 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Substitute Ingredients in Recipes
Feb 15, 2023
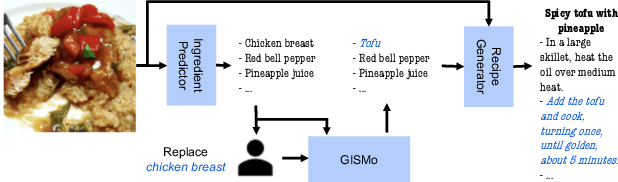
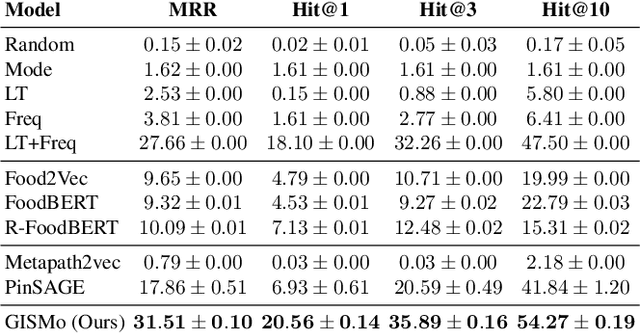
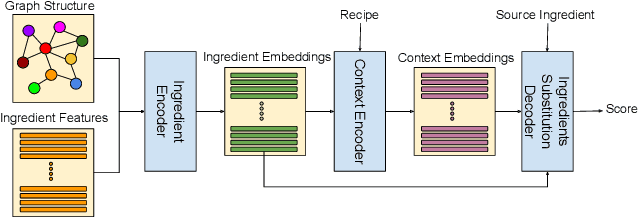
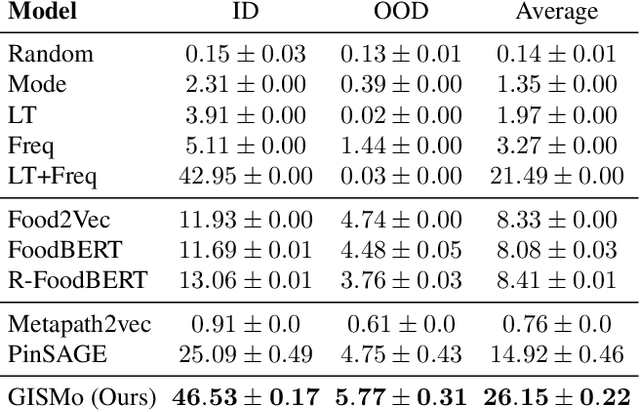
Recipe personalization through ingredient substitution has the potential to help people meet their dietary needs and preferences, avoid potential allergens, and ease culinary exploration in everyone's kitchen. To address ingredient substitution, we build a benchmark, composed of a dataset of substitution pairs with standardized splits, evaluation metrics, and baselines. We further introduce Graph-based Ingredient Substitution Module (GISMo), a novel model that leverages the context of a recipe as well as generic ingredient relational information encoded within a graph to rank plausible substitutions. We show through comprehensive experimental validation that GISMo surpasses the best performing baseline by a large margin in terms of mean reciprocal rank. Finally, we highlight the benefits of GISMo by integrating it in an improved image-to-recipe generation pipeline, enabling recipe personalization through user intervention. Quantitative and qualitative results show the efficacy of our proposed system, paving the road towards truly personalized cooking and tasting experiences.
Instance-wise Grasp Synthesis for Robotic Grasping
Feb 15, 2023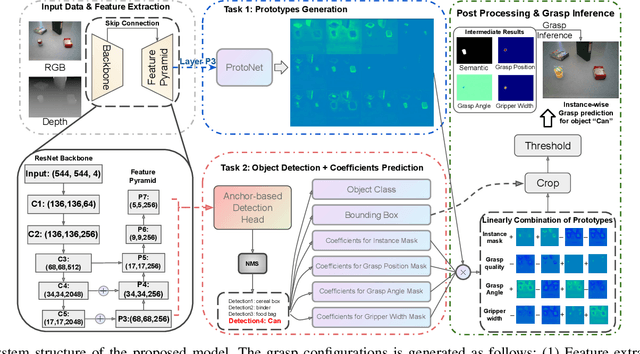

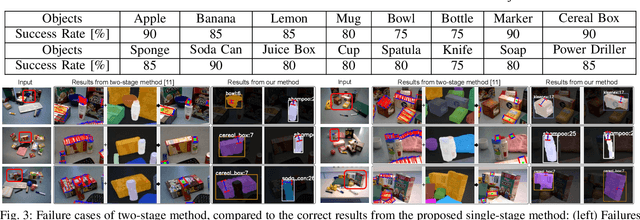

Generating high-quality instance-wise grasp configurations provides critical information of how to grasp specific objects in a multi-object environment and is of high importance for robot manipulation tasks. This work proposed a novel \textbf{S}ingle-\textbf{S}tage \textbf{G}rasp (SSG) synthesis network, which performs high-quality instance-wise grasp synthesis in a single stage: instance mask and grasp configurations are generated for each object simultaneously. Our method outperforms state-of-the-art on robotic grasp prediction based on the OCID-Grasp dataset, and performs competitively on the JACQUARD dataset. The benchmarking results showed significant improvements compared to the baseline on the accuracy of generated grasp configurations. The performance of the proposed method has been validated through both extensive simulations and real robot experiments for three tasks including single object pick-and-place, grasp synthesis in cluttered environments and table cleaning task.
A Federated Learning Benchmark for Drug-Target Interaction
Feb 15, 2023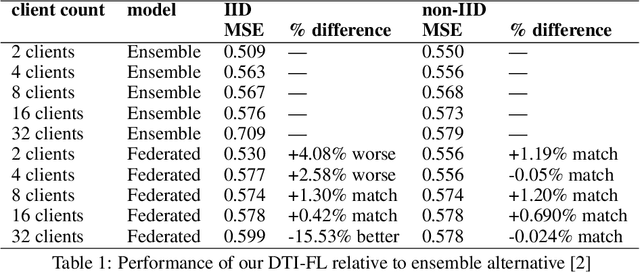
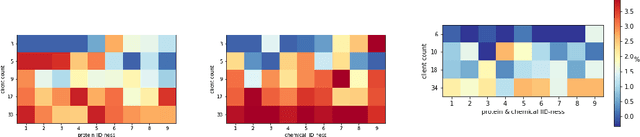
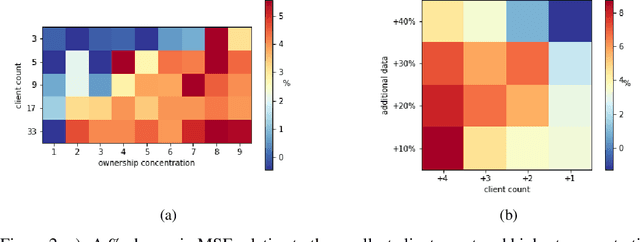
Aggregating pharmaceutical data in the drug-target interaction (DTI) domain has the potential to deliver life-saving breakthroughs. It is, however, notoriously difficult due to regulatory constraints and commercial interests. This work proposes the application of federated learning, which we argue to be reconcilable with the industry's constraints, as it does not require sharing of any information that would reveal the entities' data or any other high-level summary of it. When used on a representative GraphDTA model and the KIBA dataset it achieves up to 15% improved performance relative to the best available non-privacy preserving alternative. Our extensive battery of experiments shows that, unlike in other domains, the non-IID data distribution in the DTI datasets does not deteriorate FL performance. Additionally, we identify a material trade-off between the benefits of adding new data, and the cost of adding more clients.
Conversational AI-Powered Design: ChatGPT as Designer, User, and Product
Feb 15, 2023The recent advancements in Large Language Models (LLMs), particularly conversational LLMs like ChatGPT, have prompted changes in a range of fields, including design. This study aims to examine the capabilities of ChatGPT in a human-centered design process. To this end, a hypothetical design project was conducted, where ChatGPT was utilized to generate personas, simulate interviews with fictional users, create new design ideas, simulate usage scenarios and conversations between an imaginary prototype and fictional users, and lastly evaluate user experience. The results show that ChatGPT effectively performed the tasks assigned to it as a designer, user, or product, providing mostly appropriate responses. The study does, however, highlight some drawbacks such as forgotten information, partial responses, and a lack of output diversity. The paper explains the potential benefits and limitations of using conversational LLMs in design, discusses its implications, and suggests directions for future research in this rapidly evolving area.
Indexed Multiple Access with Reconfigurable Intelligent Surfaces: The Reflection Tuning Potential
Feb 15, 2023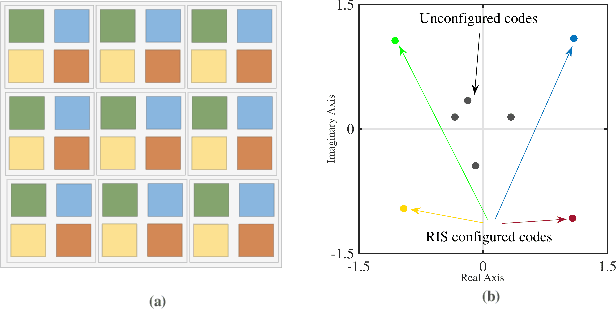
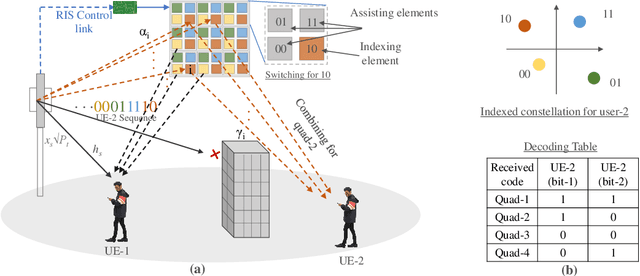
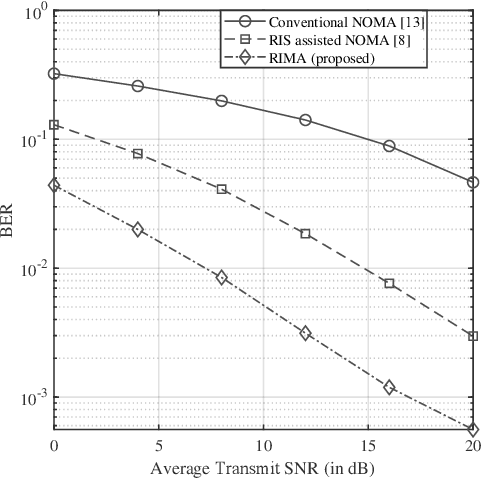

Indexed modulation (IM) is an evolving technique that has become popular due to its ability of parallel data communication over distinct combinations of transmission entities. In this article, we first provide a comprehensive survey of IM-enabled multiple access (MA) techniques, emphasizing the shortcomings of existing non-indexed MA schemes. Theoretical comparisons are presented to show how the notion of indexing eliminates the limitations of non-indexed solutions. We also discuss the benefits that the utilization of a reconfigurable intelligent surface (RIS) can offer when deployed as an indexing entity. In particular, we propose an RIS-indexed multiple access (RIMA) transmission scheme that utilizes dynamic phase tuning to embed multi-user information over a single carrier. The performance of the proposed RIMA is assessed in light of simulation results that confirm its performance gains. The article further includes a list of relevant open technical issues and research directions.
BERT is not The Count: Learning to Match Mathematical Statements with Proofs
Feb 18, 2023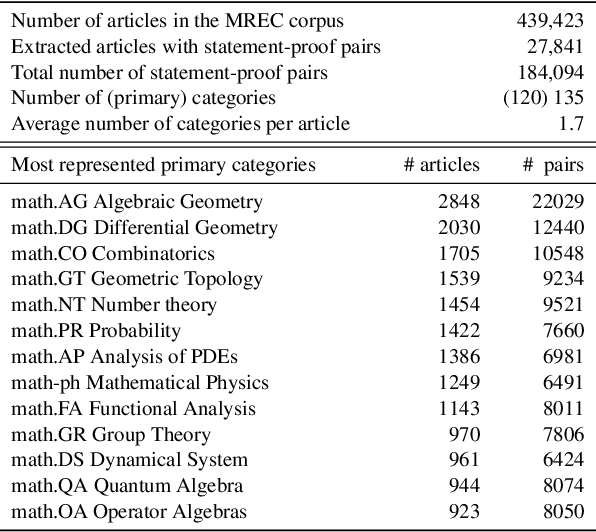
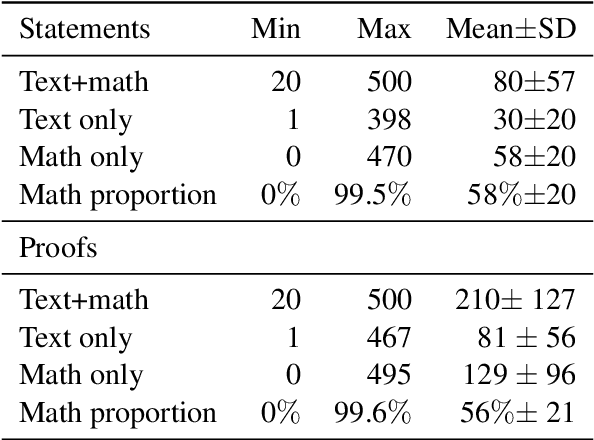

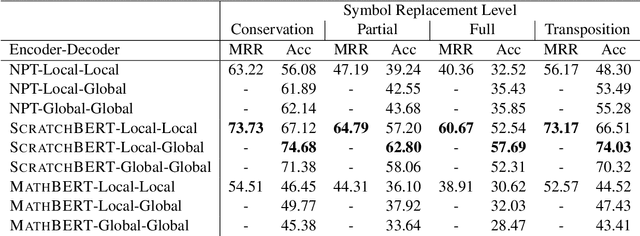
We introduce a task consisting in matching a proof to a given mathematical statement. The task fits well within current research on Mathematical Information Retrieval and, more generally, mathematical article analysis (Mathematical Sciences, 2014). We present a dataset for the task (the MATcH dataset) consisting of over 180k statement-proof pairs extracted from modern mathematical research articles. We find this dataset highly representative of our task, as it consists of relatively new findings useful to mathematicians. We propose a bilinear similarity model and two decoding methods to match statements to proofs effectively. While the first decoding method matches a proof to a statement without being aware of other statements or proofs, the second method treats the task as a global matching problem. Through a symbol replacement procedure, we analyze the "insights" that pre-trained language models have in such mathematical article analysis and show that while these models perform well on this task with the best performing mean reciprocal rank of 73.7, they follow a relatively shallow symbolic analysis and matching to achieve that performance.
Transformer-Based Neural Marked Spatio Temporal Point Process Model for Football Match Events Analysis
Feb 18, 2023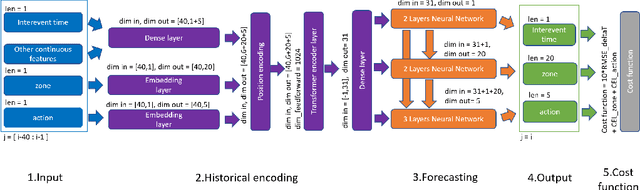


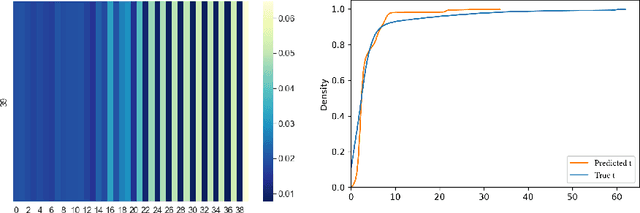
With recently available football match event data that record the details of football matches, analysts and researchers have a great opportunity to develop new performance metrics, gain insight, and evaluate key performance. However, most sports sequential events modeling methods and performance metrics approaches could be incomprehensive in dealing with such large-scale spatiotemporal data (in particular, temporal process), thereby necessitating a more comprehensive spatiotemporal model and a holistic performance metric. To this end, we proposed the Transformer-Based Neural Marked Spatio Temporal Point Process (NMSTPP) model for football event data based on the neural temporal point processes (NTPP) framework. In the experiments, our model outperformed the prediction performance of the baseline models. Furthermore, we proposed the holistic possession utilization score (HPUS) metric for a more comprehensive football possession analysis. For verification, we examined the relationship with football teams' final ranking, average goal score, and average xG over a season. It was observed that the average HPUS showed significant correlations regardless of not using goal and details of shot information. Furthermore, we show HPUS examples in analyzing possessions, matches, and between matches.
Knowledge Graph Completion based on Tensor Decomposition for Disease Gene Prediction
Feb 18, 2023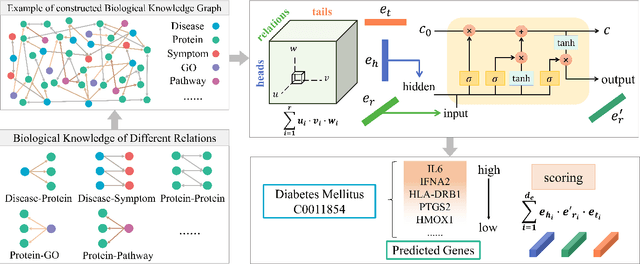
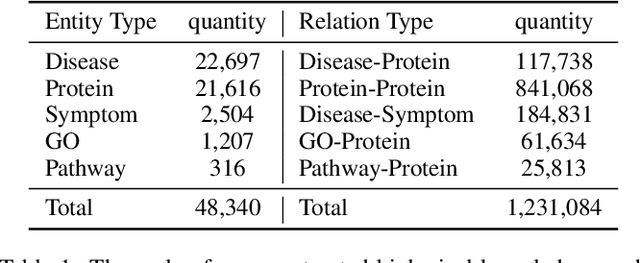
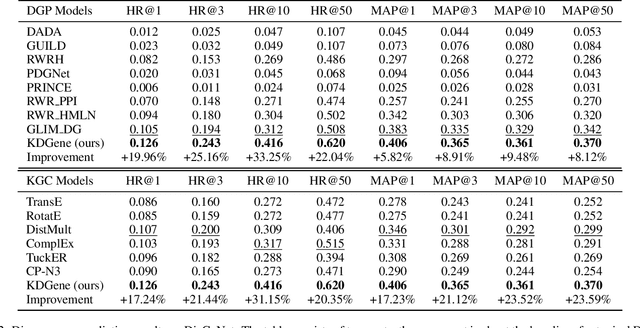
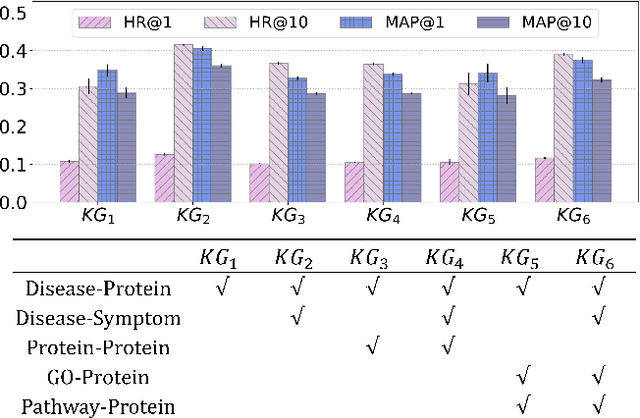
Accurate identification of disease genes has consistently been one of the keys to decoding a disease's molecular mechanism. Most current approaches focus on constructing biological networks and utilizing machine learning, especially, deep learning to identify disease genes, but ignore the complex relations between entities in the biological knowledge graph. In this paper, we construct a biological knowledge graph centered on diseases and genes, and develop an end-to-end Knowledge graph completion model for Disease Gene Prediction using interactional tensor decomposition (called KDGene). KDGene introduces an interaction module between the embeddings of entities and relations to tensor decomposition, which can effectively enhance the information interaction in biological knowledge. Experimental results show that KDGene significantly outperforms state-of-the-art algorithms. Furthermore, the comprehensive biological analysis of the case of diabetes mellitus confirms KDGene's ability for identifying new and accurate candidate genes. This work proposes a scalable knowledge graph completion framework to identify disease candidate genes, from which the results are promising to provide valuable references for further wet experiments.
AirGNN: Graph Neural Network over the Air
Feb 16, 2023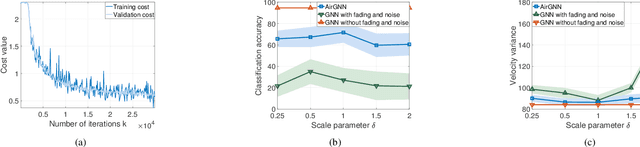
Graph neural networks (GNNs) are information processing architectures that model representations from networked data and allow for decentralized implementation through localized communications. Existing GNN architectures often assume ideal communication links, and ignore channel effects, such as fading and noise, leading to performance degradation in real-world implementation. This paper proposes graph neural networks over the air (AirGNNs), a novel GNN architecture that incorporates the communication model into the architecture. The AirGNN modifies the graph convolutional operation that shifts graph signals over random communication graphs to take into account channel fading and noise when aggregating features from neighbors, thus, improving the architecture robustness to channel impairments during testing. We propose a stochastic gradient descent based method to train the AirGNN, and show that the training procedure converges to a stationary solution. Numerical simulations on decentralized source localization and multi-robot flocking corroborate theoretical findings and show superior performance of the AirGNN over wireless communication channels.
Quantum Channel Modelling by Statistical Quantum Signal Processing
Feb 16, 2023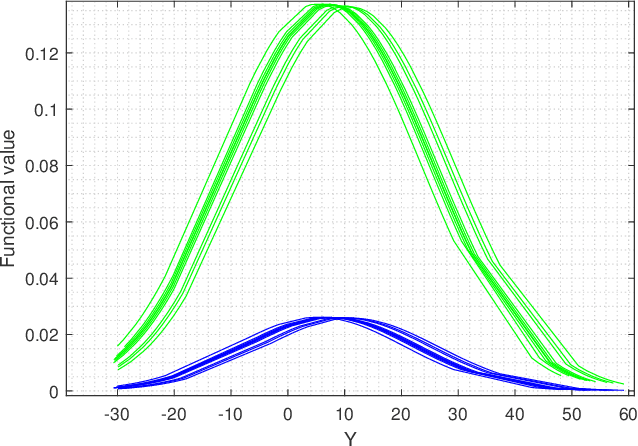
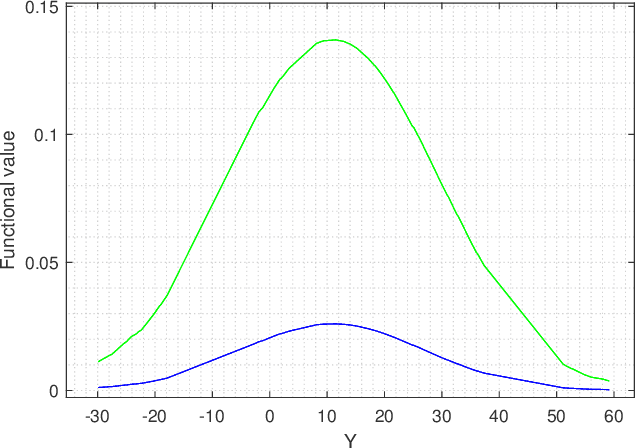
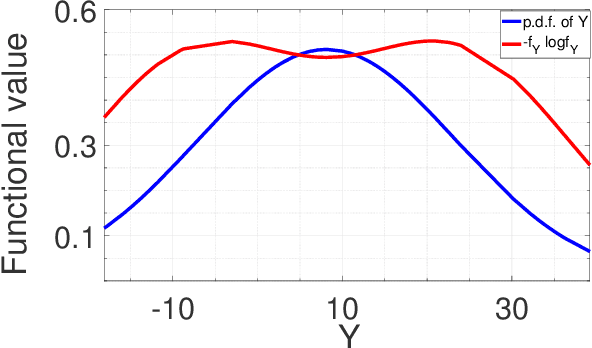
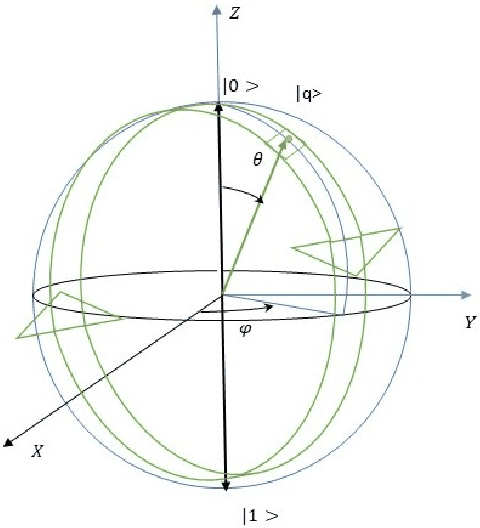
In this paper we are interested to model quantum signal by statistical signal processing methods. The Gaussian distribution has been considered for the input quantum signal as Gaussian state have been proven to a type of important robust state and most of the important experiments of quantum information are done with Gaussian light. Along with that a joint noise model has been invoked, and followed by a received signal model has been formulated by using convolution of transmitted signal and joint quantum noise to realized theoretical achievable capacity of the single quantum link. In joint quantum noise model we consider the quantum Poisson noise with classical Gaussian noise. We compare the capacity of the quantum channel with respect to SNR to detect its overall tendency. In this paper we use the channel equation in terms of random variable to investigate the quantum signals and noise model statistically. These methods are proposed to develop Quantum statistical signal processing and the idea comes from the statistical signal processing.