 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Depth-induced Saliency Comparison Network for Diagnosis of Alzheimer's Disease via Jointly Analysis of Visual Stimuli and Eye Movements
Mar 15, 2024
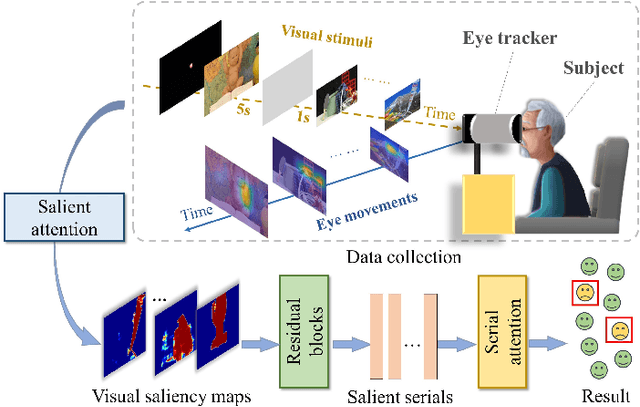
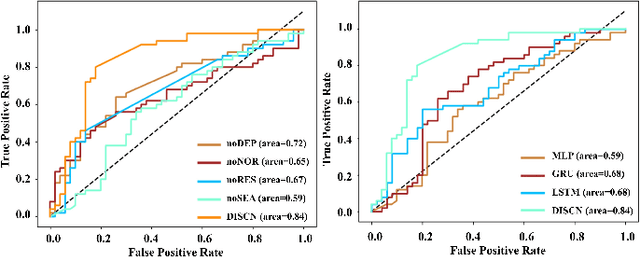
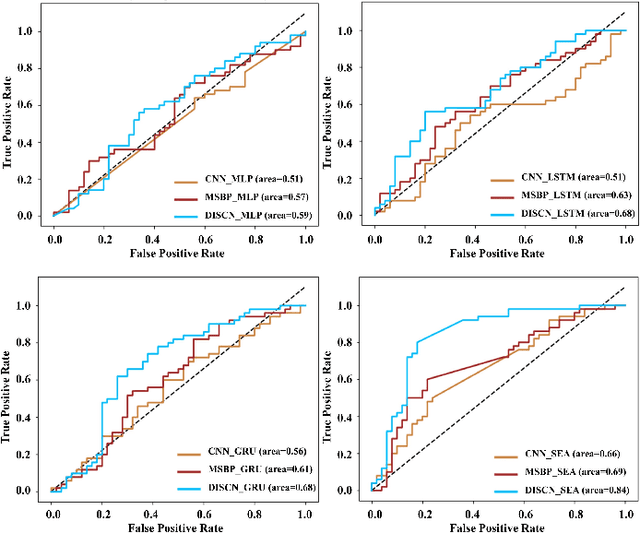
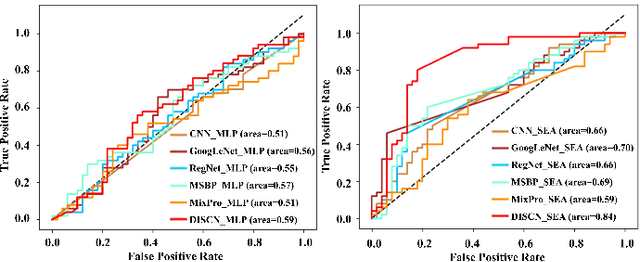
Early diagnosis of Alzheimer's Disease (AD) is very important for following medical treatments, and eye movements under special visual stimuli may serve as a potential non-invasive biomarker for detecting cognitive abnormalities of AD patients. In this paper, we propose an Depth-induced saliency comparison network (DISCN) for eye movement analysis, which may be used for diagnosis the Alzheimers disease. In DISCN, a salient attention module fuses normal eye movements with RGB and depth maps of visual stimuli using hierarchical salient attention (SAA) to evaluate comprehensive saliency maps, which contain information from both visual stimuli and normal eye movement behaviors. In addition, we introduce serial attention module (SEA) to emphasis the most abnormal eye movement behaviors to reduce personal bias for a more robust result. According to our experiments, the DISCN achieves consistent validity in classifying the eye movements between the AD patients and normal controls.
FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
Mar 15, 2024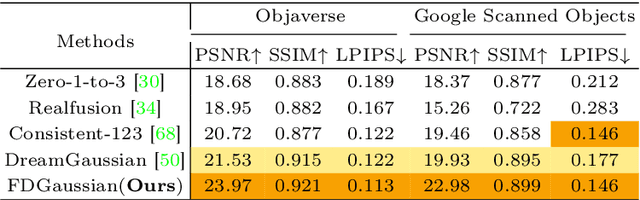
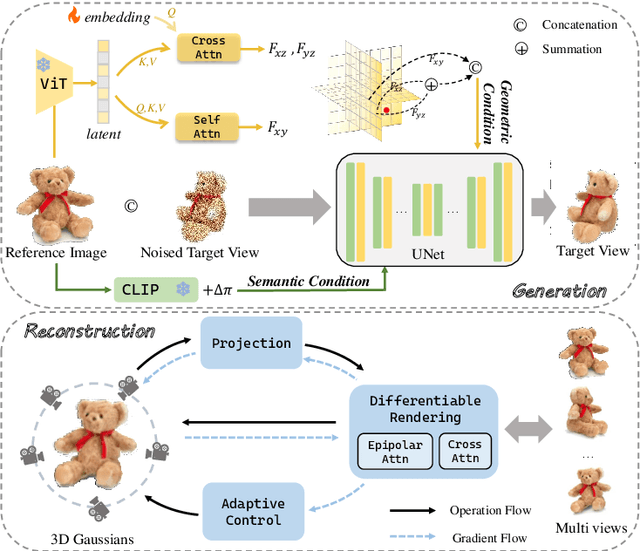
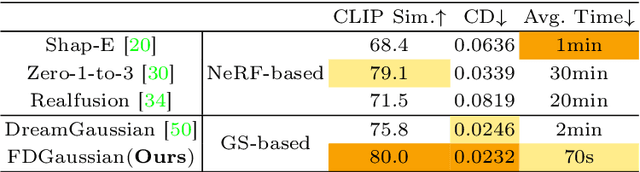
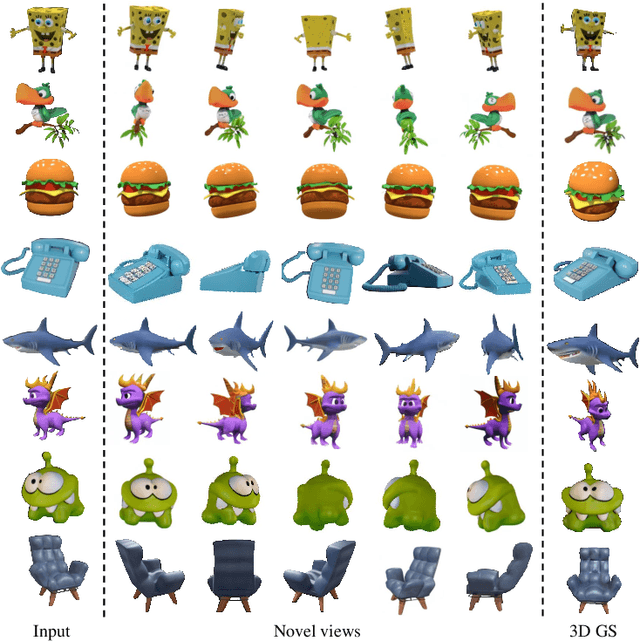
Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction. Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity. To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images. Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively. More examples can be found at our website https://qjfeng.net/FDGaussian/.
Accurate and Data-Efficient Micro-XRD Phase Identification Using Multi-Task Learning: Application to Hydrothermal Fluids
Mar 15, 2024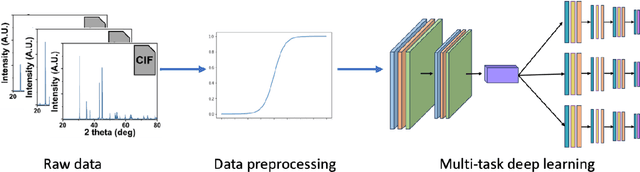

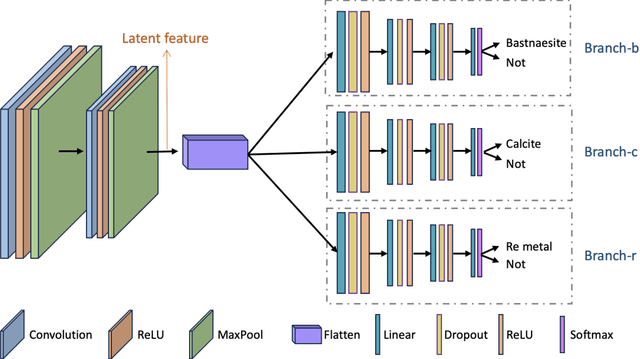
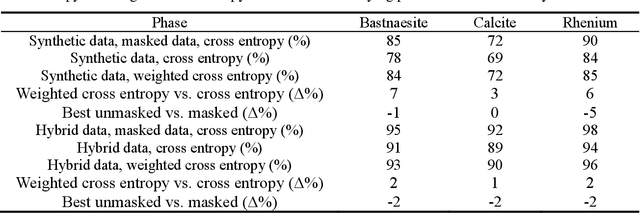
Traditional analysis of highly distorted micro-X-ray diffraction ({\mu}-XRD) patterns from hydrothermal fluid environments is a time-consuming process, often requiring substantial data preprocessing and labeled experimental data. This study demonstrates the potential of deep learning with a multitask learning (MTL) architecture to overcome these limitations. We trained MTL models to identify phase information in {\mu}-XRD patterns, minimizing the need for labeled experimental data and masking preprocessing steps. Notably, MTL models showed superior accuracy compared to binary classification CNNs. Additionally, introducing a tailored cross-entropy loss function improved MTL model performance. Most significantly, MTL models tuned to analyze raw and unmasked XRD patterns achieved close performance to models analyzing preprocessed data, with minimal accuracy differences. This work indicates that advanced deep learning architectures like MTL can automate arduous data handling tasks, streamline the analysis of distorted XRD patterns, and reduce the reliance on labor-intensive experimental datasets.
Fusing Climate Data Products using a Spatially Varying Autoencoder
Mar 12, 2024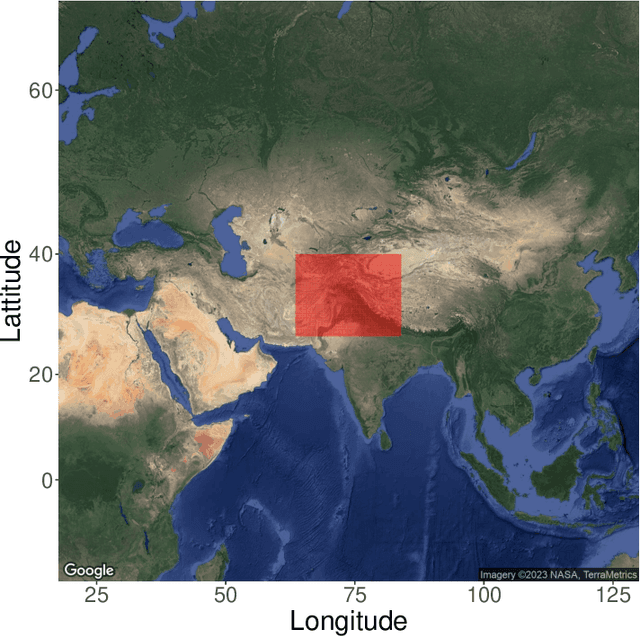
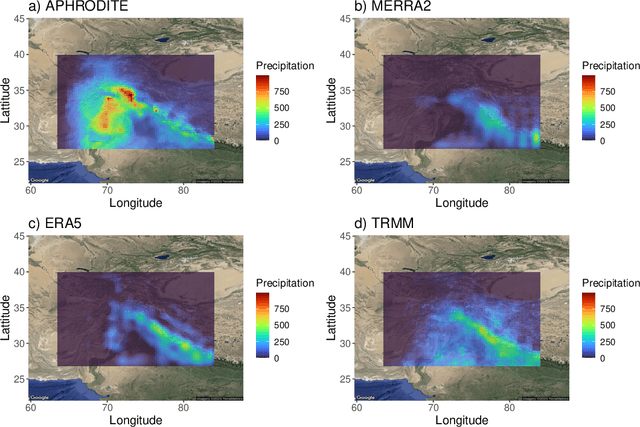
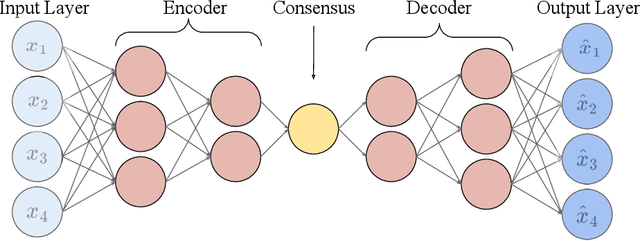
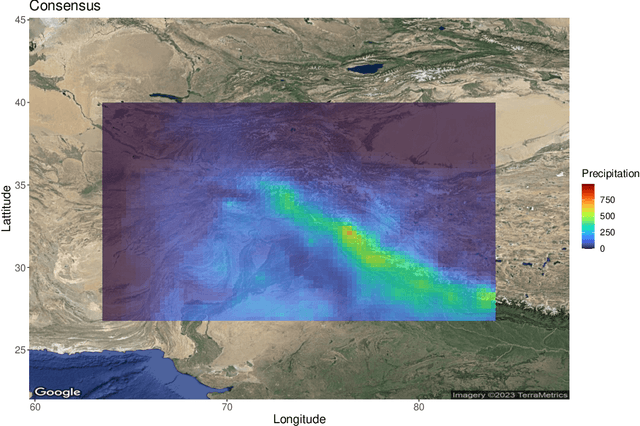
Autoencoders are powerful machine learning models used to compress information from multiple data sources. However, autoencoders, like all artificial neural networks, are often unidentifiable and uninterpretable. This research focuses on creating an identifiable and interpretable autoencoder that can be used to meld and combine climate data products. The proposed autoencoder utilizes a Bayesian statistical framework, allowing for probabilistic interpretations while also varying spatially to capture useful spatial patterns across the various data products. Constraints are placed on the autoencoder as it learns patterns in the data, creating an interpretable consensus that includes the important features from each input. We demonstrate the utility of the autoencoder by combining information from multiple precipitation products in High Mountain Asia.
Emergency Response Inference Mapping (ERIMap): A Bayesian Network-based Method for Dynamic Observation Processing in Spatially Distributed Emergencies
Mar 11, 2024

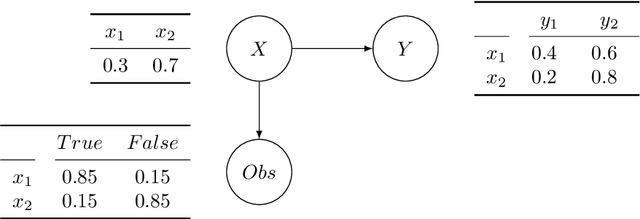

In emergencies, high stake decisions often have to be made under time pressure and strain. In order to support such decisions, information from various sources needs to be collected and processed rapidly. The information available tends to be temporally and spatially variable, uncertain, and sometimes conflicting, leading to potential biases in decisions. Currently, there is a lack of systematic approaches for information processing and situation assessment which meet the particular demands of emergency situations. To address this gap, we present a Bayesian network-based method called ERIMap that is tailored to the complex information-scape during emergencies. The method enables the systematic and rapid processing of heterogeneous and potentially uncertain observations and draws inferences about key variables of an emergency. It thereby reduces complexity and cognitive load for decision makers. The output of the ERIMap method is a dynamically evolving and spatially resolved map of beliefs about key variables of an emergency that is updated each time a new observation becomes available. The method is illustrated in a case study in which an emergency response is triggered by an accident causing a gas leakage on a chemical plant site.
LLMvsSmall Model? Large Language Model Based Text Augmentation Enhanced Personality Detection Model
Mar 12, 2024
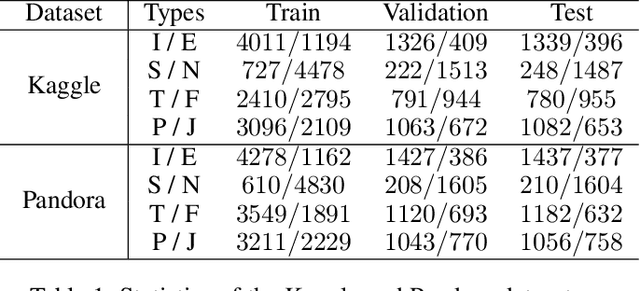
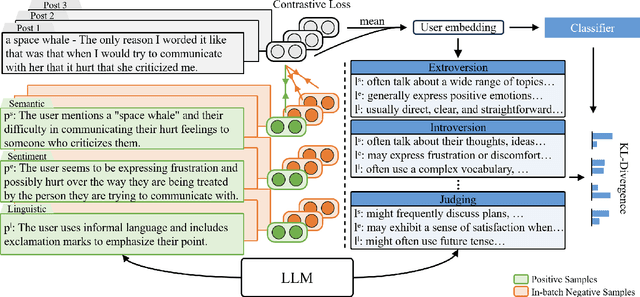
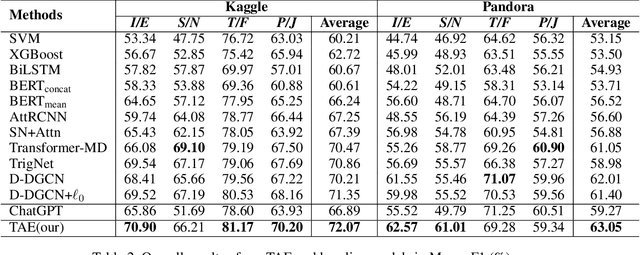
Personality detection aims to detect one's personality traits underlying in social media posts. One challenge of this task is the scarcity of ground-truth personality traits which are collected from self-report questionnaires. Most existing methods learn post features directly by fine-tuning the pre-trained language models under the supervision of limited personality labels. This leads to inferior quality of post features and consequently affects the performance. In addition, they treat personality traits as one-hot classification labels, overlooking the semantic information within them. In this paper, we propose a large language model (LLM) based text augmentation enhanced personality detection model, which distills the LLM's knowledge to enhance the small model for personality detection, even when the LLM fails in this task. Specifically, we enable LLM to generate post analyses (augmentations) from the aspects of semantic, sentiment, and linguistic, which are critical for personality detection. By using contrastive learning to pull them together in the embedding space, the post encoder can better capture the psycho-linguistic information within the post representations, thus improving personality detection. Furthermore, we utilize the LLM to enrich the information of personality labels for enhancing the detection performance. Experimental results on the benchmark datasets demonstrate that our model outperforms the state-of-the-art methods on personality detection.
A Scalable and Parallelizable Digital Twin Framework for Sustainable Sim2Real Transition of Multi-Agent Reinforcement Learning Systems
Mar 16, 2024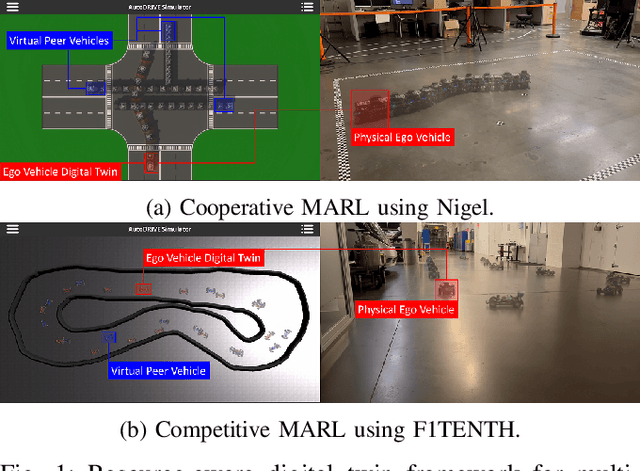
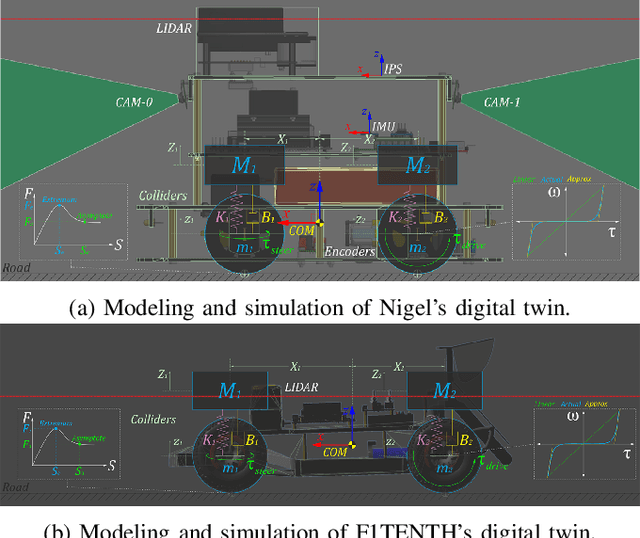


This work presents a sustainable multi-agent deep reinforcement learning framework capable of selectively scaling parallelized training workloads on-demand, and transferring the trained policies from simulation to reality using minimal hardware resources. We introduce AutoDRIVE Ecosystem as an enabling digital twin framework to train, deploy, and transfer cooperative as well as competitive multi-agent reinforcement learning policies from simulation to reality. Particularly, we first investigate an intersection traversal problem of 4 cooperative vehicles (Nigel) that share limited state information in single as well as multi-agent learning settings using a common policy approach. We then investigate an adversarial autonomous racing problem of 2 vehicles (F1TENTH) using an individual policy approach. In either set of experiments, a decentralized learning architecture was adopted, which allowed robust training and testing of the policies in stochastic environments. The agents were provided with realistically sparse observation spaces, and were restricted to sample control actions that implicitly satisfied the imposed kinodynamic and safety constraints. The experimental results for both problem statements are reported in terms of quantitative metrics and qualitative remarks for training as well as deployment phases. We also discuss agent and environment parallelization techniques adopted to efficiently accelerate MARL training, while analyzing their computational performance. Finally, we demonstrate a resource-aware transition of the trained policies from simulation to reality using the proposed digital twin framework.
Depression Detection on Social Media with Large Language Models
Mar 16, 2024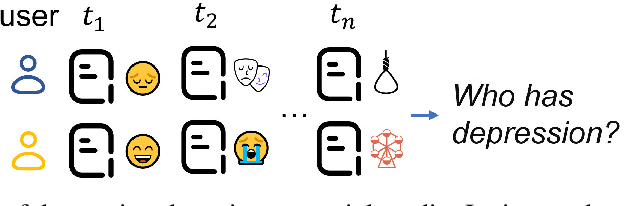
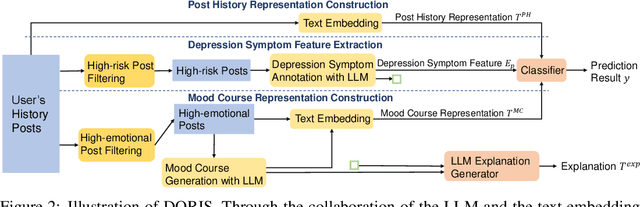
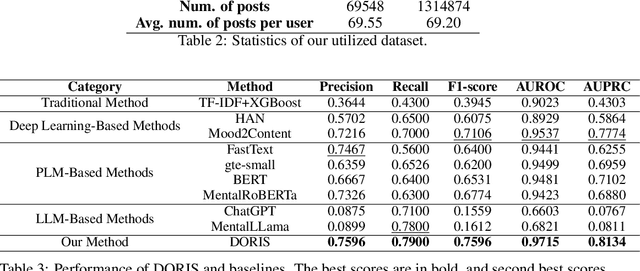
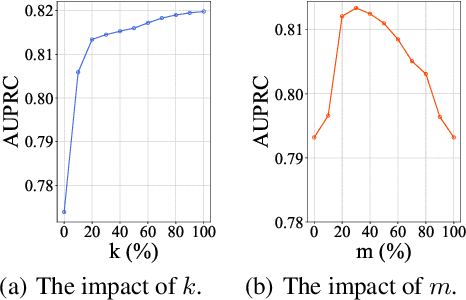
Depression harms. However, due to a lack of mental health awareness and fear of stigma, many patients do not actively seek diagnosis and treatment, leading to detrimental outcomes. Depression detection aims to determine whether an individual suffers from depression by analyzing their history of posts on social media, which can significantly aid in early detection and intervention. It mainly faces two key challenges: 1) it requires professional medical knowledge, and 2) it necessitates both high accuracy and explainability. To address it, we propose a novel depression detection system called DORIS, combining medical knowledge and the recent advances in large language models (LLMs). Specifically, to tackle the first challenge, we proposed an LLM-based solution to first annotate whether high-risk texts meet medical diagnostic criteria. Further, we retrieve texts with high emotional intensity and summarize critical information from the historical mood records of users, so-called mood courses. To tackle the second challenge, we combine LLM and traditional classifiers to integrate medical knowledge-guided features, for which the model can also explain its prediction results, achieving both high accuracy and explainability. Extensive experimental results on benchmarking datasets show that, compared to the current best baseline, our approach improves by 0.036 in AUPRC, which can be considered significant, demonstrating the effectiveness of our approach and its high value as an NLP application.
Identifying Optimal Launch Sites of High-Altitude Latex-Balloons using Bayesian Optimisation for the Task of Station-Keeping
Mar 16, 2024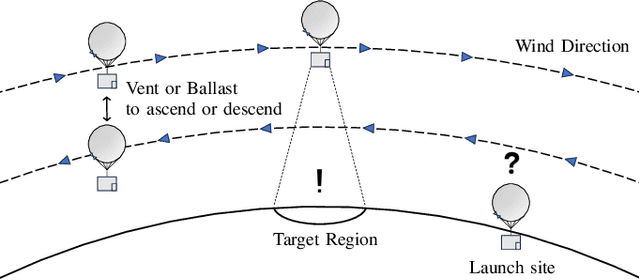
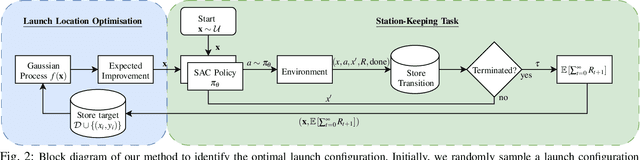
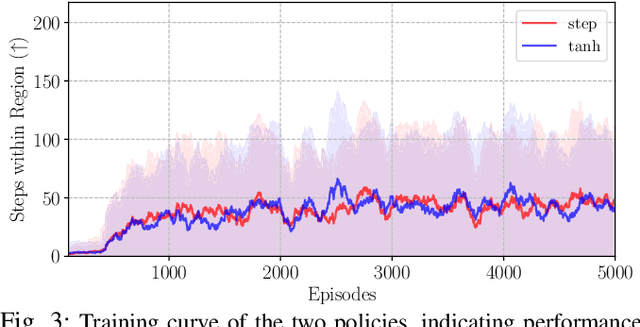
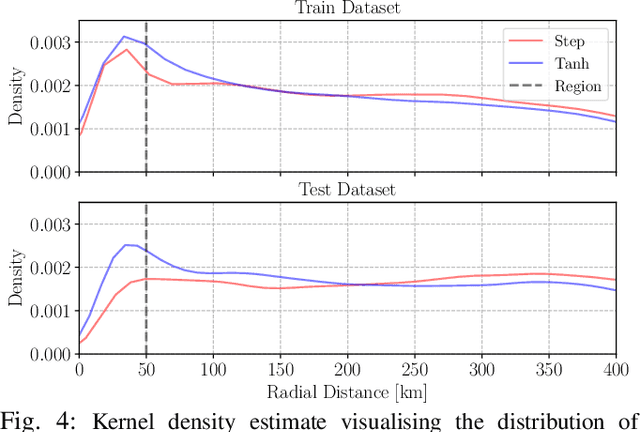
Station-keeping tasks for high-altitude balloons show promise in areas such as ecological surveys, atmospheric analysis, and communication relays. However, identifying the optimal time and position to launch a latex high-altitude balloon is still a challenging and multifaceted problem. For example, tasks such as forest fire tracking place geometric constraints on the launch location of the balloon. Furthermore, identifying the most optimal location also heavily depends on atmospheric conditions. We first illustrate how reinforcement learning-based controllers, frequently used for station-keeping tasks, can exploit the environment. This exploitation can degrade performance on unseen weather patterns and affect station-keeping performance when identifying an optimal launch configuration. Valuing all states equally in the region, the agent exploits the region's geometry by flying near the edge, leading to risky behaviours. We propose a modification which compensates for this exploitation and finds this leads to, on average, higher steps within the target region on unseen data. Then, we illustrate how Bayesian Optimisation (BO) can identify the optimal launch location to perform station-keeping tasks, maximising the expected undiscounted return from a given rollout. We show BO can find this launch location in fewer steps compared to other optimisation methods. Results indicate that, surprisingly, the most optimal location to launch from is not commonly within the target region. Please find further information about our project at https://sites.google.com/view/bo-lauch-balloon/.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024
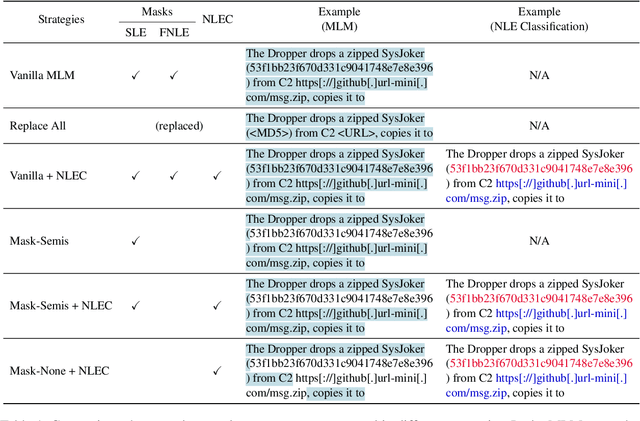
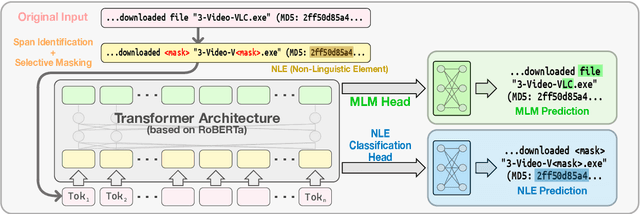
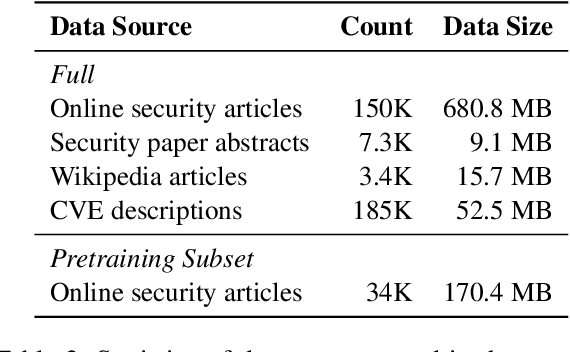
Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.