 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Common Vulnerability Scoring System Prediction based on Open Source Intelligence Information Sources
Oct 05, 2022
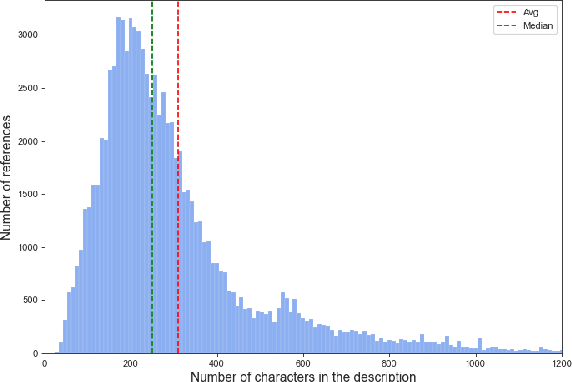
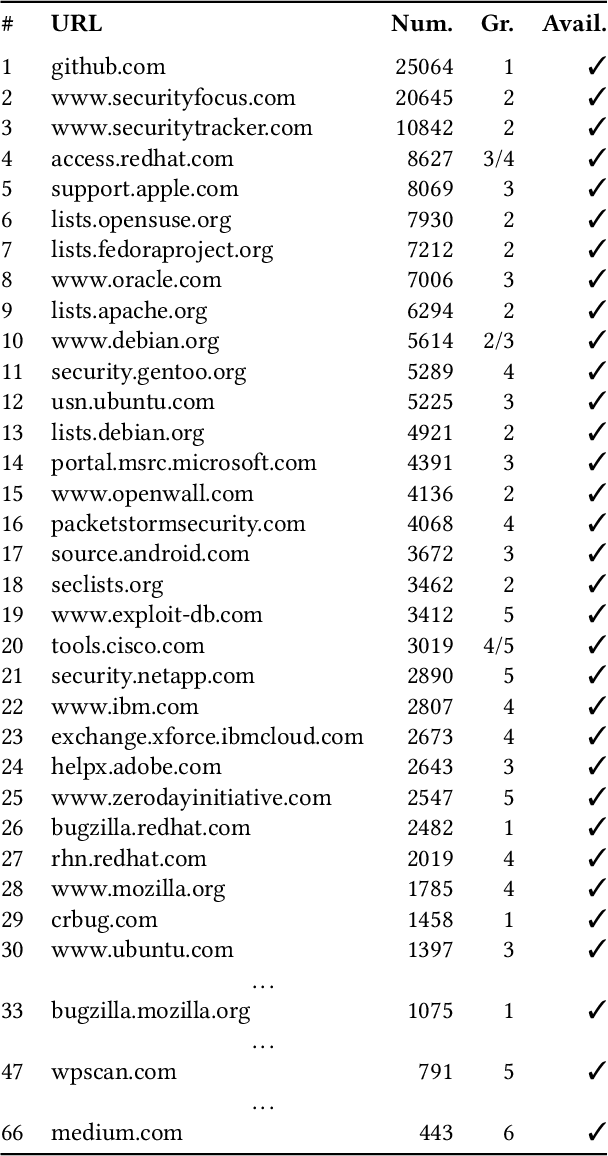
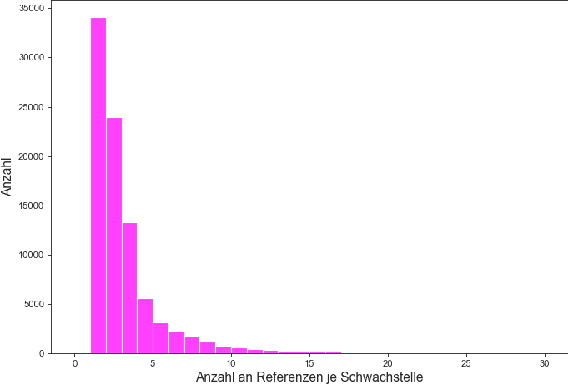
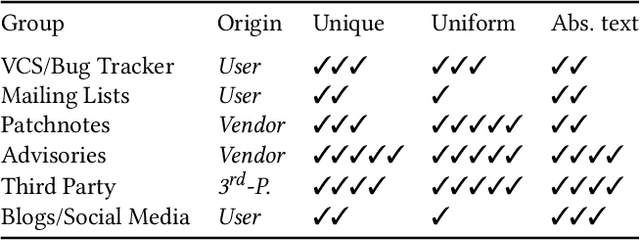
The number of newly published vulnerabilities is constantly increasing. Until now, the information available when a new vulnerability is published is manually assessed by experts using a Common Vulnerability Scoring System (CVSS) vector and score. This assessment is time consuming and requires expertise. Various works already try to predict CVSS vectors or scores using machine learning based on the textual descriptions of the vulnerability to enable faster assessment. However, for this purpose, previous works only use the texts available in databases such as National Vulnerability Database. With this work, the publicly available web pages referenced in the National Vulnerability Database are analyzed and made available as sources of texts through web scraping. A Deep Learning based method for predicting the CVSS vector is implemented and evaluated. The present work provides a classification of the National Vulnerability Database's reference texts based on the suitability and crawlability of their texts. While we identified the overall influence of the additional texts is negligible, we outperformed the state-of-the-art with our Deep Learning prediction models.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 10, 2023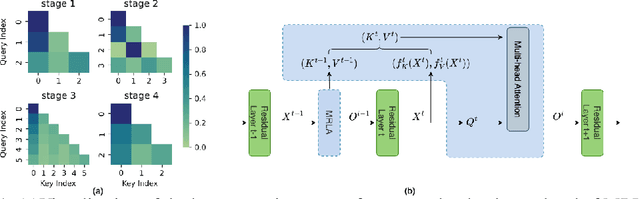
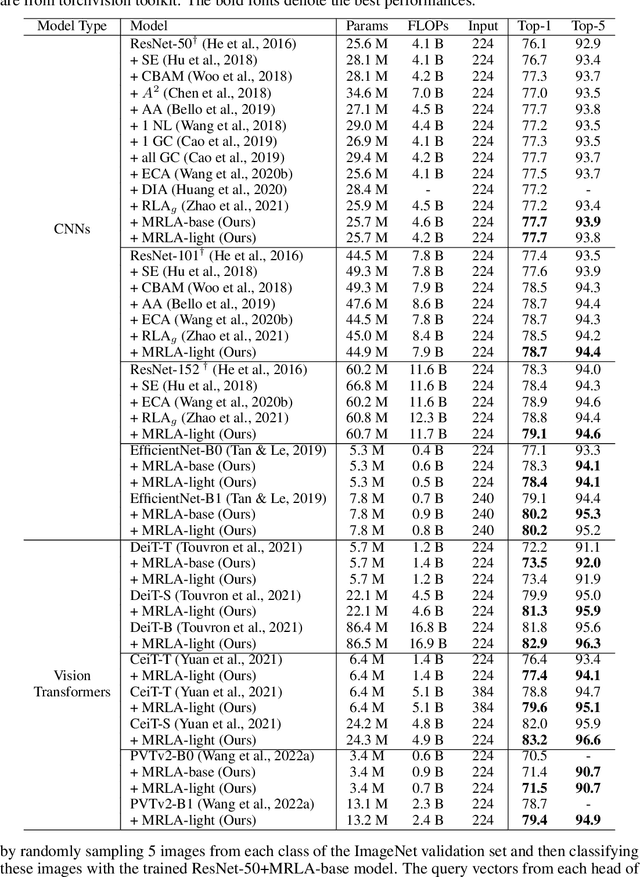
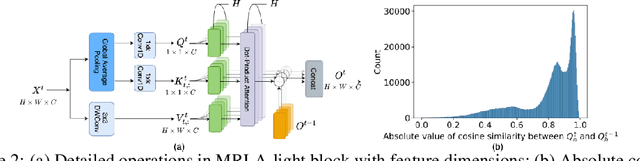
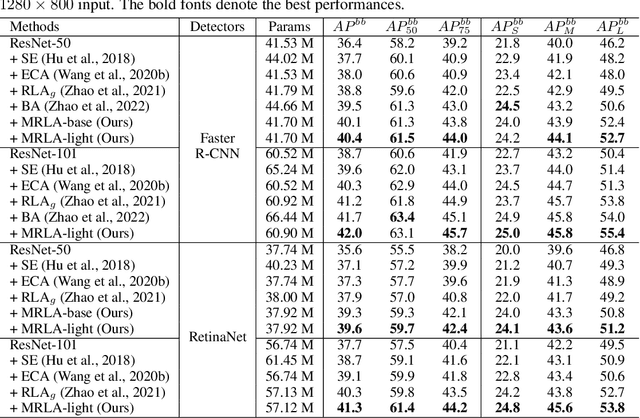
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Age of Information in Federated Learning over Wireless Networks
Sep 14, 2022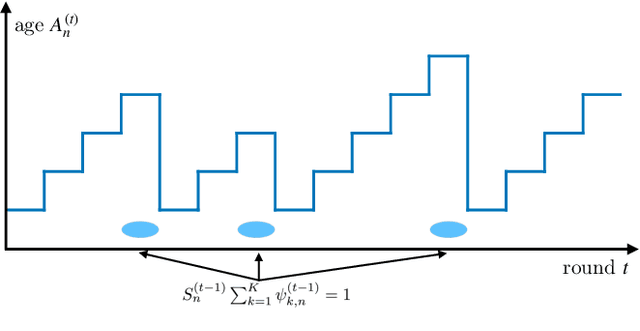
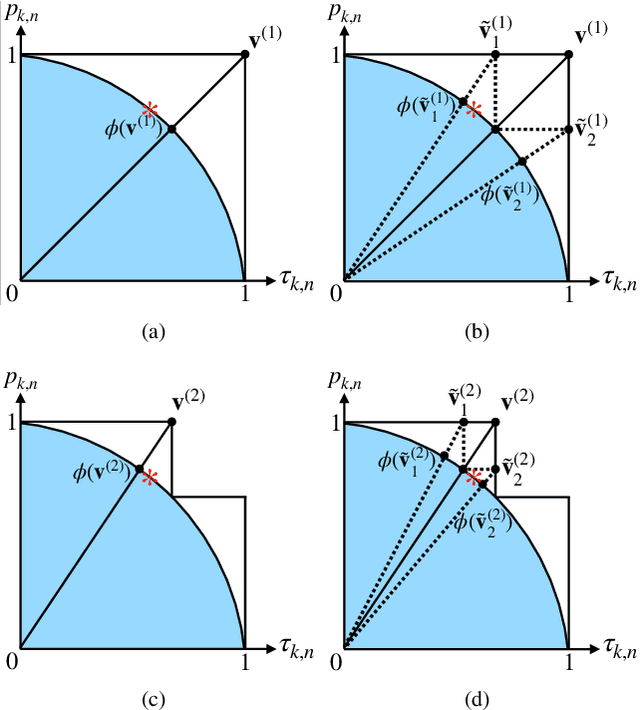
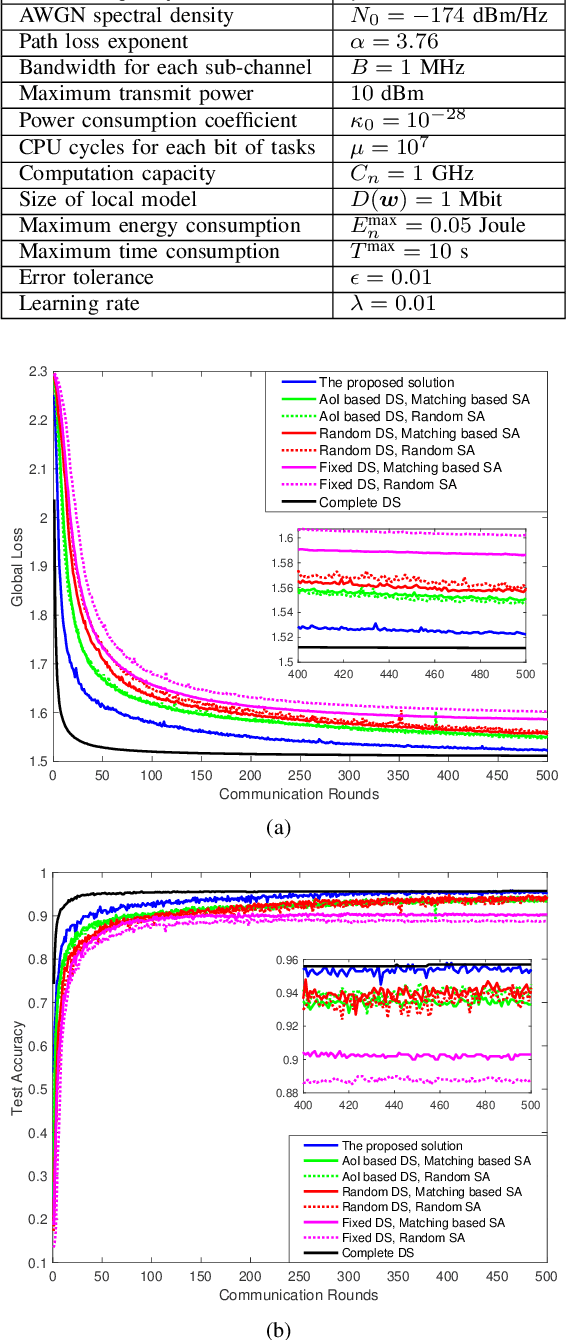
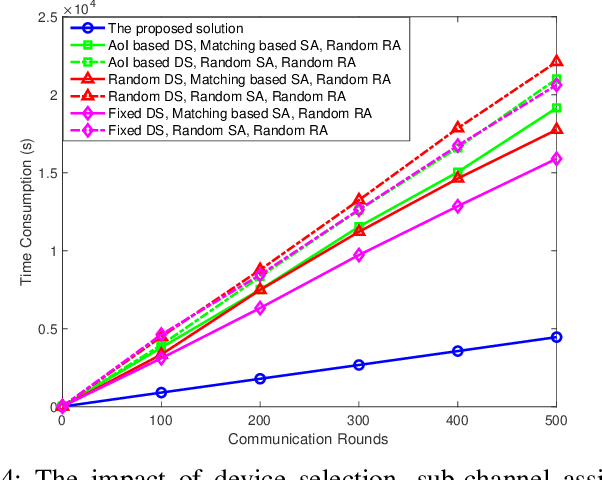
In this paper, federated learning (FL) over wireless networks is investigated. In each communication round, a subset of devices is selected to participate in the aggregation with limited time and energy. In order to minimize the convergence time, global loss and latency are jointly considered in a Stackelberg game based framework. Specifically, age of information (AoI) based device selection is considered at leader-level as a global loss minimization problem, while sub-channel assignment, computational resource allocation, and power allocation are considered at follower-level as a latency minimization problem. By dividing the follower-level problem into two sub-problems, the best response of the follower is obtained by a monotonic optimization based resource allocation algorithm and a matching based sub-channel assignment algorithm. By deriving the upper bound of convergence rate, the leader-level problem is reformulated, and then a list based device selection algorithm is proposed to achieve Stackelberg equilibrium. Simulation results indicate that the proposed device selection scheme outperforms other schemes in terms of the global loss, and the developed algorithms can significantly decrease the time consumption of computation and communication.
HairStep: Transfer Synthetic to Real Using Strand and Depth Maps for Single-View 3D Hair Modeling
Mar 05, 2023
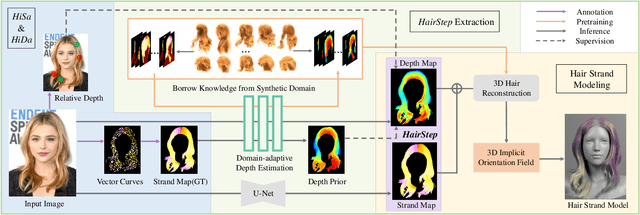
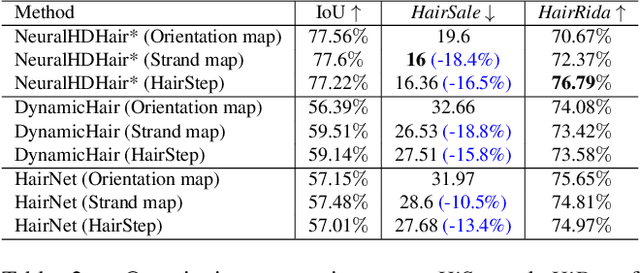

In this work, we tackle the challenging problem of learning-based single-view 3D hair modeling. Due to the great difficulty of collecting paired real image and 3D hair data, using synthetic data to provide prior knowledge for real domain becomes a leading solution. This unfortunately introduces the challenge of domain gap. Due to the inherent difficulty of realistic hair rendering, existing methods typically use orientation maps instead of hair images as input to bridge the gap. We firmly think an intermediate representation is essential, but we argue that orientation map using the dominant filtering-based methods is sensitive to uncertain noise and far from a competent representation. Thus, we first raise this issue up and propose a novel intermediate representation, termed as HairStep, which consists of a strand map and a depth map. It is found that HairStep not only provides sufficient information for accurate 3D hair modeling, but also is feasible to be inferred from real images. Specifically, we collect a dataset of 1,250 portrait images with two types of annotations. A learning framework is further designed to transfer real images to the strand map and depth map. It is noted that, an extra bonus of our new dataset is the first quantitative metric for 3D hair modeling. Our experiments show that HairStep narrows the domain gap between synthetic and real and achieves state-of-the-art performance on single-view 3D hair reconstruction.
HSIC-InfoGAN: Learning Unsupervised Disentangled Representations by Maximising Approximated Mutual Information
Aug 06, 2022
Learning disentangled representations requires either supervision or the introduction of specific model designs and learning constraints as biases. InfoGAN is a popular disentanglement framework that learns unsupervised disentangled representations by maximising the mutual information between latent representations and their corresponding generated images. Maximisation of mutual information is achieved by introducing an auxiliary network and training with a latent regression loss. In this short exploratory paper, we study the use of the Hilbert-Schmidt Independence Criterion (HSIC) to approximate mutual information between latent representation and image, termed HSIC-InfoGAN. Directly optimising the HSIC loss avoids the need for an additional auxiliary network. We qualitatively compare the level of disentanglement in each model, suggest a strategy to tune the hyperparameters of HSIC-InfoGAN, and discuss the potential of HSIC-InfoGAN for medical applications.
Information FOMO: The unhealthy fear of missing out on information. A method for removing misleading data for healthier models
Aug 27, 2022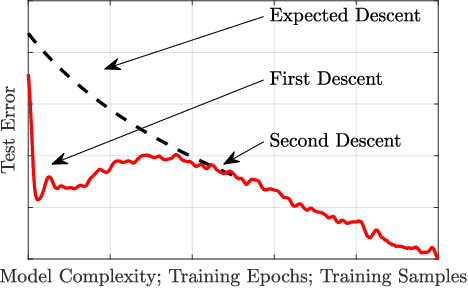
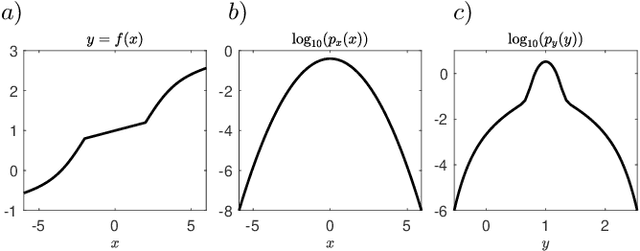
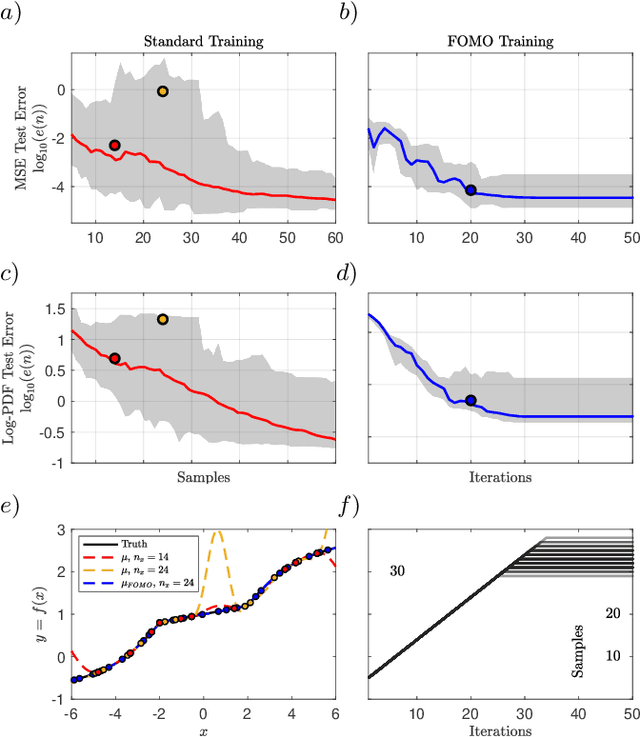
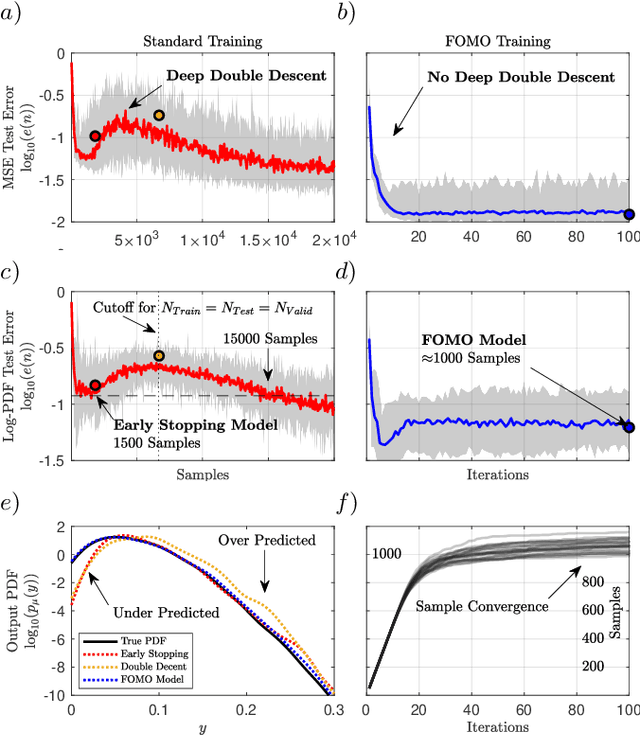
Not all data are equal. Misleading or unnecessary data can critically hinder the accuracy of Machine Learning (ML) models. When data is plentiful, misleading effects can be overcome, but in many real-world applications data is sparse and expensive to acquire. We present a method that substantially reduces the data size necessary to accurately train ML models, potentially opening the door for many new, limited-data applications in ML. Our method extracts the most informative data, while ignoring and omitting data that misleads the ML model to inferior generalization properties. Specifically, the method eliminates the phenomena of "double descent", where more data leads to worse performance. This approach brings several key features to the ML community. Notably, the method naturally converges and removes the traditional need to divide the dataset into training, testing, and validation data. Instead, the selection metric inherently assesses testing error. This ensures that key information is never wasted in testing or validation.
GRAN: Ghost Residual Attention Network for Single Image Super Resolution
Mar 02, 2023
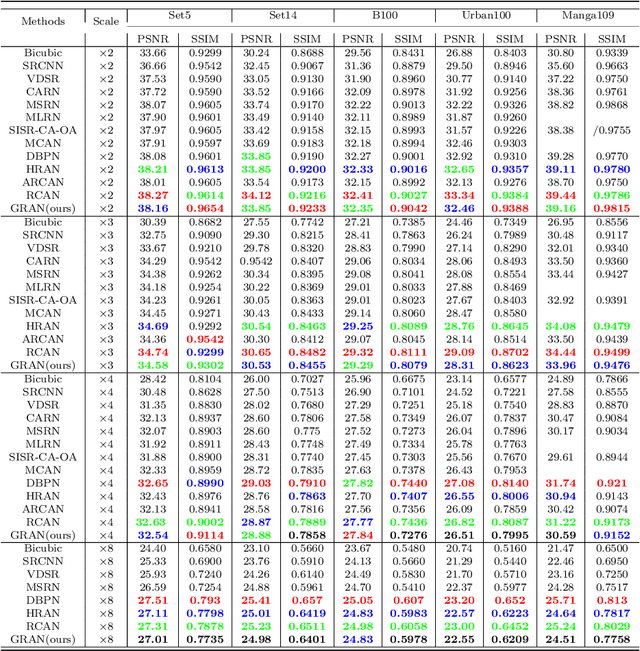
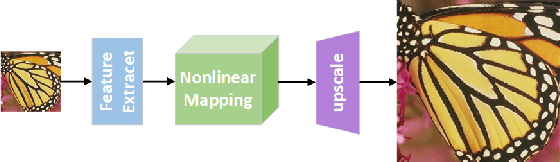

Recently, many works have designed wider and deeper networks to achieve higher image super-resolution performance. Despite their outstanding performance, they still suffer from high computational resources, preventing them from directly applying to embedded devices. To reduce the computation resources and maintain performance, we propose a novel Ghost Residual Attention Network (GRAN) for efficient super-resolution. This paper introduces Ghost Residual Attention Block (GRAB) groups to overcome the drawbacks of the standard convolutional operation, i.e., redundancy of the intermediate feature. GRAB consists of the Ghost Module and Channel and Spatial Attention Module (CSAM) to alleviate the generation of redundant features. Specifically, Ghost Module can reveal information underlying intrinsic features by employing linear operations to replace the standard convolutions. Reducing redundant features by the Ghost Module, our model decreases memory and computing resource requirements in the network. The CSAM pays more comprehensive attention to where and what the feature extraction is, which is critical to recovering the image details. Experiments conducted on the benchmark datasets demonstrate the superior performance of our method in both qualitative and quantitative. Compared to the baseline models, we achieve higher performance with lower computational resources, whose parameters and FLOPs have decreased by more than ten times.
LANDMARK: Language-guided Representation Enhancement Framework for Scene Graph Generation
Mar 02, 2023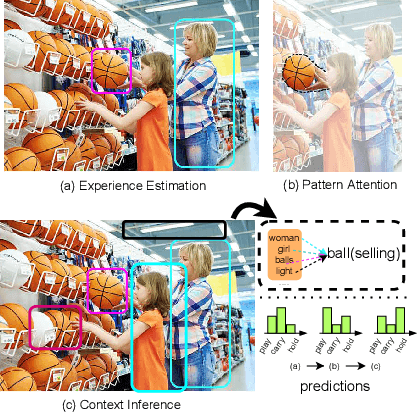
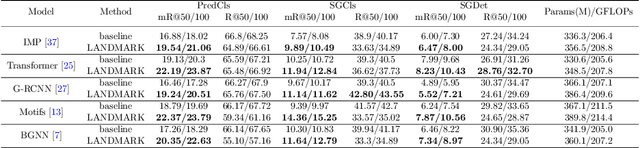
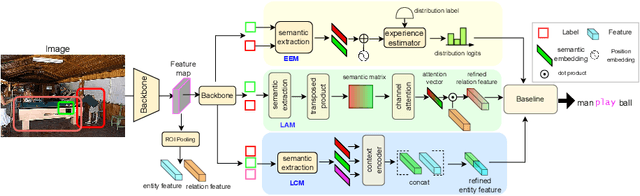
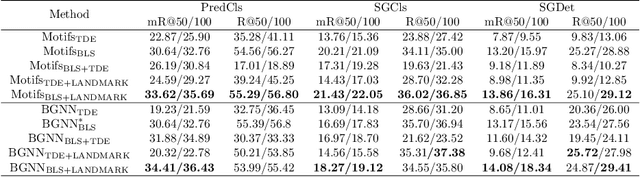
Scene graph generation (SGG) is a sophisticated task that suffers from both complex visual features and dataset long-tail problem. Recently, various unbiased strategies have been proposed by designing novel loss functions and data balancing strategies. Unfortunately, these unbiased methods fail to emphasize language priors in feature refinement perspective. Inspired by the fact that predicates are highly correlated with semantics hidden in subject-object pair and global context, we propose LANDMARK (LANguage-guiDed representationenhanceMent frAmewoRK) that learns predicate-relevant representations from language-vision interactive patterns, global language context and pair-predicate correlation. Specifically, we first project object labels to three distinctive semantic embeddings for different representation learning. Then, Language Attention Module (LAM) and Experience Estimation Module (EEM) process subject-object word embeddings to attention vector and predicate distribution, respectively. Language Context Module (LCM) encodes global context from each word embed-ding, which avoids isolated learning from local information. Finally, modules outputs are used to update visual representations and SGG model's prediction. All language representations are purely generated from object categories so that no extra knowledge is needed. This framework is model-agnostic and consistently improves performance on existing SGG models. Besides, representation-level unbiased strategies endow LANDMARK the advantage of compatibility with other methods. Code is available at https://github.com/rafa-cxg/PySGG-cxg.
Image as Set of Points
Mar 02, 2023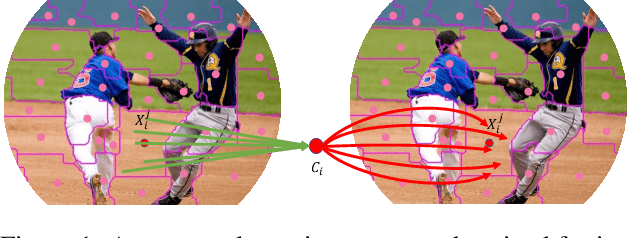
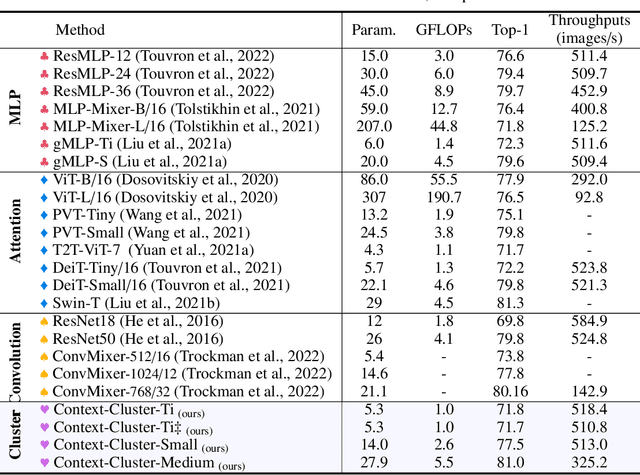
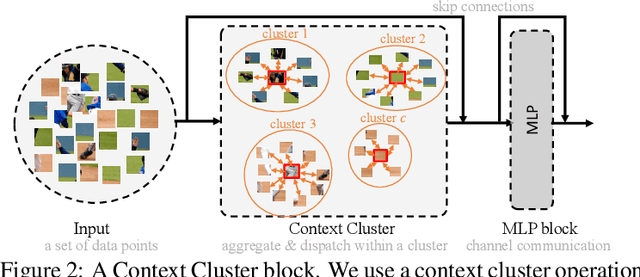
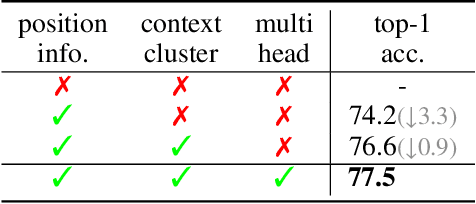
What is an image and how to extract latent features? Convolutional Networks (ConvNets) consider an image as organized pixels in a rectangular shape and extract features via convolutional operation in local region; Vision Transformers (ViTs) treat an image as a sequence of patches and extract features via attention mechanism in a global range. In this work, we introduce a straightforward and promising paradigm for visual representation, which is called Context Clusters. Context clusters (CoCs) view an image as a set of unorganized points and extract features via simplified clustering algorithm. In detail, each point includes the raw feature (e.g., color) and positional information (e.g., coordinates), and a simplified clustering algorithm is employed to group and extract deep features hierarchically. Our CoCs are convolution- and attention-free, and only rely on clustering algorithm for spatial interaction. Owing to the simple design, we show CoCs endow gratifying interpretability via the visualization of clustering process. Our CoCs aim at providing a new perspective on image and visual representation, which may enjoy broad applications in different domains and exhibit profound insights. Even though we are not targeting SOTA performance, COCs still achieve comparable or even better results than ConvNets or ViTs on several benchmarks. Codes are available at: https://github.com/ma-xu/Context-Cluster.
Evaluation of drain, a deep-learning approach to rain retrieval from gpm passive microwave radiometer
Mar 02, 2023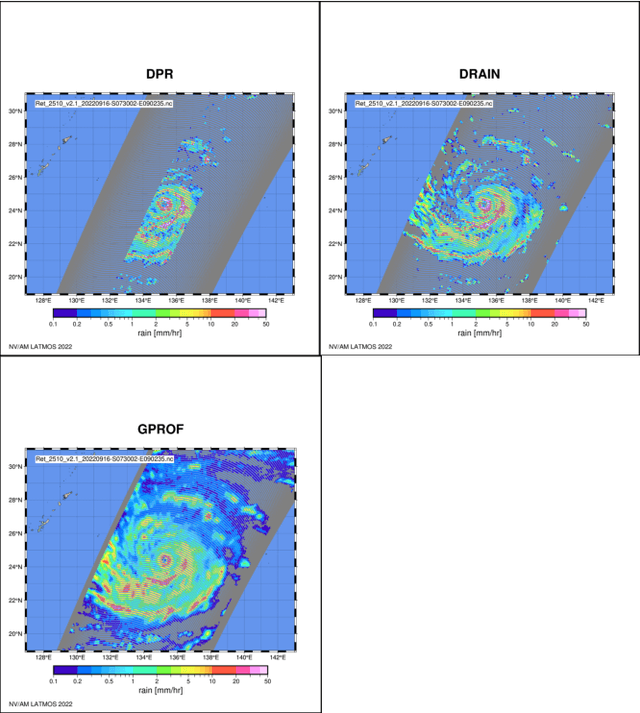
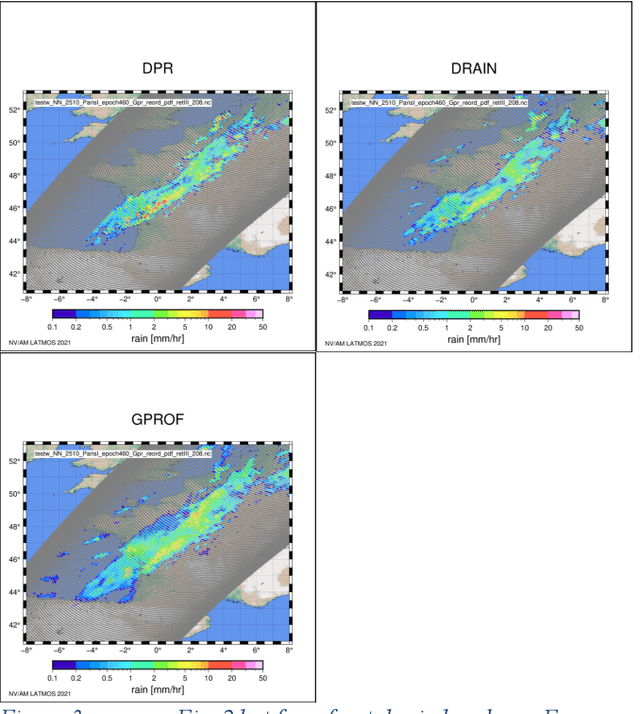
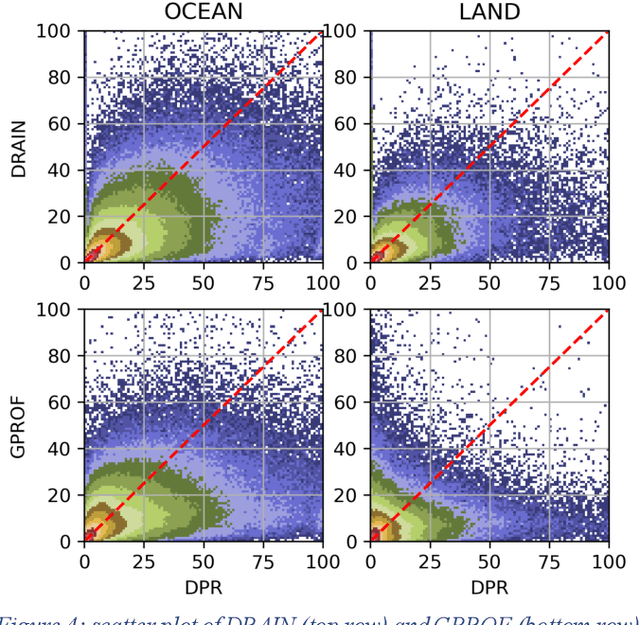
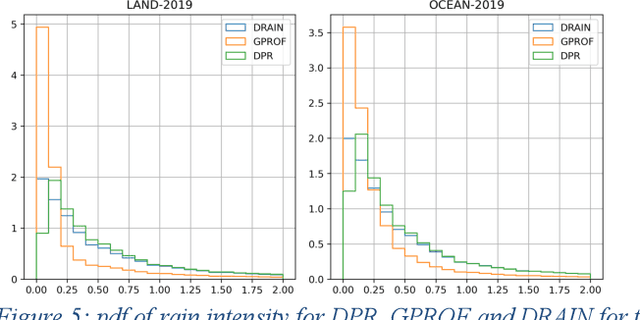
Retrieval of rain from Passive Microwave radiometers data has been a challenge ever since the launch of the first Defense Meteorological Satellite Program in the late 70s. Enormous progress has been made since the launch of the Tropical Rainfall Measuring Mission (TRMM) in 1997 but until recently the data were processed pixel-by-pixel or taking a few neighboring pixels into account. Deep learning has obtained remarkable improvement in the computer vision field, and offers a whole new way to tackle the rain retrieval problem. The Global Precipitation Measurement (GPM) Core satellite carries similarly to TRMM, a passive microwave radiometer and a radar that share part of their swath. The brightness temperatures measured in the 37 and 89 GHz channels are used like the RGB components of a regular image while rain rate from Dual Frequency radar provides the surface rain. A U-net is then trained on these data to develop a retrieval algorithm: Deep-learning RAIN (DRAIN). With only four brightness temperatures as an input and no other a priori information, DRAIN is offering similar or slightly better performances than GPROF, the GPM official algorithm, in most situations. These performances are assumed to be due to the fact that DRAIN works on an image basis instead of the classical pixel-by-pixel basis.