 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Skeleton-based Action Recognition through Contrasting Two-Stream Spatial-Temporal Networks
Jan 27, 2023
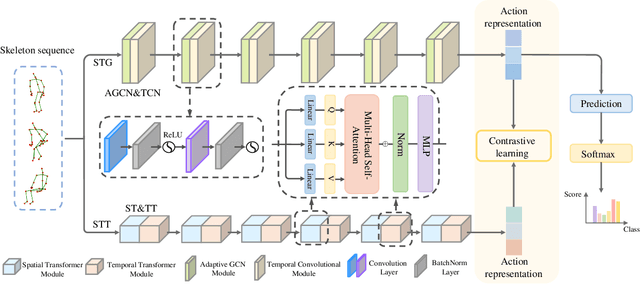
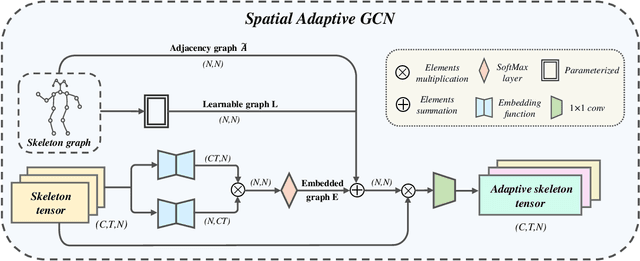
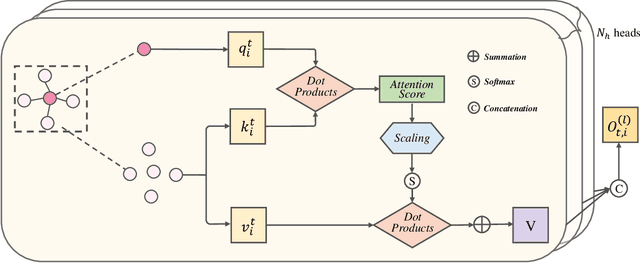
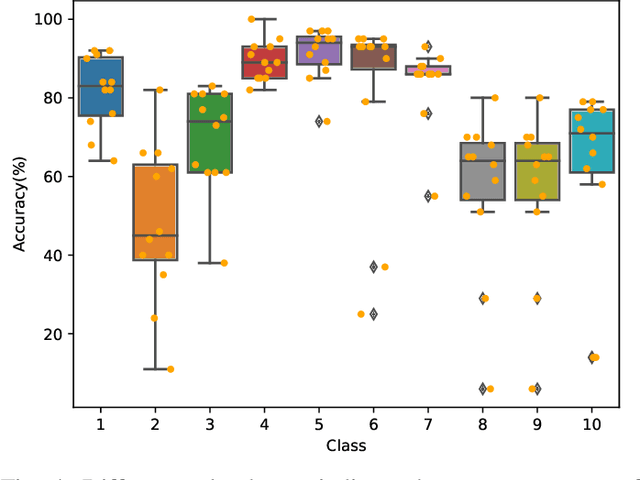
For pursuing accurate skeleton-based action recognition, most prior methods use the strategy of combining Graph Convolution Networks (GCNs) with attention-based methods in a serial way. However, they regard the human skeleton as a complete graph, resulting in less variations between different actions (e.g., the connection between the elbow and head in action ``clapping hands''). For this, we propose a novel Contrastive GCN-Transformer Network (ConGT) which fuses the spatial and temporal modules in a parallel way. The ConGT involves two parallel streams: Spatial-Temporal Graph Convolution stream (STG) and Spatial-Temporal Transformer stream (STT). The STG is designed to obtain action representations maintaining the natural topology structure of the human skeleton. The STT is devised to acquire action representations containing the global relationships among joints. Since the action representations produced from these two streams contain different characteristics, and each of them knows little information of the other, we introduce the contrastive learning paradigm to guide their output representations of the same sample to be as close as possible in a self-supervised manner. Through the contrastive learning, they can learn information from each other to enrich the action features by maximizing the mutual information between the two types of action representations. To further improve action recognition accuracy, we introduce the Cyclical Focal Loss (CFL) which can focus on confident training samples in early training epochs, with an increasing focus on hard samples during the middle epochs. We conduct experiments on three benchmark datasets, which demonstrate that our model achieves state-of-the-art performance in action recognition.
HDPV-SLAM: Hybrid Depth-augmented Panoramic Visual SLAM for Mobile Mapping System with Tilted LiDAR and Panoramic Visual Camera
Jan 27, 2023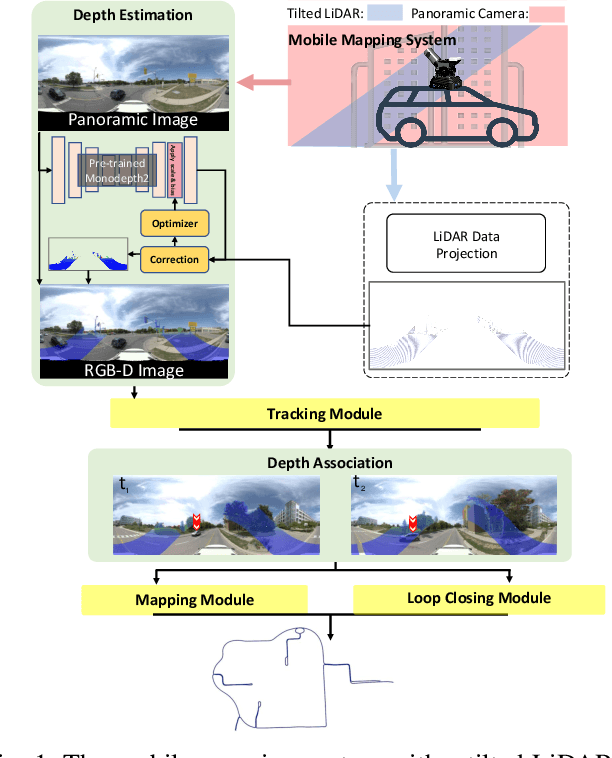
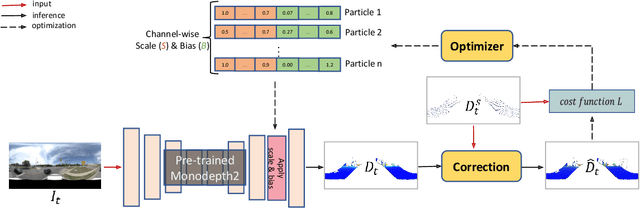


This paper proposes a novel visual simultaneous localization and mapping (SLAM), called Hybrid Depth-augmented Panoramic Visual SLAM (HDPV-SLAM), generating accurate and metrically scaled vehicle trajectories using a panoramic camera and a titled multi-beam LiDAR scanner. RGB-D SLAM served as the design foundation for HDPV-SLAM, adding depth information to visual features. It seeks to overcome the two problems that limit the performance of RGB-D SLAM systems. The first barrier is the sparseness of LiDAR depth, which makes it challenging to connect it with visual features extracted from the RGB image. We address this issue by proposing a depth estimation module for iteratively densifying sparse LiDAR depth based on deep learning (DL). The second issue relates to the challenges in the depth association caused by a significant deficiency of horizontal overlapping coverage between the panoramic camera and the tilted LiDAR sensor. To overcome this difficulty, we present a hybrid depth association module that optimally combines depth information estimated by two independent procedures, feature triangulation and depth estimation. This hybrid depth association module intends to maximize the use of more accurate depth information between the triangulated depth with visual features tracked and the DL-based corrected depth during a phase of feature tracking. We assessed HDPV-SLAM's performance using the 18.95 km-long York University and Teledyne Optech (YUTO) MMS dataset. Experimental results demonstrate that the proposed two modules significantly contribute to HDPV-SLAM's performance, which outperforms the state-of-the-art (SOTA) SLAM systems.
Capturing Global Structural Information in Long Document Question Answering with Compressive Graph Selector Network
Oct 11, 2022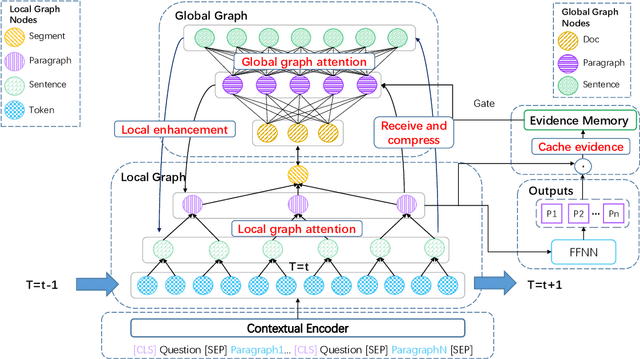
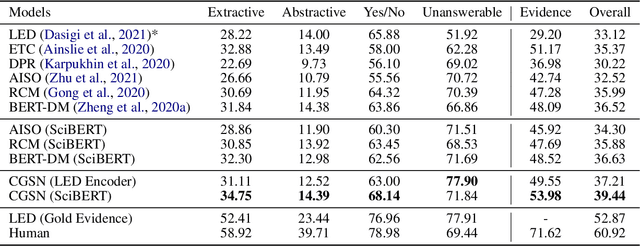
Long document question answering is a challenging task due to its demands for complex reasoning over long text. Previous works usually take long documents as non-structured flat texts or only consider the local structure in long documents. However, these methods usually ignore the global structure of the long document, which is essential for long-range understanding. To tackle this problem, we propose Compressive Graph Selector Network (CGSN) to capture the global structure in a compressive and iterative manner. Specifically, the proposed model consists of three modules: local graph network, global graph network and evidence memory network. Firstly, the local graph network builds the graph structure of the chunked segment in token, sentence, paragraph and segment levels to capture the short-term dependency of the text. Secondly, the global graph network selectively receives the information of each level from the local graph, compresses them into the global graph nodes and applies graph attention into the global graph nodes to build the long-range reasoning over the entire text in an iterative way. Thirdly, the evidence memory network is designed to alleviate the redundancy problem in the evidence selection via saving the selected result in the previous steps. Extensive experiments show that the proposed model outperforms previous methods on two datasets.
SUPS: A Simulated Underground Parking Scenario Dataset for Autonomous Driving
Feb 25, 2023
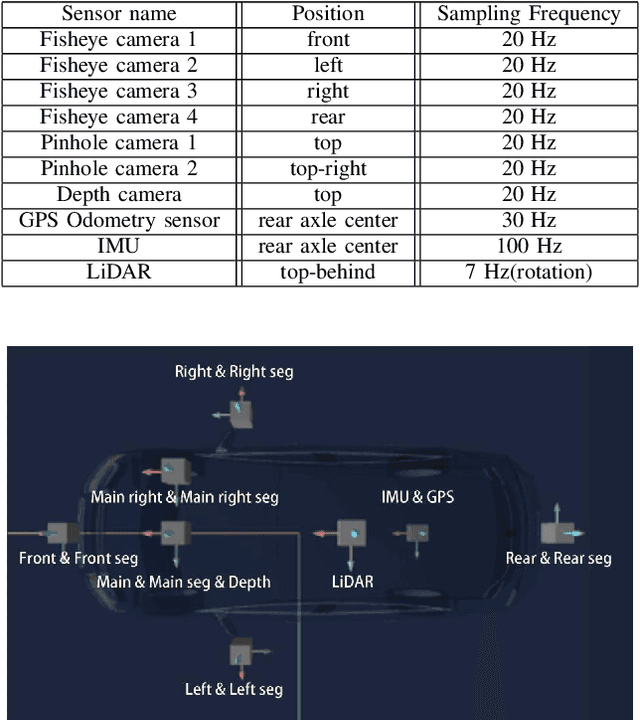

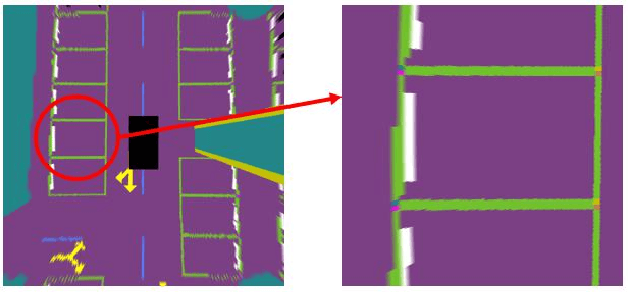
Automatic underground parking has attracted considerable attention as the scope of autonomous driving expands. The auto-vehicle is supposed to obtain the environmental information, track its location, and build a reliable map of the scenario. Mainstream solutions consist of well-trained neural networks and simultaneous localization and mapping (SLAM) methods, which need numerous carefully labeled images and multiple sensor estimations. However, there is a lack of underground parking scenario datasets with multiple sensors and well-labeled images that support both SLAM tasks and perception tasks, such as semantic segmentation and parking slot detection. In this paper, we present SUPS, a simulated dataset for underground automatic parking, which supports multiple tasks with multiple sensors and multiple semantic labels aligned with successive images according to timestamps. We intend to cover the defect of existing datasets with the variability of environments and the diversity and accessibility of sensors in the virtual scene. Specifically, the dataset records frames from four surrounding fisheye cameras, two forward pinhole cameras, a depth camera, and data from LiDAR, inertial measurement unit (IMU), GNSS. Pixel-level semantic labels are provided for objects, especially ground signs such as arrows, parking lines, lanes, and speed bumps. Perception, 3D reconstruction, depth estimation, and SLAM, and other relative tasks are supported by our dataset. We also evaluate the state-of-the-art SLAM algorithms and perception models on our dataset. Finally, we open source our virtual 3D scene built based on Unity Engine and release our dataset at https://github.com/jarvishou829/SUPS.
Visual Semantic Relatedness Dataset for Image Captioning
Jan 20, 2023
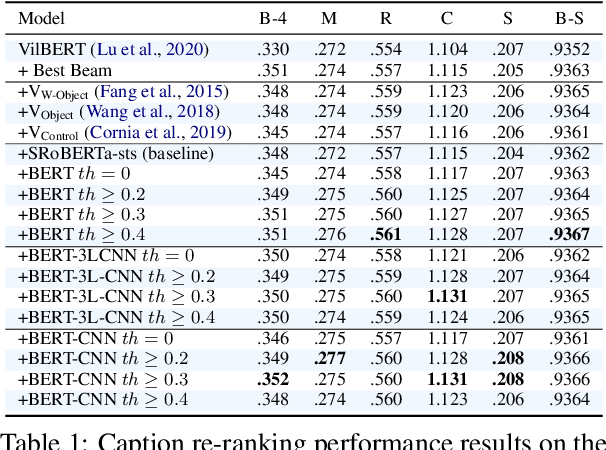
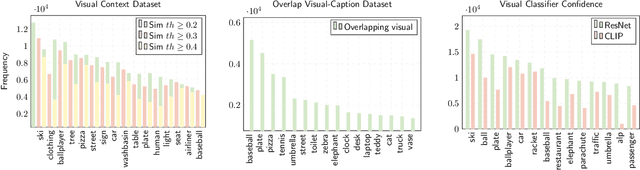
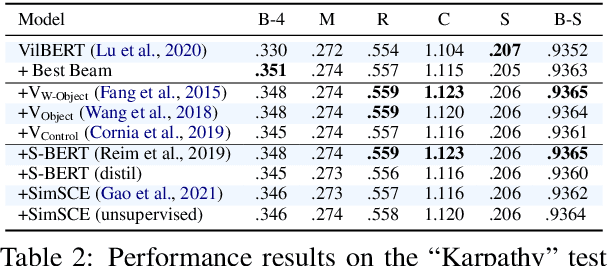
Modern image captioning system relies heavily on extracting knowledge from images to capture the concept of a static story. In this paper, we propose a textual visual context dataset for captioning, in which the publicly available dataset COCO Captions (Lin et al., 2014) has been extended with information about the scene (such as objects in the image). Since this information has a textual form, it can be used to leverage any NLP task, such as text similarity or semantic relation methods, into captioning systems, either as an end-to-end training strategy or a post-processing based approach.
On the $f$-Differential Privacy Guarantees of Discrete-Valued Mechanisms
Feb 19, 2023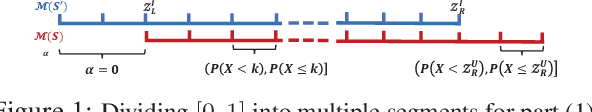
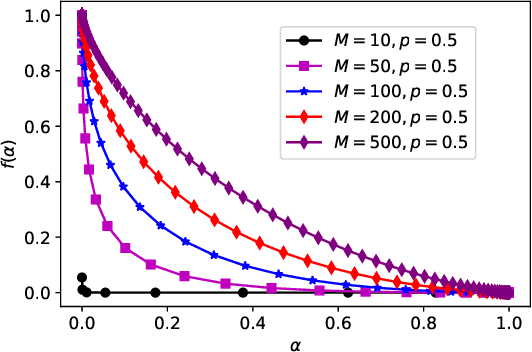
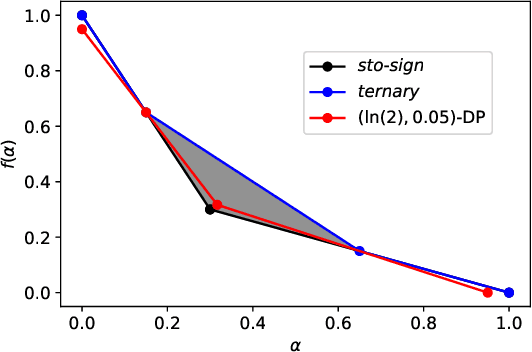
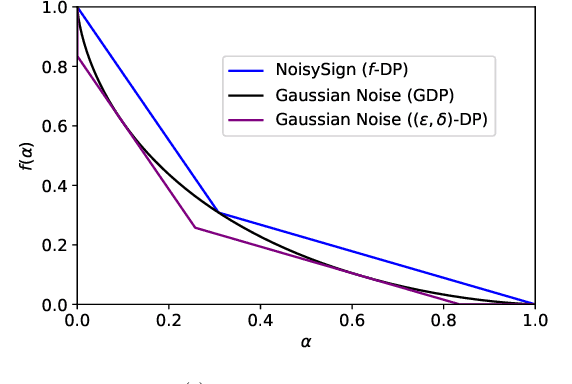
We consider a federated data analytics problem in which a server coordinates the collaborative data analysis of multiple users with privacy concerns and limited communication capability. The commonly adopted compression schemes introduce information loss into local data while improving communication efficiency, and it remains an open question whether such discrete-valued mechanisms provide any privacy protection. Considering that differential privacy has become the gold standard for privacy measures due to its simple implementation and rigorous theoretical foundation, in this paper, we study the privacy guarantees of discrete-valued mechanisms with finite output space in the lens of $f$-differential privacy (DP). By interpreting the privacy leakage as a hypothesis testing problem, we derive the closed-form expression of the tradeoff between type I and type II error rates, based on which the $f$-DP guarantees of a variety of discrete-valued mechanisms, including binomial mechanisms, sign-based methods, and ternary-based compressors, are characterized. We further investigate the Byzantine resilience of binomial mechanisms and ternary compressors and characterize the tradeoff among differential privacy, Byzantine resilience, and communication efficiency. Finally, we discuss the application of the proposed method to differentially private stochastic gradient descent in federated learning.
Video Waterdrop Removal via Spatio-Temporal Fusion in Driving Scenes
Feb 12, 2023
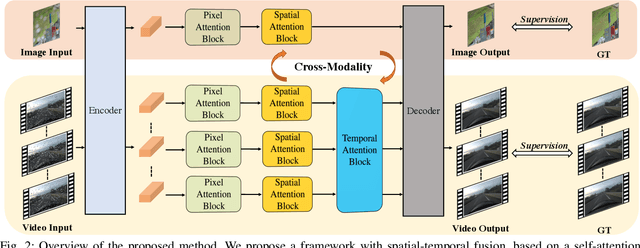

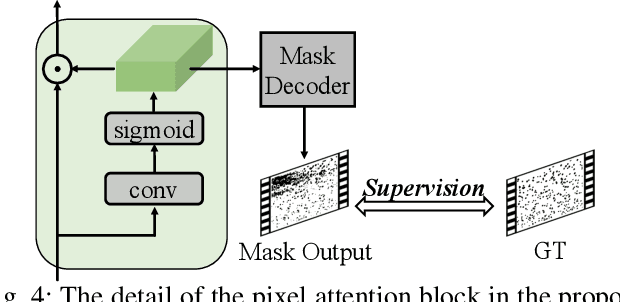
The waterdrops on windshields during driving can cause severe visual obstructions, which may lead to car accidents. Meanwhile, the waterdrops can also degrade the performance of a computer vision system in autonomous driving. To address these issues, we propose an attention-based framework that fuses the spatio-temporal representations from multiple frames to restore visual information occluded by waterdrops. Due to the lack of training data for video waterdrop removal, we propose a large-scale synthetic dataset with simulated waterdrops in complex driving scenes on rainy days. To improve the generality of our proposed method, we adopt a cross-modality training strategy that combines synthetic videos and real-world images. Extensive experiments show that our proposed method can generalize well and achieve the best waterdrop removal performance in complex real-world driving scenes.
Targeted Image Reconstruction by Sampling Pre-trained Diffusion Model
Jan 18, 2023
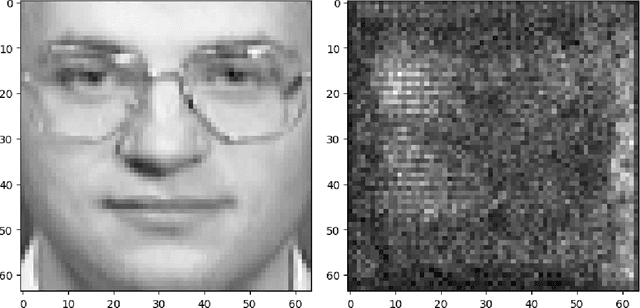
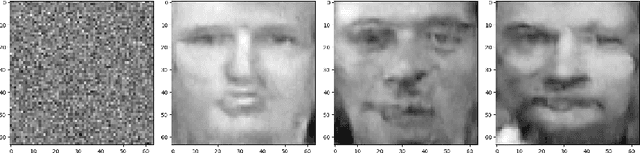

A trained neural network model contains information on the training data. Given such a model, malicious parties can leverage the "knowledge" in this model and design ways to print out any usable information (known as model inversion attack). Therefore, it is valuable to explore the ways to conduct a such attack and demonstrate its severity. In this work, we proposed ways to generate a data point of the target class without prior knowledge of the exact target distribution by using a pre-trained diffusion model.
Coalescing Global and Local Information for Procedural Text Understanding
Aug 26, 2022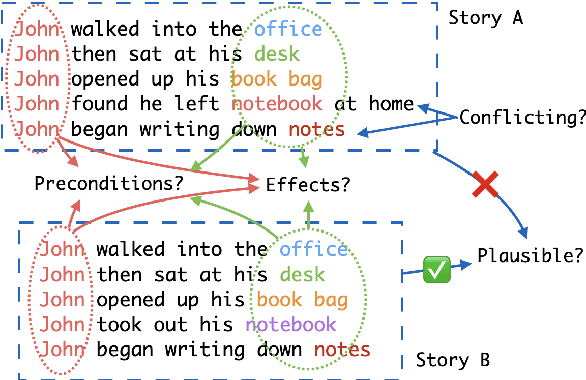
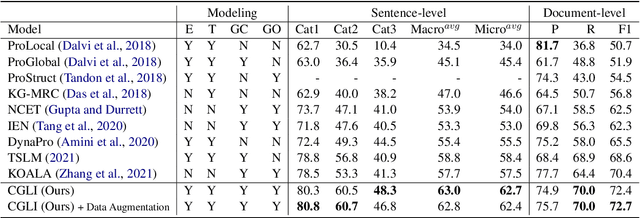
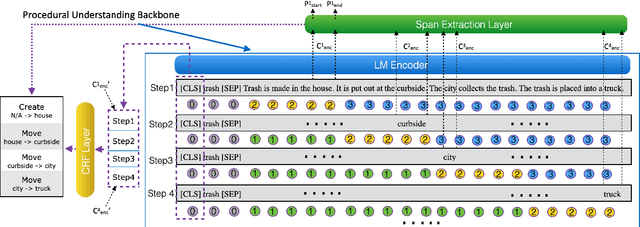
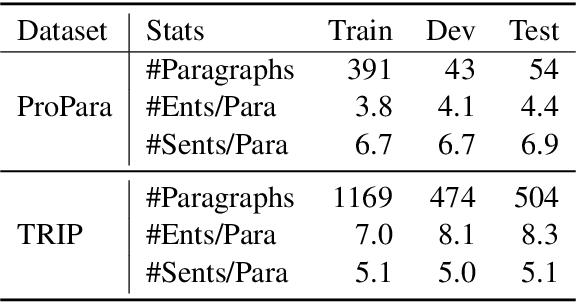
Procedural text understanding is a challenging language reasoning task that requires models to track entity states across the development of a narrative. A complete procedural understanding solution should combine three core aspects: local and global views of the inputs, and global view of outputs. Prior methods considered a subset of these aspects, resulting in either low precision or low recall. In this paper, we propose Coalescing Global and Local Information (CGLI), a new model that builds entity- and timestep-aware input representations (local input) considering the whole context (global input), and we jointly model the entity states with a structured prediction objective (global output). Thus, CGLI simultaneously optimizes for both precision and recall. We extend CGLI with additional output layers and integrate it into a story reasoning framework. Extensive experiments on a popular procedural text understanding dataset show that our model achieves state-of-the-art results; experiments on a story reasoning benchmark show the positive impact of our model on downstream reasoning.
3D-aware Blending with Generative NeRFs
Feb 13, 2023

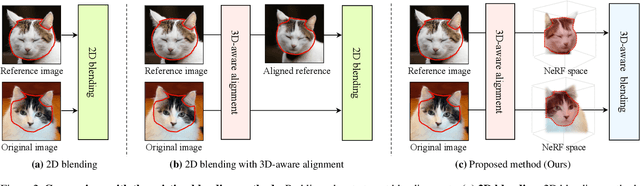
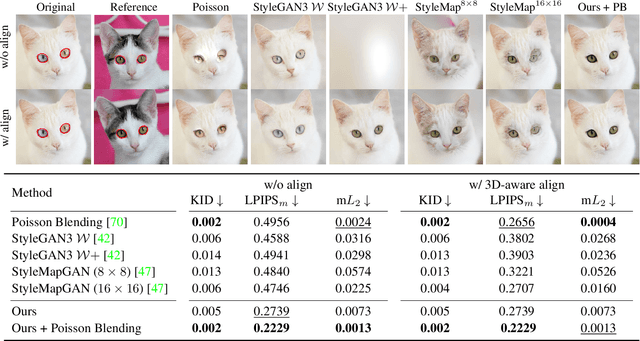
Image blending aims to combine multiple images seamlessly. It remains challenging for existing 2D-based methods, especially when input images are misaligned due to differences in 3D camera poses and object shapes. To tackle these issues, we propose a 3D-aware blending method using generative Neural Radiance Fields (NeRF), including two key components: 3D-aware alignment and 3D-aware blending. For 3D-aware alignment, we first estimate the camera pose of the reference image with respect to generative NeRFs and then perform 3D local alignment for each part. To further leverage 3D information of the generative NeRF, we propose 3D-aware blending that directly blends images on the NeRF's latent representation space, rather than raw pixel space. Collectively, our method outperforms existing 2D baselines, as validated by extensive quantitative and qualitative evaluations with FFHQ and AFHQ-Cat.