 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Mar 01, 2023
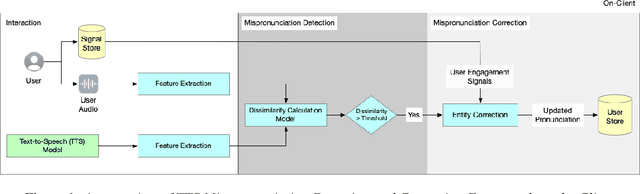
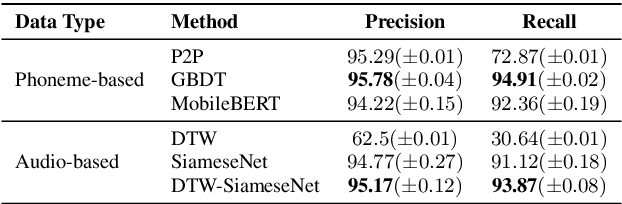

Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.
TAU: A Framework for Video-Based Traffic Analytics Leveraging Artificial Intelligence and Unmanned Aerial Systems
Mar 01, 2023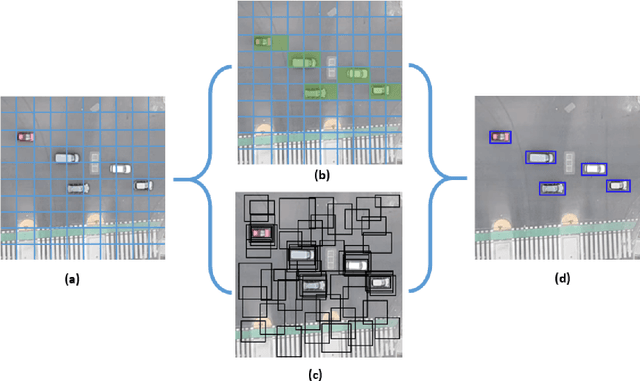

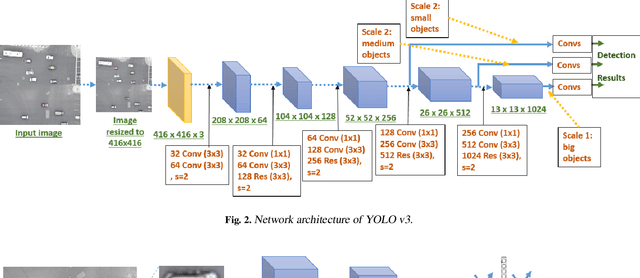

Smart traffic engineering and intelligent transportation services are in increasing demand from governmental authorities to optimize traffic performance and thus reduce energy costs, increase the drivers' safety and comfort, ensure traffic laws enforcement, and detect traffic violations. In this paper, we address this challenge, and we leverage the use of Artificial Intelligence (AI) and Unmanned Aerial Vehicles (UAVs) to develop an AI-integrated video analytics framework, called TAU (Traffic Analysis from UAVs), for automated traffic analytics and understanding. Unlike previous works on traffic video analytics, we propose an automated object detection and tracking pipeline from video processing to advanced traffic understanding using high-resolution UAV images. TAU combines six main contributions. First, it proposes a pre-processing algorithm to adapt the high-resolution UAV image as input to the object detector without lowering the resolution. This ensures an excellent detection accuracy from high-quality features, particularly the small size of detected objects from UAV images. Second, it introduces an algorithm for recalibrating the vehicle coordinates to ensure that vehicles are uniquely identified and tracked across the multiple crops of the same frame. Third, it presents a speed calculation algorithm based on accumulating information from successive frames. Fourth, TAU counts the number of vehicles per traffic zone based on the Ray Tracing algorithm. Fifth, TAU has a fully independent algorithm for crossroad arbitration based on the data gathered from the different zones surrounding it. Sixth, TAU introduces a set of algorithms for extracting twenty-four types of insights from the raw data collected. The code is shared here: https://github.com/bilel-bj/TAU. Video demonstrations are provided here: https://youtu.be/wXJV0H7LviU and here: https://youtu.be/kGv0gmtVEbI.
* This is the final proofread version submitted to Elsevier EAAI: please see the published version at: https://doi.org/10.1016/j.engappai.2022.105095
Representation Learning with Information Theory for COVID-19 Detection
Jul 04, 2022
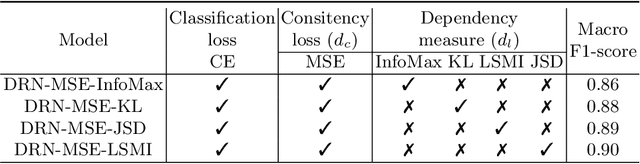
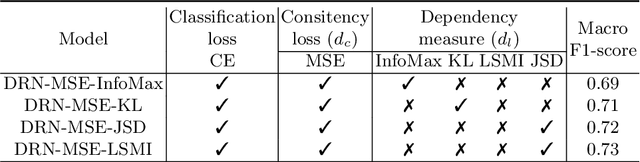
Successful data representation is a fundamental factor in machine learning based medical imaging analysis. Deep Learning (DL) has taken an essential role in robust representation learning. However, the inability of deep models to generalize to unseen data can quickly overfit intricate patterns. Thereby, we can conveniently implement strategies to aid deep models in discovering useful priors from data to learn their intrinsic properties. Our model, which we call a dual role network (DRN), uses a dependency maximization approach based on Least Squared Mutual Information (LSMI). The LSMI leverages dependency measures to ensure representation invariance and local smoothness. While prior works have used information theory measures like mutual information, known to be computationally expensive due to a density estimation step, our LSMI formulation alleviates the issues of intractable mutual information estimation and can be used to approximate it. Experiments on CT based COVID-19 Detection and COVID-19 Severity Detection benchmarks demonstrate the effectiveness of our method.
QARV: Quantization-Aware ResNet VAE for Lossy Image Compression
Feb 16, 2023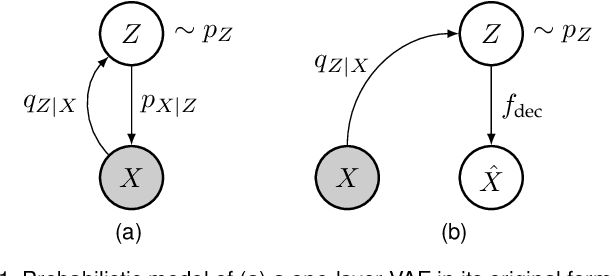
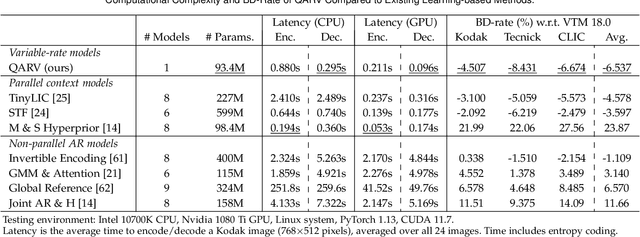

We consider the problem of lossy image compression, a fundamental problem in both information theory and many real-world applications. We begin by reviewing the relationship between variational autoencoders (VAEs), a powerful class of deep generative models, and rate-distortion theory, the theoretical foundation for lossy compression. By combining the ResNet VAE architecture and techniques including test-time quantization and quantization-aware training, we present a quantization-aware ResNet VAE (QARV) framework for lossy image compression. For sake of practical usage, we propose a new neural network architecture for fast decoding, and we introduce an adaptive normalization operation for variable-rate coding. QARV employs a hierarchical progressive coding structure, supports continuously variable-rate compression with fast entropy coding, and gives a better rate-distortion efficiency than existing baseline methods. Code is made publicly available at https://github.com/duanzhiihao/lossy-vae
Cybersecurity Challenges of Power Transformers
Feb 25, 2023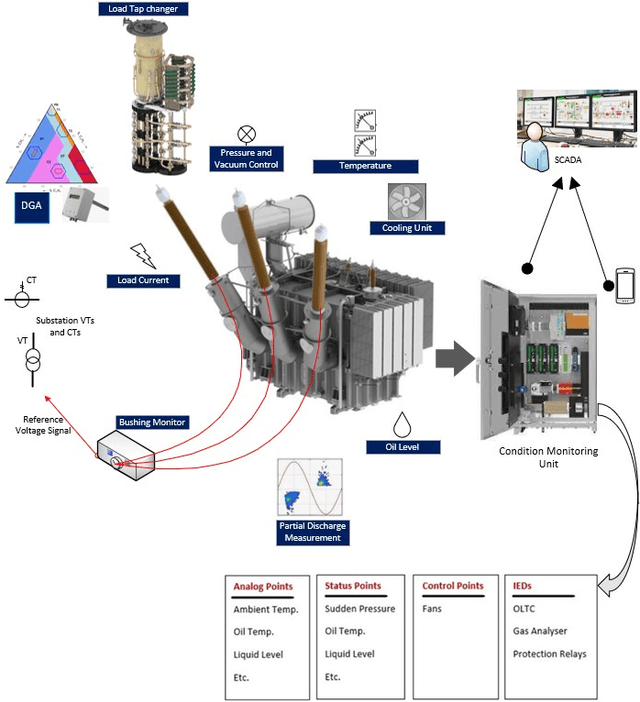
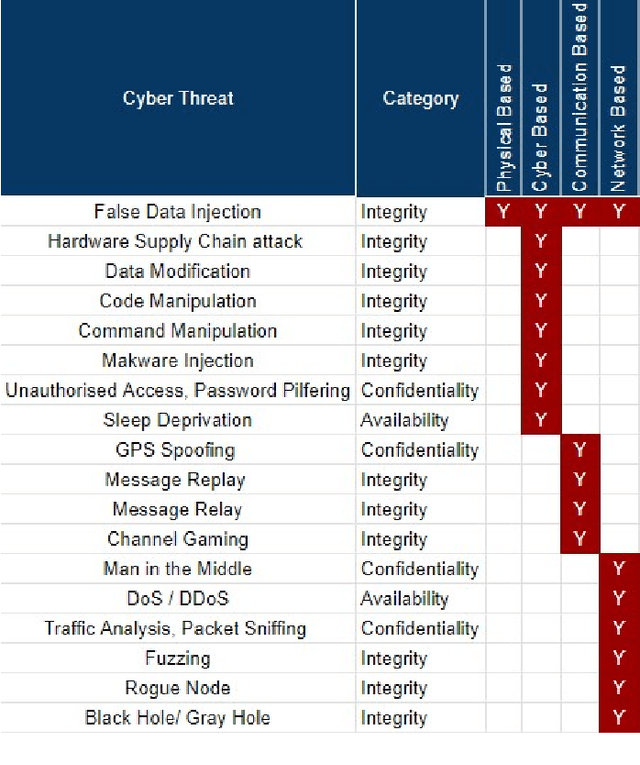
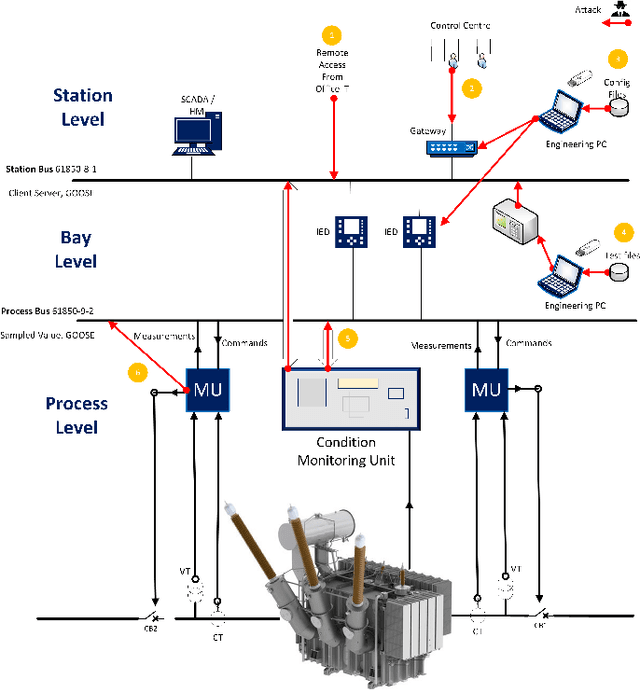
The rise of cyber threats on critical infrastructure and its potential for devastating consequences, has significantly increased. The dependency of new power grid technology on information, data analytic and communication systems make the entire electricity network vulnerable to cyber threats. Power transformers play a critical role within the power grid and are now commonly enhanced through factory add-ons or intelligent monitoring systems added later to improve the condition monitoring of critical and long lead time assets such as transformers. However, the increased connectivity of those power transformers opens the door to more cyber attacks. Therefore, the need to detect and prevent cyber threats is becoming critical. The first step towards that would be a deeper understanding of the potential cyber-attacks landscape against power transformers. Much of the existing literature pays attention to smart equipment within electricity distribution networks, and most methods proposed are based on model-based detection algorithms. Moreover, only a few of these works address the security vulnerabilities of power elements, especially transformers within the transmission network. To the best of our knowledge, there is no study in the literature that systematically investigate the cybersecurity challenges against the newly emerged smart transformers. This paper addresses this shortcoming by exploring the vulnerabilities and the attack vectors of power transformers within electricity networks, the possible attack scenarios and the risks associated with these attacks.
A Novel Collaborative Self-Supervised Learning Method for Radiomic Data
Feb 20, 2023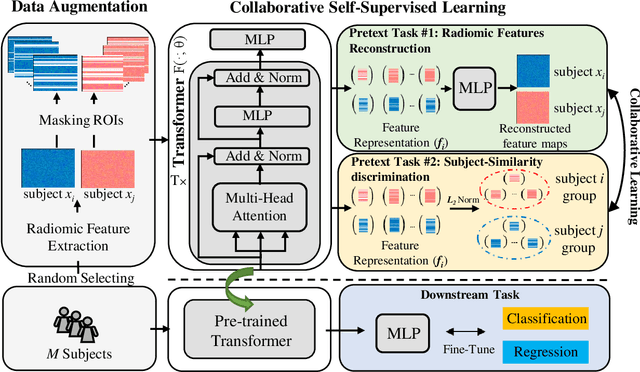
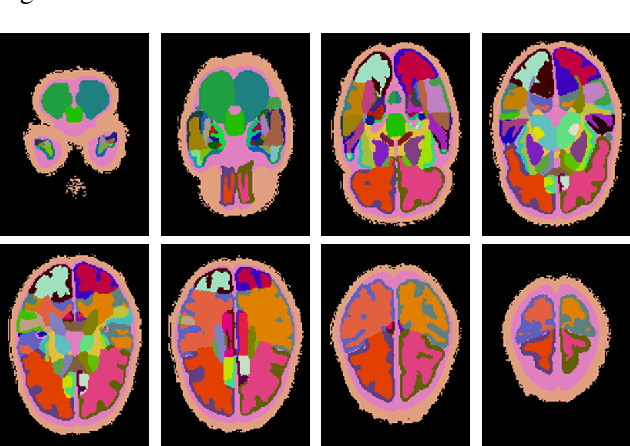
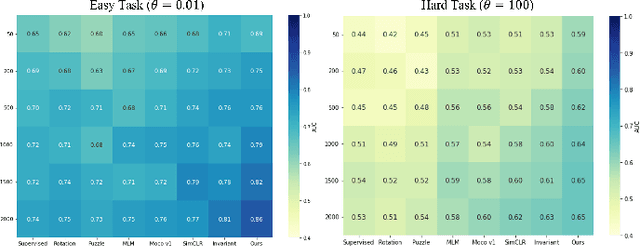
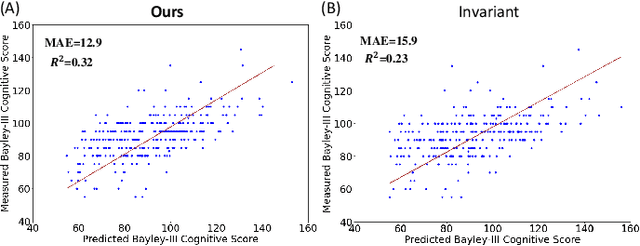
The computer-aided disease diagnosis from radiomic data is important in many medical applications. However, developing such a technique relies on annotating radiological images, which is a time-consuming, labor-intensive, and expensive process. In this work, we present the first novel collaborative self-supervised learning method to solve the challenge of insufficient labeled radiomic data, whose characteristics are different from text and image data. To achieve this, we present two collaborative pretext tasks that explore the latent pathological or biological relationships between regions of interest and the similarity and dissimilarity information between subjects. Our method collaboratively learns the robust latent feature representations from radiomic data in a self-supervised manner to reduce human annotation efforts, which benefits the disease diagnosis. We compared our proposed method with other state-of-the-art self-supervised learning methods on a simulation study and two independent datasets. Extensive experimental results demonstrated that our method outperforms other self-supervised learning methods on both classification and regression tasks. With further refinement, our method shows the potential advantage in automatic disease diagnosis with large-scale unlabeled data available.
Synergy between human and machine approaches to sound/scene recognition and processing: An overview of ICASSP special session
Feb 20, 2023Machine Listening, as usually formalized, attempts to perform a task that is, from our perspective, fundamentally human-performable, and performed by humans. Current automated models of Machine Listening vary from purely data-driven approaches to approaches imitating human systems. In recent years, the most promising approaches have been hybrid in that they have used data-driven approaches informed by models of the perceptual, cognitive, and semantic processes of the human system. Not only does the guidance provided by models of human perception and domain knowledge enable better, and more generalizable Machine Listening, in the converse, the lessons learned from these models may be used to verify or improve our models of human perception themselves. This paper summarizes advances in the development of such hybrid approaches, ranging from Machine Listening models that are informed by models of peripheral (human) auditory processes, to those that employ or derive semantic information encoded in relations between sounds. The research described herein was presented in a special session on ``Synergy between human and machine approaches to sound/scene recognition and processing'' at the 2023 ICASSP meeting.
Composer: Creative and Controllable Image Synthesis with Composable Conditions
Feb 20, 2023


Recent large-scale generative models learned on big data are capable of synthesizing incredible images yet suffer from limited controllability. This work offers a new generation paradigm that allows flexible control of the output image, such as spatial layout and palette, while maintaining the synthesis quality and model creativity. With compositionality as the core idea, we first decompose an image into representative factors, and then train a diffusion model with all these factors as the conditions to recompose the input. At the inference stage, the rich intermediate representations work as composable elements, leading to a huge design space (i.e., exponentially proportional to the number of decomposed factors) for customizable content creation. It is noteworthy that our approach, which we call Composer, supports various levels of conditions, such as text description as the global information, depth map and sketch as the local guidance, color histogram for low-level details, etc. Besides improving controllability, we confirm that Composer serves as a general framework and facilitates a wide range of classical generative tasks without retraining. Code and models will be made available.
Nyström $M$-Hilbert-Schmidt Independence Criterion
Feb 20, 2023
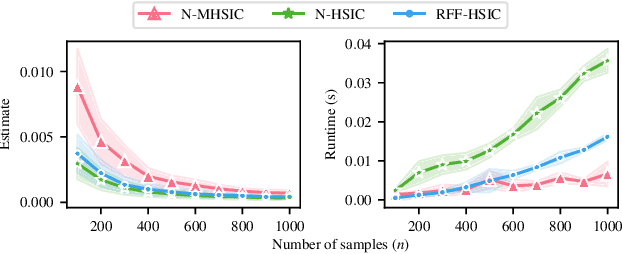
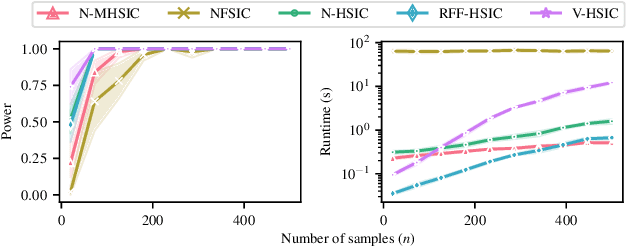
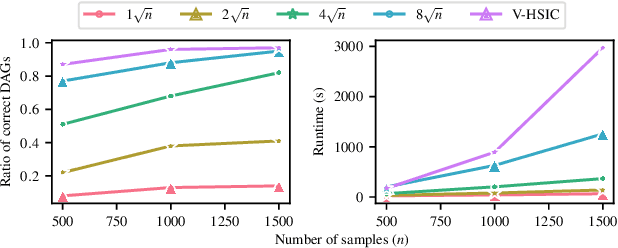
Kernel techniques are among the most popular and powerful approaches of data science. Among the key features that make kernels ubiquitous are (i) the number of domains they have been designed for, (ii) the Hilbert structure of the function class associated to kernels facilitating their statistical analysis, and (iii) their ability to represent probability distributions without loss of information. These properties give rise to the immense success of Hilbert-Schmidt independence criterion (HSIC) which is able to capture joint independence of random variables under mild conditions, and permits closed-form estimators with quadratic computational complexity (w.r.t. the sample size). In order to alleviate the quadratic computational bottleneck in large-scale applications, multiple HSIC approximations have been proposed, however these estimators are restricted to $M=2$ random variables, do not extend naturally to the $M\ge 2$ case, and lack theoretical guarantees. In this work, we propose an alternative Nystr\"om-based HSIC estimator which handles the $M\ge 2$ case, prove its consistency, and demonstrate its applicability in multiple contexts, including synthetic examples, dependency testing of media annotations, and causal discovery.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Feb 20, 2023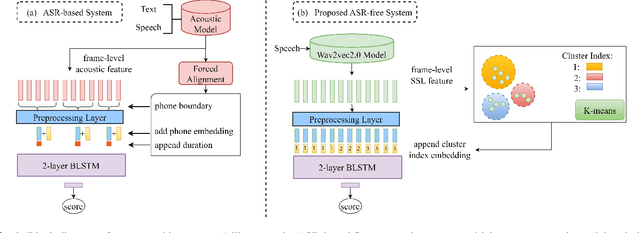
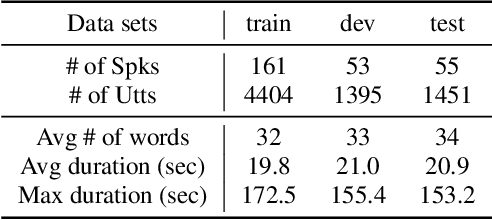
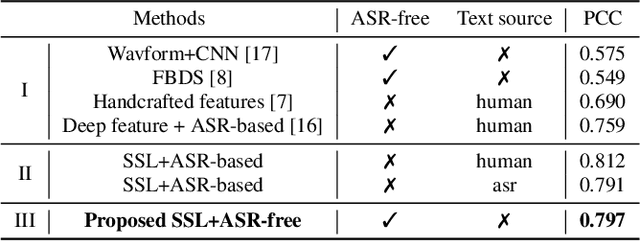
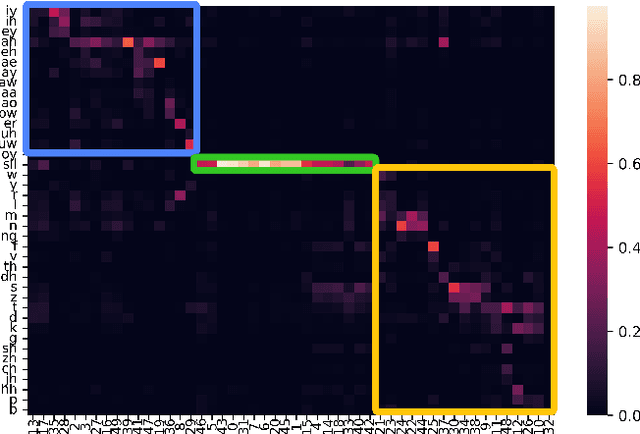
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.