 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Feature Extraction from Salient Regions by Feature Map Transformation
Jan 25, 2023
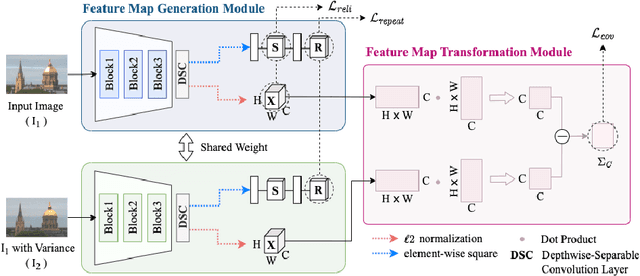
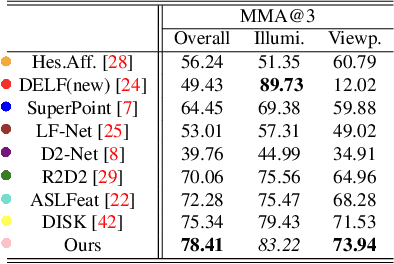

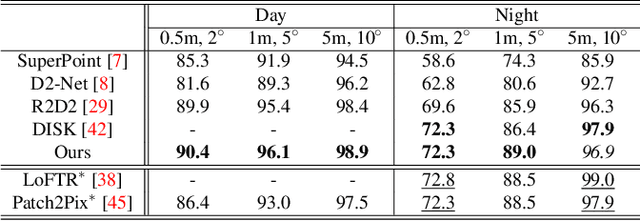
Local feature matching is essential for many applications, such as localization and 3D reconstruction. However, it is challenging to match feature points accurately in various camera viewpoints and illumination conditions. In this paper, we propose a framework that robustly extracts and describes salient local features regardless of changing light and viewpoints. The framework suppresses illumination variations and encourages structural information to ignore the noise from light and to focus on edges. We classify the elements in the feature covariance matrix, an implicit feature map information, into two components. Our model extracts feature points from salient regions leading to reduced incorrect matches. In our experiments, the proposed method achieved higher accuracy than the state-of-the-art methods in the public dataset, such as HPatches, Aachen Day-Night, and ETH, which especially show highly variant viewpoints and illumination.
Do Neural Networks Generalize from Self-Averaging Sub-classifiers in the Same Way As Adaptive Boosting?
Feb 14, 2023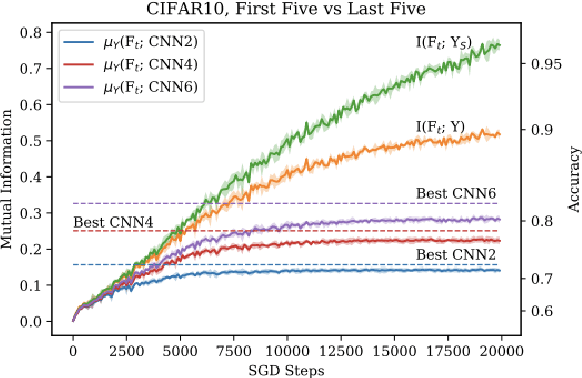
In recent years, neural networks (NNs) have made giant leaps in a wide variety of domains. NNs are often referred to as black box algorithms due to how little we can explain their empirical success. Our foundational research seeks to explain why neural networks generalize. A recent advancement derived a mutual information measure for explaining the performance of deep NNs through a sequence of increasingly complex functions. We show deep NNs learn a series of boosted classifiers whose generalization is popularly attributed to self-averaging over an increasing number of interpolating sub-classifiers. To our knowledge, we are the first authors to establish the connection between generalization in boosted classifiers and generalization in deep NNs. Our experimental evidence and theoretical analysis suggest NNs trained with dropout exhibit similar self-averaging behavior over interpolating sub-classifiers as cited in popular explanations for the post-interpolation generalization phenomenon in boosting.
Like a Good Nearest Neighbor: Practical Content Moderation with Sentence Transformers
Feb 17, 2023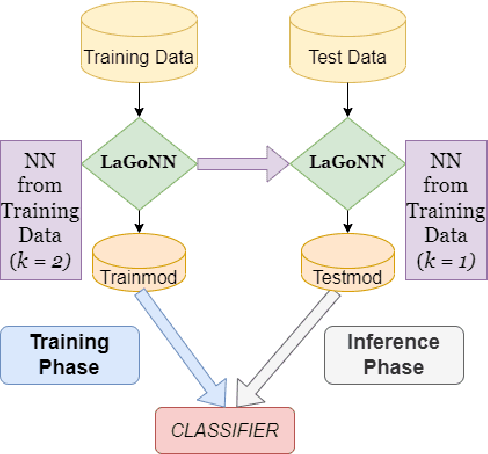
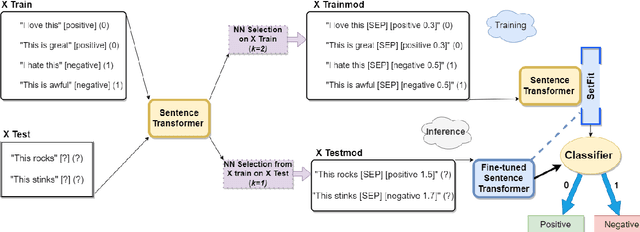
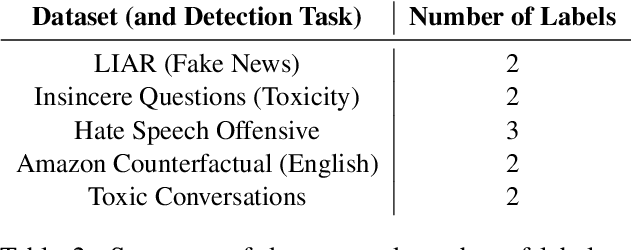
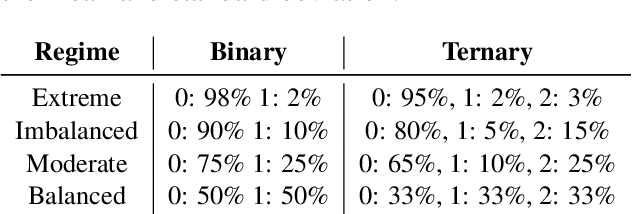
Modern text classification systems have impressive capabilities but are infeasible to deploy and use reliably due to their dependence on prompting and billion-parameter language models. SetFit (Tunstall et al., 2022) is a recent, practical approach that fine-tunes a Sentence Transformer under a contrastive learning paradigm and achieves similar results to more unwieldy systems. Text classification is important for addressing the problem of domain drift in detecting harmful content, which plagues all social media platforms. Here, we propose Like a Good Nearest Neighbor (LaGoNN), an inexpensive modification to SetFit that requires no additional parameters or hyperparameters but modifies input with information about its nearest neighbor, for example, the label and text, in the training data, making novel data appear similar to an instance on which the model was optimized. LaGoNN is effective at the task of detecting harmful content and generally improves performance compared to SetFit. To demonstrate the value of our system, we conduct a thorough study of text classification systems in the context of content moderation under four label distributions.
DREEAM: Guiding Attention with Evidence for Improving Document-Level Relation Extraction
Feb 17, 2023

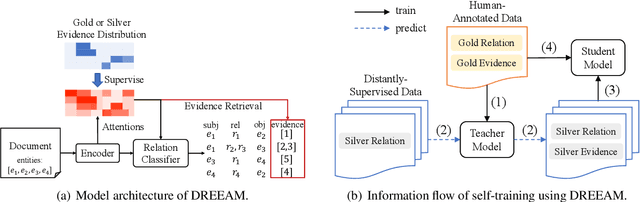
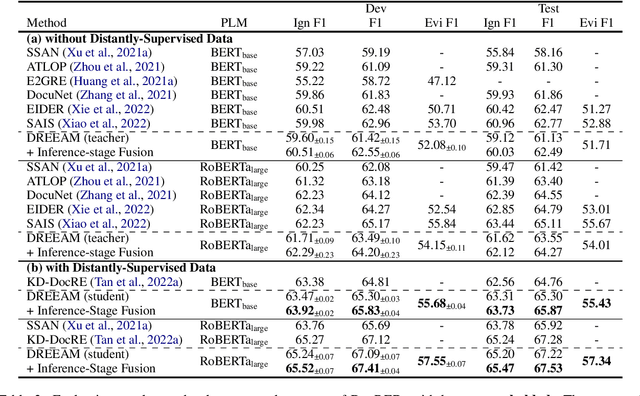
Document-level relation extraction (DocRE) is the task of identifying all relations between each entity pair in a document. Evidence, defined as sentences containing clues for the relationship between an entity pair, has been shown to help DocRE systems focus on relevant texts, thus improving relation extraction. However, evidence retrieval (ER) in DocRE faces two major issues: high memory consumption and limited availability of annotations. This work aims at addressing these issues to improve the usage of ER in DocRE. First, we propose DREEAM, a memory-efficient approach that adopts evidence information as the supervisory signal, thereby guiding the attention modules of the DocRE system to assign high weights to evidence. Second, we propose a self-training strategy for DREEAM to learn ER from automatically-generated evidence on massive data without evidence annotations. Experimental results reveal that our approach exhibits state-of-the-art performance on the DocRED benchmark for both DocRE and ER. To the best of our knowledge, DREEAM is the first approach to employ ER self-training.
Unique Identification of 50,000+ Virtual Reality Users from Head & Hand Motion Data
Feb 17, 2023
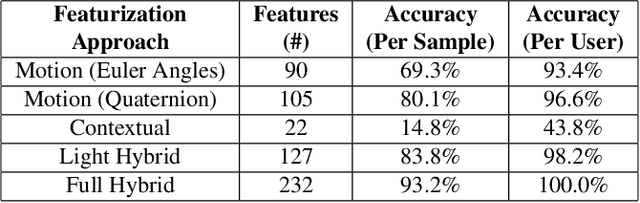
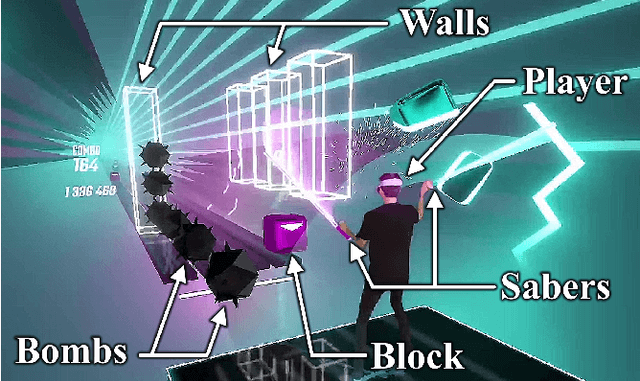
With the recent explosive growth of interest and investment in virtual reality (VR) and the so-called "metaverse," public attention has rightly shifted toward the unique security and privacy threats that these platforms may pose. While it has long been known that people reveal information about themselves via their motion, the extent to which this makes an individual globally identifiable within virtual reality has not yet been widely understood. In this study, we show that a large number of real VR users (N=55,541) can be uniquely and reliably identified across multiple sessions using just their head and hand motion relative to virtual objects. After training a classification model on 5 minutes of data per person, a user can be uniquely identified amongst the entire pool of 50,000+ with 94.33% accuracy from 100 seconds of motion, and with 73.20% accuracy from just 10 seconds of motion. This work is the first to truly demonstrate the extent to which biomechanics may serve as a unique identifier in VR, on par with widely used biometrics such as facial or fingerprint recognition.
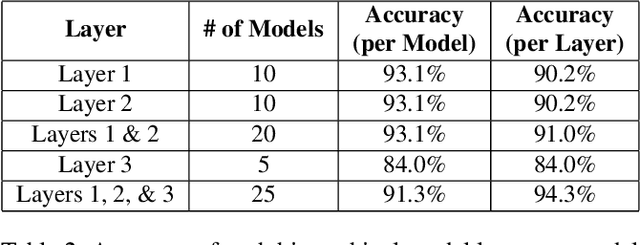
MCAE: Masked Contrastive Autoencoder for Face Anti-Spoofing
Feb 17, 2023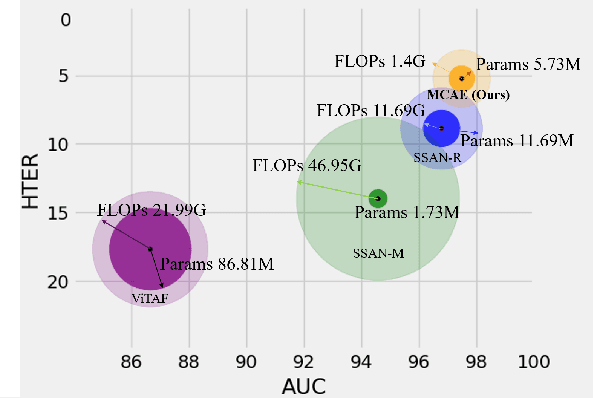
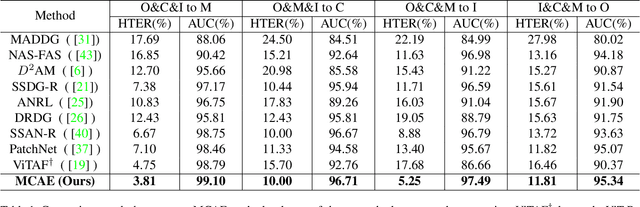
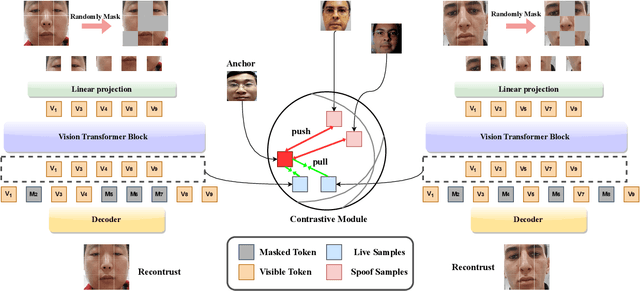
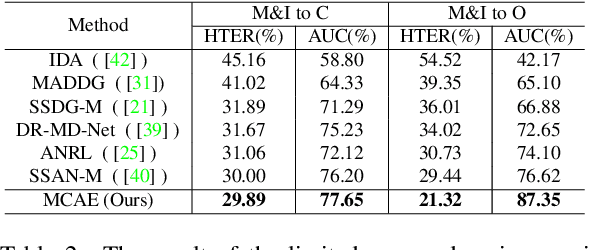
Face anti-spoofing (FAS) method performs well under the intra-domain setups. But cross-domain performance of the model is not satisfying. Domain generalization method has been used to align the feature from different domain extracted by convolutional neural network (CNN) backbone. However, the improvement is limited. Recently, the Vision Transformer (ViT) model has performed well on various visual tasks. But ViT model relies heavily on pre-training of large-scale dataset, which cannot be satisfied by existing FAS datasets. In this paper, taking the FAS task as an example, we propose Masked Contrastive Autoencoder (MCAE) method to solve this problem using only limited data. Meanwhile in order for a feature extractor to extract common features in live samples from different domains, we combine Masked Image Model (MIM) with supervised contrastive learning to train our model.Some intriguing design principles are summarized for performing MIM pre-training for downstream tasks.We also provide insightful analysis for our method from an information theory perspective. Experimental results show our approach has good performance on extensive public datasets and outperforms the state-of-the-art methods.
Long Range Object-Level Monocular Depth Estimation for UAVs
Feb 17, 2023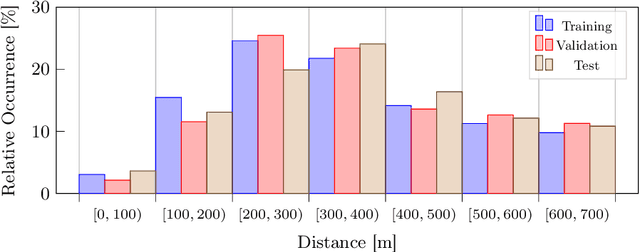
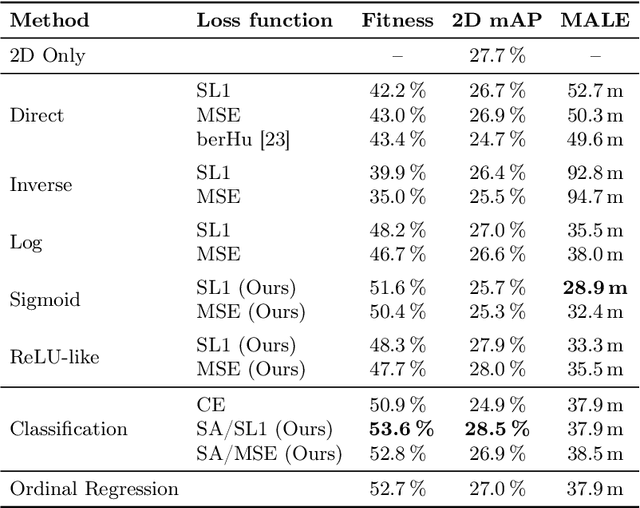
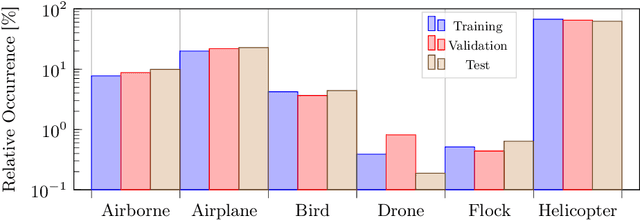
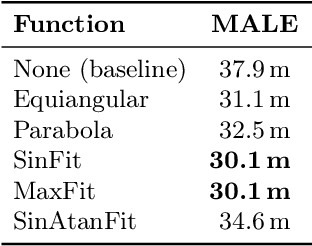
Computer vision-based object detection is a key modality for advanced Detect-And-Avoid systems that allow for autonomous flight missions of UAVs. While standard object detection frameworks do not predict the actual depth of an object, this information is crucial to avoid collisions. In this paper, we propose several novel extensions to state-of-the-art methods for monocular object detection from images at long range. Firstly, we propose Sigmoid and ReLU-like encodings when modeling depth estimation as a regression task. Secondly, we frame the depth estimation as a classification problem and introduce a Soft-Argmax function in the calculation of the training loss. The extensions are exemplarily applied to the YOLOX object detection framework. We evaluate the performance using the Amazon Airborne Object Tracking dataset. In addition, we introduce the Fitness score as a new metric that jointly assesses both object detection and depth estimation performance. Our results show that the proposed methods outperform state-of-the-art approaches w.r.t. existing, as well as the proposed metrics.
Dual Graph Multitask Framework for Imbalanced Delivery Time Estimation
Feb 17, 2023
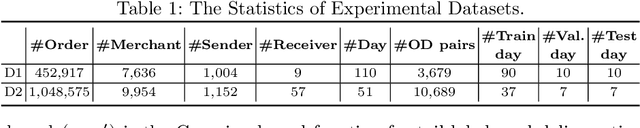
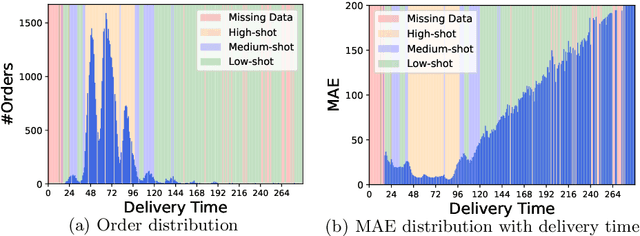
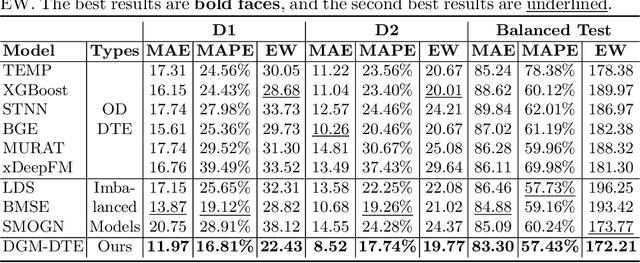
Delivery Time Estimation (DTE) is a crucial component of the e-commerce supply chain that predicts delivery time based on merchant information, sending address, receiving address, and payment time. Accurate DTE can boost platform revenue and reduce customer complaints and refunds. However, the imbalanced nature of industrial data impedes previous models from reaching satisfactory prediction performance. Although imbalanced regression methods can be applied to the DTE task, we experimentally find that they improve the prediction performance of low-shot data samples at the sacrifice of overall performance. To address the issue, we propose a novel Dual Graph Multitask framework for imbalanced Delivery Time Estimation (DGM-DTE). Our framework first classifies package delivery time as head and tail data. Then, a dual graph-based model is utilized to learn representations of the two categories of data. In particular, DGM-DTE re-weights the embedding of tail data by estimating its kernel density. We fuse two graph-based representations to capture both high- and low-shot data representations. Experiments on real-world Taobao logistics datasets demonstrate the superior performance of DGM-DTE compared to baselines.
Improving Transformer-based Networks With Locality For Automatic Speaker Verification
Feb 17, 2023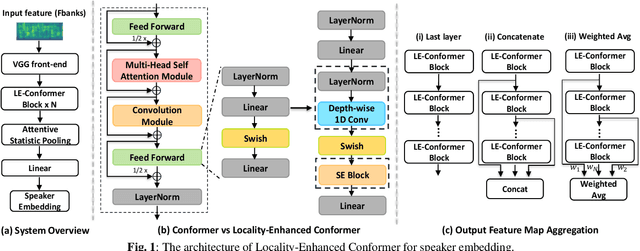
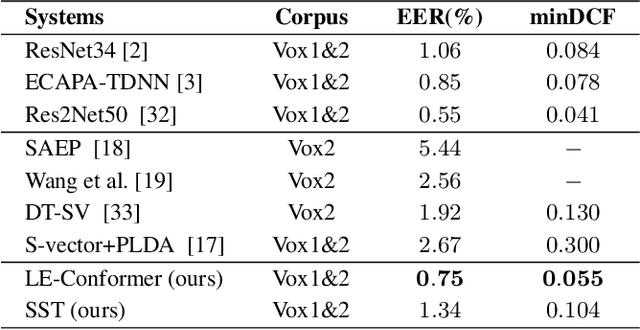
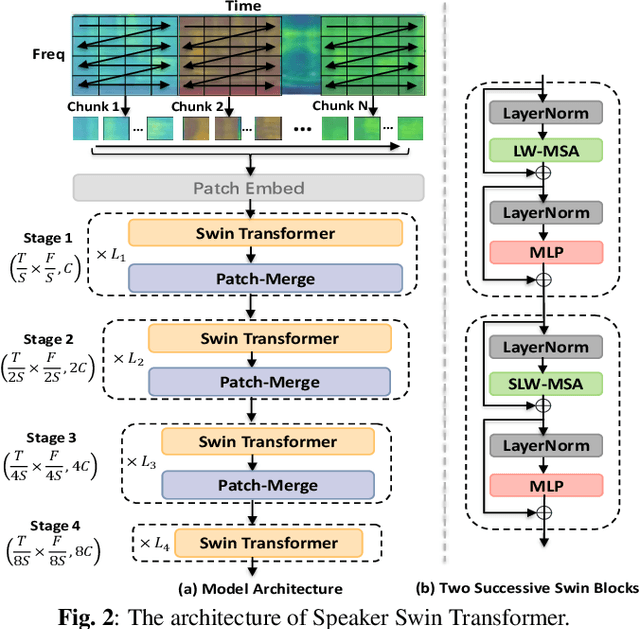
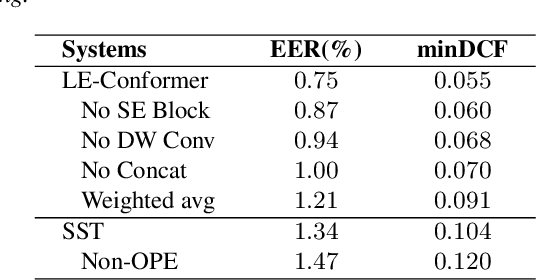
Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing short-range local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer (SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
TransNet: Transferable Neural Networks for Partial Differential Equations
Jan 27, 2023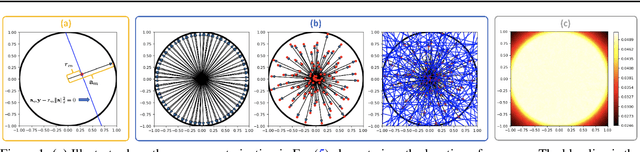

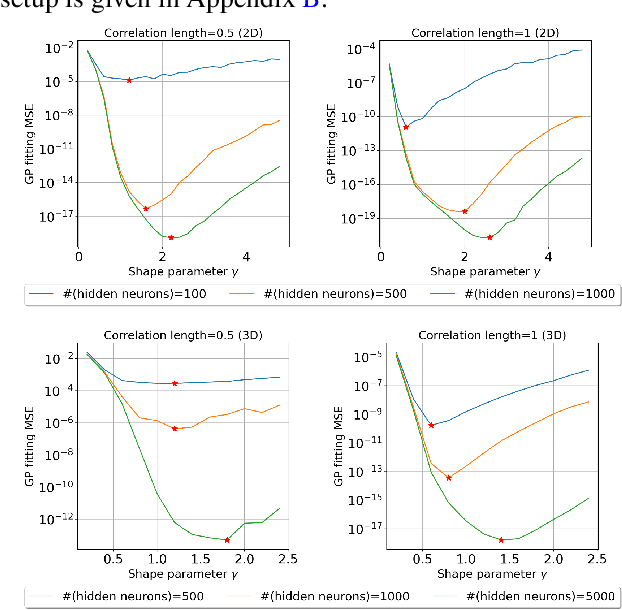
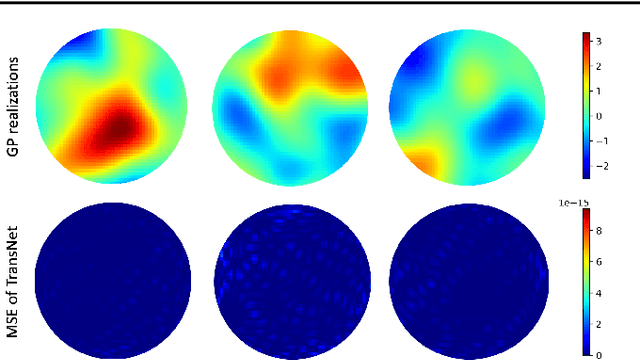
Transfer learning for partial differential equations (PDEs) is to develop a pre-trained neural network that can be used to solve a wide class of PDEs. Existing transfer learning approaches require much information of the target PDEs such as its formulation and/or data of its solution for pre-training. In this work, we propose to construct transferable neural feature spaces from purely function approximation perspectives without using PDE information. The construction of the feature space involves re-parameterization of the hidden neurons and uses auxiliary functions to tune the resulting feature space. Theoretical analysis shows the high quality of the produced feature space, i.e., uniformly distributed neurons. Extensive numerical experiments verify the outstanding performance of our method, including significantly improved transferability, e.g., using the same feature space for various PDEs with different domains and boundary conditions, and the superior accuracy, e.g., several orders of magnitude smaller mean squared error than the state of the art methods.