 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Statistical-Computational Tradeoffs in Mixed Sparse Linear Regression
Mar 03, 2023
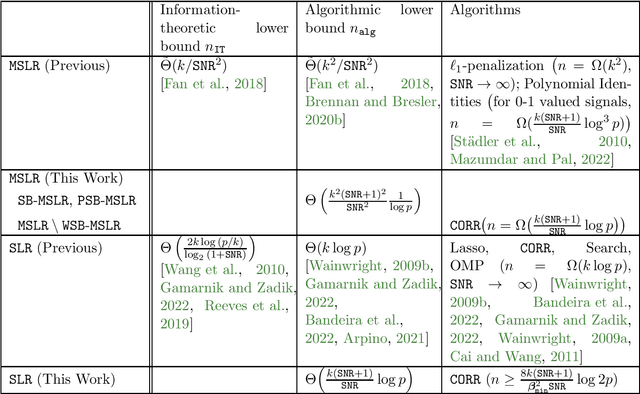
We consider the problem of mixed sparse linear regression with two components, where two real $k$-sparse signals $\beta_1, \beta_2$ are to be recovered from $n$ unlabelled noisy linear measurements. The sparsity is allowed to be sublinear in the dimension, and additive noise is assumed to be independent Gaussian with variance $\sigma^2$. Prior work has shown that the problem suffers from a $\frac{k}{SNR^2}$-to-$\frac{k^2}{SNR^2}$ statistical-to-computational gap, resembling other computationally challenging high-dimensional inference problems such as Sparse PCA and Robust Sparse Mean Estimation; here $SNR$ is the signal-to-noise ratio. We establish the existence of a more extensive computational barrier for this problem through the method of low-degree polynomials, but show that the problem is computationally hard only in a very narrow symmetric parameter regime. We identify a smooth information-computation tradeoff between the sample complexity $n$ and runtime for any randomized algorithm in this hard regime. Via a simple reduction, this provides novel rigorous evidence for the existence of a computational barrier to solving exact support recovery in sparse phase retrieval with sample complexity $n = \tilde{o}(k^2)$. Our second contribution is to analyze a simple thresholding algorithm which, outside of the narrow regime where the problem is hard, solves the associated mixed regression detection problem in $O(np)$ time with square-root the number of samples and matches the sample complexity required for (non-mixed) sparse linear regression; this allows the recovery problem to be subsequently solved by state-of-the-art techniques from the dense case. As a special case of our results, we show that this simple algorithm is order-optimal among a large family of algorithms in solving exact signed support recovery in sparse linear regression.
Anticipate, Ensemble and Prune: Improving Convolutional Neural Networks via Aggregated Early Exits
Jan 28, 2023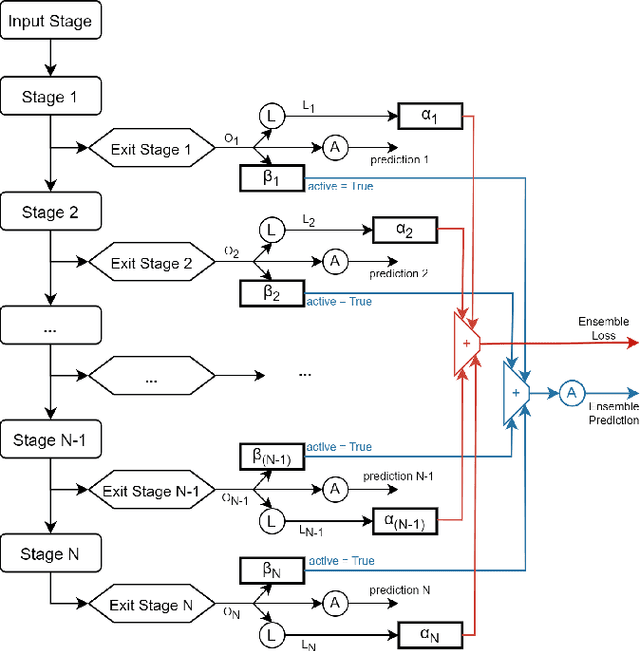

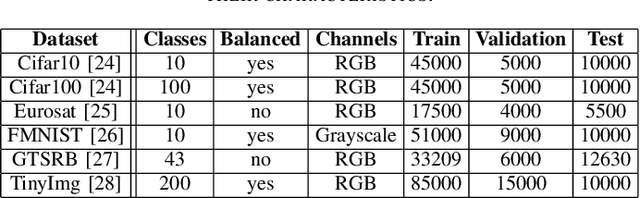
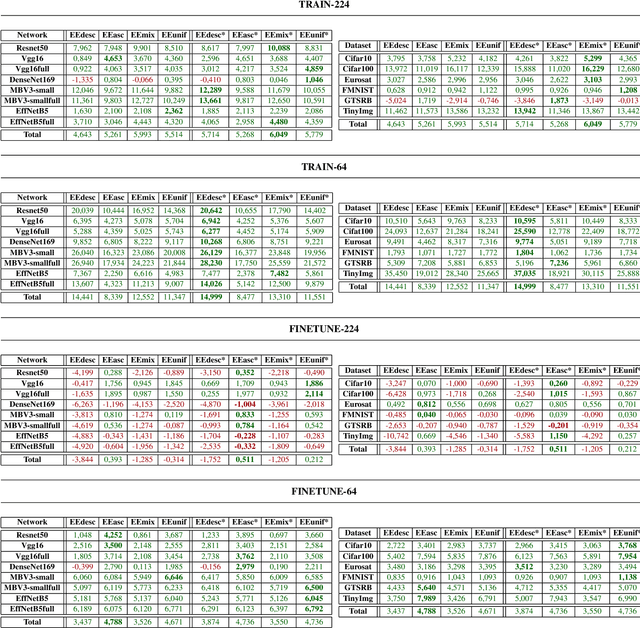
Today, artificial neural networks are the state of the art for solving a variety of complex tasks, especially in image classification. Such architectures consist of a sequence of stacked layers with the aim of extracting useful information and having it processed by a classifier to make accurate predictions. However, intermediate information within such models is often left unused. In other cases, such as in edge computing contexts, these architectures are divided into multiple partitions that are made functional by including early exits, i.e. intermediate classifiers, with the goal of reducing the computational and temporal load without extremely compromising the accuracy of the classifications. In this paper, we present Anticipate, Ensemble and Prune (AEP), a new training technique based on weighted ensembles of early exits, which aims at exploiting the information in the structure of networks to maximise their performance. Through a comprehensive set of experiments, we show how the use of this approach can yield average accuracy improvements of up to 15% over traditional training. In its hybrid-weighted configuration, AEP's internal pruning operation also allows reducing the number of parameters by up to 41%, lowering the number of multiplications and additions by 18% and the latency time to make inference by 16%. By using AEP, it is also possible to learn weights that allow early exits to achieve better accuracy values than those obtained from single-output reference models.
BERT-ERC: Fine-tuning BERT is Enough for Emotion Recognition in Conversation
Jan 17, 2023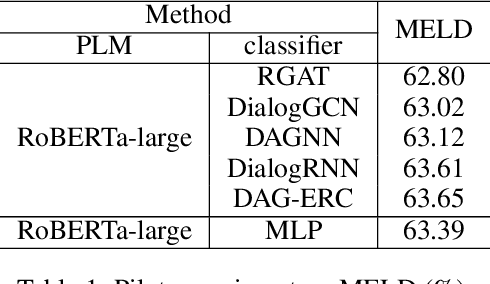
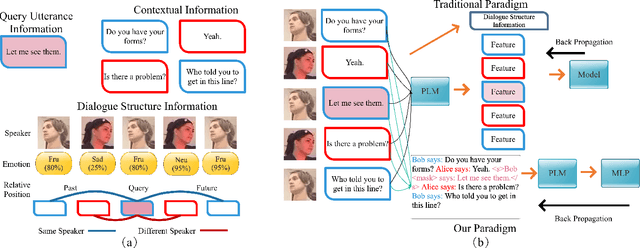
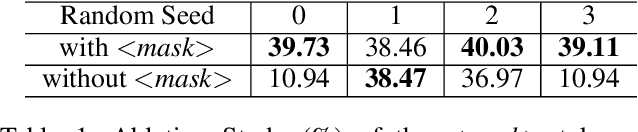
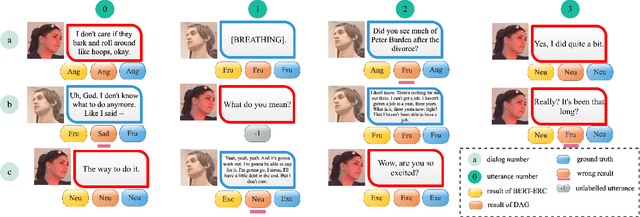
Previous works on emotion recognition in conversation (ERC) follow a two-step paradigm, which can be summarized as first producing context-independent features via fine-tuning pretrained language models (PLMs) and then analyzing contextual information and dialogue structure information among the extracted features. However, we discover that this paradigm has several limitations. Accordingly, we propose a novel paradigm, i.e., exploring contextual information and dialogue structure information in the fine-tuning step, and adapting the PLM to the ERC task in terms of input text, classification structure, and training strategy. Furthermore, we develop our model BERT-ERC according to the proposed paradigm, which improves ERC performance in three aspects, namely suggestive text, fine-grained classification module, and two-stage training. Compared to existing methods, BERT-ERC achieves substantial improvement on four datasets, indicating its effectiveness and generalization capability. Besides, we also set up the limited resources scenario and the online prediction scenario to approximate real-world scenarios. Extensive experiments demonstrate that the proposed paradigm significantly outperforms the previous one and can be adapted to various scenes.
Lifting the Information Ratio: An Information-Theoretic Analysis of Thompson Sampling for Contextual Bandits
May 27, 2022We study the Bayesian regret of the renowned Thompson Sampling algorithm in contextual bandits with binary losses and adversarially-selected contexts. We adapt the information-theoretic perspective of Russo and Van Roy [2016] to the contextual setting by introducing a new concept of information ratio based on the mutual information between the unknown model parameter and the observed loss. This allows us to bound the regret in terms of the entropy of the prior distribution through a remarkably simple proof, and with no structural assumptions on the likelihood or the prior. The extension to priors with infinite entropy only requires a Lipschitz assumption on the log-likelihood. An interesting special case is that of logistic bandits with d-dimensional parameters, K actions, and Lipschitz logits, for which we provide a $\widetilde{O}(\sqrt{dKT})$ regret upper-bound that does not depend on the smallest slope of the sigmoid link function.
Semantic-Guided Image Augmentation with Pre-trained Models
Feb 04, 2023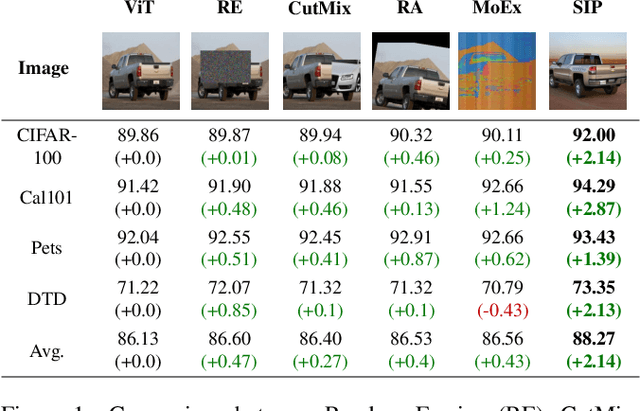
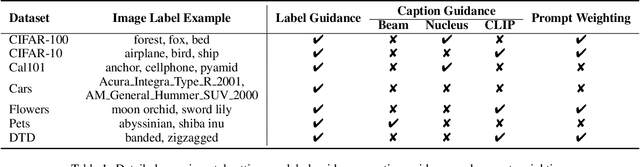
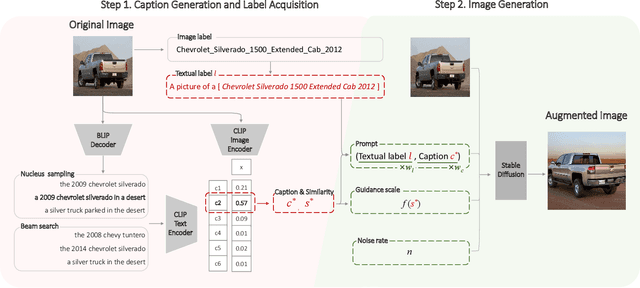
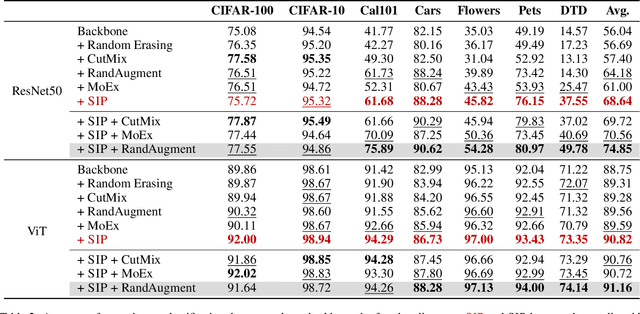
Image augmentation is a common mechanism to alleviate data scarcity in computer vision. Existing image augmentation methods often apply pre-defined transformations or mixup to augment the original image, but only locally vary the image. This makes them struggle to find a balance between maintaining semantic information and improving the diversity of augmented images. In this paper, we propose a Semantic-guided Image augmentation method with Pre-trained models (SIP). Specifically, SIP constructs prompts with image labels and captions to better guide the image-to-image generation process of the pre-trained Stable Diffusion model. The semantic information contained in the original images can be well preserved, and the augmented images still maintain diversity. Experimental results show that SIP can improve two commonly used backbones, i.e., ResNet-50 and ViT, by 12.60% and 2.07% on average over seven datasets, respectively. Moreover, SIP not only outperforms the best image augmentation baseline RandAugment by 4.46% and 1.23% on two backbones, but also further improves the performance by integrating naturally with the baseline. A detailed analysis of SIP is presented, including the diversity of augmented images, an ablation study on textual prompts, and a case study on the generated images.
Stock Broad-Index Trend Patterns Learning via Domain Knowledge Informed Generative Network
Feb 27, 2023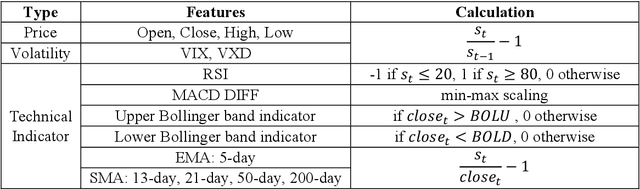
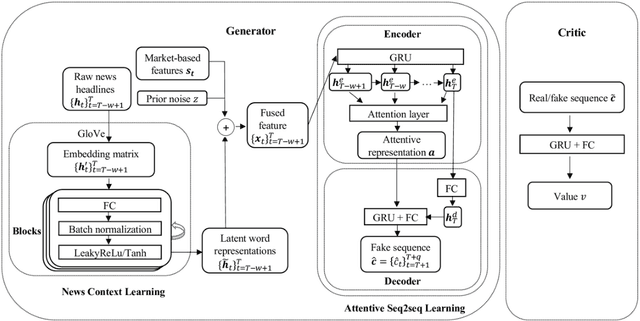

Predicting the Stock movement attracts much attention from both industry and academia. Despite such significant efforts, the results remain unsatisfactory due to the inherently complicated nature of the stock market driven by factors including supply and demand, the state of the economy, the political climate, and even irrational human behavior. Recently, Generative Adversarial Networks (GAN) have been extended for time series data; however, robust methods are primarily for synthetic series generation, which fall short for appropriate stock prediction. This is because existing GANs for stock applications suffer from mode collapse and only consider one-step prediction, thus underutilizing the potential of GAN. Furthermore, merging news and market volatility are neglected in current GANs. To address these issues, we exploit expert domain knowledge in finance and, for the first time, attempt to formulate stock movement prediction into a Wasserstein GAN framework for multi-step prediction. We propose IndexGAN, which includes deliberate designs for the inherent characteristics of the stock market, leverages news context learning to thoroughly investigate textual information and develop an attentive seq2seq learning network that captures the temporal dependency among stock prices, news, and market sentiment. We also utilize the critic to approximate the Wasserstein distance between actual and predicted sequences and develop a rolling strategy for deployment that mitigates noise from the financial market. Extensive experiments are conducted on real-world broad-based indices, demonstrating the superior performance of our architecture over other state-of-the-art baselines, also validating all its contributing components.
Multi-Action Dialog Policy Learning from Logged User Feedback
Feb 27, 2023
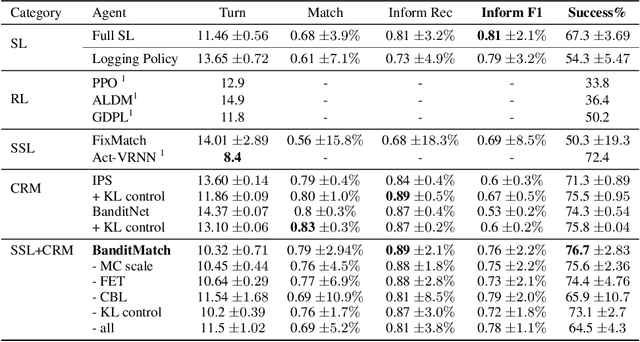
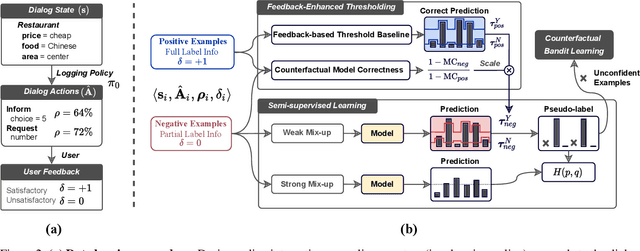
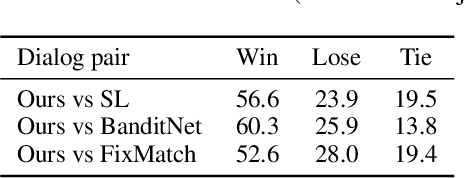
Multi-action dialog policy, which generates multiple atomic dialog actions per turn, has been widely applied in task-oriented dialog systems to provide expressive and efficient system responses. Existing policy models usually imitate action combinations from the labeled multi-action dialog examples. Due to data limitations, they generalize poorly toward unseen dialog flows. While reinforcement learning-based methods are proposed to incorporate the service ratings from real users and user simulators as external supervision signals, they suffer from sparse and less credible dialog-level rewards. To cope with this problem, we explore to improve multi-action dialog policy learning with explicit and implicit turn-level user feedback received for historical predictions (i.e., logged user feedback) that are cost-efficient to collect and faithful to real-world scenarios. The task is challenging since the logged user feedback provides only partial label feedback limited to the particular historical dialog actions predicted by the agent. To fully exploit such feedback information, we propose BanditMatch, which addresses the task from a feedback-enhanced semi-supervised learning perspective with a hybrid objective of semi-supervised learning and bandit learning. BanditMatch integrates pseudo-labeling methods to better explore the action space through constructing full label feedback. Extensive experiments show that our BanditMatch outperforms the state-of-the-art methods by generating more concise and informative responses. The source code and the appendix of this paper can be obtained from https://github.com/ShuoZhangXJTU/BanditMatch.
Predicting EEG Responses to Attended Speech via Deep Neural Networks for Speech
Feb 27, 2023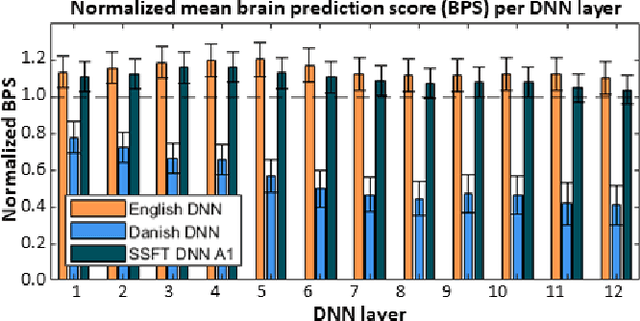
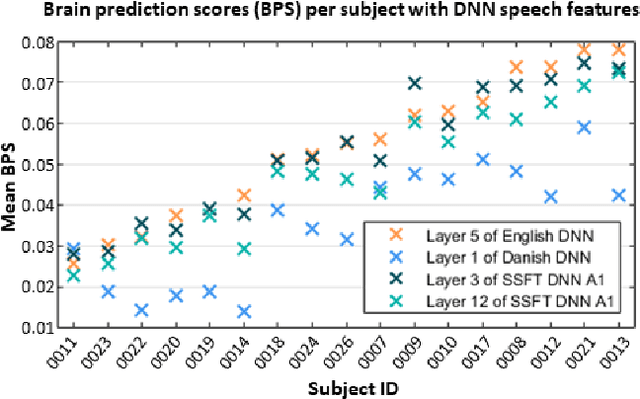
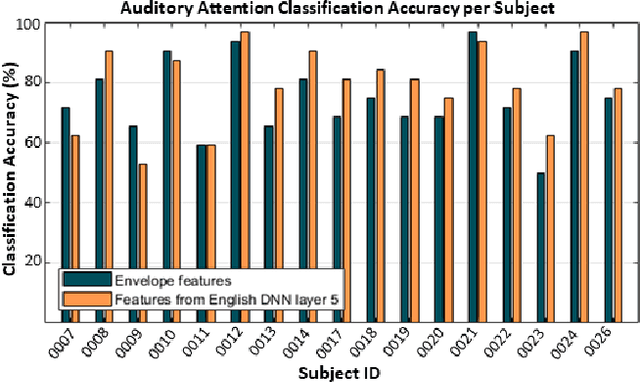
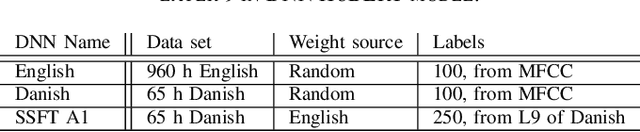
Attending to the speech stream of interest in multi-talker environments can be a challenging task, particularly for listeners with hearing impairment. Research suggests that neural responses assessed with electroencephalography (EEG) are modulated by listener`s auditory attention, revealing selective neural tracking (NT) of the attended speech. NT methods mostly rely on hand-engineered acoustic and linguistic speech features to predict the neural response. Only recently, deep neural network (DNN) models without specific linguistic information have been used to extract speech features for NT, demonstrating that speech features in hierarchical DNN layers can predict neural responses throughout the auditory pathway. In this study, we go one step further to investigate the suitability of similar DNN models for speech to predict neural responses to competing speech observed in EEG. We recorded EEG data using a 64-channel acquisition system from 17 listeners with normal hearing instructed to attend to one of two competing talkers. Our data revealed that EEG responses are significantly better predicted by DNN-extracted speech features than by hand-engineered acoustic features. Furthermore, analysis of hierarchical DNN layers showed that early layers yielded the highest predictions. Moreover, we found a significant increase in auditory attention classification accuracies with the use of DNN-extracted speech features over the use of hand-engineered acoustic features. These findings open a new avenue for development of new NT measures to evaluate and further advance hearing technology.
Self-supervised Learning for Heterogeneous Graph via Structure Information based on Metapath
Sep 09, 2022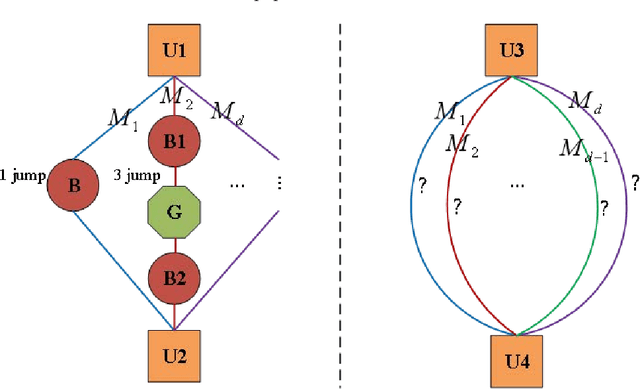
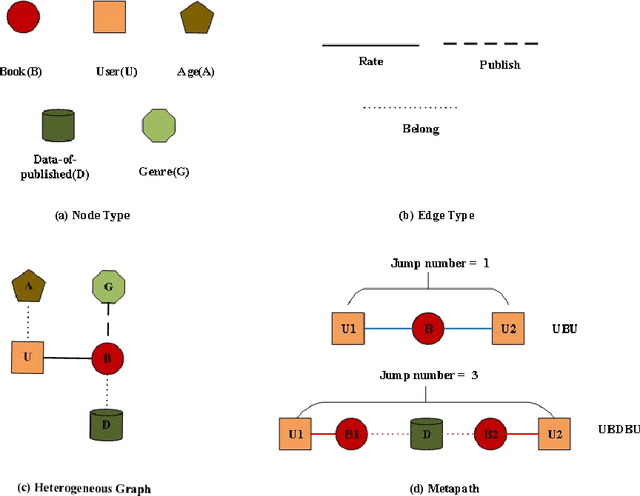
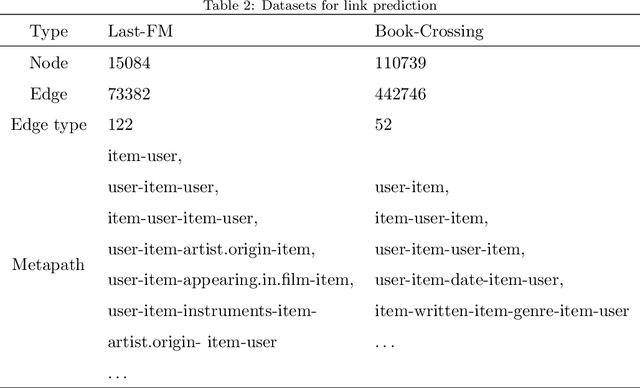
graph neural networks (GNNs) are the dominant paradigm for modeling and handling graph structure data by learning universal node representation. The traditional way of training GNNs depends on a great many labeled data, which results in high requirements on cost and time. In some special scene, it is even unavailable and impracticable. Self-supervised representation learning, which can generate labels by graph structure data itself, is a potential approach to tackle this problem. And turning to research on self-supervised learning problem for heterogeneous graphs is more challenging than dealing with homogeneous graphs, also there are fewer studies about it. In this paper, we propose a SElfsupervised learning method for heterogeneous graph via Structure Information based on Metapath (SESIM). The proposed model can construct pretext tasks by predicting jump number between nodes in each metapath to improve the representation ability of primary task. In order to predict jump number, SESIM uses data itself to generate labels, avoiding time-consuming manual labeling. Moreover, predicting jump number in each metapath can effectively utilize graph structure information, which is the essential property between nodes. Therefore, SESIM deepens the understanding of models for graph structure. At last, we train primary task and pretext tasks jointly, and use meta-learning to balance the contribution of pretext tasks for primary task. Empirical results validate the performance of SESIM method and demonstrate that this method can improve the representation ability of traditional neural networks on link prediction task and node classification task.
Time-aware Multiway Adaptive Fusion Network for Temporal Knowledge Graph Question Answering
Feb 24, 2023
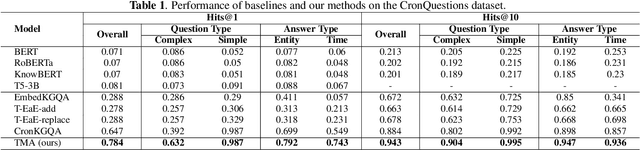
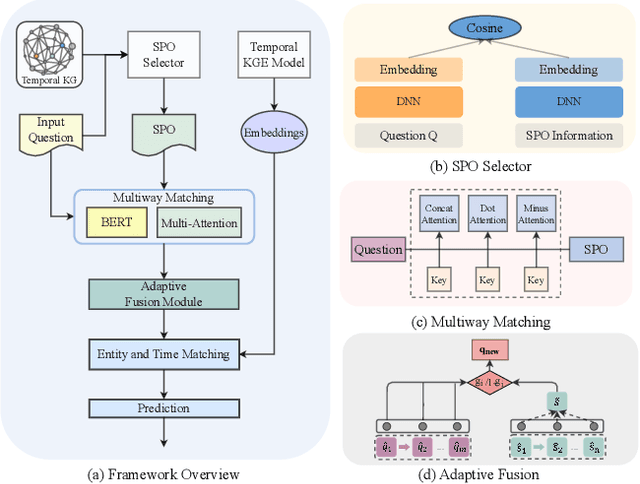
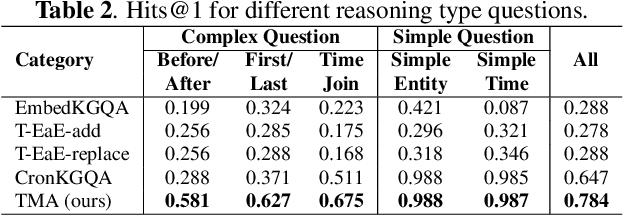
Knowledge graphs (KGs) have received increasing attention due to its wide applications on natural language processing. However, its use case on temporal question answering (QA) has not been well-explored. Most of existing methods are developed based on pre-trained language models, which might not be capable to learn \emph{temporal-specific} presentations of entities in terms of temporal KGQA task. To alleviate this problem, we propose a novel \textbf{T}ime-aware \textbf{M}ultiway \textbf{A}daptive (\textbf{TMA}) fusion network. Inspired by the step-by-step reasoning behavior of humans. For each given question, TMA first extracts the relevant concepts from the KG, and then feeds them into a multiway adaptive module to produce a \emph{temporal-specific} representation of the question. This representation can be incorporated with the pre-trained KG embedding to generate the final prediction. Empirical results verify that the proposed model achieves better performance than the state-of-the-art models in the benchmark dataset. Notably, the Hits@1 and Hits@10 results of TMA on the CronQuestions dataset's complex questions are absolutely improved by 24\% and 10\% compared to the best-performing baseline. Furthermore, we also show that TMA employing an adaptive fusion mechanism can provide interpretability by analyzing the proportion of information in question representations.
* ICASSP 2023