 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Game and Reference: Policy Combination Synthesis for Epidemic Prevention and Control
Mar 16, 2024
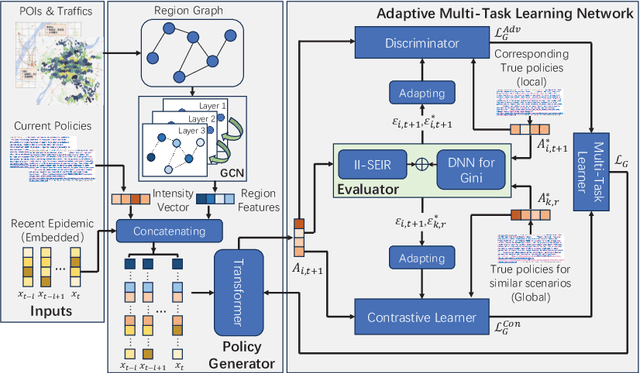
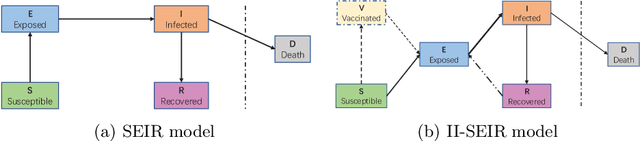
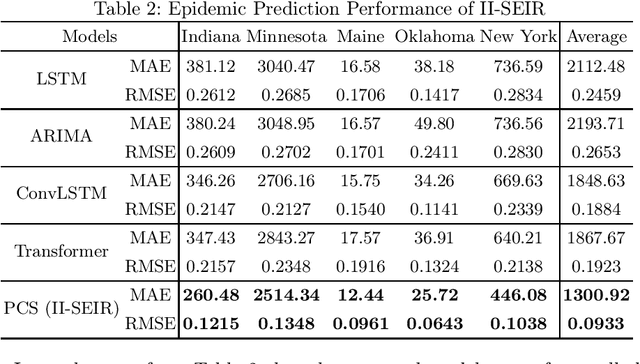

In recent years, epidemic policy-making models are increasingly being used to provide reference for governors on prevention and control policies against catastrophic epidemics such as SARS, H1N1 and COVID-19. Existing studies are currently constrained by two issues: First, previous methods develop policies based on effect evaluation, since few of factors in real-world decision-making can be modeled, the output policies will then easily become extreme. Second, the subjectivity and cognitive limitation of human make the historical policies not always optimal for the training of decision models. To these ends, we present a novel Policy Combination Synthesis (PCS) model for epidemic policy-making. Specially, to prevent extreme decisions, we introduce adversarial learning between the model-made policies and the real policies to force the output policies to be more human-liked. On the other hand, to minimize the impact of sub-optimal historical policies, we employ contrastive learning to let the model draw on experience from the best historical policies under similar scenarios. Both adversarial and contrastive learning are adaptive based on the comprehensive effects of real policies to ensure the model always learns useful information. Extensive experiments on real-world data prove the effectiveness of the proposed model.
Understanding Robustness of Visual State Space Models for Image Classification
Mar 16, 2024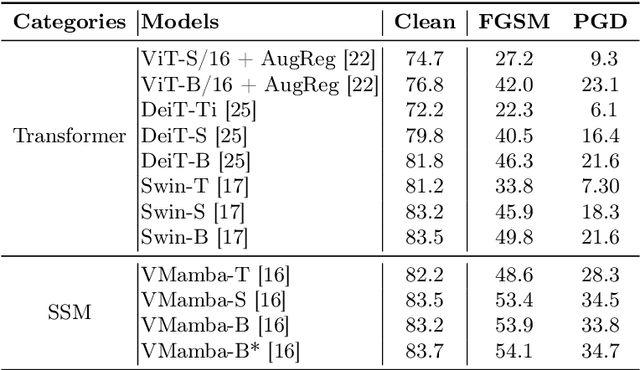

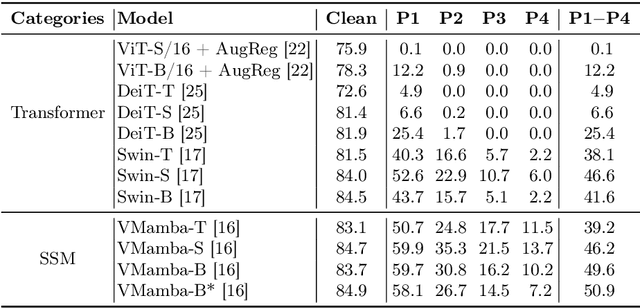
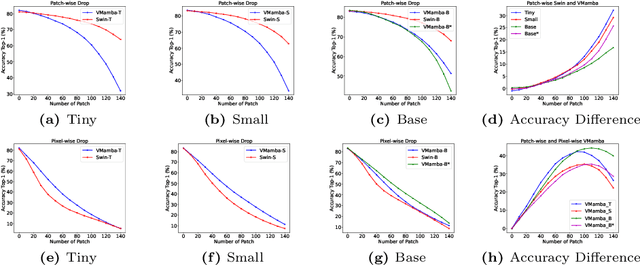
Visual State Space Model (VMamba) has recently emerged as a promising architecture, exhibiting remarkable performance in various computer vision tasks. However, its robustness has not yet been thoroughly studied. In this paper, we delve into the robustness of this architecture through comprehensive investigations from multiple perspectives. Firstly, we investigate its robustness to adversarial attacks, employing both whole-image and patch-specific adversarial attacks. Results demonstrate superior adversarial robustness compared to Transformer architectures while revealing scalability weaknesses. Secondly, the general robustness of VMamba is assessed against diverse scenarios, including natural adversarial examples, out-of-distribution data, and common corruptions. VMamba exhibits exceptional generalizability with out-of-distribution data but shows scalability weaknesses against natural adversarial examples and common corruptions. Additionally, we explore VMamba's gradients and back-propagation during white-box attacks, uncovering unique vulnerabilities and defensive capabilities of its novel components. Lastly, the sensitivity of VMamba to image structure variations is examined, highlighting vulnerabilities associated with the distribution of disturbance areas and spatial information, with increased susceptibility closer to the image center. Through these comprehensive studies, we contribute to a deeper understanding of VMamba's robustness, providing valuable insights for refining and advancing the capabilities of deep neural networks in computer vision applications.
Affective Behaviour Analysis via Integrating Multi-Modal Knowledge
Mar 16, 2024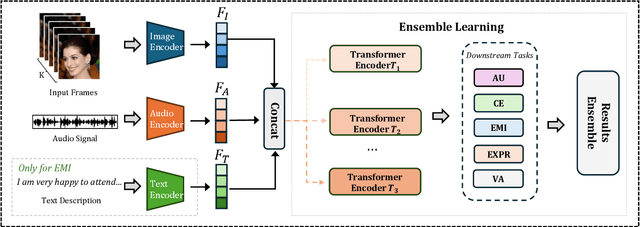
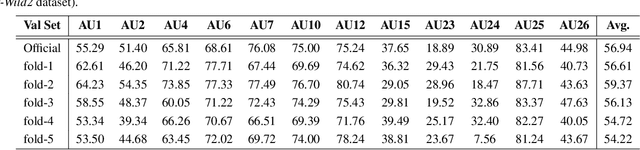
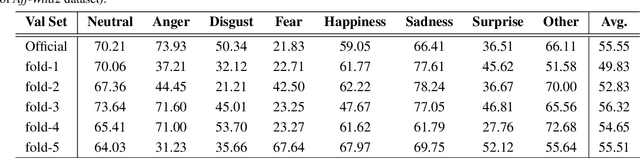
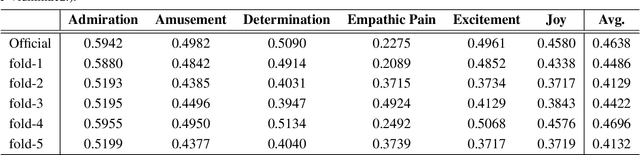
Affective Behavior Analysis aims to facilitate technology emotionally smart, creating a world where devices can understand and react to our emotions as humans do. To comprehensively evaluate the authenticity and applicability of emotional behavior analysis techniques in natural environments, the 6th competition on Affective Behavior Analysis in-the-wild (ABAW) utilizes the Aff-Wild2, Hume-Vidmimic2, and C-EXPR-DB datasets to set up five competitive tracks, i.e., Valence-Arousal (VA) Estimation, Expression (EXPR) Recognition, Action Unit (AU) Detection, Compound Expression (CE) Recognition, and Emotional Mimicry Intensity (EMI) Estimation. In this paper, we present our method designs for the five tasks. Specifically, our design mainly includes three aspects: 1) Utilizing a transformer-based feature fusion module to fully integrate emotional information provided by audio signals, visual images, and transcripts, offering high-quality expression features for the downstream tasks. 2) To achieve high-quality facial feature representations, we employ Masked-Auto Encoder as the visual features extraction model and fine-tune it with our facial dataset. 3) Considering the complexity of the video collection scenes, we conduct a more detailed dataset division based on scene characteristics and train the classifier for each scene. Extensive experiments demonstrate the superiority of our designs.
SF(DA)$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024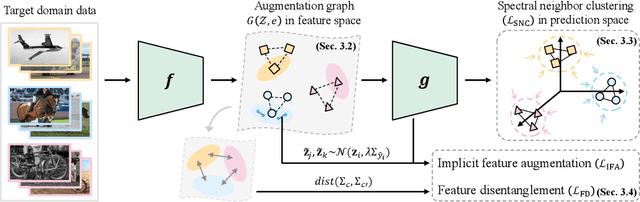
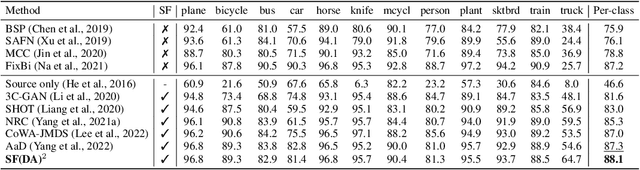
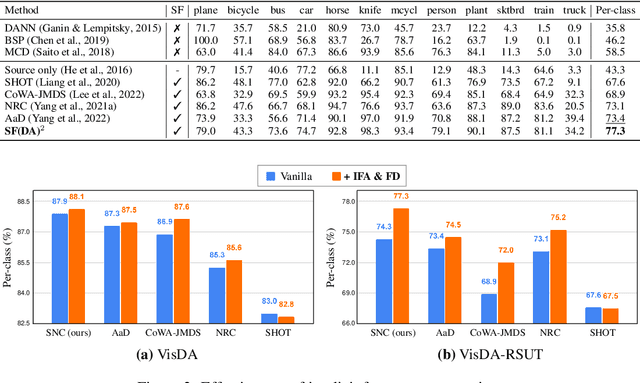
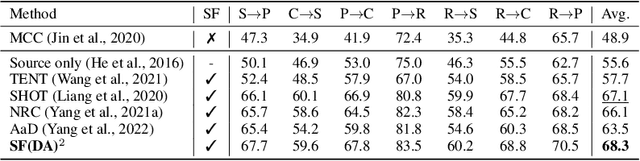
In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.
ContourDiff: Unpaired Image Translation with Contour-Guided Diffusion Models
Mar 16, 2024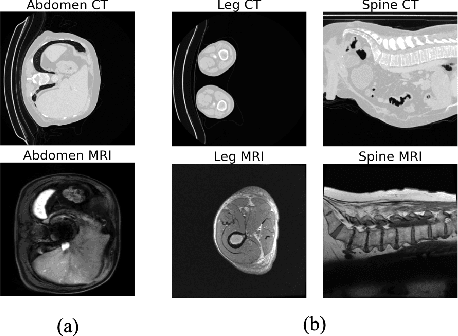
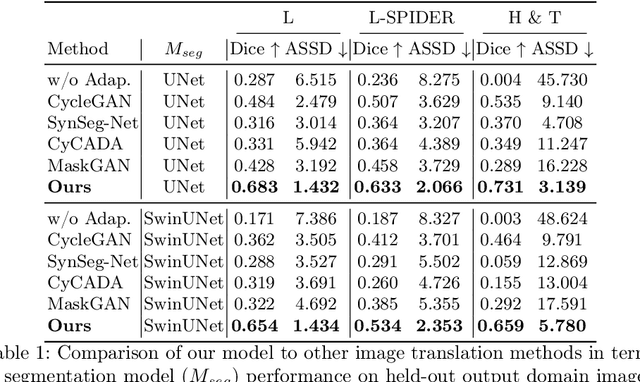
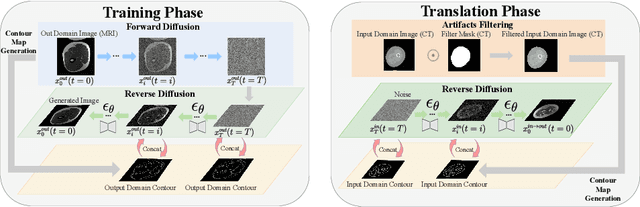
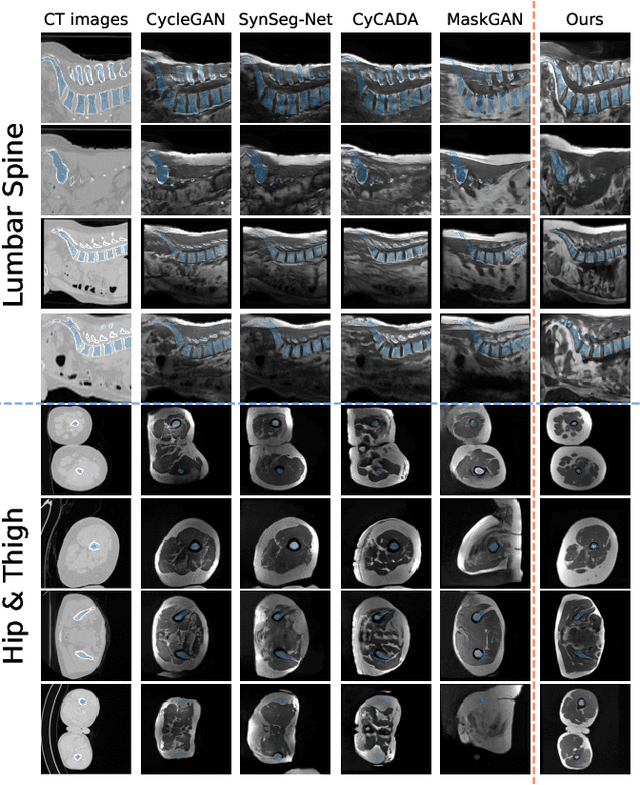
Accurately translating medical images across different modalities (e.g., CT to MRI) has numerous downstream clinical and machine learning applications. While several methods have been proposed to achieve this, they often prioritize perceptual quality with respect to output domain features over preserving anatomical fidelity. However, maintaining anatomy during translation is essential for many tasks, e.g., when leveraging masks from the input domain to develop a segmentation model with images translated to the output domain. To address these challenges, we propose ContourDiff, a novel framework that leverages domain-invariant anatomical contour representations of images. These representations are simple to extract from images, yet form precise spatial constraints on their anatomical content. We introduce a diffusion model that converts contour representations of images from arbitrary input domains into images in the output domain of interest. By applying the contour as a constraint at every diffusion sampling step, we ensure the preservation of anatomical content. We evaluate our method by training a segmentation model on images translated from CT to MRI with their original CT masks and testing its performance on real MRIs. Our method outperforms other unpaired image translation methods by a significant margin, furthermore without the need to access any input domain information during training.
Data-Efficient Sleep Staging with Synthetic Time Series Pretraining
Mar 13, 2024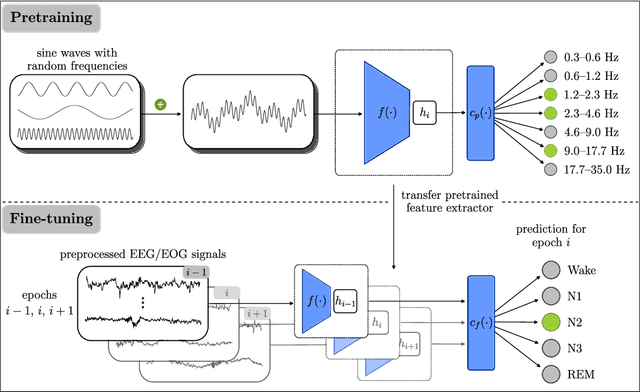
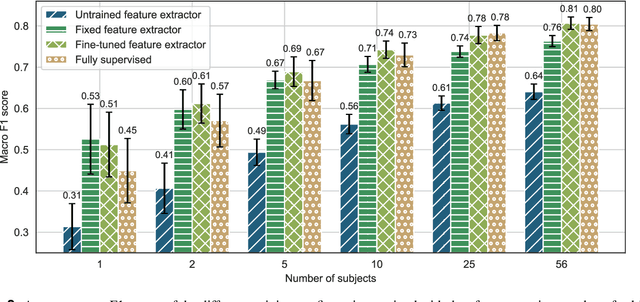
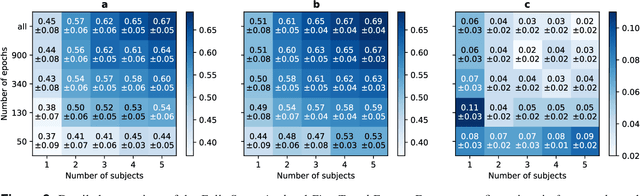
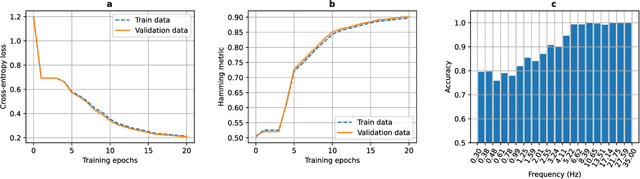
Analyzing electroencephalographic (EEG) time series can be challenging, especially with deep neural networks, due to the large variability among human subjects and often small datasets. To address these challenges, various strategies, such as self-supervised learning, have been suggested, but they typically rely on extensive empirical datasets. Inspired by recent advances in computer vision, we propose a pretraining task termed "frequency pretraining" to pretrain a neural network for sleep staging by predicting the frequency content of randomly generated synthetic time series. Our experiments demonstrate that our method surpasses fully supervised learning in scenarios with limited data and few subjects, and matches its performance in regimes with many subjects. Furthermore, our results underline the relevance of frequency information for sleep stage scoring, while also demonstrating that deep neural networks utilize information beyond frequencies to enhance sleep staging performance, which is consistent with previous research. We anticipate that our approach will be advantageous across a broad spectrum of applications where EEG data is limited or derived from a small number of subjects, including the domain of brain-computer interfaces.
From Channel Measurement to Training Data for PHY Layer AI Applications
Mar 13, 2024

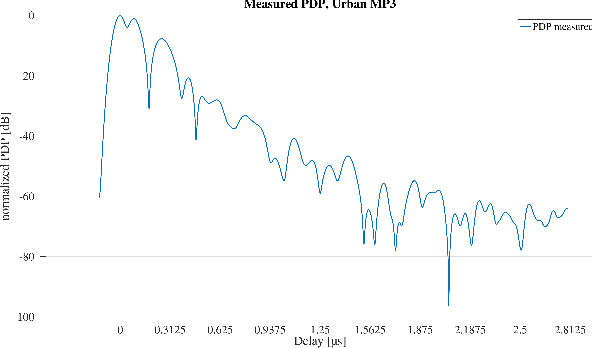
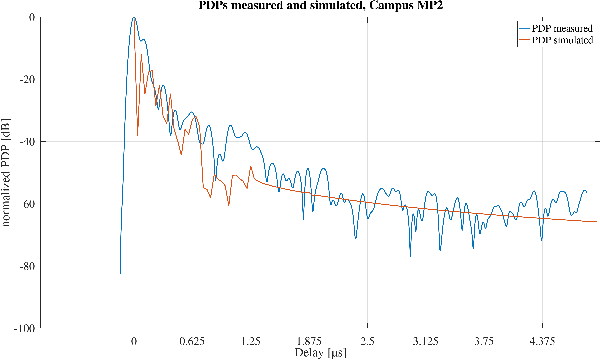
Learning-based techniques such as artificial intelligence (AI) and machine learning (ML) play an increasingly important role in the development of future communication networks. The success of a learning algorithm depends on the quality and quantity of the available training data. In the physical layer (PHY), channel information data can be obtained either through measurement campaigns or through simulations based on predefined channel models. Performing measurements can be time consuming while only gaining information about one specific position or scenario. Simulated data, on the other hand, are more generalized and reflect in most cases not a real environment but instead, a statistical approximation based on a mathematical model. This paper presents a procedure for acquiring channel data by means of fast and flexible software defined radio (SDR) based channel measurements along with a method for a parameter extraction that provides configuration input to the simulator. The procedure from the measurement to the simulated channel data is demonstrated in two exemplary propagation scenarios. It is shown, that in both cases the simulated data is in good accordance to the measurements
A Belief Propagation Algorithm for Multipath-based SLAM with Multiple Map Features: A mmWave MIMO Application
Mar 15, 2024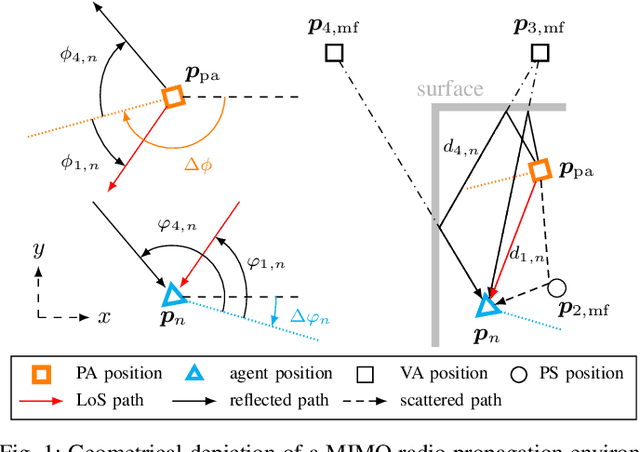
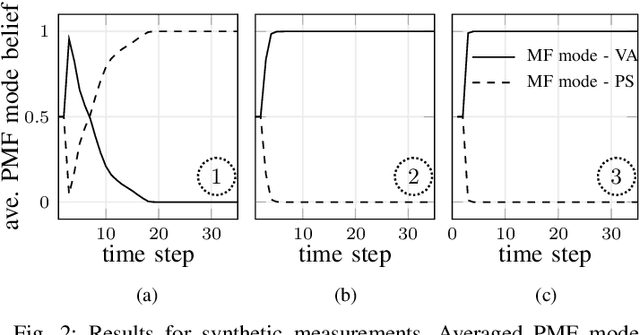

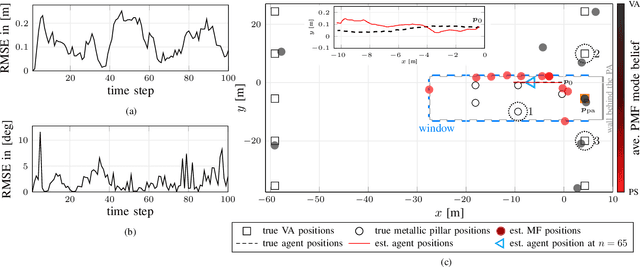
In this paper, we present a multipath-based simultaneous localization and mapping (SLAM) algorithm that continuously adapts mulitiple map feature (MF) models describing specularly reflected multipath components (MPCs) from flat surfaces and point-scattered MPCs, respectively. We develop a Bayesian model for sequential detection and estimation of interacting MF model parameters, MF states and mobile agent's state including position and orientation. The Bayesian model is represented by a factor graph enabling the use of belief propagation (BP) for efficient computation of the marginal posterior distributions. The algorithm also exploits amplitude information enabling reliable detection of weak MFs associated with MPCs of very low signal-to-noise ratios (SNRs). The performance of the proposed algorithm is evaluated using real millimeter-wave (mmWave) multiple-input-multiple-output (MIMO) measurements with single base station setup. Results demonstrate the excellent localization and mapping performance of the proposed algorithm in challenging dynamic outdoor scenarios.
MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling
Mar 15, 2024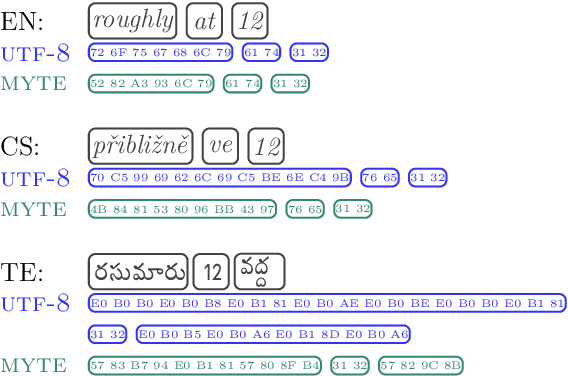
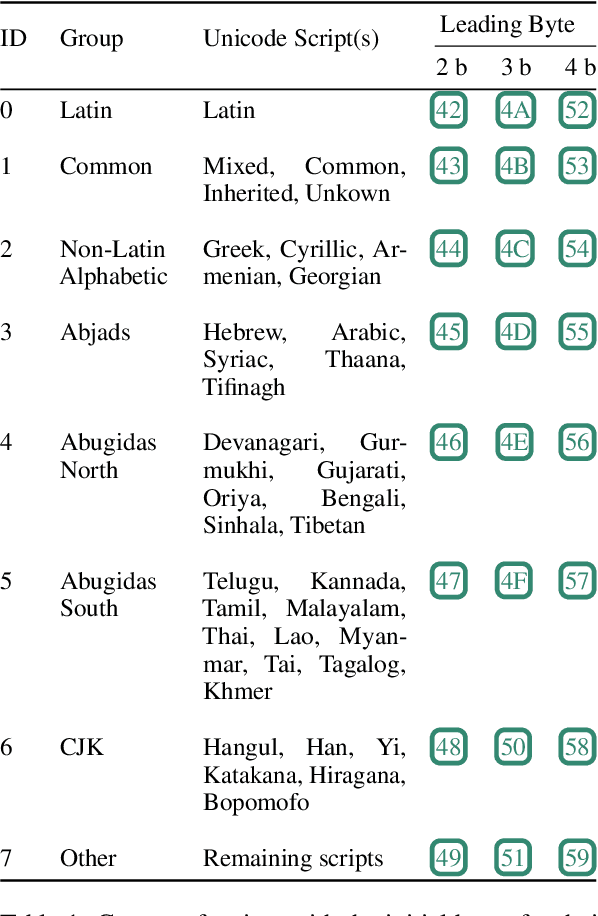
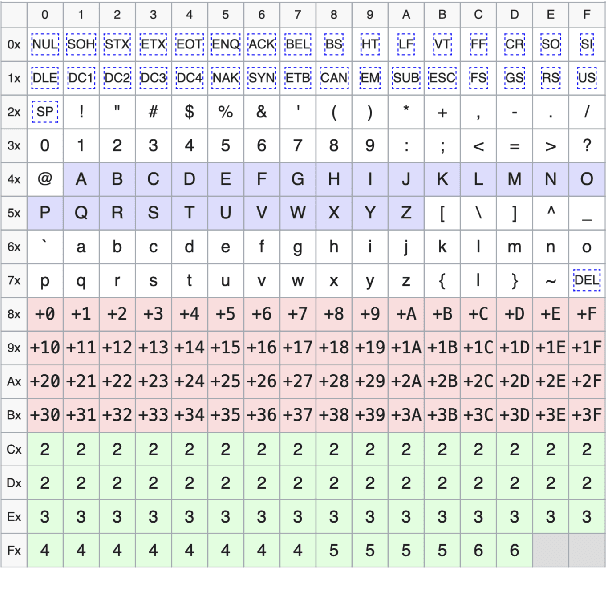
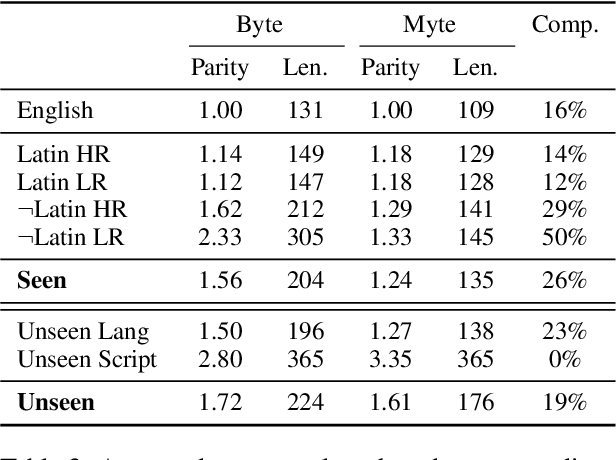
A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world's writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.
Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising
Mar 15, 2024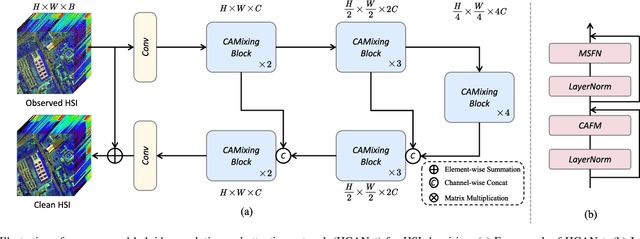
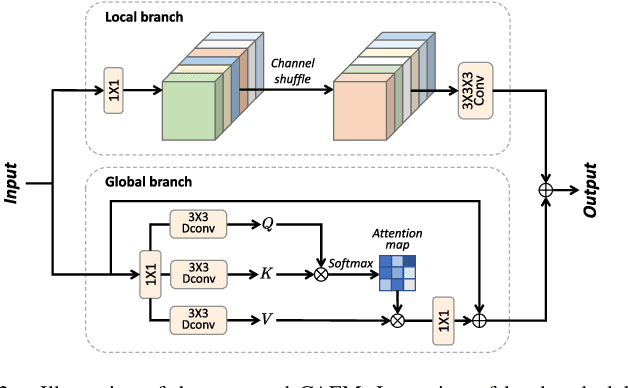
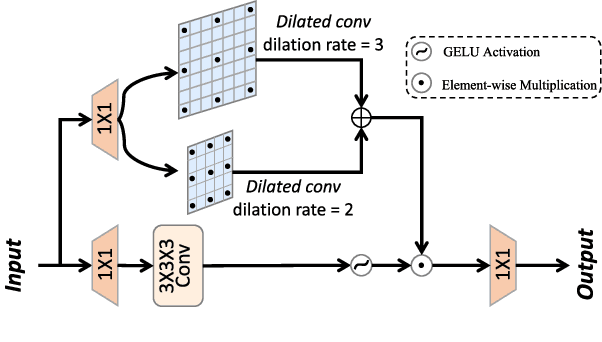

Hyperspectral image (HSI) denoising is critical for the effective analysis and interpretation of hyperspectral data. However, simultaneously modeling global and local features is rarely explored to enhance HSI denoising. In this letter, we propose a hybrid convolution and attention network (HCANet), which leverages both the strengths of convolution neural networks (CNNs) and Transformers. To enhance the modeling of both global and local features, we have devised a convolution and attention fusion module aimed at capturing long-range dependencies and neighborhood spectral correlations. Furthermore, to improve multi-scale information aggregation, we design a multi-scale feed-forward network to enhance denoising performance by extracting features at different scales. Experimental results on mainstream HSI datasets demonstrate the rationality and effectiveness of the proposed HCANet. The proposed model is effective in removing various types of complex noise. Our codes are available at \url{https://github.com/summitgao/HCANet}.