 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ConTEXTual Net: A Multimodal Vision-Language Model for Segmentation of Pneumothorax
Mar 02, 2023
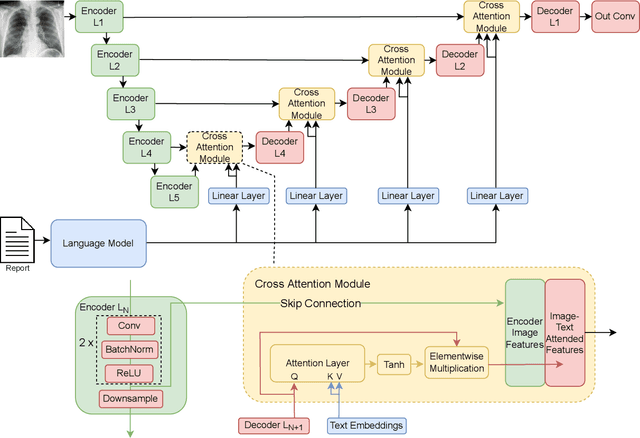
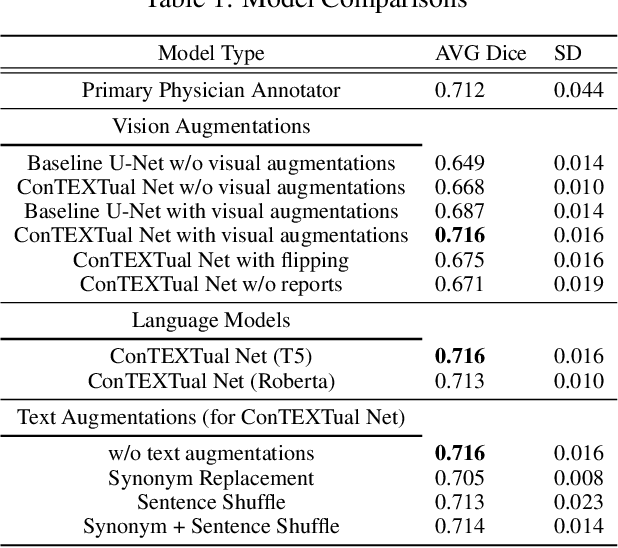
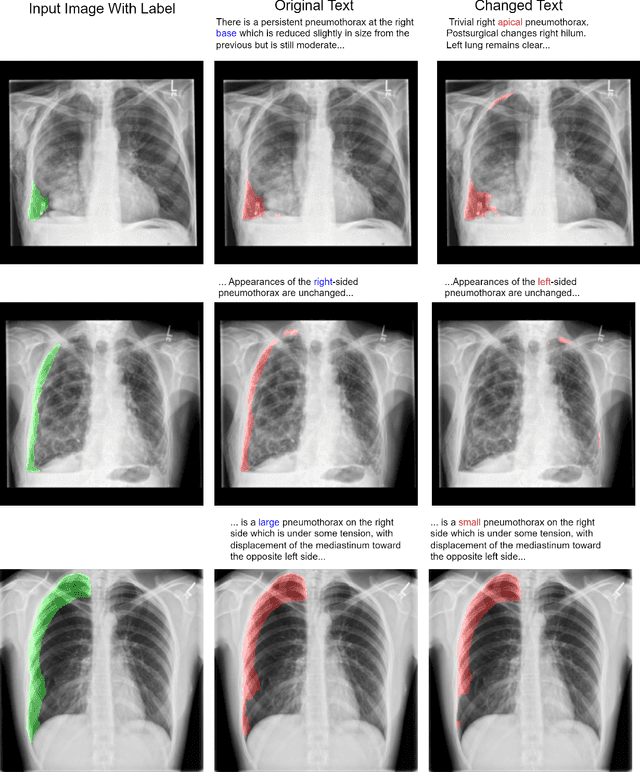
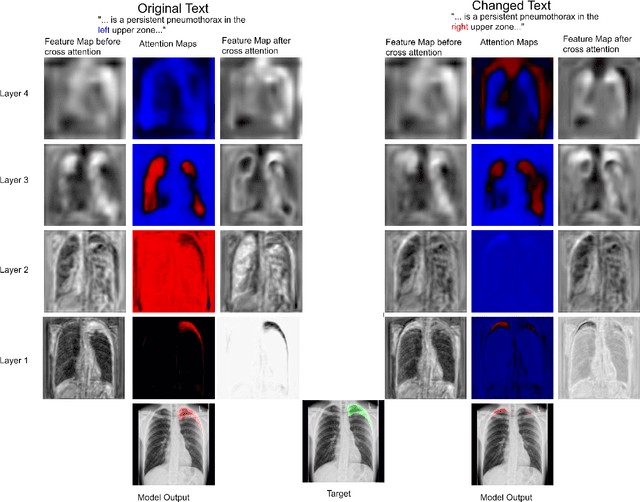
Clinical imaging databases contain not only medical images but also text reports generated by physicians. These narrative reports often describe the location, size, and shape of the disease, but using descriptive text to guide medical image analysis has been understudied. Vision-language models are increasingly used for multimodal tasks like image generation, image captioning, and visual question answering but have been scarcely used in medical imaging. In this work, we develop a vision-language model for the task of pneumothorax segmentation. Our model, ConTEXTual Net, detects and segments pneumothorax in chest radiographs guided by free-form radiology reports. ConTEXTual Net achieved a Dice score of 0.72 $\pm$ 0.02, which was similar to the level of agreement between the primary physician annotator and the other physician annotators (0.71 $\pm$ 0.04). ConTEXTual Net also outperformed a U-Net. We demonstrate that descriptive language can be incorporated into a segmentation model for improved performance. Through an ablative study, we show that it is the text information that is responsible for the performance gains. Additionally, we show that certain augmentation methods worsen ConTEXTual Net's segmentation performance by breaking the image-text concordance. We propose a set of augmentations that maintain this concordance and improve segmentation training.
CREDENCE: Counterfactual Explanations for Document Ranking
Feb 10, 2023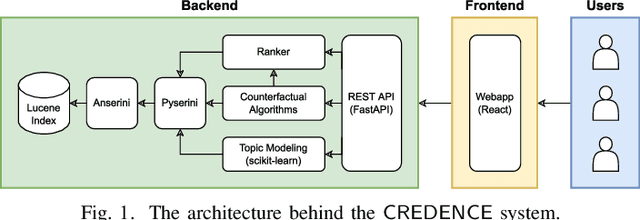
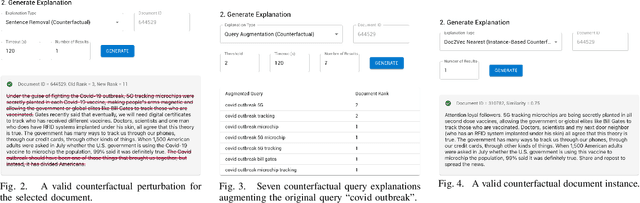
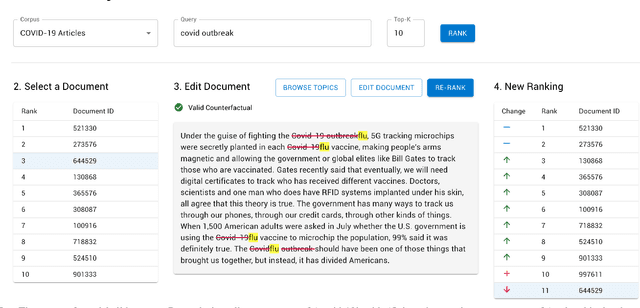
Towards better explainability in the field of information retrieval, we present CREDENCE, an interactive tool capable of generating counterfactual explanations for document rankers. Embracing the unique properties of the ranking problem, we present counterfactual explanations in terms of document perturbations, query perturbations, and even other documents. Additionally, users may build and test their own perturbations, and extract insights about their query, documents, and ranker.
ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots
Feb 08, 2023

Conversational AI and Question-Answering systems (QASs) for knowledge graphs (KGs) are both emerging research areas: they empower users with natural language interfaces for extracting information easily and effectively. Conversational AI simulates conversations with humans; however, it is limited by the data captured in the training datasets. In contrast, QASs retrieve the most recent information from a KG by understanding and translating the natural language question into a formal query supported by the database engine. In this paper, we present a comprehensive study of the characteristics of the existing alternatives towards combining both worlds into novel KG chatbots. Our framework compares two representative conversational models, ChatGPT and Galactica, against KGQAN, the current state-of-the-art QAS. We conduct a thorough evaluation using four real KGs across various application domains to identify the current limitations of each category of systems. Based on our findings, we propose open research opportunities to empower QASs with chatbot capabilities for KGs. All benchmarks and all raw results are available1 for further analysis.
Combining Variational Autoencoders and Physical Bias for Improved Microscopy Data Analysis
Feb 08, 2023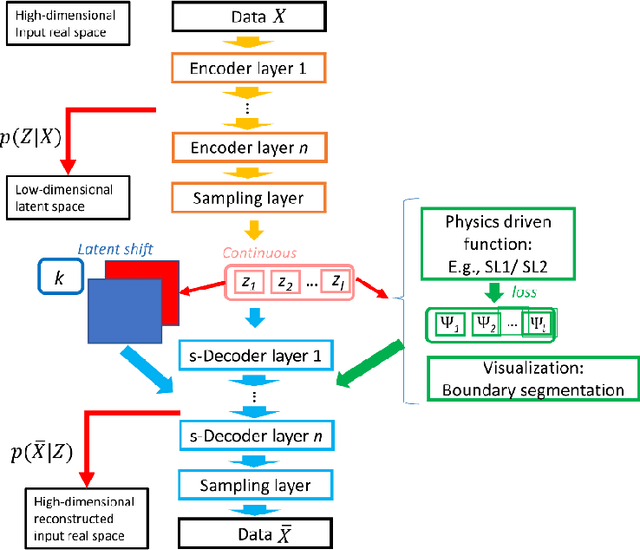

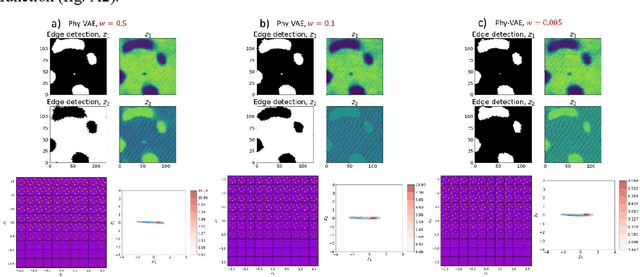
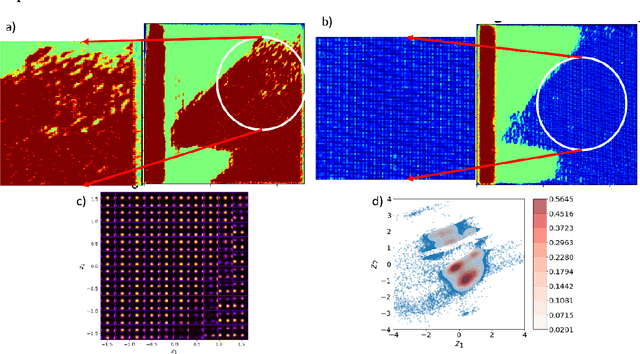
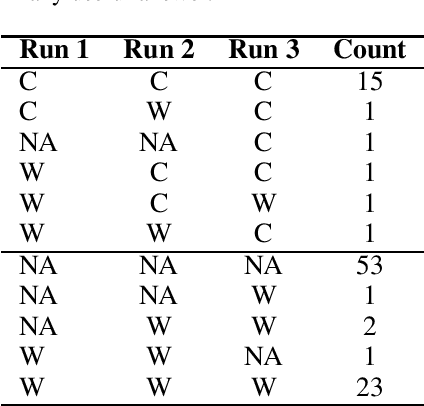
Electron and scanning probe microscopy produce vast amounts of data in the form of images or hyperspectral data, such as EELS or 4D STEM, that contain information on a wide range of structural, physical, and chemical properties of materials. To extract valuable insights from these data, it is crucial to identify physically separate regions in the data, such as phases, ferroic variants, and boundaries between them. In order to derive an easily interpretable feature analysis, combining with well-defined boundaries in a principled and unsupervised manner, here we present a physics augmented machine learning method which combines the capability of Variational Autoencoders to disentangle factors of variability within the data and the physics driven loss function that seeks to minimize the total length of the discontinuities in images corresponding to latent representations. Our method is applied to various materials, including NiO-LSMO, BiFeO3, and graphene. The results demonstrate the effectiveness of our approach in extracting meaningful information from large volumes of imaging data. The fully notebook containing implementation of the code and analysis workflow is available at https://github.com/arpanbiswas52/PaperNotebooks
Prompting for Multimodal Hateful Meme Classification
Feb 08, 2023
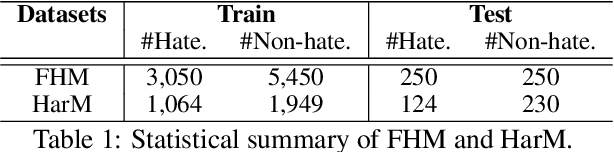

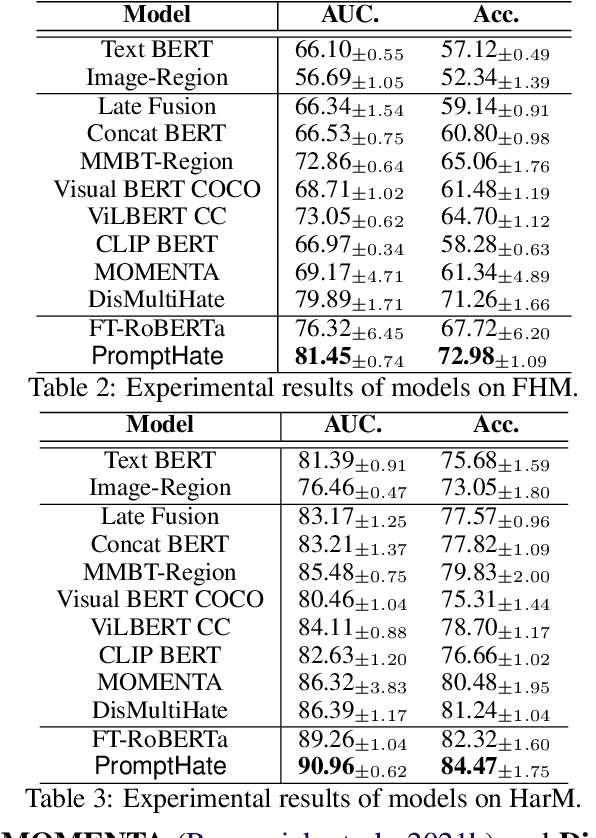
Hateful meme classification is a challenging multimodal task that requires complex reasoning and contextual background knowledge. Ideally, we could leverage an explicit external knowledge base to supplement contextual and cultural information in hateful memes. However, there is no known explicit external knowledge base that could provide such hate speech contextual information. To address this gap, we propose PromptHate, a simple yet effective prompt-based model that prompts pre-trained language models (PLMs) for hateful meme classification. Specifically, we construct simple prompts and provide a few in-context examples to exploit the implicit knowledge in the pre-trained RoBERTa language model for hateful meme classification. We conduct extensive experiments on two publicly available hateful and offensive meme datasets. Our experimental results show that PromptHate is able to achieve a high AUC of 90.96, outperforming state-of-the-art baselines on the hateful meme classification task. We also perform fine-grained analyses and case studies on various prompt settings and demonstrate the effectiveness of the prompts on hateful meme classification.
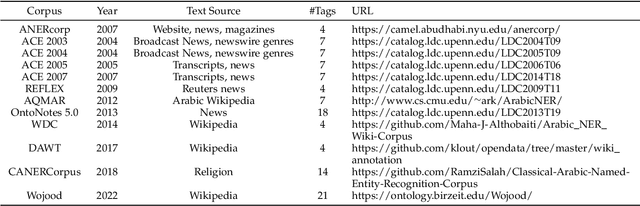
A Survey on Arabic Named Entity Recognition: Past, Recent Advances, and Future Trends
Feb 08, 2023


As more and more Arabic texts emerged on the Internet, extracting important information from these Arabic texts is especially useful. As a fundamental technology, Named entity recognition (NER) serves as the core component in information extraction technology, while also playing a critical role in many other Natural Language Processing (NLP) systems, such as question answering and knowledge graph building. In this paper, we provide a comprehensive review of the development of Arabic NER, especially the recent advances in deep learning and pre-trained language model. Specifically, we first introduce the background of Arabic NER, including the characteristics of Arabic and existing resources for Arabic NER. Then, we systematically review the development of Arabic NER methods. Traditional Arabic NER systems focus on feature engineering and designing domain-specific rules. In recent years, deep learning methods achieve significant progress by representing texts via continuous vector representations. With the growth of pre-trained language model, Arabic NER yields better performance. Finally, we conclude the method gap between Arabic NER and NER methods from other languages, which helps outline future directions for Arabic NER.
Neuronal architecture extracts statistical temporal patterns
Jan 24, 2023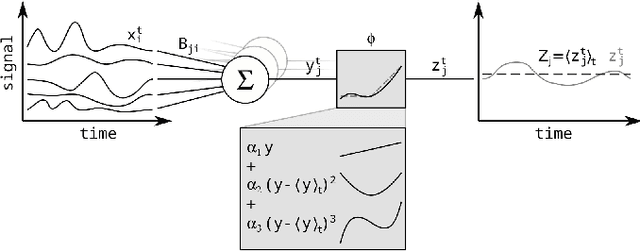
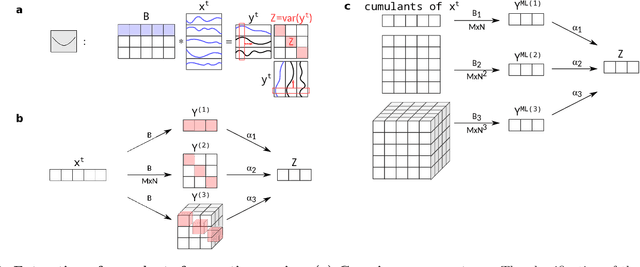
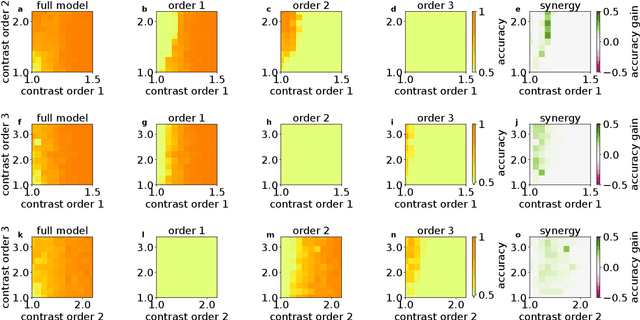
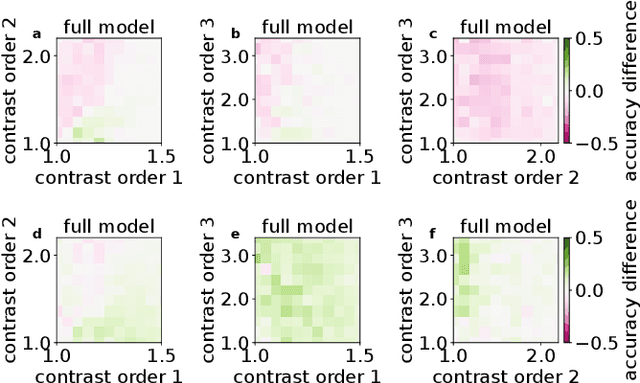
Neuronal systems need to process temporal signals. We here show how higher-order temporal (co-)fluctuations can be employed to represent and process information. Concretely, we demonstrate that a simple biologically inspired feedforward neuronal model is able to extract information from up to the third order cumulant to perform time series classification. This model relies on a weighted linear summation of synaptic inputs followed by a nonlinear gain function. Training both - the synaptic weights and the nonlinear gain function - exposes how the non-linearity allows for the transfer of higher order correlations to the mean, which in turn enables the synergistic use of information encoded in multiple cumulants to maximize the classification accuracy. The approach is demonstrated both on a synthetic and on real world datasets of multivariate time series. Moreover, we show that the biologically inspired architecture makes better use of the number of trainable parameters as compared to a classical machine-learning scheme. Our findings emphasize the benefit of biological neuronal architectures, paired with dedicated learning algorithms, for the processing of information embedded in higher-order statistical cumulants of temporal (co-)fluctuations.
New Insights on Relieving Task-Recency Bias for Online Class Incremental Learning
Feb 16, 2023
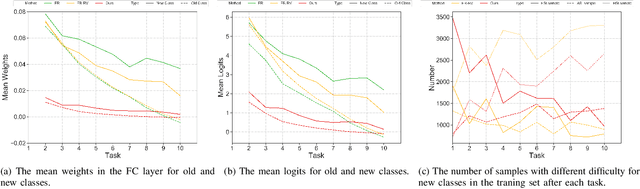
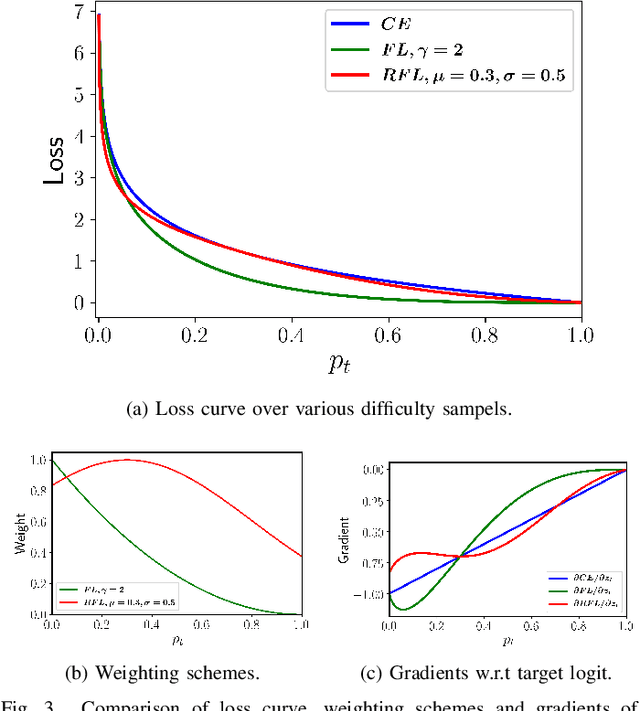
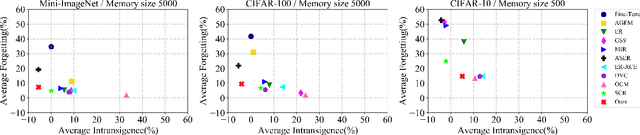
To imitate the ability of keeping learning of human, continual learning which can learn from a never-ending data stream has attracted more interests recently. In all settings, the online class incremental learning (CIL), where incoming samples from data stream can be used only once, is more challenging and can be encountered more frequently in real world. Actually, the CIL faces a stability-plasticity dilemma, where the stability means the ability to preserve old knowledge while the plasticity denotes the ability to incorporate new knowledge. Although replay-based methods have shown exceptional promise, most of them concentrate on the strategy for updating and retrieving memory to keep stability at the expense of plasticity. To strike a preferable trade-off between stability and plasticity, we propose a Adaptive Focus Shifting algorithm (AFS), which dynamically adjusts focus to ambiguous samples and non-target logits in model learning. Through a deep analysis of the task-recency bias caused by class imbalance, we propose a revised focal loss to mainly keep stability. By utilizing a new weight function, the revised focal loss can pay more attention to current ambiguous samples, which can provide more information of the classification boundary. To promote plasticity, we introduce a virtual knowledge distillation. By designing a virtual teacher, it assigns more attention to non-target classes, which can surmount overconfidence and encourage model to focus on inter-class information. Extensive experiments on three popular datasets for CIL have shown the effectiveness of AFS. The code will be available at \url{https://github.com/czjghost/AFS}.
Achieving Covert Communication in Large-Scale SWIPT-Enabled D2D Networks
Feb 16, 2023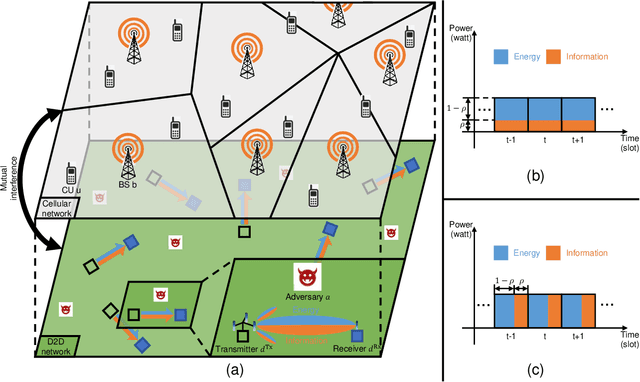
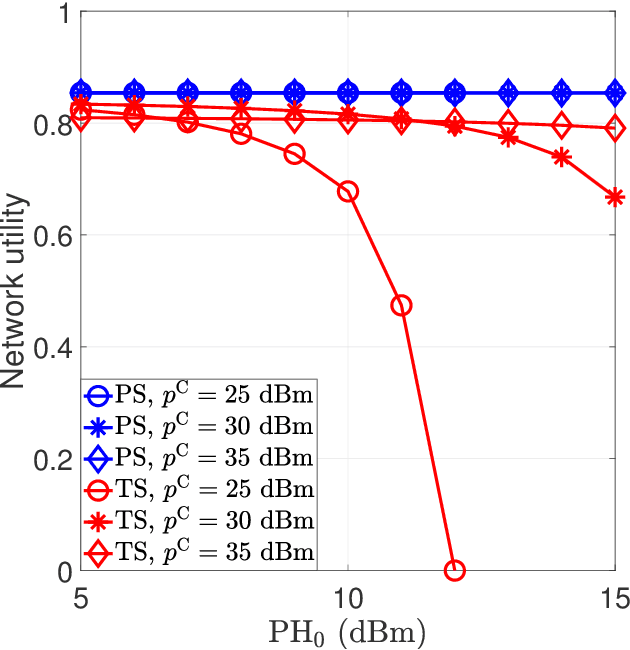
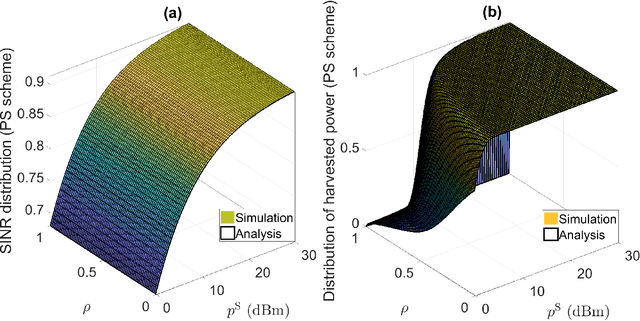
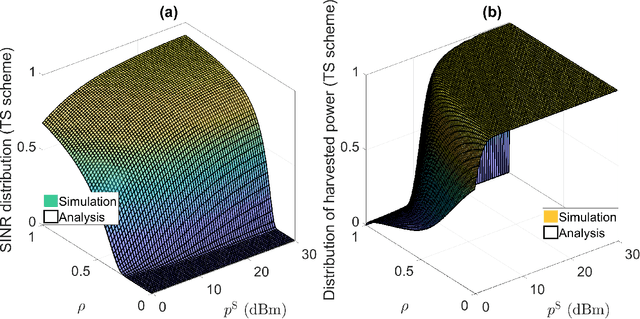
We aim to secure a large-scale device-to-device (D2D) network against adversaries. The D2D network underlays a downlink cellular network to reuse the cellular spectrum and is enabled for simultaneous wireless information and power transfer (SWIPT). In the D2D network, the transmitters communicate with the receivers, and the receivers extract information and energy from their received radio-frequency (RF) signals. In the meantime, the adversaries aim to detect the D2D transmission. The D2D network applies power control and leverages the cellular signal to achieve covert communication (i.e., hide the presence of transmissions) so as to defend against the adversaries. We model the interaction between the D2D network and adversaries by using a two-stage Stackelberg game. Therein, the adversaries are the followers minimizing their detection errors at the lower stage and the D2D network is the leader maximizing its network utility constrained by the communication covertness and power outage at the upper stage. Both power splitting (PS)-based and time switch (TS)-based SWIPT schemes are explored. We characterize the spatial configuration of the large-scale D2D network, adversaries, and cellular network by stochastic geometry. We analyze the adversary's detection error minimization problem and adopt the Rosenbrock method to solve it, where the obtained solution is the best response from the lower stage. Taking into account the best response from the lower stage, we develop a bi-level algorithm to solve the D2D network's constrained network utility maximization problem and obtain the Stackelberg equilibrium. We present numerical results to reveal interesting insights.
Do PAC-Learners Learn the Marginal Distribution?
Feb 13, 2023We study a foundational variant of Valiant and Vapnik and Chervonenkis' Probably Approximately Correct (PAC)-Learning in which the adversary is restricted to a known family of marginal distributions $\mathscr{P}$. In particular, we study how the PAC-learnability of a triple $(\mathscr{P},X,H)$ relates to the learners ability to infer \emph{distributional} information about the adversary's choice of $D \in \mathscr{P}$. To this end, we introduce the `unsupervised' notion of \emph{TV-Learning}, which, given a class $(\mathscr{P},X,H)$, asks the learner to approximate $D$ from unlabeled samples with respect to a natural class-conditional total variation metric. In the classical distribution-free setting, we show that TV-learning is \emph{equivalent} to PAC-Learning: in other words, any learner must infer near-maximal information about $D$. On the other hand, we show this characterization breaks down for general $\mathscr{P}$, where PAC-Learning is strictly sandwiched between two approximate variants we call `Strong' and `Weak' TV-learning, roughly corresponding to unsupervised learners that estimate most relevant distances in $D$ with respect to $H$, but differ in whether the learner \emph{knows} the set of well-estimated events. Finally, we observe that TV-learning is in fact equivalent to the classical notion of \emph{uniform estimation}, and thereby give a strong refutation of the uniform convergence paradigm in supervised learning.