 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Metaphor Detection with Effective Context Denoising
Feb 11, 2023
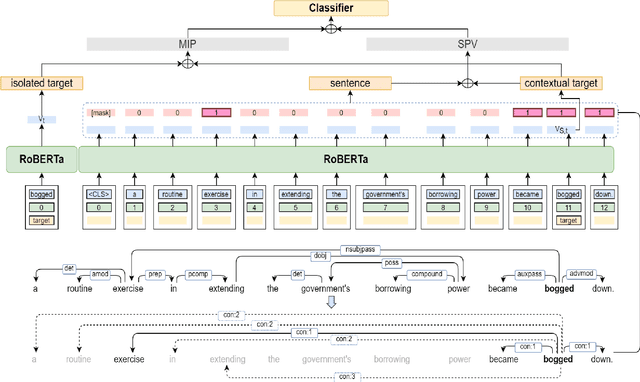
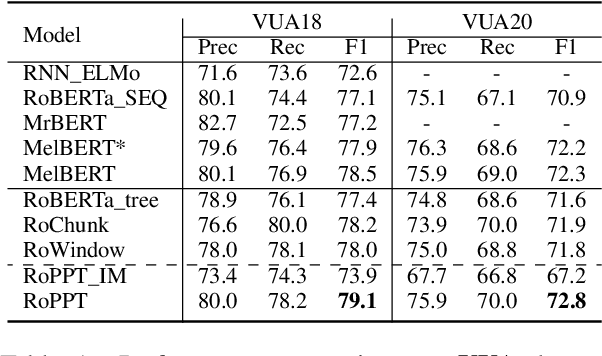
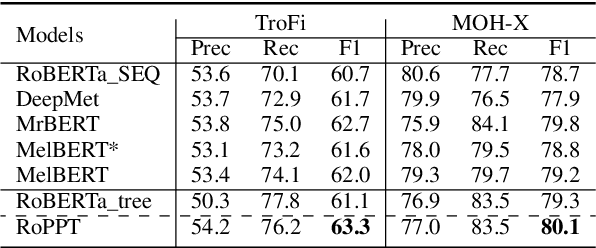
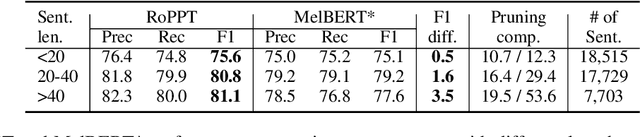
We propose a novel RoBERTa-based model, RoPPT, which introduces a target-oriented parse tree structure in metaphor detection. Compared to existing models, RoPPT focuses on semantically relevant information and achieves the state-of-the-art on several main metaphor datasets. We also compare our approach against several popular denoising and pruning methods, demonstrating the effectiveness of our approach in context denoising. Our code and dataset can be found at https://github.com/MajiBear000/RoPPT
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 09, 2023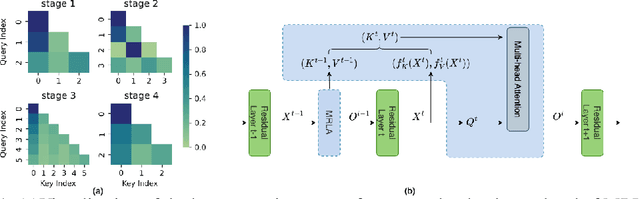
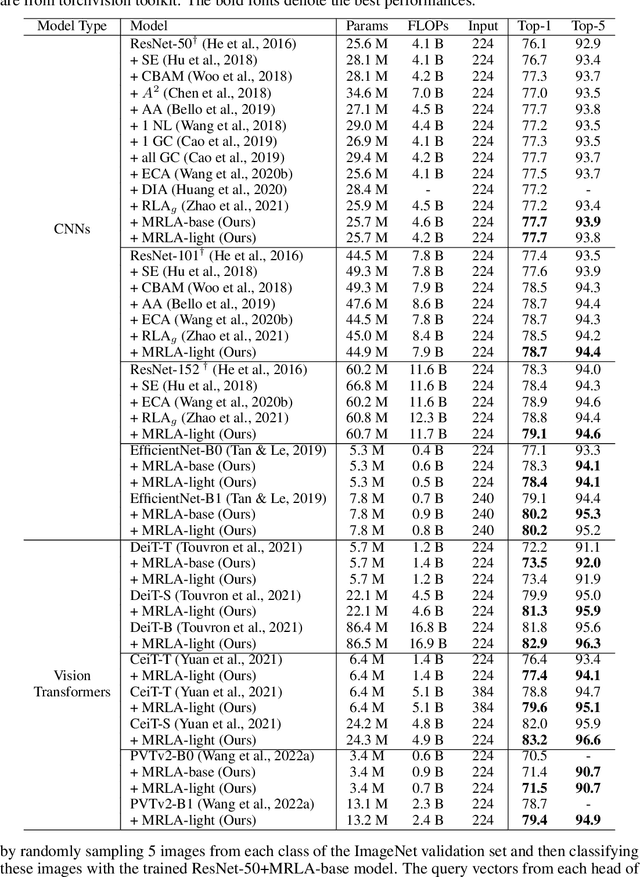
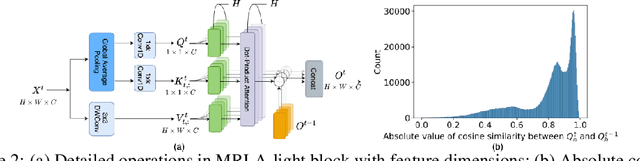
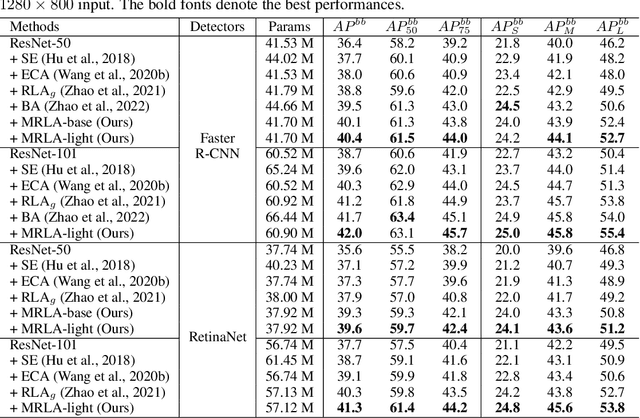
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6\% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4\% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Lorentz Equivariant Model for Knowledge-Enhanced Collaborative Filtering
Feb 09, 2023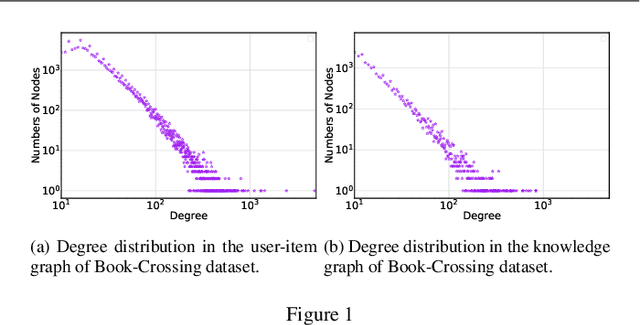
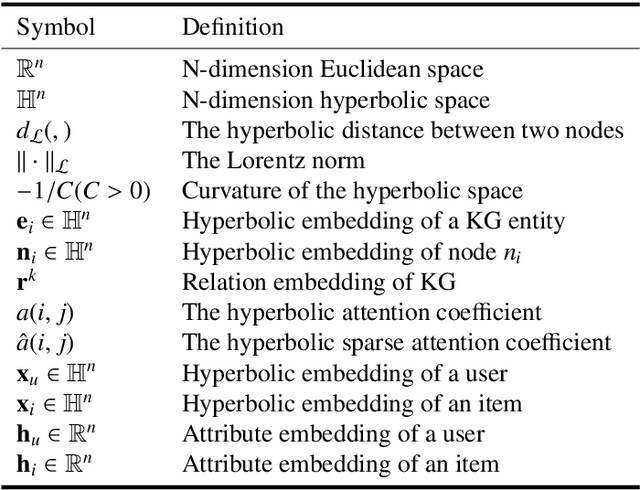
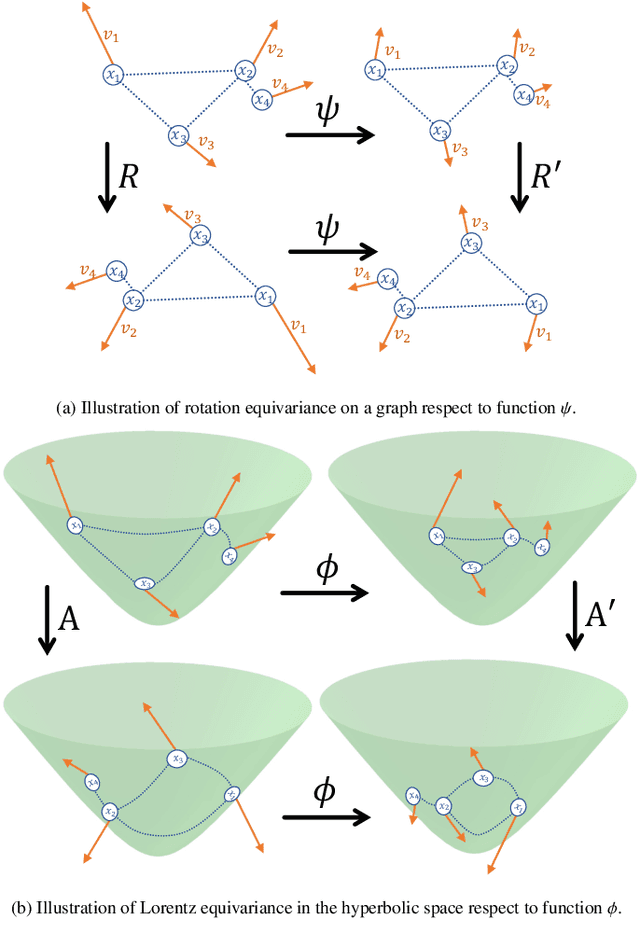
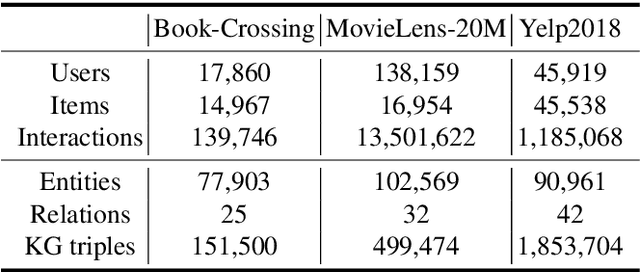
Introducing prior auxiliary information from the knowledge graph (KG) to assist the user-item graph can improve the comprehensive performance of the recommender system. Many recent studies show that the ensemble properties of hyperbolic spaces fit the scale-free and hierarchical characteristics exhibited in the above two types of graphs well. However, existing hyperbolic methods ignore the consideration of equivariance, thus they cannot generalize symmetric features under given transformations, which seriously limits the capability of the model. Moreover, they cannot balance preserving the heterogeneity and mining the high-order entity information to users across two graphs. To fill these gaps, we propose a rigorously Lorentz group equivariant knowledge-enhanced collaborative filtering model (LECF). Innovatively, we jointly update the attribute embeddings (containing the high-order entity signals from the KG) and hyperbolic embeddings (the distance between hyperbolic embeddings reveals the recommendation tendency) by the LECF layer with Lorentz Equivariant Transformation. Moreover, we propose Hyperbolic Sparse Attention Mechanism to sample the most informative neighbor nodes. Lorentz equivariance is strictly maintained throughout the entire model, and enforcing equivariance is proven necessary experimentally. Extensive experiments on three real-world benchmarks demonstrate that LECF remarkably outperforms state-of-the-art methods.
Key Information Extraction in Purchase Documents using Deep Learning and Rule-based Corrections
Oct 07, 2022
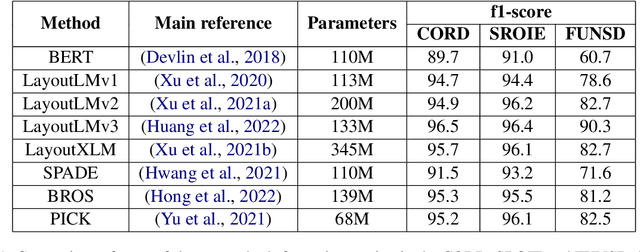


Deep Learning (DL) is dominating the fields of Natural Language Processing (NLP) and Computer Vision (CV) in the recent times. However, DL commonly relies on the availability of large data annotations, so other alternative or complementary pattern-based techniques can help to improve results. In this paper, we build upon Key Information Extraction (KIE) in purchase documents using both DL and rule-based corrections. Our system initially trusts on Optical Character Recognition (OCR) and text understanding based on entity tagging to identify purchase facts of interest (e.g., product codes, descriptions, quantities, or prices). These facts are then linked to a same product group, which is recognized by means of line detection and some grouping heuristics. Once these DL approaches are processed, we contribute several mechanisms consisting of rule-based corrections for improving the baseline DL predictions. We prove the enhancements provided by these rule-based corrections over the baseline DL results in the presented experiments for purchase documents from public and NielsenIQ datasets.
Revised Conditional t-SNE: Looking Beyond the Nearest Neighbors
Feb 07, 2023
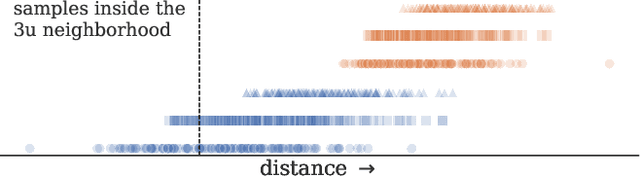

Conditional t-SNE (ct-SNE) is a recent extension to t-SNE that allows removal of known cluster information from the embedding, to obtain a visualization revealing structure beyond label information. This is useful, for example, when one wants to factor out unwanted differences between a set of classes. We show that ct-SNE fails in many realistic settings, namely if the data is well clustered over the labels in the original high-dimensional space. We introduce a revised method by conditioning the high-dimensional similarities instead of the low-dimensional similarities and storing within- and across-label nearest neighbors separately. This also enables the use of recently proposed speedups for t-SNE, improving the scalability. From experiments on synthetic data, we find that our proposed method resolves the considered problems and improves the embedding quality. On real data containing batch effects, the expected improvement is not always there. We argue revised ct-SNE is preferable overall, given its improved scalability. The results also highlight new open questions, such as how to handle distance variations between clusters.
Uplink Joint Positioning and Synchronization in Cell-Free Deployments with Radio Stripes
Feb 07, 2023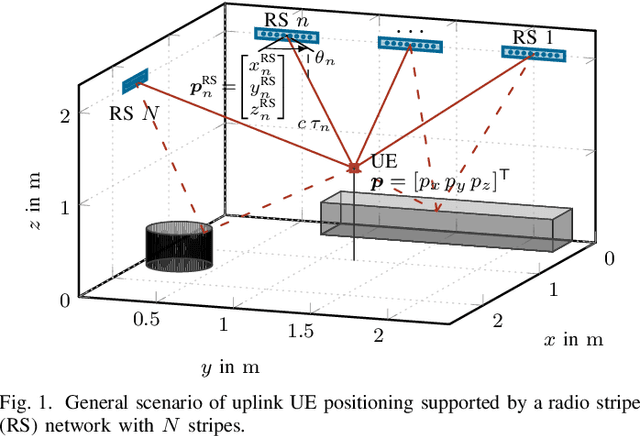
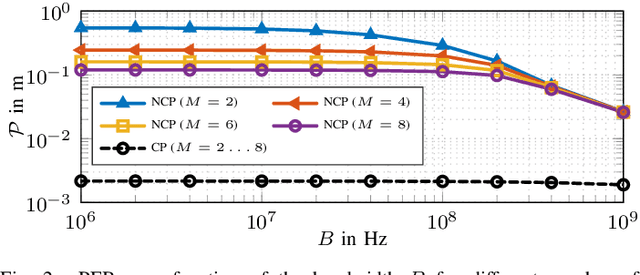
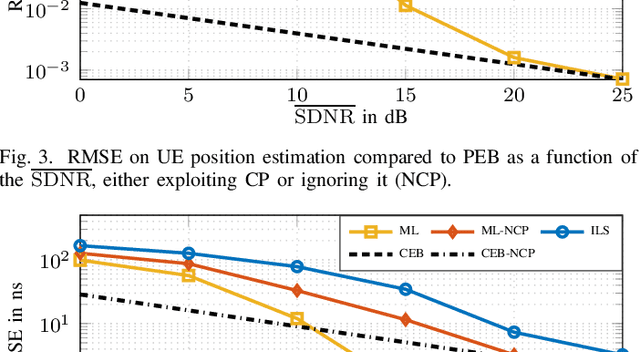
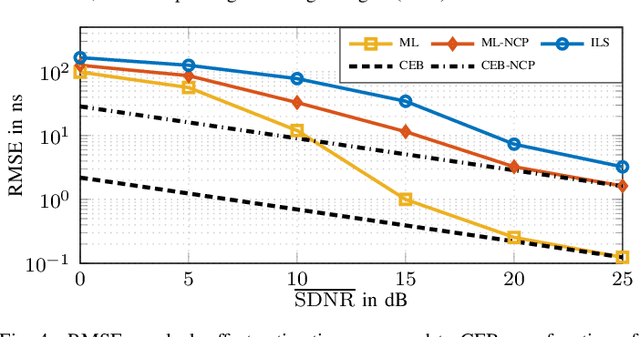
Radio stripes (RSs) is an emerging technology in beyond 5G and 6G wireless networks to support the deployment of cell-free architectures. In this paper, we investigate the potential use of RSs to enable joint positioning and synchronization in the uplink channel at sub-6 GHz bands. The considered scenario consists of a single-antenna user equipment (UE) that communicates with a network of multiple-antenna RSs distributed over a wide area. The UE is assumed to be unsynchronized to the RSs network, while individual RSs are time- and phase-synchronized. We formulate the problem of joint estimation of position, clock offset, and phase offset of the UE and derive the corresponding maximum-likelihood (ML) estimator, both with and without exploiting carrier phase information. To gain fundamental insights into the achievable performance, we also conduct a Fisher information analysis and inspect the theoretical lower bounds numerically. Simulation results demonstrate that promising positioning and synchronization performance can be obtained in cell-free architectures supported by RSs, revealing at the same time the benefits of carrier phase exploitation through phase-synchronized RSs.
Zyxin is all you need: machine learning adherent cell mechanics
Mar 01, 2023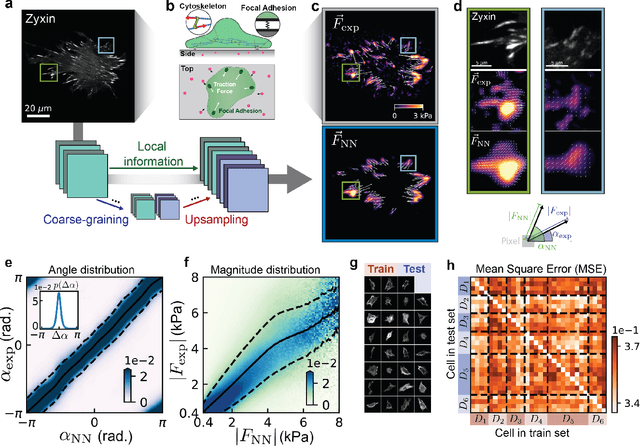
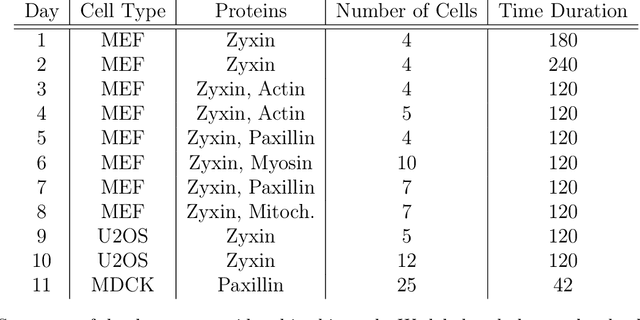
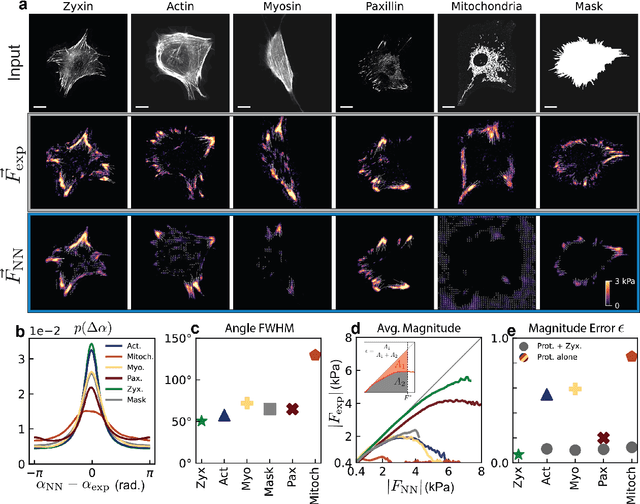
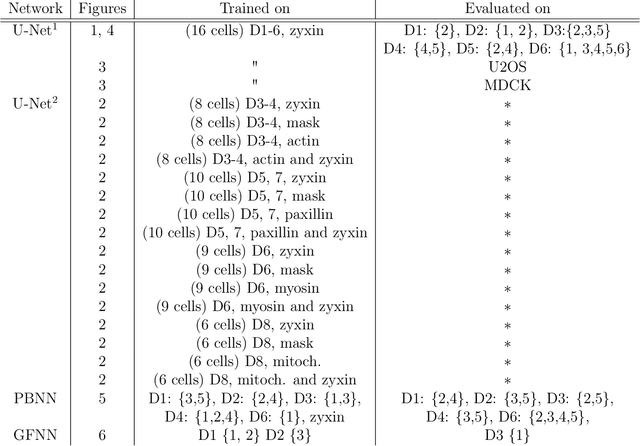
Cellular form and function emerge from complex mechanochemical systems within the cytoplasm. No systematic strategy currently exists to infer large-scale physical properties of a cell from its many molecular components. This is a significant obstacle to understanding biophysical processes such as cell adhesion and migration. Here, we develop a data-driven biophysical modeling approach to learn the mechanical behavior of adherent cells. We first train neural networks to predict forces generated by adherent cells from images of cytoskeletal proteins. Strikingly, experimental images of a single focal adhesion protein, such as zyxin, are sufficient to predict forces and generalize to unseen biological regimes. This protein field alone contains enough information to yield accurate predictions even if forces themselves are generated by many interacting proteins. We next develop two approaches - one explicitly constrained by physics, the other more agnostic - that help construct data-driven continuum models of cellular forces using this single focal adhesion field. Both strategies consistently reveal that cellular forces are encoded by two different length scales in adhesion protein distributions. Beyond adherent cell mechanics, our work serves as a case study for how to integrate neural networks in the construction of predictive phenomenological models in cell biology, even when little knowledge of the underlying microscopic mechanisms exist.
Learning the Effects of Physical Actions in a Multi-modal Environment
Feb 03, 2023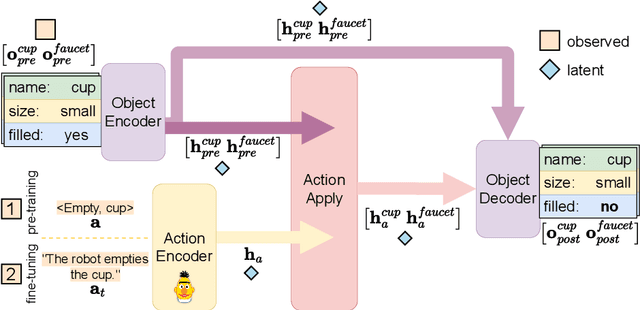
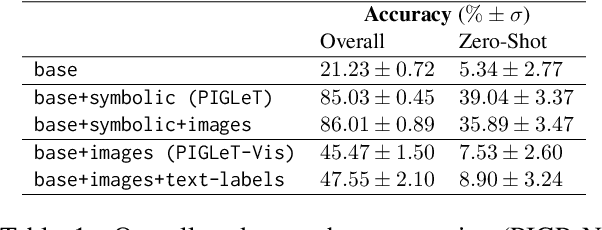
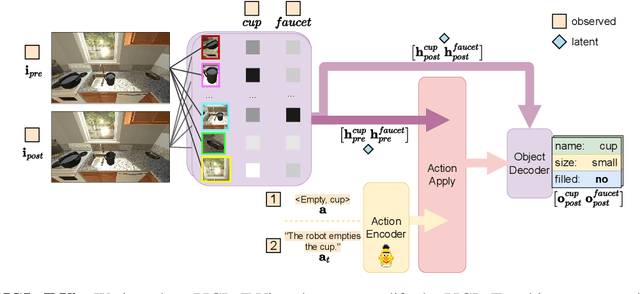
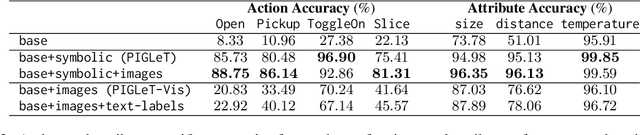
Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.
Multimodal Event Transformer for Image-guided Story Ending Generation
Jan 26, 2023
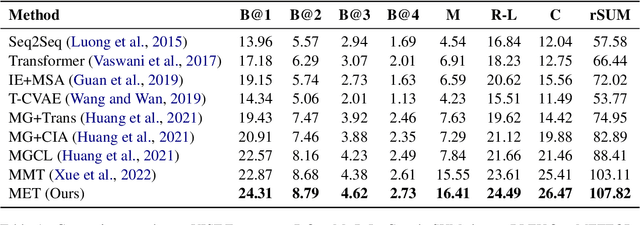
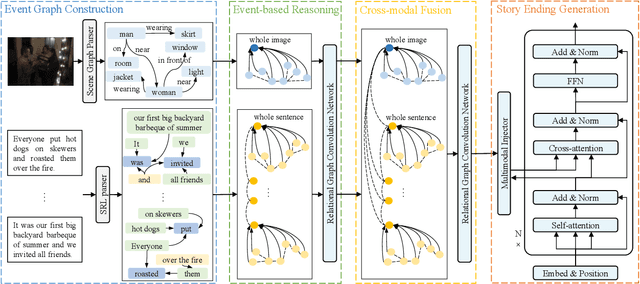
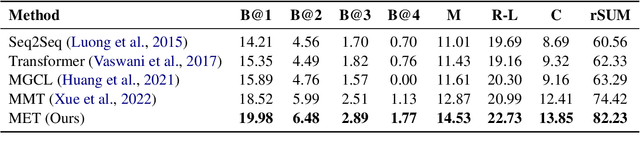
Image-guided story ending generation (IgSEG) is to generate a story ending based on given story plots and ending image. Existing methods focus on cross-modal feature fusion but overlook reasoning and mining implicit information from story plots and ending image. To tackle this drawback, we propose a multimodal event transformer, an event-based reasoning framework for IgSEG. Specifically, we construct visual and semantic event graphs from story plots and ending image, and leverage event-based reasoning to reason and mine implicit information in a single modality. Next, we connect visual and semantic event graphs and utilize cross-modal fusion to integrate different-modality features. In addition, we propose a multimodal injector to adaptive pass essential information to decoder. Besides, we present an incoherence detection to enhance the understanding context of a story plot and the robustness of graph modeling for our model. Experimental results show that our method achieves state-of-the-art performance for the image-guided story ending generation.
Incremental Information Gain Mining Of Temporal Relational Streams
Jun 11, 2022
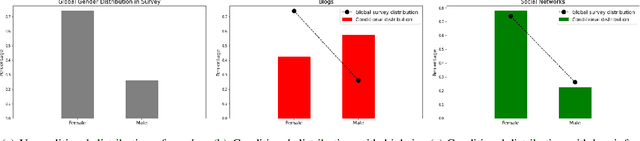
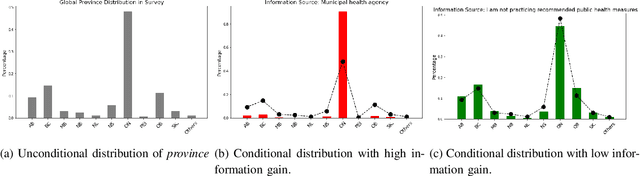

This paper studies the problem of mining for data values with high information gain in relational tables. High information gain can help data analysts and secondary data mining algorithms gain insights into strong statistical dependencies and causality relationship between key metrics. In this paper, we will study the problem of high information gain identification for scenarios involving temporal relations where new records are added continuously to the relations. We show that information gain can be efficiently maintained in an incremental fashion, making it possible to monitor continuously high information gain values.