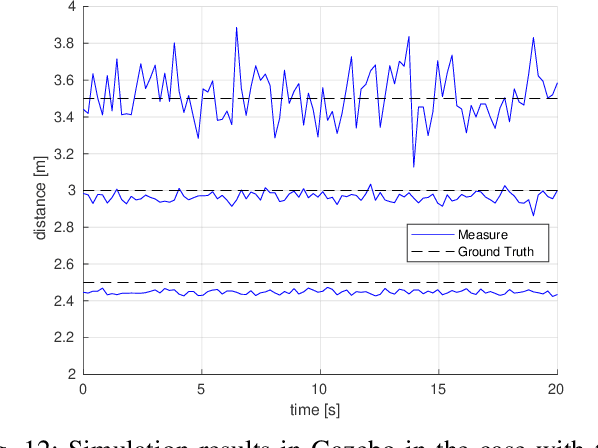
An application of stereo thermal vision to perform preliminary inspection operations of electrical power lines by a particular class of small Unmanned Aerial Vehicles (UAVs), aka Micro Unmanned Aerial Vehicles (MAVs), is presented in this paper. The proposed hardware and software setup allows the detection of overheated power equipment, one of the major causes of power outages. The stereo vision complements the GPS information by finely detecting the potential source of damage while also providing a measure of the harm extension. The reduced sizes and the light weight of the vehicle enable to survey areas otherwise difficult to access with standard UAVs. Gazebo simulations and real flight experiments demonstrate the feasibility and effectiveness of the proposed setup.
* 8 pages, 15 figures, conference
A Composite T60 Regression and Classification Approach for Speech Dereverberation
Feb 09, 2023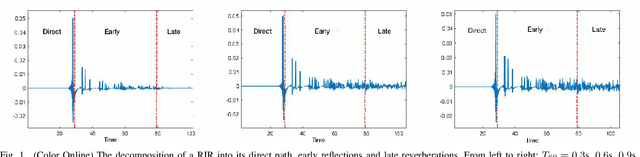
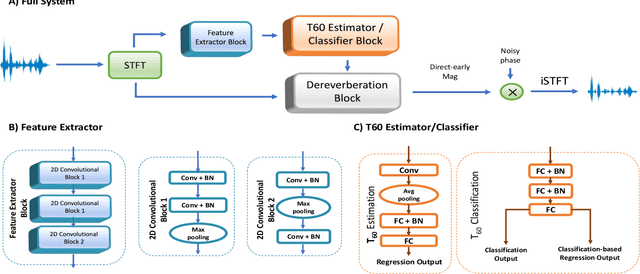
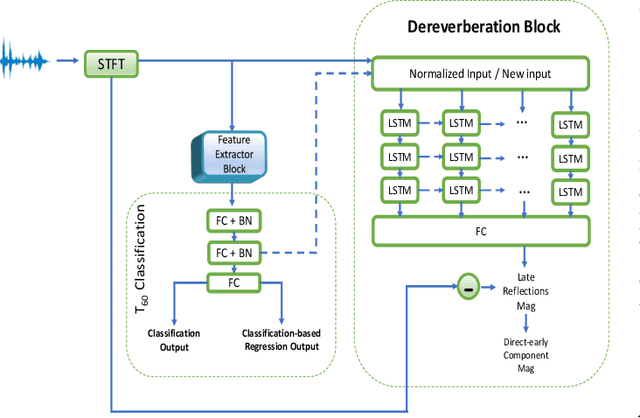
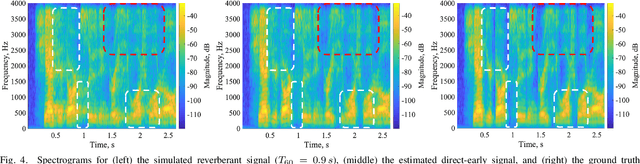
Dereverberation is often performed directly on the reverberant audio signal, without knowledge of the acoustic environment. Reverberation time, T60, however, is an essential acoustic factor that reflects how reverberation may impact a signal. In this work, we propose to perform dereverberation while leveraging key acoustic information from the environment. More specifically, we develop a joint learning approach that uses a composite T60 module and a separate dereverberation module to simultaneously perform reverberation time estimation and dereverberation. The reverberation time module provides key features to the dereverberation module during fine tuning. We evaluate our approach in simulated and real environments, and compare against several approaches. The results show that this composite framework improves performance in environments.
Variational Latent Branching Model for Off-Policy Evaluation
Feb 03, 2023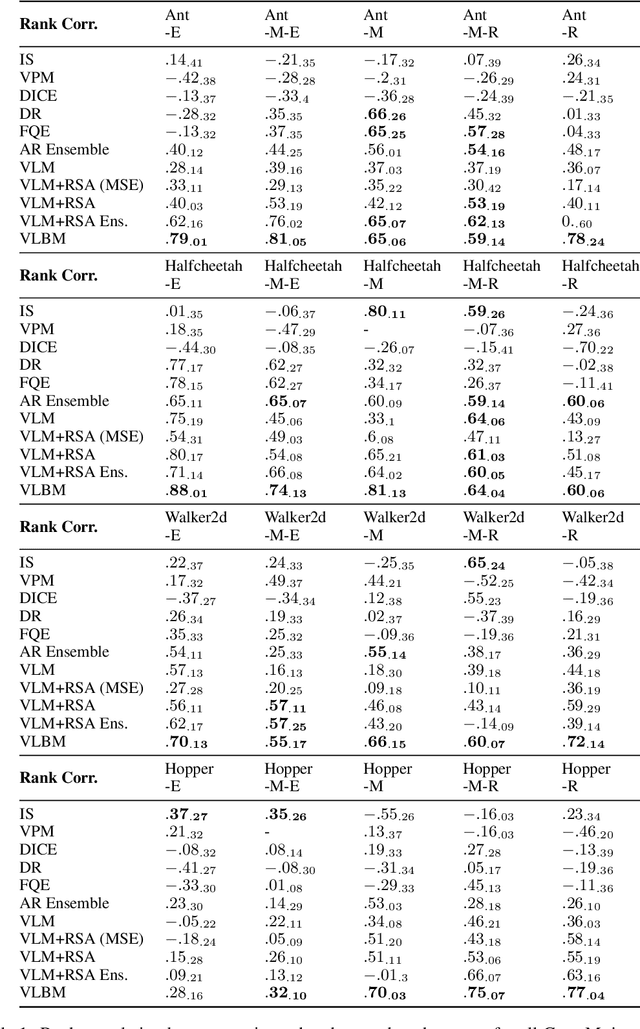
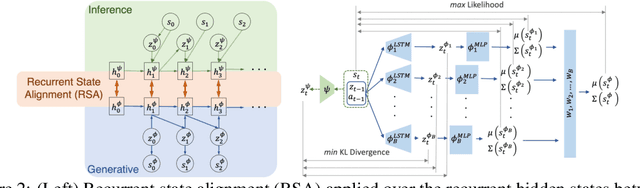
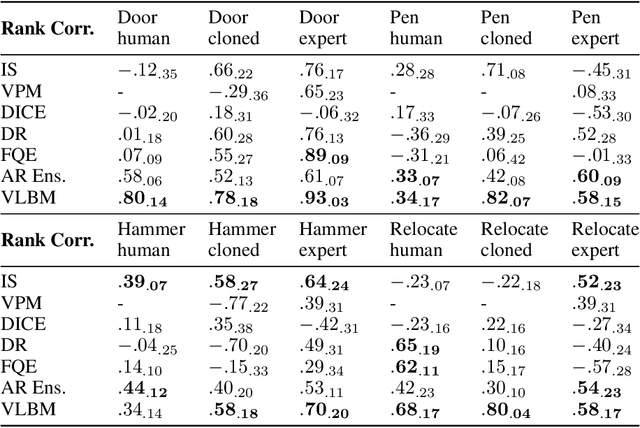
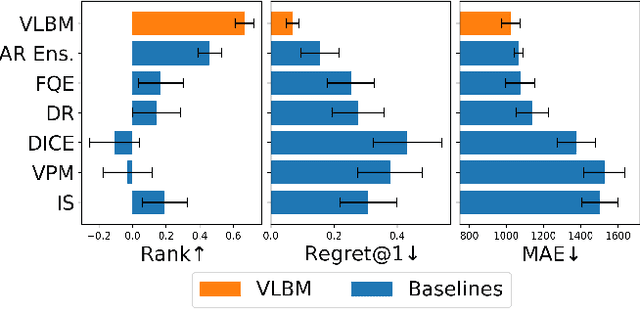
Model-based methods have recently shown great potential for off-policy evaluation (OPE); offline trajectories induced by behavioral policies are fitted to transitions of Markov decision processes (MDPs), which are used to rollout simulated trajectories and estimate the performance of policies. Model-based OPE methods face two key challenges. First, as offline trajectories are usually fixed, they tend to cover limited state and action space. Second, the performance of model-based methods can be sensitive to the initialization of their parameters. In this work, we propose the variational latent branching model (VLBM) to learn the transition function of MDPs by formulating the environmental dynamics as a compact latent space, from which the next states and rewards are then sampled. Specifically, VLBM leverages and extends the variational inference framework with the recurrent state alignment (RSA), which is designed to capture as much information underlying the limited training data, by smoothing out the information flow between the variational (encoding) and generative (decoding) part of VLBM. Moreover, we also introduce the branching architecture to improve the model's robustness against randomly initialized model weights. The effectiveness of the VLBM is evaluated on the deep OPE (DOPE) benchmark, from which the training trajectories are designed to result in varied coverage of the state-action space. We show that the VLBM outperforms existing state-of-the-art OPE methods in general.